805 KiB
🗣️ #258 - Quick-start Guide coming over from llama.cpp and ktransformers!
| Author | ubergarm |
|---|---|
| Created | 2025-03-14 |
| Updated | 2025-07-13 |
Description
ik_llama.cpp
Last Updated: Tue May 13 03:52:20 PM EDT 2025 (still needs more updates, can't keep up, check through comments below)
NEW: Two new custom quants great for CPU+GPU or CPU only inferencing fitting 32k+ context in under 24GB VRAM here on huggingface ubergarm/DeepSeek-V3-0324-GGUF! or start out with the quant you already have to kick the tires on ik_llama.cpp.
tl;dr;
ik_llama.cpp is a custom fork of llama.cpp introducing many interesting optimizations for MoE's like DeepSeek-R1 671B.
The new SOTA quant types can repack your existing GGUFs on the fly or you can roll your own to maximize quality and speed for your exact system VRAM and RAM availability.
I highly recommend you give ik_llama.cpp a try especially for CUDA+CPU or pure CPU inferencing. All the very similar ergonmics as vanilla llama-server that you already know and love.
- 64k context in under 24GB VRAM with over 15 tok/sec on a ThreadRipper Pro 24x core with 256GB RAM with single GPU.
- Gaming rig 9950X + 96GB RAM + 3090TI 24GB VRAM + NVMe for over 4 toks/sec!
- Fastest available implementation for DeepSeek-R1 671B on pure CPU dual socket Intel 6890P in my testing.
Install
# Install build dependencies and cuda toolkit as needed
# Clone
git clone https://github.com/ikawrakow/ik_llama.cpp
cd ik_llama.cpp
# Configure CUDA+CPU Backend
cmake -B ./build -DGGML_CUDA=ON -DGGML_BLAS=OFF
# *or* Configure CPU Only Backend
cmake -B ./build -DGGML_CUDA=OFF -DGGML_BLAS=OFF
# Build
cmake --build ./build --config Release -j $(nproc)
# Confirm
./build/bin/llama-server --version
version: 3597 (68a5b604)
Features
# Flash MLA & FlashMLA-2 & Flash Attention
# https://github.com/ikawrakow/ik_llama.cpp/pull/240
# https://github.com/ikawrakow/ik_llama.cpp/pull/253
# -fa, --flash-attn <0|1> (default: 0) # (for both CPU and CUDA)
# -mla, --mla-attn <0|1|2|3> (default: 0) # -mla 1 for CPU only, -mla 2 for both CPU and CUDA, -mla 3 for CPU only
# *NOTE*: for llama-bench use `-fa 1`
# *UPDATE*: you can use `-mla 3` now for CPU+GPU with new PR
# tl;dr; generally use -mla 2 for CPU+GPU and use -mla 3 for CPU assuming your model architecture supports MLA
-mla 2 -fa
## On-the-Fly MLA Tensors
# To run existing R1 671B quants that are missing MLA tensors *without* the need to roll your own
# https://github.com/ikawrakow/ik_llama.cpp/pull/259
# This means you can run your existing unsloth quants with full FlashMLA-2 support without downloading another quant!!!
# KV Cache Quantization
# https://github.com/ikawrakow/ik_llama.cpp/pull/208
# https://github.com/ikawrakow/ik_llama.cpp/pull/240#issue-2890555894
# -ctk, --cache-type-k TYPE KV cache data type for K (default: f16)
# -ctv, --cache-type-v TYPE KV cache data type for V (default: f16)
-ctk q8_0
# Re-Use K*Q tensor compute buffer specify size
# (for both CPU and CUDA)
# https://github.com/ikawrakow/ik_llama.cpp/pull/237
# (i = Size in MiB)
# -amb, --attn-max-batch <i> (default: 0)
-amb 512 # 512 MiB compute buffer is a good for DeepSeek-R1 671B on a single <24GB VRAM GPU
# Fused MoE
# (For CUDA and maybe CPU when not using computing an imatrix?)
# https://github.com/ikawrakow/ik_llama.cpp/pull/229
# -fmoe, --fused-moe <0|1> (default: 0)
# *NOTE*: for llama-bench use `-fmoe 1`
-fmoe
# Override Model Tensor Buffers
# (For CUDA or possibly RPC or other GPU backends)
# https://github.com/ikawrakow/ik_llama.cpp/pull/232
# -ot, --override-tensor pattern (default: none)
# *NOTE*: this now works with `mmap()` so run models too big for your RAM!
-ot exps=CPU -ngl 99 # put the MoE experts on CPU and the rest in GPU for max speed on lowish VRAM
# if you have multiple GPUs, this can get confusing, so take your time and start small and craft a regex for your setup
# Smart Expert Reduction
# https://github.com/ikawrakow/ik_llama.cpp/pull/239
# -ser, --smart-expert-reduction <i,f> (default: 0)
-ser 7,1 # or 6,1 or 5,1 for faster trading off quality for speed
# Run Time Repack
# Repack quants for improved performance for certain quants and hardware configs
# this disables mmap so need enough RAM to malloc all repacked quants (so pre-pack it yourself ahead of time with llama-quantize)
# (Optimize speed for repacked tensors on some CPUs - is good to use with hybrid GPU + CPU)
# https://github.com/ikawrakow/ik_llama.cpp/pull/147
# -rtr, --run-time-repack <0|1> (default: 0)
-rtr
# Offline Repacking Existing Quants
# Maximize quality, size, and speed
# Selecting quants for each tensor appropriate to your hybrid CPU/GPU configuration
# Remember repacked quants e.g. ending with `_R4` won't *run* on CUDA just sit there like expensive "RAM".
# https://github.com/ikawrakow/ik_llama.cpp/pull/274
# SoTA non-linear Quants with good CPU performance
# https://github.com/ikawrakow/ik_llama.cpp/pull/85
# ./bin/llama-quantize --help | grep non-linear
# Choose the repacked variants for CPU inferencing
# e.g. IQ2_K_R4 and friends for CPU tensors
# Supports both Explicit and Transparent Hugepages
# https://github.com/ikawrakow/ik_llama.cpp/pull/278#issuecomment-2746381515
# Pre-allocate Hugepages of 2MiB or 1GiB size to hold model weights
# or
# Configure system-wide THP support and confirm they are in use
Quick Start
Existing DeepSeek-R1 671B GGUF
Get 64k context with a single 24GB VRAM GPU using your existing unsloth quants like unsloth/DeepSeek-R1-UD-Q2-K_XL!
# CUDA GPU + CPU
# *NOTE*: This works on 68a5b604 but regression after that see GH ISSUE #271.
# *NOTE*: set --threads to number of physical cores
./build/bin/llama-server \
--alias unsloth/DeepSeek-R1-Q2_K_R4 \
--model /mnt/raid/models/unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf \
-rtr \
--ctx-size 65536 \
-ctk q8_0 \
-mla 2 -fa \
-amb 512 \
-fmoe \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--parallel 1 \
--threads 24 \
--host 127.0.0.1 \
--port 8080
.
.
.
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q2_K: 171 tensors
llama_model_loader: - type q3_K: 3 tensors
llama_model_loader: - type q4_K: 306 tensors
llama_model_loader: - type q6_K: 184 tensors
.
.
.
llm_load_tensors: offloading 61 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 62/62 layers to GPU
llm_load_tensors: CPU buffer size = 205716.00 MiB
llm_load_tensors: CUDA_Host buffer size = 497.11 MiB
llm_load_tensors: CUDA0 buffer size = 9885.95 MiB
....................................................................................................
============ llm_load_tensors: need to compute 61 wk_b tensors
Computed blk.0.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.1.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.2.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
.
.
.
Computed blk.58.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.59.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.60.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
============ Repacked 174 tensors
llama_new_context_with_model: n_ctx = 65536
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: mla_attn = 2
llama_new_context_with_model: attn_max_b = 512
llama_new_context_with_model: fused_moe = 1
llama_new_context_with_model: ser = -1, 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 0.025
.
.
.
llama_kv_cache_init: CUDA0 KV buffer size = 2333.28 MiB
llama_new_context_with_model: KV self size = 2333.25 MiB, c^KV (q8_0): 2333.25 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 6081.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 240.01 MiB
llama_new_context_with_model: graph nodes = 13613
llama_new_context_with_model: graph splits = 118
.
.
.
INFO [ print_timings] prompt eval time = 2078.89 ms / 190 tokens ( 10.94 ms per token, 91.40 tokens per second) | tid="134221729001472" timestamp=1742422435 id_slot=0 id_task=753 t_prompt_processing=2078.885 n_prompt_tokens_processed=190 t_token=10.941500000000001 n_tokens_second=91.39514691769867
INFO [ print_timings] generation eval time = 107381.01 ms / 1557 runs ( 68.97 ms per token, 14.50 tokens per second) | tid="134221729001472" timestamp=1742422435 id_slot=0 id_task=753 t_token_generation=107381.013 n_decoded=1557 t_token=68.96661078998073 n_tokens_second=14.499770085052186
INFO [ print_timings] total time = 109459.90 ms | tid="134221729001472" timestamp=1742422435 id_slot=0 id_task=753 t_prompt_processing=2078.885 t_token_generation=107381.013 t_total=109459.898
Custom Quant
I rolled my own custom quant to improve quality while still fitting 32k context in under 24GB VRAM. No need to use -rtr as this quant is already repacked so you can still use mmap() allowing you to run on systems without enough RAM by paging the disk cache. This quant has lower perplexity than UD-Q2_K_XL while only being slightly larger/slower. Good size for 256GB RAM systems where Q4_K_M doesn't fit.
# CUDA GPU + CPU
./build/bin/llama-server \
--model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-Q2_K_R4.gguf \
--alias ubergarm/DeepSeek-R1-Q2_K_R4 \
--ctx-size 32768 \
-ctk q8_0 \
-mla 2 -fa \
-amb 512 \
-fmoe \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--parallel 1 \
--threads 24 \
--host 127.0.0.1 \
--port 8080
.
.
.
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 612 tensors
llama_model_loader: - type q2_k_r4: 116 tensors
llama_model_loader: - type q3_k_r4: 58 tensors
.
.
.
llm_load_tensors: offloading 61 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 62/62 layers to GPU
llm_load_tensors: CPU buffer size = 225736.00 MiB
llm_load_tensors: CPU buffer size = 938.98 MiB
llm_load_tensors: CUDA0 buffer size = 17744.02 MiB
....................................................................................................
llama_new_context_with_model: n_ctx = 32768
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: mla_attn = 2
llama_new_context_with_model: attn_max_b = 512
llama_new_context_with_model: fused_moe = 1
llama_new_context_with_model: ser = -1, 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 0.025
.
.
.
llama_kv_cache_init: CUDA0 KV buffer size = 1166.65 MiB
llama_new_context_with_model: KV self size = 1166.62 MiB, c^KV (q8_0): 1166.62 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 3425.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 176.01 MiB
llama_new_context_with_model: graph nodes = 8245
llama_new_context_with_model: graph splits = 118
# CPU-only Example
# Configure BIOS for most RAM bandwidth in single NUMA node e.g.
# * AMD Epyc to NPS1 (or experiment with NPS0 on dual socket system)
# * Intel Xeon to SNC=Disable (no equivilent of NPS0 afaict)
# TODO: mention Explicit Huge Pages configuration and other Linux OS performance tweaks
$ numactl -N 0 -m 0 \
./build/bin/llama-server \
--alias repack/DeepSeek-R1-Q4_K_R4 \
--model /mnt/ai/models/unsloth/repack/DeepSeek-R1-Q4_K_R4.gguf \
--ctx-size 32768 \
-ctk q8_0 \
-mla 3 -fa \
-amb 1024 \
-fmoe \
--parallel 1 \
--threads 128 \
--numa numactl \
--host 127.0.0.1 \
--port 8080
Custom Quants
👇
Click here for how to make your own custom quants including repacking
# > The MLA attention tensors don't seem to quantize well at all and they are using 4bit for these, plus last time I checked they were only using 6 experts instead of 8.
# > I've got a custom llama.cpp quant with BF16 for all the _a and _b low-rank MLA attention tensors, Q6_K / Q5_K for all non-shared expert down_proj and up_proj/gate_proj respectively, and Q8_0 for everything else, and the story generation ability is on par with the official deepseek served models (and a lot better than many of the non-official versions being served on openrouter!).
# > Just changing the _b tensors for Q8_0 (and keeping everything else the same as above) starts to have really obvious negative effects on story generation, and using Q4_K or Q4_0 is severely degraded in comparison. I haven't rested this yet with the modified version of the MLA PR where I converted all the 3D batch matrix multiples to 2D though (this seemed to be a cause of some numerical problems too and might be the same reason for this). - jukofyork
# https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2708800842
# TODO: Show how to pack quants for speed and accuracy to fit into desired RAM size
# 0. Skip this and download an existing MLA supported quant e.g.
#https://huggingface.co/gghfez/DeepSeek-R1-11446-Q4_K
#https://huggingface.co/daydream-org/DeepSeek-R1-GGUF-11446/tree/main/DeepSeek-R1-Q3_K_M
#https://huggingface.co/gghfez/DeepSeek-R1-11446-Q2_K
# 1. Download original fp8 to target dir
uv venv ./venv --python 3.12 --python-preference=only-managed
source ./venv/bin/activate
uv pip install huggingface-hub hf_transfer huggingface-cli
HF_HUB_ENABLE_HF_TRANSFER=1 \
huggingface-cli \
download \
--resume-download \
--local-dir ./ \
deepseek-ai/DeepSeek-R1
# 2. Convert original fp8 to bf16
## Option A:
# Official DeepSeek pytorch implementation to convert fp8 to bf16 (may require newer/big GPU?):
# https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/fp8_cast_bf16.py
# Then convert the output bf16 .safetensors to ~50GB splits GGUF format...
## Option B:
# Unofficial Triton CPU implementation (Converts fp8 safetensors directly to bf16 llama.cpp GGUF format):
# https://huggingface.co/daydream-org/DeepSeek-R1-GGUF-11446/discussions/1#67a327570051a98a96ded9e6
# Using Unofficial Instructions here:
mkdir fp8-to-bf16
cd fp8-to-bf16
uv venv ./venv --python 3.12 --python-preference=only-managed
source venv/bin/activate
uv pip install huggingface-cli
git clone https://github.com/evshiron/llama.cpp --recursive
cd llama.cpp
uv pip install -r requirements/requirements-convert_hf_to_gguf.txt --prerelease=allow --index-strategy unsafe-best-match
cmake -B build
cmake --build build --config Release -j$(nproc)
cd ..
git clone https://github.com/triton-lang/triton-cpu --recursive
cd triton-cpu
# apply saood06's patch https://github.com/ikawrakow/ik_llama.cpp/issues/383#issuecomment-2865306085
uv pip install ninja cmake wheel setuptools pybind11
MAX_JOBS=32 uv pip install -e python --no-build-isolation
# Be patient, "Preparing Packages" downloads a lot of stuff before build begins...
cd ..
# This outputs the <=~50GB gguf splits in the same directory as the original fp8 .safetensors
# you can use --output to specify a dir if you don't have enough space on the disk etc...
# Seems to use less than ~40GB RAM and as much extra RAM as disk cache as available.
# Does *not* use any GPU. A lot of disk i/o is nice to speed up reading/writing too.
# Only seems to use a single CPU thread most of the time.
# Getting just over 700Mbyte/s running on Thread Ripper Pro.
# Requires around 1.4TB of free space to hold the output files.
# Takes just over 30 minute at this speed.
python \
llama.cpp/convert_hf_to_gguf.py \
--outtype bf16 \
--split-max-size 50G \
path-to/fp8-safetensor-checkpoints/DeepSeek-R1
# Then mv *.gguf into its own directory as well as copy *.py and *.json
# 3. Convert bf16 to Custom MLA repacked quant to fit into your system RAM
# https://github.com/ikawrakow/ik_llama.cpp/pull/244
# importance matrix discussion: https://github.com/ikawrakow/ik_llama.cpp/pull/250
# example command: https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2708537218
# 3.5 Compute or download valid imatrix data file (good for <= ~Q4 quants or so)
# You can download either of these optional imatrix data if making smaller quants <= Q4ish
# but probably only for DeepSeek-R1 671B. For other models probably roll your own like so:
# (you might need like 1.5TB RAM to do this with bf16 model, but is easier to
# make q8_0_r8 quant first, and use that to generate the imatrix.dat with *only* ~715G RAM)
# https://github.com/ikawrakow/ik_llama.cpp/blob/main/examples/imatrix/README.md
# https://github.com/ggml-org/llama.cpp/discussions/5263
# https://gist.github.com/tristandruyen/9e207a95c7d75ddf37525d353e00659c
cd ik_llama.cpp
wget https://gist.githubusercontent.com/tristandruyen/9e207a95c7d75ddf37525d353e00659c/raw/571fda718462de863e5a0171078c175420c7649a/calibration_data_v5_rc.txt
numactl -N 0 -m 0 \
./build/bin/llama-imatrix \
--verbosity 1 \
-m /mnt/ai/models/ubergarm/DeepSeek-V3-0324-GGUF/DeepSeek-V3-0324-Q8_0_R8.gguf \
-f calibration_data_v5_rc.txt \
-o imatrix-DeepSeek-V3-0324.dat \
--ctx-size 512 \
--numa numactl \
--threads 128
# Download either of these optional imatrix data files specific to R1. or roll your own like above
# wget https://huggingface.co/bartowski/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1.imatrix -O imatrix-bartowski-DeepSeek-R1.dat
# wget https://huggingface.co/mradermacher/DeepSeek-R1-i1-GGUF/resolve/main/imatrix.dat -O imatrix-mradermacher-DeepSeek-R1.dat
# UPDATE: I don't recommend using these as only recent PR fixes MLA imatrix
# https://github.com/ikawrakow/ik_llama.cpp/pull/411
# Test
cd ik_llama.cpp
source venv/bin/activate
# ./build/bin/llama-quantize --help
# 138 or IQ2_K : 2.375 bpw non-linear quantization
# 338 or IQ2_K_R4 : IQ2_K repacked
# https://github.com/ikawrakow/ik_llama.cpp/discussions/242#discussioncomment-12489932
./build/bin/llama-quantize \
--imatrix /mnt/raid/models/deepseek-ai/DeepSeek-R1-bf16-GGUF/imatrix-bartowski-DeepSeek-R1.dat \
/mnt/raid/models/deepseek-ai/DeepSeek-R1-bf16-GGUF/DeepSeek-R1-256x21B-BF16-00001-of-00030.gguf \
/mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-IQ2_K_R4.gguf \
IQ2_K_R4 \
$(nproc)
# Advanced Quants
# https://github.com/ikawrakow/ik_llama.cpp/discussions/242#discussioncomment-12452986
# https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2709032571
# Ignore these Notes
# BF16 for all the _a and _b low-rank MLA attention tensors
# Q6_K / Q5_K for all non-shared expert down_proj and up_proj/gate_proj respectively
# and Q8_0 for everything else
# Just changing the _b tensors for Q8_0 (and keeping everything else the same as above) negative effects
# https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2708800842
# might not need bf16, possibly numerican instability...
# llama_model_loader: - type f32: 361 tensors
# llama_model_loader: - type q8_0: 246 tensors
# llama_model_loader: - type q5_K: 116 tensors
# llama_model_loader: - type q6_K: 58 tensors
# llama_model_loader: - type bf16: 488 tensors
# print_info: file format = GGUF V3 (latest)
# print_info: file type = Q5_K - Medium
# print_info: file size = 467.54 GiB (5.98 BPW)
# Create a script:
#!/usr/bin/env bash 14:45:57 [43/1765]
custom="
# Token embedding and output tensors
token_embd\.weight=q8_0
output\.weight=q8_0
output_norm\.weight=q8_0
# First 3 dense layers (GPU0)
blk\.[0-2]\..*=q8_0
# Layers 3-4 (CPU) - MoE experts
blk\.[3-4]\.ffn_down_exps\.weight=q3_k_r4
blk\.[3-4]\.ffn_gate_exps\.weight=q2_k_r4
blk\.[3-4]\.ffn_up_exps\.weight=q2_k_r4
# Layers 5-11 (CPU) - MoE experts
blk\.[5-9]\.ffn_down_exps\.weight=q3_k_r4
blk\.[5-9]\.ffn_gate_exps\.weight=q2_k_r4
blk\.[5-9]\.ffn_up_exps\.weight=q2_k_r4
blk\.1[0-1]\.ffn_down_exps\.weight=q3_k_r4
blk\.1[0-1]\.ffn_gate_exps\.weight=q2_k_r4
blk\.1[0-1]\.ffn_up_exps\.weight=q2_k_r4
# Layers 12-18 (CPU) - MoE experts
blk\.1[2-8]\.ffn_down_exps\.weight=q3_k_r4
blk\.1[2-8]\.ffn_gate_exps\.weight=q2_k_r4
blk\.1[2-8]\.ffn_up_exps\.weight=q2_k_r4
# Layers 19-60 (CPU) - MoE experts
blk\.19\.ffn_down_exps\.weight=q3_k_r4
blk\.19\.ffn_gate_exps\.weight=q2_k_r4
blk\.19\.ffn_up_exps\.weight=q2_k_r4
blk\.[2-5][0-9]\.ffn_down_exps\.weight=q3_k_r4
blk\.[2-5][0-9]\.ffn_gate_exps\.weight=q2_k_r4
blk\.[2-5][0-9]\.ffn_up_exps\.weight=q2_k_r4
blk\.60\.ffn_down_exps\.weight=q3_k_r4
blk\.60\.ffn_gate_exps\.weight=q2_k_r4
blk\.60\.ffn_up_exps\.weight=q2_k_r4
# All attention tensors for MoE layers (3-60)
blk\.[3-9]\.attn_.*=q8_0
blk\.[1-5][0-9]\.attn_.*=q8_0
blk\.60\.attn_.*=q8_0
# Norm weights and bias for MoE layers (3-60)
blk\.[3-9]\.ffn_norm\.weight=q8_0
blk\.[1-5][0-9]\.ffn_norm\.weight=q8_0
blk\.60\.ffn_norm\.weight=q8_0
blk\.[3-9]\.exp_probs_b\.bias=q8_0
blk\.[1-5][0-9]\.exp_probs_b\.bias=q8_0
blk\.60\.exp_probs_b\.bias=q8_0
# Shared experts weights for MoE layers (3-60)
blk\.3\.ffn_.*shexp\.weight=q8_0
blk\.[4-9]\.ffn_.*shexp\.weight=q8_0
blk\.[1-5][0-9]\.ffn_.*shexp\.weight=q8_0
blk\.60\.ffn_.*shexp\.weight=q8_0
"
custom=$(
echo "$custom" | grep -v '^#' | \
sed -Ez 's:\n+:,:g;s:,$::;s:^,::'
)
./build/bin/llama-quantize \
--imatrix /mnt/raid/models/deepseek-ai/DeepSeek-R1-bf16-GGUF/imatrix-bartowski-DeepSeek-R1.dat \
--token-embedding-type q8_0 \
--output-tensor-type q8_0 \
--custom-q "$custom" \
/mnt/raid/models/deepseek-ai/DeepSeek-R1-bf16-GGUF/DeepSeek-R1-256x21B-BF16-00001-of-00030.gguf \
/mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-GGUF-Q2_K_R4.gguf \
Q2_K_R4 \
$(nproc)
# I actually only ever tried half of $(nproc)
# not sure what most optimal speed will come from regarding CPU cores/threads / SMT etc...
# It has taken 40 minutes to 3.2 hours or so depending on exact quants used IQ's seem slow, q2_k_r4 is fast to pack
# TODO: There is no --dry-run but would be nice to have a way to predict final sizes before running?
☝️
Benchmarking
Test Rig
- AMD Ryzen Threadripper PRO 7965WX 24-Cores
- 256GB RAM (8x 32GB KF560R32-32 DDR5-6000 running at JEDEC 4800MHz psure)
- ~225GB/s
mlcmemory read bandwidth - RTX A6000 48GB VRAM
Linux TR24 6.13.0-061300-generic #202501302155 SMP PREEMPT_DYNAMIC Sat Feb 8 09:06:55 UTC 2025 x86_64 x86_64 x86_64 GNU/Linux- BIOS = NPS1 single NUMA node
llama-bench
Note ik_llama.cpp llama-bench doesn't seem to iterate over all variables so fix these manually for test cases:
-fmoe 0,1-rtr 0,1-otprobably, i didn't test this specifically as always usingexps=CPUfor this rig...
It does seem to iterate over variables for fa, mla, and amb.
# *NOTE*: this test was using `ik/prepare_wk_b` branch to support MLA on existing unsloth quants!
# *NOTE*: newer versions actually support `-ctk q8_0 -mla 2` etc.
# *NOTE*: -rtr 1 was only used with unsloth quant as the custom quant is pre-packed
./build/bin/llama-bench \
--model /mnt/raid/models/unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf \
-ctk q8_0 -ctv q8_0 \
-mla 2 -fa 1 \
-amb 2048 \
-fmoe 1 \
-rtr 1 \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--threads 24
build: f2fb15de (3596)
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA RTX A6000, compute capability 8.6, VMM: yes
Computed blk.0.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.1.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.2.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.3.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
.
.
.
Computed blk.58.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.59.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.60.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
============ Repacked 174 tensors
| model | size | params | backend | ngl | type_k | type_v | fa | mla | amb | rtr | fmoe | test | t/s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DS-R1 671B unsloth UD-Q2_K_XL | 211.03 GiB | 671.03 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 0 | 1 | pp512 | 69.85 ± 1.67 |
| DS-R1 671B unsloth UD-Q2_K_XL | 211.03 GiB | 671.03 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 0 | 1 | tg128 | 7.35 ± 0.01 |
| DS-R1 671B unsloth UD-Q2_K_XL | 211.03 GiB | 671.03 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 1 | 1 | pp512 | 110.79 ± 5.60 |
| DS-R1 671B unsloth UD-Q2_K_XL | 211.03 GiB | 671.03 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 1 | 1 | tg128 | 13.13 ± 0.07 |
| DS-R1 671B unsloth UD-Q2_K_XL | 211.03 GiB | 671.03 B | CUDA | 63 | f16 | f16 | 1 | 2 | 2048 | 1 | 1 | pp512 | 114.56 ± 1.75 |
| DS-R1 671B unsloth UD-Q2_K_XL | 211.03 GiB | 671.03 B | CUDA | 63 | f16 | f16 | 1 | 2 | 2048 | 1 | 1 | tg128 | 13.68 ± 0.07 |
| DS-R1 671B ubergarm IQ2_XS_R4 | 213.11 GiB | 672.05 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 0 | 1 | pp512 | 65.31 ± 1.52 |
| DS-R1 671B ubergarm IQ2_XS_R4 | 213.11 GiB | 672.05 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 0 | 1 | tg128 | 10.48 ± 0.01 |
| DS-R1 671B ubergarm Q2_K_R4 | 238.69 GiB | 672.05 B | CUDA | 63 | f16 | f16 | 1 | 2 | 2048 | 0 | 1 | pp512 | 111.89 ± 2.68 |
| DS-R1 671B ubergarm Q2_K_R4 | 238.69 GiB | 672.05 B | CUDA | 63 | f16 | f16 | 1 | 2 | 2048 | 0 | 1 | tg128 | 11.55 ± 0.04 |
| DS-R1 671B ubergarm Q2_K_R4 | 238.69 GiB | 672.05 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 0 | 1 | pp512 | 109.06 ± 2.86 |
| DS-R1 671B ubergarm Q2_K_R4 | 238.69 GiB | 672.05 B | CUDA | 63 | q8_0 | q8_0 | 1 | 2 | 2048 | 0 | 1 | tg128 | 11.10 ± 0.01 |
Perplexity
# Test your quant against known quants
# Lower is Better
# https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2701019253
# example command: https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2708537247
wget https://github.com/user-attachments/files/19090237/wiki.test.raw.gz
gunzip wiki.test.raw.gz
# this can takes an hour or more for full run
# but only really need first ~25 points or so
# also some quants give nan results even on vanilla llama.cpp
# *NOTE* I don't think `-ctk q8_0 -ctv q8_0` are valid with `-mla 2 -fa` yet so take this with a grain of salt.
CUDA_VISIBLE_DEVICES="0," \
./build/bin/llama-perplexity \
--model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-IQ2_XS_R4.gguf \
-ctk q8_0 \
-mla 2 -fa \
-amb 512 \
-fmoe \
--ctx-size 512 \
--ubatch-size 512 \
-f wiki.test.raw \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--threads 24
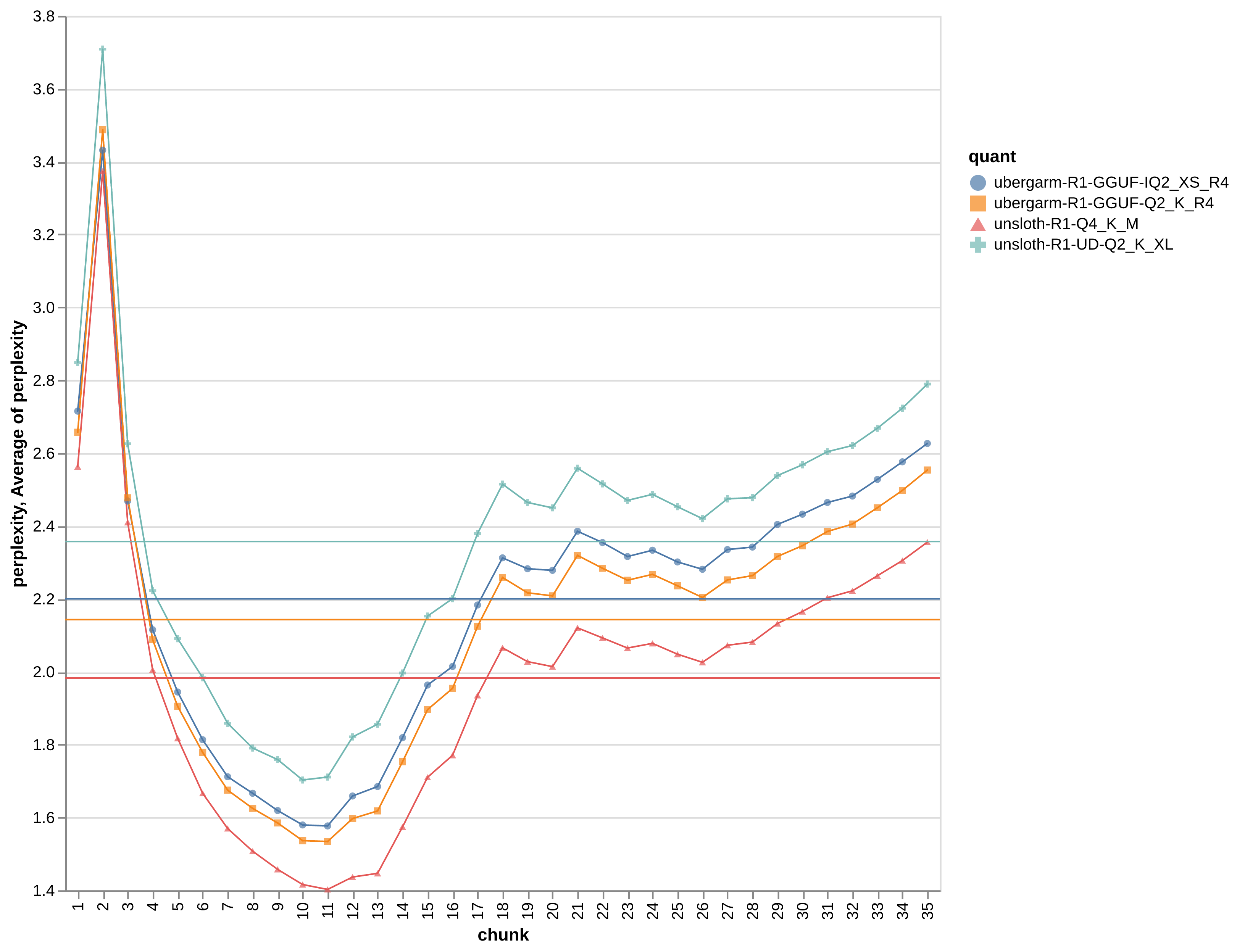
Even more perplexity logs
There is a lot going on here. There may be some issues with nan and "numerical instability" depending on exact quants and llama.cpp forks in use. So this is still evolving.
I made the above png graph using the first 35 chunks for easy comparison as generally nan didn't appear too early for most quants.
I also haven't compared perplexity across ik_llama.cpp with different settings (e.g. mla etc) vs vanilla llama.cpp and CPU vs CUDA backends etc.
The following exact detailed logs results are not included yet in the graph above.
Q8_0
I ran the unsloth Q8_0 on that intel6980P CPU only backend with vanilla llama.cpp/main@b1b132ef for a baseline. Note there is no MLA etc yet in this case.
numactl -N 0 -m 0 \
./build/bin/llama-perplexity \
--model /mnt/ai/models/unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf \
-ctk f16 -ctv f16 \
--ctx-size 512 \
--ubatch-size 512 \
-f wiki.test.raw \
--numa numactl \
--threads 80
perplexity: tokenizing the input ..
perplexity: tokenization took 724.131 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 60.35 seconds per pass - ETA 2 hours 21.05 minutes
[1]2.5013,[2]3.2882,[3]2.3700,[4]1.9826,[5]1.7891,[6]1.6469,[7]1.5544,[8]1.4883,[9]1.4387,[10]1.3997,[11]1.3842,[12]1.4194,[13]1.4299,[14]1.5576,[15]1.6890,[16]1.7483,[17]1.9110,[18]2.0408,[19]2.0033,[20]1.9911,[21]2.0982,[22]2.0702,[23]2.0430,[24]2.0560,[25]2.0267,[26]2.0035,[27]2.0524,[28]2.0598,[29]2.1085,[30]2.1396,[31]2.1742,[32]2.1918,[33]2.2304,[34]2.2706,[35]2.3192,[36]2.3717,[37]2.4071,[38]2.4526,[39]2.4940,[40]2.5527,[41]2.5950,[42]2.6072,[43]2.6559,[44]2.6723,[45]2.7517,[46]2.8023,[47]2.7573,[48]2.7107,[49]2.6842,[50]2.7039,[51]2.7504,[52]2.7650,[53]2.8143,[54]2.8275,[55]2.8585,[56]2.8898,[57]2.9036,[58]2.9402,[59]2.9512,[60]2.9968,[61]3.0366,[62]3.0894,[63]3.1213,[64]3.1652,[65]3.1751,[66]3.1579,[67]3.1353,[68]3.1665,[69]3.1618,[70]3.1771,[71]3.1956,[72]3.2115,[73]3.2259,[74]3.2494,[75]3.2284,[76]3.1816,[77]3.1389,[78]3.1344,[79]3.1122,[80]3.0929,[81]3.0561,[82]3.0596,[83]3.0282,[84]2.9923,[85]2.9572,[86]2.9321,[87]2.9257,[88]2.8971,[89]2.8805,[90]2.8542,[91]2.8245,[92]2.7997,[93]2.7731,[94]2.7463,[95]2.7224,[96]2.7210,[97]2.7283,[98]2.7132,[99]2.6960,[100]2.6985,[101]2.6899,[102]2.7065,[103]2.7327,[104]2.7513,[105]2.7482,[106]2.7706,[107]2.7948,[108]2.8154,[109]2.8493,[110]2.8832,[111]2.9028,[112]2.8771,[113]2.8641,[114]2.8419,[115]2.8266,[116]2.8114,[117]2.7885,[118]2.7677,[119]2.7465,[120]2.7277,[121]2.7122,[122]2.6947,[123]2.6785,[124]2.6597,[125]2.6422,[126]2.6257,[127]2.6117,[128]2.6027,[129]2.5920,[130]2.5797,[131]2.5724,[132]2.5798,[133]2.5894,[134]2.5959,[135]2.6064,[136]2.6225,[137]2.6379,[138]2.6461,[139]2.6576,[140]2.6586,[141]2.6603,[142]2.6594,[143]2.6599,[144]2.6569,[145]2.6481,[146]2.6467,[147]2.6512,[148]2.6510,[149]2.6527,[150]2.6476,[151]2.6458,[152]2.6429,[153]2.6392,[154]2.6399,[155]2.6443,[156]2.6465,[157]2.6527,[158]2.6615,[159]2.6634,[160]2.6723,[161]2.6806,[162]2.6900,[163]2.6941,[164]2.7141,[165]2.7378,[166]2.7551,[167]2.7673,[168]2.7915,[169]2.8139,[170]2.8354,[171]2.8586,[172]2.8427,[173]2.8264,[174]2.8128,[175]2.7995,[176]2.7872,[177]2.7756,[178]2.7630,[179]2.7493,[180]2.7532,[181]2.7671,[182]2.7822,[183]2.7970,[184]2.8112,[185]2.8216,[186]2.8381,[187]2.8534,[188]2.8675,[189]2.8782,[190]2.8785,[191]2.8859,[192]2.8899,[193]2.8950,[194]2.9146,[195]2.9234,[196]2.9368,[197]2.9468,[198]2.9513,[199]2.9570,[200]2.9566,[201]2.9717,[202]2.9671,[203]2.9724,[204]2.9760,[205]2.9759,[206]2.9785,[207]2.9874,[208]2.9970,[209]3.0063,[210]3.0069,[211]3.0022,[212]3.0021,[213]3.0097,[214]3.0116,[215]3.0174,[216]3.0180,[217]3.0140,[218]3.0142,[219]3.0152,[220]3.0146,[221]3.0148,[222]3.0149,[223]3.0155,[224]3.0205,[225]3.0224,[226]3.0144,[227]3.0122,[228]3.0145,[229]3.0191,[230]3.0256,[231]3.0318,[232]3.0236,[233]3.0158,[234]3.0158,[235]3.0142,[236]3.0230,[237]3.0315,[238]3.0410,[239]3.0508,[240]3.0601,[241]3.0713,[242]3.0857,[243]3.0992,[244]3.1073,[245]3.1183,[246]3.1288,[247]3.1276,[248]3.1235,[249]3.1216,[250]3.1154,[251]3.1133,[252]3.1158,[253]3.1196,[254]3.1267,[255]3.1331,[256]3.1369,[257]3.1393,[258]3.1405,[259]3.1438,[260]3.1459,[261]3.1473,[262]3.1465,[263]3.1522,[264]3.1545,[265]3.1550,[266]3.1568,[267]3.1597,[268]3.1634,[269]3.1665,[270]3.1659,[271]3.1644,[272]3.1577,[273]3.1576,[274]3.1507,[275]3.1399,[276]3.1291,[277]3.1308,[278]3.1410,[279]3.1472,[280]3.1551,[281]3.1625,[282]3.1687,[283]3.1751,[284]3.1818,[285]3.1954,[286]3.1979,[287]3.2013,[288]3.2060,[289]3.2087,[290]3.2005,[291]3.1911,[292]3.1892,[293]3.1883,[294]3.1855,[295]3.1829,[296]3.1848,[297]3.1853,[298]3.1902,[299]3.1961,[300]3.1992,[301]3.2030,[302]3.2052,[303]3.2072,[304]3.2067,[305]3.2186,[306]3.2261,[307]3.2370,[308]3.2258,[309]3.2204,[310]3.2109,[311]3.2145,[312]3.2167,[313]3.2230,[314]3.2251,[315]3.2283,[316]3.2297,[317]3.2315,[318]3.2321,[319]3.2324,[320]3.2367,[321]3.2370,[322]3.2390,[323]3.2454,[324]3.2463,[325]3.2516,[326]3.2563,[327]3.2604,[328]3.2634,[329]3.2652,[330]3.2715,[331]3.2752,[332]3.2800,[333]3.2786,[334]3.2787,[335]3.2792,[336]3.2794,[337]3.2805,[338]3.2808,[339]3.2835,[340]3.2871,[341]3.2925,[342]3.3015,[343]3.3108,[344]3.3161,[345]3.3074,[346]3.2997,[347]3.2945,[348]3.2872,[349]3.2835,[350]3.2817,[351]3.2864,[352]3.3013,[353]3.3104,[354]3.3232,[355]3.3318,[356]3.3371,[357]3.3487,[358]3.3583,[359]3.3615,[360]3.3680,[361]3.3772,[362]3.3858,[363]3.3915,[364]3.3981,[365]3.4044,[366]3.4148,[367]3.4234,[368]3.4301,[369]3.4380,[370]3.4465,[371]3.4602,[372]3.4689,[373]3.4722,[374]3.4758,[375]3.4808,[376]3.4936,[377]3.5048,[378]3.5075,[379]3.5069,[380]3.5037,[381]3.5083,[382]3.5139,[383]3.5175,[384]3.5218,[385]3.5257,[386]3.5319,[387]3.5377,[388]3.5411,[389]3.5308,[390]3.5213,[391]3.5107,[392]3.5051,[393]3.4955,[394]3.4865,[395]3.4772,[396]3.4672,[397]3.4584,[398]3.4488,[399]3.4385,[400]3.4296,[401]3.4196,[402]3.4093,[403]3.4007,[404]3.3905,[405]3.3811,[406]3.3711,[407]3.3619,[408]3.3531,[409]3.3446,[410]3.3386,[411]3.3392,[412]3.3345,[413]3.3363,[414]3.3385,[415]3.3353,[416]3.3351,[417]3.3375,[418]3.3317,[419]3.3332,[420]3.3308,[421]3.3298,[422]3.3312,[423]3.3304,[424]3.3346,[425]3.3341,[426]3.3346,[427]3.3335,[428]3.3360,[429]3.3378,[430]3.3406,[431]3.3413,[432]3.3403,[433]3.3366,[434]3.3366,[435]3.3289,[436]3.3226,[437]3.3185,[438]3.3167,[439]3.3134,[440]3.3183,[441]3.3237,[442]3.3311,[443]3.3293,[444]3.3302,[445]3.3315,[446]3.3363,[447]3.3396,[448]3.3421,[449]3.3452,[450]3.3490,[451]3.3520,[452]3.3540,[453]3.3557,[454]3.3543,[455]3.3564,[456]3.3567,[457]3.3594,[458]3.3646,[459]3.3653,[460]3.3654,[461]3.3622,[462]3.3659,[463]3.3732,[464]3.3785,[465]3.3714,[466]3.3696,[467]3.3677,[468]3.3688,[469]3.3658,[470]3.3631,[471]3.3634,[472]3.3640,[473]3.3632,[474]3.3624,[475]3.3635,[476]3.3619,[477]3.3610,[478]3.3617,[479]3.3633,[480]3.3660,[481]3.3620,[482]3.3654,[483]3.3646,[484]3.3682,[485]3.3746,[486]3.3775,[487]3.3812,[488]3.3864,[489]3.3889,[490]3.3935,[491]3.3997,[492]3.4042,[493]3.4040,[494]3.4052,[495]3.4076,[496]3.4095,[497]3.4124,[498]3.4127,[499]3.4122,[500]3.4163,[501]3.4209,[502]3.4200,[503]3.4185,[504]3.4205,[505]3.4239,[506]3.4323,[507]3.4350,[508]3.4385,[509]3.4312,[510]3.4254,[511]3.4188,[512]3.4142,[513]3.4080,[514]3.4065,[515]3.4084,[516]3.4033,[517]3.4032,[518]3.4024,[519]3.4029,[520]3.4073,[521]3.4062,[522]3.4047,[523]3.4105,[524]3.4092,[525]3.4076,[526]3.4028,[527]3.3979,[528]3.3942,[529]3.3913,[530]3.3883,[531]3.3852,[532]3.3797,[533]3.3735,[534]3.3692,[535]3.3700,[536]3.3728,[537]3.3759,[538]3.3785,[539]3.3812,[540]3.3865,[541]3.3898,[542]3.3922,[543]3.3865,[544]3.3822,[545]3.3819,[546]3.3753,[547]3.3688,[548]3.3624,[549]3.3557,[550]3.3497,[551]3.3436,[552]3.3378,[553]3.3319,[554]3.3298,[555]3.3283,[556]3.3311,[557]3.3351,[558]3.3410,[559]3.3455,[560]3.3508,[561]3.3490,
Final estimate: PPL = 3.3490 +/- 0.01849
llama_perf_context_print: load time = 226439.86 ms
llama_perf_context_print: prompt eval time = 8320298.42 ms / 287232 tokens ( 28.97 ms per token, 34.52 tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 8511632.28 ms / 287233 tokens
ubergarm Q2_K_R4
This is a custom quant I rolled with q8_0 for all attention/shared experts/embeddings loaded on GPU. The rest of the MoE down exps are q3_k_r4 and gate/up exps are q2_k_r4 which gives fast speed quant that fits nicely into under 256GB RAM and 24GB VRAM with about 32k context without sacrificing much perplexity.
This was run on ik_llama.cpp@127c6ee6
CUDA_VISIBLE_DEVICES="0," \
./build/bin/llama-perplexity \
--model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-Q2_K_R4.gguf \
-ctk q8_0 \
-mla 2 -fa \
-amb 512 \
-fmoe \
--ctx-size 512 \
--ubatch-size 512 \
-f wiki.test.raw \
--seed 1337 \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--threads 24
main: build = 3597 (127c6ee6)
main: built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu
main: seed = 1337
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 612 tensors
llama_model_loader: - type q2_k_r4: 116 tensors
llama_model_loader: - type q3_k_r4: 58 tensors
llm_load_tensors: CPU buffer size = 241396.85 MiB
llm_load_tensors: CPU buffer size = 938.98 MiB
llm_load_tensors: CUDA0 buffer size = 17744.02 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 72.94 MiB
llama_new_context_with_model: KV self size = 72.91 MiB, c^KV (q8_0): 72.91 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 1.97 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 503.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 162.01 MiB
llama_new_context_with_model: graph nodes = 3548
llama_new_context_with_model: graph splits = 118
system_info: n_threads = 24 / 48 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | FMA = 1 | NE
ON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1
|
perplexity: tokenizing the input ..
perplexity: tokenization took 622.117 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 22.17 seconds per pass - ETA 51.82 minutes
[1]2.6638,[2]3.4777,[3]2.4750,[4]2.0889,[5]1.9114,[6]1.7840,[7]1.6778,[8]1.6280,[9]1.5861,[10]1.5368,[11]1.5350,[12]1.6021,[13]1.6219,[14]1.7566,[15]1.8981,[16]1.9568,[17]2.1267,[18]2.2596,[19]2.2162,[20]2.2076,[21]2.3177,[22]2.2827,[23]2.2506,[24]2.2664,[25]2.2356,[26]2.2031,[27]2.2509,[28]2.2621,[29]2.3150,[30]2.3456,[31]2.3842,[32]2.4047,[33]2.4491,[34]2.4968,[35]2.5548,[36]2.6101,[37]2.6450,[38]2.6943,[39]2.7349,[40]2.7982,[41]2.8432,[42]2.8527,[43]2.9058,[44]2.9198,[45]3.0016,[46]3.0547,[47]3.0161,[48]2.9682,[49]2.9447,[50]2.9692,[51]3.0185,[52]3.0358,[53]3.0904,[54]3.1052,[55]3.1362,[56]3.1730,[57]3.1878,[58]3.2298,[59]3.2355,[60]3.2852,[61]3.3261,[62]3.3815,[63]3.4167,[64]3.4623,[65]3.4705,[66]3.4568,[67]3.4360,[68]3.4732,[69]3.4763,[70]3.4917,[71]3.5079,[72]3.5222,[73]3.5335,[74]3.5558,[75]3.5337,[76]3.4827,[77]3.4411,[78]3.4385,[79]3.4195,[80]3.4069,[81]3.3681,[82]3.3782,[83]3.3509,[84]3.3178,[85]3.2861,[86]3.2623,[87]3.2651,[88]3.2385,[89]3.2313,[90]3.2041,[91]3.1805,[92]3.1557,[93]3.1293,[94]3.1076,[95]3.0903,[96]3.0928,[97]3.1020,[98]3.0908,[99]3.0718,[100]3.0734,[101]3.0656,[102]3.0834,[103]3.1118,[104]3.1334,[105]3.1289,[106]3.1553,[107]3.1798,[108]3.2007,[109]3.2368,[110]3.2717,[111]3.2932,[112]3.2641,[113]3.2514,[114]3.2308,[115]3.2142,[116]3.2089,[117]3.1865,[118]3.1646,[119]3.1440,[120]3.1220,[121]3.1077,[122]3.0867,[123]3.0684,[124]3.0491,[125]3.0306,[126]3.0122,[127]2.9989,[128]2.9941,[129]2.9858,[130]2.9752,[131]2.9681,[132]2.9766,[133]2.9844,[134]2.9892,[135]3.0006,[136]3.0188,[137]3.0355,[138]3.0423,[139]3.0529,[140]3.0518,[141]3.0514,[142]3.0485,[143]3.0472,[144]3.0406,[145]3.0305,[146]3.0274,[147]3.0301,[148]3.0286,[149]3.0286,[150]3.0209,[151]3.0173,[152]3.0128,[153]3.0070,[154]3.0063,[155]3.0096,[156]3.0102,[157]3.0149,[158]3.0234,[159]3.0244,[160]3.0334,[161]3.0417,[162]3.0509,[163]3.0566,[164]3.0781,[165]3.1021,[166]3.1200,[167]3.1341,[168]3.1601,[169]3.1830,[170]3.2043,[171]3.2285,[172]3.2094,[173]3.1897,[174]3.1763,[175]3.1635,[176]3.1512,[177]3.1393,[178]3.1260,[179]3.1114,[180]3.1151,[181]3.1294,[182]3.1451,[183]3.1596,[184]3.1737,[185]3.1836,[186]3.2002,[187]3.2150,[188]3.2297,[189]3.2397,[190]3.2401,[191]3.2467,[192]3.2485,[193]3.2522,[194]3.2726,[195]3.2824,[196]3.2955,[197]3.3053,[198]3.3084,[199]3.3139,[200]3.3115,[201]3.3268,[202]3.3208,[203]3.3263,[204]3.3285,[205]3.3289,[206]3.3309,[207]3.3401,[208]3.3495,[209]3.3596,[210]3.3591,[211]3.3530,[212]3.3525,[213]3.3601,[214]3.3613,[215]3.3673,[216]3.3670,[217]3.3614,[218]3.3608,[219]3.3607,[220]3.3586,[221]3.3583,[222]3.3578,[223]3.3582,[224]3.3630,[225]3.3651,[226]3.3555,[227]3.3541,[228]3.3557,[229]3.3600,[230]3.3664,[231]3.3725,[232]3.3629,[233]3.3560,[234]3.3588,[235]3.3588,[236]3.3679,[237]3.3768,[238]3.3863,[239]3.3968,[240]3.4056,[241]3.4171,[242]3.4330,[243]3.4464,[244]3.4550,[245]3.4673,[246]3.4779,[247]3.4755,[248]3.4711,[249]3.4687,[250]3.4611,[251]3.4578,[252]3.4592,[253]3.4623,[254]3.4688,[255]3.4747,[256]3.4776,[257]3.4796,[258]3.4799,[259]3.4823,[260]3.4840,[261]3.4844,[262]3.4823,[263]3.4878,[264]3.4897,[265]3.4893,[266]3.4911,[267]3.4934,[268]3.4977,[269]3.5007,[270]3.4989,[271]3.4964,[272]3.4887,[273]3.4893,[274]3.4830,[275]3.4721,[276]3.4619,[277]3.4634,[278]3.4747,[279]3.4802,[280]3.4880,[281]3.4954,[282]3.5012,[283]3.5084,[284]3.5151,[285]3.5294,[286]3.5318,[287]3.5344,[288]3.5386,[289]3.5405,[290]3.5319,[291]3.5245,[292]3.5265,[293]3.5266,[294]3.5257,[295]3.5240,[296]3.5264,[297]3.5278,[298]3.5327,[299]3.5397,[300]3.5427,[301]3.5466,[302]3.5492,[303]3.5500,[304]3.5482,[305]3.5604,[306]3.5677,[307]3.5791,[308]3.5665,[309]3.5614,[310]3.5521,[311]3.5569,[312]3.5602,[313]3.5680,[314]3.5700,[315]3.5730,[316]3.5737,[317]3.5747,[318]3.5748,[319]3.5752,[320]3.5794,[321]3.5793,[322]3.5807,[323]3.5867,[324]3.5868,[325]3.5913,[326]3.5962,[327]3.5998,[328]3.6018,[329]3.6030,[330]3.6091,[331]3.6139,[332]3.6182,[333]3.6161,[334]3.6152,[335]3.6149,[336]3.6146,[337]3.6152,[338]3.6152,[339]3.6172,[340]3.6206,[341]3.6262,[342]3.6355,[343]3.6454,[344]3.6503,[345]3.6426,[346]3.6354,[347]3.6331,[348]3.6250,[349]3.6211,[350]3.6196,[351]3.6242,[352]3.6400,[353]3.6490,[354]3.6624,[355]3.6718,[356]3.6773,[357]3.6895,[358]3.7002,[359]3.7034,[360]3.7098,[361]3.7190,[362]3.7284,[363]3.7341,[364]3.7405,[365]3.7472,[366]3.7586,[367]3.7673,[368]3.7743,[369]3.7824,[370]3.7911,[371]3.8057,[372]3.8153,[373]3.8182,[374]3.8215,[375]3.8263,[376]3.8395,[377]3.8505,[378]3.8528,[379]3.8518,[380]3.8480,[381]3.8524,[382]3.8581,[383]3.8616,[384]3.8662,[385]3.8700,[386]3.8763,[387]3.8823,[388]3.8854,[389]3.8739,[390]3.8638,[391]3.8534,[392]3.8475,[393]3.8382,[394]3.8292,[395]3.8196,[396]3.8089,[397]3.7993,[398]3.7888,[399]3.7777,[400]3.7692,[401]3.7583,[402]3.7471,[403]3.7373,[404]3.7257,[405]3.7151,[406]3.7038,[407]3.6937,[408]3.6845,[409]3.6753,[410]3.6691,[411]3.6709,[412]3.6663,[413]3.6695,[414]3.6725,[415]3.6698,[416]3.6700,[417]3.6722,[418]3.6661,[419]3.6677,[420]3.6650,[421]3.6640,[422]3.6657,[423]3.6652,[424]3.6696,[425]3.6691,[426]3.6693,[427]3.6687,[428]3.6715,[429]3.6729,[430]3.6760,[431]3.6769,[432]3.6759,[433]3.6722,[434]3.6730,[435]3.6667,[436]3.6610,[437]3.6572,[438]3.6553,[439]3.6538,[440]3.6589,[441]3.6640,[442]3.6715,[443]3.6693,[444]3.6698,[445]3.6710,[446]3.6763,[447]3.6788,[448]3.6813,[449]3.6840,[450]3.6879,[451]3.6915,[452]3.6939,[453]3.6952,[454]3.6932,[455]3.6955,[456]3.6953,[457]3.6978,[458]3.7028,[459]3.7032,[460]3.7027,[461]3.6988,[462]3.7024,[463]3.7098,[464]3.7157,[465]3.7091,[466]3.7079,[467]3.7076,[468]3.7093,[469]3.7067,[470]3.7041,[471]3.7044,[472]3.7055,[473]3.7047,[474]3.7034,[475]3.7047,[476]3.7031,[477]3.7023,[478]3.7030,[479]3.7053,[480]3.7078,[481]3.7041,[482]3.7078,[483]3.7063,[484]3.7096,[485]3.7163,[486]3.7190,[487]3.7225,[488]3.7279,[489]3.7299,[490]3.7346,[491]3.7405,[492]3.7450,[493]3.7447,[494]3.7457,[495]3.7479,[496]3.7495,[497]3.7526,[498]3.7526,[499]3.7518,[500]3.7555,[501]3.7599,[502]3.7587,[503]3.7567,[504]3.7593,[505]3.7622,[506]3.7705,[507]3.7730,[508]3.7763,[509]3.7681,[510]3.7634,[511]3.7571,[512]3.7529,[513]3.7470,[514]3.7466,[515]3.7497,[516]3.7454,[517]3.7459,[518]3.7450,[519]3.7460,[520]3.7510,[521]3.7495,[522]3.7477,[523]3.7541,[524]3.7529,[525]3.7515,[526]3.7476,[527]3.7418,[528]3.7389,[529]3.7353,[530]3.7325,[531]3.7289,[532]3.7221,[533]3.7155,[534]3.7116,[535]3.7130,[536]3.7160,[537]3.7199,[538]3.7231,[539]3.7259,[540]3.7314,[541]3.7352,[542]3.7375,[543]3.7323,[544]3.7285,[545]3.7281,[546]3.7207,[547]3.7147,[548]3.7080,[549]3.7014,[550]3.6956,[551]3.6899,[552]3.6844,[553]3.6791,[554]3.6786,[555]3.6772,[556]3.6796,[557]3.6838,[558]3.6899,[559]3.6946,[560]3.7001,[561]3.6975,
Final estimate: PPL = 3.6975 +/- 0.02115
llama_print_timings: load time = 14720.43 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 2646411.18 ms / 287232 tokens ( 9.21 ms per token, 108.54 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 2649939.46 ms / 287233 tokens
ubergarm Q2_K_R4 with various -ser N,1
Testing same quant and config as above but with -ser 4,1 etc to get a feel for quality vs speed tradeoffs.
These were run on ik_llama.cpp@127c6ee6
CUDA_VISIBLE_DEVICES="0," \
./build/bin/llama-perplexity \
--model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-Q2_K_R4.gguf \
-ctk q8_0 \
-mla 2 -fa \
-amb 512 \
-fmoe \
-ser 4,1 \
--ctx-size 512 \
--ubatch-size 512 \
-f wiki.test.raw \
--seed 1337 \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--threads 24
Device 0: NVIDIA RTX A6000, compute capability 8.6, VMM: yes
main: build = 3597 (127c6ee6)
main: built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu
main: seed = 1337
llama_model_loader: loaded meta data with 48 key-value pairs and 1147 tensors from /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-Q2_K_R4.gguf
(version GGUF V3 (latest))
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 612 tensors
llama_model_loader: - type q2_k_r4: 116 tensors
llama_model_loader: - type q3_k_r4: 58 tensors
llm_load_tensors: CPU buffer size = 241396.85 MiB
llm_load_tensors: CPU buffer size = 938.98 MiB
llm_load_tensors: CUDA0 buffer size = 17744.02 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 72.94 MiB
llama_new_context_with_model: KV self size = 72.91 MiB, c^KV (q8_0): 72.91 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 1.97 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 503.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 162.01 MiB
llama_new_context_with_model: graph nodes = 3548
llama_new_context_with_model: graph splits = 118
system_info: n_threads = 24 / 48 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | FMA = 1 | NE
ON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1
|
# with -ser 4,1
perplexity: tokenizing the input ..
perplexity: tokenization took 604.75 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 13.04 seconds per pass - ETA 30.48 minutes
[1]2.7566,[2]3.5635,[3]2.5376,[4]2.2133,[5]2.0562,[6]1.9544,[7]1.8575,[8]1.8206,[9]1.7899,[10]1.7276,[11]1.7315,[12]1.8148,[13]1.8621,[14]1.9970,[15]2.1476,[16]2.2009,[17]2.3909,[18]2.5311,[19]2.4924,[20]2.4660,[21]2.5846,[22]2.5381,[23]2.4909,[24]2.5169,[25]2.4747,[26]2.4415,[27]2.4895,[28]2.4900,[29]2.5527,[30]2.5844,[31]2.6249,[32]2.6419,[33]2.6900,[34]2.7411,[35]2.8049,[36]2.8666,[37]2.9000,[38]2.9508,[39]2.9934,[40]3.0584,[41]3.0966,[42]3.1029,[43]3.1541,[44]3.1631,[45]3.2510,[46]3.3056,[47]3.2714,[48]3.2337,[49]3.2203,[50]3.2441,[51]3.2937,[52]3.3088,[53]3.3648,[54]3.3842,[55]3.4177,[56]3.4566,[57]3.4802,[58]3.5231,[59]3.5286,[60]3.5828,[61]3.6248,[62]3.6818,[63]3.7188,[64]3.7669,[65]3.7770,[66]3.7741,[67]3.7554,[68]3.7894,[69]3.7957,[70]3.8155,[71]3.8336,[72]3.8482,[73]3.8581,[74]3.8803,[75]3.8576,[76]3.8006,[77]3.7567,[78]3.7570,[79]3.7380,[80]3.7306,[81]3.6892,[82]3.6976,[83]3.6788,[84]3.6468,[85]3.6175,[86]3.5977,[87]3.6166,[88]3.5909,[89]3.5849,[90]3.5628,[91]3.5419,[92]3.5188,[93]3.4947,[94]3.4766,[95]3.4582,[96]3.4635,[97]3.4770,[98]3.4648,[99]3.4479,[100]3.4481,[101]3.4369,[102]3.4545,[103]3.4847,[104]3.5091,[105]3.5066,[106]3.5396,[107]3.5644,[108]3.5854,[109]3.6243,[110]3.6607,[111]3.6853,[112]3.6525,[113]3.6384,[114]3.6172,[115]3.5987,[116]3.5923,[117]3.5714,[118]3.5475,[119]3.5258,[120]3.5023,[121]3.4869,[122]3.4619,[123]3.4426,[124]3.4229,[125]3.4047,[126]3.3876,[127]3.3766,[128]3.3707,[129]3.3639,[130]3.3555,[131]3.3492,[132]3.3556,[133]3.3630,[134]3.3679,[135]3.3806,[136]3.3993,[137]3.4173,[138]3.4236,[139]3.4345,[140]3.4313,[141]3.4291,[142]3.4229,[143]3.4184,[144]3.4084,[145]3.3970,[146]3.3921,[147]3.3929,[148]3.3895,[149]3.3881,[150]3.3773,[151]3.3724,[152]3.3654,[153]3.3570,[154]3.3543,[155]3.3575,[156]3.3558,[157]3.3599,[158]3.3687,[159]3.3700,[160]3.3792,[161]3.3861,[162]3.3940,[163]3.4013,[164]3.4242,[165]3.4507,[166]3.4707,[167]3.4853,[168]3.5134,[169]3.5376,[170]3.5636,[171]3.5889,[172]3.5672,[173]3.5461,[174]3.5336,[175]3.5224,[176]3.5099,[177]3.4987,[178]3.4862,[179]3.4722,[180]3.4760,[181]3.4907,[182]3.5072,[183]3.5225,[184]3.5380,[185]3.5492,[186]3.5669,[187]3.5825,[188]3.5986,[189]3.6102,[190]3.6092,[191]3.6161,[192]3.6179,[193]3.6219,[194]3.6438,[195]3.6527,[196]3.6656,[197]3.6750,[198]3.6773,[199]3.6828,[200]3.6787,[201]3.6945,[202]3.6859,[203]3.6899,[204]3.6913,[205]3.6913,[206]3.6915,[207]3.7009,[208]3.7091,[209]3.7186,[210]3.7168,[211]3.7094,[212]3.7082,[213]3.7154,[214]3.7162,[215]3.7221,[216]3.7205,[217]3.7133,[218]3.7120,[219]3.7115,[220]3.7083,[221]3.7062,[222]3.7049,[223]3.7052,[224]3.7097,[225]3.7106,[226]3.7010,[227]3.6990,[228]3.7001,[229]3.7028,[230]3.7086,[231]3.7142,[232]3.7035,[233]3.6969,[234]3.7003,[235]3.7000,[236]3.7105,[237]3.7196,[238]3.7296,[239]3.7397,[240]3.7490,[241]3.7612,[242]3.7780,[243]3.7920,[244]3.8010,[245]3.8136,[246]3.8253,[247]3.8218,[248]3.8166,[249]3.8127,[250]3.8035,[251]3.7989,[252]3.7990,[253]3.8014,[254]3.8078,[255]3.8131,[256]3.8157,[257]3.8173,[258]3.8165,[259]3.8192,[260]3.8210,[261]3.8216,[262]3.8184,[263]3.8242,[264]3.8259,[265]3.8253,[266]3.8270,[267]3.8292,[268]3.8335,[269]3.8366,[270]3.8339,[271]3.8310,[272]3.8212,[273]3.8237,[274]3.8171,[275]3.8064,[276]3.7978,[277]3.8000,[278]3.8117,[279]3.8180,[280]3.8261,[281]3.8342,[282]3.8406,[283]3.8481,[284]3.8552,[285]3.8705,[286]3.8717,[287]3.8735,[288]3.8772,[289]3.8784,[290]3.8700,[291]3.8628,[292]3.8670,[293]3.8667,[294]3.8666,[295]3.8643,[296]3.8674,[297]3.8695,[298]3.8749,[299]3.8810,[300]3.8834,[301]3.8873,[302]3.8905,[303]3.8920,[304]3.8897,[305]3.9028,[306]3.9107,[307]3.9233,[308]3.9105,[309]3.9049,[310]3.8953,[311]3.9003,[312]3.9029,[313]3.9102,[314]3.9117,[315]3.9139,[316]3.9146,[317]3.9158,[318]3.9153,[319]3.9149,[320]3.9197,[321]3.9192,[322]3.9198,[323]3.9267,[324]3.9268,[325]3.9321,[326]3.9366,[327]3.9413,[328]3.9428,[329]3.9432,[330]3.9494,[331]3.9548,[332]3.9594,[333]3.9565,[334]3.9546,[335]3.9540,[336]3.9526,[337]3.9527,[338]3.9517,[339]3.9532,[340]3.9559,[341]3.9612,[342]3.9708,[343]3.9821,[344]3.9881,[345]3.9815,[346]3.9747,[347]3.9737,[348]3.9658,[349]3.9626,[350]3.9605,[351]3.9653,[352]3.9825,[353]3.9922,[354]4.0070,[355]4.0165,[356]4.0224,[357]4.0353,[358]4.0467,[359]4.0498,[360]4.0566,[361]4.0663,[362]4.0752,[363]4.0821,[364]4.0883,[365]4.0951,[366]4.1072,[367]4.1167,[368]4.1239,[369]4.1321,[370]4.1405,[371]4.1558,[372]4.1662,[373]4.1686,[374]4.1717,[375]4.1765,[376]4.1906,[377]4.2018,[378]4.2036,[379]4.2020,[380]4.1979,[381]4.2015,[382]4.2068,[383]4.2105,[384]4.2151,[385]4.2190,[386]4.2261,[387]4.2320,[388]4.2353,[389]4.2226,[390]4.2128,[391]4.2012,[392]4.1953,[393]4.1874,[394]4.1781,[395]4.1686,[396]4.1579,[397]4.1479,[398]4.1364,[399]4.1252,[400]4.1158,[401]4.1039,[402]4.0928,[403]4.0826,[404]4.0696,[405]4.0578,[406]4.0457,[407]4.0346,[408]4.0253,[409]4.0163,[410]4.0103,[411]4.0126,[412]4.0087,[413]4.0125,[414]4.0162,[415]4.0133,[416]4.0137,[417]4.0178,[418]4.0120,[419]4.0138,[420]4.0103,[421]4.0092,[422]4.0116,[423]4.0108,[424]4.0153,[425]4.0150,[426]4.0145,[427]4.0133,[428]4.0172,[429]4.0179,[430]4.0210,[431]4.0221,[432]4.0206,[433]4.0161,[434]4.0172,[435]4.0101,[436]4.0042,[437]3.9999,[438]3.9976,[439]3.9962,[440]4.0016,[441]4.0068,[442]4.0145,[443]4.0118,[444]4.0119,[445]4.0124,[446]4.0178,[447]4.0204,[448]4.0229,[449]4.0258,[450]4.0300,[451]4.0332,[452]4.0355,[453]4.0372,[454]4.0350,[455]4.0366,[456]4.0358,[457]4.0386,[458]4.0437,[459]4.0436,[460]4.0429,[461]4.0385,[462]4.0420,[463]4.0498,[464]4.0555,[465]4.0492,[466]4.0484,[467]4.0478,[468]4.0507,[469]4.0484,[470]4.0456,[471]4.0462,[472]4.0475,[473]4.0461,[474]4.0448,[475]4.0461,[476]4.0445,[477]4.0431,[478]4.0452,[479]4.0474,[480]4.0498,[481]4.0451,[482]4.0485,[483]4.0468,[484]4.0501,[485]4.0570,[486]4.0598,[487]4.0636,[488]4.0693,[489]4.0709,[490]4.0753,[491]4.0819,[492]4.0865,[493]4.0859,[494]4.0871,[495]4.0892,[496]4.0911,[497]4.0942,[498]4.0940,[499]4.0930,[500]4.0963,[501]4.1008,[502]4.0998,[503]4.0970,[504]4.0993,[505]4.1025,[506]4.1110,[507]4.1133,[508]4.1169,[509]4.1081,[510]4.1046,[511]4.0984,[512]4.0942,[513]4.0882,[514]4.0876,[515]4.0906,[516]4.0874,[517]4.0874,[518]4.0871,[519]4.0877,[520]4.0927,[521]4.0910,[522]4.0893,[523]4.0966,[524]4.0959,[525]4.0942,[526]4.0906,[527]4.0840,[528]4.0809,[529]4.0771,[530]4.0736,[531]4.0699,[532]4.0620,[533]4.0548,[534]4.0513,[535]4.0528,[536]4.0558,[537]4.0596,[538]4.0640,[539]4.0670,[540]4.0730,[541]4.0768,[542]4.0797,[543]4.0759,[544]4.0717,[545]4.0708,[546]4.0626,[547]4.0565,[548]4.0490,[549]4.0425,[550]4.0367,[551]4.0308,[552]4.0249,[553]4.0194,[554]4.0198,[555]4.0182,[556]4.0211,[557]4.0259,[558]4.0322,[559]4.0371,[560]4.0430,[561]4.0400,
Final estimate: PPL = 4.0400 +/- 0.02311
llama_print_timings: load time = 36413.72 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 1702951.63 ms / 287232 tokens ( 5.93 ms per token, 168.67 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 1706441.65 ms / 287233 tokens
## again with -ser 6,1
llama_kv_cache_init: CUDA0 KV buffer size = 72.94 MiB
llama_new_context_with_model: KV self size = 72.91 MiB, c^KV (q8_0): 72.91 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 1.97 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 503.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 162.01 MiB
llama_new_context_with_model: graph nodes = 3548
llama_new_context_with_model: graph splits = 118
system_info: n_threads = 24 / 48 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
perplexity: tokenizing the input ..
perplexity: tokenization took 608.059 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 15.81 seconds per pass - ETA 36.93 minutes
[1]2.6383,[2]3.4392,[3]2.4566,[4]2.0850,[5]1.9090,[6]1.7848,[7]1.6805,[8]1.6308,[9]1.5919,[10]1.5463,[11]1.5494,[12]1.6200,[13]1.6404,[14]1.7746,[15]1.9251,[16]1.9812,[17]2.1567,[18]2.2874,[19]2.2496,[20]2.2360,[21]2.3495,[22]2.3124,[23]2.2781,[24]2.2966,[25]2.2613,[26]2.2293,[27]2.2764,[28]2.2883,[29]2.3441,[30]2.3747,[31]2.4141,[32]2.4356,[33]2.4773,[34]2.5225,[35]2.5798,[36]2.6357,[37]2.6692,[38]2.7190,[39]2.7605,[40]2.8239,[41]2.8673,[42]2.8753,[43]2.9274,[44]2.9418,[45]3.0241,[46]3.0761,[47]3.0411,[48]2.9954,[49]2.9720,[50]2.9965,[51]3.0450,[52]3.0606,[53]3.1138,[54]3.1304,[55]3.1600,[56]3.1970,[57]3.2131,[58]3.2561,[59]3.2645,[60]3.3166,[61]3.3573,[62]3.4157,[63]3.4524,[64]3.4987,[65]3.5063,[66]3.4949,[67]3.4740,[68]3.5101,[69]3.5120,[70]3.5317,[71]3.5477,[72]3.5616,[73]3.5728,[74]3.5932,[75]3.5705,[76]3.5180,[77]3.4777,[78]3.4751,[79]3.4568,[80]3.4439,[81]3.4042,[82]3.4112,[83]3.3874,[84]3.3539,[85]3.3213,[86]3.2985,[87]3.3058,[88]3.2793,[89]3.2703,[90]3.2456,[91]3.2217,[92]3.1996,[93]3.1747,[94]3.1517,[95]3.1352,[96]3.1383,[97]3.1483,[98]3.1361,[99]3.1177,[100]3.1197,[101]3.1118,[102]3.1278,[103]3.1563,[104]3.1767,[105]3.1733,[106]3.2008,[107]3.2254,[108]3.2456,[109]3.2812,[110]3.3161,[111]3.3382,[112]3.3082,[113]3.2952,[114]3.2755,[115]3.2586,[116]3.2518,[117]3.2286,[118]3.2061,[119]3.1864,[120]3.1644,[121]3.1488,[122]3.1277,[123]3.1089,[124]3.0897,[125]3.0718,[126]3.0538,[127]3.0404,[128]3.0348,[129]3.0265,[130]3.0165,[131]3.0092,[132]3.0150,[133]3.0224,[134]3.0265,[135]3.0378,[136]3.0561,[137]3.0727,[138]3.0800,[139]3.0907,[140]3.0892,[141]3.0880,[142]3.0845,[143]3.0826,[144]3.0758,[145]3.0663,[146]3.0631,[147]3.0662,[148]3.0649,[149]3.0643,[150]3.0564,[151]3.0524,[152]3.0471,[153]3.0411,[154]3.0400,[155]3.0432,[156]3.0431,[157]3.0477,[158]3.0567,[159]3.0579,[160]3.0669,[161]3.0749,[162]3.0838,[163]3.0901,[164]3.1119,[165]3.1367,[166]3.1548,[167]3.1696,[168]3.1962,[169]3.2196,[170]3.2420,[171]3.2661,[172]3.2467,[173]3.2266,[174]3.2125,[175]3.1996,[176]3.1862,[177]3.1753,[178]3.1621,[179]3.1475,[180]3.1508,[181]3.1650,[182]3.1807,[183]3.1952,[184]3.2096,[185]3.2197,[186]3.2367,[187]3.2520,[188]3.2670,[189]3.2774,[190]3.2771,[191]3.2836,[192]3.2861,[193]3.2902,[194]3.3108,[195]3.3200,[196]3.3329,[197]3.3423,[198]3.3456,[199]3.3513,[200]3.3487,[201]3.3644,[202]3.3578,[203]3.3627,[204]3.3650,[205]3.3660,[206]3.3680,[207]3.3772,[208]3.3868,[209]3.3968,[210]3.3965,[211]3.3901,[212]3.3888,[213]3.3963,[214]3.3974,[215]3.4026,[216]3.4023,[217]3.3963,[218]3.3952,[219]3.3949,[220]3.3928,[221]3.3922,[222]3.3914,[223]3.3920,[224]3.3971,[225]3.3990,[226]3.3893,[227]3.3880,[228]3.3893,[229]3.3934,[230]3.3995,[231]3.4054,[232]3.3962,[233]3.3892,[234]3.3920,[235]3.3917,[236]3.4013,[237]3.4105,[238]3.4201,[239]3.4303,[240]3.4394,[241]3.4509,[242]3.4661,[243]3.4791,[244]3.4880,[245]3.5000,[246]3.5109,[247]3.5084,[248]3.5043,[249]3.5017,[250]3.4936,[251]3.4902,[252]3.4911,[253]3.4942,[254]3.5007,[255]3.5065,[256]3.5093,[257]3.5113,[258]3.5115,[259]3.5142,[260]3.5159,[261]3.5164,[262]3.5145,[263]3.5205,[264]3.5225,[265]3.5218,[266]3.5235,[267]3.5258,[268]3.5298,[269]3.5330,[270]3.5310,[271]3.5287,[272]3.5208,[273]3.5217,[274]3.5154,[275]3.5044,[276]3.4937,[277]3.4956,[278]3.5066,[279]3.5124,[280]3.5204,[281]3.5275,[282]3.5336,[283]3.5407,[284]3.5479,[285]3.5618,[286]3.5638,[287]3.5661,[288]3.5702,[289]3.5723,[290]3.5640,[291]3.5573,[292]3.5601,[293]3.5595,[294]3.5590,[295]3.5572,[296]3.5593,[297]3.5607,[298]3.5658,[299]3.5727,[300]3.5756,[301]3.5796,[302]3.5822,[303]3.5835,[304]3.5817,[305]3.5937,[306]3.6013,[307]3.6130,[308]3.6006,[309]3.5950,[310]3.5858,[311]3.5906,[312]3.5932,[313]3.6006,[314]3.6025,[315]3.6052,[316]3.6060,[317]3.6070,[318]3.6071,[319]3.6076,[320]3.6119,[321]3.6119,[322]3.6134,[323]3.6199,[324]3.6201,[325]3.6247,[326]3.6300,[327]3.6338,[328]3.6362,[329]3.6374,[330]3.6436,[331]3.6484,[332]3.6528,[333]3.6507,[334]3.6496,[335]3.6493,[336]3.6487,[337]3.6491,[338]3.6492,[339]3.6512,[340]3.6547,[341]3.6600,[342]3.6695,[343]3.6796,[344]3.6848,[345]3.6765,[346]3.6696,[347]3.6677,[348]3.6601,[349]3.6564,[350]3.6545,[351]3.6590,[352]3.6751,[353]3.6840,[354]3.6979,[355]3.7068,[356]3.7124,[357]3.7248,[358]3.7354,[359]3.7387,[360]3.7452,[361]3.7545,[362]3.7639,[363]3.7694,[364]3.7756,[365]3.7823,[366]3.7938,[367]3.8022,[368]3.8094,[369]3.8175,[370]3.8264,[371]3.8411,[372]3.8507,[373]3.8534,[374]3.8566,[375]3.8612,[376]3.8748,[377]3.8859,[378]3.8879,[379]3.8866,[380]3.8829,[381]3.8870,[382]3.8927,[383]3.8964,[384]3.9009,[385]3.9048,[386]3.9115,[387]3.9175,[388]3.9207,[389]3.9090,[390]3.8992,[391]3.8885,[392]3.8827,[393]3.8740,[394]3.8651,[395]3.8553,[396]3.8447,[397]3.8354,[398]3.8246,[399]3.8137,[400]3.8050,[401]3.7938,[402]3.7825,[403]3.7724,[404]3.7607,[405]3.7501,[406]3.7389,[407]3.7288,[408]3.7196,[409]3.7106,[410]3.7044,[411]3.7062,[412]3.7017,[413]3.7045,[414]3.7075,[415]3.7046,[416]3.7048,[417]3.7074,[418]3.7013,[419]3.7033,[420]3.7006,[421]3.6995,[422]3.7013,[423]3.7008,[424]3.7054,[425]3.7051,[426]3.7051,[427]3.7042,[428]3.7072,[429]3.7086,[430]3.7119,[431]3.7130,[432]3.7119,[433]3.7080,[434]3.7090,[435]3.7024,[436]3.6967,[437]3.6930,[438]3.6911,[439]3.6894,[440]3.6946,[441]3.6996,[442]3.7070,[443]3.7049,[444]3.7051,[445]3.7062,[446]3.7114,[447]3.7139,[448]3.7160,[449]3.7188,[450]3.7230,[451]3.7264,[452]3.7286,[453]3.7301,[454]3.7282,[455]3.7304,[456]3.7301,[457]3.7328,[458]3.7378,[459]3.7382,[460]3.7377,[461]3.7339,[462]3.7376,[463]3.7451,[464]3.7509,[465]3.7444,[466]3.7430,[467]3.7421,[468]3.7442,[469]3.7417,[470]3.7389,[471]3.7392,[472]3.7403,[473]3.7394,[474]3.7383,[475]3.7398,[476]3.7378,[477]3.7367,[478]3.7376,[479]3.7398,[480]3.7420,[481]3.7381,[482]3.7415,[483]3.7402,[484]3.7436,[485]3.7502,[486]3.7532,[487]3.7565,[488]3.7623,[489]3.7642,[490]3.7687,[491]3.7748,[492]3.7793,[493]3.7789,[494]3.7798,[495]3.7820,[496]3.7838,[497]3.7869,[498]3.7871,[499]3.7865,[500]3.7901,[501]3.7947,[502]3.7934,[503]3.7912,[504]3.7933,[505]3.7963,[506]3.8046,[507]3.8071,[508]3.8105,[509]3.8022,[510]3.7980,[511]3.7914,[512]3.7870,[513]3.7813,[514]3.7809,[515]3.7836,[516]3.7793,[517]3.7794,[518]3.7790,[519]3.7798,[520]3.7846,[521]3.7831,[522]3.7814,[523]3.7880,[524]3.7868,[525]3.7852,[526]3.7814,[527]3.7752,[528]3.7717,[529]3.7682,[530]3.7650,[531]3.7615,[532]3.7545,[533]3.7481,[534]3.7443,[535]3.7456,[536]3.7485,[537]3.7524,[538]3.7561,[539]3.7590,[540]3.7645,[541]3.7680,[542]3.7704,[543]3.7656,[544]3.7619,[545]3.7613,[546]3.7538,[547]3.7477,[548]3.7409,[549]3.7342,[550]3.7282,[551]3.7222,[552]3.7165,[553]3.7113,[554]3.7108,[555]3.7094,[556]3.7121,[557]3.7164,[558]3.7226,[559]3.7273,[560]3.7330,[561]3.7305,
Final estimate: PPL = 3.7305 +/- 0.02118
llama_print_timings: load time = 9810.20 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 2166647.49 ms / 287232 tokens ( 7.54 ms per token, 132.57 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 2170176.48 ms / 287233 tokens
## again with -ser 5,1
perplexity: tokenizing the input ..
perplexity: tokenization took 607.579 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 14.10 seconds per pass - ETA 32.95 minutes
[1]2.6830,[2]3.4757,[3]2.4956,[4]2.1153,[5]1.9387,[6]1.8172,[7]1.7104,[8]1.6689,[9]1.6385,[10]1.5935,[11]1.5975,[12]1.6683,[13]1.6956,[14]1.8311,[15]1.9839,[16]2.0386,[17]2.2173,[18]2.3501,[19]2.3057,[20]2.2880,[21]2.4071,[22]2.3703,[23]2.3309,[24]2.3495,[25]2.3106,[26]2.2796,[27]2.3271,[28]2.3352,[29]2.3927,[30]2.4247,[31]2.4685,[32]2.4886,[33]2.5350,[34]2.5831,[35]2.6447,[36]2.7047,[37]2.7373,[38]2.7885,[39]2.8292,[40]2.8929,[41]2.9324,[42]2.9404,[43]2.9917,[44]3.0038,[45]3.0875,[46]3.1397,[47]3.1067,[48]3.0629,[49]3.0412,[50]3.0654,[51]3.1151,[52]3.1300,[53]3.1847,[54]3.2018,[55]3.2332,[56]3.2701,[57]3.2880,[58]3.3306,[59]3.3381,[60]3.3905,[61]3.4318,[62]3.4917,[63]3.5281,[64]3.5750,[65]3.5844,[66]3.5767,[67]3.5584,[68]3.5947,[69]3.5962,[70]3.6180,[71]3.6343,[72]3.6481,[73]3.6594,[74]3.6812,[75]3.6589,[76]3.6034,[77]3.5623,[78]3.5605,[79]3.5415,[80]3.5290,[81]3.4895,[82]3.4956,[83]3.4736,[84]3.4393,[85]3.4083,[86]3.3866,[87]3.3964,[88]3.3691,[89]3.3597,[90]3.3349,[91]3.3109,[92]3.2869,[93]3.2642,[94]3.2418,[95]3.2256,[96]3.2276,[97]3.2380,[98]3.2244,[99]3.2081,[100]3.2099,[101]3.2009,[102]3.2179,[103]3.2462,[104]3.2681,[105]3.2647,[106]3.2941,[107]3.3188,[108]3.3387,[109]3.3750,[110]3.4104,[111]3.4332,[112]3.4029,[113]3.3898,[114]3.3697,[115]3.3519,[116]3.3468,[117]3.3244,[118]3.3007,[119]3.2811,[120]3.2597,[121]3.2429,[122]3.2212,[123]3.2017,[124]3.1820,[125]3.1638,[126]3.1461,[127]3.1339,[128]3.1291,[129]3.1218,[130]3.1121,[131]3.1057,[132]3.1129,[133]3.1208,[134]3.1263,[135]3.1380,[136]3.1564,[137]3.1732,[138]3.1802,[139]3.1912,[140]3.1892,[141]3.1872,[142]3.1827,[143]3.1799,[144]3.1723,[145]3.1624,[146]3.1591,[147]3.1619,[148]3.1597,[149]3.1587,[150]3.1496,[151]3.1454,[152]3.1394,[153]3.1328,[154]3.1312,[155]3.1343,[156]3.1337,[157]3.1383,[158]3.1474,[159]3.1488,[160]3.1576,[161]3.1651,[162]3.1739,[163]3.1800,[164]3.2023,[165]3.2275,[166]3.2462,[167]3.2601,[168]3.2868,[169]3.3099,[170]3.3323,[171]3.3567,[172]3.3367,[173]3.3164,[174]3.3017,[175]3.2902,[176]3.2771,[177]3.2670,[178]3.2535,[179]3.2393,[180]3.2429,[181]3.2571,[182]3.2732,[183]3.2874,[184]3.3014,[185]3.3122,[186]3.3295,[187]3.3446,[188]3.3599,[189]3.3705,[190]3.3696,[191]3.3765,[192]3.3786,[193]3.3824,[194]3.4032,[195]3.4122,[196]3.4251,[197]3.4347,[198]3.4375,[199]3.4438,[200]3.4407,[201]3.4567,[202]3.4494,[203]3.4545,[204]3.4569,[205]3.4574,[206]3.4587,[207]3.4683,[208]3.4772,[209]3.4874,[210]3.4869,[211]3.4797,[212]3.4785,[213]3.4861,[214]3.4870,[215]3.4923,[216]3.4914,[217]3.4849,[218]3.4840,[219]3.4835,[220]3.4817,[221]3.4806,[222]3.4792,[223]3.4798,[224]3.4851,[225]3.4867,[226]3.4768,[227]3.4749,[228]3.4761,[229]3.4794,[230]3.4856,[231]3.4916,[232]3.4821,[233]3.4752,[234]3.4783,[235]3.4784,[236]3.4883,[237]3.4971,[238]3.5062,[239]3.5170,[240]3.5263,[241]3.5383,[242]3.5543,[243]3.5684,[244]3.5778,[245]3.5897,[246]3.6008,[247]3.5980,[248]3.5934,[249]3.5902,[250]3.5814,[251]3.5777,[252]3.5788,[253]3.5821,[254]3.5884,[255]3.5943,[256]3.5970,[257]3.5990,[258]3.5989,[259]3.6015,[260]3.6031,[261]3.6035,[262]3.6012,[263]3.6072,[264]3.6090,[265]3.6087,[266]3.6106,[267]3.6128,[268]3.6166,[269]3.6194,[270]3.6171,[271]3.6147,[272]3.6056,[273]3.6071,[274]3.6006,[275]3.5897,[276]3.5795,[277]3.5817,[278]3.5930,[279]3.5989,[280]3.6071,[281]3.6147,[282]3.6212,[283]3.6288,[284]3.6360,[285]3.6504,[286]3.6522,[287]3.6548,[288]3.6587,[289]3.6605,[290]3.6523,[291]3.6454,[292]3.6481,[293]3.6476,[294]3.6476,[295]3.6457,[296]3.6483,[297]3.6491,[298]3.6545,[299]3.6611,[300]3.6639,[301]3.6679,[302]3.6708,[303]3.6722,[304]3.6700,[305]3.6824,[306]3.6901,[307]3.7024,[308]3.6897,[309]3.6841,[310]3.6748,[311]3.6796,[312]3.6824,[313]3.6903,[314]3.6917,[315]3.6941,[316]3.6951,[317]3.6964,[318]3.6963,[319]3.6963,[320]3.7011,[321]3.7008,[322]3.7018,[323]3.7083,[324]3.7083,[325]3.7132,[326]3.7180,[327]3.7228,[328]3.7249,[329]3.7262,[330]3.7325,[331]3.7374,[332]3.7421,[333]3.7397,[334]3.7384,[335]3.7381,[336]3.7373,[337]3.7375,[338]3.7375,[339]3.7392,[340]3.7424,[341]3.7477,[342]3.7571,[343]3.7674,[344]3.7732,[345]3.7656,[346]3.7595,[347]3.7577,[348]3.7500,[349]3.7461,[350]3.7443,[351]3.7491,[352]3.7655,[353]3.7748,[354]3.7888,[355]3.7978,[356]3.8035,[357]3.8162,[358]3.8266,[359]3.8295,[360]3.8362,[361]3.8455,[362]3.8548,[363]3.8607,[364]3.8666,[365]3.8735,[366]3.8853,[367]3.8941,[368]3.9014,[369]3.9097,[370]3.9182,[371]3.9331,[372]3.9430,[373]3.9457,[374]3.9491,[375]3.9535,[376]3.9673,[377]3.9784,[378]3.9803,[379]3.9791,[380]3.9754,[381]3.9794,[382]3.9849,[383]3.9887,[384]3.9933,[385]3.9970,[386]4.0037,[387]4.0098,[388]4.0131,[389]4.0013,[390]3.9915,[391]3.9804,[392]3.9748,[393]3.9663,[394]3.9575,[395]3.9481,[396]3.9370,[397]3.9280,[398]3.9172,[399]3.9061,[400]3.8974,[401]3.8860,[402]3.8745,[403]3.8643,[404]3.8524,[405]3.8414,[406]3.8296,[407]3.8191,[408]3.8097,[409]3.8006,[410]3.7943,[411]3.7961,[412]3.7921,[413]3.7947,[414]3.7976,[415]3.7945,[416]3.7950,[417]3.7982,[418]3.7921,[419]3.7941,[420]3.7913,[421]3.7901,[422]3.7917,[423]3.7912,[424]3.7959,[425]3.7956,[426]3.7953,[427]3.7944,[428]3.7974,[429]3.7985,[430]3.8016,[431]3.8023,[432]3.8011,[433]3.7969,[434]3.7978,[435]3.7909,[436]3.7853,[437]3.7815,[438]3.7793,[439]3.7775,[440]3.7831,[441]3.7881,[442]3.7956,[443]3.7933,[444]3.7935,[445]3.7942,[446]3.7993,[447]3.8019,[448]3.8041,[449]3.8064,[450]3.8106,[451]3.8140,[452]3.8162,[453]3.8180,[454]3.8158,[455]3.8178,[456]3.8176,[457]3.8202,[458]3.8254,[459]3.8258,[460]3.8249,[461]3.8211,[462]3.8246,[463]3.8320,[464]3.8378,[465]3.8311,[466]3.8299,[467]3.8291,[468]3.8314,[469]3.8288,[470]3.8260,[471]3.8262,[472]3.8274,[473]3.8264,[474]3.8252,[475]3.8266,[476]3.8244,[477]3.8232,[478]3.8247,[479]3.8268,[480]3.8294,[481]3.8253,[482]3.8287,[483]3.8271,[484]3.8303,[485]3.8367,[486]3.8398,[487]3.8433,[488]3.8490,[489]3.8508,[490]3.8555,[491]3.8619,[492]3.8663,[493]3.8663,[494]3.8674,[495]3.8694,[496]3.8712,[497]3.8744,[498]3.8743,[499]3.8737,[500]3.8771,[501]3.8816,[502]3.8804,[503]3.8779,[504]3.8800,[505]3.8830,[506]3.8912,[507]3.8936,[508]3.8972,[509]3.8887,[510]3.8849,[511]3.8786,[512]3.8741,[513]3.8681,[514]3.8672,[515]3.8700,[516]3.8659,[517]3.8660,[518]3.8658,[519]3.8667,[520]3.8716,[521]3.8700,[522]3.8683,[523]3.8753,[524]3.8744,[525]3.8725,[526]3.8689,[527]3.8627,[528]3.8593,[529]3.8558,[530]3.8524,[531]3.8487,[532]3.8416,[533]3.8349,[534]3.8315,[535]3.8326,[536]3.8353,[537]3.8394,[538]3.8435,[539]3.8464,[540]3.8524,[541]3.8558,[542]3.8583,[543]3.8540,[544]3.8505,[545]3.8501,[546]3.8424,[547]3.8364,[548]3.8295,[549]3.8224,[550]3.8164,[551]3.8104,[552]3.8046,[553]3.7992,[554]3.7993,[555]3.7979,[556]3.8006,[557]3.8049,[558]3.8112,[559]3.8159,[560]3.8216,[561]3.8189,
Final estimate: PPL = 3.8189 +/- 0.02171
llama_print_timings: load time = 9779.02 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 1940210.95 ms / 287232 tokens ( 6.75 ms per token, 148.04 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 1943740.46 ms / 287233 tokens
## again with -ser 7,1
perplexity: tokenizing the input ..
perplexity: tokenization took 643.261 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 17.39 seconds per pass - ETA 40.65 minutes
[1]2.6392,[2]3.4663,[3]2.4744,[4]2.0865,[5]1.9050,[6]1.7817,[7]1.6767,[8]1.6264,[9]1.5874,[10]1.5396,[11]1.5359,[12]1.5994,[13]1.6198,[14]1.7544,[15]1.8973,[16]1.9543,[17]2.1251,[18]2.2555,[19]2.2165,[20]2.2059,[21]2.3162,[22]2.2807,[23]2.2487,[24]2.2607,[25]2.2276,[26]2.1968,[27]2.2454,[28]2.2572,[29]2.3090,[30]2.3405,[31]2.3812,[32]2.4012,[33]2.4438,[34]2.4915,[35]2.5495,[36]2.6048,[37]2.6393,[38]2.6890,[39]2.7297,[40]2.7933,[41]2.8382,[42]2.8479,[43]2.9002,[44]2.9142,[45]2.9968,[46]3.0486,[47]3.0113,[48]2.9637,[49]2.9420,[50]2.9654,[51]3.0145,[52]3.0313,[53]3.0853,[54]3.1012,[55]3.1321,[56]3.1682,[57]3.1823,[58]3.2248,[59]3.2321,[60]3.2823,[61]3.3229,[62]3.3765,[63]3.4111,[64]3.4569,[65]3.4644,[66]3.4514,[67]3.4316,[68]3.4678,[69]3.4693,[70]3.4852,[71]3.5018,[72]3.5164,[73]3.5284,[74]3.5502,[75]3.5286,[76]3.4770,[77]3.4378,[78]3.4341,[79]3.4135,[80]3.4004,[81]3.3619,[82]3.3706,[83]3.3457,[84]3.3122,[85]3.2805,[86]3.2571,[87]3.2615,[88]3.2350,[89]3.2276,[90]3.2025,[91]3.1788,[92]3.1552,[93]3.1294,[94]3.1079,[95]3.0899,[96]3.0916,[97]3.0997,[98]3.0887,[99]3.0710,[100]3.0725,[101]3.0650,[102]3.0820,[103]3.1103,[104]3.1317,[105]3.1281,[106]3.1544,[107]3.1789,[108]3.1998,[109]3.2355,[110]3.2700,[111]3.2921,[112]3.2632,[113]3.2498,[114]3.2292,[115]3.2128,[116]3.2061,[117]3.1829,[118]3.1616,[119]3.1423,[120]3.1206,[121]3.1059,[122]3.0852,[123]3.0665,[124]3.0471,[125]3.0289,[126]3.0109,[127]2.9971,[128]2.9924,[129]2.9836,[130]2.9734,[131]2.9656,[132]2.9724,[133]2.9806,[134]2.9854,[135]2.9966,[136]3.0146,[137]3.0308,[138]3.0382,[139]3.0493,[140]3.0483,[141]3.0475,[142]3.0444,[143]3.0431,[144]3.0362,[145]3.0261,[146]3.0228,[147]3.0255,[148]3.0242,[149]3.0242,[150]3.0166,[151]3.0126,[152]3.0077,[153]3.0019,[154]3.0012,[155]3.0044,[156]3.0049,[157]3.0096,[158]3.0182,[159]3.0192,[160]3.0282,[161]3.0365,[162]3.0456,[163]3.0515,[164]3.0728,[165]3.0971,[166]3.1149,[167]3.1290,[168]3.1550,[169]3.1779,[170]3.1994,[171]3.2232,[172]3.2041,[173]3.1846,[174]3.1711,[175]3.1587,[176]3.1460,[177]3.1348,[178]3.1216,[179]3.1073,[180]3.1105,[181]3.1247,[182]3.1406,[183]3.1551,[184]3.1695,[185]3.1793,[186]3.1961,[187]3.2114,[188]3.2263,[189]3.2365,[190]3.2364,[191]3.2432,[192]3.2455,[193]3.2494,[194]3.2696,[195]3.2793,[196]3.2925,[197]3.3020,[198]3.3051,[199]3.3105,[200]3.3081,[201]3.3239,[202]3.3179,[203]3.3232,[204]3.3256,[205]3.3260,[206]3.3277,[207]3.3366,[208]3.3465,[209]3.3566,[210]3.3560,[211]3.3497,[212]3.3488,[213]3.3563,[214]3.3575,[215]3.3631,[216]3.3630,[217]3.3574,[218]3.3565,[219]3.3566,[220]3.3549,[221]3.3545,[222]3.3541,[223]3.3547,[224]3.3597,[225]3.3615,[226]3.3520,[227]3.3506,[228]3.3522,[229]3.3562,[230]3.3624,[231]3.3685,[232]3.3590,[233]3.3520,[234]3.3549,[235]3.3552,[236]3.3645,[237]3.3734,[238]3.3831,[239]3.3936,[240]3.4023,[241]3.4141,[242]3.4296,[243]3.4427,[244]3.4513,[245]3.4632,[246]3.4738,[247]3.4713,[248]3.4672,[249]3.4649,[250]3.4570,[251]3.4537,[252]3.4549,[253]3.4578,[254]3.4644,[255]3.4702,[256]3.4732,[257]3.4754,[258]3.4757,[259]3.4781,[260]3.4798,[261]3.4804,[262]3.4783,[263]3.4841,[264]3.4862,[265]3.4857,[266]3.4876,[267]3.4900,[268]3.4939,[269]3.4968,[270]3.4949,[271]3.4925,[272]3.4846,[273]3.4856,[274]3.4794,[275]3.4687,[276]3.4590,[277]3.4607,[278]3.4718,[279]3.4774,[280]3.4855,[281]3.4927,[282]3.4986,[283]3.5056,[284]3.5126,[285]3.5268,[286]3.5292,[287]3.5318,[288]3.5360,[289]3.5381,[290]3.5297,[291]3.5227,[292]3.5246,[293]3.5242,[294]3.5236,[295]3.5216,[296]3.5240,[297]3.5254,[298]3.5305,[299]3.5374,[300]3.5404,[301]3.5446,[302]3.5470,[303]3.5480,[304]3.5461,[305]3.5583,[306]3.5655,[307]3.5769,[308]3.5646,[309]3.5591,[310]3.5501,[311]3.5548,[312]3.5580,[313]3.5652,[314]3.5670,[315]3.5698,[316]3.5707,[317]3.5720,[318]3.5722,[319]3.5725,[320]3.5769,[321]3.5770,[322]3.5785,[323]3.5849,[324]3.5853,[325]3.5900,[326]3.5948,[327]3.5986,[328]3.6009,[329]3.6023,[330]3.6085,[331]3.6134,[332]3.6180,[333]3.6159,[334]3.6149,[335]3.6146,[336]3.6140,[337]3.6145,[338]3.6145,[339]3.6167,[340]3.6202,[341]3.6257,[342]3.6349,[343]3.6448,[344]3.6498,[345]3.6419,[346]3.6350,[347]3.6328,[348]3.6249,[349]3.6209,[350]3.6193,[351]3.6241,[352]3.6398,[353]3.6486,[354]3.6622,[355]3.6711,[356]3.6768,[357]3.6890,[358]3.6995,[359]3.7026,[360]3.7092,[361]3.7183,[362]3.7276,[363]3.7332,[364]3.7395,[365]3.7463,[366]3.7577,[367]3.7663,[368]3.7733,[369]3.7814,[370]3.7902,[371]3.8046,[372]3.8141,[373]3.8168,[374]3.8200,[375]3.8245,[376]3.8377,[377]3.8488,[378]3.8510,[379]3.8499,[380]3.8463,[381]3.8505,[382]3.8562,[383]3.8599,[384]3.8644,[385]3.8682,[386]3.8749,[387]3.8807,[388]3.8838,[389]3.8723,[390]3.8624,[391]3.8519,[392]3.8461,[393]3.8373,[394]3.8284,[395]3.8192,[396]3.8083,[397]3.7990,[398]3.7885,[399]3.7776,[400]3.7689,[401]3.7578,[402]3.7465,[403]3.7367,[404]3.7251,[405]3.7145,[406]3.7033,[407]3.6934,[408]3.6843,[409]3.6751,[410]3.6690,[411]3.6709,[412]3.6667,[413]3.6695,[414]3.6725,[415]3.6699,[416]3.6702,[417]3.6727,[418]3.6666,[419]3.6682,[420]3.6656,[421]3.6645,[422]3.6661,[423]3.6656,[424]3.6699,[425]3.6693,[426]3.6695,[427]3.6686,[428]3.6715,[429]3.6730,[430]3.6760,[431]3.6770,[432]3.6760,[433]3.6721,[434]3.6730,[435]3.6666,[436]3.6609,[437]3.6574,[438]3.6554,[439]3.6539,[440]3.6591,[441]3.6641,[442]3.6716,[443]3.6695,[444]3.6698,[445]3.6709,[446]3.6760,[447]3.6784,[448]3.6809,[449]3.6835,[450]3.6875,[451]3.6911,[452]3.6935,[453]3.6950,[454]3.6930,[455]3.6951,[456]3.6949,[457]3.6973,[458]3.7023,[459]3.7026,[460]3.7022,[461]3.6982,[462]3.7019,[463]3.7091,[464]3.7150,[465]3.7085,[466]3.7072,[467]3.7065,[468]3.7085,[469]3.7060,[470]3.7033,[471]3.7035,[472]3.7045,[473]3.7038,[474]3.7026,[475]3.7040,[476]3.7021,[477]3.7011,[478]3.7019,[479]3.7039,[480]3.7062,[481]3.7024,[482]3.7060,[483]3.7046,[484]3.7080,[485]3.7146,[486]3.7175,[487]3.7210,[488]3.7266,[489]3.7286,[490]3.7332,[491]3.7393,[492]3.7437,[493]3.7435,[494]3.7445,[495]3.7468,[496]3.7485,[497]3.7517,[498]3.7516,[499]3.7509,[500]3.7546,[501]3.7590,[502]3.7577,[503]3.7556,[504]3.7581,[505]3.7609,[506]3.7694,[507]3.7719,[508]3.7754,[509]3.7672,[510]3.7628,[511]3.7567,[512]3.7522,[513]3.7464,[514]3.7458,[515]3.7487,[516]3.7445,[517]3.7447,[518]3.7440,[519]3.7449,[520]3.7497,[521]3.7481,[522]3.7462,[523]3.7527,[524]3.7515,[525]3.7499,[526]3.7462,[527]3.7402,[528]3.7371,[529]3.7336,[530]3.7307,[531]3.7272,[532]3.7204,[533]3.7139,[534]3.7102,[535]3.7115,[536]3.7145,[537]3.7184,[538]3.7216,[539]3.7244,[540]3.7301,[541]3.7338,[542]3.7364,[543]3.7313,[544]3.7275,[545]3.7269,[546]3.7196,[547]3.7134,[548]3.7066,[549]3.7000,[550]3.6942,[551]3.6884,[552]3.6828,[553]3.6777,[554]3.6773,[555]3.6761,[556]3.6787,[557]3.6829,[558]3.6891,[559]3.6938,[560]3.6994,[561]3.6968,
Final estimate: PPL = 3.6968 +/- 0.02105
llama_print_timings: load time = 10199.69 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 2403207.35 ms / 287232 tokens ( 8.37 ms per token, 119.52 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 2406766.55 ms / 287233 tokens
ubergarm IQ2_BN_R4
This is an experimental quant I rolled with q8_0 for all attention/shared experts/embeddings loaded on GPU. The rest of the MoE down exps are iq2_xs_r4 and gate/up exps are iq2_bn_r4. However, perplexity looks pretty bad. So I'll likely aim for larger sized model with higher quality quants and make-up speed/accuracy trade off exploring -ser instead of going very small quants.
Looking back on it with advise from the team, bitnet quants are very fast to compute, but only good quality for models trained specifically as a ternary bit-net. So this is not the correct use-case.
This was run on ik_llama.cpp@127c6ee6
CUDA_VISIBLE_DEVICES="0," \
./build/bin/llama-perplexity \
--model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-IQ2_BN_R4.gguf \
-ctk q8_0 \
-mla 2 -fa \
-amb 512 \
-fmoe \
--ctx-size 512 \
--ubatch-size 512 \
-f wiki.test.raw \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--threads 24
main: build = 3597 (127c6ee6)
main: built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu
main: seed = 1742438479
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 612 tensors
llama_model_loader: - type iq2_xs_r4: 58 tensors
llama_model_loader: - type iq2_bn_r4: 116 Tensors
system_info: n_threads = 24 / 48 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
perplexity: tokenizing the input ..
perplexity: tokenization took 561.456 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 18.96 seconds per pass - ETA 44.30 minutes
[1]30.4651,[2]41.3702,[3]59.6912,[4]63.7281,[5]69.4759,[6]74.5164,[7]78.4960,[8]83.2716,[9]91.6114,[10]92.0761,[11]93.4731,[12]97.5649,[13]103.3701,[14]98.6315,[15]101.2792,[16]92.5897,[17]94.2696,[18]95.8584,[19]98.7396,[20]95.6990,[21]93.2173,[22]88.2120,[23]80.9408,[24]79.5825,[25]75.1830,[26]73.4152,[27]73.7467,[28]72.5897,[29]73.6461,[30]71.2716,[31]70.8169,[32]71.0411,[33]71.9739,[34]73.1812,[35]74.9429,[36]75.9408,[37]74.4652,[38]75.1052,[39]75.1191,[40]75.3918,[41]75.9498,[42]75.0217,[43]75.3187,[44]73.9763,[45]74.7156,[46]74.6030,[47]73.8118,[48]73.4332,[49]72.7741,[50]73.2112,[51]73.5430,[52]73.1248,[53]73.7724,[54]73.3190,[55]73.3087,[56]73.3568,[57]72.9256,[58]73.3320,[59]72.7841,[60]73.7844,[61]74.8152,[62]75.6196,[63]76.1783,[64]76.8785,[65]76.2970,[66]75.9790,[67]75.8581,[68]76.0077,[69]76.2337,[70]76.4732,[71]76.8328,[72]76.5038,[73]76.6703,[74]76.7263,[75]75.3965,[76]75.0320,[77]74.3497,[78]74.5668,[79]74.8424,[80]74.6498,[81]74.7401,[82]75.1574,[83]75.3660,[84]75.3174,[85]74.9314,[86]74.5937,[87]75.7275,[88]75.4835,[89]75.3029,[90]75.3806,[91]74.8898,[92]74.6847,[93]74.2882,[94]74.7222,[95]74.6123,[96]75.0049,[97]75.3071,[98]75.1735,[99]75.6399,[100]75.1926,[101]75.5885,[102]75.5438,[103]75.5805,[104]75.9626,[105]76.5854,[106]77.2787,[107]77.4046,[108]77.6250,[109]78.5008,[110]79.0834,[111]79.3914,[112]78.8812,[113]78.6738,[114]78.7153,[115]78.5561,[116]78.6442,[117]78.1482,[118]77.5726,[119]76.8977,[120]76.4276,[121]76.4281,[122]75.9297,[123]75.8329,[124]75.7454,[125]75.0345,[126]74.3182,[127]74.3376,[128]74.2819,[129]74.4231,[130]74.4475,[131]74.1864,[132]74.2024,[133]74.1325,[134]74.3007,[135]74.3278,[136]74.2061,[137]74.0316,[138]73.8620,[139]73.8160,[140]72.9537,[141]72.5497,[142]72.4046,[143]72.2079,[144]71.4530,[145]71.1845,[146]71.0542,[147]71.0027,[148]70.5053,[149]70.3279,[150]69.9599,[151]69.9437,[152]69.8039,[153]69.4855,[154]69.2991,[155]69.3639,[156]69.4526,[157]69.5932,[158]69.5653,[159]69.7948,[160]69.7201,[161]69.6685,[162]69.6460,[163]70.2213,[164]70.5881,[165]70.9379,[166]71.2368,[167]71.3472,[168]71.8189,[169]72.0481,[170]72.5595,[171]72.9830,[172]73.1128,[173]73.1918,[174]73.7032,[175]73.8460,[176]74.1501,[177]74.3805,[178]74.5088,[179]74.7271,[180]75.0349,[181]75.2392,[182]75.3930,[183]75.4962,[184]75.6980,[185]75.7017,[186]75.9172,[187]76.1569,[188]76.3392,[189]76.5035,[190]76.4001,[191]76.0507,[192]75.7021,[193]75.7208,[194]75.8537,[195]76.0376,[196]76.0778,[197]76.1313,[198]75.8537,[199]75.9918,[200]75.4142,[201]75.5213,[202]75.5615,[203]75.2912,[204]74.9822,[205]74.8085,[206]74.5319,[207]74.6603,[208]74.7784,[209]74.7338,[210]74.3459,[211]74.0537,[212]73.9633,[213]73.8683,[214]73.6936,[215]73.7491,[216]73.5260,[217]73.3379,[218]73.2290,[219]73.1061,[220]72.7115,[221]72.4290,[222]72.3064,[223]72.2784,[224]72.0623,[225]71.9317,[226]71.5524,[227]71.5180,[228]71.3948,[229]71.4077,[230]71.3968,[231]71.1918,[232]71.1809,[233]71.2559,[234]71.5151,[235]71.6945,[236]71.8480,[237]72.0458,[238]72.0786,[239]72.2764,[240]72.2934,[241]72.2876,[242]72.4647,[243]72.6715,[244]72.8228,[245]73.1111,[246]73.2691,[247]72.9157,[248]72.8787,[249]72.8196,[250]72.6383,[251]72.7225,[252]72.6816,[253]72.6690,[254]72.8589,[255]72.9280,[256]73.0759,[257]72.9125,[258]72.9499,[259]72.9666,[260]72.9527,[261]73.0663,[262]73.0243,[263]73.1014,[264]73.1146,[265]73.0295,[266]72.9404,[267]73.0977,[268]73.0974,[269]73.1050,[270]73.1464,[271]73.1283,[272]72.9510,[273]73.1206,[274]72.9188,[275]72.6492,[276]72.5276,[277]72.6023,[278]72.7573,[279]72.7637,[280]72.9360,[281]73.1038,[282]73.1992,[283]73.3907,[284]73.5623,[285]73.8527,[286]73.9684,[287]73.7626,[288]73.8129,[289]73.6910,[290]73.7631,[291]73.7001,[292]73.7971,[293]73.8070,[294]73.7912,[295]73.7995,[296]73.7670,[297]73.6427,[298]73.7091,[299]73.7808,[300]73.6593,[301]73.6734,[302]73.7352,[303]73.5537,[304]73.5688,[305]73.7986,[306]73.7752,[307]73.8407,[308]73.9159,[309]73.9887,[310]73.8264,[311]73.9956,[312]74.0235,[313]74.0562,[314]73.9765,[315]73.7744,[316]73.5667,[317]73.4656,[318]73.2387,[319]72.9452,[320]72.8921,[321]72.7795,[322]72.6295,[323]72.7180,[324]72.4026,[325]72.4001,[326]72.4355,[327]72.4267,[328]72.3786,[329]72.2933,[330]72.4264,[331]72.5120,[332]72.5842,[333]72.5420,[334]72.6294,[335]72.6203,[336]72.5613,[337]72.6455,[338]72.7551,[339]72.9121,[340]72.8642,[341]72.9226,[342]73.0614,[343]73.2002,[344]73.3840,[345]73.2675,[346]73.4389,[347]73.4674,[348]73.6170,[349]73.7728,[350]74.0274,[351]74.1304,[352]74.3622,[353]74.5060,[354]74.7099,[355]74.9348,[356]75.1550,[357]75.3012,[358]75.5045,[359]75.7389,[360]75.8253,[361]75.9817,[362]76.0769,[363]76.3016,[364]76.5374,[365]76.7491,[366]76.8622,[367]76.9915,[368]77.1832,[369]77.2848,[370]77.4517,[371]77.6151,[372]77.8006,[373]77.6992,[374]77.6120,[375]77.6728,[376]77.8086,[377]77.9167,[378]77.9694,[379]77.9362,[380]77.9685,[381]78.0667,[382]78.0937,[383]78.0334,[384]78.1167,[385]78.2458,[386]78.3953,[387]78.4767,[388]78.5231,[389]78.6517,[390]78.5486,[391]78.4141,[392]78.4592,[393]78.5561,[394]78.5214,[395]78.5224,[396]78.6534,[397]78.5777,[398]78.5956,[399]78.6529,[400]78.6946,[401]78.6505,[402]78.7588,[403]78.8119,[404]78.8418,[405]78.7557,[406]78.7805,[407]78.7304,[408]78.8406,[409]78.8875,[410]79.0045,[411]79.0516,[412]79.2824,[413]79.3757,[414]79.5010,[415]79.5673,[416]79.6531,[417]79.7945,[418]79.5969,[419]79.6173,[420]79.3900,[421]79.2968,[422]79.3331,[423]79.1822,[424]79.1590,[425]79.0439,[426]79.1252,[427]79.0451,[428]79.0732,[429]78.9041,[430]78.9446,[431]78.9144,[432]78.8635,[433]78.7848,[434]78.8337,[435]78.8372,[436]78.7636,[437]78.7688,[438]78.6158,[439]78.8016,[440]78.8886,[441]78.9032,[442]79.0712,[443]78.9520,[444]79.0125,[445]79.1275,[446]79.2797,[447]79.3779,[448]79.4570,[449]79.4597,[450]79.5344,[451]79.6098,[452]79.7045,[453]79.8331,[454]79.8938,[455]79.9051,[456]79.7348,[457]79.6326,[458]79.7009,[459]79.7852,[460]79.5662,[461]79.4191,[462]79.4215,[463]79.4698,[464]79.6245,[465]79.5234,[466]79.4492,[467]79.4723,[468]79.4396,[469]79.3697,[470]79.2523,[471]79.1118,[472]78.9983,[473]78.8544,[474]78.7369,[475]78.5814,[476]78.5756,[477]78.3830,[478]78.3047,[479]78.2794,[480]78.3264,[481]78.2197,[482]78.2629,[483]78.2012,[484]78.2675,[485]78.3674,[486]78.4736,[487]78.5828,[488]78.5797,[489]78.5999,[490]78.6365,[491]78.7815,[492]78.7504,[493]78.7922,[494]78.8015,[495]78.7004,[496]78.5756,[497]78.4860,[498]78.3539,[499]78.2442,[500]78.3182,[501]78.2717,[502]78.3639,[503]78.2322,[504]78.3304,[505]78.2150,[506]78.3179,[507]78.3095,[508]78.3384,[509]78.1947,[510]78.2006,[511]78.2526,[512]78.2743,[513]78.3435,[514]78.3612,[515]78.3154,[516]78.1985,[517]78.2343,[518]78.2949,[519]78.3075,[520]78.4294,[521]78.2518,[522]78.1125,[523]78.1626,[524]78.2124,[525]78.2667,[526]78.2024,[527]77.9745,[528]78.0344,[529]77.8533,[530]77.6433,[531]77.5433,[532]77.0303,[533]77.0269,[534]77.1059,[535]77.0778,[536]77.1151,[537]77.1756,[538]77.2906,[539]77.4305,[540]77.4170,[541]77.5524,[542]77.6613,[543]77.7994,[544]77.8804,[545]77.9306,[546]77.9287,[547]78.0057,[548]78.0461,[549]78.0829,[550]78.2113,[551]78.3108,[552]78.3873,[553]78.4217,[554]78.5062,[555]78.5587,[556]78.5389,[557]78.6403,[558]78.7766,[559]78.8293,[560]78.9632,[561]78.9693,
llama_print_timings: load time = 31419.46 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 2597239.00 ms / 287232 tokens ( 9.04 ms per token, 110.59 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 2600677.72 ms / 287233 tokens
Final estimate: PPL = 78.9693 +/- 0.66476
ubergarm IQ2_K_R4
Another experimental quant with q8_0 for all GPU layers (with room for 32k context still) and down=iq3_k_r4 and gate/up=iq2_k_r4 for -ot exps=CPU CPU offload.
CUDA_VISIBLE_DEVICES="0," \
./build/bin/llama-perplexity \
--model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-IQ2_K_R4.gguf \
-ctk q8_0 \
-mla 2 -fa \
-amb 512 \
-fmoe \
--ctx-size 512 \
--ubatch-size 512 \
-f wiki.test.raw \
--seed 1337 \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--threads 24
main: build = 3601 (3d6e25c8)
main: built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu
main: seed = 1337
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 612 tensors
llama_model_loader: - type iq2_k_r4: 116 tensors
llama_model_loader: - type iq3_k_r4: 58 tensors
system_info: n_threads = 24 / 48 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
perplexity: tokenizing the input ..
perplexity: tokenization took 611.597 ms
perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4
perplexity: 20.37 seconds per pass - ETA 47.62 minutes
[1]2.8167,[2]3.5984,[3]2.5279,[4]2.1350,[5]1.9307,[6]1.8199,[7]1.7183,[8]1.6549,[9]1.6132,[10]1.5715,[11]1.5652,[12]1.6259,[13]1.6478,[14]1.7798,[15]1.9153,[16]1.9692,[17]2.1392,[18]2.2755,[19]2.2279,[20]2.2171,[21]2.3203,[22]2.2886,[23]2.2519,[24]2.2700,[25]2.2320,[26]2.2026,[27]2.2543,[28]2.2624,[29]2.3195,[30]2.3504,[31]2.3870,[32]2.4029,[33]2.4421,[34]2.4923,[35]2.5471,[36]2.6029,[37]2.6384,[38]2.6881,[39]2.7250,[40]2.7885,[41]2.8333,[42]2.8477,[43]2.9012,[44]2.9163,[45]3.0018,[46]3.0529,[47]3.0155,[48]2.9704,[49]2.9533,[50]2.9794,[51]3.0260,[52]3.0432,[53]3.1013,[54]3.1143,[55]3.1468,[56]3.1829,[57]3.2004,[58]3.2455,[59]3.2565,[60]3.3071,[61]3.3500,[62]3.4085,[63]3.4443,[64]3.4925,[65]3.5020,[66]3.4960,[67]3.4727,[68]3.5045,[69]3.5053,[70]3.5287,[71]3.5449,[72]3.5590,[73]3.5715,[74]3.5914,[75]3.5693,[76]3.5179,[77]3.4743,[78]3.4715,[79]3.4516,[80]3.4385,[81]3.4028,[82]3.4083,[83]3.3817,[84]3.3448,[85]3.3113,[86]3.2904,[87]3.2976,[88]3.2723,[89]3.2646,[90]3.2395,[91]3.2150,[92]3.1917,[93]3.1638,[94]3.1410,[95]3.1215,[96]3.1248,[97]3.1335,[98]3.1231,[99]3.1061,[100]3.1060,[101]3.0979,[102]3.1176,[103]3.1448,[104]3.1673,[105]3.1652,[106]3.1920,[107]3.2174,[108]3.2381,[109]3.2746,[110]3.3091,[111]3.3311,[112]3.3003,[113]3.2870,[114]3.2635,[115]3.2465,[116]3.2384,[117]3.2167,[118]3.1937,[119]3.1713,[120]3.1487,[121]3.1329,[122]3.1128,[123]3.0950,[124]3.0722,[125]3.0524,[126]3.0345,[127]3.0218,[128]3.0145,[129]3.0055,[130]2.9943,[131]2.9862,[132]2.9922,[133]2.9999,[134]3.0062,[135]3.0185,[136]3.0349,[137]3.0503,[138]3.0577,[139]3.0696,[140]3.0682,[141]3.0675,[142]3.0642,[143]3.0624,[144]3.0560,[145]3.0458,[146]3.0428,[147]3.0450,[148]3.0424,[149]3.0424,[150]3.0349,[151]3.0310,[152]3.0262,[153]3.0201,[154]3.0184,[155]3.0218,[156]3.0224,[157]3.0273,[158]3.0364,[159]3.0374,[160]3.0464,[161]3.0545,[162]3.0632,[163]3.0686,[164]3.0893,[165]3.1137,[166]3.1324,[167]3.1459,[168]3.1722,[169]3.1956,[170]3.2185,[171]3.2428,[172]3.2243,[173]3.2042,[174]3.1909,[175]3.1779,[176]3.1654,[177]3.1541,[178]3.1408,[179]3.1267,[180]3.1301,[181]3.1442,[182]3.1594,[183]3.1742,[184]3.1882,[185]3.1979,[186]3.2146,[187]3.2298,[188]3.2433,[189]3.2538,[190]3.2533,[191]3.2597,[192]3.2620,[193]3.2666,[194]3.2868,[195]3.2961,[196]3.3094,[197]3.3196,[198]3.3230,[199]3.3280,[200]3.3258,[201]3.3412,[202]3.3351,[203]3.3396,[204]3.3417,[205]3.3418,[206]3.3442,[207]3.3534,[208]3.3635,[209]3.3729,[210]3.3721,[211]3.3663,[212]3.3666,[213]3.3746,[214]3.3760,[215]3.3822,[216]3.3823,[217]3.3756,[218]3.3754,[219]3.3761,[220]3.3743,[221]3.3739,[222]3.3731,[223]3.3745,[224]3.3794,[225]3.3812,[226]3.3714,[227]3.3702,[228]3.3716,[229]3.3757,[230]3.3812,[231]3.3870,[232]3.3788,[233]3.3715,[234]3.3735,[235]3.3734,[236]3.3822,[237]3.3904,[238]3.4001,[239]3.4104,[240]3.4189,[241]3.4301,[242]3.4457,[243]3.4594,[244]3.4676,[245]3.4795,[246]3.4902,[247]3.4876,[248]3.4827,[249]3.4802,[250]3.4725,[251]3.4688,[252]3.4704,[253]3.4731,[254]3.4793,[255]3.4855,[256]3.4890,[257]3.4906,[258]3.4907,[259]3.4927,[260]3.4949,[261]3.4954,[262]3.4931,[263]3.4987,[264]3.5010,[265]3.5011,[266]3.5027,[267]3.5054,[268]3.5099,[269]3.5128,[270]3.5109,[271]3.5089,[272]3.5014,[273]3.5018,[274]3.4945,[275]3.4831,[276]3.4719,[277]3.4732,[278]3.4836,[279]3.4894,[280]3.4974,[281]3.5045,[282]3.5104,[283]3.5171,[284]3.5233,[285]3.5375,[286]3.5392,[287]3.5420,[288]3.5462,[289]3.5486,[290]3.5395,[291]3.5314,[292]3.5335,[293]3.5346,[294]3.5327,[295]3.5317,[296]3.5342,[297]3.5356,[298]3.5404,[299]3.5472,[300]3.5502,[301]3.5536,[302]3.5554,[303]3.5564,[304]3.5546,[305]3.5669,[306]3.5741,[307]3.5855,[308]3.5734,[309]3.5676,[310]3.5575,[311]3.5611,[312]3.5644,[313]3.5713,[314]3.5734,[315]3.5763,[316]3.5771,[317]3.5780,[318]3.5784,[319]3.5792,[320]3.5834,[321]3.5835,[322]3.5852,[323]3.5914,[324]3.5913,[325]3.5967,[326]3.6011,[327]3.6050,[328]3.6073,[329]3.6086,[330]3.6146,[331]3.6183,[332]3.6224,[333]3.6204,[334]3.6199,[335]3.6193,[336]3.6187,[337]3.6194,[338]3.6192,[339]3.6215,[340]3.6248,[341]3.6304,[342]3.6399,[343]3.6496,[344]3.6548,[345]3.6471,[346]3.6407,[347]3.6381,[348]3.6305,[349]3.6265,[350]3.6247,[351]3.6297,[352]3.6453,[353]3.6544,[354]3.6677,[355]3.6766,[356]3.6830,[357]3.6952,[358]3.7059,[359]3.7091,[360]3.7151,[361]3.7246,[362]3.7337,[363]3.7394,[364]3.7462,[365]3.7520,[366]3.7629,[367]3.7718,[368]3.7787,[369]3.7863,[370]3.7948,[371]3.8090,[372]3.8188,[373]3.8216,[374]3.8250,[375]3.8296,[376]3.8427,[377]3.8541,[378]3.8562,[379]3.8550,[380]3.8515,[381]3.8561,[382]3.8620,[383]3.8653,[384]3.8698,[385]3.8737,[386]3.8797,[387]3.8852,[388]3.8884,[389]3.8764,[390]3.8669,[391]3.8562,[392]3.8500,[393]3.8403,[394]3.8315,[395]3.8224,[396]3.8120,[397]3.8024,[398]3.7916,[399]3.7813,[400]3.7720,[401]3.7610,[402]3.7497,[403]3.7400,[404]3.7283,[405]3.7171,[406]3.7060,[407]3.6953,[408]3.6859,[409]3.6767,[410]3.6704,[411]3.6721,[412]3.6675,[413]3.6708,[414]3.6744,[415]3.6716,[416]3.6722,[417]3.6743,[418]3.6686,[419]3.6700,[420]3.6670,[421]3.6655,[422]3.6680,[423]3.6679,[424]3.6724,[425]3.6721,[426]3.6730,[427]3.6723,[428]3.6754,[429]3.6767,[430]3.6800,[431]3.6808,[432]3.6794,[433]3.6754,[434]3.6759,[435]3.6699,[436]3.6642,[437]3.6599,[438]3.6578,[439]3.6563,[440]3.6613,[441]3.6664,[442]3.6743,[443]3.6722,[444]3.6726,[445]3.6734,[446]3.6784,[447]3.6816,[448]3.6841,[449]3.6867,[450]3.6906,[451]3.6941,[452]3.6967,[453]3.6982,[454]3.6964,[455]3.6985,[456]3.6982,[457]3.7008,[458]3.7059,[459]3.7063,[460]3.7060,[461]3.7018,[462]3.7057,[463]3.7133,[464]3.7193,[465]3.7124,[466]3.7106,[467]3.7094,[468]3.7118,[469]3.7091,[470]3.7064,[471]3.7068,[472]3.7077,[473]3.7068,[474]3.7055,[475]3.7070,[476]3.7055,[477]3.7043,[478]3.7053,[479]3.7071,[480]3.7095,[481]3.7052,[482]3.7088,[483]3.7075,[484]3.7110,[485]3.7175,[486]3.7204,[487]3.7238,[488]3.7292,[489]3.7315,[490]3.7362,[491]3.7426,[492]3.7472,[493]3.7465,[494]3.7474,[495]3.7497,[496]3.7512,[497]3.7541,[498]3.7543,[499]3.7532,[500]3.7569,[501]3.7613,[502]3.7604,[503]3.7586,[504]3.7608,[505]3.7641,[506]3.7728,[507]3.7754,[508]3.7785,[509]3.7704,[510]3.7659,[511]3.7599,[512]3.7561,[513]3.7495,[514]3.7488,[515]3.7515,[516]3.7472,[517]3.7477,[518]3.7471,[519]3.7481,[520]3.7532,[521]3.7515,[522]3.7495,[523]3.7557,[524]3.7544,[525]3.7533,[526]3.7488,[527]3.7433,[528]3.7407,[529]3.7373,[530]3.7342,[531]3.7305,[532]3.7239,[533]3.7171,[534]3.7130,[535]3.7146,[536]3.7176,[537]3.7211,[538]3.7247,[539]3.7276,[540]3.7332,[541]3.7369,[542]3.7395,[543]3.7350,[544]3.7308,[545]3.7304,[546]3.7231,[547]3.7171,[548]3.7102,[549]3.7039,[550]3.6979,[551]3.6923,[552]3.6866,[553]3.6810,[554]3.6803,[555]3.6789,[556]3.6814,[557]3.6851,[558]3.6912,[559]3.6956,[560]3.7011,[561]3.6989,
Final estimate: PPL = 3.6989 +/- 0.02106
llama_print_timings: load time = 51361.04 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 2841460.32 ms / 287232 tokens ( 9.89 ms per token, 101.09 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 2844956.64 ms / 287233 tokens
Debugging Crashes
Usually no need to do this, as any asserts will print the line number direclty.
# re-Build with Debugging symbols and CUDA backend enabled
git pull
git checkout ik/prepare_wk_b
cmake -B ./build -DCMAKE_BUILD_TYPE=Debug -DGGML_CUDA=ON -DGGML_BLAS=OFF
cmake --build ./build --config Debug -j $(nproc)
git rev-parse --short HEAD
1324de97
./build/bin/llama-server --version
version: 3594 (1324de97)
built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu
# Run it in gdb
CUDA_VISIBLE_DEVICES="0," \
gdb ./build/bin/llama-server
(gdb) run \
./build/bin/llama-server \
--verbose \
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL \
--model /mnt/raid/models/unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf \
--ctx-size 4096 \
--parallel 1 \
-mla 2 -fa \
-amb 2048 \
-fmoe \
-rtr \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--threads 24 \
--host 127.0.0.1 \
--port 8080
.
CRASH
.
# Print backtrace after it crashes/segfaults
(gdb) bt
.
.
.
TODO
- Enumerate features with examples and links to PRs
- Show specific examples of making your own quants with brief discussion and perplexity comparison
- Benchmark various configurations against llama.cpp@main, llama.cpp w/ experimental branches, and ktransformers.
References
🗣️ Discussion
👤 ubergarm replied the 2025-03-14 at 20:34:10:
@saood06
I trolled through some of the PRs you linked to me and pulled together this rough guide as my notes for getting started with ik_llama.cpp. Thanks for pointing me in the right direction.
The biggest hurdle so far is needing a custom quant for MLA support. I'll work on that another time as I'm using og unsloth UD-Q2_K_XL which fits in this systems 256GB RAM.
My initial impression is with the right settings it can get faster prompt processing than ktransformers and about the same token generation.
Looking forward to trying it with an MLA supported quant.
👤 saood06 replied the 2025-03-15 at 04:08:06:
I trolled through some of the PRs you linked to me and pulled together this rough guide as my notes for getting started with
ik_llama.cpp. Thanks for pointing me in the right direction.Glad I can be of help. I've seen a lot of people show interest in using ik_llama.cpp but the amount of options and the spread out documentation was a deterrent. This guide (even in it's current state) is a much better resource to give people than my explanations and links to PR's, so thank you for putting it together.
The biggest hurdle so far is needing a custom quant for MLA support. I'll work on that another time as I'm using og unsloth
UD-Q2_K_XLwhich fits in this systems 256GB RAM.You seemed to have found all the huggingface MLA quants I know of but I forgot to mention that you can use the technique listed here in order to skip a step if you are going to manually convert from the original fp8 model files. (I've thought about porting that here but the triton dependence adds more complication than I think it is worth for most people, when more fp8 native models are released, I think something along the lines of this is the best path forward).
I think reading through this discussion https://github.com/ikawrakow/ik_llama.cpp/discussions/242 (most relevant bits are this, this, and this but there are other bits of the discussion that are worth reading if you are making your own imatrix as you may run into similar issues, but as mentioned you can just use an imatrix from someone else, just make sure to set the new MLA tensors to high quant types as those won't be in any imatrix unless they created it with MLA.
Making a custom quant has a lot of flexibility in terms of quality, size, and performance (for example the quant of the attention tensors and shared experts has much lower impact on size, but has larger impacts on quality and size, whereas the quant of the non-shared experts has a much larger impact on size, and a smaller impact on performance). This is demonstrated here where the custom blend that is smaller had lower PPL than the IQ4_KSS quant. There is a lot more discussion about quants in that thread (and it is where the issue of CUDA for certain tensors was first noticed).
My initial impression is with the right settings it can get faster prompt processing than ktransformers and about the same token generation.
Looking forward to trying it with an MLA supported quant.
I think ktransformers will outperform ik_llama.cpp without MLA for TG at higher context lengths as it uses MLA. The higher PP is nice, I wonder if the lead is still held with MLA.
Also you may find https://github.com/ikawrakow/ik_llama.cpp/pull/225 useful for benchmarking.
👤 magikRUKKOLA replied the 2025-07-13 at 22:39:43:
@saood06 please keep in mind that there is no such thing as comparing the performance of ik_llama.cpp with ktransformers. Simply because the ktransformers is using old fork of flashinfer (see 0.2.3). If simply put, you will get either crash in the sampler or the garbage output (or lost context). Yeah, I initially thought ik_llama.cpp suck because the decode speed is slower (esp. on a long context because they dont't use matrix absorption etrc.) .. but ... there is simply no way to run ktransformers with large context. ktransformers doesn't even have the --seed parameter implemented lol so each time the llm answers you you can't tell if its a right answer or its a garbage lol. ktransformers was written by script-kiddies (I looked at the code -- its awful). So please be serious.👤 saood06 replied the 2025-07-13 at 22:52:02:
@saood06 please keep in mind that there is no such thing as comparing the performance of ik_llama.cpp with ktransformers. [...] So please be serious.
Not sure why you are replying to old comments. I said in a later comment in this same discussion page, "Even then and still now I still see ktransformers as more of a performance demo because of how limited it is in what it supports both in hardware and the server/API they expose."
👤 magikRUKKOLA replied the 2025-07-13 at 23:30:53:
@saood06 please keep in mind that there is no such thing as comparing the performance of ik_llama.cpp with ktransformers. [...] So please be serious.
Not sure why you are replying to old comments. I said in a later comment in this same discussion page, "Even then and still now I still see ktransformers as more of a performance demo because of how limited it is in what it supports both in hardware and the server/API they expose."
Well, you didn't say that ktransformers ARE unusable. I am saying that.
Its not about the stuff that it supports or not. The problem is that they claiming to support 128k context when in reality it just crashes or outputs the garbage. So anyone reading this thread should be aware to not waste any time with ktransformers. That's it.
👤 ikawrakow replied the 2025-03-15 at 09:16:27:
Thank you for these results.
The biggest hurdle so far is needing a custom quant for MLA support
#259 should remove this hurdle. With this PR models prepared with mainline llama.cpp can be used also with MLA enabled.
👤 saood06 replied the 2025-03-16 at 03:37:18:
# Results for unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf # was getting nan's even without -mla 2 -fa -amb 2048 -fmoe. switched to default --ubatch-size 512 and nan's appear later in the sequence
Just thought you'd want to know this, manually notifying you as edit's don't trigger notifications.
👤 ubergarm replied the 2025-03-16 at 03:58:21:
Yeah I managed to cobble together a quantize script and create my first quantIQ2_K_R4weighing in at179Gand slightly higher perplexity thatUD-Q2_K_XLat212Gcomparing across the first 10 perplexity data points. I saw a note aboutnanover here too on this huggingface unsloth R1-GGUF discussion (can't compare against those charts as they use a custom txt file and notwiki.test.raw). The new quant at 32k context took an 8k prompt at ~63 tok/sec pp and gave ~11.3 tok/sec tg.Now that I see how it works better I'm rolling another one with more
q8_0s for the less frequent layers and targeting under 256GB RAM system. At least I have enough perplexity data points to compare across these specific quants.The other thing I need to dig into more is what combination of
-ctkand-ctvwork with what mla/amb/fmoe/fa settings. I noticed-ctk q8_0 -ctv q8_0works with-mla 2 -fa -amb 2048 -fmoeand allows 32k context to fit in 24GB VRAM comfortably. However, tryingq8_KVandiq4_nltypes segfaulted (didn't grab a backtrace, might be a known invalid combination).Made a lot of progress today! Hope to move on to making a CPU only optimized quant for the Intel 6980P to try (e.g. exps around
q6_k_r4or whatever repacked quant types might be good combo of high quality and reasonably fast assuming plenty of RAM.👤 saood06 replied the 2025-03-16 at 04:43:23:
Yeah I managed to cobble together a quantize script and create my first quant
IQ2_K_R4weighing in at179Gand slightly higher perplexity thatUD-Q2_K_XLat212Gcomparing across the first 10 perplexity data points.I saw that and was about to write a separate comment to you, but wanted to alert ikawrakow about the NaNs first, so I'll just reply to you in this comment.
I saw a note about
nans over here too on this huggingface unsloth R1-GGUF discussion (can't compare against those charts as they use a custom txt file and notwiki.test.raw).Thank you so much for linking that to me. I don't think there is any mention of this in llama.cpp issues/PR's (it may have occurred in the discussions as I haven't followed that as closely), but there really should be. The only thing similar is the issues jukofyork reported with numerical instability.
Now that I see how it works better I'm rolling another one with more
q8_0s for the less frequent layers and targeting under 256GB RAM system. At least I have enough perplexity data points to compare across these specific quants.Are you also going to be maximizing the GPU VRAM? You mentioned 36GiB VRAM used of 48GB for your card. Also I know I could do the math, but what context size was reported there (I think it should be included in the snippet as KV size is based on context size). Also Q8_K_R8 and Q8_K exist and may be useful to you.
The other thing I need to dig into more is what combination of
-ctkand-ctvwork with what mla/amb/fmoe/fa settings. I noticed-ctk q8_0 -ctv q8_0works with-mla 2 -fa -amb 2048 -fmoeand allows 32k context to fit in 24GB VRAM comfortably. However, tryingq8_KVandiq4_nltypes segfaulted (didn't grab a backtrace, might be a known invalid combination).As far as I'm aware q8_KV is not supported for CUDA with FlashMLA (q8_0 was added here: https://github.com/ikawrakow/ik_llama.cpp/pull/252) . This PR: https://github.com/ikawrakow/ik_llama.cpp/pull/240 lists combinations supported for CPU (but not sure if that applies to all combinations of -mla and -fa).
Made a lot of progress today!
Yes, it is fun to keep up with. I've been sidetracked with using QwQ-32B but I really want to try out a lot of the Deepseek optimizations ( and also get my RPC sync PR finished which should allow me to run more models and more configurations (such as quantized KV cache) with RPC as that is my best option for performance given my hardware.
Hope to move on to making a CPU only optimized quant for the Intel 6980P to try (e.g. exps around
q6_k_r4or whatever repacked quant types might be good combo of high quality and reasonably fast assuming plenty of RAM.There is q6_k_r4 and iq6_k but no iq6_k_r4. I'm curious how quickly that system can generate quants as your current testing already makes quants at atleast double the speed mine does (a bit over 4 hours per quant).
wtf was: --ignore-imatrix-rules TODO: maybe grep the code?
The code for it is here.
is there a "dry-run" to calculate/show sizes of everything before actually doing it?
There is not.
👤 ubergarm replied the 2025-03-16 at 15:45:41:
I don't think there is any mention of this in llama.cpp issues/PR's Yeah, doing research in 2025 is a mind bending exercise in digging through subreddit comments, hugging face discussions, github PRs, and right I didn't even realize github "discussions" was a thing until a couple weeks ago lol.
But to the point, yeah seems like
nanwhen computing perplexity with R1 is a known issue for vanilla llama-perplexity as well and not specific to this fork from what I can tell.Are you also going to be maximizing the GPU VRAM? You mentioned 36GiB VRAM used of 48GB for your card.
This rig actually has 2x 48GB A6000's in it, but only testing with one most of the time as I'd like to find a good configuration that will run locally on my personal 3090TI rig in under 24GB VRAM. It has been cool to try
QwQ-32Bwith-tp 2on sglang and vllm (sglang was slightly faster, both over 50 tok/sec using both GPUs). It runs around 30 tok/sec on my local rig in single 3090.what context size was reported there
Now that dynamic MLA stuff seems to be working, I need to update my examples. psure it was 64k context with fp16 for kv iirc... 32k with q8_0 kv cache quants fits into 24GB VRAM nicely so far.
my RPC sync PR
Interesting, I'll have to take a look to see what you're up to. I have a small patch to vanilla llama.cpp RPC server to add number of threads to configuration. I was trying to launch 1x RPC server for each NUMA node. It "worked" but was much slower than just paying the NUMA penalty.
a bit over 4 hours per quant
Thanks for the info, the most recent quant I rolled last night took about 3.2 hours, so I guess it depends on the exact configuration. I don't know if the Dual Intel 6980P has enough disk space lol...
I appreciate all your guidance and quality feedback!
👤 saood06 replied the 2025-03-17 at 03:26:23:
Yeah, doing research in 2025 is a mind bending exercise in digging through subreddit comments, hugging face discussions, github PRs, and right I didn't even realize github "discussions" was a thing until a couple weeks ago lol.
I'm curious how you found out about ik_llama.cpp then. I wouldn't have mentioned it to you on the llama.cpp discussion if you hadn't (but probably still would have in your r1-ktransformers-guide as you mentioned other inference engines), but I agree the state of research (there apparently is stuff on twitter/x but I've never really touched that platform besides people referencing it on other platforms). There are also forums and other places as well that I used to check out but not really so much anymore.
But to the point, yeah seems like
nanwhen computing perplexity with R1 is a known issue for vanilla llama-perplexity as well and not specific to this fork from what I can tell.I still think an issue should be raised on llama.cpp about it, but I don't feel like doing it (especially as I haven't reproduced it myself).
This rig actually has 2x 48GB A6000's in it, but only testing with one most of the time as I'd like to find a good configuration that will run locally on my personal 3090TI rig in under 24GB VRAM.
That might be useful for me as well once RPC is working as I have a 3090 on my desktop to use with the server with 384GB of RAM. There does seem to be an issue where only one GPU might be used anyway according to this.
It has been cool to try
QwQ-32Bwith-tp 2on sglang and vllm (sglang was slightly faster, both over 50 tok/sec using both GPUs). It runs around 30 tok/sec on my local rig in single 3090.I haven't bothered to make a custom quant of it yet as I have with some other finetunes of Qwen-32B (including ones that used QwQ-32B preview). How have you liked it so far? For me it seems not much better for a lot of the tasks I prefer using a local LLM for than QwQ-32B preview (for convenience I've been using some free services offering R1 for other tasks). I only really like the speed as ~30t/s is a lot nicer than ~3t/s for local R1, but it is annoyingly stupid and the thought sections aren't as useful or steerable as with R1 from my experience with both. If I could run R1 faster QwQ would have no purpose to me.
Interesting, I'll have to take a look to see what you're up to.
You can take a look here: https://github.com/ikawrakow/ik_llama.cpp/pull/193 , but it is basically to pull in this change https://github.com/ggml-org/llama.cpp/pull/11047 which is needed for Deepseek-R1, Qwen-72B, quantized caches, etc. I left some code comments of where it doesn't work, and my next test whenever I get around to it would be to comment out the
if (tensor == nullptr)block and add change theif (tensor->buffer == nullptr)toif (tensor == nullptr || tensor->buffer == nullptr)and hope that fixes it, and if not I'll have to actually understand what ik_llama.cpp is doing that causes this issue when llama.cpp doesn'tI have a small patch to vanilla llama.cpp RPC server to add number of threads to configuration. I was trying to launch 1x RPC server for each NUMA node. It "worked" but was much slower than just paying the NUMA penalty.
I saw that, it dissapointed me, since if it had worked you could unconsolidate the expert tensors and then get expert parallelism, but now I know that is a dead end until the RPC code gets overhauled to be async.
Thanks for the info, the most recent quant I rolled last night took about 3.2 hours, so I guess it depends on the exact configuration. I don't know if the Dual Intel 6980P has enough disk space lol...
Oh ya, I kinda forgot that as I generally tend to IQK quants which take a while to make. If you look into how each quant type is made you'll see how compute intensive what each quant type is doing would be and thus how much time it would take, some quants do very little compute while others require a lot.
Perplexity
A bit sad to see the full perplexity numbers gone from your guide, I think (not at all sure though) the values printed by the perplexity command are already a some sort of running average as I noticed the last value is always the same as the final estimate.
also some quants give nan results even on vanilla llama.cpp
I still think this is indicative of a problem, as I've only seen this reported for Deepseek-R1, and I think generally a NaN result means the quant is broken or something is going wrong with the model implementation, and in this case I think it is the latter.
I appreciate all your guidance and quality feedback!
I'm happy to do it, since I appreciate your guide and benchmarking.
👤 ubergarm replied the 2025-03-17 at 20:36:43:
@saood06I'm curious how you found out about ik_llama.cpp then.
I was trying to track some llama.cpp experimental branches and saw a comment about this fork. I followed the trail and here we are lol. Yeah I don't mess with twitter stuff either.
I still think an issue should be raised on llama.cpp about it, but I don't feel like doing it (especially as I haven't reproduced it myself)
I'm checking to see if the three unsloth quants I have on the intel6980P CPU only rig throw
nanwith vanilla llama.cpp. If I can repo it there, then I'll check and possibly report. Though I'm out most of this tues/weds.How have you liked [QwQ-32B] so far?
I agree the speed is nice, especially for such a long rambling thinker haha... When prompted well it seems to perform surprisingly good for its size. However, I still prefer
R1-UD-Q2_K_XLas it seems to write better prose.A bit sad to see the full perplexity numbers gone from your guide, I think (not at all sure though) the values printed by the perplexity command are already a some sort of running average as I noticed the last value is always the same as the final estimate.
Oh sorry, I have that stuff in local logs but switched to the visual chart .png image to try to keep this "guide" less spammy haha... Yeah, its unclear to me if that total value it prints out (if no nans occur) is simply an average for each chunk or some other calculation, I didn't look that closely. I realize I was using
-mla 2and-ctk/ctv q8_0for these calculations which is not a valid combination yet I just learned today. So take it with a grain of salt. --- I added another detail drop down with some full perplexity run logs if that is useful to you. Also just saw #261 to help withnanpsure.One other thing, I'm fussing a bit to see if it is possible to still use
mmap()when using-ot exps=CPU? Just realized using tensor overrides disablesmmap(). So I can't actually try my sweet new quant locally on the 9950X 96GB RAM. Somehow ktransformers--optimize_config_path optimize_rules/DeepSeek-V3-Chat.yamlregex seems to still allowmmap()for the non-GPU tensors.Finally, I'm still scratching my head a bit about the whole CUDA graphs stuff. I probably have to dig more into ktransformers code to see exactly what they are talking about there as using
ktransformers --no-use_cuda_graphdefinitely slows it down about 50%...👤 saood06 replied the 2025-03-17 at 22:13:36:
I'm checking to see if the three unsloth quants I have on the intel6980P CPU only rig throw
nanwith vanilla llama.cpp. If I can repo it there, then I'll check and possibly report. Though I'm out most of this tues/weds.Thanks, sorry for not wanting to make the issue myself even though I want the issue made.
I agree the speed is nice, especially for such a long rambling thinker haha... When prompted well it seems to perform surprisingly good for its size. However, I still prefer
R1-UD-Q2_K_XLas it seems to write better prose.It is good for it's size, but ya I feel the same about R1 (IQ4_K_R4 for me though), as besides QwQ-32B's tendency to make mistakes that show it's holes in world modeling (it's not just unlucky token selection as I look into the token probabilities and also often slightly tweak right before the mistake with some hints and regenerate it and it will often repeat the same mistakes), the prose is lacking compared to R1.
Oh sorry, I have that stuff in local logs but switched to the visual chart .png image to try to keep this "guide" less spammy haha...
I also think the visual chart is far better for the guide, it's just personally I'm curious about full PPL runs. I should have made that clear earlier, sorry.
Yeah, its unclear to me if that total value it prints out (if no nans occur) is simply an average for each chunk or some other calculation, I didn't look that closely.
I wish I could give you a better answer so that people looking at the chart could be more informed, but I still don't really know other than the fact that it looks like some kind of running average as the values change a lot early and then very little late with the final chunk number being the final estimate.
I realize I was using
-mla 2and-ctk/ctv q8_0for these calculations which is not a valid combination yet I just learned today. So take it with a grain of salt.I saw ikawrakow said "it will terminate when it arrives at the op that is not supported on CUDA for quantized data", but it completed the full ppl run, so take that as you will.
One other thing, I'm fussing a bit to see if it is possible to still use
mmap()when using-ot exps=CPU? Just realized using tensor overrides disablesmmap().That was mentioned in the PR that implemented tensor override here "The PR is still a bit rough around the edges (not much error handling, mmap gets disabled for the tensors with buffer type override, etc.), but throwing it out there to get feedback." , I barely tested the llama.cpp implementation so not sure if it shares that limitation
So I can't actually try my sweet new quant locally on the 9950X 96GB RAM. Somehow ktransformers
--optimize_config_path optimize_rules/DeepSeek-V3-Chat.yamlregex seems to still allowmmap()for the non-GPU tensors.Interesting, but it makes sense as the whole point of ktransformers is for flexibility as they do some but not that much implementation themselves and just have a framework of allowing you to mix and match implementations.
Finally, I'm still scratching my head a bit about the whole CUDA graphs stuff. I probably have to dig more into ktransformers code to see exactly what they are talking about there as using
ktransformers --no-use_cuda_graphdefinitely slows it down about 50%...I may be wrong but I think that's because they use specialized kernels designed around cuda graphs, and for llama.cpp/ik_llama.cpp CUDA graphs is a meaningful but small optimization.
I added another detail drop down with some full perplexity run logs if that is useful to you.
Thank you, sorry again for not being clear about it being something I was curious about and not something that is that useful to the guide.
Also just saw https://github.com/ikawrakow/ik_llama.cpp/pull/261 to help with nan psure.
That is for his custom quant types IQ_K quants (https://github.com/ikawrakow/ik_llama.cpp/discussions/8), the nans in unsloth's quant won't be helped by that.
👤 ubergarm replied the 2025-03-19 at 22:59:19:
I'm curious about full PPL runs.
Yeah, looking more I see the full run is more useful for easy comparisons than just the first N chunks.
That is for his custom quant types IQ_K quants (https://github.com/ikawrakow/ik_llama.cpp/discussions/8), the nans in unsloth's quant won't be helped by that.
I see. Are you aware of other quants that throw
nanon CPU backends? Because, I've been trying to run perplexity on unsloth/DeepSeek-R1-Q8_0 as theQ8_0would make a nice baseline for comparison. However, on the intel6980P compiled for CPU only its throwing allnan. Right, the recent the recent PR fixesIQ_Kquants on CUDA.It runs the
Q4_K_Mclean to the end, so maybeQ8_0only?There were no nans running it with vanilla
llama.cpp@mainearlier this week. I tried a lot of things withik_llama.cppllama-perplexityincluding various options combinations, not using-rtr, exact same command as vanilla, and different git sha's from today through a few days ago. No luck.See here for exact logs. Let me know if you think I should open an issue or of maybe just user error?
`ik_llama.cpp llama-perplexity` logs.
$ numactl -N 0 -m 0 \ ./build/bin/llama-perplexity \ --model /mnt/ai/models/unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf \ -rtr \ -ctk q8_0 \ -mla 2 -fa \ -amb 512 \ -fmoe \ --ctx-size 512 \ --ubatch-size 512 \ -f wiki.test.raw \ --numa numactl \ --threads 128 # also similar results on `ik_llama.cpp@f2fb15de` without fancy options etc. main: build = 3597 (127c6ee6) 20:14:51 [199/1921] main: built with cc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0 for x86_64-linux-gnu main: seed = 1742415291 WARNING: /proc/sys/kernel/numa_balancing is enabled, this has been observed to impair performance llama_model_loader: additional 14 GGUFs metadata loaded. llama_model_loader: loaded meta data with 48 key-value pairs and 1025 tensors from /mnt/ai/models/unsloth/DeepSeek-R1-GGUF/DeepSeek-R1-Q8_0/DeepSeek-R 1.Q8_0-00001-of-00015.gguf (version GGUF V3 (latest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek R1 BF16 llama_model_loader: - kv 3: general.quantized_by str = Unsloth llama_model_loader: - kv 4: general.size_label str = 256x20B llama_model_loader: - kv 5: general.repo_url str = https://huggingface.co/unsloth llama_model_loader: - kv 6: deepseek2.block_count u32 = 61 llama_model_loader: - kv 7: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 8: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 9: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 10: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 11: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 12: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 13: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 14: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 15: general.file_type u32 = 7 llama_model_loader: - kv 16: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 17: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 18: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 19: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 20: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 21: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 22: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 23: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 24: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 25: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 26: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 27: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 28: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 29: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 30: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 31: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 32: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 33: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 34: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 35: tokenizer.ggml.tokens arr[str,129280] = ["<|begin▁of▁sentence|>", "<... llama_model_loader: - kv 36: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 37: tokenizer.ggml.merges arr[str,127741] = ["Ġ t", "Ġ a", "i n", "Ġ Ġ", "h e... llama_model_loader: - kv 38: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 39: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 40: tokenizer.ggml.padding_token_id u32 = 128815 llama_model_loader: - kv 41: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 42: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 43: tokenizer.chat_template str = {% if not add_generation_prompt is de... llama_model_loader: - kv 44: general.quantization_version u32 = 2 llama_model_loader: - kv 45: split.no u16 = 0 llama_model_loader: - kv 46: split.count u16 = 15 llama_model_loader: - kv 47: split.tensors.count i32 = 1025 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 664 tensors llm_load_vocab: special tokens cache size = 819 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = Q8_0 llm_load_print_meta: model params = 671.026 B llm_load_print_meta: model size = 664.295 GiB (8.504 BPW) llm_load_print_meta: repeating layers = 662.461 GiB (8.504 BPW, 669.173 B parameters) llm_load_print_meta: general.name = DeepSeek R1 BF16 llm_load_print_meta: BOS token = 0 '<|begin▁of▁sentence|>' llm_load_print_meta: EOS token = 1 '<|end▁of▁sentence|>' llm_load_print_meta: PAD token = 128815 '<|PAD▁TOKEN|>' llm_load_print_meta: LF token = 131 'Ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.42 MiB llm_load_tensors: CPU buffer size = 680237.97 MiB .................................................................................................... ============ llm_load_tensors: need to compute 61 wk_b tensors Computed blk.0.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.1.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.2.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.3.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.4.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.5.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.6.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.7.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.8.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.9.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.10.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.11.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.12.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.13.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.14.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.15.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.16.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.17.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.18.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.19.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.20.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.21.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.22.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.23.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.24.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.25.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.26.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.27.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.28.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.29.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.30.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.31.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.32.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.33.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.34.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.35.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.36.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.37.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.38.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.39.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.40.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.41.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.42.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.43.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.44.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.45.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.46.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.47.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.48.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.49.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.50.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.51.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.52.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.53.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.54.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.55.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.56.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.57.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.58.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.59.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU Computed blk.60.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CPU ============ Repacked 663 tensors llama_new_context_with_model: n_ctx = 2048 llama_new_context_with_model: n_batch = 2048 llama_new_context_with_model: n_ubatch = 512 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 2 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: layer 0: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 1: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 2: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 3: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 4: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 5: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 6: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 7: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 8: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 9: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 10: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 11: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 12: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 13: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 14: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 15: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 16: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 17: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 18: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 19: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 20: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 21: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 22: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 23: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 24: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 25: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 26: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 27: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 28: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 29: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 30: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 31: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 32: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 33: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 34: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 35: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 36: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 37: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 38: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 39: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 40: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 41: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 42: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 43: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 44: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 45: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 46: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 47: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 48: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 49: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 50: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 51: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 52: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 53: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 54: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 55: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 56: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 57: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 58: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 59: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: layer 60: n_embd_head_qk_rope = 64, kv_lora_rank = 512 llama_kv_cache_init: CPU KV buffer size = 72.91 MiB llama_new_context_with_model: KV self size = 72.91 MiB, c^KV (q8_0): 72.91 MiB, kv^T: not used llama_new_context_with_model: CPU output buffer size = 1.97 MiB llama_new_context_with_model: CPU compute buffer size = 450.01 MiB llama_new_context_with_model: graph nodes = 3487 llama_new_context_with_model: graph splits = 1 system_info: n_threads = 128 / 512 | AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | AVX512_BF16 = 1 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 | perplexity: tokenizing the input .. perplexity: tokenization took 888.249 ms perplexity: calculating perplexity over 561 chunks, n_ctx=512, batch_size=2048, n_seq=4 perplexity: 14.92 seconds per pass - ETA 34.85 minutes [1]nan,[2]nan,[3]nan,[4]nan,[5]nan,[6]nan,[7]nan,[8]nan,[9]nan,[10]nan,[11]nan,[12]nan,[13]nan,[14]nan,[15]nan,[16]nan,[17]nan,[18]nan,[19]nan,[20]nan ,[21]nan,[22]nan,[23]nan,[24]nan,[25]nan,[26]nan,[27]nan,[28]nan,[29]nan,[30]nan,[31]nan,[32]nan,[33]nan,[34]nan,[35]nan,[36]nan,[37]nan,[38]nan,[39]n an,[40]nan,[41]nan,[42]nan,[43]nan,[44]nan,[45]nan,[46]nan,[47]nan,[48]nan,[49]nan,[50]nan,[51]nan,[52]nan,[53]nan,[54]nan,[55]nan,[56]nan,[57]nan,[58 ]nan,[59]nan,[60]nan,[61]nan,[62]nan,[63]nan,[64]nan,[65]nan,[66]nan,[67]nan,[68]nan,[69]nan,[70]nan,[71]nan,[72]nan,[73]nan,[74]nan,[75]nan,[76]nan,[ 77]nan,[78]nan,[79]nan,[80]nan,[81]nan,[82]nan,[83]nan,[84]nan,[85]nan,[86]nan,[87]nan,[88]nan,[89]nan,[90]nan,[91]nan,[92]nan,[93]nan,[94]nan,[95]nan ,[96]nan,[97]nan,[98]nan,[99]nan,[100]nan,^CThat was mentioned in the PR that implemented tensor override here
Another recent PR allows for
mmap()now so I got my quant running locally around 3 tok/sec. Get almost 4.5 when playing aroun with-ser 5,1- hope to do some perplexity testing with other-sersettings for comparison. More fun stuff!👤 vaulter replied the 2025-03-20 at 01:24:37:
Hi Guys, I've been struggling on my dual Xeon 8558 (48cores) with 768Gb RAM and Quad 3090 with Q8 (that is on lamma.cpp mainline, Q4_K_S gives me 6-7 tk/s in real world prompting) - gives me nan's, can you recommend and help to create custom quants for my situation? I would like to get best performance and ik_llama.cpp seems on the edge, I've been following this thread but might get lost in details calculating and applying custom quants logic...👤 ubergarm replied the 2025-03-20 at 03:06:51:
@vaulterI've been struggling on my dual Xeon 8558 (48cores) with 768Gb RAM and Quad 3090 with Q8
Heya, so assuming you have set BIOS to
SNC=Disableto get a single NUMA node per CPU socket that means you have 2x NUMA nodes each with 384 GB RAM plus 96GB VRAM. So unfortunately, not enough RAM to runQ8_0in a single NUMA node. On AMD Epyc using two NUMA nodes gives barely any performance benefit and in my testing with CPU only inference on Intel Xeon gives a performance regression in token generation benchmarks.Also you don't have enough RAM to run ktransformers compiled with
USE_NUMA=1which enables "data parallel" to load the entire model weights into memory twice (once for each CPU socket's NUMA node). Not efficient, but the main way to get around the issue being explored in implementation that I have seen.So your best bet is probably as follows:
- use
ik_llama.cpp- roll a custom quant to take advantage of your 96GB VRAM and offload the rest fitting into a single 384GB RAM NUMA node.
- come up with a command to do custom tensor offload of your custom quant to distribute the layers across the 4x GPUs VRAM and 1x NUMA node RAM.
To start out I'd recommend simply trying to run your existing
Q4_K_Swithik_llama.cpplooking at the first example quick start in this guide and use only a single GPU at first to get some quick success. You can use a single NUMA node by adding this to the beginning of the command so something like this all together:CUDA_VISIBLE_DEVICES="0," \ numactl -N 0 -m 0 \ ./build/bin/llama-server \ --alias somequant/DeepSeek-R1-Q4_K_S \ --model /models/somequant/DeepSeek-R1-Q4_K_S.gguf \ -rtr \ --ctx-size 32768 \ -ctk q8_0 \ -mla 2 -fa \ -amb 512 \ -fmoe \ --n-gpu-layers 63 \ --override-tensor exps=CPU \ --parallel 1 \ --numa numactl \ --threads 48 \ --host 127.0.0.1 \ --port 8080 # if you get assert error after `============ llm_load_tensors: need to compute 61 wk_b tensors` # git checkout 68a5b604 # and try with that versiongives me nan's
This is with
Q8_0and vanillallama.cpp@main?? When doingllama-perplexityor when do you see nan's?Okay, holler if you get stuck and looking forward to hearing your results! Also feel free to chat about how to make quants, I put some rough notes in this guide where I'm stumbling through the process myself haha...
👤 vaulter replied the 2025-03-20 at 04:47:15:
Well, assuming nan is a token with a single D (basically the output is DDDDD...) - I'm using vannilla llama.cpp@main the same way as with Q4_K_S, it loads, and start outputting D's with out any errors, after I close session it give me tok/s stats, prompt eval is also low vs Q4_K_S at around 0,57 tok/s As for the ik_llama.cpp I'll try and report the results And I was following your other threads with Granit rapids testing - that was really helpful - so thanks for that work! @ubergarm👤 vaulter replied the 2025-03-23 at 14:04:43:
Ok here is a bit of testing - I was getting around 6-6.7 tok/s on vanilla llama and achieved 10.8 tok/s on ik_llama on 8192 context. That is Q4_K_S. I was getting assert errors so had to checkout the given branch. Currently I've done exact instructions besides I didnt isolate to 1 3090 but used all 4 - anyways its offloads whatever (not expert layers as these are CPU override) at around 11Gb on each GPUs - I'm looking in trying a single CPU 4677 motherboard with 2 dimms per channel - this will give me 768GB but for 1 NUMA node and I probably can try Q8 on it
👤 saood06 replied the 2025-03-20 at 01:47:18:
Are you aware of other quants that throw nan on CPU backends?
None that still do that haven't been mentioned in the conversation already, there was an issue with IQ1_S_R4 but that was fixed here: https://github.com/ikawrakow/ik_llama.cpp/pull/194
Let me know if you think I should open an issue or of maybe just user error?
Everything looks reasonable to me (especially since you were thorough and tried a bunch of valid combinations, and any valid combination shouldn't NaN on perplexity, but since all of them do that might help narrow down where the problem lies).
Another recent PR allows for mmap() now so I got my quant running locally around 3 tok/sec. Get almost 4.5 when playing aroun with -ser 5,1 - hope to do some perplexity testing with other -ser settings for comparison. More fun stuff!
Nice.
👤 saood06 replied the 2025-03-21 at 07:32:24:
This is an experimental quant I rolled with q8_0 for all attention/shared experts/embeddings loaded on GPU. The rest of the MoE down exps are iq2_xs_r4 and gate/up exps are iq2_bn_r4. However, perplexity looks pretty bad. So I'll likely aim for larger sized model with higher quality quants and make-up speed/accuracy trade off exploring -ser instead of going very small quants.
I don't think it's the size that is the issue, iq2_bn_r4 is a bitnet quant. I briefly tested an IQ1_S_R4 which didn't even have the benefit of going to q8_0 for the non expert tensors like you did and I still got FAR more reasonable perplexity numbers (exact values here, with the quant log here )
If you are still experimenting with quant types, you might be able to improve on your Q2_K_R4 at around the same size by replacing the q2_k_r4, and q3_k_r4 which are k quants with similar sized i quants or iqk quants instead of using k quants, this PR https://github.com/ikawrakow/ik_llama.cpp/pull/85 has a really nice chart focusing on that quant range (caveat IQ3_KL is not a quant type, it is a quant recipe), and shows how the three different quant types (i, k and iqk) stack up.
👤 ubergarm replied the 2025-03-21 at 15:38:10:
iq2_bn_r4 is a bitnet quant
I saw a few small bitnet quants and wanted to try it out. Okay so its not the size but the bitnet quants are not great for non bit-net trained models. Good to know!
q2_k_r4, and q3_k_r4 which are k quants with similar sized i quants or iqk quants
My first attempt was i quants, which are indeed quite small but seem be more CPU intensive on generation. I see, the
iqk"non-linear" quants in the PR 85 are probably the best bang for the bit assuming I am patient enough to generate the quant. Yeah I'll do another iteration on my custom quant then with these!Thanks for taking the time to explain with references, really appreciate it!
👤 ubergarm replied the 2025-03-21 at 16:39:43:
Okie I'm cooking up one targeting a 256GB RAM + ~24GB VRAM system with-ot exps=CPU:CPU Optimized MoE Tensors
ffn_down_exps=iq3_k_r4 ffn_gate_exps=iq2_k_r4 ffn_up_exps=iq2_k_r4GPU Offload Tensors
Everything else is full
q8_0which with-mla 2 -fa -amb 512still fits 32k context in under 24GB VRAM.I may try another one like this knocking the
gate/upTensors smaller to thatIQ1_M_R4or evenIQ1_S_R4to see how perplexity looks and speed on my local 9950X + 96GB RAM rig.Then I could compare against the bigger model with
-ser 6,1perplexity and speed vs the smaller model. A lot of knobs to play with and optimize.👤 saood06 replied the 2025-03-23 at 01:09:20:
I see you made the IQ2_K_R4 quant, the ppl seems about the same, but performance is a bit confusing as the initial ETA is lower for IQ2_K_R4, but the Q2_K_R4 ETA was higher but it ended up finishing quicker than estimated making it faster.Any system load or anything that would cause that?
👤 ubergarm replied the 2025-03-23 at 14:39:38:
@saood06Wow, good eyes! I was wondering the same thing myself.
model size down/gate&up perplexity ETA duration name GiB quants ppl minutes minutes DeepSeek-R1-Q2_K_R4 239 q3_k_r4/q2_k_r4 3.6975 51.82 44.17 DeepSeek-R1-IQ2_K_R4 227 iq3_k_r4/iq2_k_r4 3.6989 47.62 47.42 Yeah, I too was surprised the slightly larger Q2 seems to have finished faster than the IQ2. I don't think there was any background system load.
I'll need to run some
llama-benchto test pp/tg across various context sizes for both and see how they perform. Both seem quite good if can be compared against mainline perplexity calculation forQ8_0of 3.3490.I may end up using
-ser 6,1or similar on my local rig as that seems to give better perplexity/speed than going down to smaller quant sizes.Waiting for the Qwen to drop an MoE with MLA that an
iq4_k_r4quant will fit into 96GB RAM + 24GB VRAM lmao... 🤞Will keep you posted when I run some benchmarks!
👤 ikawrakow replied the 2025-03-23 at 14:47:08:
PP performance is not really correlated with model size. TheIQX_Kquants are somewhat slower than k-quants for prompt processing (unpacking them to be ready for dot products is more involved). They are quite a bit faster than similarly sized i-quants (IQ2_XXS,IQ2_XS,IQ3_S, etc.) for PP and TG on the CPU. Here you are getting the same PPL as a model that is 5% larger, so that's pretty good.👤 saood06 replied the 2025-03-23 at 14:51:46:
Waiting for the Qwen to drop an MoE with MLA that an
iq4_k_r4quant will fit into 96GB RAM + 24GB VRAM lmao... 🤞Does WizardLM-2-8x22B or any other 8x22B interest you as that could fit, and someone tried it (albeit on llama.cpp) here and got good results.
Will keep you posted when I run some benchmarks!
Thanks, I periodically check on this page as github doesn't notify on edits.
👤 ubergarm replied the 2025-03-23 at 16:00:02:
I ran a quick comparison between theQ2_K_R4and theIQ2_K_R4which do seem like the better choices for CPU inferencing overIQ2_XSand family.For this specific config seems like pp is slightly slower but tg is slightly faster! With basically the same perplexity and 5% smaller, these non-linear
IQ?_K_R4do seem like a great choice for CPU inferencing.
model size test t/s Q2_K_R4 238.69 GiB pp512 112.21 ± 0.74 Q2_K_R4 238.69 GiB pp8192 97.59 ± 1.21 Q2_K_R4 238.69 GiB pp16384 83.55 ± 1.56 Q2_K_R4 238.69 GiB tg64@pp512 10.05 ± 0.00 Q2_K_R4 238.69 GiB tg64@pp8192 8.97 ± 0.01 Q2_K_R4 238.69 GiB tg64@pp16384 7.93 ± 0.01 --------------------- ------------: ---------------: IQ2_K_R4 226.00 GiB pp512 105.33 ± 0.46 IQ2_K_R4 226.00 GiB pp8192 93.17 ± 0.70 IQ2_K_R4 226.00 GiB pp16384 81.67 ± 1.51 IQ2_K_R4 226.00 GiB tg64@pp512 10.32 ± 0.00 IQ2_K_R4 226.00 GiB tg64@pp8192 9.16 ± 0.02 IQ2_K_R4 226.00 GiB tg64@pp16384 8.10 ± 0.02 👤 saood06 replied the 2025-03-23 at 16:14:16:
With basically the same perplexity and 5% smaller, these non-linear IQ?_K_R4 do seem like a great choice for CPU inferencing.
Yes, I basically always use IQK quants, and at higher bpw levels ( where I-quants do not exist) they are often a far better quality option at their size (see: the data in https://github.com/ikawrakow/ik_llama.cpp/pull/83 and https://github.com/ikawrakow/ik_llama.cpp/pull/89) which is why for models that I use in the 4.25-7 bpw range I make an IQK quant (with an imatrix).
👤 ikawrakow replied the 2025-03-23 at 17:21:45:
Does WizardLM-2-8x22B or any other 8x22B interest you as that could fit, and someone tried it (albeit on llama.cpp) https://github.com/ggml-org/llama.cpp/pull/11397#issuecomment-2661302167 and got good results.
Quantized 8x22B is something I can run on my Ryzen-5975WX. I get
PP-512=61 t/s,TG-128 = 2.16 t/srunning CPU-only for theQ4_K_Mmodel used in the linked post. They said that the difference between 100 t/s and 74 t/s wasn't that important, so based on that logic, I'm matching the performance of 3 GPUs for PP 😄👤 ikawrakow replied the 2025-03-23 at 18:31:20:
With my paltry 16 GB RTX-4080 that is in the Ryzen-7950WX box, I getPP-512 = 80 t/sandTG-128 = 3.1 t/susing-ot "blk\.[0-6]\.ffn=CUDA0,exps=CPU" -rtr -t 32 -ngl 100
👤 ikawrakow replied the 2025-03-21 at 15:49:36:
Okay so its not the size but the bitnet quants are not currently great.
They are actually great. But they are Bitnet quants, so quants for a model that has been trained such that model weights take one of 3 possible values (-1, 0, 1). Hence, they absolutely cannot be used for normal models trained using actual floats. But that does not make them not great. The ternary quants in this repo (IQ2_BN, IQ1_BN) have, as far as I can tell, by far the fastest CPU implementation around.
👤 ubergarm replied the 2025-03-21 at 15:51:44:
Okay gotchu. Yeah I picked them hoping they were fast, but given R1 was not trained as a bitnet they are not the right match for this specific case.
👤 ikawrakow replied the 2025-03-21 at 17:26:50:
The iq3_k_r4/iq2_k_r4 MoE mix that you are cooking should work out to about 207 GiB for the experts (3.582 GiB per layer). It may be useful to have a few MoE layers quantized with more bits (e.g., iq4_k_r4 for ffn_downandiq3_k_r4forffn_up/fate`). If you do the first 8 MoE layers like that, it will add about 11.2 GiB to the weights stored on the CPU.
👤 anikifoss replied the 2025-04-08 at 16:39:03:
@ubergarm huge thanks for this guide! Any chance you could publish the DeepSeek-R1_Q2_K_R4 quant described here?
First of all, thanks for doing all the research on running DeepSeek-R1 locally and publishing high quality technical details. Your posts on level1techs and reddit are currently the only good sources of information available on the subject. My internet searches related to purchasing decisions for running DSR1 always end up on one of your posts!
I started with a 7975wx system for CPU only inference, and overclocked the memory controller based on your benchmarking on level1techs. Then, based on this guide, I ended up shelling out for an RTX 5090. Switching from CPU only inferencw with ollama to CPU+GPU inferece with ik_llama resulted in a 5x inference speedup. The speed improvement are more pronounced for longer contexts, I am able to get roughly 10 tps inference on a 40k context with the unsloth/DeepSeek-R1-UD-Q2_K_XL quant.
Since 5090 has more memory, I offloaded all the small layers onto the GPU with --override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU, though the speedup from that was minor.
./build/bin/llama-server \
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL \
--model /mnt/models/deepseek-ai/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL.gguf \
-rtr \
--ctx-size 106496 \
-ctk f16 -ctv f16 \
-mla 2 -fa \
-amb 1024 \
-fmoe \
--n-gpu-layers 200 \
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU \
--parallel 1 \
--threads 32 \
--host 127.0.0.1 \
--port 8090
Would love to get my hands on the DeepSeek-R1_Q2_K_R4 quant!
👤 ubergarm replied the 2025-04-08 at 17:07:44:
Heya @anikiforovopensource , I appreciate the feedback, its been great working with tools provided by the great developers to push the envelope! Glad you have found some of this useful
Any chance you could publish the DeepSeek-R1_Q2_K_R4 quant described here?
I updated the guide with a link to the hugging face repo that contains a couple ik_llama.cpp exclusive quants:
https://huggingface.co/ubergarm/DeepSeek-V3-0324-GGUF
Sorry it is difficult to piece together all the bread crumbs across so many sites, but sounds like you are having good success.
Since 5090 has more memory, I offloaded all the small layers onto the GPU with --override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU, though the speedup from that was minor.
The 5090 is pretty great size 32GB VRAM for the quants I made actually. Use the CPU+GPU example on the model card, you want to be using -ot exps=CPU to put only routed experts on CPU RAM. As mentioned by ik, that is the "special sauce" of ktransformers. We go a step further here by optimizing the quants for GPU or CPU inferencing. You can probably fit almost 128k context in I'm guessing with this setup with either of the quants I published given the VRAM weights are exactly the same, only the CPU weights are different.
I would recommend:
- Use the
IQ2_K_R4if you have 256GB system RAM - Use the
IQ4_K_R4if you have 512GB system RAM
I'd love to see any benchmark results, you can see how to run llama-sweep-bench here if you are interested. Just adjust the command to match your CPU+GPU setup like I show in the model card.
Cheers and good luck, sounds like you have a great rig to experiment!
👤 ikawrakow replied the 2025-04-08 at 17:43:47:
Switching from CPU only inferencw with ollama to CPU+GPU inferece with ik_llama resulted in a 5x inference speedup.
Where are my 136k stars 😃
👤 fredlas replied the 2025-04-08 at 18:50:04:
Has something changed with how llama-quantize wants the --custom-q flag to be formatted? I'm trying to follow the example, but it won't accept most of the types there. As far as I can tell it only wants to accept "classic" types like q8_0, not q5_k.
Specifically, it gives me e.g. "Invalid quantization type 'q5_k' in custom quantization input blk.[3-4].ffn_gate_exps.weight=q5_k"
👤 ikawrakow replied the 2025-04-08 at 18:57:45:
There have been no changes related to custom quants. Can you post your full command? llama-quantize error messages can be misleading sometimes.
👤 fredlas replied the 2025-04-08 at 19:04:38:
Sure! I arrived at:
custom2="token_embd\.weight=q8_0,output\.weight=q8_0,output_norm\.weight=q8_0,blk\.[0-2]\..*=q8_0,blk\.[3-4]\.ffn_down_exps\.weight=q8_0,blk\.[3-4]\.ffn_gate_exps\.weight=q5_k,blk\.[3-4]\.ffn_up_exps\.weight=iq4_xs,blk\.[5-9]\.ffn_down_exps\.weight=q5_k,blk\.[5-9]\.ffn_gate_exps\.weight=q5_k,blk\.[5-9]\.ffn_up_exps\.weight=q5_k,blk\.1[0-1]\.ffn_down_exps\.weight=iq4_xs,blk\.1[0-1]\.ffn_gate_exps\.weight=iq4_xs,blk\.1[0-1]\.ffn_up_exps\.weight=iq4_xs,blk\.1[2-8]\.ffn_down_exps\.weight=q5_k,blk\.1[2-8]\.ffn_gate_exps\.weight=q5_k,blk\.1[2-8]\.ffn_up_exps\.weight=iq4_xs,blk\.19\.ffn_down_exps\.weight=iq4_xs,blk\.19\.ffn_gate_exps\.weight=iq3_s,blk\.19\.ffn_up_exps\.weight=iq3_s,blk\.[2-5][0-9]\.ffn_down_exps\.weight=iq4_xs,blk\.[2-5][0-9]\.ffn_gate_exps\.weight=iq3_s,blk\.[2-5][0-9]\.ffn_up_exps\.weight=iq3_s,blk\.60\.ffn_down_exps\.weight=iq4_xs,blk\.60\.ffn_gate_exps\.weight=iq3_s,blk\.60\.ffn_up_exps\.weight=iq3_s,blk\.[3-9]\.attn_.*=q8_0,blk\.[1-5][0-9]\.attn_.*=q8_0,blk\.60\.attn_.*=q8_0,blk\.[3-9]\.ffn_norm\.weight=q8_0,blk\.[1-5][0-9]\.ffn_norm\.weight=q8_0,blk\.60\.ffn_norm\.weight=q8_0,blk\.[3-9]\.exp_probs_b\.bias=q8_0,blk\.[1-5][0-9]\.exp_probs_b\.bias=q8_0,blk\.60\.exp_probs_b\.bias=q8_0,blk\.3\.ffn_.*shexp\.weight=q8_0,blk\.[4-9]\.ffn_.*shexp\.weight=q8_0,blk\.[1-5][0-9]\.ffn_.*shexp\.weight=q8_0,blk\.60\.ffn_.*shexp\.weight=q8_0"
./ik_llama.cpp/build/bin/llama-quantize \
--imatrix /home/fred/imatrices/imatrix-bartowski-DeepSeek-R1.dat \
--token-embedding-type q8_0 \
--output-tensor-type q8_0 \
--custom-q "$custom2" \
/home/fred/usb/deepseek_r1_bf16/Downloads-256x21B-BF16-00001-of-00030.gguf \
/home/fred/usb/deepseek_r1_my_mostlyq5/DeepSeek-R1-GGUF/DeepSeek-R1-my_mostly_q5.gguf \
Q5_K \
28
It also doesn't like q6_k, but is ok with q4_0. I dug around a little, but ggml_type_name() ended up at some opaque array access thing, and I'm also having trouble finding where ggml_type's enum values are listed.
👤 ikawrakow replied the 2025-04-08 at 19:10:47:
Oh, this is Kawrakow-style usability at its best!
The "K" in k-quants need to be capitalized. So, q5_K, not q5_k.
This applies only to q2_K, q3_K, q4_K, q5_K, q6_K. In the other cases (iq4_k, etc.) it is small k.
👤 fredlas replied the 2025-04-08 at 19:19:28:
Oh man, thanks. I actually tried different capitalizations, but hadn't gone as far as mixing them!
👤 anikifoss replied the 2025-04-08 at 22:32:55:
Ok, I run the benchmarks, results are below. System: 7975wx with FCLK=2100 , 768G RAM at 5600MHz, RTX 5090.
unsloth/DeepSeek-R1-UD-Q2_K_XL_morepushes more layers onto the GPUunsloth/DeepSeek-R1-UD-Q2_K_XL_attnusesexps=CPUubergarm/DeepSeek-V3-0324-IQ2_K_R4_morepushes more layers onto the GPUubergarm/DeepSeek-V3-0324-IQ2_K_R4_attnusesexps=CPU
Partial benchmark logs
unsloth/DeepSeek-R1-UD-Q2_K_XL
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU
./build/bin/llama-sweep-bench
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL
--model /mnt/models/deepseek-ai/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL.gguf
--run-time-repack
--no-mmap
-ctk f16 -ctv f16
-mla 2 -fa
-amb 1024
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 200
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU
--parallel 1
--threads 32
--threads-batch 128
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 200, n_threads = 32, n_threads_batch = 128
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 4.003 | 127.90 | 7.029 | 18.21 |
| 512 | 128 | 512 | 4.034 | 126.92 | 7.242 | 17.67 |
| 512 | 128 | 1024 | 4.053 | 126.31 | 7.405 | 17.29 |
| 512 | 128 | 1536 | 4.088 | 125.24 | 7.413 | 17.27 |
| 512 | 128 | 2048 | 4.139 | 123.70 | 7.348 | 17.42 |
| 512 | 128 | 2560 | 4.163 | 122.98 | 7.462 | 17.15 |
| 512 | 128 | 3072 | 4.217 | 121.40 | 7.516 | 17.03 |
| 512 | 128 | 3584 | 4.242 | 120.71 | 7.638 | 16.76 |
| 512 | 128 | 4096 | 4.280 | 119.62 | 7.570 | 16.91 |
| 512 | 128 | 4608 | 4.304 | 118.96 | 7.586 | 16.87 |
| 512 | 128 | 5120 | 4.335 | 118.12 | 7.712 | 16.60 |
| 512 | 128 | 5632 | 4.362 | 117.39 | 7.766 | 16.48 |
| 512 | 128 | 6144 | 4.425 | 115.70 | 7.754 | 16.51 |
| 512 | 128 | 6656 | 4.449 | 115.09 | 7.876 | 16.25 |
| 512 | 128 | 7168 | 4.518 | 113.33 | 7.936 | 16.13 |
| 512 | 128 | 7680 | 4.542 | 112.72 | 7.988 | 16.02 |
| 512 | 128 | 8192 | 4.606 | 111.17 | 7.981 | 16.04 |
| 512 | 128 | 8704 | 4.646 | 110.21 | 7.936 | 16.13 |
| 512 | 128 | 9216 | 4.685 | 109.29 | 8.034 | 15.93 |
| 512 | 128 | 9728 | 4.714 | 108.61 | 8.257 | 15.50 |
| 512 | 128 | 10240 | 4.771 | 107.32 | 8.238 | 15.54 |
| 512 | 128 | 10752 | 4.808 | 106.48 | 8.157 | 15.69 |
| 512 | 128 | 11264 | 4.838 | 105.84 | 8.429 | 15.19 |
| 512 | 128 | 11776 | 4.897 | 104.55 | 8.279 | 15.46 |
| 512 | 128 | 12288 | 4.930 | 103.86 | 8.452 | 15.15 |
| 512 | 128 | 12800 | 4.976 | 102.89 | 8.512 | 15.04 |
| 512 | 128 | 13312 | 5.025 | 101.89 | 8.732 | 14.66 |
| 512 | 128 | 13824 | 5.050 | 101.38 | 8.483 | 15.09 |
| 512 | 128 | 14336 | 5.097 | 100.46 | 8.608 | 14.87 |
| 512 | 128 | 14848 | 5.131 | 99.79 | 8.636 | 14.82 |
| 512 | 128 | 15360 | 5.177 | 98.90 | 8.769 | 14.60 |
| 512 | 128 | 15872 | 5.249 | 97.55 | 9.109 | 14.05 |
| 512 | 128 | 16384 | 5.421 | 94.45 | 8.999 | 14.22 |
| 512 | 128 | 16896 | 5.470 | 93.61 | 9.044 | 14.15 |
| 512 | 128 | 17408 | 5.468 | 93.63 | 9.073 | 14.11 |
| 512 | 128 | 17920 | 5.520 | 92.76 | 8.868 | 14.43 |
| 512 | 128 | 18432 | 5.559 | 92.10 | 8.917 | 14.35 |
| 512 | 128 | 18944 | 5.600 | 91.43 | 9.064 | 14.12 |
| 512 | 128 | 19456 | 5.645 | 90.69 | 9.051 | 14.14 |
| 512 | 128 | 19968 | 5.726 | 89.42 | 9.059 | 14.13 |
| 512 | 128 | 20480 | 5.737 | 89.25 | 9.306 | 13.75 |
| 512 | 128 | 20992 | 5.808 | 88.16 | 9.162 | 13.97 |
| 512 | 128 | 21504 | 5.817 | 88.02 | 9.372 | 13.66 |
| 512 | 128 | 22016 | 5.899 | 86.80 | 9.476 | 13.51 |
| 512 | 128 | 22528 | 5.958 | 85.94 | 9.503 | 13.47 |
| 512 | 128 | 23040 | 6.022 | 85.03 | 9.457 | 13.53 |
| 512 | 128 | 23552 | 5.869 | 87.23 | 9.531 | 13.43 |
| 512 | 128 | 24064 | 5.886 | 86.98 | 9.630 | 13.29 |
| 512 | 128 | 24576 | 5.949 | 86.07 | 9.768 | 13.10 |
| 512 | 128 | 25088 | 5.927 | 86.39 | 9.716 | 13.17 |
| 512 | 128 | 25600 | 5.971 | 85.74 | 9.775 | 13.10 |
| 512 | 128 | 26112 | 6.047 | 84.67 | 9.837 | 13.01 |
| 512 | 128 | 26624 | 6.094 | 84.02 | 9.736 | 13.15 |
| 512 | 128 | 27136 | 6.136 | 83.44 | 9.882 | 12.95 |
| 512 | 128 | 27648 | 6.189 | 82.73 | 9.924 | 12.90 |
| 512 | 128 | 28160 | 6.217 | 82.36 | 9.903 | 12.93 |
| 512 | 128 | 28672 | 6.274 | 81.61 | 9.972 | 12.84 |
| 512 | 128 | 29184 | 6.297 | 81.31 | 9.965 | 12.84 |
| 512 | 128 | 29696 | 6.354 | 80.57 | 10.105 | 12.67 |
| 512 | 128 | 30208 | 6.401 | 79.99 | 10.188 | 12.56 |
| 512 | 128 | 30720 | 6.429 | 79.64 | 10.216 | 12.53 |
| 512 | 128 | 31232 | 6.475 | 79.07 | 10.275 | 12.46 |
| 512 | 128 | 31744 | 6.527 | 78.44 | 10.285 | 12.44 |
| 512 | 128 | 32256 | 6.540 | 78.29 | 10.392 | 12.32 |
--override-tensor exps=CPU
./build/bin/llama-sweep-bench
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL
--model /mnt/models/deepseek-ai/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL.gguf
--run-time-repack
--no-mmap
-ctk f16 -ctv f16
-mla 2 -fa
-amb 1024
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 200
--override-tensor exps=CPU
--parallel 1
--threads 32
--threads-batch 128
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 200, n_threads = 32, n_threads_batch = 128
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 4.041 | 126.72 | 7.106 | 18.01 |
| 512 | 128 | 512 | 4.059 | 126.14 | 7.887 | 16.23 |
| 512 | 128 | 1024 | 4.098 | 124.93 | 7.855 | 16.30 |
| 512 | 128 | 1536 | 4.124 | 124.14 | 7.999 | 16.00 |
| 512 | 128 | 2048 | 4.178 | 122.56 | 7.412 | 17.27 |
| 512 | 128 | 2560 | 4.224 | 121.21 | 7.608 | 16.83 |
| 512 | 128 | 3072 | 4.231 | 121.00 | 7.638 | 16.76 |
| 512 | 128 | 3584 | 4.261 | 120.17 | 7.620 | 16.80 |
| 512 | 128 | 4096 | 4.295 | 119.20 | 7.623 | 16.79 |
| 512 | 128 | 4608 | 4.308 | 118.84 | 7.647 | 16.74 |
| 512 | 128 | 5120 | 4.354 | 117.58 | 7.763 | 16.49 |
| 512 | 128 | 5632 | 4.390 | 116.63 | 7.799 | 16.41 |
| 512 | 128 | 6144 | 4.462 | 114.74 | 8.017 | 15.97 |
| 512 | 128 | 6656 | 4.466 | 114.66 | 8.159 | 15.69 |
| 512 | 128 | 7168 | 4.511 | 113.50 | 8.038 | 15.92 |
| 512 | 128 | 7680 | 4.552 | 112.47 | 8.243 | 15.53 |
| 512 | 128 | 8192 | 4.598 | 111.34 | 7.836 | 16.34 |
| 512 | 128 | 8704 | 4.645 | 110.22 | 8.037 | 15.93 |
| 512 | 128 | 9216 | 4.686 | 109.27 | 8.136 | 15.73 |
| 512 | 128 | 9728 | 4.707 | 108.76 | 8.221 | 15.57 |
| 512 | 128 | 10240 | 4.785 | 107.00 | 8.393 | 15.25 |
| 512 | 128 | 10752 | 4.809 | 106.46 | 8.372 | 15.29 |
| 512 | 128 | 11264 | 4.854 | 105.49 | 8.360 | 15.31 |
| 512 | 128 | 11776 | 4.931 | 103.83 | 8.572 | 14.93 |
| 512 | 128 | 12288 | 4.952 | 103.39 | 8.564 | 14.95 |
| 512 | 128 | 12800 | 5.013 | 102.13 | 8.859 | 14.45 |
| 512 | 128 | 13312 | 5.051 | 101.36 | 8.738 | 14.65 |
| 512 | 128 | 13824 | 5.073 | 100.93 | 8.513 | 15.04 |
| 512 | 128 | 14336 | 5.097 | 100.46 | 8.567 | 14.94 |
| 512 | 128 | 14848 | 5.155 | 99.33 | 8.600 | 14.88 |
| 512 | 128 | 15360 | 5.187 | 98.71 | 8.709 | 14.70 |
| 512 | 128 | 15872 | 5.220 | 98.08 | 8.800 | 14.54 |
| 512 | 128 | 16384 | 5.393 | 94.94 | 8.739 | 14.65 |
| 512 | 128 | 16896 | 5.419 | 94.48 | 8.830 | 14.50 |
| 512 | 128 | 17408 | 5.476 | 93.50 | 8.844 | 14.47 |
| 512 | 128 | 17920 | 5.522 | 92.73 | 8.829 | 14.50 |
| 512 | 128 | 18432 | 5.564 | 92.02 | 8.980 | 14.25 |
| 512 | 128 | 18944 | 5.596 | 91.49 | 8.983 | 14.25 |
| 512 | 128 | 19456 | 5.672 | 90.27 | 9.139 | 14.01 |
| 512 | 128 | 19968 | 5.698 | 89.86 | 9.153 | 13.98 |
| 512 | 128 | 20480 | 5.724 | 89.45 | 9.259 | 13.82 |
| 512 | 128 | 20992 | 5.788 | 88.46 | 9.125 | 14.03 |
| 512 | 128 | 21504 | 5.820 | 87.97 | 9.241 | 13.85 |
| 512 | 128 | 22016 | 5.896 | 86.84 | 9.392 | 13.63 |
| 512 | 128 | 22528 | 6.010 | 85.19 | 9.569 | 13.38 |
| 512 | 128 | 23040 | 6.012 | 85.16 | 9.695 | 13.20 |
| 512 | 128 | 23552 | 5.915 | 86.55 | 9.488 | 13.49 |
| 512 | 128 | 24064 | 5.907 | 86.68 | 9.490 | 13.49 |
| 512 | 128 | 24576 | 5.903 | 86.74 | 9.614 | 13.31 |
| 512 | 128 | 25088 | 5.929 | 86.35 | 9.688 | 13.21 |
| 512 | 128 | 25600 | 6.021 | 85.03 | 9.701 | 13.19 |
| 512 | 128 | 26112 | 6.154 | 83.19 | 9.722 | 13.17 |
| 512 | 128 | 26624 | 6.163 | 83.07 | 10.042 | 12.75 |
| 512 | 128 | 27136 | 6.238 | 82.07 | 9.866 | 12.97 |
| 512 | 128 | 27648 | 6.298 | 81.29 | 10.199 | 12.55 |
| 512 | 128 | 28160 | 6.363 | 80.46 | 10.197 | 12.55 |
| 512 | 128 | 28672 | 6.287 | 81.44 | 10.276 | 12.46 |
| 512 | 128 | 29184 | 6.310 | 81.14 | 9.948 | 12.87 |
| 512 | 128 | 29696 | 6.411 | 79.87 | 10.264 | 12.47 |
| 512 | 128 | 30208 | 6.489 | 78.90 | 10.408 | 12.30 |
| 512 | 128 | 30720 | 6.480 | 79.01 | 10.365 | 12.35 |
| 512 | 128 | 31232 | 6.597 | 77.61 | 10.456 | 12.24 |
| 512 | 128 | 31744 | 6.530 | 78.41 | 10.365 | 12.35 |
| 512 | 128 | 32256 | 6.628 | 77.25 | 10.444 | 12.26 |
ubergarm/DeepSeek-V3-0324-IQ2_K_R4
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU
./build/bin/llama-sweep-bench
--alias ubergarm/DeepSeek-V3-0324-IQ2_K_R4
--model /mnt/models/deepseek-ai/DeepSeek-V3-0324-IQ2_K_R4/DeepSeek-V3-0324-IQ2_K_R4-00001-of-00005.gguf
--run-time-repack
--no-mmap
-ctk q8_0
-mla 2 -fa
-amb 1024
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 200
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU
--parallel 1
--threads 32
--threads-batch 128
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 200, n_threads = 32, n_threads_batch = 128
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 4.350 | 117.69 | 8.328 | 15.37 |
| 512 | 128 | 512 | 4.361 | 117.42 | 8.260 | 15.50 |
| 512 | 128 | 1024 | 4.398 | 116.42 | 8.622 | 14.85 |
| 512 | 128 | 1536 | 4.440 | 115.31 | 8.632 | 14.83 |
| 512 | 128 | 2048 | 4.467 | 114.61 | 8.652 | 14.79 |
| 512 | 128 | 2560 | 4.501 | 113.75 | 9.231 | 13.87 |
| 512 | 128 | 3072 | 4.566 | 112.13 | 8.970 | 14.27 |
| 512 | 128 | 3584 | 4.594 | 111.44 | 8.700 | 14.71 |
| 512 | 128 | 4096 | 4.609 | 111.09 | 8.996 | 14.23 |
| 512 | 128 | 4608 | 4.655 | 110.00 | 8.935 | 14.33 |
| 512 | 128 | 5120 | 4.701 | 108.92 | 8.879 | 14.42 |
| 512 | 128 | 5632 | 4.756 | 107.66 | 9.050 | 14.14 |
| 512 | 128 | 6144 | 4.760 | 107.57 | 9.359 | 13.68 |
| 512 | 128 | 6656 | 4.795 | 106.78 | 9.247 | 13.84 |
| 512 | 128 | 7168 | 4.836 | 105.88 | 9.250 | 13.84 |
| 512 | 128 | 7680 | 4.873 | 105.07 | 9.421 | 13.59 |
| 512 | 128 | 8192 | 4.939 | 103.66 | 9.491 | 13.49 |
| 512 | 128 | 8704 | 4.986 | 102.70 | 9.231 | 13.87 |
| 512 | 128 | 9216 | 5.033 | 101.74 | 9.319 | 13.74 |
| 512 | 128 | 9728 | 5.059 | 101.22 | 9.467 | 13.52 |
| 512 | 128 | 10240 | 5.106 | 100.28 | 9.500 | 13.47 |
| 512 | 128 | 10752 | 5.155 | 99.33 | 9.485 | 13.50 |
| 512 | 128 | 11264 | 5.190 | 98.66 | 9.578 | 13.36 |
| 512 | 128 | 11776 | 5.238 | 97.74 | 9.651 | 13.26 |
| 512 | 128 | 12288 | 5.315 | 96.32 | 9.913 | 12.91 |
| 512 | 128 | 12800 | 5.319 | 96.26 | 10.666 | 12.00 |
| 512 | 128 | 13312 | 5.382 | 95.13 | 9.888 | 12.95 |
| 512 | 128 | 13824 | 5.418 | 94.50 | 9.937 | 12.88 |
| 512 | 128 | 14336 | 5.475 | 93.51 | 10.205 | 12.54 |
| 512 | 128 | 14848 | 5.474 | 93.53 | 9.936 | 12.88 |
| 512 | 128 | 15360 | 5.503 | 93.04 | 9.931 | 12.89 |
| 512 | 128 | 15872 | 5.551 | 92.23 | 9.928 | 12.89 |
| 512 | 128 | 16384 | 5.726 | 89.41 | 10.235 | 12.51 |
| 512 | 128 | 16896 | 5.757 | 88.93 | 10.154 | 12.61 |
| 512 | 128 | 17408 | 5.849 | 87.54 | 10.392 | 12.32 |
| 512 | 128 | 17920 | 5.951 | 86.03 | 10.163 | 12.59 |
| 512 | 128 | 18432 | 5.893 | 86.88 | 10.108 | 12.66 |
| 512 | 128 | 18944 | 5.928 | 86.37 | 10.283 | 12.45 |
| 512 | 128 | 19456 | 5.949 | 86.06 | 10.394 | 12.31 |
| 512 | 128 | 19968 | 6.029 | 84.92 | 10.557 | 12.12 |
| 512 | 128 | 20480 | 6.029 | 84.92 | 10.507 | 12.18 |
| 512 | 128 | 20992 | 6.078 | 84.24 | 10.565 | 12.12 |
| 512 | 128 | 21504 | 6.111 | 83.78 | 10.404 | 12.30 |
| 512 | 128 | 22016 | 6.158 | 83.14 | 10.648 | 12.02 |
| 512 | 128 | 22528 | 6.195 | 82.64 | 10.623 | 12.05 |
| 512 | 128 | 23040 | 6.255 | 81.85 | 10.795 | 11.86 |
| 512 | 128 | 23552 | 6.191 | 82.70 | 10.728 | 11.93 |
| 512 | 128 | 24064 | 6.204 | 82.53 | 10.805 | 11.85 |
| 512 | 128 | 24576 | 6.261 | 81.77 | 10.975 | 11.66 |
| 512 | 128 | 25088 | 6.301 | 81.25 | 10.903 | 11.74 |
| 512 | 128 | 25600 | 6.351 | 80.62 | 11.110 | 11.52 |
| 512 | 128 | 26112 | 6.374 | 80.33 | 10.962 | 11.68 |
| 512 | 128 | 26624 | 6.433 | 79.59 | 10.960 | 11.68 |
| 512 | 128 | 27136 | 6.478 | 79.04 | 11.133 | 11.50 |
| 512 | 128 | 27648 | 6.509 | 78.66 | 11.222 | 11.41 |
| 512 | 128 | 28160 | 6.543 | 78.26 | 11.193 | 11.44 |
| 512 | 128 | 28672 | 6.597 | 77.61 | 11.351 | 11.28 |
| 512 | 128 | 29184 | 6.634 | 77.18 | 11.231 | 11.40 |
| 512 | 128 | 29696 | 6.667 | 76.80 | 11.568 | 11.06 |
| 512 | 128 | 30208 | 6.771 | 75.62 | 11.527 | 11.10 |
| 512 | 128 | 30720 | 6.764 | 75.70 | 11.581 | 11.05 |
| 512 | 128 | 31232 | 6.801 | 75.29 | 11.443 | 11.19 |
| 512 | 128 | 31744 | 6.865 | 74.58 | 11.446 | 11.18 |
| 512 | 128 | 32256 | 6.888 | 74.33 | 11.558 | 11.07 |
--override-tensor exps=CPU
./build/bin/llama-sweep-bench
--alias ubergarm/DeepSeek-V3-0324-IQ2_K_R4
--model /mnt/models/deepseek-ai/DeepSeek-V3-0324-IQ2_K_R4/DeepSeek-V3-0324-IQ2_K_R4-00001-of-00005.gguf
--run-time-repack
--no-mmap
-ctk q8_0
-mla 2 -fa
-amb 1024
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 200
--override-tensor exps=CPU
--parallel 1
--threads 32
--threads-batch 128
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 4.330 | 118.24 | 8.120 | 15.76 |
| 512 | 128 | 512 | 4.330 | 118.23 | 8.315 | 15.39 |
| 512 | 128 | 1024 | 4.380 | 116.90 | 8.239 | 15.54 |
| 512 | 128 | 1536 | 4.419 | 115.87 | 8.571 | 14.93 |
| 512 | 128 | 2048 | 4.467 | 114.62 | 8.616 | 14.86 |
| 512 | 128 | 2560 | 4.543 | 112.71 | 8.923 | 14.35 |
| 512 | 128 | 3072 | 4.570 | 112.05 | 9.140 | 14.00 |
| 512 | 128 | 3584 | 4.619 | 110.85 | 8.797 | 14.55 |
| 512 | 128 | 4096 | 4.645 | 110.23 | 9.397 | 13.62 |
| 512 | 128 | 4608 | 4.691 | 109.14 | 9.114 | 14.04 |
| 512 | 128 | 5120 | 4.764 | 107.48 | 9.182 | 13.94 |
| 512 | 128 | 5632 | 4.716 | 108.57 | 9.477 | 13.51 |
| 512 | 128 | 6144 | 4.816 | 106.32 | 9.217 | 13.89 |
| 512 | 128 | 6656 | 4.811 | 106.43 | 9.626 | 13.30 |
| 512 | 128 | 7168 | 4.863 | 105.28 | 9.594 | 13.34 |
| 512 | 128 | 7680 | 4.905 | 104.38 | 9.384 | 13.64 |
| 512 | 128 | 8192 | 4.931 | 103.84 | 9.389 | 13.63 |
| 512 | 128 | 8704 | 4.980 | 102.82 | 9.203 | 13.91 |
| 512 | 128 | 9216 | 5.005 | 102.30 | 9.403 | 13.61 |
| 512 | 128 | 9728 | 5.052 | 101.34 | 9.254 | 13.83 |
| 512 | 128 | 10240 | 5.215 | 98.17 | 9.835 | 13.02 |
| 512 | 128 | 10752 | 5.152 | 99.38 | 9.910 | 12.92 |
| 512 | 128 | 11264 | 5.230 | 97.89 | 9.746 | 13.13 |
| 512 | 128 | 11776 | 5.275 | 97.06 | 9.928 | 12.89 |
| 512 | 128 | 12288 | 5.277 | 97.03 | 9.837 | 13.01 |
| 512 | 128 | 12800 | 5.317 | 96.30 | 10.236 | 12.50 |
| 512 | 128 | 13312 | 5.342 | 95.84 | 10.023 | 12.77 |
| 512 | 128 | 13824 | 5.431 | 94.27 | 9.999 | 12.80 |
| 512 | 128 | 14336 | 5.497 | 93.14 | 10.285 | 12.45 |
| 512 | 128 | 14848 | 5.604 | 91.37 | 10.568 | 12.11 |
| 512 | 128 | 15360 | 5.597 | 91.48 | 10.124 | 12.64 |
| 512 | 128 | 15872 | 5.640 | 90.78 | 10.218 | 12.53 |
| 512 | 128 | 16384 | 5.814 | 88.06 | 10.254 | 12.48 |
| 512 | 128 | 16896 | 5.855 | 87.45 | 10.448 | 12.25 |
| 512 | 128 | 17408 | 5.806 | 88.19 | 10.499 | 12.19 |
| 512 | 128 | 17920 | 5.900 | 86.78 | 10.420 | 12.28 |
| 512 | 128 | 18432 | 5.974 | 85.71 | 10.529 | 12.16 |
| 512 | 128 | 18944 | 5.941 | 86.18 | 10.273 | 12.46 |
| 512 | 128 | 19456 | 5.978 | 85.65 | 10.678 | 11.99 |
| 512 | 128 | 19968 | 6.095 | 84.01 | 10.653 | 12.02 |
| 512 | 128 | 20480 | 6.161 | 83.11 | 10.883 | 11.76 |
| 512 | 128 | 20992 | 6.243 | 82.01 | 10.895 | 11.75 |
| 512 | 128 | 21504 | 6.109 | 83.80 | 10.525 | 12.16 |
| 512 | 128 | 22016 | 6.157 | 83.16 | 10.673 | 11.99 |
| 512 | 128 | 22528 | 6.221 | 82.31 | 10.789 | 11.86 |
| 512 | 128 | 23040 | 6.282 | 81.50 | 11.070 | 11.56 |
| 512 | 128 | 23552 | 6.261 | 81.78 | 11.337 | 11.29 |
| 512 | 128 | 24064 | 6.303 | 81.24 | 10.997 | 11.64 |
| 512 | 128 | 24576 | 6.262 | 81.77 | 10.803 | 11.85 |
| 512 | 128 | 25088 | 6.320 | 81.02 | 10.864 | 11.78 |
| 512 | 128 | 25600 | 6.460 | 79.26 | 10.962 | 11.68 |
| 512 | 128 | 26112 | 6.418 | 79.77 | 11.359 | 11.27 |
| 512 | 128 | 26624 | 6.436 | 79.55 | 11.038 | 11.60 |
| 512 | 128 | 27136 | 6.518 | 78.55 | 11.211 | 11.42 |
| 512 | 128 | 27648 | 6.605 | 77.52 | 11.407 | 11.22 |
| 512 | 128 | 28160 | 6.690 | 76.53 | 11.495 | 11.14 |
| 512 | 128 | 28672 | 6.651 | 76.98 | 11.358 | 11.27 |
| 512 | 128 | 29184 | 6.680 | 76.65 | 11.737 | 10.91 |
| 512 | 128 | 29696 | 6.677 | 76.68 | 11.371 | 11.26 |
| 512 | 128 | 30208 | 6.739 | 75.97 | 11.278 | 11.35 |
| 512 | 128 | 30720 | 6.768 | 75.65 | 11.427 | 11.20 |
| 512 | 128 | 31232 | 6.820 | 75.07 | 11.517 | 11.11 |
| 512 | 128 | 31744 | 6.849 | 74.76 | 11.387 | 11.24 |
| 512 | 128 | 32256 | 6.936 | 73.82 | 11.624 | 11.01 |
👤 ikawrakow replied the 2025-04-09 at 05:49:42:
@saood06 You said somewhere that KTransformers was the fastest toolkit for DeepSeek inference. This is not faster?👤 ubergarm replied the 2025-04-09 at 17:03:08:
@anikiforovopensourceOh great, thanks for the results! Double thanks for exact logs! That looks about right to me. Here are a few observations:
- Both
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPUand--override-tensor exps=CPUare doing the exact same thing. Given it is a regular expression,-ot exps=CPUmatchesdown_exps/gate_exps/up_exps. So really there are only two different comparisons, each one run twice. So your_moreand_attntrials are the same. Good to see there is repeatability.- There is no need to
--run-time-repack(aka-rtr`) my quant, it is already repacked. So you can run it with mmap (for faster startup times) or not. Gives more flexibility.- You specified
-ctk f16 -ctv f16for the unsloth quant, anymore I only specify-ctk q8_0and no need to specify-ctvwhen using MLA psure.q8_0is fine for context especially with this lower quant mix.- For your system I'd recommend keeping
--threads 32and--threads-batch 32instead of what you used--threads-batch 128. You can just use--threads 32and call it good. On that class AMD system with 32 physical cores that will likely be best, and probably even increase your prompt processing speeds. I get faster tok/sec prompt processing for low context on a smaller 24 core version of that thread ripper pro and a slower GPU. For CPU only rigs with tons of cores (like the Intel Xeon 6980P, tuning number of threads is more difficult).- The reason my quant is slower than the unsloth is because I chose to trade-off a little speed for quite a bit better perplexity. That unsloth quant does not use imatrix and has lower quality tensors for attention/shared experts etc. Mine uses an imatrix and has the best quality
q8_0for all tensors on the GPU. If you're interested you could check the perplexity of your unsloth quant yourself using the commands below. No pressure, but I'd be curious to see how it compares. I'm guessing the unsloth is around 3.8 to 3.9 whereas mine isFinal estimate: PPL = 3.5614 +/- 0.02001. Bartowski's was around 3.9, but his latest "V2" recipe made with ik's suggestions is better now. Unsloth is introducing imatrix now too going forward.To test perplexity with either quant on your rig you can run:
wget https://github.com/user-attachments/files/19090237/wiki.test.raw.gz gunzip wiki.test.raw.gz ./build/bin/llama-perplexity \ --model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-IQ2_XS_R4.gguf \ -ctk q8_0 \ -mla 2 -fa \ -amb 512 \ -fmoe \ --ctx-size 512 \ --ubatch-size 512 \ -f wiki.test.raw \ --n-gpu-layers 63 \ --override-tensor exps=CPU \ --threads 32 # to test the unsloth, keep it exactly the same but add `-rtr` if you want to speed it up a bit.You could definitely run the bigger IQ4_K_R4 given you have enough RAM in a single NUMA node (BIOS
NPS1). It will get you almost original quality perplexity with a trade-off in slightly slower speed.Finally, for your normal API usage there is plenty of VRAM left on the table so you can increase context to about 100k with either of my quants, or probably 128k with the unsloth quant (given it has smaller attention/shared experts etc).
@saood06 You said somewhere that KTransformers was the fastest toolkit for DeepSeek inference. This is not faster?
I haven't used ktransformers in over a month since finding
ik_llama.cpp, but my last ktransformers benchmarks on very similar hardware suggest ik is potentially faster or at least on-par with ktransformers speed.👤 ikawrakow replied the 2025-04-09 at 17:25:51:
ik is potentially faster or at least on-par with ktransformers speed.
So, where are my 13k stars? One also has a longer context and better quantization options available...
👤 saood06 replied the 2025-04-10 at 03:54:09:
@saood06 You said somewhere that KTransformers was the fastest toolkit for DeepSeek inference. This is not faster?
I said something to that tune on Feb 19, ik_llama.cpp has improved a lot since then. Even then and still now I still see ktransformers as more of a performance demo because of how limited it is in what it supports both in hardware and the server/API they expose.
So, where are my 13k stars?
I was never sure if you wanted more publicity, I always offered technical support and explanations whenever ik_llama.cpp was brought up and only brought it up when it was relevant to discussions, but there were times I felt like I could have posted about it and gotten strong reception but I never did because I wasn't sure if you wanted this project to be popular.
One also has a longer context and better quantization options available...
I find this repo amazing, and it is full of options, but popularity and quality aren't linked. Your bitnet implementation is far better than the popular Microsoft one, but the Microsoft one (which also has 13k stars), is far better known.
👤 ikawrakow replied the 2025-04-10 at 06:51:50:
I felt like I could have posted about it and gotten strong reception but I never did because I wasn't sure if you wanted this project to be popular.
I'm not necessarily looking for popularity (as you say, the correlation between popularity and quality is not very strong), but KTransformers copying code from here without acknowledgement (see #319) does rub me the wrong way. You can for sure post about that. And I'm now thinking that if this repository was better known, perhaps they wouldn't do it so blatantly. They do acknowledge to have taken the CPU implementation from
llamafile, butllamafileis not a competitor (doesn't even support DeepSeek models), whileik_llama.cppdefinitely is.👤 saood06 replied the 2025-04-10 at 08:19:34:
I'm not necessarily looking for popularity (as you say, the correlation between popularity and quality is not very strong), but KTransformers copying code from here without acknowledgement (see #319) does rub me the wrong way. You can for sure post about that.
I saw that discussion, and I wasn't really happy with it either, but that isn't the sort of thing I would post about. My potential posts were more feature/performance highlights.
And I'm now thinking that if this repository was better known, perhaps they wouldn't do it so blatantly. They do acknowledge to have taken the CPU implementation from llamafile.
That may have helped avoid the situation.
but llamafile is not a competitor (doesn't even support DeepSeek models), while ik_llama.cpp definitely is.
I really don't see the different inference engine as competitors, they just serve different niches.
👤 ubergarm replied the 2025-04-10 at 21:51:50:
@anikiforovopensourceOne last quick tip, if you want to sacrifice some quality in exchange for extra speed add
-ser 6,1to your command. Details on that feature are in PR#239.
👤 anikifoss replied the 2025-04-11 at 15:36:54:
@ubergarm I incorporated some of your suggestions and re-run the benchmark.
Both --override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU and --override-tensor exps=CPU are doing the exact same thing. Given it is a regular expression, -ot exps=CPU matches down_exps/gate_exps/up_exps. So really there are only two different comparisons, each one run twice. So your _more and _attn trials are the same. Good to see there is repeatability.
I ran gguf-dump and found more smaller layers, so I'm trying offload onto the GPU as much as possible, for example:
40: 4128768 | 7168, 576, 1, 1 | Q6_K | blk.3.attn_kv_a_mqa.weight
41: 512 | 512, 1, 1, 1 | F32 | blk.3.attn_kv_a_norm.weight
42: 16777216 | 512, 32768, 1, 1 | Q6_K | blk.3.attn_kv_b.weight
43: 7168 | 7168, 1, 1, 1 | F32 | blk.3.attn_norm.weight
44: 117440512 | 16384, 7168, 1, 1 | Q4_K | blk.3.attn_output.weight
45: 11010048 | 7168, 1536, 1, 1 | Q4_K | blk.3.attn_q_a.weight
46: 1536 | 1536, 1, 1, 1 | F32 | blk.3.attn_q_a_norm.weight
47: 37748736 | 1536, 24576, 1, 1 | Q4_K | blk.3.attn_q_b.weight
48: 256 | 256, 1, 1, 1 | F32 | blk.3.exp_probs_b.bias
49: 3758096384 | 2048, 7168, 256, 1 | Q3_K | blk.3.ffn_down_exps.weight
50: 14680064 | 2048, 7168, 1, 1 | Q6_K | blk.3.ffn_down_shexp.weight
51: 3758096384 | 7168, 2048, 256, 1 | Q2_K | blk.3.ffn_gate_exps.weight
52: 1835008 | 7168, 256, 1, 1 | F32 | blk.3.ffn_gate_inp.weight
53: 14680064 | 7168, 2048, 1, 1 | Q4_K | blk.3.ffn_gate_shexp.weight
54: 7168 | 7168, 1, 1, 1 | F32 | blk.3.ffn_norm.weight
55: 3758096384 | 7168, 2048, 256, 1 | Q2_K | blk.3.ffn_up_exps.weight
56: 14680064 | 7168, 2048, 1, 1 | Q4_K | blk.3.ffn_up_shexp.weight
You specified -ctk f16 -ctv f16 for the unsloth quant, anymore I only specify -ctk q8_0 and no need to specify -ctv when using MLA psure. q8_0 is fine for context especially with this lower quant mix.
From my tests, -ctk f16 -ctv f16 is faster than -ctk q8_0 (see the new benchmark results).
You could definitely run the bigger IQ4_K_R4 given you have enough RAM in a single NUMA node (BIOS NPS1). It will get you almost original quality perplexity with a trade-off in slightly slower speed.
I prefer to run R1 instead of V3, so I currently don't have the quant to utilize more RAM. I can run benchmarks on your DS-R1 671B ubergarm IQ2_XS_R4 and DS-R1 671B ubergarm Q2_K_R4 quants if you share those.
Benchmark results (system: 7975wx with FCLK=2100 , RAM at 5600MHz, RTX 5090):
-ctk f16 -ctv f16with first 3 experts fully offloaded onto the GPU-ctk f16 -ctv f16with all experts on the CPU-ctk q8_0with all experts on the CPU-ctk f16 -ctv f16with no GPU
Partial benchmark logs
GPU
-ctk f16 -ctv f16, --override-tensor all_but_3_exps
VRAM: 30G, RAM: 216G
./build/bin/llama-sweep-bench
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL
--model /mnt/models/deepseek-ai/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL.gguf
--run-time-repack
--no-mmap
-ctk f16 -ctv f16
-mla 2 -fa
-amb 1024
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 200
--override-tensor 6.ffn_down_exps=CPU,6.ffn_gate_exps=CPU,6.ffn_up_exps=CPU,7.ffn_down_exps=CPU,7.ffn_gate_exps=CPU,7.ffn_up_exps=CPU,8.ffn_down_exps=CPU,8.ffn_gate_exps=CPU,8.ffn_up_exps=CPU,9.ffn_down_exps=CPU,9.ffn_gate_exps=CPU,9.ffn_up_exps=CPU,10.ffn_down_exps=CPU,10.ffn_gate_exps=CPU,10.ffn_up_exps=CPU,11.ffn_down_exps=CPU,11.ffn_gate_exps=CPU,11.ffn_up_exps=CPU,12.ffn_down_exps=CPU,12.ffn_gate_exps=CPU,12.ffn_up_exps=CPU,13.ffn_down_exps=CPU,13.ffn_gate_exps=CPU,13.ffn_up_exps=CPU,14.ffn_down_exps=CPU,14.ffn_gate_exps=CPU,14.ffn_up_exps=CPU,15.ffn_down_exps=CPU,15.ffn_gate_exps=CPU,15.ffn_up_exps=CPU,16.ffn_down_exps=CPU,16.ffn_gate_exps=CPU,16.ffn_up_exps=CPU,17.ffn_down_exps=CPU,17.ffn_gate_exps=CPU,17.ffn_up_exps=CPU,18.ffn_down_exps=CPU,18.ffn_gate_exps=CPU,18.ffn_up_exps=CPU,19.ffn_down_exps=CPU,19.ffn_gate_exps=CPU,19.ffn_up_exps=CPU,20.ffn_down_exps=CPU,20.ffn_gate_exps=CPU,20.ffn_up_exps=CPU,21.ffn_down_exps=CPU,21.ffn_gate_exps=CPU,21.ffn_up_exps=CPU,22.ffn_down_exps=CPU,22.ffn_gate_exps=CPU,22.ffn_up_exps=CPU,23.ffn_down_exps=CPU,23.ffn_gate_exps=CPU,23.ffn_up_exps=CPU,24.ffn_down_exps=CPU,24.ffn_gate_exps=CPU,24.ffn_up_exps=CPU,25.ffn_down_exps=CPU,25.ffn_gate_exps=CPU,25.ffn_up_exps=CPU,26.ffn_down_exps=CPU,26.ffn_gate_exps=CPU,26.ffn_up_exps=CPU,27.ffn_down_exps=CPU,27.ffn_gate_exps=CPU,27.ffn_up_exps=CPU,28.ffn_down_exps=CPU,28.ffn_gate_exps=CPU,28.ffn_up_exps=CPU,29.ffn_down_exps=CPU,29.ffn_gate_exps=CPU,29.ffn_up_exps=CPU,30.ffn_down_exps=CPU,30.ffn_gate_exps=CPU,30.ffn_up_exps=CPU,31.ffn_down_exps=CPU,31.ffn_gate_exps=CPU,31.ffn_up_exps=CPU,32.ffn_down_exps=CPU,32.ffn_gate_exps=CPU,32.ffn_up_exps=CPU,33.ffn_down_exps=CPU,33.ffn_gate_exps=CPU,33.ffn_up_exps=CPU,34.ffn_down_exps=CPU,34.ffn_gate_exps=CPU,34.ffn_up_exps=CPU,35.ffn_down_exps=CPU,35.ffn_gate_exps=CPU,35.ffn_up_exps=CPU,36.ffn_down_exps=CPU,36.ffn_gate_exps=CPU,36.ffn_up_exps=CPU,37.ffn_down_exps=CPU,37.ffn_gate_exps=CPU,37.ffn_up_exps=CPU,38.ffn_down_exps=CPU,38.ffn_gate_exps=CPU,38.ffn_up_exps=CPU,39.ffn_down_exps=CPU,39.ffn_gate_exps=CPU,39.ffn_up_exps=CPU,40.ffn_down_exps=CPU,40.ffn_gate_exps=CPU,40.ffn_up_exps=CPU,41.ffn_down_exps=CPU,41.ffn_gate_exps=CPU,41.ffn_up_exps=CPU,42.ffn_down_exps=CPU,42.ffn_gate_exps=CPU,42.ffn_up_exps=CPU,43.ffn_down_exps=CPU,43.ffn_gate_exps=CPU,43.ffn_up_exps=CPU,44.ffn_down_exps=CPU,44.ffn_gate_exps=CPU,44.ffn_up_exps=CPU,45.ffn_down_exps=CPU,45.ffn_gate_exps=CPU,45.ffn_up_exps=CPU,46.ffn_down_exps=CPU,46.ffn_gate_exps=CPU,46.ffn_up_exps=CPU,47.ffn_down_exps=CPU,47.ffn_gate_exps=CPU,47.ffn_up_exps=CPU,48.ffn_down_exps=CPU,48.ffn_gate_exps=CPU,48.ffn_up_exps=CPU,49.ffn_down_exps=CPU,49.ffn_gate_exps=CPU,49.ffn_up_exps=CPU,50.ffn_down_exps=CPU,50.ffn_gate_exps=CPU,50.ffn_up_exps=CPU,51.ffn_down_exps=CPU,51.ffn_gate_exps=CPU,51.ffn_up_exps=CPU,52.ffn_down_exps=CPU,52.ffn_gate_exps=CPU,52.ffn_up_exps=CPU,53.ffn_down_exps=CPU,53.ffn_gate_exps=CPU,53.ffn_up_exps=CPU,54.ffn_down_exps=CPU,54.ffn_gate_exps=CPU,54.ffn_up_exps=CPU,55.ffn_down_exps=CPU,55.ffn_gate_exps=CPU,55.ffn_up_exps=CPU,56.ffn_down_exps=CPU,56.ffn_gate_exps=CPU,56.ffn_up_exps=CPU,57.ffn_down_exps=CPU,57.ffn_gate_exps=CPU,57.ffn_up_exps=CPU,58.ffn_down_exps=CPU,58.ffn_gate_exps=CPU,58.ffn_up_exps=CPU,59.ffn_down_exps=CPU,59.ffn_gate_exps=CPU,59.ffn_up_exps=CPU,60.ffn_down_exps=CPU,60.ffn_gate_exps=CPU,60.ffn_up_exps=CPU
--parallel 1
--threads 32
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 200, n_threads = 32, n_threads_batch = 32
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 3.483 | 147.00 | 7.086 | 18.06 |
| 512 | 128 | 512 | 3.586 | 142.79 | 7.139 | 17.93 |
| 512 | 128 | 1024 | 4.750 | 107.80 | 7.262 | 17.63 |
| 512 | 128 | 1536 | 3.795 | 134.92 | 7.177 | 17.83 |
| 512 | 128 | 2048 | 4.432 | 115.53 | 7.133 | 17.94 |
| 512 | 128 | 2560 | 5.032 | 101.75 | 7.272 | 17.60 |
| 512 | 128 | 3072 | 3.625 | 141.26 | 7.220 | 17.73 |
| 512 | 128 | 3584 | 4.195 | 122.04 | 7.565 | 16.92 |
| 512 | 128 | 4096 | 5.331 | 96.04 | 7.525 | 17.01 |
| 512 | 128 | 4608 | 4.207 | 121.70 | 7.799 | 16.41 |
| 512 | 128 | 5120 | 4.043 | 126.62 | 7.914 | 16.17 |
| 512 | 128 | 5632 | 4.568 | 112.09 | 7.672 | 16.68 |
| 512 | 128 | 6144 | 5.210 | 98.28 | 7.681 | 16.66 |
| 512 | 128 | 6656 | 4.640 | 110.34 | 8.177 | 15.65 |
| 512 | 128 | 7168 | 5.266 | 97.22 | 7.647 | 16.74 |
| 512 | 128 | 7680 | 4.113 | 124.49 | 7.870 | 16.26 |
| 512 | 128 | 8192 | 4.108 | 124.64 | 7.844 | 16.32 |
| 512 | 128 | 8704 | 4.145 | 123.51 | 8.036 | 15.93 |
| 512 | 128 | 9216 | 4.924 | 103.98 | 8.235 | 15.54 |
| 512 | 128 | 9728 | 4.349 | 117.72 | 7.951 | 16.10 |
| 512 | 128 | 10240 | 4.192 | 122.13 | 7.845 | 16.32 |
| 512 | 128 | 10752 | 4.229 | 121.08 | 7.798 | 16.41 |
| 512 | 128 | 11264 | 4.324 | 118.40 | 7.876 | 16.25 |
| 512 | 128 | 11776 | 5.983 | 85.58 | 8.406 | 15.23 |
| 512 | 128 | 12288 | 6.235 | 82.12 | 8.470 | 15.11 |
| 512 | 128 | 12800 | 5.358 | 95.56 | 8.495 | 15.07 |
| 512 | 128 | 13312 | 5.793 | 88.38 | 8.264 | 15.49 |
| 512 | 128 | 13824 | 5.758 | 88.92 | 8.450 | 15.15 |
| 512 | 128 | 14336 | 6.229 | 82.19 | 8.483 | 15.09 |
| 512 | 128 | 14848 | 5.692 | 89.95 | 8.696 | 14.72 |
| 512 | 128 | 15360 | 5.541 | 92.39 | 8.659 | 14.78 |
| 512 | 128 | 15872 | 4.766 | 107.42 | 8.626 | 14.84 |
| 512 | 128 | 16384 | 4.902 | 104.45 | 8.613 | 14.86 |
| 512 | 128 | 16896 | 5.080 | 100.78 | 8.512 | 15.04 |
| 512 | 128 | 17408 | 5.087 | 100.64 | 8.479 | 15.10 |
| 512 | 128 | 17920 | 5.986 | 85.54 | 8.614 | 14.86 |
| 512 | 128 | 18432 | 6.323 | 80.97 | 8.775 | 14.59 |
| 512 | 128 | 18944 | 5.914 | 86.58 | 8.760 | 14.61 |
| 512 | 128 | 19456 | 5.382 | 95.13 | 8.708 | 14.70 |
| 512 | 128 | 19968 | 5.111 | 100.19 | 8.703 | 14.71 |
| 512 | 128 | 20480 | 5.287 | 96.85 | 8.849 | 14.47 |
| 512 | 128 | 20992 | 5.949 | 86.06 | 9.010 | 14.21 |
| 512 | 128 | 21504 | 6.323 | 80.97 | 9.487 | 13.49 |
| 512 | 128 | 22016 | 5.922 | 86.45 | 9.215 | 13.89 |
| 512 | 128 | 22528 | 5.324 | 96.16 | 9.090 | 14.08 |
| 512 | 128 | 23040 | 5.939 | 86.21 | 9.080 | 14.10 |
| 512 | 128 | 23552 | 5.323 | 96.19 | 9.308 | 13.75 |
| 512 | 128 | 24064 | 5.610 | 91.27 | 9.150 | 13.99 |
| 512 | 128 | 24576 | 5.433 | 94.25 | 9.219 | 13.88 |
| 512 | 128 | 25088 | 5.394 | 94.92 | 9.244 | 13.85 |
| 512 | 128 | 25600 | 5.560 | 92.09 | 9.303 | 13.76 |
| 512 | 128 | 26112 | 5.625 | 91.02 | 9.380 | 13.65 |
| 512 | 128 | 26624 | 5.622 | 91.07 | 9.386 | 13.64 |
| 512 | 128 | 27136 | 5.592 | 91.56 | 9.465 | 13.52 |
| 512 | 128 | 27648 | 5.689 | 89.99 | 9.489 | 13.49 |
| 512 | 128 | 28160 | 5.653 | 90.57 | 9.555 | 13.40 |
| 512 | 128 | 28672 | 5.727 | 89.40 | 9.560 | 13.39 |
| 512 | 128 | 29184 | 5.752 | 89.01 | 9.612 | 13.32 |
| 512 | 128 | 29696 | 5.764 | 88.82 | 9.681 | 13.22 |
| 512 | 128 | 30208 | 5.797 | 88.32 | 9.714 | 13.18 |
| 512 | 128 | 30720 | 5.821 | 87.96 | 9.775 | 13.09 |
| 512 | 128 | 31232 | 5.881 | 87.06 | 9.826 | 13.03 |
| 512 | 128 | 31744 | 5.908 | 86.66 | 9.895 | 12.94 |
| 512 | 128 | 32256 | 5.934 | 86.29 | 9.920 | 12.90 |
GPU (best so far)
-ctk f16 -ctv f16, --override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU
VRAM: 18.5G, RAM: 228G
./build/bin/llama-sweep-bench
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL
--model /mnt/models/deepseek-ai/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL.gguf
--run-time-repack
--no-mmap
-ctk f16 -ctv f16
-mla 2 -fa
-amb 1024
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 200
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU
--parallel 1
--threads 32
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 200, n_threads = 32, n_threads_batch = 32
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 3.643 | 140.54 | 7.130 | 17.95 |
| 512 | 128 | 512 | 3.681 | 139.08 | 7.104 | 18.02 |
| 512 | 128 | 1024 | 4.019 | 127.39 | 7.177 | 17.83 |
| 512 | 128 | 1536 | 3.665 | 139.70 | 7.243 | 17.67 |
| 512 | 128 | 2048 | 3.680 | 139.13 | 7.266 | 17.62 |
| 512 | 128 | 2560 | 4.598 | 111.34 | 7.285 | 17.57 |
| 512 | 128 | 3072 | 3.884 | 131.83 | 7.342 | 17.43 |
| 512 | 128 | 3584 | 3.745 | 136.71 | 7.394 | 17.31 |
| 512 | 128 | 4096 | 4.303 | 118.99 | 7.463 | 17.15 |
| 512 | 128 | 4608 | 4.421 | 115.81 | 7.551 | 16.95 |
| 512 | 128 | 5120 | 4.159 | 123.12 | 7.604 | 16.83 |
| 512 | 128 | 5632 | 4.138 | 123.74 | 7.592 | 16.86 |
| 512 | 128 | 6144 | 4.053 | 126.33 | 7.649 | 16.74 |
| 512 | 128 | 6656 | 4.297 | 119.17 | 7.731 | 16.56 |
| 512 | 128 | 7168 | 4.133 | 123.88 | 7.768 | 16.48 |
| 512 | 128 | 7680 | 5.511 | 92.90 | 7.795 | 16.42 |
| 512 | 128 | 8192 | 4.164 | 122.97 | 7.917 | 16.17 |
| 512 | 128 | 8704 | 4.160 | 123.07 | 7.866 | 16.27 |
| 512 | 128 | 9216 | 4.203 | 121.83 | 7.909 | 16.19 |
| 512 | 128 | 9728 | 4.721 | 108.45 | 8.027 | 15.95 |
| 512 | 128 | 10240 | 4.720 | 108.48 | 8.026 | 15.95 |
| 512 | 128 | 10752 | 4.422 | 115.77 | 8.041 | 15.92 |
| 512 | 128 | 11264 | 4.682 | 109.36 | 8.089 | 15.82 |
| 512 | 128 | 11776 | 4.419 | 115.87 | 8.125 | 15.75 |
| 512 | 128 | 12288 | 4.446 | 115.16 | 8.188 | 15.63 |
| 512 | 128 | 12800 | 4.470 | 114.54 | 8.293 | 15.43 |
| 512 | 128 | 13312 | 4.896 | 104.58 | 8.345 | 15.34 |
| 512 | 128 | 13824 | 4.593 | 111.46 | 8.402 | 15.23 |
| 512 | 128 | 14336 | 4.652 | 110.06 | 8.481 | 15.09 |
| 512 | 128 | 14848 | 4.649 | 110.14 | 8.535 | 15.00 |
| 512 | 128 | 15360 | 4.731 | 108.21 | 8.512 | 15.04 |
| 512 | 128 | 15872 | 4.738 | 108.05 | 8.570 | 14.94 |
| 512 | 128 | 16384 | 4.895 | 104.59 | 8.592 | 14.90 |
| 512 | 128 | 16896 | 4.944 | 103.55 | 8.647 | 14.80 |
| 512 | 128 | 17408 | 6.140 | 83.39 | 8.738 | 14.65 |
| 512 | 128 | 17920 | 6.833 | 74.94 | 9.564 | 13.38 |
| 512 | 128 | 18432 | 5.571 | 91.90 | 9.122 | 14.03 |
| 512 | 128 | 18944 | 6.351 | 80.62 | 9.246 | 13.84 |
| 512 | 128 | 19456 | 5.668 | 90.33 | 9.256 | 13.83 |
| 512 | 128 | 19968 | 7.063 | 72.49 | 9.243 | 13.85 |
| 512 | 128 | 20480 | 5.548 | 92.29 | 9.477 | 13.51 |
| 512 | 128 | 20992 | 6.814 | 75.14 | 9.710 | 13.18 |
| 512 | 128 | 21504 | 6.293 | 81.37 | 9.490 | 13.49 |
| 512 | 128 | 22016 | 6.535 | 78.35 | 9.666 | 13.24 |
| 512 | 128 | 22528 | 5.550 | 92.25 | 9.764 | 13.11 |
| 512 | 128 | 23040 | 5.926 | 86.40 | 9.460 | 13.53 |
| 512 | 128 | 23552 | 5.482 | 93.40 | 9.766 | 13.11 |
| 512 | 128 | 24064 | 5.667 | 90.36 | 9.816 | 13.04 |
| 512 | 128 | 24576 | 5.696 | 89.89 | 9.596 | 13.34 |
| 512 | 128 | 25088 | 5.613 | 91.22 | 9.505 | 13.47 |
| 512 | 128 | 25600 | 5.604 | 91.36 | 9.529 | 13.43 |
| 512 | 128 | 26112 | 5.630 | 90.94 | 9.794 | 13.07 |
| 512 | 128 | 26624 | 5.657 | 90.51 | 9.796 | 13.07 |
| 512 | 128 | 27136 | 5.720 | 89.51 | 9.771 | 13.10 |
| 512 | 128 | 27648 | 5.843 | 87.62 | 9.736 | 13.15 |
| 512 | 128 | 28160 | 5.869 | 87.24 | 9.869 | 12.97 |
| 512 | 128 | 28672 | 5.818 | 88.00 | 9.837 | 13.01 |
| 512 | 128 | 29184 | 5.865 | 87.30 | 9.894 | 12.94 |
| 512 | 128 | 29696 | 5.898 | 86.81 | 9.912 | 12.91 |
| 512 | 128 | 30208 | 5.918 | 86.52 | 9.995 | 12.81 |
| 512 | 128 | 30720 | 5.938 | 86.22 | 10.068 | 12.71 |
| 512 | 128 | 31232 | 5.986 | 85.53 | 10.133 | 12.63 |
| 512 | 128 | 31744 | 6.001 | 85.32 | 10.145 | 12.62 |
| 512 | 128 | 32256 | 6.067 | 84.39 | 10.210 | 12.54 |
GPU
-ctk q8_0
VRAM: 17.5G, RAM: 228G
./build/bin/llama-sweep-bench
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL
--model /mnt/models/deepseek-ai/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL.gguf
--run-time-repack
--no-mmap
-ctk q8_0
-mla 2 -fa
-amb 1024
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 200
--override-tensor down_exps=CPU,gate_exps=CPU,up_exps=CPU
--parallel 1
--threads 32
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 200, n_threads = 32, n_threads_batch = 32
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 4.096 | 124.99 | 7.672 | 16.69 |
| 512 | 128 | 512 | 3.678 | 139.20 | 7.677 | 16.67 |
| 512 | 128 | 1024 | 3.979 | 128.69 | 7.566 | 16.92 |
| 512 | 128 | 1536 | 3.872 | 132.23 | 7.561 | 16.93 |
| 512 | 128 | 2048 | 3.740 | 136.89 | 7.633 | 16.77 |
| 512 | 128 | 2560 | 3.856 | 132.78 | 7.684 | 16.66 |
| 512 | 128 | 3072 | 3.720 | 137.63 | 7.730 | 16.56 |
| 512 | 128 | 3584 | 4.022 | 127.31 | 7.722 | 16.58 |
| 512 | 128 | 4096 | 5.110 | 100.19 | 7.784 | 16.44 |
| 512 | 128 | 4608 | 4.787 | 106.95 | 8.121 | 15.76 |
| 512 | 128 | 5120 | 5.096 | 100.46 | 8.074 | 15.85 |
| 512 | 128 | 5632 | 4.062 | 126.03 | 8.162 | 15.68 |
| 512 | 128 | 6144 | 5.254 | 97.44 | 8.617 | 14.85 |
| 512 | 128 | 6656 | 4.788 | 106.94 | 8.147 | 15.71 |
| 512 | 128 | 7168 | 4.554 | 112.42 | 8.303 | 15.42 |
| 512 | 128 | 7680 | 5.438 | 94.15 | 8.298 | 15.43 |
| 512 | 128 | 8192 | 4.562 | 112.23 | 9.095 | 14.07 |
| 512 | 128 | 8704 | 4.309 | 118.83 | 8.437 | 15.17 |
| 512 | 128 | 9216 | 6.090 | 84.08 | 8.855 | 14.46 |
| 512 | 128 | 9728 | 4.384 | 116.79 | 8.890 | 14.40 |
| 512 | 128 | 10240 | 4.501 | 113.74 | 8.700 | 14.71 |
| 512 | 128 | 10752 | 5.173 | 98.98 | 8.756 | 14.62 |
| 512 | 128 | 11264 | 5.883 | 87.03 | 8.907 | 14.37 |
| 512 | 128 | 11776 | 5.338 | 95.92 | 9.013 | 14.20 |
| 512 | 128 | 12288 | 4.596 | 111.40 | 8.877 | 14.42 |
| 512 | 128 | 12800 | 4.989 | 102.62 | 9.279 | 13.80 |
| 512 | 128 | 13312 | 6.270 | 81.65 | 9.298 | 13.77 |
| 512 | 128 | 13824 | 6.395 | 80.06 | 9.615 | 13.31 |
| 512 | 128 | 14336 | 6.610 | 77.45 | 9.614 | 13.31 |
| 512 | 128 | 14848 | 6.563 | 78.02 | 9.810 | 13.05 |
| 512 | 128 | 15360 | 5.766 | 88.80 | 9.491 | 13.49 |
| 512 | 128 | 15872 | 5.942 | 86.17 | 9.488 | 13.49 |
| 512 | 128 | 16384 | 5.158 | 99.27 | 9.452 | 13.54 |
| 512 | 128 | 16896 | 6.553 | 78.14 | 9.518 | 13.45 |
| 512 | 128 | 17408 | 5.054 | 101.31 | 9.495 | 13.48 |
| 512 | 128 | 17920 | 5.118 | 100.05 | 9.453 | 13.54 |
| 512 | 128 | 18432 | 5.605 | 91.34 | 9.458 | 13.53 |
| 512 | 128 | 18944 | 5.161 | 99.20 | 9.610 | 13.32 |
| 512 | 128 | 19456 | 5.235 | 97.80 | 9.665 | 13.24 |
| 512 | 128 | 19968 | 5.946 | 86.11 | 9.482 | 13.50 |
| 512 | 128 | 20480 | 5.966 | 85.82 | 9.673 | 13.23 |
| 512 | 128 | 20992 | 6.732 | 76.05 | 9.690 | 13.21 |
| 512 | 128 | 21504 | 5.708 | 89.70 | 9.987 | 12.82 |
| 512 | 128 | 22016 | 5.422 | 94.43 | 9.757 | 13.12 |
| 512 | 128 | 22528 | 5.618 | 91.13 | 9.918 | 12.91 |
| 512 | 128 | 23040 | 6.370 | 80.38 | 9.888 | 12.94 |
| 512 | 128 | 23552 | 6.118 | 83.69 | 9.927 | 12.89 |
| 512 | 128 | 24064 | 5.658 | 90.50 | 10.228 | 12.51 |
| 512 | 128 | 24576 | 5.764 | 88.83 | 10.345 | 12.37 |
| 512 | 128 | 25088 | 7.223 | 70.89 | 10.030 | 12.76 |
| 512 | 128 | 25600 | 5.684 | 90.07 | 10.493 | 12.20 |
| 512 | 128 | 26112 | 6.165 | 83.05 | 10.326 | 12.40 |
| 512 | 128 | 26624 | 5.884 | 87.01 | 10.250 | 12.49 |
| 512 | 128 | 27136 | 6.007 | 85.24 | 10.161 | 12.60 |
| 512 | 128 | 27648 | 5.818 | 88.00 | 10.435 | 12.27 |
| 512 | 128 | 28160 | 5.947 | 86.09 | 10.270 | 12.46 |
| 512 | 128 | 28672 | 5.895 | 86.85 | 10.255 | 12.48 |
| 512 | 128 | 29184 | 5.879 | 87.09 | 10.382 | 12.33 |
| 512 | 128 | 29696 | 6.140 | 83.38 | 10.372 | 12.34 |
| 512 | 128 | 30208 | 6.441 | 79.49 | 10.734 | 11.92 |
| 512 | 128 | 30720 | 6.289 | 81.41 | 10.518 | 12.17 |
| 512 | 128 | 31232 | 6.314 | 81.09 | 10.602 | 12.07 |
| 512 | 128 | 31744 | 7.195 | 71.16 | 10.691 | 11.97 |
| 512 | 128 | 32256 | 6.132 | 83.49 | 10.576 | 12.10 |
CPU with ctk=f16
./build/bin/llama-sweep-bench
--alias unsloth/DeepSeek-R1-UD-Q2_K_XL
--model /mnt/models/deepseek-ai/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL.gguf
--run-time-repack
--no-mmap
-ctk f16 -ctv f16
-mla 3 -fa
-amb 512
-fmoe
--ctx-size 32768
-ub 512
--n-gpu-layers 0
--parallel 1
--threads 32
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|---|---|---|---|---|---|---|
| 512 | 128 | 0 | 6.693 | 76.50 | 13.734 | 9.32 |
| 512 | 128 | 512 | 7.237 | 70.75 | 14.045 | 9.11 |
| 512 | 128 | 1024 | 7.980 | 64.16 | 14.287 | 8.96 |
| 512 | 128 | 1536 | 8.488 | 60.32 | 14.600 | 8.77 |
| 512 | 128 | 2048 | 8.844 | 57.89 | 14.792 | 8.65 |
| 512 | 128 | 2560 | 9.452 | 54.17 | 15.179 | 8.43 |
| 512 | 128 | 3072 | 10.167 | 50.36 | 15.516 | 8.25 |
| 512 | 128 | 3584 | 13.772 | 37.18 | 15.650 | 8.18 |
| 512 | 128 | 4096 | 11.631 | 44.02 | 16.067 | 7.97 |
| 512 | 128 | 4608 | 12.248 | 41.80 | 16.280 | 7.86 |
| 512 | 128 | 5120 | 12.859 | 39.82 | 16.483 | 7.77 |
| 512 | 128 | 5632 | 13.792 | 37.12 | 16.788 | 7.62 |
| 512 | 128 | 6144 | 14.501 | 35.31 | 17.094 | 7.49 |
| 512 | 128 | 6656 | 15.965 | 32.07 | 17.506 | 7.31 |
| 512 | 128 | 7168 | 16.059 | 31.88 | 17.939 | 7.14 |
| 512 | 128 | 7680 | 16.810 | 30.46 | 18.098 | 7.07 |
| 512 | 128 | 8192 | 18.140 | 28.23 | 18.482 | 6.93 |
| 512 | 128 | 8704 | 18.309 | 27.96 | 18.781 | 6.82 |
| 512 | 128 | 9216 | 18.683 | 27.40 | 18.961 | 6.75 |
| 512 | 128 | 9728 | 19.460 | 26.31 | 19.409 | 6.59 |
| 512 | 128 | 10240 | 20.460 | 25.02 | 19.746 | 6.48 |
| 512 | 128 | 10752 | 20.846 | 24.56 | 19.919 | 6.43 |
| 512 | 128 | 11264 | 21.317 | 24.02 | 20.436 | 6.26 |
| 512 | 128 | 11776 | 22.945 | 22.31 | 20.508 | 6.24 |
| 512 | 128 | 12288 | 23.226 | 22.04 | 20.768 | 6.16 |
| 512 | 128 | 12800 | 23.970 | 21.36 | 21.068 | 6.08 |
| 512 | 128 | 13312 | 24.957 | 20.51 | 21.428 | 5.97 |
| 512 | 128 | 13824 | 25.210 | 20.31 | 21.920 | 5.84 |
| 512 | 128 | 14336 | 26.145 | 19.58 | 22.193 | 5.77 |
| 512 | 128 | 14848 | 26.998 | 18.96 | 22.321 | 5.73 |
| 512 | 128 | 15360 | 26.816 | 19.09 | 22.634 | 5.66 |
| 512 | 128 | 15872 | 27.456 | 18.65 | 22.988 | 5.57 |
| 512 | 128 | 16384 | 33.351 | 15.35 | 23.617 | 5.42 |
| 512 | 128 | 16896 | 30.500 | 16.79 | 24.075 | 5.32 |
| 512 | 128 | 17408 | 30.462 | 16.81 | 23.842 | 5.37 |
| 512 | 128 | 17920 | 33.618 | 15.23 | 24.286 | 5.27 |
| 512 | 128 | 18432 | 34.112 | 15.01 | 24.634 | 5.20 |
| 512 | 128 | 18944 | 35.576 | 14.39 | 24.711 | 5.18 |
| 512 | 128 | 19456 | 33.324 | 15.36 | 25.133 | 5.09 |
| 512 | 128 | 19968 | 35.278 | 14.51 | 25.442 | 5.03 |
| 512 | 128 | 20480 | 34.604 | 14.80 | 25.888 | 4.94 |
| 512 | 128 | 20992 | 36.698 | 13.95 | 26.474 | 4.83 |
| 512 | 128 | 21504 | 35.757 | 14.32 | 26.663 | 4.80 |
| 512 | 128 | 22016 | 45.165 | 11.34 | 27.099 | 4.72 |
| 512 | 128 | 22528 | 39.834 | 12.85 | 27.743 | 4.61 |
| 512 | 128 | 23040 | 38.361 | 13.35 | 27.766 | 4.61 |
| 512 | 128 | 23552 | 39.702 | 12.90 | 28.031 | 4.57 |
| 512 | 128 | 24064 | 39.953 | 12.81 | 28.079 | 4.56 |
| 512 | 128 | 24576 | 40.666 | 12.59 | 28.842 | 4.44 |
| 512 | 128 | 25088 | 41.713 | 12.27 | 28.696 | 4.46 |
| 512 | 128 | 25600 | 41.596 | 12.31 | 29.217 | 4.38 |
| 512 | 128 | 26112 | 42.487 | 12.05 | 29.505 | 4.34 |
| 512 | 128 | 26624 | 43.267 | 11.83 | 30.323 | 4.22 |
| 512 | 128 | 27136 | 44.043 | 11.63 | 30.938 | 4.14 |
| 512 | 128 | 27648 | 44.502 | 11.51 | 30.299 | 4.22 |
| 512 | 128 | 28160 | 44.618 | 11.48 | 31.427 | 4.07 |
| 512 | 128 | 28672 | 46.315 | 11.05 | 31.198 | 4.10 |
| 512 | 128 | 29184 | 48.194 | 10.62 | 31.528 | 4.06 |
| 512 | 128 | 29696 | 46.799 | 10.94 | 32.231 | 3.97 |
| 512 | 128 | 30208 | 47.748 | 10.72 | 32.316 | 3.96 |
| 512 | 128 | 30720 | 48.746 | 10.50 | 33.054 | 3.87 |
| 512 | 128 | 31232 | 52.171 | 9.81 | 32.868 | 3.89 |
| 512 | 128 | 31744 | 53.965 | 9.49 | 33.132 | 3.86 |
| 512 | 128 | 32256 | 56.242 | 9.10 | 33.238 | 3.85 |
👤 ubergarm replied the 2025-04-11 at 19:03:52:
@anikiforovopensourceHey very nice, I appreciate how thorough you are!
- Interesting that
-ctk f16is faster while only adding about 1GiB of VRAM @ 32k context as compared to-ctk q8_0. I'll keep that in mind for how I'm running, given I might prefer the extra speed over extra context in some configs.- Aye, great job finding and offloading a few more layers into VRAM. This is exactly the right approch. I just learned some tips about which layers might be best to offload from @ikawrakow here on Discussion #323.
- You could collapse the override tensor command in your logs using regex e.g. either of these two I tested which are equivalent:
# its okay if you have excessive stuff that doesn't match e.g. layer 61,62,63,...,69 --override-tensor [6-9]\.*exps=CPU,[1-6][0-9]\.*exps=CPU # or since it uses order of operations, specify the exact CUDA device layers first then "the rest on CPU" --override-tensor [3-5]\.*exps=CUDA0,exps=CPU # or pass multiple times, the order matters so first cli options get first preference -ot [3-5]\.*exps=CUDA0 \ -ot exps=CPUIts also fine to leave it how you have it to make it explicit.
If you wanted to try something like ik mentions in the other discussion given you are using
-fmoe, you could try to see how much fits like so:-ot blk\.[3-9]\.ffn_up_exps=CUDA0 \ -ot blk\.[3-9]\.ffn_gate_exps=CUDA0 \ -ot exps=CPUI prefer to run R1 instead of V3, so I currently don't have the quant to utilize more RAM. I can run benchmarks on your DS-R1 671B ubergarm IQ2_XS_R4 and DS-R1 671B ubergarm Q2_K_R4 quants if you share those.
Wow thanks, yeah I never went back and quantized R1 given I just learned how to do this when V3-0324 dropped lol...
If there is demand for it I might try to release a couple with slightly reduced shared experts / attention to fit longer context in 24GB VRAM. If things go well and I still have access to these remote rigs from https://level1techs.com, I def plan to hopefully release something assuming R2 is similar architecture.
Thanks again!
👤 saood06 replied the 2025-04-12 at 04:17:40:
I prefer to run R1 instead of V3, so I currently don't have the quant to utilize more RAM.
If you have the capability, I would recommend making your own quants, that way you can optimally make them exactly to your system specs.
👤 anikifoss replied the 2025-04-12 at 21:09:33:
I fixed some cooling issues with the system and re-run benmarks withser. Also run perplexity.Perplexity for
unsloth/DeepSeek-R1-UD-Q2_K_XL(not plotting, becuseserfailed, and thectkresults are indistinguishable when plotted):
-ctk f16 -ser 7,1: [1]nan,[2]nan,[3]nan,[4]nan,[5]nan,[6]nan,[7]nan,[8]nan,-ctk f16 -ser 6,1: [1]nan,[2]nan,[3]nan,[4]nan,[5]nan,[6]nan,[7]nan,[8]nan,-ctk f16 -ser 5,1: [1]nan,[2]nan,[3]nan,[4]nan,[5]nan,[6]nan,[7]nan,[8]nan,-ctk f16: [1]4.3546,[2]3.3802,[3]3.6638,[4]3.7678,[5]3.7361,[6]4.1076,[7]4.0225,[8]4.0192,-ctk f32: [1]4.3596,[2]3.3839,[3]3.6658,[4]3.7711,[5]3.7389,[6]4.1106,[7]4.0248,[8]4.0216,-ctk q8_0: [1]4.3602,[2]3.3846,[3]3.6666,[4]3.7718,[5]3.7395,[6]4.1110,[7]4.0260,[8]4.0223,Benchmark results (system: 7975wx with FCLK=2100 , RAM at 5600MHz, RTX 5090):

👤 anikifoss replied the 2025-04-12 at 21:12:10:
@saood06 thanks, I'll try making my own quant targetting 32G VRAM. I could use some tips on how to validate it :)👤 anikifoss replied the 2025-04-13 at 23:50:25:
@ubergarm I testedDeepSeek-R1-UD-IQ1_Squant, and it turns out to be slower thanDeepSeek-R1-UD-Q2_K_XL. It looks like theIQquants are generally slower than the correspondingQquants, and even slower than largerQquants!👤 ikawrakow replied the 2025-04-14 at 08:58:02:
i-quants tend to be slower than k-quants (the only exceptions beingIQ4_XSandIQ4_KS). Their advantage is that they tend to achieve better quality for the same number of bits spent than k-quants. In the case where this leads to being able to fully fit the model on the GPU this results in a clear performance advantage. But when using partial GPU offload, then yes, k-quants will tend to give better performance.
👤 ikawrakow replied the 2025-04-14 at 09:05:56:
Interesting that -ctk f16 is faster while only adding about 1GiB of VRAM @ 32k context as compared to -ctk q8_0. I'll keep that in mind for how I'm running, given I might prefer the extra speed over extra context in some configs.
This is only true when attention is computed on the GPU (on the GPU fp16 is king). But for CPU-only inference, or for hybrid inference where for whatever reason the attention ops involving the KV cache are run on the CPU, q8_0 KV-cache will outperform fp16 by a significant margin.
👤 anikifoss replied the 2025-04-14 at 15:19:35:
It's interesting to see how applying one optimization immediately moves the bottleneck somewhere else, running these models is pushing the hardware limits in different ways.
👤 Dampfinchen replied the 2025-04-14 at 18:52:59:
Hello, I have a question. I'm using a laptop 2060 and I'm trying to speed up partial offloading for Gemma 3 12B.
I've compiled your build of llama.cpp with CUDA and AVX2 to see if there's any improvement compared to mainline, however it was noticeably slower. In the readme it is mentioned that for CUDA you need to offload the token embeddings tensors to the GPU, but nowhere can I see the command to do that.
I think its --override-tensor but I don't know the specific command. I tried ffn_down_exps=CUDA0 which resulted in a speedup almost on par with main, but using that and ffn_up_exps=CUDA0, gate_exps=CUDA0 results in a performance loss again (although I think the latter of which is only for MoE models?)
What is the command for doing that? Thank you!
👤 ikawrakow replied the 2025-04-14 at 19:16:16:
Can you give more details? (quantization used, if any, commands used here and in mainline). It is hard to diagnose and give suggestions based on the provided information.👤 Dampfinchen replied the 2025-04-14 at 19:35:17:
Can you give more details? (quantization used, if any, commands used here and in mainline). It is hard to diagnose and give suggestions based on the provided information.
Apologies, I was retesting it again and your build is indeed faster. Is this the expected speedup? I'm asking because I don't know if I'm putting the token embeddings on the GPU correctly. The commands below look MoE specific.
llama.cpp
./llama-server -m ./gemma-3-12b-it-q4_0_s.gguf -c 10240 -ngl 16 --host 127.0.0.1 --port 5001 -t 6 prompt eval time = 35475.31 ms / 10025 tokens ( 3.54 ms per token, 282.59 tokens per second) eval time = 66889.29 ms / 172 tokens ( 388.89 ms per token, 2.57 tokens per second) total time = 102364.60 ms / 10197 tokensik_llamacpp
./llama-server -m "./gemma-3-12b-it-q4_0_s.gguf" -c 10240 -ngl 16 --host 127.0.0.1 --port 5001 -t 6 --override-tensor "down_exps=CUDA0,gate_exps=CUDA0,up_exps=CUDA0" print_timings] prompt eval time = 34348.19 ms / 10025 tokens ( 3.43 ms per token, 291.86 tokens per second) | generation eval time = 53177.83 ms / 154 runs ( 345.31 ms per token, 2.90 tokens per second)My hardware is Core i7 9750H, RTX 2060 6 GB, 32 GB RAM.
👤 Dampfinchen replied the 2025-04-14 at 19:52:41:
I've found the culprit of the slowdown of my previous test. It was Flash Attention. This is the performance with -fa (everything else is the same)
prompt eval time = 30858.00 ms / 10025 tokens ( 3.08 ms per token, 324.88 tokens per second) | print_timings] generation eval time = 100601.17 ms / 170 runs ( 591.77 ms per token, 1.69 tokens per second)Token generation is significantly slower with -fa, PP is a bit faster.
👤 ikawrakow replied the 2025-04-15 at 05:33:24:
There is now a Gemma3 12B MoE model? Or are you using this one? If the latter, the--override-tensor "down_exps=CUDA0,gate_exps=CUDA0,up_exps=CUDA0"command line option does nothing as there are no tensors in that model where their names match the regular expressions you have specified.On my computer (Ryzen-5975WX with RTX-4080) running the command you used for
llama.cpp(i.e., 16 layers offloaded to the GPU, 6 CPU threads) gives me about 10 t/s.The best I can get using < 6 GiB VRAM is 23.3 t/s using
./bin/llama-cli -m gemma3-it-q4_0.gguf -p "I believe the meaning of life is" -t 6 -ngl 100 -ot attn=CPU -nkvo -c 10240I.e., keep all attention tensors and the KV cache on the CPU, offload everything else to the GPU. The reported buffer sizes are
llm_load_tensors: offloaded 49/49 layers to GPU llm_load_tensors: CPU buffer size = 5795,25 MiB llm_load_tensors: CPU buffer size = 787,50 MiB llm_load_tensors: CUDA0 buffer size = 5366,99 MiB ... llama_kv_cache_init: CUDA_Host KV buffer size = 3840,00 MiB llama_new_context_with_model: KV self size = 3840,00 MiB, K (f16): 1920,00 MiB, V (f16): 1920,00 MiB llama_new_context_with_model: CUDA_Host output buffer size = 1,00 MiB llama_new_context_with_model: CUDA0 compute buffer size = 519,50 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 376,01 MiB llama_new_context_with_model: graph nodes = 1590 llama_new_context_with_model: graph splits = 482so,
5366.90 + 519.50 =5,886.4MiB = 5.75 GiB of VRAM used. If that refuses to run (dangerously close to the 6 GiB VRAM you have), you can keep a few additional layers on the CPU. For instance./bin/llama-cli -m gemma3-it-q4_0.gguf -p "I believe the meaning of life is" -t 6 -ngl 100 -ot "attn=CPU,blk\.[0-3]\.ffn=CPU" -nkvo -c 10240will keep the FFN tensors of the first 4 layers on the CPU. With that we have
CUDA0 buffer size = 4973,18 MiB, so this should for sure work. Performance is now 21.8 t/s, so lower than the above but still 2.1X faster than just having 16 full layers on the GPU. Having KV cache and attention calculations on the CPU also allows you to increase the maximum context size. For instance, usingQ8_0quantized KV cache and a max. context of 32768 tokens,./bin/llama-cli -m gemma3-it-q4_0.gguf -s 1234 -n 128 -p "I believe the meaning of life is" -t 6 -ngl 100 -ot "attn=CPU" -c 32768 -nkvo -ctk q8_0 -ctv q8_0 -fagives 20.7 t/s and reports
llm_load_tensors: offloading 48 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 49/49 layers to GPU llm_load_tensors: CPU buffer size = 5795,25 MiB llm_load_tensors: CPU buffer size = 787,50 MiB llm_load_tensors: CUDA0 buffer size = 5366,99 MiB ................................................................................. llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 2048 llama_new_context_with_model: n_ubatch = 512 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 0 llama_new_context_with_model: attn_max_b = 0 llama_new_context_with_model: fused_moe = 0 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 1000000,0 llama_new_context_with_model: freq_scale = 0,125 llama_kv_cache_init: CUDA_Host KV buffer size = 6528,00 MiB llama_new_context_with_model: KV self size = 6528,00 MiB, K (q8_0): 3264,00 MiB, V (q8_0): 3264,00 MiB llama_new_context_with_model: CUDA_Host output buffer size = 1,00 MiB llama_new_context_with_model: CUDA0 compute buffer size = 519,50 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 144,01 MiB llama_new_context_with_model: graph nodes = 1400 llama_new_context_with_model: graph splits = 486👤 Dampfinchen replied the 2025-04-15 at 09:00:59:
Hi! Thank you very much for your detailed reply and testing, I appreciate it a lot!With this command:
./bin/llama-server -m ./gemma3 model -t 6 -ngl 100 -ot "attn=CPU,blk\.[0-3]\.ffn=CPU" -nkvo -c 10240I'm getting much reduced prompt processing speed (30 token/s from 280 token/s) to the point where the full answer of the model takes 4x as long as before. Keep in mind I'm not using a simple "What is the meaning of life" prompt, I'm instead processing a 10K tokens worth of context, and prompt processing is very important to me, so using -nkvo is not an option. Token generation speed however didn't change, it's still 2.95 token/s as it was before.
So then I removed the -nvko flag to have the KV Cache in the GPU again. Sadly then, even playing around with the attn=CPU,blk.[0-3] value, for example setting it to [0-8] to load more FFN tensors to the CPU, doesn't lead to a decrease in VRAM usage in Windows task manager, it does however lead to a reduction in CUDA0 buffer size. Still, it swaps into system memory, slowing the whole thing down to a crawl. Does the CUDA0 buffer size not include the KV Cache? It appears that way.
So the next thing i've tried is quantizing the KV Cache. But as soon as I use flash attention with your build, it slows it down a lot again, so -fa is not an option here as well, and you need it for quanting the full KV Cache.
So I've tried all sorts of combinations and your commands of course, but I'm unable to get decent performance out of it. So far the best performance I've got is with koboldcpp (a llama.cpp wrapper). There with the same configuration and prompt I'm getting 3.2 token/s text gen and 350 token/s pp so I will be switching back to that. For some reason I can use FA there, too.
My laptop is pretty old so that's the best it can do it appears. Still, thank you very much for your helpful replies.
👤 ikawrakow replied the 2025-04-15 at 10:09:30:
If we exchange a few more messages, eventually I will know what your use case is 😃I have pushed PR #330 to allow using
Q8_0KV cache for Gemma models on CUDA.If you pull that one, and then use
-t 6 -ngl 100 -ctk q8_0 -ctv q8_0 -fa -ot "blk\.[0-9]\.ffn=CUDA0,ffn=CPU"you should get a hopefully quite a bit better performance. The above offloads all attention plus the first 10 layers of FFN tensors to the GPU, the remaining tensors are kept on the CPU. Total VRAM used with the above is 5.5 GiB.
This repo has the
sweep-benchtool, which allows you to benchmark PP and TG performance as a function of the number of tokens in the KV cache. Here is what I get with the above./bin/llama-sweep-bench -m gemma3-it-q4_0.ggyf -c 10240 -t 6 -ngl 100 -ot "blk\.[0-9]\.ffn=CUDA0,ffn=CPU" -ctk q8_0 -ctv q8_0 -fa
PP TG N_KV T_PP s S_PP t/s T_TG s S_TG t/s 512 128 0 0.369 1386.47 9.116 14.04 512 128 512 0.371 1381.48 9.152 13.99 512 128 1024 0.379 1349.91 9.268 13.81 512 128 1536 0.380 1348.61 9.315 13.74 512 128 2048 0.384 1333.76 9.415 13.60 512 128 2560 0.388 1318.81 9.478 13.50 512 128 3072 0.393 1302.74 9.619 13.31 512 128 3584 0.398 1286.98 9.696 13.20 512 128 4096 0.402 1272.11 9.824 13.03 512 128 4608 0.408 1255.53 9.892 12.94 512 128 5120 0.414 1237.70 10.035 12.76 512 128 5632 0.418 1223.63 10.135 12.63 512 128 6144 0.423 1210.06 10.300 12.43 512 128 6656 0.432 1184.00 10.398 12.31 512 128 7168 0.433 1182.04 10.545 12.14 512 128 7680 0.438 1169.29 10.643 12.03 512 128 8192 0.443 1155.52 10.770 11.88 512 128 8704 0.448 1142.85 10.809 11.84 512 128 9216 0.453 1131.30 10.968 11.67 512 128 9728 0.457 1120.02 11.031 11.60
llama-sweep-benchperforms a series of prompt processing batches (size 512 in this case) followed by TG (128 tokens in this case). The KV cache is not cleared, so theN_KVcolumns tells you how many tokens were in the KV cache when the PP/TG was processed.👤 ikawrakow replied the 2025-04-15 at 10:11:39:
And here is what I get with more traditionalllama.cppstyle benchmarking:
model size params backend ngl threads type_k type_v fa test t/s gemma3 12B Q4_0 7.20 GiB 12.77 B CUDA 100 6 q8_0 q8_0 1 pp512 1426.31 ± 11.04 gemma3 12B Q4_0 7.20 GiB 12.77 B CUDA 100 6 q8_0 q8_0 1 pp1024 1427.80 ± 6.97 gemma3 12B Q4_0 7.20 GiB 12.77 B CUDA 100 6 q8_0 q8_0 1 pp2048 1416.34 ± 7.49 gemma3 12B Q4_0 7.20 GiB 12.77 B CUDA 100 6 q8_0 q8_0 1 pp4096 1386.97 ± 7.89 gemma3 12B Q4_0 7.20 GiB 12.77 B CUDA 100 6 q8_0 q8_0 1 pp8192 1320.41 ± 4.75 gemma3 12B Q4_0 7.20 GiB 12.77 B CUDA 100 6 q8_0 q8_0 1 pp10240 1288.77 ± 4.29 gemma3 12B Q4_0 7.20 GiB 12.77 B CUDA 100 6 q8_0 q8_0 1 pp10000+tg240 355.33 ± 0.02 👤 Dampfinchen replied the 2025-04-15 at 12:48:11:
Hi! Of course, I will be glad. I'm sure it's exciting for you too to work with such a low spec consumer system! :) Thank you for reacting so fast!With your new PR, I get fast prompt processing speeds again at good VRAM usage. (I had to set one more layer to the CPU to not overspill into RAM) This is the result of your benchmark: -t 6 -ngl 100 -ctk q8_0 -ctv q8_0 -fa -ot "blk.[0-10].ffn=CUDA0,ffn=CPU"
PP TG N_KV T_PP s S_PP t/s T_TG s S_TG t/s 512 128 0 1.185 432.18 27.297 4.69 512 128 512 1.221 419.23 27.740 4.61 512 128 1024 1.340 382.02 28.671 4.46 512 128 1536 1.298 394.40 29.333 4.36 512 128 2048 1.338 382.68 30.151 4.25 512 128 2560 1.354 378.09 30.706 4.17 512 128 3072 1.406 364.14 30.511 4.20 512 128 3584 1.373 372.89 30.753 4.16 512 128 4096 1.376 372.18 31.012 4.13 512 128 4608 1.413 362.26 31.361 4.08 512 128 5120 1.425 359.36 31.538 4.06 512 128 5632 1.474 347.37 31.723 4.03 512 128 6144 1.472 347.84 32.082 3.99 512 128 6656 1.482 345.43 32.598 3.93 512 128 7168 1.571 325.90 32.623 3.92 512 128 7680 1.517 337.49 32.571 3.93 512 128 8192 1.546 331.22 33.001 3.88 512 128 8704 1.572 325.80 33.284 3.85 512 128 9216 1.623 315.50 33.511 3.82 512 128 9728 1.641 312.05 33.640 3.81 So basically we get 3.81 token/s at the full 10K context now and prompt processing is as fast as expected. This is a very nice and welcome improvement from the 2.95 token/s in llama.cpp, and 3.12 token/s in koboldcpp.
However, when trying to use it real world, the server connected to SillyTavern (which has token streaming by the way, I don't know if this matters) prompt processing completes well, but after that token generation stops and I get the error:
ik_quantkv\ik_llama.cpp\ggml\src\ggml-cuda\rope.cu:370: GGML_ASSERT(src0->type == GGML_TYPE_F32 || src0->type == GGML_TYPE_F16) failed👤 ikawrakow replied the 2025-04-15 at 12:59:06:
Well, RoPE can indeed only takef16orf32tensors. The very same assert is present in mainline as well. Are there any shenanigans being played (such as undoing RoPE for context shifting)?👤 Dampfinchen replied the 2025-04-15 at 13:09:20:
With mainline I'm not getting this error, but yes I'm pretty sure llama.cpp is using context shifting as a default. In ST there's also token padding.So llama.cpp is probably using ctx shift while your build uses RoPE, could that be it?
👤 ikawrakow replied the 2025-04-15 at 13:47:32:
With mainline I'm not getting this error
But are you using quantized KV cache with mainline? It is very slow, no?
👤 Dampfinchen replied the 2025-04-15 at 14:55:51:
With mainline I'm not getting this error
But are you using quantized KV cache with mainline? It is very slow, no?
Yes you are very right about that. I've took a cup of coffee and... waited until it was all said and done.
prompt eval time = 723006.03 ms / 10025 tokens ( 72.12 ms per token, 13.87 tokens per second) eval time = 88686.15 ms / 182 tokens ( 487.29 ms per token, 2.05 tokens per second) total time = 811692.19 ms / 10207 tokens srv update_slots: all slots are idleAs you can see, Quant KV Cache + FA and Gemma 3 is completely unsuable with mainline llama.cpp. However, it doesn't throw the error that I've mentioned above.
👤 ikawrakow replied the 2025-04-15 at 15:00:53:
However, it doesn't throw the error that I've mentioned above.
This is interesting. I'll need to investigate. It is not that I couldn't implement RoPE for
Q8_0quantized tensors, but something else has changed and I need to understand what (which is not easy as the two code bases have not much left in common).
👤 cmoncure replied the 2025-05-13 at 01:48:14:
Alright. I want to put down some baseline numbers. I've built a system with EPYC 9175F and 768 GB @5600, with 2x RTX 6000 Ada Generation for 96 GB VRAM. Due to my dumb ass and inexperience with this kind of hardware, I'm running without GPUs and RAM is configured at 3600 for the time being.
Pulled down ubergarm/DeepSeek-V3-0324-IQ4_K_R4 and running it with ik_llama.cpp on master, with config flags: --run-time-repack -mla 3 -fa -ctk q8_0 --ctx-size 32768 -fmoe -amb 2048 --threads 16 --threads-batch 32
RTR seems to have a huge impact. Overall things are about 66% faster than mainline llama.cpp with the unsloth 4-bit quant. First 700 tokens PP runs at 48 t/s, then TG at 7 t/s. With 8000 context PP drops to ~30t/s.
I'm actually okay with this TG, but I gotta get my PP up 😜; my use case requires trawling through a lot of context. I'll check back in when I get GPU working and RAM at expected speed.
👤 saood06 replied the 2025-05-13 at 03:44:10:
RTR seems to have a huge impact.
Yes this is because the quant you pulled is optimized for hybrid inference, see #272/#274 for ways to convert it to be CPU optimized (if you plan to keep using it CPU only), if you want to be able to avoid the load times of
-rtr, but if you plan on using it with your GPU than the quant is already made for that and you just need to use the correct--override-tensorfor it.my use case requires trawling through a lot of context.
Just a reminder that parallel inference exists and can help get more overall throughput if your use case can allow for it.
👤 cmoncure replied the 2025-05-13 at 12:17:53:
Yes, I'm generating actionable intelligence by analyzing hundreds of documents in a batch. I have a huge demand for input tokens (i.e. PP) and not very high output tokens, probably a ratio of 1000 to 1. A typical run would look like 100,000 input tokens, 100 output tokens. I've never done parallel inference before. How would it work in this hardware/software configuration? In practice I think I'll end up pre-processing with a smaller model like Gemma to extract only the relevant tokens from the documents, but...👤 ubergarm replied the 2025-05-13 at 14:40:10:
Thanks for the report and glad you're getting some better results already before optimizing your system.For this specific ubergarm/DeepSeek-V3-0324-IQ4_K_R4 quant all of the attention tensors are Q8_0 (not repacked) and the rest is already repacked. Keep in mind if you put a repacked quant offloaded to your GPU is is just "expensive RAM" as the GPU is not processing it.
Given your use case of wanting high throughput PP of multiple texts, I'd recommend:
- Getting your GPUs online first of all as that will definitely speed up PP running attention on there
- Figure out the longest context you will need for the given input text for this example let's say 16k
- Increase context as much as you want as MLA is very efficient e.g.
160 * 1024 = 160k--ctx-size 163840which will still only use up like 38GB VRAM- Now run with
--parallel 10to get ten concurrent slots each with one tenth of the context size so 16k each.- Keep the queue full by running
10+1=11client threads / asyncio coroutines or what not to feed the beast.- Individual responses will be slower, but the goal is to find the right number of parallel slots to maximize aggregate throughput.
Going forward I'm not uploaded "pre-repacked" quants to hugging face as a bunch of multi-GPU people were trying to offload the repacked tensors and getting confused. Its easy enough to use the offline repack tool for folks who do want to use mmap() or avoid the extra startup time with
-rtr. Anyway, this is to say that if you want to use more of your VRAM to offload some extra layers you will want your own quant or one that is not "pre repacked" to get the best use of your specific setup.Cheers and keep us posted!
(NOTE: the
--parallelworks very well for smaller models so keep in mind if you're using one to pre-process faster to speed that up as well. You could probably some decent size models in full GPU offload with 96GB VRAM for max speed)👤 cmoncure replied the 2025-05-13 at 16:00:06:
Now I just have more questions about how --parallel works.
- The models AFAIK have a maximum context window size. Suppose a model has a window of 8192 tokens. Can I load it with --ctx-size 81920 and --parallel 10 and get ten slots of 8192, keeping each slot under the maximum window size, and everything would be fine?
- What's the resource that's not being maximally utilized by consecutive requests? Compute? Mem B/W? Does the gain come from the asymmetry between PP and TG, so that running this slot's TG concurrently with the next slot's PP increases overall throughput?
- The "I" in "IQ4" means I-matrix, means 'importance' matrix, right? I understand that it has implication for the accuracy of a model at a given average bit-depth by giving more weight to certain things during quantization. Does it mean anything for PP performance in a partial GPU offload scenario? Would a non-I quant run faster?
- I doubt I'm covering new ground with this question, but do we know anything about the utilization of the individual experts in e.g. DeepSeek V3? Are they routed equally or are some preferred over others, in which case we'd presumably want to offload the preferred experts to GPU? I suppose the stochastic training process would result in uniform routing but who knows??
Thank you all very much for your attention!
👤 ubergarm replied the 2025-05-13 at 16:49:14:
- ... Can I load it with --ctx-size 81920 and --parallel 10 and get ten slots of 8192, keeping each slot under the maximum window size, and everything would be fine?
That is my understanding.
- What's the resource that's not being maximally utilized by consecutive requests?
I'd not use
consecutivebutconcurrent. Though to be honest I'm not 100% sure, you might be able to get similar increased throughput by fiddling with the batch and ubatch values. The basic concept is you can get higher aggregate throughput by computing multiple "batches" at the same time.
- The "I" in "IQ4" means I-matrix, means 'importance' matrix, right?
It is confusing as important-matrix
imatrixcalculation as part of quantization came around at a somewhat similar time as iq quants. You can have iq quants with or without the imatrix quantization i'm talking about. Check look at the gguf dump (or hugging face model card side bar e.g. here) and scroll down and see if it has an entry forquantize.imatrix.blahblahdata or not to see if imatrix was used as part of the quantization process regardless of the quantization size/type.)
- (continued) Would a non-I quant run faster?
Yes, different quants have different kernels and optimizations depending on the hardware e.g. CUDA vs CPU etc. If you're offloading to GPU with enough VRAM like you have definitely use
-ctk f16as that will be faster for your specific model CUDA implementation that using-ctk q8_0(which would be faster for CPU inferencing).Stuff like Q8_0 and Q4_0 can be faster despite not quite as good quality bpw. There is an engineering trade-off between performance and compression more or less. On this fork the
iq4_ksjust got updated for CUDA and is quite a bit faster now for example which might be good for your use case.
- we'd presumably want to offload the preferred experts to GPU?
I don't think it is possible to simply say "oh I'm doing coding, so I know those experts live on layer 23 so I'll offload that to GPU) no. It is not that simple. When I don't have enough RAM and am using mmap() I just let the linux kernel page cache handle keeping the "most hot" data in RAM, despite this it is constantly paging almost 6GB/s off my NVMe drive even for "all coding" example.
Enjoy the ride! You have a sweet rig, have fun getting it dialed in for your use case!
👤 cmoncure replied the 2025-05-14 at 00:25:32:
Okay. Got my RAM configured at 4800 MT/s but this does not result in any improvement. PP still small. TG went from 7 t/s to 8.5 t/s in the same scenario. I'll have my GPUs online in the next couple of days.👤 saood06 replied the 2025-05-14 at 01:49:43:
Okay. Got my RAM configured at 4800 MT/s but this does not result in any improvement. PP still small.
PP is compute bound, TG is bandwidth bound (at a batch size of 1).
👤 cmoncure replied the 2025-05-14 at 14:32:33:
An expensive lesson to learn👤 ubergarm replied the 2025-05-14 at 14:52:46:
@cmoncureGet those GPUs online, more of the iqX_k quants just got faster on CUDA: https://github.com/ikawrakow/ik_llama.cpp/pull/417 !!
👤 cmoncure replied the 2025-05-14 at 20:23:32:
OK so I've hit a roadblock. I got GPU 1 online. I'm running now with the following options:~/ik_llama.cpp/build/bin/llama-server \ -mla 2 -fa \ -ctk f16 \ -ctv f16 \ --ctx-size 32768 \ -fmoe \ -thp \ -amb 512 \ -b 1024 \ -ub 1024 \ --threads 16 \ --threads-batch 16 \ --n-gpu-layers 99 \ --override-tensor exps=CPU \ --host 0.0.0.0 --port 7862 \ --alias DeepSeek/DeepSeek-V3-0324-IQ4_K_R4 \ -m ~/AIModels/textgen/DeepSeek-V3-0324-IQ4_K_R4-00001-of-00010.ggufIn my 700 tokens scenario, I now reach 74 t/s PP and 14 t/s TG. However... during PP the GPU utilization is nearly zero as reported by nvidia-smi. During TG it's around 33%. It seems like something is misconfigured or the GPU is starved for work?
editing with some output confirming layer offload and buffer sizes etc.
llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CPU buffer size = 36235.39 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 40525.67 MiB llm_load_tensors: CPU buffer size = 31988.10 MiB llm_load_tensors: CPU buffer size = 938.98 MiB llm_load_tensors: CUDA0 buffer size = 17744.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 1024 llama_new_context_with_model: n_ubatch = 1024 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 2 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB llama_new_context_with_model: CUDA0 compute buffer size = 3650.00 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 352.01 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 118Edit 2: I also find that my timings are not behaving as I would expect with increasing prompt size. Compare these two runs:
INFO [ print_timings] prompt eval time = 54496.29 ms / 4058 tokens ( 13.43 ms per token, 74.46 tokens per second) | tid="133195110408192" timestamp=1747256009 id_slot=0 id_task=3 t_prompt_processing=54496.29 n_prompt_tokens_processed=4058 t_token=13.429346968950222 n_tokens_second=74.4637845989149 INFO [ print_timings] generation eval time = 34866.66 ms / 466 runs ( 74.82 ms per token, 13.37 tokens per second) | tid="133195110408192" timestamp=1747256009 id_slot=0 id_task=3 t_token_generation=34866.662 n_decoded=466 t_token=74.82116309012875 n_tokens_second=13.365202553659998 INFO [ print_timings] prompt eval time = 9444.43 ms / 691 tokens ( 13.67 ms per token, 73.16 tokens per second) | tid="138188855021568" timestamp=1747255624 id_slot=0 id_task=115 t_prompt_processing=9444.428 n_prompt_tokens_processed=691 t_token=13.667768451519537 n_tokens_second=73.16483327523912 INFO [ print_timings] generation eval time = 16514.60 ms / 233 runs ( 70.88 ms per token, 14.11 tokens per second) | tid="138188855021568" timestamp=1747255624 id_slot=0 id_task=115 t_token_generation=16514.605 n_decoded=233 t_token=70.8781330472103 n_tokens_second=14.108723762996451They're the same, within a margin of error I guess, between 700 and 4000 tokens. And then,
INFO [ print_timings] prompt eval time = 381183.86 ms / 25820 tokens ( 14.76 ms per token, 67.74 tokens per second) | tid="133195110408192" timestamp=1747256663 id_slot=0 id_task=478 t_prompt_processing=381183.863 n_prompt_tokens_processed=25820 t_token=14.76312405112316 n_tokens_second=67.73634066455746👤 ubergarm replied the 2025-05-14 at 21:33:55:
Good job getting the next step going. Each GPU has 48GB VRAM right (i'm using the same two cards on a remote rig I have access to for now).tl;dr;
- What is
-thp?- You'll probably want a different quant without pre-repacked
_R4quants to offload a few more layers onto VRAM.- You can use
-mla 3now with GPU as of a few days ago, check the closed PRs (in a rush to find reference sry!)- What is your bios in NPS1 with a single socket? (single numa node?)
- i generally don't mess with the batch or ubatch at first and only after the basic command is working would i fuss with twiddling it to see if it helps, but you probably know more about that than me honestly.
- Sometimes increasing
--threads-batchabove what--threadsis can boost PP depending on exact core count and such. I've only seen it on big core count intel processor, but it def helped in that case.Okie, keep taking small steps to dial it it, its like honing a fine blade lmao... Cheers!
Oh one last thing, check out llama-sweep-bench, i'll modify your command for it, it will help understand the speed across full range of context
~/ik_llama.cpp/build/bin/llama-sweep-bench \ -mla 3 -fa \ -ctk f16 \ --ctx-size 8192 \ -fmoe \ -amb 512 \ --threads 16 \ --threads-batch 24 \ --n-gpu-layers 99 \ --override-tensor exps=CPU \ -m ~/AIModels/textgen/DeepSeek-V3-0324-IQ4_K_R4-00001-of-00010.ggufI knocked it down to 8192 just so you can get a quick result to see how it works. Increase as desired given however much time you want to wait benchmarking.
👤 cmoncure replied the 2025-05-15 at 00:39:16:
Here's the result with many rows removed. Looks like this TG performance is competitive, matching the scores on the Q2 quant above even though it's running Q4 here.
PP TG N_KV T_PP s S_PP t/s T_TG s S_TG t/s 512 128 512 6.901 74.19 8.990 14.24 512 128 1024 6.946 73.71 9.001 14.22 512 128 2048 7.036 72.77 9.044 14.15 512 128 4096 7.178 71.33 9.101 14.06 512 128 4608 7.237 70.75 9.208 13.90 512 128 5120 7.279 70.34 9.227 13.87 512 128 5632 7.384 69.34 9.215 13.89 512 128 6144 7.411 69.09 9.264 13.82 512 128 6656 7.426 68.94 9.248 13.84 512 128 7168 7.475 68.50 9.287 13.78 512 128 7680 7.557 67.75 9.290 13.78 512 128 8192 7.622 67.17 9.270 13.81 512 128 12288 7.958 64.33 9.420 13.59 512 128 16384 8.376 61.13 9.573 13.37 512 128 20480 8.712 58.77 9.768 13.10 512 128 24576 9.154 55.93 9.895 12.94 512 128 28672 9.634 53.14 10.063 12.72 512 128 32768 10.081 50.79 10.206 12.54 512 128 36864 10.533 48.61 10.374 12.34 512 128 40960 11.020 46.46 10.505 12.19 512 128 47616 11.734 43.63 10.709 11.95 👤 saood06 replied the 2025-05-15 at 01:39:57:
Here's the result with many rows removed.
You can use the bundled python script for visualizations if you want. Also llama-batched-bench exists (with many knobs) if you want to see how batched performance differs.
👤 ikawrakow replied the 2025-05-15 at 05:13:33:
In my 700 tokens scenario, I now reach 74 t/s PP and 14 t/s TG. However... during PP the GPU utilization is nearly zero as reported by nvidia-smi. During TG it's around 33%. It seems like something is misconfigured or the GPU is starved for work?
The experts are computed on the CPU, hence the GPU sits idle while the CPU is computing. For PP this leads to nearly zero GPU utilization.
12-14 t/s TG for a 4-bit quantized DeepSeek-V3 is a pretty good result.
If PP is more important, your best option is
- Don't use row-interleaved quants (
*_R4or*_R8). These don't have a CUDA implementation and will always get computed on the CPU- Use as large a batch and u-batch size as your VRAM will permit
Let's do some napkin math. A GPU like your will do in the range of 400 t/s with DeepSeek-V3 if all tensors were in VRAM. But this is not true in your case, so you need to factor in the time it takes to offload the experts tensors to the GPU. Let's assume your PCI-E is 15 GB/s and you need to offload 360 GB worth of tensor data, so that takes 24 seconds. With that we get the following estimate as a function of u-batch size:
u-batch time offload time compute total time PP (t/s) 512 24 1.3 25.3 20.2 1024 24 2.6 26.6 38.5 2048 24 5.1 29.1 70.4 4096 24 10.2 34.2 119.8 If your PCI-E is 30 GB/s, then u-batch=4096 PP will become
4096/(10.2 + 12) = 184.5 t/s.If your use case is such that you cannot use large batches, then as you can see from the above table it is better to not offload the experts computation to the GPU. This is accomplished either by using
*_R4quants, or by adding-op 26,0,27,0,29,0to the command line (see #405, which adds the ability to explicitly control which operations are offloaded to the GPU).👤 cmoncure replied the 2025-05-15 at 14:15:02:
Thanks for writing, and engaging with my very shaky mental model of how all this works.Continuing the napkin math, then with 2 GPUs, I have twice the PCI-E TX bandwidth. Can't we interleave experts- upload experts 0, 2... to GPU 0 and experts 1, 3... to GPU 1, cutting
time offloadin half? Overall, at small batch sizes, wheretime offloaddominates, this should result in a <2x PP speedup, approaching 1.5x at 4096.I don't know how PP actually works, though. Do experts have to be consulted sequentially, or randomly so that the next expert is not known until the current computation is finished? Is there state that gets acted on by each consecutive expert, or can all computation results be concatenated at the end? I should look at the code.
I'm getting more storage installed so I can
play withexperiment on different quants and make my own.👤 ikawrakow replied the 2025-05-15 at 15:08:02:
Which experts are needed and have to be uploaded is not known until the experts are needed (the very last op before they are needed determines which experts are active). But in a batch, each token in the batch activates different experts. So, at the end, basically all experts are needed and one needs to upload them all.There is also a heuristic to not offload experts to the GPU if the batch size is less than 32 - this is important for TG (where batch size is 1). So, when generating tokens one-by-one, the experts are running on the CPU.
👤 cmoncure replied the 2025-05-15 at 18:21:55:
Okay so how TF do the big boys do it? Last I checked they don't have GPUs with 600 GB of VRAM either. Does it all just come down to PCI-E vs. SXM bandwidth? They can just shove the experts in and out of the GPUs faster than we can and that's it??I don't understand how batching works. Can you validate my axioms here?
Prompt Processing:
- Tokens T in a prompt must be processed in sequential order.
- T[i+1] cannot begin to process before T[i] is completely processed.
- Each token in the prompt must meet a random subset Es of total experts E determined on a per-token basis.
- Es < E
- The experts for a given token are not known until the token is ready to be evaluated
- The token must meet each of its experts Es before its computation is complete.
- Each token must meet its experts in sequential order.
- Expert Es[j+1] cannot be met by a token before expert Es[j] is met by that token.
How does batching work, then? When you say "batching" in regards to prompt processing, are you referring to behavior that is controlled in the code by the
n_batchandn_ubatchparameters?👤 cmoncure replied the 2025-05-16 at 19:03:57:
I'm going to assume that token and expert processing during PP is fully parallelizable, i.e. tokens do not have to be processed in order and tokens do not have to meet experts in any order.Is a quant where row-interleaved layers are duplicated with non-row-interleaved layers possible? Does row-interleaving change the calculations?
In my system there are three processing units:
- CPU
- GPU0
- GPU1
Extending the napkin math above, with 2 GPUs I have 2x the PCI-E TX bandwidth. Let's assume we have a model with 20 experts comprising our 360 GB. Suppose it were possible to create a quant with duplicate row-interleaved experts, then leave 8 experts (4 each) for the GPUs. We don't have to upload all 4 experts each batch, either, since at least one expert will remain in memory from the previous batch.
Then, CPU will have (interleaved) experts 1 -12. GPU0 will be assigned (non-interleaved) experts 13 - 16 and load them in this order- [13, 14, 15, 16] [(16), 15, 14, 13] [(13), 14, 15, 16]... GPU1 will be assigned (non-interleaved) experts 17 - 20 and load them in this order- [17, 18, 19, 20] [(20), 19, 18, 17] [(17), 18, 19, 20]...
This reduces the upload data per GPU per batch after the first one, to 60 GB cutting the time to just 4 seconds in the theoretical hardware. The idea would be to equalize the time spent in CPU compute with GPU upload + GPU compute so each finishes in the same time. The 3/1/1 split is just a guess. Per-unit GPU utilization can be increased by, ironically, adding more GPUs since I/O and VRAM are the limiting factor.
Or should I just buy big boy hardware 🤮
👤 cmoncure replied the 2025-05-17 at 01:28:04:
Please bear with me as I learn LLMs 101 in public. Grok informs me that the results of expert calculations are combined as a weighted sum which as we all know is commutative, validating that the tokens can meet the experts in any order. Hopefully Grok is not misinformed on this point.It occurs to me that if we have enough VRAM per GPU to store TWO sets of the necessary buffers for expert calculation, then we can pipeline and eliminate the GPU compute time term from the processing time estimate. Since TX and RX are symmetric on PCI-E, uploading experts and downloading results won't interfere with one another, and with two buffers we can compute an expert simultaneously with uploading the next one.
We ought to be able to achieve an optimization somewhere between 3x CPU-only performance, and 2x I/O-limited GPU-only performance. Right???
👤 cmoncure replied the 2025-05-17 at 02:34:50:
In fact. Forget about CPU for PP. PCI-E 4.0 x16 is supposed to be 32 GB/s symmetric. So let's say 30 GB/s following the above scenario. It would therefore require 6 seconds per GPU to offload each half of the experts, and 5.1 seconds to do each half of the compute. Doesn't that mean with two such GPUs and pipelining offload and compute we can consume the entire model's worth of layers in 6 seconds per batch of 4096 tokens? Surely that has to be a more ideal way to run a huge model like DeepSeek on (kinda-)commodity hardware. I'd gladly take 6 seconds as a lower bound on prompt processing if it meant prefilling 30,000 tokens in 48 seconds instead of 480.I guess the only question is whether a hybrid model could then permit us to do TG at the current rate on CPU.
👤 ikawrakow replied the 2025-05-17 at 04:50:17:
It would therefore require 6 seconds per GPU to offload each half of the experts, and 5.1 seconds to do each half of the compute. Doesn't that mean with two such GPUs and pipelining offload and compute we can consume the entire model's worth of layers in 6 seconds per batch of 4096 tokens?
This is known as tensor parallelism (TP) or, in the
llama.cppworld, as split mode (SM) "row" (as opposed to SM "layer"). Unfortunately SM "row" does not work for MoE models. Not here and also not in mainlinellama.cpp. There are LLM inference frameworks that support TP (e.g., vLLM, sglang), but I'm not sure if/how well they support your use case with partial GPU offload. Somebody comparedik_llama.cppto vLLM on a 16 x 3090 system with a model that fully fits in VRAM, and vLLM was only about 20% faster thanik_llama.cppdespite using 8-way TP.👤 cmoncure replied the 2025-05-17 at 19:59:53:
Thank you very much for your comment. I must be confused about something. There is an inherent difficulty to speak accurately about these things when there are really three competing vocabularies- the mathematical vocabulary of the model architecture, that of the code implementation of llama.cpp and GGUF, and the flawed, simplistic abstractions in my mind that I approach the topic with. (I think "blk" is roughly equivalent to "layer"?)I will try to describe some real and some hypothetical execution models for prompt processing, incrementally increasing the level of parallelism, and will you please note at which case execution becomes impossible and why?
The model shall be DeepSeek-V3-0324, in GGUF format.
Case ACase B, "All experts on CPU, attn on GPU", my current configuration The hardware is a CPU with 768 GB of RAM and GPU with 48 GB of VRAM.
- The model is loaded with "exp" tensors overriden to CPU, and the remaining ("attn") tensors in GPU VRAM.
- A batch of 4096 tokens is obtained from the prompt.
- The batch is sent to CPU and GPU and processed. (I do not fully understand the constraints on tensor placement or order of operations.)
- Goto 2 until PP done.
Fact: Processing can proceed with certain tensors being separated between devices.
Case C, "Attn and the first few experts on GPU, the remaining experts on CPU", a configuration evident elsewhere in this discussion (charts posted above). The hardware is a CPU with 768 GB of RAM and GPU with 48 GB of VRAM.
- The model is loaded with a handful of (e.g. 3) "exp" tensors on GPU, the remaining "exp" tensors overriden to CPU, and the remaining ("attn") tensors in GPU VRAM.
- A batch of 4096 tokens is obtained from the prompt.
- The batch is sent to CPU and GPU and processed. (I do not fully understand the constraints on tensor placement or order of operations.)
- Goto 2 until PP done.
Fact: Processing can proceed with some exp tensors being split between GPU and CPU.
Case D "Serial offload of model experts to single GPU" The hardware is a GPU with 48 GB of VRAM.
- The model is loaded with a handful of "exp" tensors on GPU, the remaining "exp" tensors in system RAM or disk, and the remaining tensors on GPU.
- A batch of 4096 tokens is obtained from the prompt.
- The batch is sent to GPU and processed.
- More "exp" tensors are offloaded to GPU VRAM, overwriting the ones present.
- The final "exp" tensors are offloaded to GPU VRAM, expert calculations are summed up and the batch is complete.
- Goto 2 until PP done.
Question: Processing can proceed with expert layers being uploaded sequentially to GPU, until all experts have been processed against all tokens?
Case E "Serial offload of model experts to multiple GPUs in separate batches" The hardware is 2 GPUs with 48 GB VRAM each.
- The model is loaded as in case D. 2a. A batch B0 of 4096 tokens is obtained from the prompt. 2b. A second batch B1 of 4096 more tokens is obtained from the prompt. 3a. The batch B0 is sent to GPU0 and processed. 3b. The batch B1 is sent to GPU1 and processed. 4a. More "exp" tensors are offloaded to GPU0 VRAM, overwriting the ones present. 4b. More "exp" tensors are offloaded to GPU1 VRAM, overwriting the ones present. 5a. The final "exp" tensors are offloaded to GPU0 VRAM, expert calculations are summed up and the batch B0 is complete. 5b. The final "exp" tensors are offloaded to GPU1 VRAM, expert calculations are summed up and the batch B1 is complete.
- Goto 2 until PP done.
Question: Batches can be processed in parallel across devices, if each batch processes from start to finish on the same device? Or does the calculation of Batch N depend on the result of Batch N-1? Note: This model achieves the same throughput to the proposed "impossible" model in the previous comment, but with higher granularity: 8192 tokens in 12 seconds. This model must be possible if it is true that "tokens may be processed in any order during prefill".
Case F "Serial offload of model experts to multiple GPUs with pipelined batches" The hardware is 2 GPUs with 48 GB VRAM each.
- The model is loaded as in case D.
- A batch B0 of 4096 tokens is obtained from the prompt.
- The batch B0 is sent to GPU0 and processed.
- More "exp" tensors are offloaded to GPU0 VRAM, overwriting the ones present.
- Half of the model tensors have been offloaded to GPU0 VRAM, expert calculations are summed up and batch B0 is halfway complete.
- Batch B0 calculation is moved to GPU 1. 7a. More "exp tensors are offloaded to GPU1 VRAM, overwriting the ones present. 7b. A new batch B1 of 4096 tokens is obtained from the prompt. Batch B1 processing continues from step 3 on GPU0...
- The final "exp" tensors are offloaded to GPU1 VRAM, B0 GPU1 expert calculations are summed up with B0 GPU0 calculations and the batch B0 is complete.
Question: Processing can be stopped halfway through on one device, and then resumed on another device? This seems reasonable- There is nothing special about GPU0 or GPU1; memory is memory. Note: This model eventually achieves the same throughput to the proposed "impossible" model in the previous comment, when the pipeline is full and with at least 8192 tokens.
Case G "Parallel execution of a batch on multiple GPUS", "Impossible" The hardware is 2 GPUs with 48 GB VRAM each.
- The model is loaded with a handful of even-numbered "exp" tensors on GPU0, odd-numbered "exp" tensors on GPU1.
- A batch B0 of 4096 tokens is obtained from the prompt. 3a. The batch B0 is sent to GPU0 and processed. 3b. The same batch B0 is sent to GPU1 and processed. 4a. More even-numbered "exp" tensors are offloaded to GPU0 VRAM, overwriting the ones present. 4b. More odd-numbered "exp" tensors are offloaded to GPU1 VRAM, overwriting the ones present. 5a. The final even-numbered "exp" tensors are offloaded to GPU0 VRAM, expert calculations are summed up. 5b. The final odd-numbered "exp" tensors are offloaded to GPU1 VRAM, expert calculations are summed up.
- The expert calculations from GPU1 is sent to GPU0 and summed together, and the batch B0 is complete.
- Goto 2 until PP done.
Question: A single batch can be processed in parallel between devices, with layers/blk/experts split between devices? This must be possible, if "layers" are "experts", and if "tokens can meet experts in any order". If it is not possible, there must be some constraint or entanglement that is beyond my shallow understanding of the model architecture or its implementation, or there is slippage in the vocabulary I'm using to describe the entities in the domain.
👤 cmoncure replied the 2025-05-20 at 01:12:34:
I brought GPU0 and GPU1 online and tried to split layers among them and it was dog slow. Forget. Adding--numa isolateto the commandline gave about a 10% performance boost (my CPU has 1 core per CCD). Now 82 PP/13.5 TG.Just answer me this- if I shell out for the 48 core version of my (16 core) CPU, will PP scale to roughly 3x?
👤 ikawrakow replied the 2025-05-20 at 04:24:24:
Can you share your command line that resulted in dog slow performance with 2 GPUs? With that I can give you a more informed answer to your question about expected performance increase with a 48-core CPU.👤 ubergarm replied the 2025-05-20 at 14:44:57:
@cmoncureSorry I didn't comprehend all the "Case A, B, C...F" stuff above as it was too dense to read.
(my CPU has 1 core per CCD)
What really?? Oh, I found it in an AMD white paper, you're right:
the 16-core EPYC 9175F uses 16 CPU dies, each with one core per die active. This results in 32 MB L3 cache per core.
If I didn't already mention it, can you configure your BIOS to
NPS1to present a single NUMA node for all 768GB RAM? Having 16 NUMA nodes (one for each CCD / CORE) would probably be bad for performance. In general if I must run across multiple NUMA nodes I generally usenumactl --interleave=all llama-server --numa distribute ...👤 cmoncure replied the 2025-05-22 at 20:22:55:
Hybrid LLM execution models.pdfOkay, I illustrated it. Hope it makes things more clear. And yes I did NPS1. Thanks!
👤 ubergarm replied the 2025-05-23 at 15:02:22:
@cmoncure(I think "blk" is roughly equivalent to "layer"?)
Yeah GGUF naming convention is a bit different than transformers convention.
- GGUF
blk.25.attn_q_norm.weight- Transformers
model.layers.25.self_attn.q_projYou can learn more by using
./gguf-py/scripts/gguf_dump.pyfor GGUF and in transformers you can iterate over a pytorch model e.g.for name, module in model.named_modules()or something kinda like that.I will try to describe some real and some hypothetical execution models for prompt processing, incrementally increasing the level of parallelism, and will you please note at which case execution becomes impossible and why?
Sorry, I appreciate the image but I don't understand what you're asking? Are you asking "what is the best way to run a particular LLM on my specific hardware with ik_llama.cpp right now?" ?
In general just try some things out and A/B test with llama-sweep-bench to see what is faster and keep iterating. See what commands other folks are using and what they say is faster/better. Sorry I don't have more motivation for this big question.
👤 cmoncure replied the 2025-05-23 at 17:06:40:
what you're asking?
I'll restate the thread of discussion from the beginning.
- I asked, how can I improve my PP?
- @ikawrakow proposed a hypothetical scenario in which model tensors were streamed to my GPU, and PCI-E bandwidth becomes the limiting factor:
A GPU like your will do in the range of 400 t/s with DeepSeek-V3 if all tensors were in VRAM. But this is not true in your case, so you need to factor in the time it takes to offload the experts tensors to the GPU. Let's assume your PCI-E is 15 GB/s and you need to offload 360 GB worth of tensor data, so that takes 24 seconds.
- I refined and extended this proposal (CASE "G"). In fact, I should have 30 GB/s of PCI-E TX bandwidth per GPU, and since I have 2 GPUs, I have 60 GB/s altogether. That means total upload time is reduced to 6 seconds if processing the batch can occur on both GPUs simultaneously.
- @ikawrakow responded saying that this is impossible:
This is known as tensor parallelism (TP) or, in the llama.cpp world, as split mode (SM) "row" (as opposed to SM "layer"). Unfortunately SM "row" does not work for MoE models. Not here and also not in mainline llama.cpp.
- This last response confused me, and I do not have a complete mental model of possible execution models. I do not know why:
statically splitting experts between CPU and GPU is possible (CASE "C")
streaming experts to one GPU is possible (CASE "D")
but streaming experts to two GPUs is impossible (CASE "G").
I wrote out six possible execution models (CASE "B" through "G") and asked at which case, execution becomes not supported or impossible in llama.cpp? 6. I illustrated the six cases in a PDF graphic. 7. I am asking: at which case exactly does execution become "impossible" and unsupported? Does the "split mode" differ between CASE D and CASE G? What about CASE E and F? If Batch N can meet experts 1...60 on GPU0, why can it not meet experts 1...30 on GPU0 and 31..60 on GPU1? Do we call these "layers" if split between GPU and CPU, but "row" if split between GPU and GPU?
👤 VinnyG9 replied the 2025-05-13 at 19:02:29:
can you please add to the guide: llama-sweep-bench where it came from? where does it live? what does it feed on?
👤 ubergarm replied the 2025-05-13 at 19:26:14:
The guide is missing a lot of things as this fork has been moving pretty quickly. Your best bet in general is to search closed PRs for more details.Regarding llama-sweep-bench:
where it came from?
I believe @saood06 introduced it in https://github.com/ikawrakow/ik_llama.cpp/pull/225
where does it live?
On this fork it will be built and live in
ik_llama.cpp/build/bin/llama-sweep-benchdepending on your build command. I don't think it exists for mainline, but i just rebased and force pushed my fork's branch with the ported code here and tested that it compiles.what does it feed on?
consciousness. of what else could this universe be comprised?
I have some examples in my recent speed benchmark methodology gist as well. You can use the python script that comes with it to make plots or vibe code your own plotting tool etc.
Basically you figure out the command you want to use for your specific system then replace the binary with
llama-sweep-benchand it more or less will work. I really like to see the speed trade-offs for longer context which you just don't get with most other benchmark tools.
👤 bart2 replied the 2025-05-20 at 06:11:45:
Thanks for putting this guide together! I have to say ik_llama.cpp has been a great experience so far for me:
- much faster than llama.cpp on a hybrid CPU+GPU setup
- actually works, compared with ktransformers (I've spent multiple days trying to get it to work with Deepseek R1 and even smaller Qwen3 models, without success)
I'm already very happy with the tokens/s I'm getting from ik_llama.cpp when using DeepSeek-R1-UD-Q2_K_XL:
INFO [ print_timings] prompt eval time = 17761.71 ms / 1772 tokens ( 10.02 ms per token, 99.77 tokens per second) | tid="140329687441408" timestamp=1747720494 id_slot=0 id_task=0 t_prompt_processing=17761.708 n_prompt_tokens_processed=1772 t_token=10.02353724604966 n_tokens_second=99.76518024054894
INFO [ print_timings] generation eval time = 227769.84 ms / 3803 runs ( 59.89 ms per token, 16.70 tokens per second) | tid="140329687441408" timestamp=1747720494 id_slot=0 id_task=0 t_token_generation=227769.842 n_decoded=3803 t_token=59.892148829871154 n_tokens_second=16.69667927328149
INFO [ print_timings] total time = 245531.55 ms | tid="140329687441408" timestamp=1747720494 id_slot=0 id_task=0 t_prompt_processing=17761.708 t_token_generation=227769.842 t_total=245531.55
What I'd like to try to optimize now is the context size.
Specs of the machine:
- VRAM: 2x 3090 24GB
- RAM: 8x64GB DDR5 for a total of 512GB
- CPUs: 2x Xeon 8480
Current maximum context size I managed to get so far was 41000. Full ik_llama.cpp run arguments:
./ik_llama.cpp/build/bin/llama-server \
--alias unsloth/DeepSeek-R1-Q2_K_R4 \
--model ggufs/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf \
-rtr \
--ctx-size 41000 \
-ctk q8_0 \
-mla 3 -fa \
-amb 512 \
-fmoe \
--n-gpu-layers 63 \
--override-tensor exps=CPU \
--parallel 1 \
--threads 56 \
--host 0.0.0.0 \
-ser 5,1 \
--port 8080
Is there any way to squeeze a larger context size out of this hardware, while maintaining reasonable tokens/s (>15tps)?
Thanks for any help and for working on this!
👤 ikawrakow replied the 2025-05-20 at 06:16:57:
Can you post the part of the log where it tells you what the CUDA buffer sizes are?👤 bart2 replied the 2025-05-20 at 06:23:01:
I saw two sections of the log mentioning CUDA buffer sizes (with different values):llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CPU buffer size = 205716.00 MiB llm_load_tensors: CUDA_Host buffer size = 497.11 MiB llm_load_tensors: CUDA0 buffer size = 5106.51 MiB llm_load_tensors: CUDA1 buffer size = 4779.44 MiBllama_kv_cache_init: CUDA0 KV buffer size = 769.80 MiB llama_kv_cache_init: CUDA1 KV buffer size = 697.63 MiB llama_new_context_with_model: KV self size = 1467.40 MiB, c^KV (q8_0): 1467.40 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB llama_new_context_with_model: pipeline parallelism enabled (n_copies=4) ggml_cuda_host_malloc: failed to allocate 3829.80 MiB of pinned memory: invalid argument llama_new_context_with_model: CUDA0 compute buffer size = 17186.79 MiB llama_new_context_with_model: CUDA1 compute buffer size = 16985.55 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 3829.80 MiB👤 ikawrakow replied the 2025-05-20 at 07:11:05:
The CUDA compute buffers are unexpectedly large for this command line. Can you replace-mla 3with-mla 1and post the compute buffer sizes with that? The TG speed should be about the same. The PP performance will decrease (with the performance degradation increasing with number of tokens in the KV cache), but just to see what happens.👤 bart2 replied the 2025-05-20 at 07:17:54:
CUDA buffer sizes with-mla 1:llm_load_tensors: CPU buffer size = 205716.00 MiB llm_load_tensors: CUDA_Host buffer size = 497.11 MiB llm_load_tensors: CUDA0 buffer size = 5106.51 MiB llm_load_tensors: CUDA1 buffer size = 4779.44 MiBllama_kv_cache_init: CUDA0 KV buffer size = 769.80 MiB llama_kv_cache_init: CUDA1 KV buffer size = 697.63 MiB llama_new_context_with_model: KV self size = 1467.40 MiB, c^KV (q8_0): 1467.40 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB llama_new_context_with_model: pipeline parallelism enabled (n_copies=4) ggml_cuda_host_malloc: failed to allocate 3829.80 MiB of pinned memory: invalid argument llama_new_context_with_model: CUDA0 compute buffer size = 13836.29 MiB llama_new_context_with_model: CUDA1 compute buffer size = 13635.05 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 3829.80 MiB👤 bart2 replied the 2025-05-20 at 07:30:07:
PP, TG timings with-mla 1:INFO [ print_timings] prompt eval time = 22153.91 ms / 1800 tokens ( 12.31 ms per token, 81.25 tokens per second) | tid="135099310661632" timestamp=1747725975 id_slot=0 id_task=0 t_prompt_processing=22153.908 n_prompt_tokens_processed=1800 t_token=12.307726666666666 n_tokens_second=81.24977317771655 INFO [ print_timings] generation eval time = 420810.57 ms / 6840 runs ( 61.52 ms per token, 16.25 tokens per second) | tid="135099310661632" timestamp=1747725975 id_slot=0 id_task=0 t_token_generation=420810.567 n_decoded=6840 t_token=61.522012719298246 n_tokens_second=16.254344677613574 INFO [ print_timings] total time = 442964.47 ms | tid="135099310661632" timestamp=1747725975 id_slot=0 id_task=0 t_prompt_processing=22153.908 t_token_generation=420810.567 t_total=442964.475Prompt processing speed degradation is not too bad. I'll try to find the new maximum context size now.
👤 bart2 replied the 2025-05-20 at 07:57:03:
DeepSeek-R1-UD-Q2_K_XLnow seems to load fine with--ctx-size 131072:) I wonder if RoPE scaling can work here as well... :)👤 saood06 replied the 2025-05-20 at 08:00:51:
Try addingDGGML_SCHED_MAX_COPIES=1to your build process.👤 bart2 replied the 2025-05-20 at 08:03:37:
@saood06, what kind of improvement can I expect to see after building with that option?👤 saood06 replied the 2025-05-20 at 08:10:27:
See https://github.com/ggml-org/llama.cpp/pull/11397#issuecomment-2645971721 but it may lower memory.I can see
pipeline parallelism enabled (n_copies=4)in your output.👤 ikawrakow replied the 2025-05-20 at 08:12:57:
I don't understand the massive CUDA compute buffer size. Can someone running a similar setup chime in?👤 bart2 replied the 2025-05-20 at 08:17:28:
wow, building with-DGGML_SCHED_MAX_COPIES=1really reduced VRAM usage:llama_kv_cache_init: CUDA0 KV buffer size = 2448.02 MiB llama_kv_cache_init: CUDA1 KV buffer size = 2218.51 MiB llama_new_context_with_model: KV self size = 4666.50 MiB, c^KV (q8_0): 4666.50 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB llama_new_context_with_model: pipeline parallelism enabled (n_copies=1) llama_new_context_with_model: CUDA0 compute buffer size = 670.00 MiB llama_new_context_with_model: CUDA1 compute buffer size = 555.50 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 270.01 MiBThat's with
--ctx-size 131072.Testing the model performance now.
👤 saood06 replied the 2025-05-20 at 08:22:50:
wow, building with -DGGML_SCHED_MAX_COPIES=1 really reduced VRAM usage:
Glad to hear it helped you.
👤 bart2 replied the 2025-05-20 at 08:27:48:
wow, building with -DGGML_SCHED_MAX_COPIES=1 really reduced VRAM usage:
Glad to hear it helped you.
Thanks for pointing it out :)
-mla 1from @ikawrakow also helped a lot!Now with all this available VRAM, is there any way to go beyond 128k context size with Deepseek R1?
👤 saood06 replied the 2025-05-20 at 08:30:20:
wow, building with -DGGML_SCHED_MAX_COPIES=1 really reduced VRAM usage:
Glad to hear it helped you.
Thanks for pointing it out :)
-mla 1from @ikawrakow also helped a lot!You might be able to go back to
-mla 3now and get back the PP performance?👤 ikawrakow replied the 2025-05-20 at 08:30:44:
You can now go back to-mla 3and see the compute buffer sizes. Then you know how much VRAM you have left. Most likely you can go to the claimed max. context size of 163k tokens. There may be even some space left for offloading some of the experts to the GPUs.👤 ubergarm replied the 2025-05-20 at 14:51:54:
In addition to above recommendations, if you have configured BIOS to set each socket as a single NUMA node e.g.SNC=Disable(on recent intel systems), you could also try adding numactl and using more threads for PP than TG like so:numactl --interleave=all llama-server --numa distribute --threads 56 --threads-batch 112 ...`On intel Xeon in my limited experience the optimal number of threads for PP is larger than for TG.
👤 bart2 replied the 2025-05-21 at 02:26:30:
@ubergarm thanks. I did disable NUMA in BIOS. With the options you suggested I'm getting ~10% faster PP:INFO [ print_timings] prompt eval time = 18652.78 ms / 1800 tokens ( 10.36 ms per token, 96.50 tokens per second) | tid="135194909810688" timestamp=1747793997 id_slot=0 id_task=0 t_prompt_processing=18652.778 n_prompt_tokens_processed=1800 t_token=10.362654444444443 n_tokens_second=96.50037115114972 INFO [ print_timings] generation eval time = 425150.66 ms / 7052 runs ( 60.29 ms per token, 16.59 tokens per second) | tid="135194909810688" timestamp=1747793997 id_slot=0 id_task=0 t_token_generation=425150.664 n_decoded=7052 t_token=60.28795575723199 n_tokens_second=16.587061004801818 INFO [ print_timings] total time = 443803.44 ms | tid="135194909810688" timestamp=1747793997 id_slot=0 id_task=0 t_prompt_processing=18652.778 t_token_generation=425150.664 t_total=443803.442That's with
--ctx-size 163840.👤 ubergarm replied the 2025-05-21 at 14:34:29:
@bart2That's with
--ctx-size 163840.Great you got it going! As ik mentioned, if you have some VRAM left-over you might be able to offload another layer or so of experts to GPU another small boost and max out performance in this configuration e.g.
-ot ...=CUDA0 -ot ...=CUDA1before the-ot exps=CPUline.I'm not sure on sapphire rapids intel xeon, but your BIOS may also have some kind of
Opportunistic Snoop Broadcast (OSB)mode which reportedly can give better performance for CPU/RAM inferencing: https://github.com/ikawrakow/ik_llama.cpp/discussions/201#discussioncomment-13214852Finally, while
-ser 5,1improves speed, have you found any noticible loss in generation quality? Just curious.👤 bart2 replied the 2025-05-22 at 05:30:42:
@ubergarm, thanks for those pointers!As for
-ser 5,1, I did see some quality degradation, while the speed improvement wasn't very substantial, so I decided to stop using it.I tried to apply your suggestion to use
-otto offload additional layers to GPU, but that resulted in... lower token generation speed. Granted, I haven't performed many tests yet.Here are my ik_llama.cpp arguments with
-otpresent:numactl --interleave=all ./ik_llama.cpp/build/bin/llama-server --alias unsloth/DeepSeek-R1-Q2_K_R4 \ --model ggufs/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf \ -rtr \ --ctx-size 163840 \ -ctk q8_0 \ -mla 1 -fa \ -amb 512 \ -fmoe \ --n-gpu-layers 63 \ --override-tensor exps=CPU \ --parallel 1 \ --threads 56 \ --host 0.0.0.0 \ --port 8080 \ --numa distribute \ --threads-batch 112 \ -ot "blk.*[02468].ffn.=CUDA0" \ -ot "blk.*[13579].ffn.=CUDA1"Corresponding TG speed:
INFO [ print_timings] generation eval time = 571161.96 ms / 7783 runs ( 73.39 ms per token, 13.63 tokens per second) | tid="137939727560704" timestamp=1747891101 id_slot=0 id_task=0 t_token_generation=571161.96 n_decoded=7783 t_token=73.38583579596556 n_tokens_second=13.626607766385563Then TG speed with all the same arguments, except for a lack of
-ot:INFO [ print_timings] generation eval time = 548990.12 ms / 7783 runs ( 70.54 ms per token, 14.18 tokens per second) | tid="128638380834816" timestamp=1747890059 id_slot=0 id_task=0 t_token_generation=548990.119 n_decoded=7783 t_token=70.53708325838365 n_tokens_second=14.176940040700442Does my
-otregex look reasonable? Is there anything else I could try to speed up token generation?👤 ubergarm replied the 2025-05-22 at 13:49:02:
@bart2I'm not 100% on the best
-otoptions for DeepSeek, but you will want to put those lines with CUDAx before the one with CPU as the regex are applied in order. So maybe something like:-ot "blk\.(3|4)\.ffn.*exps=CUDA0 \ -ot "blk\.(5|6)\.ffn.*exps=CUDA1 \ -ot exps=CPU \The idea being to assign just one or two or however many fit until you OOM of the routed expert layers (exps) onto specific GPUs with the balance being caught by the final regex and going to CPU/RAM. Implicitly everything not overridden like attention and shared experts (shexp) will be split normally as you used
-ngl 99(or 63 whatever is fine as long as its >= number of actual layer). Though you might need to add-ts 24,24or whatever to make it split evenly across both GPUs assuming that is the correct ratio of VRAM on each GPU.You'll probably have to fiddle with the regex as needed to catch the right tensors/layers for your remaining VRAM. Some folks like the [3-4[0-9] style and others like the (0|2|4|6|8) style depending on how your brain works haha...
And finally you should be able to use
-mla 3again once you iron out everything above.Good luck!
👤 cfelicio replied the 2025-05-25 at 02:35:57:
Hi Everyone,
Great thread on the subject, and was very helpful for me to optimize the oldish hardware I currently have to play with this. I wanted to share some of the results of my experiments after reading everything here, and see if anyone has any further suggestions on how to make things faster for CPU only?
1 - I'm using 2 Xeon Gold (Skylake) with 1TB of ram 2 - On the bios, I have a few options for NUMA. The first option, under processor, is called "Sub Numa Cluster", and the second option, under memory, is called "Node Interleaving"
If I enable subcluster and leave interleaving disabled, the 2 CPUs will present 4 numa nodes. With subcluster disabled and interleaving disabled, I get 1 node per CPU. And finally, with numa disabled and interleaving enabled, I get a single node for both CPUs
Using the intel mlc tool, the maximum bandwidth is achieved with 1 numa node per CPU, around 100gb / s each. Having a single node for both CPUs gives me around 130gb / s.
In theory, going with 2 nodes should be faster, but in reality, it seems like having everything consolidated under a single numa node is the fastest option (around 30% faster). I'm using Windows, perhaps the results would be better on Linux?
Best result I got so far:
G:\ik_llama>llama-bench.exe --model "G:\Qwen3-235B-A22B-128K-Q8_0-00001-of-00006.gguf" -mla 3 -fa 1 -t 28 --run-time-repack 1
| model | size | params | backend | threads | fa | mla | rtr | test | t/s |
|---|---|---|---|---|---|---|---|---|---|
| ============ Repacked 659 tensors | |||||||||
| qwen3moe ?B Q8_0 | 232.77 GiB | 235.09 B | CPU | 28 | 1 | 3 | 1 | pp512 | 32.30 ± 3.51 |
| qwen3moe ?B Q8_0 | 232.77 GiB | 235.09 B | CPU | 28 | 1 | 3 | 1 | tg128 | 3.80 ± 0.01 |
Any suggestions are appreciated! :-)
👤 ubergarm replied the 2025-05-25 at 15:50:57:
Hey glad you got it going on your system. Thanks a lot for the detailed explanation of the BIOS settings as I don't have access to intel xeon BIOS. I had never heard of "node interleaving" option and just assumed that dual socket intel had no equivalent of AMDNPS0to present a single numa node for both sockets.Right, I watched a good deep dive on AMD Epyc server BIOS on level1techs youtube recently and the AMD engineers basically said "don't use NPS0 unless your workload is not optimized at all" and that is basically the case for all CPU inferencing engines so even though aggregate RAM bandwidth goes down it will likely be the fastest for now.
You could compare a single numa node setup with having 1x numa node per socket and running with
numactl --interleave=all llama-server --numa distributejust to see the difference.So quick possible optimizations thoughts for you given you are running CPU only:
- Use different number of
--threads 28and--threads-batch 56or something like that as in general PP is more CPU bottle-necked whereas TG is more RAM i/o bottlenecked. Generally for PP I would use the number of total physical cores across both CPUs and (not counting SMT/hyperthreads) and then for TG go with the number for a single CPU. You can adjust from there for your specific setup.- In general I would advise against any of those "128k" versions of the model as they are basically the same model but the GGUF has baked in the yarn options to run in 4x mode which the qwen official version does not enable on purpose and also puts a big warning on their model card that this can degrade performance if your prompts tend to be shorter than 32k when usin 4x yarn mode. Given you're getting only 30ish tok/sec PP I can't imaging you want to wait around for big 32k+ prompt lengths so just get a normal GGUF or override the yarn back to normal mode as the baked in ~40k context is plenty for most people unless they know what they are doing and really need that 32k+ context on almost every prompt. haha...
- Linux might be a little faster but given you are fully in RAM you're not fighting the mmap swapping business on windows which is supposedly slower than native linux page cache. If your CPUs have a mix of P cores and E cores you might be able to play around pinning threads to P cores and all that jazz but it is probably a lot of fuss especially in windows. Linux might do a better job of thread allocation on newer kernels, but just speculating wildly.
- You can probably get a boost using q8_0 for ctk/ctv kv-cache quantization as the default is f16. f16 is typically faster on cuda GPUs but takes more VRAM. q8 is generally faster on CPU than f16 and also gives the side benefit of taking less RAM. psure ik's fork will re-pack the q8_0 kv-cache under the hood for generally better performance (and old PR allows you to turn that off if you really wanted to a/b test that on your specific rig). That would be adding
-ctk q8_0 -ctv q8_0to your command.- Add
-fmoefor fused moe as this version of qwen3moe supports that psure and may give some benefits even on CPU.- For actual use you probably want to use
-c 32768for a reasonable amount of context given this is a thinking model. Though at your speeds you may want to just include/no_thinkat the beginning of your prompts or whatever the secret word is to disable thinking for speed up at the cost of worse performance on logic/coding responses.- Finally, you might consider going with a Q4 model or rolling your own iq4_ks model as having smaller weights will likely speed up TG with similar PP (or slightly slower depending on exact quant). I know you have enough RAM to hold the big models, but it might be worth it for you to get a little more speed given you have no GPU at all.
Have fun tweaking!
👤 cfelicio replied the 2025-05-28 at 17:55:56:
Thanks for providing such a detailed reply, this has been super helpful! I ended up spending some more time on this, and wanted to share my results:1 - Windows turned out to be a big limitation, as it is not possible to control NUMA behavior the same way as you can in Linux. I also tried Proxmox, but could not figure out how to reach the maximum bandwidth in a Linux VM. I ended up installing Debian on bare metal, and easily got close to 200gb / s doing the Intel MLC test, with 2 numa nodes
2 - Equipped with Debian bare metal, I was now able to use numactl, and the best results were obtained with numactl --interleave=all and --numa distribute, I got over 4 tokens / s on the llama-bench. Not a spetacular result as I was expecting, but better than the max I had reached before with Windows
3 - I switched over to your model (Qwen3-235B-A22B-mix-IQ3_K) as you suggested, and that also helped in real world usage once I started the llama-server. After filling up the context, I can still get over 3 t/s, not bad!
4 - fmoe and ctk / ctv did not make much of a difference
5 - final startup command with best results: numactl --interleave=all /media/xyz/data/ik_llama/llama-bench --model /media/xyz/data/Qwen3-235B-A22B-mix-IQ3_K-00001-of-00003.gguf -mla 3 -fa 1 --run-time-repack 1 --numa distribute
Also adding the screenshots below in case anyone has a similar system and wants to play with NUMA:
Sub numa cluster settings if you want to reduce numa nodes from 4 to 2 (probably best option on Linux bare metal):
Interleaving, probably the best option on windows if you want to present a single numa node:
Sub numa cluster is disabled if you enable interleaving (as expected):
👤 cmoncure replied the 2025-06-01 at 19:34:56:
What's the easiest method to produce a file that simply applies the --runtime-repack transformation to an existing GGUF? I can run DeepSeek at Q_8 but the startup time is a killer.
👤 ubergarm replied the 2025-06-01 at 19:47:13:
What's the easiest method to produce a file that simply applies the --runtime-repack transformation to an existing GGUF?
I ran it once a few months ago but lost my logs and my rigs are tied up at the moment. Someone was asking me on reddit too: https://www.reddit.com/r/LocalLLaMA/comments/1kb97ys/comment/mvg837s/
If you want to repack everything for CPU inferencing, it is basically
./build/bin/llama-quantize --repack inputmodel outputmodelbut I haven't tested so let me know once u figure it out and I'll try to update the guide/model card with a reference and let that guy on reddit know.There is an option for regex matching if you only want to repack some tensors, check out
./build/bin/llama-quantize --helpor the code for more deets.👤 saood06 replied the 2025-06-02 at 00:49:12:
#274 and #272 are where you can find more details about this.👤 ubergarm replied the 2025-06-02 at 14:33:27:
Thanks @saood06 I couldn't find my old logs for this but apparently I'd buried a command in a detail fold over two months ago. So @cmoncure probably something like this would work if you want to repack all the attn/shexp layers to optimize for running without any GPU:$ ./build/bin/llama-quantize \ --repack \ /models/ubergarm/DeepSeek-R1-0528-GGUF/IQ2_K_R4/DeepSeek-R1-0528-IQ2_K_R4-00001-of-00005.gguf \ /models/DeepSeek-R1-0528-IQ2_K_R4-all-repacked.gguf \ IQ2_K_R4Then you should be able to start up with mmap() and no longer need to wait for
-rtr. Let me know if that works for you!👤 ciprianveg replied the 2025-06-02 at 14:53:10:
Thank you, I will try it this evening and let you know. Much appreciated.
👤 sousekd replied the 2025-06-24 at 13:48:04:
Hi everyone,
First, I want to sincerely thank @ikawrakow for this amazing repo (definitely deserves much more attention!), and @ubergarm for his excellent guides, insights, and quants. Big appreciation also goes out to unsloth and bartowski.
I'm currently building a new AI/LLM machine. Although it's still a WIP (with some cooling issues), I couldn't resist running some tests. The final setup will run Proxmox, and will have multiple GPUs, but for now, it is AMD Epyc 9355 with 768 GB RAM and single RTX 4090 running Windows.
Without much expertise, I managed to compile the library with:
cmake -B build -G Ninja ^
-DCMAKE_BUILD_TYPE=Release ^
-DLLAMA_CURL=OFF ^
-DGGML_CUDA=ON ^
-DGGML_BLAS=OFF ^
-DGGML_AVX512=ON ^
-DGGML_AVX512_VNNI=ON ^
-DGGML_AVX512_BF16=OFF ^
-DCMAKE_CUDA_ARCHITECTURES=89
cmake --build build --config Release -j $env:NUMBER_OF_PROCESSORS
Honestly, I’m unsure if I'm losing performance by disabling GGML_AVX512_BF16, but I couldn't compile it with MSVC otherwise. Similarly, I'm curious about any actual benefits from enabling both GGML_AVX512 and GGML_AVX512_VNNI as I have not seen them mentioned in the guide - so I'd love some insights here!
With ik-llama finally running, I tested DeepSeek-V3 quants with various params, and ended up with these:
- all of them:
--no-mmap --ctx-size 32768 -mla 3 -fa -amb 512 -fmoe --n-gpu-layers 63 --override-tensor exps=CPU --parallel 1 --threads 32 --threads-batch 56 - ubergarm/DeepSeek-V3-0324-IQ4_K_R4:
-ctk q8_0 - unsloth/DeepSeek-V3-0324-UD-Q4_K_XL:
-rtr - bartowski/DeepSeek-V3-0324-Q4_K_M-V2:
-rtr
Results
Observations and Thoughts
- Overall, these numbers seem great to me, provided they translate effectively to real-world usage. I'm particularly surprised by the stable token-generation speed across various context sizes.
- Interestingly, unsloth's quants benefited significantly from using fp16 kv-cache (default), whereas @ubergarm's quants performed best exclusively with q8_0. Bartowski's quants showed mixed effects (improved tg speed but reduced pp speed) with
fp16. - Increasing
threads-batchslightly improved prompt processing speed, but I don't think it justified the extra CPU load. - Raising the value of
-ambdidn't produce consistently measurable improvements.
Logs - ubergarm
.\build\bin\llama-sweep-bench.exe `
--alias $alias `
--model $model `
--no-mmap `
--ctx-size 32768 `
-ctk q8_0 `
-mla 3 -fa `
-amb 512 `
-fmoe `
--n-gpu-layers 63 `
--override-tensor exps=CPU `
--parallel 1 `
--threads 32 `
--threads-batch 56
**********************
version: 3762 (1843ed22)
built with MSVC 19.44.35211.0 for
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
llama_model_loader: additional 9 GGUFs metadata loaded.
llama_model_loader: loaded meta data with 53 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms
tudio\models\ubergarm\DeepSeek-V3-0324-GGUF\DeepSeek-V3-0324-IQ4_K_R4-00001-of-00010.gguf (version GGUF V3 (la
test))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = deepseek2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = DeepSeek V3 0324
llama_model_loader: - kv 3: general.version str = V3-0324
llama_model_loader: - kv 4: general.basename str = DeepSeek
llama_model_loader: - kv 5: general.size_label str = 256x21B
llama_model_loader: - kv 6: general.license str = mit
llama_model_loader: - kv 7: deepseek2.block_count u32 = 61
llama_model_loader: - kv 8: deepseek2.context_length u32 = 163840
llama_model_loader: - kv 9: deepseek2.embedding_length u32 = 7168
llama_model_loader: - kv 10: deepseek2.feed_forward_length u32 = 18432
llama_model_loader: - kv 11: deepseek2.attention.head_count u32 = 128
llama_model_loader: - kv 12: deepseek2.attention.head_count_kv u32 = 128
llama_model_loader: - kv 13: deepseek2.rope.freq_base f32 = 10000.000000
llama_model_loader: - kv 14: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 15: deepseek2.expert_used_count u32 = 8
llama_model_loader: - kv 16: general.file_type u32 = 340
llama_model_loader: - kv 17: deepseek2.leading_dense_block_count u32 = 3
llama_model_loader: - kv 18: deepseek2.vocab_size u32 = 129280
llama_model_loader: - kv 19: deepseek2.attention.q_lora_rank u32 = 1536
llama_model_loader: - kv 20: deepseek2.attention.kv_lora_rank u32 = 512
llama_model_loader: - kv 21: deepseek2.attention.key_length u32 = 192
llama_model_loader: - kv 22: deepseek2.attention.value_length u32 = 128
llama_model_loader: - kv 23: deepseek2.expert_feed_forward_length u32 = 2048
llama_model_loader: - kv 24: deepseek2.expert_count u32 = 256
llama_model_loader: - kv 25: deepseek2.expert_shared_count u32 = 1
llama_model_loader: - kv 26: deepseek2.expert_weights_scale f32 = 2.500000
llama_model_loader: - kv 27: deepseek2.expert_weights_norm bool = true
llama_model_loader: - kv 28: deepseek2.expert_gating_func u32 = 2
llama_model_loader: - kv 29: deepseek2.rope.dimension_count u32 = 64
llama_model_loader: - kv 30: deepseek2.rope.scaling.type str = yarn
llama_model_loader: - kv 31: deepseek2.rope.scaling.factor f32 = 40.000000
llama_model_loader: - kv 32: deepseek2.rope.scaling.original_context_length u32 = 4096
llama_model_loader: - kv 33: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000
llama_model_loader: - kv 34: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 35: tokenizer.ggml.pre str = deepseek-v3
llama_model_loader: - kv 36: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû
üsentence∩╜£>", "<∩...
llama_model_loader: - kv 37: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1,
1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 38: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", "
i n", "─á ─á", "h e...
llama_model_loader: - kv 39: tokenizer.ggml.bos_token_id u32 = 0
llama_model_loader: - kv 40: tokenizer.ggml.eos_token_id u32 = 1
llama_model_loader: - kv 41: tokenizer.ggml.padding_token_id u32 = 1
llama_model_loader: - kv 42: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 43: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 44: tokenizer.chat_template str = {% if not add_gene
ration_prompt is de...
llama_model_loader: - kv 45: general.quantization_version u32 = 2
llama_model_loader: - kv 46: quantize.imatrix.file str = /mnt/raid/models/u
bergarm/DeepSeek-V3...
llama_model_loader: - kv 47: quantize.imatrix.dataset str = calibration_data_v
5_rc.txt
llama_model_loader: - kv 48: quantize.imatrix.entries_count i32 = 720
llama_model_loader: - kv 49: quantize.imatrix.chunks_count i32 = 213
llama_model_loader: - kv 50: split.no u16 = 0
llama_model_loader: - kv 51: split.count u16 = 10
llama_model_loader: - kv 52: split.tensors.count i32 = 1147
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 612 tensors
llama_model_loader: - type iq4_k_r4: 116 tensors
llama_model_loader: - type iq5_k_r4: 58 tensors
llm_load_vocab: special tokens cache size = 818
llm_load_vocab: token to piece cache size = 0.8223 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = deepseek2
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 129280
llm_load_print_meta: n_merges = 127741
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 163840
llm_load_print_meta: n_embd = 7168
llm_load_print_meta: n_layer = 61
llm_load_print_meta: n_head = 128
llm_load_print_meta: n_head_kv = 128
llm_load_print_meta: n_rot = 64
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_swa_pattern = 1
llm_load_print_meta: n_embd_head_k = 192
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 24576
llm_load_print_meta: n_embd_v_gqa = 16384
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 18432
llm_load_print_meta: n_expert = 256
llm_load_print_meta: n_expert_used = 8
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = yarn
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 0.025
llm_load_print_meta: n_ctx_orig_yarn = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 671B
llm_load_print_meta: model ftype = IQ4_K_R4 - 4.5 bpw
llm_load_print_meta: model params = 672.050 B
llm_load_print_meta: model size = 386.183 GiB (4.936 BPW)
llm_load_print_meta: repeating layers = 384.349 GiB (4.926 BPW, 670.196 B parameters)
llm_load_print_meta: general.name = DeepSeek V3 0324
llm_load_print_meta: BOS token = 0 '<|begin▁of▁sentence|>'
llm_load_print_meta: EOS token = 1 '<|end▁of▁sentence|>'
llm_load_print_meta: PAD token = 1 '<|end▁of▁sentence|>'
llm_load_print_meta: LF token = 131 'Ä'
llm_load_print_meta: max token length = 256
llm_load_print_meta: n_layer_dense_lead = 3
llm_load_print_meta: n_lora_q = 1536
llm_load_print_meta: n_lora_kv = 512
llm_load_print_meta: n_ff_exp = 2048
llm_load_print_meta: n_expert_shared = 1
llm_load_print_meta: expert_weights_scale = 2.5
llm_load_print_meta: expert_weights_norm = 1
llm_load_print_meta: expert_gating_func = sigmoid
llm_load_print_meta: rope_yarn_log_mul = 0.1000
llm_load_tensors: ggml ctx size = 0.93 MiB
Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU
llm_load_tensors: offloading 61 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 62/62 layers to GPU
llm_load_tensors: CPU buffer size = 376768.00 MiB
llm_load_tensors: CUDA_Host buffer size = 938.98 MiB
llm_load_tensors: CUDA0 buffer size = 17744.02 MiB
....................................................................................................
llama_new_context_with_model: n_ctx = 32768
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: mla_attn = 3
llama_new_context_with_model: attn_max_b = 512
llama_new_context_with_model: fused_moe = 1
llama_new_context_with_model: ser = -1, 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 0.025
llama_kv_cache_init: CUDA0 KV buffer size = 1166.65 MiB
llama_new_context_with_model: KV self size = 1166.62 MiB, c^KV (q8_0): 1166.62 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 3425.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 176.01 MiB
llama_new_context_with_model: graph nodes = 8245
llama_new_context_with_model: graph splits = 118
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_t
hreads_batch = 56
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|-------|--------|--------|----------|----------|----------|----------|
| 512 | 128 | 0 | 4.466 | 114.64 | 10.403 | 12.30 |
| 512 | 128 | 512 | 4.320 | 118.52 | 9.744 | 13.14 |
| 512 | 128 | 1024 | 4.380 | 116.89 | 10.437 | 12.26 |
| 512 | 128 | 1536 | 4.487 | 114.11 | 10.327 | 12.40 |
| 512 | 128 | 2048 | 4.533 | 112.95 | 10.421 | 12.28 |
| 512 | 128 | 2560 | 4.559 | 112.31 | 10.471 | 12.22 |
| 512 | 128 | 3072 | 4.612 | 111.00 | 10.448 | 12.25 |
| 512 | 128 | 3584 | 4.745 | 107.91 | 10.462 | 12.24 |
| 512 | 128 | 4096 | 4.753 | 107.72 | 10.466 | 12.23 |
| 512 | 128 | 4608 | 4.759 | 107.58 | 10.519 | 12.17 |
| 512 | 128 | 5120 | 4.843 | 105.71 | 10.499 | 12.19 |
| 512 | 128 | 5632 | 4.875 | 105.02 | 10.533 | 12.15 |
| 512 | 128 | 6144 | 4.955 | 103.34 | 10.528 | 12.16 |
| 512 | 128 | 6656 | 4.934 | 103.76 | 10.497 | 12.19 |
| 512 | 128 | 7168 | 5.001 | 102.38 | 10.300 | 12.43 |
| 512 | 128 | 7680 | 5.047 | 101.45 | 10.569 | 12.11 |
| 512 | 128 | 8192 | 5.113 | 100.14 | 10.597 | 12.08 |
| 512 | 128 | 8704 | 5.131 | 99.78 | 10.629 | 12.04 |
| 512 | 128 | 9216 | 5.194 | 98.57 | 10.704 | 11.96 |
| 512 | 128 | 9728 | 5.251 | 97.50 | 10.628 | 12.04 |
| 512 | 128 | 10240 | 5.287 | 96.83 | 10.616 | 12.06 |
| 512 | 128 | 10752 | 5.365 | 95.43 | 10.650 | 12.02 |
| 512 | 128 | 11264 | 5.368 | 95.38 | 10.710 | 11.95 |
| 512 | 128 | 11776 | 5.458 | 93.81 | 10.627 | 12.05 |
| 512 | 128 | 12288 | 5.496 | 93.16 | 10.754 | 11.90 |
| 512 | 128 | 12800 | 5.529 | 92.60 | 10.733 | 11.93 |
| 512 | 128 | 13312 | 5.576 | 91.83 | 10.911 | 11.73 |
| 512 | 128 | 13824 | 5.619 | 91.13 | 10.819 | 11.83 |
| 512 | 128 | 14336 | 5.687 | 90.03 | 10.846 | 11.80 |
| 512 | 128 | 14848 | 5.691 | 89.96 | 10.810 | 11.84 |
| 512 | 128 | 15360 | 5.724 | 89.46 | 10.801 | 11.85 |
| 512 | 128 | 15872 | 5.760 | 88.89 | 10.873 | 11.77 |
| 512 | 128 | 16384 | 5.883 | 87.03 | 10.901 | 11.74 |
| 512 | 128 | 16896 | 5.841 | 87.65 | 10.957 | 11.68 |
| 512 | 128 | 17408 | 5.964 | 85.85 | 11.025 | 11.61 |
| 512 | 128 | 17920 | 5.997 | 85.37 | 11.007 | 11.63 |
| 512 | 128 | 18432 | 6.030 | 84.91 | 11.038 | 11.60 |
| 512 | 128 | 18944 | 6.049 | 84.64 | 11.101 | 11.53 |
| 512 | 128 | 19456 | 6.140 | 83.39 | 11.039 | 11.60 |
| 512 | 128 | 19968 | 6.148 | 83.28 | 11.076 | 11.56 |
| 512 | 128 | 20480 | 6.179 | 82.87 | 11.175 | 11.45 |
| 512 | 128 | 20992 | 6.191 | 82.70 | 11.187 | 11.44 |
| 512 | 128 | 21504 | 6.209 | 82.46 | 11.236 | 11.39 |
| 512 | 128 | 22016 | 6.239 | 82.06 | 11.281 | 11.35 |
| 512 | 128 | 22528 | 6.298 | 81.30 | 11.285 | 11.34 |
| 512 | 128 | 23040 | 6.322 | 80.98 | 11.125 | 11.51 |
| 512 | 128 | 23552 | 6.234 | 82.13 | 11.367 | 11.26 |
| 512 | 128 | 24064 | 6.310 | 81.14 | 11.266 | 11.36 |
| 512 | 128 | 24576 | 6.318 | 81.04 | 11.342 | 11.29 |
| 512 | 128 | 25088 | 6.376 | 80.30 | 11.466 | 11.16 |
| 512 | 128 | 25600 | 6.430 | 79.62 | 11.501 | 11.13 |
| 512 | 128 | 26112 | 6.458 | 79.28 | 11.450 | 11.18 |
| 512 | 128 | 26624 | 6.523 | 78.49 | 11.467 | 11.16 |
| 512 | 128 | 27136 | 6.561 | 78.04 | 11.488 | 11.14 |
| 512 | 128 | 27648 | 6.604 | 77.53 | 11.481 | 11.15 |
| 512 | 128 | 28160 | 6.645 | 77.05 | 11.459 | 11.17 |
| 512 | 128 | 28672 | 6.693 | 76.50 | 11.645 | 10.99 |
| 512 | 128 | 29184 | 6.755 | 75.79 | 11.578 | 11.06 |
| 512 | 128 | 29696 | 6.766 | 75.67 | 11.740 | 10.90 |
| 512 | 128 | 30208 | 6.836 | 74.89 | 11.603 | 11.03 |
| 512 | 128 | 30720 | 6.854 | 74.70 | 11.567 | 11.07 |
| 512 | 128 | 31232 | 6.929 | 73.89 | 11.580 | 11.05 |
| 512 | 128 | 31744 | 6.962 | 73.55 | 11.654 | 10.98 |
| 512 | 128 | 32256 | 7.028 | 72.85 | 11.674 | 10.96 |
Logs - unsloth
.\build\bin\llama-sweep-bench.exe `
--alias $alias `
--model $model `
--no-mmap `
--ctx-size 32768 `
-mla 3 -fa `
-amb 512 `
-fmoe `
-rtr `
--n-gpu-layers 63 `
--override-tensor exps=CPU `
--parallel 1 `
--threads 32 `
--threads-batch 56
**********************
version: 3762 (1843ed22)
built with MSVC 19.44.35211.0 for
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
llama_model_loader: additional 7 GGUFs metadata loaded.
llama_model_loader: loaded meta data with 64 key-value pairs and 1086 tensors from C:\Users\Administrator\.lms
tudio\models\unsloth\DeepSeek-V3-0324-GGUF-UD\DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf (version GGUF V3
(latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = deepseek2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Deepseek-V3-0324
llama_model_loader: - kv 3: general.version str = V3-0324
llama_model_loader: - kv 4: general.basename str = Deepseek-V3-0324
llama_model_loader: - kv 5: general.quantized_by str = Unsloth
llama_model_loader: - kv 6: general.size_label str = 256x20B
llama_model_loader: - kv 7: general.license str = mit
llama_model_loader: - kv 8: general.repo_url str = https://huggingfac
e.co/unsloth
llama_model_loader: - kv 9: general.base_model.count u32 = 1
llama_model_loader: - kv 10: general.base_model.0.name str = DeepSeek V3 0324
llama_model_loader: - kv 11: general.base_model.0.version str = V3-0324
llama_model_loader: - kv 12: general.base_model.0.organization str = Deepseek Ai
llama_model_loader: - kv 13: general.base_model.0.repo_url str = https://huggingfac
e.co/deepseek-ai/De...
llama_model_loader: - kv 14: general.tags arr[str,4] = ["deepseek_v3", "d
eepseek", "unsloth"...
llama_model_loader: - kv 15: general.languages arr[str,1] = ["en"]
llama_model_loader: - kv 16: deepseek2.block_count u32 = 61
llama_model_loader: - kv 17: deepseek2.context_length u32 = 163840
llama_model_loader: - kv 18: deepseek2.embedding_length u32 = 7168
llama_model_loader: - kv 19: deepseek2.feed_forward_length u32 = 18432
llama_model_loader: - kv 20: deepseek2.attention.head_count u32 = 128
llama_model_loader: - kv 21: deepseek2.attention.head_count_kv u32 = 1
llama_model_loader: - kv 22: deepseek2.rope.freq_base f32 = 10000.000000
llama_model_loader: - kv 23: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 24: deepseek2.expert_used_count u32 = 8
llama_model_loader: - kv 25: deepseek2.leading_dense_block_count u32 = 3
llama_model_loader: - kv 26: deepseek2.vocab_size u32 = 129280
llama_model_loader: - kv 27: deepseek2.attention.q_lora_rank u32 = 1536
llama_model_loader: - kv 28: deepseek2.attention.kv_lora_rank u32 = 512
llama_model_loader: - kv 29: deepseek2.attention.key_length u32 = 576
llama_model_loader: - kv 30: deepseek2.attention.value_length u32 = 512
llama_model_loader: - kv 31: deepseek2.attention.key_length_mla u32 = 192
llama_model_loader: - kv 32: deepseek2.attention.value_length_mla u32 = 128
llama_model_loader: - kv 33: deepseek2.expert_feed_forward_length u32 = 2048
llama_model_loader: - kv 34: deepseek2.expert_count u32 = 256
llama_model_loader: - kv 35: deepseek2.expert_shared_count u32 = 1
llama_model_loader: - kv 36: deepseek2.expert_weights_scale f32 = 2.500000
llama_model_loader: - kv 37: deepseek2.expert_weights_norm bool = true
llama_model_loader: - kv 38: deepseek2.expert_gating_func u32 = 2
llama_model_loader: - kv 39: deepseek2.rope.dimension_count u32 = 64
llama_model_loader: - kv 40: deepseek2.rope.scaling.type str = yarn
llama_model_loader: - kv 41: deepseek2.rope.scaling.factor f32 = 40.000000
llama_model_loader: - kv 42: deepseek2.rope.scaling.original_context_length u32 = 4096
llama_model_loader: - kv 43: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000
llama_model_loader: - kv 44: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 45: tokenizer.ggml.pre str = deepseek-v3
llama_model_loader: - kv 46: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû
üsentence∩╜£>", "<∩...
llama_model_loader: - kv 47: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1,
1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 48: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", "
i n", "─á ─á", "h e...
llama_model_loader: - kv 49: tokenizer.ggml.bos_token_id u32 = 0
llama_model_loader: - kv 50: tokenizer.ggml.eos_token_id u32 = 1
llama_model_loader: - kv 51: tokenizer.ggml.padding_token_id u32 = 2
llama_model_loader: - kv 52: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 53: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 54: tokenizer.chat_template str = {% if not add_gene
ration_prompt is de...
llama_model_loader: - kv 55: general.quantization_version u32 = 2
llama_model_loader: - kv 56: general.file_type u32 = 15
llama_model_loader: - kv 57: quantize.imatrix.file str = DeepSeek-V3-0324-G
GUF/imatrix_unsloth...
llama_model_loader: - kv 58: quantize.imatrix.dataset str = unsloth_calibratio
n_DeepSeek-V3-0324.txt
llama_model_loader: - kv 59: quantize.imatrix.entries_count i32 = 720
llama_model_loader: - kv 60: quantize.imatrix.chunks_count i32 = 60
llama_model_loader: - kv 61: split.no u16 = 0
llama_model_loader: - kv 62: split.tensors.count i32 = 1086
llama_model_loader: - kv 63: split.count u16 = 8
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 122 tensors
llama_model_loader: - type q4_K: 485 tensors
llama_model_loader: - type q5_K: 95 tensors
llama_model_loader: - type q6_K: 23 tensors
==========================================================================
Detected incompatible DeepSeek model.
Will try to fix, but there are no guarantees
*** Your prompt processing speed will be crippled ***
Consider making your own ik_llama.cpp compatible model or
ask the model provider to make one for you,
==========================================================================
llm_load_vocab: special tokens cache size = 818
llm_load_vocab: token to piece cache size = 0.8223 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = deepseek2
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 129280
llm_load_print_meta: n_merges = 127741
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 163840
llm_load_print_meta: n_embd = 7168
llm_load_print_meta: n_layer = 61
llm_load_print_meta: n_head = 128
llm_load_print_meta: n_head_kv = 128
llm_load_print_meta: n_rot = 64
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_swa_pattern = 1
llm_load_print_meta: n_embd_head_k = 192
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 24576
llm_load_print_meta: n_embd_v_gqa = 16384
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 18432
llm_load_print_meta: n_expert = 256
llm_load_print_meta: n_expert_used = 8
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = yarn
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 0.025
llm_load_print_meta: n_ctx_orig_yarn = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 671B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 671.026 B
llm_load_print_meta: model size = 357.623 GiB (4.578 BPW)
llm_load_print_meta: repeating layers = 356.429 GiB (4.575 BPW, 669.173 B parameters)
llm_load_print_meta: general.name = Deepseek-V3-0324
llm_load_print_meta: BOS token = 0 '<|begin▁of▁sentence|>'
llm_load_print_meta: EOS token = 1 '<|end▁of▁sentence|>'
llm_load_print_meta: PAD token = 2 '<|▁pad▁|>'
llm_load_print_meta: LF token = 131 'Ä'
llm_load_print_meta: max token length = 256
llm_load_print_meta: n_layer_dense_lead = 3
llm_load_print_meta: n_lora_q = 1536
llm_load_print_meta: n_lora_kv = 512
llm_load_print_meta: n_ff_exp = 2048
llm_load_print_meta: n_expert_shared = 1
llm_load_print_meta: expert_weights_scale = 2.5
llm_load_print_meta: expert_weights_norm = 1
llm_load_print_meta: expert_gating_func = sigmoid
llm_load_print_meta: rope_yarn_log_mul = 0.1000
llm_load_tensors: ggml ctx size = 0.89 MiB
Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU
llm_load_tensors: offloading 61 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 62/62 layers to GPU
llm_load_tensors: CPU buffer size = 355712.00 MiB
llm_load_tensors: CUDA_Host buffer size = 497.11 MiB
llm_load_tensors: CUDA0 buffer size = 9996.68 MiB
....................................................................................................
============ llm_prepare_mla: need to compute 61 wkv_b tensors
Computed blk.0.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.1.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.2.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.3.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.4.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.5.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.6.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.7.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.8.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.9.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.10.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.11.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.12.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.13.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.14.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.15.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.16.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.17.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.18.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.19.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.20.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.21.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.22.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.23.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.24.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.25.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.26.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.27.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.28.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.29.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.30.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.31.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.32.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.33.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.34.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.35.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.36.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.37.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.38.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.39.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.40.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.41.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.42.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.43.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.44.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.45.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.46.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.47.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.48.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.49.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.50.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.51.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.52.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.53.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.54.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.55.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.56.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.57.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.58.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.59.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
Computed blk.60.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0
============ Repacked 174 tensors
llama_new_context_with_model: n_ctx = 32768
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: mla_attn = 3
llama_new_context_with_model: attn_max_b = 512
llama_new_context_with_model: fused_moe = 1
llama_new_context_with_model: ser = -1, 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 0.025
llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB
llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 3393.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 176.01 MiB
llama_new_context_with_model: graph nodes = 8184
llama_new_context_with_model: graph splits = 118
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_t
hreads_batch = 56
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|-------|--------|--------|----------|----------|----------|----------|
| 512 | 128 | 0 | 3.817 | 134.15 | 8.525 | 15.01 |
| 512 | 128 | 512 | 3.815 | 134.20 | 8.333 | 15.36 |
| 512 | 128 | 1024 | 3.861 | 132.61 | 7.549 | 16.96 |
| 512 | 128 | 1536 | 3.945 | 129.79 | 7.784 | 16.44 |
| 512 | 128 | 2048 | 4.024 | 127.22 | 7.767 | 16.48 |
| 512 | 128 | 2560 | 4.071 | 125.77 | 7.734 | 16.55 |
| 512 | 128 | 3072 | 4.104 | 124.77 | 7.632 | 16.77 |
| 512 | 128 | 3584 | 4.118 | 124.34 | 7.538 | 16.98 |
| 512 | 128 | 4096 | 4.149 | 123.42 | 7.642 | 16.75 |
| 512 | 128 | 4608 | 4.203 | 121.81 | 7.593 | 16.86 |
| 512 | 128 | 5120 | 4.269 | 119.93 | 7.552 | 16.95 |
| 512 | 128 | 5632 | 4.385 | 116.76 | 7.895 | 16.21 |
| 512 | 128 | 6144 | 4.354 | 117.58 | 7.571 | 16.91 |
| 512 | 128 | 6656 | 4.401 | 116.34 | 7.799 | 16.41 |
| 512 | 128 | 7168 | 4.444 | 115.22 | 7.713 | 16.59 |
| 512 | 128 | 7680 | 4.476 | 114.38 | 7.560 | 16.93 |
| 512 | 128 | 8192 | 4.529 | 113.04 | 7.869 | 16.27 |
| 512 | 128 | 8704 | 4.582 | 111.74 | 7.763 | 16.49 |
| 512 | 128 | 9216 | 4.623 | 110.75 | 8.812 | 14.53 |
| 512 | 128 | 9728 | 4.578 | 111.83 | 7.681 | 16.67 |
| 512 | 128 | 10240 | 4.657 | 109.93 | 8.100 | 15.80 |
| 512 | 128 | 10752 | 4.645 | 110.23 | 7.979 | 16.04 |
| 512 | 128 | 11264 | 4.689 | 109.20 | 7.788 | 16.44 |
| 512 | 128 | 11776 | 4.712 | 108.66 | 7.848 | 16.31 |
| 512 | 128 | 12288 | 4.760 | 107.56 | 8.004 | 15.99 |
| 512 | 128 | 12800 | 4.782 | 107.06 | 7.851 | 16.30 |
| 512 | 128 | 13312 | 4.799 | 106.68 | 7.854 | 16.30 |
| 512 | 128 | 13824 | 4.824 | 106.13 | 8.000 | 16.00 |
| 512 | 128 | 14336 | 4.874 | 105.06 | 7.954 | 16.09 |
| 512 | 128 | 14848 | 4.907 | 104.33 | 7.955 | 16.09 |
| 512 | 128 | 15360 | 4.959 | 103.25 | 7.978 | 16.04 |
| 512 | 128 | 15872 | 4.999 | 102.42 | 8.069 | 15.86 |
| 512 | 128 | 16384 | 5.132 | 99.77 | 8.207 | 15.60 |
| 512 | 128 | 16896 | 5.173 | 98.97 | 8.071 | 15.86 |
| 512 | 128 | 17408 | 5.225 | 97.99 | 8.193 | 15.62 |
| 512 | 128 | 17920 | 5.285 | 96.88 | 8.241 | 15.53 |
| 512 | 128 | 18432 | 5.314 | 96.34 | 8.116 | 15.77 |
| 512 | 128 | 18944 | 5.367 | 95.40 | 8.320 | 15.38 |
| 512 | 128 | 19456 | 5.393 | 94.93 | 8.097 | 15.81 |
| 512 | 128 | 19968 | 5.458 | 93.80 | 8.255 | 15.51 |
| 512 | 128 | 20480 | 5.501 | 93.07 | 8.299 | 15.42 |
| 512 | 128 | 20992 | 5.554 | 92.19 | 8.348 | 15.33 |
| 512 | 128 | 21504 | 5.592 | 91.56 | 8.309 | 15.41 |
| 512 | 128 | 22016 | 5.630 | 90.94 | 8.290 | 15.44 |
| 512 | 128 | 22528 | 5.688 | 90.01 | 8.290 | 15.44 |
| 512 | 128 | 23040 | 5.742 | 89.16 | 8.328 | 15.37 |
| 512 | 128 | 23552 | 5.732 | 89.32 | 8.413 | 15.21 |
| 512 | 128 | 24064 | 5.794 | 88.37 | 8.332 | 15.36 |
| 512 | 128 | 24576 | 5.827 | 87.87 | 8.407 | 15.22 |
| 512 | 128 | 25088 | 5.858 | 87.40 | 8.496 | 15.07 |
| 512 | 128 | 25600 | 5.927 | 86.38 | 8.373 | 15.29 |
| 512 | 128 | 26112 | 5.940 | 86.20 | 8.351 | 15.33 |
| 512 | 128 | 26624 | 6.010 | 85.20 | 8.577 | 14.92 |
| 512 | 128 | 27136 | 6.041 | 84.75 | 8.469 | 15.11 |
| 512 | 128 | 27648 | 6.100 | 83.93 | 8.559 | 14.96 |
| 512 | 128 | 28160 | 6.129 | 83.54 | 8.455 | 15.14 |
| 512 | 128 | 28672 | 6.172 | 82.95 | 8.481 | 15.09 |
| 512 | 128 | 29184 | 6.246 | 81.97 | 8.614 | 14.86 |
| 512 | 128 | 29696 | 6.262 | 81.76 | 8.672 | 14.76 |
| 512 | 128 | 30208 | 6.315 | 81.08 | 8.628 | 14.84 |
| 512 | 128 | 30720 | 6.357 | 80.54 | 8.561 | 14.95 |
| 512 | 128 | 31232 | 6.401 | 79.99 | 8.638 | 14.82 |
| 512 | 128 | 31744 | 6.482 | 78.99 | 8.723 | 14.67 |
| 512 | 128 | 32256 | 6.521 | 78.51 | 8.618 | 14.85 |
Logs - bartowski
.\build\bin\llama-sweep-bench.exe `
--alias $alias `
--model $model `
--no-mmap `
--ctx-size 32768 `
-mla 3 -fa `
-amb 512 `
-fmoe `
-rtr `
--n-gpu-layers 63 `
--override-tensor exps=CPU `
--parallel 1 `
--threads 32 `
--threads-batch 56
**********************
version: 3762 (1843ed22)
built with MSVC 19.44.35211.0 for
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
llama_model_loader: additional 10 GGUFs metadata loaded.
llama_model_loader: loaded meta data with 53 key-value pairs and 1025 tensors from C:\Users\Administrator\.lms
tudio\models\bartowski\deepseek-ai_DeepSeek-V3-0324-GGUF\deepseek-ai_DeepSeek-V3-0324-Q4_K_M-V2-00001-of-00011
.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = deepseek2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = DeepSeek V3 0324
llama_model_loader: - kv 3: general.version str = V3-0324
llama_model_loader: - kv 4: general.basename str = DeepSeek
llama_model_loader: - kv 5: general.size_label str = 256x20B
llama_model_loader: - kv 6: general.license str = mit
llama_model_loader: - kv 7: deepseek2.block_count u32 = 61
llama_model_loader: - kv 8: deepseek2.context_length u32 = 163840
llama_model_loader: - kv 9: deepseek2.embedding_length u32 = 7168
llama_model_loader: - kv 10: deepseek2.feed_forward_length u32 = 18432
llama_model_loader: - kv 11: deepseek2.attention.head_count u32 = 128
llama_model_loader: - kv 12: deepseek2.attention.head_count_kv u32 = 128
llama_model_loader: - kv 13: deepseek2.rope.freq_base f32 = 10000.000000
llama_model_loader: - kv 14: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 15: deepseek2.expert_used_count u32 = 8
llama_model_loader: - kv 16: deepseek2.leading_dense_block_count u32 = 3
llama_model_loader: - kv 17: deepseek2.vocab_size u32 = 129280
llama_model_loader: - kv 18: deepseek2.attention.q_lora_rank u32 = 1536
llama_model_loader: - kv 19: deepseek2.attention.kv_lora_rank u32 = 512
llama_model_loader: - kv 20: deepseek2.attention.key_length u32 = 192
llama_model_loader: - kv 21: deepseek2.attention.value_length u32 = 128
llama_model_loader: - kv 22: deepseek2.expert_feed_forward_length u32 = 2048
llama_model_loader: - kv 23: deepseek2.expert_count u32 = 256
llama_model_loader: - kv 24: deepseek2.expert_shared_count u32 = 1
llama_model_loader: - kv 25: deepseek2.expert_weights_scale f32 = 2.500000
llama_model_loader: - kv 26: deepseek2.expert_weights_norm bool = true
llama_model_loader: - kv 27: deepseek2.expert_gating_func u32 = 2
llama_model_loader: - kv 28: deepseek2.rope.dimension_count u32 = 64
llama_model_loader: - kv 29: deepseek2.rope.scaling.type str = yarn
llama_model_loader: - kv 30: deepseek2.rope.scaling.factor f32 = 40.000000
llama_model_loader: - kv 31: deepseek2.rope.scaling.original_context_length u32 = 4096
llama_model_loader: - kv 32: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000
llama_model_loader: - kv 33: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 34: tokenizer.ggml.pre str = deepseek-v3
llama_model_loader: - kv 35: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû
üsentence∩╜£>", "<∩...
llama_model_loader: - kv 36: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1,
1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 37: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", "
i n", "─á ─á", "h e...
llama_model_loader: - kv 38: tokenizer.ggml.bos_token_id u32 = 0
llama_model_loader: - kv 39: tokenizer.ggml.eos_token_id u32 = 1
llama_model_loader: - kv 40: tokenizer.ggml.padding_token_id u32 = 1
llama_model_loader: - kv 41: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 42: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 43: tokenizer.chat_template str = {% if not add_gene
ration_prompt is de...
llama_model_loader: - kv 44: general.quantization_version u32 = 2
llama_model_loader: - kv 45: general.file_type u32 = 15
llama_model_loader: - kv 46: quantize.imatrix.file str = /models/DeepSeek-V
3-0324-GGUF/DeepSee...
llama_model_loader: - kv 47: quantize.imatrix.dataset str = /workspace/calibra
tion_datav3.txt
llama_model_loader: - kv 48: quantize.imatrix.entries_count i32 = 720
llama_model_loader: - kv 49: quantize.imatrix.chunks_count i32 = 124
llama_model_loader: - kv 50: split.no u16 = 0
llama_model_loader: - kv 51: split.tensors.count i32 = 1025
llama_model_loader: - kv 52: split.count u16 = 11
llama_model_loader: - type f32: 361 tensors
llama_model_loader: - type q8_0: 151 tensors
llama_model_loader: - type q4_K: 154 tensors
llama_model_loader: - type q5_K: 153 tensors
llama_model_loader: - type q6_K: 206 tensors
llm_load_vocab: special tokens cache size = 818
llm_load_vocab: token to piece cache size = 0.8223 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = deepseek2
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 129280
llm_load_print_meta: n_merges = 127741
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 163840
llm_load_print_meta: n_embd = 7168
llm_load_print_meta: n_layer = 61
llm_load_print_meta: n_head = 128
llm_load_print_meta: n_head_kv = 128
llm_load_print_meta: n_rot = 64
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_swa_pattern = 1
llm_load_print_meta: n_embd_head_k = 192
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 24576
llm_load_print_meta: n_embd_v_gqa = 16384
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 18432
llm_load_print_meta: n_expert = 256
llm_load_print_meta: n_expert_used = 8
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = yarn
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 0.025
llm_load_print_meta: n_ctx_orig_yarn = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 671B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 671.026 B
llm_load_print_meta: model size = 379.030 GiB (4.852 BPW)
llm_load_print_meta: repeating layers = 377.836 GiB (4.850 BPW, 669.173 B parameters)
llm_load_print_meta: general.name = DeepSeek V3 0324
llm_load_print_meta: BOS token = 0 '<|begin▁of▁sentence|>'
llm_load_print_meta: EOS token = 1 '<|end▁of▁sentence|>'
llm_load_print_meta: PAD token = 1 '<|end▁of▁sentence|>'
llm_load_print_meta: LF token = 131 'Ä'
llm_load_print_meta: max token length = 256
llm_load_print_meta: n_layer_dense_lead = 3
llm_load_print_meta: n_lora_q = 1536
llm_load_print_meta: n_lora_kv = 512
llm_load_print_meta: n_ff_exp = 2048
llm_load_print_meta: n_expert_shared = 1
llm_load_print_meta: expert_weights_scale = 2.5
llm_load_print_meta: expert_weights_norm = 1
llm_load_print_meta: expert_gating_func = sigmoid
llm_load_print_meta: rope_yarn_log_mul = 0.1000
llm_load_tensors: ggml ctx size = 0.85 MiB
Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU
Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU
llm_load_tensors: offloading 61 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 62/62 layers to GPU
llm_load_tensors: CPU buffer size = 375732.00 MiB
llm_load_tensors: CUDA_Host buffer size = 497.11 MiB
llm_load_tensors: CUDA0 buffer size = 11897.18 MiB
....................................................................................................
============ llm_prepare_mla: need to compute 61 wk_b/wv_b tensors
Computed blk.0.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.1.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.2.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.3.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.4.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.5.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.6.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.7.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.8.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.9.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.10.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.11.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.12.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.13.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.14.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.15.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.16.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.17.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.18.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.19.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.20.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.21.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.22.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.23.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.24.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.25.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.26.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.27.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.28.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.29.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.30.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.31.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.32.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.33.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.34.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.35.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.36.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.37.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.38.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.39.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.40.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.41.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.42.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.43.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.44.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.45.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.46.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.47.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.48.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.49.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.50.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.51.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.52.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.53.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.54.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.55.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.56.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.57.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.58.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.59.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
Computed blk.60.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0
============ Repacked 174 tensors
llama_new_context_with_model: n_ctx = 32768
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: mla_attn = 3
llama_new_context_with_model: attn_max_b = 512
llama_new_context_with_model: fused_moe = 1
llama_new_context_with_model: ser = -1, 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 0.025
llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB
llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 3393.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 176.01 MiB
llama_new_context_with_model: graph nodes = 8184
llama_new_context_with_model: graph splits = 118
main: n_kv_max = 32768, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_t
hreads_batch = 56
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|-------|--------|--------|----------|----------|----------|----------|
| 512 | 128 | 0 | 3.950 | 129.61 | 9.283 | 13.79 |
| 512 | 128 | 512 | 3.854 | 132.87 | 8.692 | 14.73 |
| 512 | 128 | 1024 | 3.896 | 131.43 | 7.995 | 16.01 |
| 512 | 128 | 1536 | 3.941 | 129.92 | 7.937 | 16.13 |
| 512 | 128 | 2048 | 4.032 | 126.98 | 8.095 | 15.81 |
| 512 | 128 | 2560 | 4.089 | 125.21 | 7.976 | 16.05 |
| 512 | 128 | 3072 | 4.147 | 123.46 | 8.157 | 15.69 |
| 512 | 128 | 3584 | 4.216 | 121.43 | 8.032 | 15.94 |
| 512 | 128 | 4096 | 4.256 | 120.29 | 8.188 | 15.63 |
| 512 | 128 | 4608 | 4.283 | 119.53 | 8.253 | 15.51 |
| 512 | 128 | 5120 | 4.316 | 118.62 | 8.226 | 15.56 |
| 512 | 128 | 5632 | 4.352 | 117.63 | 8.121 | 15.76 |
| 512 | 128 | 6144 | 4.414 | 116.00 | 8.245 | 15.52 |
| 512 | 128 | 6656 | 4.462 | 114.74 | 8.311 | 15.40 |
| 512 | 128 | 7168 | 4.496 | 113.88 | 8.353 | 15.32 |
| 512 | 128 | 7680 | 4.552 | 112.47 | 8.287 | 15.45 |
| 512 | 128 | 8192 | 4.592 | 111.50 | 8.256 | 15.50 |
| 512 | 128 | 8704 | 4.640 | 110.35 | 8.329 | 15.37 |
| 512 | 128 | 9216 | 4.664 | 109.78 | 8.139 | 15.73 |
| 512 | 128 | 9728 | 4.641 | 110.31 | 8.282 | 15.46 |
| 512 | 128 | 10240 | 4.698 | 108.98 | 8.345 | 15.34 |
| 512 | 128 | 10752 | 4.823 | 106.15 | 8.338 | 15.35 |
| 512 | 128 | 11264 | 4.769 | 107.37 | 8.185 | 15.64 |
| 512 | 128 | 11776 | 4.788 | 106.94 | 8.234 | 15.55 |
| 512 | 128 | 12288 | 4.805 | 106.55 | 8.362 | 15.31 |
| 512 | 128 | 12800 | 4.840 | 105.78 | 8.406 | 15.23 |
| 512 | 128 | 13312 | 4.872 | 105.08 | 8.462 | 15.13 |
| 512 | 128 | 13824 | 4.891 | 104.67 | 8.502 | 15.05 |
| 512 | 128 | 14336 | 4.926 | 103.94 | 8.442 | 15.16 |
| 512 | 128 | 14848 | 4.968 | 103.06 | 8.467 | 15.12 |
| 512 | 128 | 15360 | 5.013 | 102.13 | 8.447 | 15.15 |
| 512 | 128 | 15872 | 5.061 | 101.17 | 8.454 | 15.14 |
| 512 | 128 | 16384 | 5.278 | 97.00 | 8.493 | 15.07 |
| 512 | 128 | 16896 | 5.319 | 96.26 | 8.635 | 14.82 |
| 512 | 128 | 17408 | 5.370 | 95.35 | 8.593 | 14.90 |
| 512 | 128 | 17920 | 5.421 | 94.45 | 8.562 | 14.95 |
| 512 | 128 | 18432 | 5.463 | 93.72 | 8.544 | 14.98 |
| 512 | 128 | 18944 | 5.494 | 93.20 | 8.546 | 14.98 |
| 512 | 128 | 19456 | 5.562 | 92.05 | 8.696 | 14.72 |
| 512 | 128 | 19968 | 5.612 | 91.24 | 8.595 | 14.89 |
| 512 | 128 | 20480 | 5.643 | 90.73 | 8.723 | 14.67 |
| 512 | 128 | 20992 | 5.695 | 89.91 | 8.771 | 14.59 |
| 512 | 128 | 21504 | 5.742 | 89.17 | 8.640 | 14.82 |
| 512 | 128 | 22016 | 5.761 | 88.87 | 8.794 | 14.55 |
| 512 | 128 | 22528 | 5.836 | 87.74 | 8.721 | 14.68 |
| 512 | 128 | 23040 | 5.880 | 87.08 | 8.841 | 14.48 |
| 512 | 128 | 23552 | 5.784 | 88.52 | 8.717 | 14.68 |
| 512 | 128 | 24064 | 5.848 | 87.55 | 8.923 | 14.34 |
| 512 | 128 | 24576 | 5.884 | 87.02 | 8.957 | 14.29 |
| 512 | 128 | 25088 | 5.931 | 86.33 | 8.984 | 14.25 |
| 512 | 128 | 25600 | 5.979 | 85.63 | 8.937 | 14.32 |
| 512 | 128 | 26112 | 6.015 | 85.12 | 8.982 | 14.25 |
| 512 | 128 | 26624 | 6.064 | 84.43 | 8.944 | 14.31 |
| 512 | 128 | 27136 | 6.122 | 83.63 | 8.948 | 14.31 |
| 512 | 128 | 27648 | 6.154 | 83.19 | 8.957 | 14.29 |
| 512 | 128 | 28160 | 6.211 | 82.44 | 9.005 | 14.21 |
| 512 | 128 | 28672 | 6.233 | 82.15 | 9.097 | 14.07 |
| 512 | 128 | 29184 | 6.302 | 81.24 | 9.255 | 13.83 |
| 512 | 128 | 29696 | 6.318 | 81.03 | 9.052 | 14.14 |
| 512 | 128 | 30208 | 6.389 | 80.14 | 9.392 | 13.63 |
| 512 | 128 | 30720 | 6.411 | 79.87 | 9.156 | 13.98 |
| 512 | 128 | 31232 | 6.483 | 78.97 | 9.254 | 13.83 |
| 512 | 128 | 31744 | 6.539 | 78.31 | 9.165 | 13.97 |
| 512 | 128 | 32256 | 6.611 | 77.44 | 9.009 | 14.21 |
I have NPS0 set in BIOS, and "LLC as NUMA domain (ACPI SRAT L3 Cache as NUMA domain)" ENABLED. It might be worth re-testing with this option DISABLED. I will test smaller and larger quants, too, but downloads take ages 😃.
Anyway, just wanted to say "thanks" and share my excitement 💯. Any tips, insights or discussion would be welcome.
👤 cmoncure replied the 2025-06-25 at 22:33:44:
Great post. Your perf results track with my similar system (EPYC 9175F), with your PP about 1.3x bigger than mine at low context, I guess due to having 32 cores to my 16. All your remarks about command line flags impact on performance track with my observations. I don't know how to make it run faster so I will just recommend that applying a permanent repack to the quant is fairly easy and straightforward so consider it when you're bored of waiting for -rtr.👤 sousekd replied the 2025-06-27 at 23:10:41:
Okay, so after spending several hours benchmarking and trying various stuff to little effect, I managed to squeeze out slightly better results. Here's what I did:
- Disabled "LLC as NUMA domain (ACPI SRAT L3 Cache as NUMA domain)" in the BIOS.
- Enabled "Lock Pages in Memory" via the Local Security Policy in Windows.
- Switched the build to clang-cl and compiled with the following flags:
-DGGML_SCHED_MAX_COPIES=1-DCMAKE_CUDA_ARCHITECTURES="89-real"-DCMAKE_INTERPROCEDURAL_OPTIMIZATION=ON- Reduced the number of threads to
--threads 30and increased the batch size to-b 4096(and-ub 4096for Unsloth).I also experimented with several other build parameters such as:
-DGGML_CUDA_F16=ON-DGGML_CUDA_FORCE_MMQ=ON-DGGML_CUDA_USE_GRAPHS=ON-DGGML_CUDA_FA_ALL_QUANTS=ON-DGGML_CUDA_IQK_FORCE_BF16=ON-DGGML_IQK_FA_ALL_QUANTS=1…but didn't notice any measurable impact. My full
cmakecommand looks like this:cmake -B build -G Ninja ` -DCMAKE_BUILD_TYPE=Release ` -DCMAKE_C_COMPILER="clang-cl" ` -DCMAKE_CXX_COMPILER="clang-cl" ` -DCMAKE_CUDA_HOST_COMPILER="cl.exe" ` -DGGML_CUDA=ON ` -DGGML_AVX512=ON ` -DGGML_AVX512_VNNI=ON ` -DGGML_AVX512_VBMI=ON ` -DGGML_AVX512_BF16=ON ` -DGGML_BLAS=OFF ` -DGGML_SCHED_MAX_COPIES=1 ` -DCMAKE_C_FLAGS='/clang:-march=znver5' ` -DCMAKE_CXX_FLAGS='/EHsc /clang:-march=znver5' ` -DCMAKE_CUDA_ARCHITECTURES="89-real" ` -DCMAKE_INTERPROCEDURAL_OPTIMIZATION=ON ` -DLLAMA_CURL=OFF ` -DBUILD_SHARED_LIBS=OFFHere are the results:

ubergarm_DeepSeek-V3-0324-IQ2_K_R4
PS> .\bin\llama-server --version version: 3772 (5236c98b) built with Clang 19.1.5 for PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 2048 ` -ctk q8_0 ` -c 32768 ` -ngl 63 ` -ot exps=CPU ` --threads 30 ` --threads-batch 30 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes llama_model_loader: additional 4 GGUFs metadata loaded. llama_model_loader: loaded meta data with 53 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms tudio\models\ubergarm\DeepSeek-V3-0324-GGUF\DeepSeek-V3-0324-IQ2_K_R4-00001-of-00005.gguf (version GGUF V3 (la test)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek V3 0324 llama_model_loader: - kv 3: general.version str = V3-0324 llama_model_loader: - kv 4: general.basename str = DeepSeek llama_model_loader: - kv 5: general.size_label str = 256x21B llama_model_loader: - kv 6: general.license str = mit llama_model_loader: - kv 7: deepseek2.block_count u32 = 61 llama_model_loader: - kv 8: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 9: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 10: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 11: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 12: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 13: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 14: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 15: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 16: general.file_type u32 = 338 llama_model_loader: - kv 17: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 18: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 19: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 20: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 21: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 22: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 23: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 24: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 25: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 26: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 27: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 28: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 29: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 30: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 31: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 32: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 33: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 34: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 35: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 36: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 37: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 38: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 39: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 40: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 41: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 42: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 43: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 44: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 45: general.quantization_version u32 = 2 llama_model_loader: - kv 46: quantize.imatrix.file str = /mnt/raid/models/u bergarm/DeepSeek-V3... llama_model_loader: - kv 47: quantize.imatrix.dataset str = calibration_data_v 5_rc.txt llama_model_loader: - kv 48: quantize.imatrix.entries_count i32 = 720 llama_model_loader: - kv 49: quantize.imatrix.chunks_count i32 = 213 llama_model_loader: - kv 50: split.no u16 = 0 llama_model_loader: - kv 51: split.count u16 = 5 llama_model_loader: - kv 52: split.tensors.count i32 = 1147 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 612 tensors llama_model_loader: - type iq2_k_r4: 116 tensors llama_model_loader: - type iq3_k_r4: 58 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = IQ2_K_R4 - 2.375 bpw llm_load_print_meta: model params = 672.050 B llm_load_print_meta: model size = 226.003 GiB (2.889 BPW) llm_load_print_meta: repeating layers = 224.169 GiB (2.873 BPW, 670.196 B parameters) llm_load_print_meta: general.name = DeepSeek V3 0324 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.93 MiB Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 938.98 MiB llm_load_tensors: CPU buffer size = 212744.00 MiB llm_load_tensors: CUDA0 buffer size = 17744.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 2048 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 1166.65 MiB llama_new_context_with_model: KV self size = 1166.62 MiB, c^KV (q8_0): 1166.62 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 3588.01 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 312.02 MiB llama_new_context_with_model: graph nodes = 8245 llama_new_context_with_model: graph splits = 118 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 2048, flash_attn = 1, n_gpu_layers = 63, n_threads = 30, n_ threads_batch = 30 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 2048 | 512 | 0 | 15.290 | 133.95 | 28.471 | 17.98 | | 2048 | 512 | 2048 | 15.612 | 131.18 | 28.960 | 17.68 | | 2048 | 512 | 4096 | 15.980 | 128.16 | 30.046 | 17.04 | | 2048 | 512 | 6144 | 16.307 | 125.59 | 30.095 | 17.01 | | 2048 | 512 | 8192 | 16.691 | 122.70 | 30.578 | 16.74 | | 2048 | 512 | 10240 | 17.080 | 119.91 | 31.082 | 16.47 | | 2048 | 512 | 12288 | 17.437 | 117.45 | 31.874 | 16.06 | | 2048 | 512 | 14336 | 17.780 | 115.18 | 32.039 | 15.98 | | 2048 | 512 | 16384 | 18.214 | 112.44 | 32.559 | 15.73 | | 2048 | 512 | 18432 | 18.611 | 110.04 | 33.341 | 15.36 | | 2048 | 512 | 20480 | 18.972 | 107.95 | 33.402 | 15.33 | | 2048 | 512 | 22528 | 19.330 | 105.95 | 33.656 | 15.21 | | 2048 | 512 | 24576 | 19.687 | 104.03 | 34.162 | 14.99 | | 2048 | 512 | 26624 | 20.033 | 102.23 | 34.425 | 14.87 | | 2048 | 512 | 28672 | 20.425 | 100.27 | 35.012 | 14.62 | | 2048 | 512 | 30720 | 20.769 | 98.61 | 35.254 | 14.52 |ubergarm_DeepSeek-R1-0528-IQ4_KS_R4
PS> .\bin\llama-server --version version: 3772 (5236c98b) built with Clang 19.1.5 for PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 ` -ctk q8_0 ` -c 32768 ` -ngl 63 ` -ot exps=CPU ` --threads 30 ` --threads-batch 30 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes llama_model_loader: additional 8 GGUFs metadata loaded. llama_model_loader: loaded meta data with 52 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms tudio\models\ubergarm\DeepSeek-R1-0528-GGUF\DeepSeek-R1-0528-IQ4_KS_R4-00001-of-00009.gguf (version GGUF V3 (l atest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek R1 0528 llama_model_loader: - kv 3: general.version str = 0528 llama_model_loader: - kv 4: general.basename str = DeepSeek-R1 llama_model_loader: - kv 5: general.size_label str = 256x21B llama_model_loader: - kv 6: deepseek2.block_count u32 = 61 llama_model_loader: - kv 7: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 8: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 9: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 10: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 11: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 12: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 13: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 14: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 15: general.file_type u32 = 345 llama_model_loader: - kv 16: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 17: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 18: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 19: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 20: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 21: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 22: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 23: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 24: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 25: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 26: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 27: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 28: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 29: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 30: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 31: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 32: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 33: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 34: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 35: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 36: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 37: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 38: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 39: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 40: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 41: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 42: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 43: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 44: general.quantization_version u32 = 2 llama_model_loader: - kv 45: quantize.imatrix.file str = /mnt/raid/models/u bergarm/DeepSeek-R1... llama_model_loader: - kv 46: quantize.imatrix.dataset str = ubergarm-imatrix-c alibration-corpus-v... llama_model_loader: - kv 47: quantize.imatrix.entries_count i32 = 721 llama_model_loader: - kv 48: quantize.imatrix.chunks_count i32 = 812 llama_model_loader: - kv 49: split.no u16 = 0 llama_model_loader: - kv 50: split.count u16 = 9 llama_model_loader: - kv 51: split.tensors.count i32 = 1147 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 612 tensors llama_model_loader: - type iq4_ks_r4: 116 tensors llama_model_loader: - type iq5_ks_r4: 58 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = IQ4_KS_R4 - 4.25 bpw llm_load_print_meta: model params = 672.050 B llm_load_print_meta: model size = 367.774 GiB (4.701 BPW) llm_load_print_meta: repeating layers = 365.940 GiB (4.690 BPW, 670.196 B parameters) llm_load_print_meta: general.name = DeepSeek R1 0528 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.93 MiB Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 938.98 MiB llm_load_tensors: CPU buffer size = 357918.00 MiB llm_load_tensors: CUDA0 buffer size = 17744.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 512 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 1166.65 MiB llama_new_context_with_model: KV self size = 1166.62 MiB, c^KV (q8_0): 1166.62 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 3425.00 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 176.01 MiB llama_new_context_with_model: graph nodes = 8245 llama_new_context_with_model: graph splits = 118 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 63, n_threads = 30, n_t hreads_batch = 30 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 512 | 128 | 0 | 3.493 | 146.59 | 8.407 | 15.23 | | 512 | 128 | 512 | 3.768 | 135.90 | 8.487 | 15.08 | | 512 | 128 | 1024 | 3.905 | 131.11 | 8.484 | 15.09 | | 512 | 128 | 1536 | 3.633 | 140.95 | 8.648 | 14.80 | | 512 | 128 | 2048 | 3.770 | 135.81 | 8.563 | 14.95 | | 512 | 128 | 2560 | 3.748 | 136.61 | 8.609 | 14.87 | | 512 | 128 | 3072 | 3.766 | 135.94 | 8.567 | 14.94 | | 512 | 128 | 3584 | 3.815 | 134.19 | 8.648 | 14.80 | | 512 | 128 | 4096 | 3.894 | 131.49 | 8.722 | 14.68 | | 512 | 128 | 4608 | 3.935 | 130.12 | 8.768 | 14.60 | | 512 | 128 | 5120 | 3.956 | 129.44 | 8.776 | 14.58 | | 512 | 128 | 5632 | 4.132 | 123.91 | 8.784 | 14.57 | | 512 | 128 | 6144 | 4.071 | 125.75 | 8.835 | 14.49 | | 512 | 128 | 6656 | 4.139 | 123.71 | 8.836 | 14.49 | | 512 | 128 | 7168 | 4.170 | 122.78 | 8.778 | 14.58 | | 512 | 128 | 7680 | 4.235 | 120.89 | 8.810 | 14.53 | | 512 | 128 | 8192 | 4.312 | 118.74 | 8.917 | 14.36 | | 512 | 128 | 8704 | 4.343 | 117.90 | 8.996 | 14.23 | | 512 | 128 | 9216 | 4.317 | 118.60 | 9.000 | 14.22 | | 512 | 128 | 9728 | 4.399 | 116.40 | 9.106 | 14.06 | | 512 | 128 | 10240 | 4.555 | 112.41 | 9.056 | 14.13 | | 512 | 128 | 10752 | 4.476 | 114.40 | 9.103 | 14.06 | | 512 | 128 | 11264 | 4.534 | 112.92 | 9.027 | 14.18 | | 512 | 128 | 11776 | 4.551 | 112.49 | 9.073 | 14.11 | | 512 | 128 | 12288 | 4.600 | 111.30 | 9.162 | 13.97 | | 512 | 128 | 12800 | 4.667 | 109.70 | 9.205 | 13.91 | | 512 | 128 | 13312 | 4.726 | 108.33 | 9.204 | 13.91 | | 512 | 128 | 13824 | 4.688 | 109.22 | 9.327 | 13.72 | | 512 | 128 | 14336 | 4.764 | 107.47 | 9.266 | 13.81 | | 512 | 128 | 14848 | 4.788 | 106.94 | 9.297 | 13.77 | | 512 | 128 | 15360 | 4.839 | 105.81 | 9.267 | 13.81 | | 512 | 128 | 15872 | 4.878 | 104.97 | 9.309 | 13.75 | | 512 | 128 | 16384 | 5.004 | 102.33 | 9.413 | 13.60 | | 512 | 128 | 16896 | 5.089 | 100.61 | 9.558 | 13.39 | | 512 | 128 | 17408 | 5.118 | 100.04 | 9.519 | 13.45 | | 512 | 128 | 17920 | 5.251 | 97.51 | 9.462 | 13.53 | | 512 | 128 | 18432 | 5.259 | 97.36 | 9.531 | 13.43 | | 512 | 128 | 18944 | 5.321 | 96.22 | 9.568 | 13.38 | | 512 | 128 | 19456 | 5.369 | 95.35 | 9.503 | 13.47 | | 512 | 128 | 19968 | 5.341 | 95.86 | 9.535 | 13.42 | | 512 | 128 | 20480 | 5.381 | 95.15 | 9.572 | 13.37 | | 512 | 128 | 20992 | 5.434 | 94.22 | 9.688 | 13.21 | | 512 | 128 | 21504 | 5.492 | 93.23 | 9.725 | 13.16 | | 512 | 128 | 22016 | 5.555 | 92.17 | 9.692 | 13.21 | | 512 | 128 | 22528 | 5.547 | 92.31 | 9.703 | 13.19 | | 512 | 128 | 23040 | 5.589 | 91.60 | 9.723 | 13.16 | | 512 | 128 | 23552 | 5.618 | 91.14 | 9.746 | 13.13 | | 512 | 128 | 24064 | 5.663 | 90.41 | 9.706 | 13.19 | | 512 | 128 | 24576 | 5.739 | 89.22 | 9.798 | 13.06 | | 512 | 128 | 25088 | 5.795 | 88.35 | 9.811 | 13.05 | | 512 | 128 | 25600 | 5.877 | 87.12 | 9.854 | 12.99 | | 512 | 128 | 26112 | 5.837 | 87.71 | 9.907 | 12.92 | | 512 | 128 | 26624 | 5.864 | 87.31 | 9.853 | 12.99 | | 512 | 128 | 27136 | 5.915 | 86.56 | 9.906 | 12.92 | | 512 | 128 | 27648 | 6.051 | 84.62 | 9.926 | 12.90 | | 512 | 128 | 28160 | 6.006 | 85.24 | 9.895 | 12.94 | | 512 | 128 | 28672 | 6.069 | 84.37 | 9.992 | 12.81 | | 512 | 128 | 29184 | 6.118 | 83.69 | 9.990 | 12.81 | | 512 | 128 | 29696 | 6.146 | 83.31 | 10.184 | 12.57 | | 512 | 128 | 30208 | 6.338 | 80.78 | 10.168 | 12.59 | | 512 | 128 | 30720 | 6.226 | 82.23 | 10.156 | 12.60 | | 512 | 128 | 31232 | 6.296 | 81.33 | 10.046 | 12.74 | | 512 | 128 | 31744 | 6.346 | 80.69 | 10.098 | 12.68 | | 512 | 128 | 32256 | 6.373 | 80.34 | 10.104 | 12.67 |ubergarm_DeepSeek-V3-0324-IQ4_K_R4
PS> .\bin\llama-server --version version: 3772 (5236c98b) built with Clang 19.1.5 for PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 ` -ctk q8_0 ` -c 32768 ` -ngl 63 ` -ot exps=CPU ` --threads 30 ` --threads-batch 30 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes llama_model_loader: additional 9 GGUFs metadata loaded. llama_model_loader: loaded meta data with 53 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms tudio\models\ubergarm\DeepSeek-V3-0324-GGUF\DeepSeek-V3-0324-IQ4_K_R4-00001-of-00010.gguf (version GGUF V3 (la test)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek V3 0324 llama_model_loader: - kv 3: general.version str = V3-0324 llama_model_loader: - kv 4: general.basename str = DeepSeek llama_model_loader: - kv 5: general.size_label str = 256x21B llama_model_loader: - kv 6: general.license str = mit llama_model_loader: - kv 7: deepseek2.block_count u32 = 61 llama_model_loader: - kv 8: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 9: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 10: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 11: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 12: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 13: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 14: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 15: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 16: general.file_type u32 = 340 llama_model_loader: - kv 17: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 18: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 19: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 20: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 21: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 22: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 23: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 24: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 25: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 26: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 27: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 28: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 29: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 30: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 31: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 32: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 33: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 34: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 35: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 36: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 37: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 38: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 39: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 40: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 41: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 42: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 43: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 44: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 45: general.quantization_version u32 = 2 llama_model_loader: - kv 46: quantize.imatrix.file str = /mnt/raid/models/u bergarm/DeepSeek-V3... llama_model_loader: - kv 47: quantize.imatrix.dataset str = calibration_data_v 5_rc.txt llama_model_loader: - kv 48: quantize.imatrix.entries_count i32 = 720 llama_model_loader: - kv 49: quantize.imatrix.chunks_count i32 = 213 llama_model_loader: - kv 50: split.no u16 = 0 llama_model_loader: - kv 51: split.count u16 = 10 llama_model_loader: - kv 52: split.tensors.count i32 = 1147 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 612 tensors llama_model_loader: - type iq4_k_r4: 116 tensors llama_model_loader: - type iq5_k_r4: 58 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = IQ4_K_R4 - 4.5 bpw llm_load_print_meta: model params = 672.050 B llm_load_print_meta: model size = 386.183 GiB (4.936 BPW) llm_load_print_meta: repeating layers = 384.349 GiB (4.926 BPW, 670.196 B parameters) llm_load_print_meta: general.name = DeepSeek V3 0324 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.93 MiB Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 938.98 MiB llm_load_tensors: CPU buffer size = 376768.00 MiB llm_load_tensors: CUDA0 buffer size = 17744.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 512 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 1166.65 MiB llama_new_context_with_model: KV self size = 1166.62 MiB, c^KV (q8_0): 1166.62 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 3425.00 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 176.01 MiB llama_new_context_with_model: graph nodes = 8245 llama_new_context_with_model: graph splits = 118 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 63, n_threads = 30, n_t hreads_batch = 30 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 512 | 128 | 0 | 3.690 | 138.75 | 8.496 | 15.07 | | 512 | 128 | 512 | 3.717 | 137.76 | 8.502 | 15.06 | | 512 | 128 | 1024 | 3.772 | 135.73 | 8.572 | 14.93 | | 512 | 128 | 1536 | 3.830 | 133.66 | 8.578 | 14.92 | | 512 | 128 | 2048 | 3.873 | 132.19 | 8.612 | 14.86 | | 512 | 128 | 2560 | 3.909 | 130.99 | 8.619 | 14.85 | | 512 | 128 | 3072 | 3.960 | 129.28 | 8.669 | 14.77 | | 512 | 128 | 3584 | 4.017 | 127.47 | 8.718 | 14.68 | | 512 | 128 | 4096 | 4.065 | 125.94 | 8.818 | 14.52 | | 512 | 128 | 4608 | 4.109 | 124.60 | 8.853 | 14.46 | | 512 | 128 | 5120 | 4.139 | 123.71 | 8.839 | 14.48 | | 512 | 128 | 5632 | 4.257 | 120.26 | 8.885 | 14.41 | | 512 | 128 | 6144 | 4.230 | 121.04 | 8.929 | 14.34 | | 512 | 128 | 6656 | 4.287 | 119.44 | 8.904 | 14.38 | | 512 | 128 | 7168 | 4.349 | 117.72 | 8.872 | 14.43 | | 512 | 128 | 7680 | 4.370 | 117.15 | 8.897 | 14.39 | | 512 | 128 | 8192 | 4.425 | 115.71 | 9.049 | 14.14 | | 512 | 128 | 8704 | 4.466 | 114.65 | 9.054 | 14.14 | | 512 | 128 | 9216 | 4.527 | 113.11 | 9.124 | 14.03 | | 512 | 128 | 9728 | 4.560 | 112.29 | 9.108 | 14.05 | | 512 | 128 | 10240 | 4.865 | 105.25 | 9.086 | 14.09 | | 512 | 128 | 10752 | 4.732 | 108.21 | 9.301 | 13.76 | | 512 | 128 | 11264 | 4.727 | 108.31 | 9.140 | 14.00 | | 512 | 128 | 11776 | 4.931 | 103.83 | 9.159 | 13.98 | | 512 | 128 | 12288 | 4.932 | 103.81 | 9.339 | 13.71 | | 512 | 128 | 12800 | 4.879 | 104.94 | 9.468 | 13.52 | | 512 | 128 | 13312 | 4.951 | 103.41 | 9.548 | 13.41 | | 512 | 128 | 13824 | 4.895 | 104.59 | 9.343 | 13.70 | | 512 | 128 | 14336 | 4.946 | 103.52 | 9.346 | 13.70 | | 512 | 128 | 14848 | 5.031 | 101.76 | 9.459 | 13.53 | | 512 | 128 | 15360 | 5.093 | 100.53 | 9.396 | 13.62 | | 512 | 128 | 15872 | 5.115 | 100.10 | 9.492 | 13.49 | | 512 | 128 | 16384 | 5.203 | 98.40 | 9.535 | 13.42 | | 512 | 128 | 16896 | 5.259 | 97.36 | 9.544 | 13.41 | | 512 | 128 | 17408 | 5.341 | 95.86 | 9.609 | 13.32 | | 512 | 128 | 17920 | 5.351 | 95.68 | 9.572 | 13.37 | | 512 | 128 | 18432 | 5.359 | 95.53 | 9.608 | 13.32 | | 512 | 128 | 18944 | 5.486 | 93.32 | 9.589 | 13.35 | | 512 | 128 | 19456 | 5.559 | 92.10 | 9.639 | 13.28 | | 512 | 128 | 19968 | 5.507 | 92.97 | 9.809 | 13.05 | | 512 | 128 | 20480 | 5.683 | 90.10 | 9.796 | 13.07 | | 512 | 128 | 20992 | 5.596 | 91.49 | 9.748 | 13.13 | | 512 | 128 | 21504 | 5.637 | 90.83 | 9.760 | 13.12 | | 512 | 128 | 22016 | 5.730 | 89.35 | 9.782 | 13.09 | | 512 | 128 | 22528 | 5.740 | 89.20 | 9.785 | 13.08 | | 512 | 128 | 23040 | 5.778 | 88.61 | 9.930 | 12.89 | | 512 | 128 | 23552 | 5.874 | 87.16 | 9.814 | 13.04 | | 512 | 128 | 24064 | 5.846 | 87.58 | 9.816 | 13.04 | | 512 | 128 | 24576 | 5.953 | 86.00 | 9.931 | 12.89 | | 512 | 128 | 25088 | 6.129 | 83.54 | 9.968 | 12.84 | | 512 | 128 | 25600 | 6.022 | 85.03 | 9.978 | 12.83 | | 512 | 128 | 26112 | 6.233 | 82.14 | 10.094 | 12.68 | | 512 | 128 | 26624 | 6.075 | 84.28 | 10.004 | 12.79 | | 512 | 128 | 27136 | 6.134 | 83.46 | 10.022 | 12.77 | | 512 | 128 | 27648 | 6.188 | 82.75 | 10.014 | 12.78 | | 512 | 128 | 28160 | 6.270 | 81.66 | 10.043 | 12.75 | | 512 | 128 | 28672 | 6.259 | 81.81 | 10.219 | 12.53 | | 512 | 128 | 29184 | 6.468 | 79.16 | 10.145 | 12.62 | | 512 | 128 | 29696 | 6.346 | 80.68 | 10.208 | 12.54 | | 512 | 128 | 30208 | 6.470 | 79.14 | 10.278 | 12.45 | | 512 | 128 | 30720 | 6.481 | 79.00 | 10.324 | 12.40 | | 512 | 128 | 31232 | 6.500 | 78.77 | 10.175 | 12.58 | | 512 | 128 | 31744 | 6.535 | 78.34 | 10.338 | 12.38 | | 512 | 128 | 32256 | 6.684 | 76.60 | 10.272 | 12.46 |unsloth_DeepSeek-V3-0324-UD-Q4_K_XL
PS> .\bin\llama-server --version version: 3772 (5236c98b) built with Clang 19.1.5 for PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -rtr ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 4096 ` -ctk f16 ` -c 32768 ` -ngl 99 ` -ot exps=CPU ` --threads 30 ` --threads-batch 30 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes llama_model_loader: additional 7 GGUFs metadata loaded. llama_model_loader: loaded meta data with 64 key-value pairs and 1086 tensors from C:\Users\Administrator\.lms tudio\models\unsloth\DeepSeek-V3-0324-GGUF-UD\DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf (version GGUF V3 (latest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = Deepseek-V3-0324 llama_model_loader: - kv 3: general.version str = V3-0324 llama_model_loader: - kv 4: general.basename str = Deepseek-V3-0324 llama_model_loader: - kv 5: general.quantized_by str = Unsloth llama_model_loader: - kv 6: general.size_label str = 256x20B llama_model_loader: - kv 7: general.license str = mit llama_model_loader: - kv 8: general.repo_url str = https://huggingfac e.co/unsloth llama_model_loader: - kv 9: general.base_model.count u32 = 1 llama_model_loader: - kv 10: general.base_model.0.name str = DeepSeek V3 0324 llama_model_loader: - kv 11: general.base_model.0.version str = V3-0324 llama_model_loader: - kv 12: general.base_model.0.organization str = Deepseek Ai llama_model_loader: - kv 13: general.base_model.0.repo_url str = https://huggingfac e.co/deepseek-ai/De... llama_model_loader: - kv 14: general.tags arr[str,4] = ["deepseek_v3", "d eepseek", "unsloth"... llama_model_loader: - kv 15: general.languages arr[str,1] = ["en"] llama_model_loader: - kv 16: deepseek2.block_count u32 = 61 llama_model_loader: - kv 17: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 18: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 19: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 20: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 21: deepseek2.attention.head_count_kv u32 = 1 llama_model_loader: - kv 22: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 23: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 24: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 25: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 26: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 27: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 28: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 29: deepseek2.attention.key_length u32 = 576 llama_model_loader: - kv 30: deepseek2.attention.value_length u32 = 512 llama_model_loader: - kv 31: deepseek2.attention.key_length_mla u32 = 192 llama_model_loader: - kv 32: deepseek2.attention.value_length_mla u32 = 128 llama_model_loader: - kv 33: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 34: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 35: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 36: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 37: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 38: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 39: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 40: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 41: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 42: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 43: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 44: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 45: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 46: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 47: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 48: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 49: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 50: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 51: tokenizer.ggml.padding_token_id u32 = 2 llama_model_loader: - kv 52: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 53: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 54: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 55: general.quantization_version u32 = 2 llama_model_loader: - kv 56: general.file_type u32 = 15 llama_model_loader: - kv 57: quantize.imatrix.file str = DeepSeek-V3-0324-G GUF/imatrix_unsloth... llama_model_loader: - kv 58: quantize.imatrix.dataset str = unsloth_calibratio n_DeepSeek-V3-0324.txt llama_model_loader: - kv 59: quantize.imatrix.entries_count i32 = 720 llama_model_loader: - kv 60: quantize.imatrix.chunks_count i32 = 60 llama_model_loader: - kv 61: split.no u16 = 0 llama_model_loader: - kv 62: split.tensors.count i32 = 1086 llama_model_loader: - kv 63: split.count u16 = 8 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 122 tensors llama_model_loader: - type q4_K: 485 tensors llama_model_loader: - type q5_K: 95 tensors llama_model_loader: - type q6_K: 23 tensors ========================================================================== Detected incompatible DeepSeek model. Will try to fix, but there are no guarantees *** Your prompt processing speed will be crippled *** Consider making your own ik_llama.cpp compatible model or ask the model provider to make one for you, ========================================================================== llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = Q4_K - Medium llm_load_print_meta: model params = 671.026 B llm_load_print_meta: model size = 357.623 GiB (4.578 BPW) llm_load_print_meta: repeating layers = 356.429 GiB (4.575 BPW, 669.173 B parameters) llm_load_print_meta: general.name = Deepseek-V3-0324 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 2 '<∩╜£ΓûüpadΓûü∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.89 MiB Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 497.11 MiB llm_load_tensors: CPU buffer size = 355712.00 MiB llm_load_tensors: CUDA0 buffer size = 9996.68 MiB .................................................................................................... ============ llm_prepare_mla: need to compute 61 wkv_b tensors Computed blk.0.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.1.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.2.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.3.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.4.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.5.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.6.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.7.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.8.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.9.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.10.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.11.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.12.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.13.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.14.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.15.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.16.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.17.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.18.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.19.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.20.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.21.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.22.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.23.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.24.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.25.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.26.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.27.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.28.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.29.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.30.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.31.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.32.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.33.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.34.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.35.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.36.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.37.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.38.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.39.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.40.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.41.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.42.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.43.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.44.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.45.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.46.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.47.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.48.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.49.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.50.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.51.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.52.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.53.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.54.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.55.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.56.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.57.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.58.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.59.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.60.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 ============ Repacked 174 tensors llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 4096 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 4104.02 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 1408.05 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 118 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, n_gpu_layers = 99, n_threads = 30, n_ threads_batch = 30 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 4096 | 1024 | 0 | 25.617 | 159.89 | 59.771 | 17.13 | | 4096 | 1024 | 4096 | 28.082 | 145.86 | 60.772 | 16.85 | | 4096 | 1024 | 8192 | 27.919 | 146.71 | 62.109 | 16.49 | | 4096 | 1024 | 12288 | 29.379 | 139.42 | 63.651 | 16.09 | | 4096 | 1024 | 16384 | 31.197 | 131.29 | 65.150 | 15.72 | | 4096 | 1024 | 20480 | 31.742 | 129.04 | 65.364 | 15.67 | | 4096 | 1024 | 24576 | 32.952 | 124.30 | 66.506 | 15.40 | | 4096 | 1024 | 28672 | 36.312 | 112.80 | 68.284 | 15.00 |The numbers look great! That said, looking around, I feel like I should be able to get slightly better results with 12 channels of DDR5-6400 😄. OCCT reports RAM bandwidth at 598 GB/s read, 427 GB/s write, and 136.82 ns latency.
I’d love to hear what more experienced people here think - @ubergarm?
👤 saood06 replied the 2025-06-28 at 00:34:39:
Switched the build to clang-cl -DCMAKE_INTERPROCEDURAL_OPTIMIZATION=ON
Do you mind telling me how much these two changes matter?
👤 sousekd replied the 2025-06-28 at 00:51:40:
Do you mind telling me how much these two changes matter?
Close to not-at-all, at least in my testing. AI insisited to use LVVM/clang instead of MSVC and as a good citizen, I obliged. The same applies to
DCMAKE_INTERPROCEDURAL_OPTIMIZATION. I think most of the improvements were caused simply by playing with-band-ub. I did not manage to get @ubergarm's models play well with-ubhigher then default (without OOM on my system), but even change in-bmade some difference.👤 saood06 replied the 2025-06-28 at 01:19:59:
Do you mind telling me how much these two changes matter?
Close to not-at-all, at least in my testing. AI insisited to use LVVM/clang instead of MSVC and as a good citizen, I obliged.
Thanks for confirming, that aligns with my previous testing. I also experimented with GGML_LTO on Windows (MSVC) and found that it caused issues, hadn't tried it with the other compilers (clang, gcc).
👤 ubergarm replied the 2025-06-28 at 16:20:27:
@sousekdThanks for the detailed report and many iterations to search out the best performance for your rig. Yes, my models can be a bit slower than mainline quants given I tend to use bigger tensors for the GPU offload portion which leads to a little better perplexity and KLD scores for a given GiB size class.
Recently some PRs were merged that speed up my quants (especially the IQ2_K_R4) if you can offload some more exps to GPU. Given you've tweaked BIOS and compilation stuff already, the last thing to consider is "how can I offload more layers onto GPU".
Given u have a 4090 with 24GB VRAM you could:
- dial back on the
-ubsize a bit (as in some of my testing 2048 was faster PP than 4096 depends on VRAM bandwidth.)- go a little lower with amb to get a little more VRAM
- try to offload 1 or more exps layers for faster TG
.\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 128 -b 2048 -ub 2048 ` -ctk q8_0 ` -c 32768 ` -ngl 63 ` -ot "blk\.(3|4)\.ffn_.*=CUDA0" ` -ot exps=CPU ` --threads 30 ` --threads-batch 30 ` --warmup-batchAdjust
-ot "blk\.(3|4)\.ffn_.*=CUDA0"up or down e.g.(3)or(3|4|5|6)... to fill up VRAM until you OOM and dial back by one. TheIQ2_K_R4is your best bet here as that was designed to use less VRAM in the first place.If you can get this running, check amount of VRAM used with
nvidia-smietc and then you could possibly increase-amb 256or add a little more context back to max it out.Good luck!
👤 sousekd replied the 2025-06-28 at 17:53:29:
Thank you @ubergarm for the great tips to try, and for helping people here and around the web :). I’ll give it a try once I’m back from my holiday.Do you find my pp/tg numbers as expected, or do you think the machine should be able to do better? I think I saw your Threadripper PRO 7965WX numbers somewhere and thought the higher memory bandwidth of EPYC should help achieve even better results.
I’m perfectly happy with these numbers and grateful to @ikawrakow and other contributors to ik_llama, but improving pp speed would unlock even more use cases.
I have another 4090 and a 5090 in my other PC, and one of them will be moved to this server to get more VRAM. I’m also considering buying an RTX 6000, but I’m not at all sure how much it would actually help with these huge models not fitting in VRAM anyway. Could you elaborate based on your knowledge and experience, please? Thank you very much!
👤 saood06 replied the 2025-06-28 at 23:43:05:
If you can get this running, check amount of VRAM used with nvidia-smi etc
From my experience for watching usage (split by CUDA, 3d, video decode etc.) and memory usage (shared and dedicated) task manager is pretty good on windows.
👤 sousekd replied the 2025-07-09 at 07:12:18:
Back from holiday, I added another GPU to the server, expecting the extra VRAM would only help. Turns out I was totally wrong - using both GPUs actually hurt performance. Clearly, I've got a lot more to learn 🙂. PCIe bandwidth and latency seem to matter a lot, and I need to experiment more with batch sizes and which parts of the model to offload, as it can have a significant impact.Anyway, sticking to a single RTX 5090 for now, playing with batch sizes and offloading one, two, or no experts, I managed to improve speeds a bit:

ubergarm_DeepSeek-V3-0324-IQ2_K_R4
PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 4096 ` -ctk f16 ` -c 32768 ` -ngl 63 ` -ot exps=CPU ` --parallel 1 ` --threads 32 ` --threads-batch 32 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 5090, compute capability 12.0, VMM: yes llama_model_loader: additional 4 GGUFs metadata loaded. llama_model_loader: loaded meta data with 53 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms tudio\models\ubergarm\DeepSeek-V3-0324-GGUF\DeepSeek-V3-0324-IQ2_K_R4-00001-of-00005.gguf (version GGUF V3 (la test)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek V3 0324 llama_model_loader: - kv 3: general.version str = V3-0324 llama_model_loader: - kv 4: general.basename str = DeepSeek llama_model_loader: - kv 5: general.size_label str = 256x21B llama_model_loader: - kv 6: general.license str = mit llama_model_loader: - kv 7: deepseek2.block_count u32 = 61 llama_model_loader: - kv 8: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 9: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 10: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 11: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 12: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 13: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 14: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 15: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 16: general.file_type u32 = 338 llama_model_loader: - kv 17: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 18: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 19: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 20: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 21: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 22: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 23: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 24: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 25: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 26: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 27: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 28: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 29: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 30: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 31: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 32: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 33: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 34: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 35: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 36: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 37: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 38: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 39: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 40: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 41: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 42: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 43: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 44: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 45: general.quantization_version u32 = 2 llama_model_loader: - kv 46: quantize.imatrix.file str = /mnt/raid/models/u bergarm/DeepSeek-V3... llama_model_loader: - kv 47: quantize.imatrix.dataset str = calibration_data_v 5_rc.txt llama_model_loader: - kv 48: quantize.imatrix.entries_count i32 = 720 llama_model_loader: - kv 49: quantize.imatrix.chunks_count i32 = 213 llama_model_loader: - kv 50: split.no u16 = 0 llama_model_loader: - kv 51: split.count u16 = 5 llama_model_loader: - kv 52: split.tensors.count i32 = 1147 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 612 tensors llama_model_loader: - type iq2_k_r4: 116 tensors llama_model_loader: - type iq3_k_r4: 58 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = IQ2_K_R4 - 2.375 bpw llm_load_print_meta: model params = 672.050 B llm_load_print_meta: model size = 226.003 GiB (2.889 BPW) llm_load_print_meta: repeating layers = 224.169 GiB (2.873 BPW, 670.196 B parameters) llm_load_print_meta: general.name = DeepSeek V3 0324 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.93 MiB Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 938.98 MiB llm_load_tensors: CPU buffer size = 212744.00 MiB llm_load_tensors: CUDA0 buffer size = 17744.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 4096 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 4104.02 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 624.05 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 118 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_ threads_batch = 32 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 4096 | 1024 | 0 | 14.237 | 287.69 | 51.199 | 20.00 | | 4096 | 1024 | 4096 | 15.184 | 269.76 | 51.878 | 19.74 | | 4096 | 1024 | 8192 | 16.390 | 249.92 | 53.417 | 19.17 | | 4096 | 1024 | 12288 | 17.387 | 235.58 | 53.820 | 19.03 | | 4096 | 1024 | 16384 | 18.827 | 217.56 | 55.314 | 18.51 | | 4096 | 1024 | 20480 | 19.854 | 206.30 | 55.229 | 18.54 | | 4096 | 1024 | 24576 | 20.544 | 199.37 | 56.770 | 18.04 | | 4096 | 1024 | 28672 | 21.351 | 191.84 | 58.240 | 17.58 |ubergarm_DeepSeek-V3-0324-IQ4_K_R4
PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 2048 ` -ctk f16 ` -c 32768 ` -ngl 63 ` -op 27,0,29,0 ` -ot "blk\.(3)\.ffn_.*=CUDA0" ` -ot exps=CPU ` --parallel 1 ` --threads 32 ` --threads-batch 32 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 5090, compute capability 12.0, VMM: yes llama_model_loader: additional 9 GGUFs metadata loaded. llama_model_loader: loaded meta data with 53 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms tudio\models\ubergarm\DeepSeek-V3-0324-GGUF\DeepSeek-V3-0324-IQ4_K_R4-00001-of-00010.gguf (version GGUF V3 (la test)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek V3 0324 llama_model_loader: - kv 3: general.version str = V3-0324 llama_model_loader: - kv 4: general.basename str = DeepSeek llama_model_loader: - kv 5: general.size_label str = 256x21B llama_model_loader: - kv 6: general.license str = mit llama_model_loader: - kv 7: deepseek2.block_count u32 = 61 llama_model_loader: - kv 8: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 9: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 10: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 11: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 12: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 13: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 14: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 15: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 16: general.file_type u32 = 340 llama_model_loader: - kv 17: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 18: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 19: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 20: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 21: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 22: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 23: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 24: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 25: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 26: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 27: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 28: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 29: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 30: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 31: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 32: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 33: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 34: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 35: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 36: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 37: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 38: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 39: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 40: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 41: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 42: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 43: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 44: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 45: general.quantization_version u32 = 2 llama_model_loader: - kv 46: quantize.imatrix.file str = /mnt/raid/models/u bergarm/DeepSeek-V3... llama_model_loader: - kv 47: quantize.imatrix.dataset str = calibration_data_v 5_rc.txt llama_model_loader: - kv 48: quantize.imatrix.entries_count i32 = 720 llama_model_loader: - kv 49: quantize.imatrix.chunks_count i32 = 213 llama_model_loader: - kv 50: split.no u16 = 0 llama_model_loader: - kv 51: split.count u16 = 10 llama_model_loader: - kv 52: split.tensors.count i32 = 1147 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 612 tensors llama_model_loader: - type iq4_k_r4: 116 tensors llama_model_loader: - type iq5_k_r4: 58 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = IQ4_K_R4 - 4.5 bpw llm_load_print_meta: model params = 672.050 B llm_load_print_meta: model size = 386.183 GiB (4.936 BPW) llm_load_print_meta: repeating layers = 384.349 GiB (4.926 BPW, 670.196 B parameters) llm_load_print_meta: general.name = DeepSeek V3 0324 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.93 MiB Tensor blk.3.ffn_norm.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_inp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_shexp.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 938.98 MiB llm_load_tensors: CPU buffer size = 370272.00 MiB llm_load_tensors: CUDA0 buffer size = 24240.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 2048 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 4472.01 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 312.02 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 116 XXXXXXXXXXXXXXXXXXXXX Setting offload policy for op MUL_MAT_ID to OFF XXXXXXXXXXXXXXXXXXXXX Setting offload policy for op MOE_FUSED_UP_GATE to OFF main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 2048, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_ threads_batch = 32 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 2048 | 512 | 0 | 12.944 | 158.22 | 31.369 | 16.32 | | 2048 | 512 | 2048 | 13.033 | 157.14 | 31.081 | 16.47 | | 2048 | 512 | 4096 | 14.656 | 139.74 | 32.354 | 15.83 | | 2048 | 512 | 6144 | 13.112 | 156.19 | 32.268 | 15.87 | | 2048 | 512 | 8192 | 14.911 | 137.35 | 32.582 | 15.71 | | 2048 | 512 | 10240 | 14.696 | 139.36 | 32.603 | 15.70 | | 2048 | 512 | 12288 | 16.359 | 125.19 | 33.604 | 15.24 | | 2048 | 512 | 14336 | 16.903 | 121.16 | 37.064 | 13.81 | | 2048 | 512 | 16384 | 18.052 | 113.45 | 36.977 | 13.85 | | 2048 | 512 | 18432 | 16.068 | 127.46 | 37.528 | 13.64 | | 2048 | 512 | 20480 | 18.269 | 112.10 | 36.381 | 14.07 | | 2048 | 512 | 22528 | 18.843 | 108.69 | 37.739 | 13.57 | | 2048 | 512 | 24576 | 16.540 | 123.82 | 37.389 | 13.69 | | 2048 | 512 | 26624 | 17.738 | 115.46 | 37.084 | 13.81 | | 2048 | 512 | 28672 | 17.882 | 114.53 | 37.602 | 13.62 | | 2048 | 512 | 30720 | 17.947 | 114.11 | 38.464 | 13.31 |ubergarm_DeepSeek-R1-0528-IQ4_KS_R4
PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 2048 ` -ctk f16 ` -c 32768 ` -ngl 63 ` -op 27,0,29,0 ` -ot "blk\.(3)\.ffn_.*=CUDA0" ` -ot exps=CPU ` --parallel 1 ` --threads 32 ` --threads-batch 32 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 5090, compute capability 12.0, VMM: yes llama_model_loader: additional 8 GGUFs metadata loaded. llama_model_loader: loaded meta data with 52 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms tudio\models\ubergarm\DeepSeek-R1-0528-GGUF\DeepSeek-R1-0528-IQ4_KS_R4-00001-of-00009.gguf (version GGUF V3 (l atest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek R1 0528 llama_model_loader: - kv 3: general.version str = 0528 llama_model_loader: - kv 4: general.basename str = DeepSeek-R1 llama_model_loader: - kv 5: general.size_label str = 256x21B llama_model_loader: - kv 6: deepseek2.block_count u32 = 61 llama_model_loader: - kv 7: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 8: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 9: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 10: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 11: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 12: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 13: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 14: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 15: general.file_type u32 = 345 llama_model_loader: - kv 16: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 17: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 18: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 19: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 20: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 21: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 22: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 23: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 24: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 25: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 26: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 27: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 28: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 29: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 30: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 31: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 32: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 33: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 34: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 35: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 36: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 37: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 38: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 39: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 40: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 41: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 42: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 43: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 44: general.quantization_version u32 = 2 llama_model_loader: - kv 45: quantize.imatrix.file str = /mnt/raid/models/u bergarm/DeepSeek-R1... llama_model_loader: - kv 46: quantize.imatrix.dataset str = ubergarm-imatrix-c alibration-corpus-v... llama_model_loader: - kv 47: quantize.imatrix.entries_count i32 = 721 llama_model_loader: - kv 48: quantize.imatrix.chunks_count i32 = 812 llama_model_loader: - kv 49: split.no u16 = 0 llama_model_loader: - kv 50: split.count u16 = 9 llama_model_loader: - kv 51: split.tensors.count i32 = 1147 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 612 tensors llama_model_loader: - type iq4_ks_r4: 116 tensors llama_model_loader: - type iq5_ks_r4: 58 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = IQ4_KS_R4 - 4.25 bpw llm_load_print_meta: model params = 672.050 B llm_load_print_meta: model size = 367.774 GiB (4.701 BPW) llm_load_print_meta: repeating layers = 365.940 GiB (4.690 BPW, 670.196 B parameters) llm_load_print_meta: general.name = DeepSeek R1 0528 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.93 MiB Tensor blk.3.ffn_norm.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_inp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_shexp.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 938.98 MiB llm_load_tensors: CPU buffer size = 351747.00 MiB llm_load_tensors: CUDA0 buffer size = 23915.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 2048 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 4252.01 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 312.02 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 116 XXXXXXXXXXXXXXXXXXXXX Setting offload policy for op MUL_MAT_ID to OFF XXXXXXXXXXXXXXXXXXXXX Setting offload policy for op MOE_FUSED_UP_GATE to OFF main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 2048, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_ threads_batch = 32 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 2048 | 512 | 0 | 12.402 | 165.13 | 29.459 | 17.38 | | 2048 | 512 | 2048 | 12.842 | 159.48 | 30.073 | 17.03 | | 2048 | 512 | 4096 | 13.830 | 148.08 | 30.314 | 16.89 | | 2048 | 512 | 6144 | 13.118 | 156.12 | 30.838 | 16.60 | | 2048 | 512 | 8192 | 13.118 | 156.13 | 30.962 | 16.54 | | 2048 | 512 | 10240 | 13.574 | 150.87 | 31.037 | 16.50 | | 2048 | 512 | 12288 | 14.502 | 141.22 | 31.698 | 16.15 | | 2048 | 512 | 14336 | 13.952 | 146.79 | 31.598 | 16.20 | | 2048 | 512 | 16384 | 14.894 | 137.50 | 32.068 | 15.97 | | 2048 | 512 | 18432 | 15.149 | 135.19 | 33.219 | 15.41 | | 2048 | 512 | 20480 | 16.170 | 126.65 | 34.629 | 14.79 | | 2048 | 512 | 22528 | 15.486 | 132.25 | 35.577 | 14.39 | | 2048 | 512 | 24576 | 16.883 | 121.31 | 35.522 | 14.41 | | 2048 | 512 | 26624 | 15.762 | 129.94 | 35.570 | 14.39 | | 2048 | 512 | 28672 | 16.430 | 124.65 | 35.937 | 14.25 | | 2048 | 512 | 30720 | 16.625 | 123.19 | 36.151 | 14.16 |unsloth_DeepSeek-V3-0324-UD-Q4_K_XL
PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -rtr ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 4096 ` -ctk f16 ` -c 32768 ` -ngl 63 ` -ot "blk\.(3|4)\.ffn_.*=CUDA0" ` -ot exps=CPU ` --parallel 1 ` --threads 32 ` --threads-batch 32 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 5090, compute capability 12.0, VMM: yes llama_model_loader: additional 7 GGUFs metadata loaded. llama_model_loader: loaded meta data with 64 key-value pairs and 1086 tensors from C:\Users\Administrator\.lms tudio\models\unsloth\DeepSeek-V3-0324-GGUF-UD\DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf (version GGUF V3 (latest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = Deepseek-V3-0324 llama_model_loader: - kv 3: general.version str = V3-0324 llama_model_loader: - kv 4: general.basename str = Deepseek-V3-0324 llama_model_loader: - kv 5: general.quantized_by str = Unsloth llama_model_loader: - kv 6: general.size_label str = 256x20B llama_model_loader: - kv 7: general.license str = mit llama_model_loader: - kv 8: general.repo_url str = https://huggingfac e.co/unsloth llama_model_loader: - kv 9: general.base_model.count u32 = 1 llama_model_loader: - kv 10: general.base_model.0.name str = DeepSeek V3 0324 llama_model_loader: - kv 11: general.base_model.0.version str = V3-0324 llama_model_loader: - kv 12: general.base_model.0.organization str = Deepseek Ai llama_model_loader: - kv 13: general.base_model.0.repo_url str = https://huggingfac e.co/deepseek-ai/De... llama_model_loader: - kv 14: general.tags arr[str,4] = ["deepseek_v3", "d eepseek", "unsloth"... llama_model_loader: - kv 15: general.languages arr[str,1] = ["en"] llama_model_loader: - kv 16: deepseek2.block_count u32 = 61 llama_model_loader: - kv 17: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 18: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 19: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 20: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 21: deepseek2.attention.head_count_kv u32 = 1 llama_model_loader: - kv 22: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 23: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 24: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 25: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 26: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 27: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 28: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 29: deepseek2.attention.key_length u32 = 576 llama_model_loader: - kv 30: deepseek2.attention.value_length u32 = 512 llama_model_loader: - kv 31: deepseek2.attention.key_length_mla u32 = 192 llama_model_loader: - kv 32: deepseek2.attention.value_length_mla u32 = 128 llama_model_loader: - kv 33: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 34: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 35: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 36: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 37: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 38: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 39: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 40: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 41: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 42: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 43: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 44: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 45: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 46: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 47: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 48: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 49: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 50: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 51: tokenizer.ggml.padding_token_id u32 = 2 llama_model_loader: - kv 52: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 53: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 54: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 55: general.quantization_version u32 = 2 llama_model_loader: - kv 56: general.file_type u32 = 15 llama_model_loader: - kv 57: quantize.imatrix.file str = DeepSeek-V3-0324-G GUF/imatrix_unsloth... llama_model_loader: - kv 58: quantize.imatrix.dataset str = unsloth_calibratio n_DeepSeek-V3-0324.txt llama_model_loader: - kv 59: quantize.imatrix.entries_count i32 = 720 llama_model_loader: - kv 60: quantize.imatrix.chunks_count i32 = 60 llama_model_loader: - kv 61: split.no u16 = 0 llama_model_loader: - kv 62: split.tensors.count i32 = 1086 llama_model_loader: - kv 63: split.count u16 = 8 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 122 tensors llama_model_loader: - type q4_K: 485 tensors llama_model_loader: - type q5_K: 95 tensors llama_model_loader: - type q6_K: 23 tensors ========================================================================== Detected incompatible DeepSeek model. Will try to fix, but there are no guarantees *** Your prompt processing speed will be crippled *** Consider making your own ik_llama.cpp compatible model or ask the model provider to make one for you, ========================================================================== llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = Q4_K - Medium llm_load_print_meta: model params = 671.026 B llm_load_print_meta: model size = 357.623 GiB (4.578 BPW) llm_load_print_meta: repeating layers = 356.429 GiB (4.575 BPW, 669.173 B parameters) llm_load_print_meta: general.name = Deepseek-V3-0324 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 2 '<∩╜£ΓûüpadΓûü∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.89 MiB Tensor blk.3.ffn_norm.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_inp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_shexp.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_norm.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_gate_inp.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_down_exps.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_up_exps.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_gate_shexp.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_down_shexp.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_up_shexp.weight buffer type overriden to CUDA0 Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 497.11 MiB llm_load_tensors: CPU buffer size = 343168.00 MiB llm_load_tensors: CUDA0 buffer size = 22540.68 MiB .................................................................................................... ============ llm_prepare_mla: need to compute 61 wkv_b tensors Computed blk.0.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.1.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.2.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.3.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.4.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.5.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.6.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.7.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.8.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.9.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.10.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.11.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.12.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.13.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.14.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.15.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.16.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.17.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.18.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.19.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.20.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.21.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.22.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.23.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.24.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.25.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.26.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.27.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.28.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.29.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.30.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.31.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.32.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.33.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.34.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.35.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.36.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.37.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.38.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.39.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.40.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.41.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.42.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.43.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.44.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.45.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.46.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.47.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.48.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.49.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.50.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.51.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.52.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.53.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.54.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.55.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.56.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.57.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.58.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.59.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 Computed blk.60.attn_kv_b.weight as 512 x 32768 and stored in buffer CUDA0 ============ Repacked 168 tensors llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 4096 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 4104.02 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 1408.05 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 114 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_ threads_batch = 32 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 4096 | 1024 | 0 | 22.144 | 184.97 | 54.304 | 18.86 | | 4096 | 1024 | 4096 | 23.428 | 174.83 | 55.060 | 18.60 | | 4096 | 1024 | 8192 | 24.258 | 168.85 | 56.973 | 17.97 | | 4096 | 1024 | 12288 | 25.513 | 160.55 | 57.823 | 17.71 | | 4096 | 1024 | 16384 | 26.249 | 156.04 | 60.916 | 16.81 | | 4096 | 1024 | 20480 | 27.529 | 148.79 | 64.578 | 15.86 | | 4096 | 1024 | 24576 | 28.390 | 144.28 | 68.217 | 15.01 | | 4096 | 1024 | 28672 | 29.499 | 138.85 | 67.379 | 15.20 |bartowski_DeepSeek-V3-0324-Q4_K_M-V2
PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -rtr ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 4096 ` -ctk f16 ` -c 32768 ` -ngl 63 ` -ot "blk\.(3)\.ffn_.*=CUDA0" ` -ot exps=CPU ` --parallel 1 ` --threads 32 ` --threads-batch 32 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 5090, compute capability 12.0, VMM: yes llama_model_loader: additional 10 GGUFs metadata loaded. llama_model_loader: loaded meta data with 53 key-value pairs and 1025 tensors from C:\Users\Administrator\.lms tudio\models\bartowski\deepseek-ai_DeepSeek-V3-0324-GGUF\deepseek-ai_DeepSeek-V3-0324-Q4_K_M-V2-00001-of-00011 .gguf (version GGUF V3 (latest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek V3 0324 llama_model_loader: - kv 3: general.version str = V3-0324 llama_model_loader: - kv 4: general.basename str = DeepSeek llama_model_loader: - kv 5: general.size_label str = 256x20B llama_model_loader: - kv 6: general.license str = mit llama_model_loader: - kv 7: deepseek2.block_count u32 = 61 llama_model_loader: - kv 8: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 9: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 10: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 11: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 12: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 13: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 14: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 15: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 16: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 17: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 18: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 19: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 20: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 21: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 22: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 23: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 24: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 25: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 26: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 27: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 28: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 29: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 30: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 31: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 32: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 33: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 34: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 35: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 36: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 37: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 38: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 39: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 40: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 41: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 42: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 43: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 44: general.quantization_version u32 = 2 llama_model_loader: - kv 45: general.file_type u32 = 15 llama_model_loader: - kv 46: quantize.imatrix.file str = /models/DeepSeek-V 3-0324-GGUF/DeepSee... llama_model_loader: - kv 47: quantize.imatrix.dataset str = /workspace/calibra tion_datav3.txt llama_model_loader: - kv 48: quantize.imatrix.entries_count i32 = 720 llama_model_loader: - kv 49: quantize.imatrix.chunks_count i32 = 124 llama_model_loader: - kv 50: split.no u16 = 0 llama_model_loader: - kv 51: split.tensors.count i32 = 1025 llama_model_loader: - kv 52: split.count u16 = 11 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 151 tensors llama_model_loader: - type q4_K: 154 tensors llama_model_loader: - type q5_K: 153 tensors llama_model_loader: - type q6_K: 206 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = Q4_K - Medium llm_load_print_meta: model params = 671.026 B llm_load_print_meta: model size = 379.030 GiB (4.852 BPW) llm_load_print_meta: repeating layers = 377.836 GiB (4.850 BPW, 669.173 B parameters) llm_load_print_meta: general.name = DeepSeek V3 0324 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.85 MiB Tensor blk.3.ffn_norm.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_inp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_exps.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_gate_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_down_shexp.weight buffer type overriden to CUDA0 Tensor blk.3.ffn_up_shexp.weight buffer type overriden to CUDA0 Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 497.11 MiB llm_load_tensors: CPU buffer size = 368760.00 MiB llm_load_tensors: CUDA0 buffer size = 18869.18 MiB .................................................................................................... ============ llm_prepare_mla: need to compute 61 wk_b/wv_b tensors Computed blk.0.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.1.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.2.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.3.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.4.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.5.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.6.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.7.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.8.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.9.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.10.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.11.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.12.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.13.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.14.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.15.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.16.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.17.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.18.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.19.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.20.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.21.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.22.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.23.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.24.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.25.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.26.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.27.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.28.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.29.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.30.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.31.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.32.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.33.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.34.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.35.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.36.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.37.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.38.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.39.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.40.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.41.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.42.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.43.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.44.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.45.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.46.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.47.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.48.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.49.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.50.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.51.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.52.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.53.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.54.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.55.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.56.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.57.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.58.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.59.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 Computed blk.60.attn_v_b.weight as 128 x 512 x 128 and stored in buffer CUDA0 ============ Repacked 171 tensors llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 4096 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 4104.02 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 1408.05 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 116 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_ threads_batch = 32 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 4096 | 1024 | 0 | 22.611 | 181.15 | 57.344 | 17.86 | | 4096 | 1024 | 4096 | 24.195 | 169.29 | 57.844 | 17.70 | | 4096 | 1024 | 8192 | 25.145 | 162.89 | 59.430 | 17.23 | | 4096 | 1024 | 12288 | 25.140 | 162.93 | 60.603 | 16.90 | | 4096 | 1024 | 16384 | 27.017 | 151.61 | 64.168 | 15.96 | | 4096 | 1024 | 20480 | 27.447 | 149.23 | 68.141 | 15.03 | | 4096 | 1024 | 24576 | 28.346 | 144.50 | 69.662 | 14.70 | | 4096 | 1024 | 28672 | 30.268 | 135.32 | 71.957 | 14.23 |anikifoss_DeepSeek-R1-0528-DQ4_K_R4
PS> .\bin\llama-sweep-bench.exe ` --alias $ModelAlias ` --model $ModelPath ` --no-mmap ` -mla 3 -fa -fmoe ` -amb 512 -b 4096 -ub 2048 ` -ctk f16 ` -c 32768 ` -ngl 63 ` -ot exps=CPU,attn_kv_b=CPU ` --parallel 1 ` --threads 32 ` --threads-batch 32 ` --warmup-batch ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 5090, compute capability 12.0, VMM: yes llama_model_loader: additional 9 GGUFs metadata loaded. llama_model_loader: loaded meta data with 46 key-value pairs and 1147 tensors from C:\Users\Administrator\.lms tudio\models\anikifoss\DeepSeek-R1-0528-DQ4_K_R4\DeepSeek-R1-0528-DQ4_K_R4-00001-of-00010.gguf (version GGUF V 3 (latest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = deepseek2 llama_model_loader: - kv 1: general.type str = model llama_model_loader: - kv 2: general.name str = DeepSeek R1 0528 B f16 llama_model_loader: - kv 3: general.size_label str = 256x21B llama_model_loader: - kv 4: deepseek2.block_count u32 = 61 llama_model_loader: - kv 5: deepseek2.context_length u32 = 163840 llama_model_loader: - kv 6: deepseek2.embedding_length u32 = 7168 llama_model_loader: - kv 7: deepseek2.feed_forward_length u32 = 18432 llama_model_loader: - kv 8: deepseek2.attention.head_count u32 = 128 llama_model_loader: - kv 9: deepseek2.attention.head_count_kv u32 = 128 llama_model_loader: - kv 10: deepseek2.rope.freq_base f32 = 10000.000000 llama_model_loader: - kv 11: deepseek2.attention.layer_norm_rms_epsilon f32 = 0.000001 llama_model_loader: - kv 12: deepseek2.expert_used_count u32 = 8 llama_model_loader: - kv 13: general.file_type u32 = 214 llama_model_loader: - kv 14: deepseek2.leading_dense_block_count u32 = 3 llama_model_loader: - kv 15: deepseek2.vocab_size u32 = 129280 llama_model_loader: - kv 16: deepseek2.attention.q_lora_rank u32 = 1536 llama_model_loader: - kv 17: deepseek2.attention.kv_lora_rank u32 = 512 llama_model_loader: - kv 18: deepseek2.attention.key_length u32 = 192 llama_model_loader: - kv 19: deepseek2.attention.value_length u32 = 128 llama_model_loader: - kv 20: deepseek2.expert_feed_forward_length u32 = 2048 llama_model_loader: - kv 21: deepseek2.expert_count u32 = 256 llama_model_loader: - kv 22: deepseek2.expert_shared_count u32 = 1 llama_model_loader: - kv 23: deepseek2.expert_weights_scale f32 = 2.500000 llama_model_loader: - kv 24: deepseek2.expert_weights_norm bool = true llama_model_loader: - kv 25: deepseek2.expert_gating_func u32 = 2 llama_model_loader: - kv 26: deepseek2.rope.dimension_count u32 = 64 llama_model_loader: - kv 27: deepseek2.rope.scaling.type str = yarn llama_model_loader: - kv 28: deepseek2.rope.scaling.factor f32 = 40.000000 llama_model_loader: - kv 29: deepseek2.rope.scaling.original_context_length u32 = 4096 llama_model_loader: - kv 30: deepseek2.rope.scaling.yarn_log_multiplier f32 = 0.100000 llama_model_loader: - kv 31: tokenizer.ggml.model str = gpt2 llama_model_loader: - kv 32: tokenizer.ggml.pre str = deepseek-v3 llama_model_loader: - kv 33: tokenizer.ggml.tokens arr[str,129280] = ["<∩╜£beginΓûüofΓû üsentence∩╜£>", "<∩... llama_model_loader: - kv 34: tokenizer.ggml.token_type arr[i32,129280] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... llama_model_loader: - kv 35: tokenizer.ggml.merges arr[str,127741] = ["─á t", "─á a", " i n", "─á ─á", "h e... llama_model_loader: - kv 36: tokenizer.ggml.bos_token_id u32 = 0 llama_model_loader: - kv 37: tokenizer.ggml.eos_token_id u32 = 1 llama_model_loader: - kv 38: tokenizer.ggml.padding_token_id u32 = 1 llama_model_loader: - kv 39: tokenizer.ggml.add_bos_token bool = true llama_model_loader: - kv 40: tokenizer.ggml.add_eos_token bool = false llama_model_loader: - kv 41: tokenizer.chat_template str = {% if not add_gene ration_prompt is de... llama_model_loader: - kv 42: general.quantization_version u32 = 2 llama_model_loader: - kv 43: split.no u16 = 0 llama_model_loader: - kv 44: split.count u16 = 10 llama_model_loader: - kv 45: split.tensors.count i32 = 1147 llama_model_loader: - type f32: 361 tensors llama_model_loader: - type q8_0: 612 tensors llama_model_loader: - type q4_k_r4: 116 tensors llama_model_loader: - type q6_k_r4: 58 tensors llm_load_vocab: special tokens cache size = 818 llm_load_vocab: token to piece cache size = 0.8223 MB llm_load_print_meta: format = GGUF V3 (latest) llm_load_print_meta: arch = deepseek2 llm_load_print_meta: vocab type = BPE llm_load_print_meta: n_vocab = 129280 llm_load_print_meta: n_merges = 127741 llm_load_print_meta: vocab_only = 0 llm_load_print_meta: n_ctx_train = 163840 llm_load_print_meta: n_embd = 7168 llm_load_print_meta: n_layer = 61 llm_load_print_meta: n_head = 128 llm_load_print_meta: n_head_kv = 128 llm_load_print_meta: n_rot = 64 llm_load_print_meta: n_swa = 0 llm_load_print_meta: n_swa_pattern = 1 llm_load_print_meta: n_embd_head_k = 192 llm_load_print_meta: n_embd_head_v = 128 llm_load_print_meta: n_gqa = 1 llm_load_print_meta: n_embd_k_gqa = 24576 llm_load_print_meta: n_embd_v_gqa = 16384 llm_load_print_meta: f_norm_eps = 0.0e+00 llm_load_print_meta: f_norm_rms_eps = 1.0e-06 llm_load_print_meta: f_clamp_kqv = 0.0e+00 llm_load_print_meta: f_max_alibi_bias = 0.0e+00 llm_load_print_meta: f_logit_scale = 0.0e+00 llm_load_print_meta: n_ff = 18432 llm_load_print_meta: n_expert = 256 llm_load_print_meta: n_expert_used = 8 llm_load_print_meta: causal attn = 1 llm_load_print_meta: pooling type = 0 llm_load_print_meta: rope type = 0 llm_load_print_meta: rope scaling = yarn llm_load_print_meta: freq_base_train = 10000.0 llm_load_print_meta: freq_scale_train = 0.025 llm_load_print_meta: n_ctx_orig_yarn = 4096 llm_load_print_meta: rope_finetuned = unknown llm_load_print_meta: ssm_d_conv = 0 llm_load_print_meta: ssm_d_inner = 0 llm_load_print_meta: ssm_d_state = 0 llm_load_print_meta: ssm_dt_rank = 0 llm_load_print_meta: model type = 671B llm_load_print_meta: model ftype = Q4_K_R4 llm_load_print_meta: model params = 672.050 B llm_load_print_meta: model size = 413.144 GiB (5.281 BPW) llm_load_print_meta: repeating layers = 411.310 GiB (5.272 BPW, 670.196 B parameters) llm_load_print_meta: general.name = DeepSeek R1 0528 Bf16 llm_load_print_meta: BOS token = 0 '<∩╜£beginΓûüofΓûüsentence∩╜£>' llm_load_print_meta: EOS token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: PAD token = 1 '<∩╜£endΓûüofΓûüsentence∩╜£>' llm_load_print_meta: LF token = 131 '├ä' llm_load_print_meta: max token length = 256 llm_load_print_meta: n_layer_dense_lead = 3 llm_load_print_meta: n_lora_q = 1536 llm_load_print_meta: n_lora_kv = 512 llm_load_print_meta: n_ff_exp = 2048 llm_load_print_meta: n_expert_shared = 1 llm_load_print_meta: expert_weights_scale = 2.5 llm_load_print_meta: expert_weights_norm = 1 llm_load_print_meta: expert_gating_func = sigmoid llm_load_print_meta: rope_yarn_log_mul = 0.1000 llm_load_tensors: ggml ctx size = 0.93 MiB Tensor blk.0.attn_kv_b.weight buffer type overriden to CPU Tensor blk.1.attn_kv_b.weight buffer type overriden to CPU Tensor blk.2.attn_kv_b.weight buffer type overriden to CPU Tensor blk.3.attn_kv_b.weight buffer type overriden to CPU Tensor blk.3.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.3.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.4.attn_kv_b.weight buffer type overriden to CPU Tensor blk.4.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.4.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.5.attn_kv_b.weight buffer type overriden to CPU Tensor blk.5.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.5.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.6.attn_kv_b.weight buffer type overriden to CPU Tensor blk.6.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.6.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.7.attn_kv_b.weight buffer type overriden to CPU Tensor blk.7.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.7.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.8.attn_kv_b.weight buffer type overriden to CPU Tensor blk.8.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.8.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.9.attn_kv_b.weight buffer type overriden to CPU Tensor blk.9.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.9.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.10.attn_kv_b.weight buffer type overriden to CPU Tensor blk.10.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.10.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.11.attn_kv_b.weight buffer type overriden to CPU Tensor blk.11.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.11.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.12.attn_kv_b.weight buffer type overriden to CPU Tensor blk.12.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.12.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.13.attn_kv_b.weight buffer type overriden to CPU Tensor blk.13.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.13.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.14.attn_kv_b.weight buffer type overriden to CPU Tensor blk.14.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.14.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.15.attn_kv_b.weight buffer type overriden to CPU Tensor blk.15.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.15.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.16.attn_kv_b.weight buffer type overriden to CPU Tensor blk.16.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.16.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.17.attn_kv_b.weight buffer type overriden to CPU Tensor blk.17.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.17.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.18.attn_kv_b.weight buffer type overriden to CPU Tensor blk.18.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.18.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.19.attn_kv_b.weight buffer type overriden to CPU Tensor blk.19.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.19.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.20.attn_kv_b.weight buffer type overriden to CPU Tensor blk.20.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.20.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.21.attn_kv_b.weight buffer type overriden to CPU Tensor blk.21.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.21.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.22.attn_kv_b.weight buffer type overriden to CPU Tensor blk.22.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.22.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.23.attn_kv_b.weight buffer type overriden to CPU Tensor blk.23.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.23.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.24.attn_kv_b.weight buffer type overriden to CPU Tensor blk.24.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.24.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.25.attn_kv_b.weight buffer type overriden to CPU Tensor blk.25.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.25.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.26.attn_kv_b.weight buffer type overriden to CPU Tensor blk.26.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.26.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.27.attn_kv_b.weight buffer type overriden to CPU Tensor blk.27.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.27.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.28.attn_kv_b.weight buffer type overriden to CPU Tensor blk.28.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.28.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.29.attn_kv_b.weight buffer type overriden to CPU Tensor blk.29.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.29.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.30.attn_kv_b.weight buffer type overriden to CPU Tensor blk.30.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.30.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.31.attn_kv_b.weight buffer type overriden to CPU Tensor blk.31.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.31.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.32.attn_kv_b.weight buffer type overriden to CPU Tensor blk.32.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.32.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.33.attn_kv_b.weight buffer type overriden to CPU Tensor blk.33.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.33.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.34.attn_kv_b.weight buffer type overriden to CPU Tensor blk.34.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.34.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.35.attn_kv_b.weight buffer type overriden to CPU Tensor blk.35.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.35.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.36.attn_kv_b.weight buffer type overriden to CPU Tensor blk.36.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.36.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.37.attn_kv_b.weight buffer type overriden to CPU Tensor blk.37.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.37.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.38.attn_kv_b.weight buffer type overriden to CPU Tensor blk.38.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.38.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.39.attn_kv_b.weight buffer type overriden to CPU Tensor blk.39.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.39.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.40.attn_kv_b.weight buffer type overriden to CPU Tensor blk.40.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.40.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.41.attn_kv_b.weight buffer type overriden to CPU Tensor blk.41.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.41.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.42.attn_kv_b.weight buffer type overriden to CPU Tensor blk.42.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.42.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.43.attn_kv_b.weight buffer type overriden to CPU Tensor blk.43.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.43.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.44.attn_kv_b.weight buffer type overriden to CPU Tensor blk.44.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.44.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.45.attn_kv_b.weight buffer type overriden to CPU Tensor blk.45.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.45.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.46.attn_kv_b.weight buffer type overriden to CPU Tensor blk.46.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.46.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.47.attn_kv_b.weight buffer type overriden to CPU Tensor blk.47.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.47.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.48.attn_kv_b.weight buffer type overriden to CPU Tensor blk.48.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.48.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.49.attn_kv_b.weight buffer type overriden to CPU Tensor blk.49.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.49.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.50.attn_kv_b.weight buffer type overriden to CPU Tensor blk.50.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.50.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.51.attn_kv_b.weight buffer type overriden to CPU Tensor blk.51.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.51.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.52.attn_kv_b.weight buffer type overriden to CPU Tensor blk.52.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.52.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.53.attn_kv_b.weight buffer type overriden to CPU Tensor blk.53.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.53.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.54.attn_kv_b.weight buffer type overriden to CPU Tensor blk.54.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.54.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.55.attn_kv_b.weight buffer type overriden to CPU Tensor blk.55.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.55.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.56.attn_kv_b.weight buffer type overriden to CPU Tensor blk.56.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.56.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.57.attn_kv_b.weight buffer type overriden to CPU Tensor blk.57.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.57.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.58.attn_kv_b.weight buffer type overriden to CPU Tensor blk.58.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.58.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.59.attn_kv_b.weight buffer type overriden to CPU Tensor blk.59.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.59.ffn_up_exps.weight buffer type overriden to CPU Tensor blk.60.attn_kv_b.weight buffer type overriden to CPU Tensor blk.60.ffn_gate_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_down_exps.weight buffer type overriden to CPU Tensor blk.60.ffn_up_exps.weight buffer type overriden to CPU llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CUDA_Host buffer size = 938.98 MiB llm_load_tensors: CPU buffer size = 405413.00 MiB llm_load_tensors: CUDA0 buffer size = 16707.02 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 32768 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 2048 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 2196.00 MiB llama_new_context_with_model: KV self size = 2196.00 MiB, c^KV (f16): 2196.00 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: CUDA0 compute buffer size = 3677.51 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 704.02 MiB llama_new_context_with_model: graph nodes = 8184 llama_new_context_with_model: graph splits = 121 main: n_kv_max = 32768, n_batch = 4096, n_ubatch = 2048, flash_attn = 1, n_gpu_layers = 63, n_threads = 32, n_ threads_batch = 32 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 2048 | 512 | 0 | 11.381 | 179.96 | 31.016 | 16.51 | | 2048 | 512 | 2048 | 11.780 | 173.86 | 31.205 | 16.41 | | 2048 | 512 | 4096 | 12.428 | 164.79 | 31.668 | 16.17 | | 2048 | 512 | 6144 | 13.581 | 150.80 | 32.024 | 15.99 | | 2048 | 512 | 8192 | 12.713 | 161.10 | 31.975 | 16.01 | | 2048 | 512 | 10240 | 13.121 | 156.08 | 33.650 | 15.22 | | 2048 | 512 | 12288 | 17.815 | 114.96 | 36.286 | 14.11 | | 2048 | 512 | 14336 | 14.433 | 141.90 | 36.377 | 14.07 | | 2048 | 512 | 16384 | 14.695 | 139.36 | 36.859 | 13.89 | | 2048 | 512 | 18432 | 15.379 | 133.17 | 38.146 | 13.42 | | 2048 | 512 | 20480 | 16.053 | 127.58 | 36.940 | 13.86 | | 2048 | 512 | 22528 | 15.272 | 134.10 | 37.814 | 13.54 | | 2048 | 512 | 24576 | 15.584 | 131.42 | 37.930 | 13.50 | | 2048 | 512 | 26624 | 15.690 | 130.53 | 37.834 | 13.53 | | 2048 | 512 | 28672 | 16.384 | 125.00 | 38.202 | 13.40 | | 2048 | 512 | 30720 | 16.294 | 125.69 | 39.147 | 13.08 |@ubergarm's IQ2_K_R4 PP speed doubled with
-ub 4096. I would love to discover a similar miracle switch for the larger models 🙂.👤 ubergarm replied the 2025-07-09 at 22:23:05:
@sousekdThanks for the update, and huh I would have thought adding another GPU would give a slight increase to TG. I'd have to see the full command you were using for multi-GPU setup. I was just talking with @Panchovix about it over on my latest model https://huggingface.co/ubergarm/DeepSeek-TNG-R1T2-Chimera-GGUF/discussions/2#686eea805532fabe4bf9bce5
and trying to figure out if it is possible to put all the attn/shexp/first 3 dense ffn layers onto a single GPU and offload only routed experts onto the other GPUs and CPU. Not sure if there is a switch or method to put kv-cache on a single GPU as well, or if that would even help e.g. keep it with the attn tensors with the theory being to avoid PCIe bus between GPUs.
Try out the new TNG Chimera model as it is not
_R4type so might benefit more from-ub 4096 -b 4096now.👤 sousekd replied the 2025-07-10 at 09:17:29:
Thank you @ubergarm. I'll read and experiment more with the multi-GPU setup. Naturally, I would also think the second GPU should help, but at the same time I can understand that PCIE bandwidth has its limits - and it might become a bottleneck if data travels over it frequently, effectively negating any gains of faster memory and/or processing. Is there even anybody with multiple GPUs achieving significantly better speeds using ik_llama? Any thoughts on the topic @ikawrakow?I originally planned to buy two CPUs and spread memory across two sockets (to get 24 channels to RAM), but then reading about NUMA issues I realized it might not help much - quite the opposite. Even cross-CCDs memory access has a negative effect, so I can see why PCIE transfers should be avoided as much as possible.
👤 ikawrakow replied the 2025-07-10 at 09:33:30:
@sousekd Yoursweep-benchresults look pretty good. IIRC, someone got up to 350 t/s prompt processing speed using-b 16384 -ub 16384with 96 GB VRAM (all routed experts left on the CPU), but you need to go and pock around in the issues/discussions to find the setup and the model used (I'm not very well organized in keeping track of all the discussions). Also, I think it is better to remind us of your hardware (CPU, GPUs) instead of us having to go and search where they were posted.While I can see that competition for PCI-E bandwidth/latency may hinder PP improvements, I'm not sure I understand why one cannot get TG speed improvement by having additional routed experts offloaded to the second GPU. No tensor data is copied from RAM to VRAM when generating tokens, so PCI-E shouldn't be a bottleneck, so I expect to see at least some TG speed improvement.
I'm quite interested in improving the speed further if possible, so I think it would be useful for you to post what you have tried and the results. You may want to start a new discussion for that as this one is getting difficult to follow all comments.
👤 sousekd replied the 2025-07-10 at 11:01:17:
Thank you, @ikawrakow for your thoughts.The system is an EPYC 9355 (32 cores) with 12x DDR5-6400, and the latest results above are from a single RTX 5090 on PCIe 5.0 x16. Previous results were from a single RTX 4090 on PCIe 4.0 x16. Combined - without much tuning of the parameters - both PP t/s and TG t/s were significantly lower than on a single GPU. Oh, and it's currently running on Windows Server - only temporarily.

I'm quite interested in improving the speed further if possible, so I think it would be useful for you to post what you have tried and the results. You may want to start a new discussion for that as this one is getting difficult to follow all comments.
Yes, I will play with params and benchmark more and once I have some results, I will open a new discussion. The reason I post these results (and params) are meant to help other people. When I was deciding on what hardware to buy for running these huge models the lack of available information and real results on larger contexts was putting me off. All I was able to find is "MacBook Pro can run DeepSeek", but no information about how the performance is degrading with growing context... and k-transformers for AMX.
Anyway, it is quite possible I am doing something wrong, or Windows. Thank you very much - the numbers are great as they are, but obviously one can always try to improve, and the fact the second GPU did not help surprised me.
👤 ubergarm replied the 2025-07-10 at 15:19:09:
@sousekdJust helped some of the multi-gpu crew tune up their commands. Feel free to take a look on how they are achieving over 300 tok/sec PP and almost 20 tok/sec TG on my newest quants (using very fast IQ2_KS and the new IQ3_KS): https://huggingface.co/ubergarm/DeepSeek-TNG-R1T2-Chimera-GGUF/discussions/2
Yeah feel free to start a new discussion listing your hardware and multi-GPU arrangement as well as your current command and folks can help workshop it. There is a lot of confusion partially from my own older mistakes still floating around as well as the fact that Qwen3 has different tensor names than DeepSeek so the override-tensor regex commands look similar but are importantly different.
I originally planned to buy two CPUs and spread memory across two sockets (to get 24 channels to RAM), but then reading about NUMA issues I realized it might not help much - quite the opposite. Even cross-CCDs memory access has a negative effect, so I can see why PCIE transfers should be avoided as much as possible.
Yeah give your BIOS configuration as well e.g. if you have dual socket are you running
NPS0(normally not a good idea, but for this workload probably best if you can't fit the model in a single socket's worth of RAM in NPS1) etc...I believe if you use dual GPU and are offloading efficiently TG should definitely be like ~1 tok/sec faster or so probably as a 4090 with ~1TB/sec VRAM bandwidth bets almost any CPU RAM speeds.
👤 ikawrakow replied the 2025-07-10 at 15:33:00:
@ubergarmBtw, the other day I randomly came across a discussion in the KTransformers repository where 2 guys were thinking that
ik_llama.cpprequires a "different format" (and they didn't like that). Apparently they came to that conclusion because of yourik_llama.cppspecific quants on HF. See this comment (and you may want to read the response to my comment). So, perhaps it would be a good idea to actually add a clarification to your HF repos thatik_llama.cppalso works with "standard" GGUFs, so people don't need to download these giant models just to tryik_llama.cpp.👤 ubergarm replied the 2025-07-10 at 16:54:58:
I attempted to address it there also: https://github.com/kvcache-ai/ktransformers/issues/1417#issuecomment-3058222619I'll spend some time updating my huggingface model cards so hopefully people don't make this mistake and accidentally spread more misinformation.
Kind of reminds me of "Brandolini's law" aka the "bullshit asymmetry principle":
The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it.
thanks
UPDATE: Adding this to the model cards:
Note
ik_llama.cppcan also run your existing GGUFs from bartowski, unsloth, mradermacher, etc if you want to try it out before downloading my quants.
👤 ikawrakow replied the 2025-06-24 at 14:16:26:
@sousekd
Thank you for the kind words!
Honestly, I’m unsure if I'm losing performance by disabling GGML_AVX512_BF16, but I couldn't compile it with MSVC otherwise. Similarly, I'm curious about any actual benefits from enabling both GGML_AVX512 and GGML_AVX512_VNNI as I have not seen them mentioned in the guide - so I'd love some insights here!
Please post the compilation errors you get with AVX512_BF16. It is supposed to work, but I guess there is GCC/clang-specific stuff that I must have missed. The only impact native BF16 support has is when running inference with bf16 models, so you will not see a difference with quantized models.
There are places where I have added GEMM/GEMV implementations optimized for AVX512 extensions that I have available on my Ryzen-7950X CPU (Zen4 core). To be effective, one needs to enable AVX512, AVX512_VNNI, AVX512VL, AVX512BW and AVX512DQ. I don't think these are all available via GGML_something cmake definitions. When building on Linux they all get enabled with GGML_NATIVE, but on Windows you most likely need to work with -DGGML_ARCH_FLAGS=add_necessary_compiler_flags. TG performance is memory bound, so there will not be much impact there, but for PP you may get some additional performance increases if your CPU supports all of these.
👤 sousekd replied the 2025-06-24 at 15:26:15:
Please post the compilation errors you get with
AVX512_BF16. It is supposed to work, ...Oh, you are 100% correct and I am an idiot. ik_llama.cpp builds perfectly fine with
-DGGML_AVX512_BF16=ONusing MSVC - it was (and is) llama.cpp which does not build. I was experimenting with both and got confused :). Thank you!
👤 createthis replied the 2025-07-10 at 16:13:24:
I have a dual EPYC 9355 system which normally has 768gb of RAM across 24 channels and scores roughly 720gb/s memory bandwidth on the stream triad test. At the moment, I had a RDIMM failure, so I'm down a stick and I only have 23 channels and 736gb of system RAM. I also have a blackwell 6000 pro on this system.
I run with NPS4 set in the system BIOS, so I have 8 numa domains. I typically run Deepseek-V3-0324 671b:Q4_K_XL, so that's the model I'll be showing benchmarks for here.
I run this before every llama server startup:
echo 0 | sudo tee /proc/sys/kernel/numa_balancing
echo 3 | sudo tee /proc/sys/vm/drop_caches
Using llama.cpp, it's common to see 20 - 22 tok/s generation and between 5 and 40 tok/s PP. Example benchmark:
./build/bin/llama-batched-bench \
--model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \
--numa numactl \
--threads 32 \
--ctx-size 163840 \
--n-gpu-layers 62 \
-ot ".ffn_.*_exps.=CPU" \
--seed 3407 \
--prio 3 \
--temp 0.3 \
--min-p 0.0 \
--flash-attn \
-npp 512 -ntg 128 -npl 1
main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 512, flash_attn = 1, is_pp_shared = 0, n_gpu_layers = 62, n_threads = 32, n_threads_batch = 32
| PP | TG | B | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | T s | S t/s |
|-------|--------|------|--------|----------|----------|----------|----------|----------|----------|
| 512 | 128 | 1 | 640 | 24.441 | 20.95 | 5.973 | 21.43 | 30.414 | 21.04 |
With ik_llama.cpp, I see significantly higher PP tok/s, but significantly lower generation tok/s. I played with a few settings and this is my best benchmark so far:
./build/bin/llama-sweep-bench \
--model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \
--alias DeepSeek-V3-0324:671b-q4_k_xl \
--numa numactl \
--threads 32 \
--ctx-size 163840 \
--n-gpu-layers 62 \
-ot ".ffn_.*_exps.=CPU" \
--seed 3407 \
--temp 0.3 \
--min-p 0.0 \
--flash-attn \
--host 0.0.0.0 \
-mla 3 \
-fmoe \
-rtr \
--port 11434
main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 62, n_threads = 32, n_threads_batch = 32
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|-------|--------|--------|----------|----------|----------|----------|
| 512 | 128 | 0 | 3.862 | 132.56 | 15.186 | 8.43 |
| 512 | 128 | 512 | 3.851 | 132.94 | 15.240 | 8.40 |
| 512 | 128 | 1024 | 3.873 | 132.19 | 15.232 | 8.40 |
| 512 | 128 | 1536 | 3.925 | 130.45 | 15.253 | 8.39 |
I'm just curious: Why is generation tok/s so much lower in ik_llama.cpp vs llama.cpp? I think I prefer the higher PP speed for agentic work, but I haven't tested enough to decide yet. I'm just curious why there is such a dramatic generation difference.
Thanks!
👤 ubergarm replied the 2025-07-10 at 17:33:21:
Hey thanks for taking some time to try this out. I too started using ktransformers but have since moved over to ik's for given he is the author on pretty much all the quants after the originalq8_0types.I run with NPS4 set in the system BIOS, so I have 8 numa domains.
Both myself an fairydreaming have done a lot of research on the NUMA domain issue for both intel xeon and amd epyc dual socket rigs.
the tl;dr; is I recommend you try out
NPS0for dual socket systems given the nature of this workload being not optimized. The more NUMA nodes you have likely the worse performance, but if you must use more NUMA domains because of other system workloads then consider running with either:# if u need RAM from all NUMA nodes to fit the model numactl --interleave=all llama-server --numactl distribute ... # if a single NUMA node (e.g. in NPS1) has enough RAM: numactl -N 0 -m 0 llama-server --numactl numactl ...Generally PP will benefit from as much physical cores that you can throw at it, but TG will likely be fastest with some smaller number of threads so get the best of both worlds with
--threads-batch <num_phys_corses> --threads <slightly_less_sometimes>etc...I've been helping folks tune their exact command to get max speed, so I'll take a crack at yours as it stands assuming you are still running with 8 numa domains and haven't attempted the above BIOS optimizations yet:
# build for RTX PRO Blackwel 96GB VRAM arch/capabilities 120 psure cmake -B ./build -DGGML_CUDA=ON -DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_IQK_FORCE_BF16=1 -DCMAKE_CUDA_ARCHITECTURES="120" cmake --build ./build --config Release -j $(nproc) # run on single CPU socket assuming NPS4 (4x domains per socket) numactl --interleave=0,1,2,3 \ ./build/bin/llama-sweep-bench \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ -fa -mla 3 -fmoe -amb 512 -mg 0 \ --ctx-size 20480 \ -ngl 99 \ -ot "blk\.(3|4|5|6|7|8)\.ffn_.*=CUDA0" \ -ot exps=CPU \ --threads 32 \ --threads-batch 32 \ -ub 4096 -b 4096 \ -rtr \ --numa numactl \ --warmup-batchAdjust
-ot "blk\.(3|4|5|6|7|8)\.ffn_.*=CUDA0" \as high as it goes without OOMing... This is how we do multi-GPU here vs ktransformers chat yaml things. Also here on ik's fork there is no performance hit offloading additonal layers like ktransformers (at least used to have) due to its cuda graphs stuff.
-DGGML_SCHED_MAX_COPIES=1is also in mainline llama.cpp and the default is 4 pipeline parallel but using 1 is much more simple and allows more VRAM and easier for multi-GPU and then just increase batches for more speed. You will possibly see a debug log likellama_new_context_with_model: pipeline parallelism enabled (n_copies=1).Once you've dialed in the command you can then just switch out the executable back to
llama-serverand add back in alias/host/port and remove--warmup-batch.Okay, let me know if u have any questions, you have a very nice rig!
👤 sousekd replied the 2025-07-10 at 18:29:53:
Hi @createthis, I was able to achieve the following on (single) Epyc 9355 and RTX 5090:
PP TG N_KV T_PP s S_PP t/s T_TG s S_TG t/s 2048 512 0 12.944 158.22 31.369 16.32 2048 512 2048 13.033 157.14 31.081 16.47 2048 512 4096 14.656 139.74 32.354 15.83 As @ubergarm noted, try NPS0. Also, did you experiment with --numa param? I am not sure how/whether it is supported here.
Edit: Huh, haven't seen @ubergarm's full response 😀.
👤 ikawrakow replied the 2025-07-10 at 16:46:17:
@createthis
I think you are observing a difference in GPU offload policy. In llama.cpp model tensors that are stored in RAM will get offloaded to the GPU whenever the batch size is greater than 32 tokens. This results in a seriously low PP performance for a MoE model and the batch sizes you are using. But fort TG, because the tokens are generated in batches, the offload to the GPU helps, and you get a better TG performance (which is about the same as PP, as you are basically measuring how long it takes to offload tensors to the GPU). In ik_llama.cpp I have changed the offload to the GPU for MoE models to only kick in if the batch size is greater than
32 * total_experts / active_experts
which for DeepSeek-R1/V3 translates to 1024 tokens. So, basically, in this benchmark you are not using the GPU at all, everything runs on the CPU when using ik_llama.cpp!
batched-bench results can be quite confusing and not immediately easy to interpret. Unless you are planning to be serving multiple users at once (and using relatively small batches to reduce response latency), it may be easier to get going by looking at PP and TG performance as a function of the tokens in the KV cache. In ik_llama.cpp you have llama-sweep-bench for that, so for instance
./bin./llama-sweep-bench -m $model -c 32768 -b 4096 -ub 4096 -mla 3 -fa -fmoe -amb 512 -t 32 -ngl 100 -ot exps=CPU
will give a nice table with PP and TG performance for 0...32k tokens in the KV cache.
I think in llama.cpp they have added the --depth argument to llama-bench that allows you to get similar results.
Another comment related to the NUMA situation: I don't have access to a NUMA system myself, but people report that, sadly, on dual socket systems they get the best performance by disabling NUMA in the BIOS and running on a single CPU. @ubergarm has done quite a few experiments in that regard. I haven't followed what is happening in llama.cpp land on that front, so maybe they have improved in the meantime (but hadn't only 2-3 months ago).
👤 ikawrakow replied the 2025-07-10 at 16:48:34:
But apart from everything else, worth pointing out thatik_llama.cppneeds only half the total time for PP+TG compared tollama.cpp.
👤 Panchovix replied the 2025-07-10 at 20:39:17:
Just to let you know guys, did some benchmarks on iklcpp on my setup (192GB RAM + 208GB VRAM) on DeepSeek V3/R1/Chimera of Q2_K_XL, IQ3_XXS, IQ3_KS, Q3_K_XL and IQ4_XS on reddit, if you want to take a look!
https://www.reddit.com/r/LocalLLaMA/comments/1lwnj5x/performance_benchmarks_on_deepseek/
Performance of ikllamacpp for these kind of setups, is really impressive!
👤 createthis replied the 2025-07-10 at 21:35:54:
@ikawrakow here it is with NPS0:
mla 3
./build/bin/llama-sweep-bench \
--model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \
--alias DeepSeek-V3-0324:671b-q4_k_xl \
--threads 32 \
--ctx-size 163840 \
--n-gpu-layers 62 \
-ot ".ffn_.*_exps.=CPU" \
--seed 3407 \
--temp 0.3 \
--min-p 0.0 \
--flash-attn \
--host 0.0.0.0 \
-mla 3 \
-fmoe \
-rtr \
--port 11434
main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 62, n_threads = 32, n_threads_batch = 32
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|-------|--------|--------|----------|----------|----------|----------|
| 512 | 128 | 0 | 3.677 | 139.23 | 12.996 | 9.85 |
| 512 | 128 | 512 | 3.994 | 128.19 | 13.160 | 9.73 |
| 512 | 128 | 1024 | 4.020 | 127.37 | 13.161 | 9.73 |
| 512 | 128 | 1536 | 4.279 | 119.65 | 13.426 | 9.53 |
| 512 | 128 | 2048 | 4.193 | 122.11 | 13.596 | 9.41 |
| 512 | 128 | 2560 | 3.868 | 132.38 | 12.987 | 9.86 |
| 512 | 128 | 3072 | 4.655 | 109.98 | 13.682 | 9.36 |
| 512 | 128 | 3584 | 4.291 | 119.31 | 13.344 | 9.59 |
| 512 | 128 | 4096 | 4.287 | 119.44 | 12.890 | 9.93 |
| 512 | 128 | 4608 | 4.221 | 121.29 | 12.835 | 9.97 |
mla 2
./build/bin/llama-sweep-bench \
--model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \
--alias DeepSeek-V3-0324:671b-q4_k_xl \
--threads 32 \
--ctx-size 163840 \
--n-gpu-layers 62 \
-ot ".ffn_.*_exps.=CPU" \
--seed 3407 \
--temp 0.3 \
--min-p 0.0 \
--flash-attn \
--host 0.0.0.0 \
-mla 2 \
-fmoe \
-rtr \
--port 11434
main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 62, n_threads = 32, n_threads_batch = 32
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|-------|--------|--------|----------|----------|----------|----------|
| 512 | 128 | 0 | 3.766 | 135.95 | 12.805 | 10.00 |
| 512 | 128 | 512 | 3.774 | 135.66 | 12.753 | 10.04 |
| 512 | 128 | 1024 | 3.833 | 133.59 | 13.051 | 9.81 |
| 512 | 128 | 1536 | 4.051 | 126.38 | 13.200 | 9.70 |
| 512 | 128 | 2048 | 3.882 | 131.89 | 13.089 | 9.78 |
| 512 | 128 | 2560 | 3.887 | 131.71 | 13.085 | 9.78 |
| 512 | 128 | 3072 | 3.993 | 128.24 | 13.275 | 9.64 |
| 512 | 128 | 3584 | 4.380 | 116.89 | 13.879 | 9.22 |
| 512 | 128 | 4096 | 4.273 | 119.82 | 13.199 | 9.70 |
| 512 | 128 | 4608 | 4.115 | 124.41 | 12.996 | 9.85 |
Doesn't seem to make much difference mla 2 vs 3.
PP speed does continue to rise past 32 threads though, which is suprising:
./build/bin/llama-sweep-bench \
--model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \
--alias DeepSeek-V3-0324:671b-q4_k_xl \
--threads 61 \
--ctx-size 163840 \
--n-gpu-layers 62 \
-ot ".ffn_.*_exps.=CPU" \
--seed 3407 \
--temp 0.3 \
--min-p 0.0 \
--flash-attn \
--host 0.0.0.0 \
-mla 2 \
-fmoe \
-rtr \
--port 11434
main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 62, n_threads = 61, n_threads_batch = 61
| PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s |
|-------|--------|--------|----------|----------|----------|----------|
| 512 | 128 | 0 | 3.274 | 156.36 | 12.792 | 10.01 |
| 512 | 128 | 512 | 3.174 | 161.33 | 12.924 | 9.90 |
| 512 | 128 | 1024 | 3.099 | 165.22 | 13.011 | 9.84 |
| 512 | 128 | 1536 | 3.204 | 159.83 | 13.140 | 9.74 |
| 512 | 128 | 2048 | 3.196 | 160.22 | 13.131 | 9.75 |
| 512 | 128 | 2560 | 3.093 | 165.54 | 13.327 | 9.60 |
| 512 | 128 | 3072 | 3.443 | 148.70 | 13.393 | 9.56 |
| 512 | 128 | 3584 | 3.369 | 151.97 | 13.454 | 9.51 |
| 512 | 128 | 4096 | 3.413 | 150.02 | 13.577 | 9.43 |
👤 ubergarm replied the 2025-07-10 at 23:13:21:
@createthis./build/bin/llama-batched-bench
I've never used
llama-batched-benchbut @saood06 has mentioned it before. Is that why you're seeing more TG tok/sec there? It might be comparing something different thanllama-sweep-bench? I know usingllama-server --parallel 4for example gives higher aggregate throughput at a cost to individual request speeds.PP speed does continue to rise past 32 threads though, which is suprising:
This is as expected as PP is CPU limited, so more cores will give some speed boosts there.
Okay cool looks like you got it into NPS0! So now that you don't need to worry about numactl, give this a try:
./build/bin/llama-sweep-bench \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ -fa -mla 3 -fmoe -amb 512 -mg 0 \ --ctx-size 20480 \ -ngl 99 \ -ot "blk\.(3|4|5|6|7|8)\.ffn_.*=CUDA0" \ -ot exps=CPU \ --threads 48 \ --threads-batch 64 \ -ub 4096 -b 4096 \ -rtr \ --warmup-batchThe trade off is how you want to spend your VRAM:
- you will get more PP by increasing
-ub -b- you will get more TG by offloading more layers with
-ot ...- try with and without
-rtras benefits can vary with batch sizeIf it OOMs on VRAM already, just back off how many offload layers e.g.
-ot "blk\.(3|4|5)\.ffn_.*=CUDA0" \👤 saood06 replied the 2025-07-10 at 23:23:43:
./build/bin/llama-batched-bench
I've never used
llama-batched-benchbut @saood06 has mentioned it before. Is that why you're seeing more TG tok/sec there? It might be comparing something different thanllama-sweep-bench? I know usingllama-server --parallel 4for example gives higher aggregate throughput at a cost to individual request speeds.He is using it with a batch size of 1, so no aggregating performance, and it is at 0 depth so it should be comparable to the first line of a
sweep-benchor even standardbenchresult.
llama-batched-benchis a really nice tool for evaluating performance, but I tend to use it to performance for specific scenarios by providing specific parameters, unlikellama-sweep-benchwhere I mostly just choose how long/deep I want to test.👤 createthis replied the 2025-07-11 at 02:37:27:
@ubergarm./build/bin/llama-sweep-bench \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ -fa -mla 3 -fmoe -amb 512 -mg 0 \ --ctx-size 20480 \ -ngl 99 \ -ot "blk\.(3|4|5|6|7|8)\.ffn_.*=CUDA0" \ -ot exps=CPU \ --threads 48 \ --threads-batch 64 \ -ub 4096 -b 4096 \ -rtr \ --warmup-batchThe trade off is how you want to spend your VRAM:
you will get more PP by increasing -ub -b you will get more TG by offloading more layers with -ot ... try with and without -rtr as benefits can vary with batch size
If it OOMs on VRAM already, just back off how many offload layers e.g. -ot "blk.(3|4|5).ffn_.*=CUDA0" \
./build/bin/llama-sweep-bench \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ -fa -mla 3 -fmoe -amb 512 -mg 0 \ --ctx-size 163840 \ -ngl 99 \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ --threads 32 \ --threads-batch 64 \ -ub 4096 -b 4096 \ -rtr \ --warmup-batch main: n_kv_max = 163840, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, n_gpu_layers = 99, n_threads = 32, n_threads_batch = 64 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 4096 | 1024 | 0 | 14.037 | 291.81 | 81.438 | 12.57 | | 4096 | 1024 | 4096 | 18.769 | 218.24 | 70.924 | 14.44 | | 4096 | 1024 | 8192 | 22.589 | 181.33 | 67.183 | 15.24 |Whoa! The limiting factor has become the cooling capacity of my chassis. I'm having to throttle back the settings to avoid pushing the CPUs and CPU voltage regulators too far beyond 60C.
Interesting notes: I couldn't increase
-otbeyond11. Also, lowering-ub and -bback down to512didn't save VRAM, but it did make it slower.EDIT: This, unfortunately, does not really translate into real world performance, but real world performance is still pretty good:
./build/bin/llama-server \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --alias DeepSeek-V3-0324:671b-q4_k_xl \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ --threads 32 \ --threads-batch 64 \ -ub 4096 -b 4096 \ --ctx-size 163840 \ --n-gpu-layers 62 \ --seed 3407 \ --temp 0.3 \ --min-p 0.0 \ --flash-attn \ --host 0.0.0.0 \ -mla 3 \ -fmoe \ -amb 512 \ -mg 0 \ -rtr \ --port 11434
👤 sousekd replied the 2025-07-11 at 06:06:26:
Great numbers @createthis! Would the model fit to only half of your RAM? I would be very interested to see the numbers when using only one socket, to avoid slower 4x16 xGMI3 link between CPUs.I have very similar system to yours (Epyc 9355 on MZ73-LM2), but with only one CPU populated (and still waiting for RTX 6000 to arrive).
👤 createthis replied the 2025-07-11 at 13:06:10:
@sousekd It's using about 300gb of system ram and nearly the entire 96gb of VRAM. I'm not sure if that's sustainable at full context length as my current work project doesn't require agentic loads at the moment, but I'll stress test it as soon as I get a chance. I suspect single socket performance will be lower, but I'm not sure. Please report back and let us know.👤 createthis replied the 2025-07-11 at 14:00:50:
Here are thellama.cppnumbers with the same settings (and NPS0):./build/bin/llama-batched-bench \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --threads 32 \ --ctx-size 163840 \ --n-gpu-layers 62 \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ -ub 4096 -b 4096 \ --seed 3407 \ --prio 3 \ --temp 0.3 \ --min-p 0.0 \ --flash-attn \ -npp 4096 \ -ntg 1024 \ -npl 1 main: n_kv_max = 163840, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, is_pp_shared = 0, n_gpu_layers = 62, n_threads = 32, n_threads_batch = 32 | PP | TG | B | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | T s | S t/s | |-------|--------|------|--------|----------|----------|----------|----------|----------|----------| | 4096 | 1024 | 1 | 5120 | 12.963 | 315.98 | 93.325 | 10.97 | 106.287 | 48.17 |Double whoa.
EDIT: This, unfortunately, does NOT translate into real world performance:
./build/bin/llama-server \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --alias DeepSeek-V3-0324:671b-q4_k_xl \ --no-webui \ --threads 32 \ --ctx-size 163840 \ --n-gpu-layers 62 \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ -ub 4096 -b 4096 \ --seed 3407 \ --prio 3 \ --temp 0.3 \ --min-p 0.0 \ --log-colors \ --flash-attn \ --host 0.0.0.0 \ --jinja \ --port 11434
👤 ubergarm replied the 2025-07-11 at 15:24:50:
@createthisGreat job tuning and reporting your findings, much appreciated! Hope your rig is holding up under the stress and heat haha...
It's using about 300gb of system ram and nearly the entire 96gb of VRAM. I'm not sure if that's sustainable at full context length
Yeah you could configure your system into NPS1 for example and use
numactl -N 0 -m 0 llama-sweep-bench --numa numactl ...to test using just a single socket. My guess is PP would be reduced (as it is CPU bound and benefits from the extra core), however TG might remain the same or possibly slightly increase. If you can startup with the context it is all pre-allocated and shouldn't OOM after filling context (though with large ub i have seen it oom vram when deeper into kv-cache).Your NPS0 is probably the best setup for now until any multi-NUMA optimization come along that work consistently without going full on data parallel two copies of the weights.
This, unfortunately, does not really translate into real world performance
Looking at your screen captures, you're only sending a small ~200 token prompt for this "real world" test. Given the batch size is 4096 you won't see the full benefit on such small prompts. If you're processing real "real world" prompts you should see the benefits. I take those single short 1shot prompt llama-server speeds with a grain of salt and much prefer llama-sweep-bench for the full view.
Here are the llama.cpp numbers with the same settings
So you're using that
llama-batched-benchagain and I'm sus of the TG numbers. Either mainline llama.cpp is much faster at TG and almost breaking the theoretical limit of your rig (720 GB/s memory bandwidth divided by 37B active weights with guestimate ~15GiB [given partial offload with a ~4bpw quant] would be 48 tok/sec). Given inefficiencies of NPS0 and latency etc I've never seen multi CPU rig get within 70% of theoretical max TG.If you could provide a more apples-apples comparison, I maintain a branch of mainline llama.cpp patched with
llama-sweep-benchhere on my fork. You would run the same command as ik_llama.cpp but omit the--warmup-batchas it is hardcoded enabled.cd llama.cpp git remote add ubergarm https://github.com/ubergarm/llama.cpp.git git fetch ubergarm git checkout ug/port-sweep-bench # build as you normally build mainline llama.cpp # now u can run llama-sweep-bench on mainlineAppreciate you sharing all your results!
👤 createthis replied the 2025-07-11 at 16:47:25:
Another sort of interesting result: This is NPS4 withllama.cpp:./build/bin/llama-batched-bench \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --numa numactl \ --threads 32 \ --ctx-size 163840 \ --n-gpu-layers 62 \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ -ub 4096 -b 4096 \ --seed 3407 \ --prio 3 \ --temp 0.3 \ --min-p 0.0 \ --flash-attn \ -npp 4096 \ -ntg 1024 \ -npl 1 main: n_kv_max = 163840, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, is_pp_shared = 0, n_gpu_layers = 62, n_threads = 32, n_threads_batch = 32 | PP | TG | B | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | T s | S t/s | |-------|--------|------|--------|----------|----------|----------|----------|----------|----------| | 4096 | 1024 | 1 | 5120 | 21.628 | 189.38 | 46.545 | 22.00 | 68.173 | 75.10 |The "real world" numbers, which are small context, as you pointed out:
./build/bin/llama-server \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --alias DeepSeek-V3-0324:671b-q4_k_xl \ --no-webui \ --numa numactl \ --threads 32 \ --ctx-size 163840 \ --n-gpu-layers 62 \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ -ub 4096 -b 4096 \ --seed 3407 \ --prio 3 \ --temp 0.3 \ --min-p 0.0 \ --log-colors \ --flash-attn \ --host 0.0.0.0 \ --jinja \ --port 11434
It is a huge time suck switching between NPS0 and NPS4. The machine takes like 10 minutes to reboot.
@ubergarm I'm interested in trying out your llama.cpp sweep benchmark. I need to get some work done on a paid project at the moment, but I'll try to take a look later this weekend and report my findings. I'll also report higher context real world results as they come in. I don't have an agentic workload at the moment, so I'm not sure when that will be, but maybe I can fabricate one this weekend if nothing pops up today.
Thanks for all the feedback and help thus far!
👤 createthis replied the 2025-07-11 at 20:56:50:
This is still NPS4 withllama.cpp, just because I've been too lazy to reboot into NPS0.I'm never 100% sure I'm reading these correctly, but I think this is performance at
47kcontext:./build/bin/llama-server \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --alias DeepSeek-V3-0324:671b-q4_k_xl \ --no-webui \ --numa numactl \ --threads 32 \ --ctx-size 163840 \ --n-gpu-layers 62 \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ -ub 4096 -b 4096 \ --seed 3407 \ --prio 3 \ --temp 0.3 \ --min-p 0.0 \ --log-colors \ --flash-attn \ --host 0.0.0.0 \ --jinja \ --port 11434
Not too shabby performance.
EDIT: updated to be the same prompt as the below 47k context "real world" examples for an apples to apples comparison
👤 createthis replied the 2025-07-11 at 22:06:31:
"real world" NPS0 withllama.cppand 47k context (same prompt as last one, I just hit regenerate):./build/bin/llama-server \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --alias DeepSeek-V3-0324:671b-q4_k_xl \ --no-webui \ --threads 32 \ --ctx-size 163840 \ --n-gpu-layers 62 \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ -ub 4096 -b 4096 \ --seed 3407 \ --prio 3 \ --temp 0.3 \ --min-p 0.0 \ --log-colors \ --flash-attn \ --host 0.0.0.0 \ --jinja \ --port 11434
This is in-line with my original findings.
llama.cppseems to prefer NPS4 for some reason.👤 createthis replied the 2025-07-11 at 22:25:43:
"real world" NPS0ik_llama.cpp47k context. I just replayed the last prompt../build/bin/llama-server \ --model /data/DeepSeek-V3-0324-GGUF-UD/UD-Q4_K_XL/DeepSeek-V3-0324-UD-Q4_K_XL-00001-of-00008.gguf \ --alias DeepSeek-V3-0324:671b-q4_k_xl \ -ot "blk\.(3|4|5|6|7|8|9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \ --threads 32 \ --threads-batch 64 \ -ub 4096 -b 4096 \ --ctx-size 163840 \ --n-gpu-layers 62 \ --seed 3407 \ --temp 0.3 \ --min-p 0.0 \ --flash-attn \ --host 0.0.0.0 \ -mla 3 \ -fmoe \ -amb 512 \ -mg 0 \ -rtr \ --port 11434
This performance is quite good. PP is slightly better than NPS4
llama.cpp. Gen is a fair bit lower though. Based on these numbers alone, I would probably opt forllama.cppwith NPS4, but I'm not convinced the verdict is out yet. I plan to run them both agentically for a while and see which one I like better.👤 magikRUKKOLA replied the 2025-07-11 at 22:50:35:
@createthis as related to the comparison of ik_llama.cpp and llama.cpp. The following likely unrelated to your case, but I will mention it just in case someone else would have the issue. Today I was installing the ik_llama.cpp and was unable to [do] it. It was falling out with:undefined symbol: ggml_backend_reg_get_countafter stracing it I realized that the compiled ik_llama.cpp binary is trying to pickup the /usr/local/lib/libggml.so and /usr/local/lib/libggml-base.so. I realized that these are from the old installation of ollama! Hence please make sure that the ik_llama.cpp doesn't pick up the libraries from the llama.cpp and wise versa lol! Again, it might be absolutely unrealed but still.
👤 magikRUKKOLA replied the 2025-07-10 at 23:24:47:
transferring from https://github.com/kvcache-ai/ktransformers/issues/1417
Short story -- I would like to switch to the ik_llama.cpp from ktransformers (the ktransformers are having huge problems with the stability).
I would like to know how I can run Deepseek R1/V3 with 128k context and more.
In the ktransformers they used the matrix absorption trick ( https://docs.flashinfer.ai/api/mla.html, https://github.com/madsys-dev/deepseekv2-profile/blob/main/workspace/blog/optimizing-mla.md ) -- that is, the flashinfer allows to use one 24GB GPU to prefill up to 128k context (i never tried more because I didn't know the Deepseek supports 163k).
So what can be done currently in my case to support large context? I have a various machines mostly with Threadripper Pro 3995wx (inc. lenovo-locked), overclocked Samsung ECC RAM up to 3200 MT/s and currently up to 3 GPUs RTX 3090 FE per workstation with p2p enabled:
/opt/nvidia/cuda-samples/Samples/5_Domain_Specific/p2pBandwidthLatencyTest/build/p2pBandwidthLatencyTest
[P2P (Peer-to-Peer) GPU Bandwidth Latency Test]
Device: 0, NVIDIA GeForce RTX 3090, pciBusID: 41, pciDeviceID: 0, pciDomainID:0
Device: 1, NVIDIA GeForce RTX 3090, pciBusID: 42, pciDeviceID: 0, pciDomainID:0
Device: 2, NVIDIA GeForce RTX 3090, pciBusID: 61, pciDeviceID: 0, pciDomainID:0
Device=0 CAN Access Peer Device=1
Device=0 CAN Access Peer Device=2
Device=1 CAN Access Peer Device=0
Device=1 CAN Access Peer Device=2
Device=2 CAN Access Peer Device=0
Device=2 CAN Access Peer Device=1
Bidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1 2
0 840.24 52.01 51.95
1 52.01 839.38 52.04
2 52.04 52.04 840.28
P2P=Enabled Latency (P2P Writes) Matrix (us)
GPU 0 1 2
0 1.62 1.08 1.06
1 1.07 1.58 1.05
2 1.08 1.09 1.59
CPU 0 1 2
0 2.55 2.08 2.10
1 2.26 2.58 2.15
2 2.11 2.04 2.51
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.51.02 Driver Version: 575.51.02 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:41:00.0 Off | N/A |
| 30% 43C P8 20W / 350W | 4225MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 3090 Off | 00000000:42:00.0 Off | N/A |
| 0% 39C P8 8W / 350W | 18529MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA GeForce RTX 3090 Off | 00000000:61:00.0 Off | N/A |
| 0% 42C P8 9W / 350W | 16063MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 3181836 C whisper-server 4216MiB |
| 1 N/A N/A 3637807 C llama-server 18520MiB |
| 2 N/A N/A 3637807 C llama-server 16054MiB |
+-----------------------------------------------------------------------------------------+
Currently researching what @ubergarm suggested and actually trying to fix the bug in ktransformers.
Please advise what can be done.
[EDIT]:
Currently doing this:
CUDA_VISIBLE_DEVICES="0" \
/opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server \
--model /opt/anikifoss/DeepSeek-R1-0528-DQ4_K_R4/DeepSeek-R1-0528-DQ4_K_R4-00001-of-00010.gguf \
--alias anikifoss/DeepSeek-R1-0528-DQ4_K_R4 \
--ctx-size $((41 * 1024)) \
--temp 0.5 --top-k 0 --top-p 1.0 --min-p 0.1 --repeat-penalty 1.0 \
-ctk q8_0 \
-mla 3 -fa \
-amb 512 \
-b 1024 -ub 1024 \
-fmoe \
--n-gpu-layers 99 \
--override-tensor exps=CPU,attn_kv_b=CPU \
--threads $(grep ^cpu\\scores /proc/cpuinfo | uniq | awk '{print $4}' | xargs -I{} echo "{}-0" | bc) \
--host 0.0.0.0 \
--port 8080
Its running well on a single GPU but its only 41k context. -mla 3 is significantly better that -mla 2 for decode t/s in my case.
[EDIT2]: it seems to be that lots of people having trouble using flashinfer instead of flash attention. For example:
https://github.com/turboderp-org/exllamav3
FlashAttention-2 is currently required. I hope to switch over to FlashInfer in time, but there are some obstacles to overcome first.
The same thing goes for ik_llama.cpp etc. -- the matrix absorption trick in flash infer is not available in flashattn hence the for the full context in ik_llama.cpp its required to have at least 48 GB VRAM which is not ideal.
👤 ubergarm replied the 2025-07-10 at 23:42:50:
Sorry not sure which of these is the real one, I replied over here: https://github.com/ikawrakow/ik_llama.cpp/discussions/477#discussioncomment-13726306👤 ubergarm replied the 2025-07-10 at 23:51:29:
@magikRUKKOLASo let's assume you have a thread ripper configured in NPS1 so all your RAM is in a single NUMA node and 3x CUDA devices, give this a try:
compile
For multi-GPU deepseek inferencing I use:
cmake -B ./build -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_IQK_FORCE_BF16=1 cmake --build ./build --config Release -j $(nproc)api-server
That particular quant is fine and despite having full q8_0 attn/shexp/first 3 dense layers you should still be able to run full 160k context and have additional VRAM to spare. It is fairly slow though and I'd personally recommend something a bit smaller made with imatrix, but feel free to choose whichever quant suites your speed/accurace trade-off taste. Perhaps ubergarm/DeepSeek-TNG-R1T2-Chimera-IQ3_KS or this freshly uploaded same recipe ubergarm/DeepSeek-R1-0528-GGUF/IQ3_KS would suit. (give the R1-0528 45 minutes to finish uploading lol)
/opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server \ --model /opt/anikifoss/DeepSeek-R1-0528-DQ4_K_R4/DeepSeek-R1-0528-DQ4_K_R4-00001-of-00010.gguf \ --alias anikifoss/DeepSeek-R1-0528-DQ4_K_R4 \ --ctx-size 163840 \ --temp 0.5 --top-k 0 --top-p 1.0 --min-p 0.1 --repeat-penalty 1.0 \ -ctk q8_0 \ -fa -fmoe -mla 3 \ -amb 512 \ -b 4096 -ub 4096 \ -ngl 99 \ -ot exps=CPU \ --threads $(grep ^cpu\\scores /proc/cpuinfo | uniq | awk '{print $4}' | xargs -I{} echo "{}-0" | bc) \ --host 0.0.0.0 \ --port 8080You have enough VRAM that you could then get bigger gains experimenting offloading more layers until it OOMs. Keep the order in mind as the regex catch in order listed:
-ngl 99 \ -ot "blk\.(3|4|5)\.ffn_.*=CUDA0" \ -ot "blk\.(6|7|8)\.ffn_.*=CUDA0" \ -ot "blk\.(9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \👤 magikRUKKOLA replied the 2025-07-11 at 13:11:37:
@ubergarmI decided to install the additional fans for the ECC ram so I haven't tried yet the config with three GPU. But I decided to try it out with two GPUs on my test rig with Threadripper PRO 3[9]45wx (only 12 cores) with 96k context.
As related to the:
-ngl 99 \ -ot "blk\.(3|4|5)\.ffn_.*=CUDA0" \ -ot "blk\.(6|7|8)\.ffn_.*=CUDA0" \ -ot "blk\.(9|10|11)\.ffn_.*=CUDA0" \ -ot exps=CPU \Possibly you may mean it like:
-ngl 99 \ -ot "blk\.(3|4|5)\.ffn_.*=CUDA0" \ -ot "blk\.(6|7|8)\.ffn_.*=CUDA1" \ -ot "blk\.(9|10|11)\.ffn_.*=CUDA2" \ -ot exps=CPU \?
Well, I am not sure I will be able to put anything onto the CUDA0 since its VRAM is almost taken with the KV-cache. So I tried to skip the first three dense layers and to the next three to the CUDA1:
#!/usr/bin/env bash #CUDA_VISIBLE_DEVICES="0" \ # --override-tensor exps=CPU,attn_kv_b=CPU \ CUDA_VISIBLE_DEVICES="0,1" \ /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server \ --model /opt/anikifoss/DeepSeek-R1-0528-DQ4_K_R4/DeepSeek-R1-0528-DQ4_K_R4-00001-of-00010.gguf \ --alias anikifoss/DeepSeek-R1-0528-DQ4_K_R4 \ --ctx-size $((96 * 1024)) \ --temp 0.5 --top-k 0 --top-p 1.0 --min-p 0.1 --repeat-penalty 1.0 \ -ctk q8_0 \ -mla 3 -fa \ -amb 512 \ -b $((4 * 1024)) -ub $((4 * 1024)) \ -fmoe \ --n-gpu-layers 99 \ --override-tensor exps=CPU \ --threads $(grep ^cpu\\scores /proc/cpuinfo | uniq | awk '{print $4}' | xargs -I{} echo "{}-0" | bc) \ --host 0.0.0.0 \ --port 8080 \ --lookup-cache-dynamic /mnt/data/ik_llama.kv.dump \ -ot "blk\.(3|4|5)\.ffn_.*=CUDA1"Fri Jul 11 11:58:42 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 575.51.02 Driver Version: 575.51.02 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3090 Off | 00000000:01:00.0 Off | N/A | | 33% 52C P8 29W / 350W | 22256MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA GeForce RTX 3090 Off | 00000000:02:00.0 Off | N/A | | 38% 69C P2 185W / 350W | 20472MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 2095246 C ...ma.cpp/build/bin/llama-server 22244MiB | | 1 N/A N/A 2095246 C ...ma.cpp/build/bin/llama-server 20460MiB | +-----------------------------------------------------------------------------------------+And, interestingly, the performance is not bad already. With ktransformers I was getting two times less in prefill, but about 25% better in decode (but with just one GPU). That's cool. I was under the wrong impression all this time that ik_llama.cpp can't deal with long context with old gpus (24GB VRAM) lol
53k prefill, 9k decode:
INFO [ print_timings] prompt eval time = 1760154.40 ms / 54458 tokens ( 32.32 ms per token, 30.94 tokens per second) | tid="139875703574528" timestamp=1752238479 id_slot=0 id_task=2842 t_prompt_processing=1760154.401 n_prompt_tokens_processed=54458 t_token=32.32131920011752 n_tokens_second=30.939331213818893 INFO [ print_timings] generation eval time = 2440353.29 ms / 8916 runs ( 273.70 ms per token, 3.65 tokens per second) | tid="139875703574528" timestamp=1752238479 id_slot=0 id_task=2842 t_token_generation=2440353.295 n_decoded=8916 t_token=273.7049456034096 n_tokens_second=3.6535693492691603 INFO [ print_timings] total time = 4200507.70 ms | tid="139875703574528" timestamp=1752238479 id_slot=0 id_task=2842 t_prompt_processing=1760154.401 t_token_generation=2440353.295 t_total=4200507.696I am downloading various quants to try out with various configs.
👤 magikRUKKOLA replied the 2025-07-11 at 15:21:56:
Tried the IQ2_K_R4 quant:#!/usr/bin/env bash #CUDA_VISIBLE_DEVICES="0" \ # --override-tensor exps=CPU,attn_kv_b=CPU \ CUDA_VISIBLE_DEVICES="0,1" \ /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server \ --model /opt/ubergarm/DeepSeek-R1-0528-GGUF/IQ2_K_R4/DeepSeek-R1-0528-IQ2_K_R4-00001-of-00005.gguf \ --alias ubergarm/DeepSeek-R1-0528-IQ2_K_R4-GGUF \ --ctx-size $((96 * 1024)) \ --temp 0.5 --top-k 0 --top-p 1.0 --min-p 0.1 --repeat-penalty 1.0 \ -ctk q8_0 \ -mla 3 -fa \ -amb 512 \ -b $((4 * 1024)) -ub $((4 * 1024)) \ -fmoe \ --n-gpu-layers 99 \ --override-tensor exps=CPU \ --threads $(grep ^cpu\\scores /proc/cpuinfo | uniq | awk '{print $4}' | xargs -I{} echo "{}-0" | bc) \ --host 0.0.0.0 \ --port 8080 \ --lookup-cache-dynamic /mnt/data/ik_llama.kv.dump \ -ot "blk\.(3|4|5)\.ffn_.*=CUDA1"nvidia-smi Fri Jul 11 15:03:12 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 575.51.02 Driver Version: 575.51.02 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3090 Off | 00000000:01:00.0 Off | N/A | | 71% 69C P2 184W / 350W | 19680MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA GeForce RTX 3090 Off | 00000000:02:00.0 Off | N/A | | 50% 73C P2 321W / 350W | 17222MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 2124121 C ...ma.cpp/build/bin/llama-server 19668MiB | | 1 N/A N/A 2124121 C ...ma.cpp/build/bin/llama-server 17210MiB | +-----------------------------------------------------------------------------------------+again, 53k prefill, 5k decode:
INFO [ print_timings] prompt eval time = 453747.84 ms / 54458 tokens ( 8.33 ms per token, 120.02 tokens per second) | tid="140498654953472" timestamp=1752247184 id_slot=0 id_task=167 t_prompt_processing=453747.84 n_prompt_tokens_processed=54458 t_token=8.332069484740535 n_tokens_second=120.0182021803123 INFO [ print_timings] generation eval time = 961266.93 ms / 5089 runs ( 188.89 ms per token, 5.29 tokens per second) | tid="140498654953472" timestamp=1752247184 id_slot=0 id_task=167 t_token_generation=961266.934 n_decoded=5089 t_token=188.89112477893497 n_tokens_second=5.294054980986166 INFO [ print_timings] total time = 1415014.77 ms | tid="140498654953472" timestamp=1752247184 id_slot=0 id_task=167 t_prompt_processing=453747.84 t_token_generation=961266.934 t_total=1415014.774Whoa! 120 tps prefill! Intriguing!
👤 magikRUKKOLA replied the 2025-07-11 at 16:19:40:
Uh oh! Apparently the -ot etc. doesn't really do much.96k context:
llama_kv_cache_init: CUDA0 KV buffer size = 2448.02 MiB llama_kv_cache_init: CUDA1 KV buffer size = 2218.51 MiB llama_new_context_with_model: KV self size = 4666.50 MiB, c^KV (q8_0): 4666.50 MiB, kv^T: not used ... llama_new_context_with_model: pipeline parallelism enabled (n_copies=1) llama_new_context_with_model: CUDA0 compute buffer size = 10632.02 MiB llama_new_context_with_model: CUDA1 compute buffer size = 9584.03 MiBSo the whole VRAM just goes to the KV-cache computation, right? So not a single layer can be put onto the GPU. But the KV-cache is distributed okay.
👤 ubergarm replied the 2025-07-11 at 16:24:23:
@magikRUKKOLAPossibly you may mean it like:
Yeah, sorry about my copy paste typo: you are correct I meant CUDA0 CUDA1 CUDA2...
Great job getting your rig in shape to give it a go with 2x 3090s (still the best bang for the buck imo haha).
Well, I am not sure I will be able to put anything onto the CUDA0 since its VRAM is almost taken with the KV-cache.
The KV-cache is split almost equally across both GPUs, so not sure what is going on here unless you didn't compile with
-DGGML_SCHED_MAX_COPIES=1which causes bloated VRAM usage.Let's workshop your command again for the
IQ2_K_R4and see what you can get. We'll usellama-sweep-benchas it provides a better full view of expected speeds for both PP (prefill) and TG across various kv-depths. I prefer it to looking at a single 1shot prompt output, though you did good to use a 50k prompt!Also I have some new non-
_R4quants like this ubergarm/DeepSeek-R1-0528-GGUF/IQ3_KS (and also the TNG-R1T2-Chimera version) using my latest recipes and the newest IQ3_KS type that might benefit more from-ub 4096 -b 4096than the_R4quants.Anyway, here we go:
compile
# compile for mixed CUDA+CPU inferencingof deepseek arch cmake -B ./build -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DGGML_BLAS=OFF -DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_IQK_FORCE_BF16=1 cmake --build ./build --config Release -j $(nproc)Keep in mind the order of
-otmatters so put the-ot exps=CPUlast after the-ot ...=CUDAXstuff so I'm not sure you were actually offloading more routed exps layers like intended in your command above. I'll use my convention of ngl then ot CUDAs then ot exps=CPU:benchmark
#!/usr/bin/env bash CUDA_VISIBLE_DEVICES="0,1" \ /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-sweep-bench \ --model /opt/ubergarm/DeepSeek-R1-0528-GGUF/IQ2_K_R4/DeepSeek-R1-0528-IQ2_K_R4-00001-of-00005.gguf \ --ctx-size 20480 \ -ctk q8_0 \ -fa -fmoe -mla 3 \ -amb 512 \ -ngl 99 \ -ot "blk\.(3|4)\.ffn_.*=CUDA0" \ -ot "blk\.(5|6)\.ffn_.*=CUDA1" \ -ot exps=CPU \ -ub 2048 -b 2048 \ --threads $(grep ^cpu\\scores /proc/cpuinfo | uniq | awk '{print $4}' | xargs -I{} echo "{}-0" | bc) \ --warmup-batchI tested llama-server and confirmed you can offload full 160k context onto 2x 24GB VRAM GPUs. However, without the 3rd GPU you can't increase
-ub 4096 -b 4096nor offload additional dense layers e.g.-ot "blk\.(5|6)\.ffn_.*=CUDA1"Notice it prints out usage showing KV cache buffer distributed almost evenly across both GPUs (though the main gpu does get just a little more):
#!/usr/bin/env bash CUDA_VISIBLE_DEVICES="0,1" \ /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server \ --model /opt/ubergarm/DeepSeek-R1-0528-GGUF/IQ2_K_R4/DeepSeek-R1-0528-IQ2_K_R4-00001-of-00005.gguf \ --alias ubergarm/DeepSeek-R1-0528-IQ2_K_R4-GGUF \ --ctx-size $((160 * 1024)) \ --temp 0.5 --top-k 0 --top-p 1.0 --min-p 0.1 --repeat-penalty 1.0 \ -ctk q8_0 \ -mla 3 -fa \ -amb 512 \ -fmoe \ --n-gpu-layers 99 \ --override-tensor exps=CPU \ --parallel 1 \ --threads $(grep ^cpu\\scores /proc/cpuinfo | uniq | awk '{print $4}' | xargs -I{} echo "{}-0" | bc) \ --host 0.0.0.0 \ --port 8080 \ --lookup-cache-dynamic /mnt/data/ik_llama.kv.dump . llama_kv_cache_init: CUDA0 KV buffer size = 3060.02 MiB llama_kv_cache_init: CUDA1 KV buffer size = 2773.14 MiB llama_new_context_with_model: KV self size = 5833.12 MiB, c^KV (q8_0): 5833.12 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB llama_new_context_with_model: pipeline parallelism enabled (n_copies=1) llama_new_context_with_model: CUDA0 compute buffer size = 13649.00 MiB llama_new_context_with_model: CUDA1 compute buffer size = 13515.50 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 334.01 MiB
nvitopshown for dual RTX A6000s but made sure they are not loaded past 24GB VRAM each.👤 ubergarm replied the 2025-07-11 at 16:26:32:
I was replying at the same time hahUh oh! Apparently the -ot etc. doesn't really do much.
The order matters, you were putting the final
-ottoo late and a previous regex already was in play.So the whole VRAM just goes to the KV-cache computation, right? So not a single layer can be put onto the GPU. But the KV-cache is distributed okay.
Not quite, it is still offloading all the attn/shexp/first 3 dense layers onto GPU. Since you want full 160k context on only 48GB VRAM you cannot offload any additional routed exps though.
👤 magikRUKKOLA replied the 2025-07-11 at 16:31:20:
The KV-cache is split almost equally across both GPUs, so not sure what is going on here unless you didn't compile with
-DGGML_SCHED_MAX_COPIES=1which causes bloated VRAM usage.Well, let me see...
#!/usr/bin/env bash cd ik_llama.cpp cmake -B build -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DGGML_CUDA_FA_ALL_QUANTS=1 -DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_IQK_FORCE_BF16=1 cmake --build ./build --config Release -j $(nproc)So it looks like the DGGML_SCHED_MAX_COPIES=1 is present. Not sure if I can check it ...
/opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server --version --verbose version: 3795 (c53cb652) built with cc (Debian 14.2.0-19) 14.2.0 for x86_64-linux-gnu👤 magikRUKKOLA replied the 2025-07-11 at 16:33:53:
Also I have some new non-
_R4quants like this ubergarm/DeepSeek-R1-0528-GGUF/IQ3_KS (and also the TNG-R1T2-Chimera version) using my latest recipes and the newest IQ3_KS type that might benefit more from-ub 4096 -b 4096than the_R4quants.Yeah, I know. I am downloading it.
Keep in mind the order of -ot matters so put the -ot exps=CPU last after the -ot ...=CUDAX stuff so I'm not sure you were actually offloading more routed exps layers like intended in your command above. I'll use my convention of ngl then ot CUDAs then ot exps=CPU:
Uh oh.. May bad. :)
👤 magikRUKKOLA replied the 2025-07-11 at 17:06:06:
benchmark
test-rig (12 core CPU) setup benchmark:
... llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CPU buffer size = 28331.35 MiB llm_load_tensors: CPU buffer size = 44228.69 MiB llm_load_tensors: CPU buffer size = 45768.69 MiB llm_load_tensors: CPU buffer size = 44704.69 MiB llm_load_tensors: CPU buffer size = 43745.14 MiB llm_load_tensors: CPU buffer size = 580.45 MiB llm_load_tensors: CUDA0 buffer size = 13023.84 MiB llm_load_tensors: CUDA1 buffer size = 12599.48 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 20480 llama_new_context_with_model: n_batch = 2048 llama_new_context_with_model: n_ubatch = 2048 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 382.52 MiB llama_kv_cache_init: CUDA1 KV buffer size = 346.65 MiB llama_new_context_with_model: KV self size = 729.14 MiB, c^KV (q8_0): 729.14 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: pipeline parallelism enabled (n_copies=1) llama_new_context_with_model: CUDA0 compute buffer size = 2552.01 MiB llama_new_context_with_model: CUDA1 compute buffer size = 2456.02 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 216.02 MiB llama_new_context_with_model: graph nodes = 8245 llama_new_context_with_model: graph splits = 148 main: n_kv_max = 20480, n_batch = 2048, n_ubatch = 2048, flash_attn = 1, n_gpu_layers = 99, n_threads = 12, n_threads_batch = 12 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 2048 | 512 | 0 | 14.651 | 139.79 | 63.572 | 8.05 | | 2048 | 512 | 2048 | 15.004 | 136.50 | 64.516 | 7.94 | | 2048 | 512 | 4096 | 15.405 | 132.94 | 65.437 | 7.82 | | 2048 | 512 | 6144 | 15.777 | 129.81 | 66.337 | 7.72 | | 2048 | 512 | 8192 | 16.183 | 126.56 | 67.494 | 7.59 | | 2048 | 512 | 10240 | 16.566 | 123.63 | 68.447 | 7.48 | | 2048 | 512 | 12288 | 17.026 | 120.29 | 68.812 | 7.44 | | 2048 | 512 | 14336 | 17.377 | 117.86 | 70.177 | 7.30 | | 2048 | 512 | 16384 | 17.864 | 114.64 | 71.332 | 7.18 | | 2048 | 512 | 18432 | 18.530 | 110.52 | 72.430 | 7.07 |full 160k context benchmariking (n_ubatch = 2048 would OOM with two GPUs):
main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 512, flash_attn = 1, n_gpu_layers = 99, n_threads = 12, n_threads_batch = 12 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 512 | 128 | 0 | 17.472 | 29.30 | 16.515 | 7.75 | | 512 | 128 | 512 | 17.267 | 29.65 | 16.704 | 7.66 | | 512 | 128 | 1024 | 17.572 | 29.14 | 16.750 | 7.64 | | 512 | 128 | 1536 | 17.799 | 28.77 | 16.620 | 7.70 | | 512 | 128 | 2048 | 18.560 | 27.59 | 16.691 | 7.67 | | 512 | 128 | 2560 | 19.379 | 26.42 | 16.838 | 7.60 | | 512 | 128 | 3072 | 18.259 | 28.04 | 17.097 | 7.49 | | 512 | 128 | 3584 | 18.151 | 28.21 | 17.040 | 7.51 | | 512 | 128 | 4096 | 18.542 | 27.61 | 17.002 | 7.53 | | 512 | 128 | 4608 | 18.624 | 27.49 | 16.974 | 7.54 | | 512 | 128 | 5120 | 18.059 | 28.35 | 17.207 | 7.44 | | 512 | 128 | 5632 | 18.478 | 27.71 | 17.154 | 7.46 | | 512 | 128 | 6144 | 18.702 | 27.38 | 17.253 | 7.42 | | 512 | 128 | 6656 | 19.287 | 26.55 | 17.318 | 7.39 | | 512 | 128 | 7168 | 18.875 | 27.13 | 17.291 | 7.40 | | 512 | 128 | 7680 | 18.351 | 27.90 | 17.423 | 7.35 | | 512 | 128 | 8192 | 18.892 | 27.10 | 17.549 | 7.29 | | 512 | 128 | 8704 | 19.834 | 25.81 | 17.573 | 7.28 | | 512 | 128 | 9216 | 19.126 | 26.77 | 17.623 | 7.26 | | 512 | 128 | 9728 | 19.085 | 26.83 | 17.729 | 7.22 | | 512 | 128 | 10240 | 19.435 | 26.34 | 17.785 | 7.20 | | 512 | 128 | 10752 | 19.572 | 26.16 | 17.842 | 7.17 | | 512 | 128 | 11264 | 20.064 | 25.52 | 17.951 | 7.13 | | 512 | 128 | 11776 | 20.130 | 25.43 | 17.959 | 7.13 | | 512 | 128 | 12288 | 19.609 | 26.11 | 17.881 | 7.16 | | 512 | 128 | 12800 | 20.042 | 25.55 | 17.964 | 7.13 | | 512 | 128 | 13312 | 21.219 | 24.13 | 18.234 | 7.02 | | 512 | 128 | 13824 | 20.415 | 25.08 | 18.192 | 7.04 | | 512 | 128 | 14336 | 19.826 | 25.82 | 18.255 | 7.01 | | 512 | 128 | 14848 | 20.029 | 25.56 | 18.294 | 7.00 | | 512 | 128 | 15360 | 20.848 | 24.56 | 18.286 | 7.00 | | 512 | 128 | 15872 | 20.456 | 25.03 | 18.591 | 6.89 | | 512 | 128 | 16384 | 20.403 | 25.09 | 18.602 | 6.88 | | 512 | 128 | 16896 | 21.461 | 23.86 | 18.568 | 6.89 | | 512 | 128 | 17408 | 20.234 | 25.30 | 18.577 | 6.89 | | 512 | 128 | 17920 | 20.737 | 24.69 | 18.606 | 6.88 | | 512 | 128 | 18432 | 21.229 | 24.12 | 18.889 | 6.78 | | 512 | 128 | 18944 | 21.383 | 23.94 | 18.758 | 6.82 | | 512 | 128 | 19456 | 21.426 | 23.90 | 18.970 | 6.75 | | 512 | 128 | 19968 | 21.790 | 23.50 | 18.813 | 6.80 | | 512 | 128 | 20480 | 21.667 | 23.63 | 18.861 | 6.79 | | 512 | 128 | 20992 | 21.045 | 24.33 | 19.140 | 6.69 | | 512 | 128 | 21504 | 21.635 | 23.67 | 19.153 | 6.68 | | 512 | 128 | 22016 | 21.605 | 23.70 | 19.182 | 6.67 | | 512 | 128 | 22528 | 22.088 | 23.18 | 19.136 | 6.69 | | 512 | 128 | 23040 | 23.202 | 22.07 | 19.185 | 6.67 | | 512 | 128 | 23552 | 22.371 | 22.89 | 19.396 | 6.60 | | 512 | 128 | 24064 | 22.362 | 22.90 | 19.370 | 6.61 | | 512 | 128 | 24576 | 22.327 | 22.93 | 19.582 | 6.54 | | 512 | 128 | 25088 | 21.469 | 23.85 | 19.541 | 6.55 | | 512 | 128 | 25600 | 23.207 | 22.06 | 19.537 | 6.55 | | 512 | 128 | 26112 | 22.506 | 22.75 | 19.831 | 6.45 | | 512 | 128 | 26624 | 22.454 | 22.80 | 19.754 | 6.48 | | 512 | 128 | 27136 | 21.959 | 23.32 | 19.719 | 6.49 | | 512 | 128 | 27648 | 22.406 | 22.85 | 19.747 | 6.48 | | 512 | 128 | 28160 | 23.292 | 21.98 | 19.824 | 6.46 | | 512 | 128 | 28672 | 23.243 | 22.03 | 19.890 | 6.44 | | 512 | 128 | 29184 | 22.465 | 22.79 | 20.025 | 6.39 | | 512 | 128 | 29696 | 23.009 | 22.25 | 20.055 | 6.38 | | 512 | 128 | 30208 | 22.775 | 22.48 | 20.137 | 6.36 | | 512 | 128 | 30720 | 22.873 | 22.38 | 20.062 | 6.38 | | 512 | 128 | 31232 | 23.173 | 22.09 | 20.157 | 6.35 | | 512 | 128 | 31744 | 23.412 | 21.87 | 20.381 | 6.28 | | 512 | 128 | 32256 | 23.396 | 21.88 | 20.445 | 6.26 | | 512 | 128 | 32768 | 23.725 | 21.58 | 20.405 | 6.27 | | 512 | 128 | 33280 | 23.229 | 22.04 | 20.396 | 6.28 | | 512 | 128 | 33792 | 24.151 | 21.20 | 20.486 | 6.25 | | 512 | 128 | 34304 | 23.372 | 21.91 | 20.603 | 6.21 | | 512 | 128 | 34816 | 23.995 | 21.34 | 20.754 | 6.17 | | 512 | 128 | 35328 | 24.350 | 21.03 | 20.715 | 6.18 | | 512 | 128 | 35840 | 24.258 | 21.11 | 20.698 | 6.18 | | 512 | 128 | 36352 | 24.019 | 21.32 | 20.696 | 6.18 | | 512 | 128 | 36864 | 24.370 | 21.01 | 20.923 | 6.12 | | 512 | 128 | 37376 | 24.755 | 20.68 | 20.899 | 6.12 | | 512 | 128 | 37888 | 24.977 | 20.50 | 20.892 | 6.13 | | 512 | 128 | 38400 | 24.635 | 20.78 | 21.070 | 6.07 | | 512 | 128 | 38912 | 24.351 | 21.03 | 20.980 | 6.10 | | 512 | 128 | 39424 | 23.790 | 21.52 | 21.193 | 6.04 | | 512 | 128 | 39936 | 24.513 | 20.89 | 21.234 | 6.03 | | 512 | 128 | 40448 | 24.956 | 20.52 | 21.321 | 6.00 | | 512 | 128 | 40960 | 24.242 | 21.12 | 21.294 | 6.01 | | 512 | 128 | 41472 | 25.322 | 20.22 | 21.289 | 6.01 | | 512 | 128 | 41984 | 24.602 | 20.81 | 21.507 | 5.95 | | 512 | 128 | 42496 | 24.615 | 20.80 | 21.570 | 5.93 | | 512 | 128 | 43008 | 24.668 | 20.76 | 21.474 | 5.96 | | 512 | 128 | 43520 | 24.846 | 20.61 | 21.560 | 5.94 | | 512 | 128 | 44032 | 25.545 | 20.04 | 21.654 | 5.91 | | 512 | 128 | 44544 | 25.043 | 20.44 | 21.812 | 5.87 | | 512 | 128 | 45056 | 26.800 | 19.10 | 21.857 | 5.86 | | 512 | 128 | 45568 | 26.709 | 19.17 | 21.863 | 5.85 | | 512 | 128 | 46080 | 28.429 | 18.01 | 24.090 | 5.31 | | 512 | 128 | 46592 | 30.055 | 17.04 | 24.886 | 5.14 | | 512 | 128 | 47104 | 25.631 | 19.98 | 21.861 | 5.86 | | 512 | 128 | 47616 | 25.295 | 20.24 | 21.923 | 5.84 | | 512 | 128 | 48128 | 25.475 | 20.10 | 21.967 | 5.83 | | 512 | 128 | 48640 | 26.043 | 19.66 | 21.954 | 5.83 | | 512 | 128 | 49152 | 25.561 | 20.03 | 21.945 | 5.83 | | 512 | 128 | 49664 | 25.886 | 19.78 | 22.228 | 5.76 | | 512 | 128 | 50176 | 25.947 | 19.73 | 22.264 | 5.75 | | 512 | 128 | 50688 | 26.746 | 19.14 | 22.185 | 5.77 | | 512 | 128 | 51200 | 25.750 | 19.88 | 22.248 | 5.75 | | 512 | 128 | 51712 | 26.636 | 19.22 | 22.276 | 5.75 | | 512 | 128 | 52224 | 26.040 | 19.66 | 22.582 | 5.67 | | 512 | 128 | 52736 | 25.971 | 19.71 | 22.573 | 5.67 | | 512 | 128 | 53248 | 26.117 | 19.60 | 22.518 | 5.68 | | 512 | 128 | 53760 | 26.287 | 19.48 | 22.588 | 5.67 | | 512 | 128 | 54272 | 26.309 | 19.46 | 22.562 | 5.67 | | 512 | 128 | 54784 | 26.575 | 19.27 | 22.635 | 5.65 | | 512 | 128 | 55296 | 27.304 | 18.75 | 22.819 | 5.61 | | 512 | 128 | 55808 | 26.922 | 19.02 | 22.857 | 5.60 | | 512 | 128 | 56320 | 27.201 | 18.82 | 22.877 | 5.60 | | 512 | 128 | 56832 | 26.951 | 19.00 | 22.906 | 5.59 | | 512 | 128 | 57344 | 26.970 | 18.98 | 22.906 | 5.59 | | 512 | 128 | 57856 | 27.578 | 18.57 | 23.122 | 5.54 | | 512 | 128 | 58368 | 27.568 | 18.57 | 23.139 | 5.53 | | 512 | 128 | 58880 | 27.328 | 18.74 | 23.196 | 5.52 | | 512 | 128 | 59392 | 27.581 | 18.56 | 23.180 | 5.52 | | 512 | 128 | 59904 | 27.861 | 18.38 | 23.217 | 5.51 | | 512 | 128 | 60416 | 27.844 | 18.39 | 23.428 | 5.46 | | 512 | 128 | 60928 | 27.975 | 18.30 | 23.440 | 5.46 | | 512 | 128 | 61440 | 27.999 | 18.29 | 23.516 | 5.44 | | 512 | 128 | 61952 | 28.307 | 18.09 | 23.507 | 5.45 | | 512 | 128 | 62464 | 27.803 | 18.42 | 23.532 | 5.44 | | 512 | 128 | 62976 | 27.973 | 18.30 | 23.740 | 5.39 | | 512 | 128 | 63488 | 28.003 | 18.28 | 23.743 | 5.39 | | 512 | 128 | 64000 | 29.202 | 17.53 | 23.760 | 5.39 | | 512 | 128 | 64512 | 28.273 | 18.11 | 23.896 | 5.36 | | 512 | 128 | 65024 | 29.046 | 17.63 | 23.861 | 5.36 | | 512 | 128 | 65536 | 29.029 | 17.64 | 24.051 | 5.32 | | 512 | 128 | 66048 | 28.906 | 17.71 | 24.040 | 5.32 | | 512 | 128 | 66560 | 29.617 | 17.29 | 24.079 | 5.32 | | 512 | 128 | 67072 | 30.107 | 17.01 | 24.075 | 5.32 | | 512 | 128 | 67584 | 29.184 | 17.54 | 24.126 | 5.31 | | 512 | 128 | 68096 | 30.140 | 16.99 | 24.344 | 5.26 | | 512 | 128 | 68608 | 30.181 | 16.96 | 24.327 | 5.26 | | 512 | 128 | 69120 | 30.301 | 16.90 | 24.357 | 5.26 | | 512 | 128 | 69632 | 30.393 | 16.85 | 24.448 | 5.24 | | 512 | 128 | 70144 | 29.443 | 17.39 | 24.416 | 5.24 | | 512 | 128 | 70656 | 29.791 | 17.19 | 24.580 | 5.21 | | 512 | 128 | 71168 | 30.668 | 16.70 | 24.667 | 5.19 | | 512 | 128 | 71680 | 30.656 | 16.70 | 24.715 | 5.18 | | 512 | 128 | 72192 | 30.238 | 16.93 | 24.700 | 5.18 | | 512 | 128 | 72704 | 30.157 | 16.98 | 24.713 | 5.18 | | 512 | 128 | 73216 | 30.428 | 16.83 | 24.767 | 5.17 | | 512 | 128 | 73728 | 31.239 | 16.39 | 25.001 | 5.12 | | 512 | 128 | 74240 | 30.339 | 16.88 | 24.958 | 5.13 | | 512 | 128 | 74752 | 30.364 | 16.86 | 25.014 | 5.12 | | 512 | 128 | 75264 | 30.406 | 16.84 | 25.037 | 5.11 | | 512 | 128 | 75776 | 30.569 | 16.75 | 25.057 | 5.11 | | 512 | 128 | 76288 | 32.370 | 15.82 | 25.233 | 5.07 | | 512 | 128 | 76800 | 31.332 | 16.34 | 25.296 | 5.06 | | 512 | 128 | 77312 | 30.762 | 16.64 | 25.480 | 5.02 | | 512 | 128 | 77824 | 31.014 | 16.51 | 25.349 | 5.05 | | 512 | 128 | 78336 | 31.310 | 16.35 | 25.386 | 5.04 | | 512 | 128 | 78848 | 31.054 | 16.49 | 25.607 | 5.00 | | 512 | 128 | 79360 | 32.403 | 15.80 | 25.681 | 4.98 | | 512 | 128 | 79872 | 31.562 | 16.22 | 25.706 | 4.98 | | 512 | 128 | 80384 | 31.596 | 16.20 | 25.661 | 4.99 | | 512 | 128 | 80896 | 31.515 | 16.25 | 25.667 | 4.99 | | 512 | 128 | 81408 | 31.740 | 16.13 | 25.914 | 4.94 | | 512 | 128 | 81920 | 32.172 | 15.91 | 25.919 | 4.94 | | 512 | 128 | 82432 | 32.865 | 15.58 | 25.976 | 4.93 | | 512 | 128 | 82944 | 32.047 | 15.98 | 25.967 | 4.93 | | 512 | 128 | 83456 | 32.330 | 15.84 | 25.995 | 4.92 | | 512 | 128 | 83968 | 32.994 | 15.52 | 26.204 | 4.88 | | 512 | 128 | 84480 | 32.322 | 15.84 | 26.230 | 4.88 | | 512 | 128 | 84992 | 32.212 | 15.89 | 26.227 | 4.88 | | 512 | 128 | 85504 | 34.280 | 14.94 | 26.283 | 4.87 | | 512 | 128 | 86016 | 32.352 | 15.83 | 26.285 | 4.87 | | 512 | 128 | 86528 | 32.939 | 15.54 | 26.545 | 4.82 | | 512 | 128 | 87040 | 34.451 | 14.86 | 26.525 | 4.83 | | 512 | 128 | 87552 | 33.039 | 15.50 | 26.567 | 4.82 | | 512 | 128 | 88064 | 33.203 | 15.42 | 26.586 | 4.81 | | 512 | 128 | 88576 | 33.866 | 15.12 | 26.660 | 4.80 | | 512 | 128 | 89088 | 33.002 | 15.51 | 26.790 | 4.78 | | 512 | 128 | 89600 | 33.354 | 15.35 | 26.810 | 4.77 | | 512 | 128 | 90112 | 33.401 | 15.33 | 26.901 | 4.76 | | 512 | 128 | 90624 | 33.967 | 15.07 | 27.018 | 4.74 | | 512 | 128 | 91136 | 33.725 | 15.18 | 26.940 | 4.75 | | 512 | 128 | 91648 | 34.573 | 14.81 | 26.992 | 4.74 | | 512 | 128 | 92160 | 33.802 | 15.15 | 27.107 | 4.72 | | 512 | 128 | 92672 | 33.775 | 15.16 | 27.183 | 4.71 | | 512 | 128 | 93184 | 35.030 | 14.62 | 27.162 | 4.71 | | 512 | 128 | 93696 | 34.058 | 15.03 | 27.196 | 4.71 | | 512 | 128 | 94208 | 34.821 | 14.70 | 27.167 | 4.71 | | 512 | 128 | 94720 | 34.729 | 14.74 | 27.463 | 4.66 | | 512 | 128 | 95232 | 35.091 | 14.59 | 27.478 | 4.66 | | 512 | 128 | 95744 | 34.685 | 14.76 | 27.531 | 4.65 | | 512 | 128 | 96256 | 34.733 | 14.74 | 27.470 | 4.66 | | 512 | 128 | 96768 | 35.150 | 14.57 | 27.539 | 4.65 | | 512 | 128 | 97280 | 35.110 | 14.58 | 27.783 | 4.61 | | 512 | 128 | 97792 | 34.677 | 14.76 | 27.784 | 4.61 | | 512 | 128 | 98304 | 34.856 | 14.69 | 27.760 | 4.61 | | 512 | 128 | 98816 | 34.997 | 14.63 | 27.780 | 4.61 | | 512 | 128 | 99328 | 34.918 | 14.66 | 27.824 | 4.60 | | 512 | 128 | 99840 | 35.286 | 14.51 | 28.058 | 4.56 | | 512 | 128 | 100352 | 35.331 | 14.49 | 28.093 | 4.56 | | 512 | 128 | 100864 | 35.583 | 14.39 | 28.239 | 4.53 | | 512 | 128 | 101376 | 35.967 | 14.24 | 28.275 | 4.53 | | 512 | 128 | 101888 | 36.048 | 14.20 | 28.481 | 4.49 | | 512 | 128 | 102400 | 36.263 | 14.12 | 28.319 | 4.52 | | 512 | 128 | 102912 | 35.850 | 14.28 | 28.641 | 4.47 | | 512 | 128 | 103424 | 35.833 | 14.29 | 28.761 | 4.45 | | 512 | 128 | 103936 | 36.091 | 14.19 | 28.443 | 4.50 | | 512 | 128 | 104448 | 35.922 | 14.25 | 28.445 | 4.50 | | 512 | 128 | 104960 | 36.532 | 14.02 | 28.645 | 4.47 | | 512 | 128 | 105472 | 36.909 | 13.87 | 28.713 | 4.46 | | 512 | 128 | 105984 | 36.463 | 14.04 | 28.655 | 4.47 | | 512 | 128 | 106496 | 36.328 | 14.09 | 28.773 | 4.45 | | 512 | 128 | 107008 | 36.538 | 14.01 | 28.802 | 4.44 | | 512 | 128 | 107520 | 36.887 | 13.88 | 28.907 | 4.43 | | 512 | 128 | 108032 | 36.939 | 13.86 | 29.109 | 4.40 | | 512 | 128 | 108544 | 36.829 | 13.90 | 29.143 | 4.39 | | 512 | 128 | 109056 | 37.279 | 13.73 | 29.173 | 4.39 | | 512 | 128 | 109568 | 36.797 | 13.91 | 29.035 | 4.41 | | 512 | 128 | 110080 | 36.917 | 13.87 | 29.245 | 4.38 | | 512 | 128 | 110592 | 37.756 | 13.56 | 29.311 | 4.37 | | 512 | 128 | 111104 | 37.160 | 13.78 | 29.415 | 4.35 | | 512 | 128 | 111616 | 37.150 | 13.78 | 29.397 | 4.35 | | 512 | 128 | 112128 | 37.542 | 13.64 | 29.396 | 4.35 | | 512 | 128 | 112640 | 38.233 | 13.39 | 29.511 | 4.34 | | 512 | 128 | 113152 | 37.700 | 13.58 | 29.591 | 4.33 | | 512 | 128 | 113664 | 37.565 | 13.63 | 29.599 | 4.32 | | 512 | 128 | 114176 | 38.247 | 13.39 | 29.647 | 4.32 | | 512 | 128 | 114688 | 37.796 | 13.55 | 29.707 | 4.31 | | 512 | 128 | 115200 | 38.230 | 13.39 | 29.684 | 4.31 | | 512 | 128 | 115712 | 38.026 | 13.46 | 29.959 | 4.27 | | 512 | 128 | 116224 | 38.500 | 13.30 | 29.904 | 4.28 | | 512 | 128 | 116736 | 38.124 | 13.43 | 29.977 | 4.27 | | 512 | 128 | 117248 | 38.468 | 13.31 | 30.007 | 4.27 | | 512 | 128 | 117760 | 38.359 | 13.35 | 29.984 | 4.27 | | 512 | 128 | 118272 | 39.026 | 13.12 | 30.190 | 4.24 | | 512 | 128 | 118784 | 38.430 | 13.32 | 30.201 | 4.24 | | 512 | 128 | 119296 | 38.838 | 13.18 | 30.335 | 4.22 | | 512 | 128 | 119808 | 39.675 | 12.90 | 30.290 | 4.23 | | 512 | 128 | 120320 | 38.879 | 13.17 | 30.332 | 4.22 | | 512 | 128 | 120832 | 40.290 | 12.71 | 30.529 | 4.19 | | 512 | 128 | 121344 | 39.566 | 12.94 | 30.519 | 4.19 | | 512 | 128 | 121856 | 39.134 | 13.08 | 30.579 | 4.19 | | 512 | 128 | 122368 | 39.376 | 13.00 | 30.594 | 4.18 | | 512 | 128 | 122880 | 39.525 | 12.95 | 30.572 | 4.19 | | 512 | 128 | 123392 | 40.089 | 12.77 | 30.781 | 4.16 | | 512 | 128 | 123904 | 40.548 | 12.63 | 30.819 | 4.15 | | 512 | 128 | 124416 | 40.275 | 12.71 | 31.094 | 4.12 | | 512 | 128 | 124928 | 39.708 | 12.89 | 30.929 | 4.14 | | 512 | 128 | 125440 | 41.369 | 12.38 | 30.895 | 4.14 | | 512 | 128 | 125952 | 40.456 | 12.66 | 31.138 | 4.11 | | 512 | 128 | 126464 | 40.763 | 12.56 | 31.098 | 4.12 | | 512 | 128 | 126976 | 40.437 | 12.66 | 31.253 | 4.10 | | 512 | 128 | 127488 | 40.542 | 12.63 | 31.242 | 4.10 | | 512 | 128 | 128000 | 40.171 | 12.75 | 31.255 | 4.10 | | 512 | 128 | 128512 | 41.136 | 12.45 | 31.351 | 4.08 | | 512 | 128 | 129024 | 41.602 | 12.31 | 31.443 | 4.07 | | 512 | 128 | 129536 | 40.801 | 12.55 | 31.437 | 4.07 | | 512 | 128 | 130048 | 40.960 | 12.50 | 31.490 | 4.06 | | 512 | 128 | 130560 | 41.054 | 12.47 | 31.511 | 4.06 | | 512 | 128 | 131072 | 42.154 | 12.15 | 31.655 | 4.04 | | 512 | 128 | 131584 | 41.993 | 12.19 | 31.683 | 4.04 | | 512 | 128 | 132096 | 42.359 | 12.09 | 31.695 | 4.04 | | 512 | 128 | 132608 | 42.544 | 12.03 | 31.728 | 4.03 | | 512 | 128 | 133120 | 42.724 | 11.98 | 31.780 | 4.03 | | 512 | 128 | 133632 | 42.867 | 11.94 | 31.831 | 4.02 | | 512 | 128 | 134144 | 42.708 | 11.99 | 31.991 | 4.00 | | 512 | 128 | 134656 | 42.568 | 12.03 | 31.860 | 4.02 | | 512 | 128 | 135168 | 42.896 | 11.94 | 31.887 | 4.01 | | 512 | 128 | 135680 | 43.065 | 11.89 | 31.878 | 4.02 | | 512 | 128 | 136192 | 43.748 | 11.70 | 32.276 | 3.97 | | 512 | 128 | 136704 | 42.989 | 11.91 | 32.183 | 3.98 | | 512 | 128 | 137216 | 44.261 | 11.57 | 32.025 | 4.00 | | 512 | 128 | 137728 | 43.268 | 11.83 | 32.023 | 4.00 | | 512 | 128 | 138240 | 43.885 | 11.67 | 32.019 | 4.00 | | 512 | 128 | 138752 | 43.499 | 11.77 | 32.065 | 3.99 | | 512 | 128 | 139264 | 44.430 | 11.52 | 32.185 | 3.98 | | 512 | 128 | 139776 | 44.435 | 11.52 | 32.184 | 3.98 | | 512 | 128 | 140288 | 44.593 | 11.48 | 32.306 | 3.96 | | 512 | 128 | 140800 | 43.719 | 11.71 | 32.365 | 3.95 | | 512 | 128 | 141312 | 44.376 | 11.54 | 32.246 | 3.97 | | 512 | 128 | 141824 | 44.826 | 11.42 | 32.322 | 3.96 | | 512 | 128 | 142336 | 44.378 | 11.54 | 32.553 | 3.93 | | 512 | 128 | 142848 | 44.235 | 11.57 | 32.379 | 3.95 | | 512 | 128 | 143360 | 44.434 | 11.52 | 32.361 | 3.96 | | 512 | 128 | 143872 | 44.813 | 11.43 | 32.376 | 3.95 | | 512 | 128 | 144384 | 44.579 | 11.49 | 32.566 | 3.93 | | 512 | 128 | 144896 | 44.859 | 11.41 | 32.551 | 3.93 | | 512 | 128 | 145408 | 45.202 | 11.33 | 32.630 | 3.92 | | 512 | 128 | 145920 | 45.502 | 11.25 | 32.563 | 3.93 | | 512 | 128 | 146432 | 45.579 | 11.23 | 32.682 | 3.92 | | 512 | 128 | 146944 | 45.011 | 11.38 | 32.655 | 3.92 | | 512 | 128 | 147456 | 45.547 | 11.24 | 32.796 | 3.90 | | 512 | 128 | 147968 | 46.100 | 11.11 | 32.738 | 3.91 | | 512 | 128 | 148480 | 45.545 | 11.24 | 32.775 | 3.91 | | 512 | 128 | 148992 | 45.517 | 11.25 | 32.947 | 3.89 | | 512 | 128 | 149504 | 45.413 | 11.27 | 32.877 | 3.89 | | 512 | 128 | 150016 | 46.299 | 11.06 | 32.963 | 3.88 | | 512 | 128 | 150528 | 45.696 | 11.20 | 33.039 | 3.87 | | 512 | 128 | 151040 | 46.669 | 10.97 | 33.082 | 3.87 | | 512 | 128 | 151552 | 46.031 | 11.12 | 33.097 | 3.87 | | 512 | 128 | 152064 | 46.368 | 11.04 | 33.253 | 3.85 | | 512 | 128 | 152576 | 46.274 | 11.06 | 33.209 | 3.85 | | 512 | 128 | 153088 | 46.397 | 11.04 | 33.267 | 3.85 | | 512 | 128 | 153600 | 46.635 | 10.98 | 33.283 | 3.85 | | 512 | 128 | 154112 | 46.994 | 10.90 | 33.280 | 3.85 | | 512 | 128 | 154624 | 48.391 | 10.58 | 33.458 | 3.83 | | 512 | 128 | 155136 | 47.461 | 10.79 | 33.562 | 3.81 | | 512 | 128 | 155648 | 46.955 | 10.90 | 33.436 | 3.83 | | 512 | 128 | 156160 | 47.331 | 10.82 | 33.426 | 3.83 | | 512 | 128 | 156672 | 46.917 | 10.91 | 33.474 | 3.82 | | 512 | 128 | 157184 | 47.340 | 10.82 | 33.525 | 3.82 | | 512 | 128 | 157696 | 47.340 | 10.82 | 33.590 | 3.81 | | 512 | 128 | 158208 | 47.334 | 10.82 | 33.633 | 3.81 | | 512 | 128 | 158720 | 47.349 | 10.81 | 33.670 | 3.80 | | 512 | 128 | 159232 | 47.514 | 10.78 | 33.660 | 3.80 | | 512 | 128 | 159744 | 48.311 | 10.60 | 33.724 | 3.80 | | 512 | 128 | 160256 | 48.225 | 10.62 | 33.767 | 3.79 | | 512 | 128 | 160768 | 47.868 | 10.70 | 33.874 | 3.78 | | 512 | 128 | 161280 | 47.926 | 10.68 | 33.785 | 3.79 | | 512 | 128 | 161792 | 48.188 | 10.63 | 33.823 | 3.78 | | 512 | 128 | 162304 | 48.468 | 10.56 | 33.840 | 3.78 | | 512 | 128 | 162816 | 48.757 | 10.50 | 33.936 | 3.77 | | 512 | 128 | 163328 | 48.810 | 10.49 | 34.005 | 3.76 |With 1024 n_ubatch the prefill doubles, decode slightly improves and it doesnt seem to OOM:
llama_new_context_with_model: KV self size = 5833.12 MiB, c^KV (q8_0): 5833.12 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB llama_new_context_with_model: pipeline parallelism enabled (n_copies=1) llama_new_context_with_model: CUDA0 compute buffer size = 14258.00 MiB llama_new_context_with_model: CUDA1 compute buffer size = 13748.01 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 668.01 MiB llama_new_context_with_model: graph nodes = 45821 llama_new_context_with_model: graph splits = 148 main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 1024, flash_attn = 1, n_gpu_layers = 99, n_threads = 12, n_threads_batch = 12 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 1024 | 256 | 0 | 13.922 | 73.55 | 32.533 | 7.87 | | 1024 | 256 | 1024 | 14.102 | 72.61 | 32.658 | 7.84 | | 1024 | 256 | 2048 | 14.165 | 72.29 | 32.765 | 7.81 | | 1024 | 256 | 3072 | 14.304 | 71.59 | 33.276 | 7.69 | | 1024 | 256 | 4096 | 14.403 | 71.10 | 33.382 | 7.67 | | 1024 | 256 | 5120 | 14.534 | 70.46 | 33.909 | 7.55 | | 1024 | 256 | 6144 | 14.640 | 69.95 | 34.024 | 7.52 | | 1024 | 256 | 7168 | 14.797 | 69.20 | 34.110 | 7.51 | | 1024 | 256 | 8192 | 14.925 | 68.61 | 34.554 | 7.41 | | 1024 | 256 | 9216 | 15.042 | 68.08 | 34.607 | 7.40 | | 1024 | 256 | 10240 | 15.183 | 67.45 | 34.759 | 7.36 | | 1024 | 256 | 11264 | 15.290 | 66.97 | 35.253 | 7.26 |Here is the test for the same setup with 12C CPU, 3200 MT/sec RAM and two GPUs with IQ3_KS:
main: n_kv_max = 163840, n_batch = 2048, n_ubatch = 1024, flash_attn = 1, n_gpu_layers = 99, n_threads = 12, n_threads_batch = 12 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 1024 | 256 | 0 | 17.903 | 57.20 | 40.040 | 6.39 | | 1024 | 256 | 1024 | 18.000 | 56.89 | 40.233 | 6.36 | | 1024 | 256 | 2048 | 18.102 | 56.57 | 40.237 | 6.36 | | 1024 | 256 | 3072 | 18.238 | 56.15 | 40.943 | 6.25 | | 1024 | 256 | 4096 | 18.384 | 55.70 | 40.959 | 6.25 | | 1024 | 256 | 5120 | 18.497 | 55.36 | 41.472 | 6.17 | | 1024 | 256 | 6144 | 18.577 | 55.12 | 41.597 | 6.15 | | 1024 | 256 | 7168 | 18.726 | 54.68 | 41.665 | 6.14 | | 1024 | 256 | 8192 | 18.900 | 54.18 | 42.114 | 6.08 | | 1024 | 256 | 9216 | 19.015 | 53.85 | 42.239 | 6.06 | | 1024 | 256 | 10240 | 19.143 | 53.49 | 42.333 | 6.05 | | 1024 | 256 | 11264 | 19.253 | 53.19 | 42.744 | 5.99 | | 1024 | 256 | 12288 | 19.434 | 52.69 | 42.829 | 5.98 | | 1024 | 256 | 13312 | 19.502 | 52.51 | 43.328 | 5.91 | | 1024 | 256 | 14336 | 19.662 | 52.08 | 43.325 | 5.91 | | 1024 | 256 | 15360 | 19.752 | 51.84 | 43.502 | 5.88 | | 1024 | 256 | 16384 | 19.993 | 51.22 | 44.008 | 5.82 |12C CPU, 3200 MT/sec RAM and two GPUs with DQ4_K_R4:
main: n_kv_max = 131072, n_batch = 2048, n_ubatch = 1024, flash_attn = 1, n_gpu_layers = 99, n_threads = 12, n_threads_batch = 12 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 1024 | 256 | 0 | 31.194 | 32.83 | 56.149 | 4.56 | | 1024 | 256 | 1024 | 32.316 | 31.69 | 54.468 | 4.70 | | 1024 | 256 | 2048 | 31.388 | 32.62 | 54.157 | 4.73 | | 1024 | 256 | 3072 | 31.680 | 32.32 | 54.828 | 4.67 | | 1024 | 256 | 4096 | 31.400 | 32.61 | 54.894 | 4.66 | | 1024 | 256 | 5120 | 31.722 | 32.28 | 55.239 | 4.63 | | 1024 | 256 | 6144 | 35.045 | 29.22 | 56.205 | 4.55 | | 1024 | 256 | 7168 | 32.723 | 31.29 | 55.511 | 4.61 | | 1024 | 256 | 8192 | 33.342 | 30.71 | 55.944 | 4.58 | | 1024 | 256 | 9216 | 33.622 | 30.46 | 56.269 | 4.55 | | 1024 | 256 | 10240 | 32.821 | 31.20 | 56.942 | 4.50 | | 1024 | 256 | 11264 | 32.100 | 31.90 | 55.735 | 4.59 | | 1024 | 256 | 12288 | 31.582 | 32.42 | 55.820 | 4.59 | | 1024 | 256 | 13312 | 32.822 | 31.20 | 56.248 | 4.55 | | 1024 | 256 | 14336 | 33.532 | 30.54 | 56.419 | 4.54 | | 1024 | 256 | 15360 | 33.617 | 30.46 | 56.434 | 4.54 |12C CPU, 3200 MT/sec RAM and two GPUs with IQ4_KS_R4:
main: n_kv_max = 131072, n_batch = 2048, n_ubatch = 1024, flash_attn = 1, n_gpu_layers = 99, n_threads = 12, n_threads_batch = 12 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 1024 | 256 | 0 | 21.779 | 47.02 | 48.989 | 5.23 | | 1024 | 256 | 1024 | 21.930 | 46.69 | 48.995 | 5.23 | | 1024 | 256 | 2048 | 22.086 | 46.37 | 49.121 | 5.21 | | 1024 | 256 | 3072 | 22.265 | 45.99 | 49.576 | 5.16 | | 1024 | 256 | 4096 | 22.285 | 45.95 | 49.686 | 5.15 | | 1024 | 256 | 5120 | 22.393 | 45.73 | 50.089 | 5.11 | | 1024 | 256 | 6144 | 22.535 | 45.44 | 50.258 | 5.09 | | 1024 | 256 | 7168 | 22.675 | 45.16 | 50.411 | 5.08 | | 1024 | 256 | 8192 | 22.783 | 44.95 | 50.748 | 5.04 | | 1024 | 256 | 9216 | 22.895 | 44.73 | 50.924 | 5.03 | | 1024 | 256 | 10240 | 23.022 | 44.48 | 51.098 | 5.01 | | 1024 | 256 | 11264 | 23.152 | 44.23 | 51.598 | 4.96 | | 1024 | 256 | 12288 | 23.287 | 43.97 | 51.607 | 4.96 | | 1024 | 256 | 13312 | 23.405 | 43.75 | 52.111 | 4.91 | | 1024 | 256 | 14336 | 23.524 | 43.53 | 52.300 | 4.89 | | 1024 | 256 | 15360 | 23.661 | 43.28 | 52.277 | 4.90 | | 1024 | 256 | 16384 | 23.899 | 42.85 | 52.671 | 4.86 |12C CPU, 3200 MT/sec RAM and two GPUs with UD-Q4_K_XL:
main: n_kv_max = 131072, n_batch = 2048, n_ubatch = 1024, flash_attn = 1, n_gpu_layers = 99, n_threads = 12, n_threads_batch = 12 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 1024 | 256 | 0 | 21.863 | 46.84 | 45.770 | 5.59 | | 1024 | 256 | 1024 | 22.030 | 46.48 | 45.932 | 5.57 | | 1024 | 256 | 2048 | 22.339 | 45.84 | 46.129 | 5.55 | | 1024 | 256 | 3072 | 22.207 | 46.11 | 46.657 | 5.49 | | 1024 | 256 | 4096 | 22.374 | 45.77 | 46.668 | 5.49 | | 1024 | 256 | 5120 | 22.524 | 45.46 | 47.454 | 5.39 | | 1024 | 256 | 6144 | 22.638 | 45.23 | 47.312 | 5.41 | | 1024 | 256 | 7168 | 22.736 | 45.04 | 47.412 | 5.40 | | 1024 | 256 | 8192 | 22.774 | 44.96 | 48.036 | 5.33 | | 1024 | 256 | 9216 | 22.895 | 44.73 | 48.090 | 5.32 | | 1024 | 256 | 10240 | 22.987 | 44.55 | 48.126 | 5.32 | | 1024 | 256 | 11264 | 23.116 | 44.30 | 48.779 | 5.25 | | 1024 | 256 | 12288 | 23.248 | 44.05 | 48.654 | 5.26 | | 1024 | 256 | 13312 | 23.545 | 43.49 | 49.123 | 5.21 | | 1024 | 256 | 14336 | 23.701 | 43.21 | 49.268 | 5.20 | | 1024 | 256 | 15360 | 23.993 | 42.68 | 50.471 | 5.07 | | 1024 | 256 | 16384 | 24.325 | 42.10 | 50.327 | 5.09 | | 1024 | 256 | 17408 | 24.821 | 41.26 | 50.353 | 5.08 |👤 ubergarm replied the 2025-07-11 at 17:58:44:
Great, now you have a baseline command you can adjust to dial in for any given quant. You can see how it is distributing the kv-cache across both GPUs fairly equally. You can tinker adding or removing the-ot ...=CUDA0routed expert layer offloads or increasing batch sizes or trying with a different quant. You can also modify the command a bit to use on mainline llama.cpp for the most apples-apples comparison of which I know. (just remove-mla 3 -amb 512 -fmoe --warmup-batchfirst as those don't exist on mainline.).Have fun and keep us posted!
👤 magikRUKKOLA replied the 2025-07-11 at 21:40:57:
Tried with three GPU and 2933 MT/sec 8-channel RAM 256GB and 64C CPU.150k context with -b 4096 -ub 4096 is achieved! 124 tps prefill, 6.6 tps decode (53k prefill sample).
#!/usr/bin/env bash #CUDA_VISIBLE_DEVICES="0" \ # --override-tensor exps=CPU,attn_kv_b=CPU \ CUDA_VISIBLE_DEVICES="0,1,2" \ #/opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-sweep-bench \ # --warmup-batch /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server \ --model /opt/ubergarm/DeepSeek-R1-0528-GGUF/IQ2_K_R4/DeepSeek-R1-0528-IQ2_K_R4-00001-of-00005.gguf \ --alias ubergarm/DeepSeek-R1-0528-IQ2_K_R4-GGUF \ --ctx-size $((150 * 1024)) \ --temp 0.5 --top-k 0 --top-p 1.0 --min-p 0.1 --repeat-penalty 1.0 \ -ctk q8_0 \ -mla 3 -fa \ -amb 512 \ -fmoe \ -b $((4 * 1024)) -ub $((4 * 1024)) \ --n-gpu-layers 99 \ --override-tensor exps=CPU \ --threads $(grep ^cpu\\scores /proc/cpuinfo | uniq | awk '{print $4}' | xargs -I{} echo "{}-0" | bc) \ --host 0.0.0.0 \ --port 8080 \ --lookup-cache-dynamic /mnt/data/ik_llama.kv.dumpRAM BW during decode: 50.15 GB/s numactl -H available: 1 nodes (0) node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 node 0 size: 257546 MB node 0 free: 2671 MB node distances: node 0 0: 10Fri Jul 11 21:26:50 2025 ╒═════════════════════════════════════════════════════════════════════════════╕ │ NVITOP 1.5.2.dev2 Driver Version: 575.51.02 CUDA Driver Version: 12.9 │ ├───────────────────────────────┬──────────────────────┬──────────────────────┤ │ GPU Name Persistence-M│ Bus-Id Disp.A │ Volatile Uncorr. ECC │ │ Fan Temp Perf Pwr:Usage/Cap│ Memory-Usage │ GPU-Util Compute M. │ ╞═══════════════════════════════╪══════════════════════╪══════════════════════╪════════════════════════════════════════════════════════════╕ │ 0 GeForce RTX 3090 Off │ 00000000:41:00.0 Off │ N/A │ MEM: ███████████████████████████████████████████████▎ 96% │ │ 79% 83C P2 176W / 350W │ 23.13GiB / 24.00GiB │ 18% Default │ UTL: ████████▉ 18% │ ├───────────────────────────────┼──────────────────────┼──────────────────────┼────────────────────────────────────────────────────────────┤ │ 1 GeForce RTX 3090 Off │ 00000000:42:00.0 Off │ N/A │ MEM: ████████████████████████████████████████ 81.7% │ │ 32% 61C P2 145W / 350W │ 20074MiB / 24.00GiB │ 18% Default │ UTL: ████████▉ 18% │ ├───────────────────────────────┼──────────────────────┼──────────────────────┼────────────────────────────────────────────────────────────┤ │ 2 GeForce RTX 3090 Off │ 00000000:61:00.0 Off │ N/A │ MEM: ████████████████████████████████████████▏ 82.0% │ │ 60% 75C P2 163W / 350W │ 20154MiB / 24.00GiB │ 6% Default │ UTL: ███ 6% │ ╘═══════════════════════════════╧══════════════════════╧══════════════════════╧════════════════════════════════════════════════════════════╛ [ CPU: ██████████████████▊ 20.9% UPTIME: 107.8 days ] ( Load Average: 63.01 43.50 21.19 ) [ MEM: █████▋ 6.3% USED: 3.97GiB ] [ SWP: ▏ 0.0% ] ╒══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╕ │ Processes: root@xxxx │ │ GPU PID USER GPU-MEM %SM %GMBW %CPU %MEM TIME COMMAND │ ╞══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╡ │ 0 280302 C root 23.12GiB 20 10 5872 88.3 13:45 /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server --model /opt/uberga.. │ ├──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ 1 280302 C root 20062MiB 16 8 9999+ 88.3 13:45 /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server --model /opt/uberga.. │ ├──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ 2 280302 C root 20142MiB 18 9 0.0 88.3 13:45 /opt/ik_llama.cpp/ik_llama.cpp/build/bin/llama-server --model /opt/uberga.. │ ╘══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╛53k prefill, decode:
llm_load_tensors: offloading 61 repeating layers to GPU llm_load_tensors: offloading non-repeating layers to GPU llm_load_tensors: offloaded 62/62 layers to GPU llm_load_tensors: CPU buffer size = 43640.69 MiB llm_load_tensors: CPU buffer size = 44228.69 MiB llm_load_tensors: CPU buffer size = 45768.69 MiB llm_load_tensors: CPU buffer size = 44704.69 MiB llm_load_tensors: CPU buffer size = 43745.14 MiB llm_load_tensors: CPU buffer size = 580.45 MiB llm_load_tensors: CUDA0 buffer size = 3997.42 MiB llm_load_tensors: CUDA1 buffer size = 3346.05 MiB llm_load_tensors: CUDA2 buffer size = 3607.86 MiB .................................................................................................... llama_new_context_with_model: n_ctx = 153600 llama_new_context_with_model: n_batch = 4096 llama_new_context_with_model: n_ubatch = 4096 llama_new_context_with_model: flash_attn = 1 llama_new_context_with_model: mla_attn = 3 llama_new_context_with_model: attn_max_b = 512 llama_new_context_with_model: fused_moe = 1 llama_new_context_with_model: ser = -1, 0 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 0.025 llama_kv_cache_init: CUDA0 KV buffer size = 1882.63 MiB llama_kv_cache_init: CUDA1 KV buffer size = 1882.63 MiB llama_kv_cache_init: CUDA2 KV buffer size = 1703.33 MiB llama_new_context_with_model: KV self size = 5468.55 MiB, c^KV (q8_0): 5468.55 MiB, kv^T: not used llama_new_context_with_model: CUDA_Host output buffer size = 0.99 MiB llama_new_context_with_model: pipeline parallelism enabled (n_copies=1) llama_new_context_with_model: CUDA0 compute buffer size = 16257.02 MiB llama_new_context_with_model: CUDA1 compute buffer size = 14157.02 MiB llama_new_context_with_model: CUDA2 compute buffer size = 14157.02 MiB llama_new_context_with_model: CUDA_Host compute buffer size = 2512.05 MiB llama_new_context_with_model: graph nodes = 45821 llama_new_context_with_model: graph splits = 160 ... INFO [ log_server_request] request | tid="139671036215296" timestamp=1752269512 remote_addr="127.0.0.1" remote_port=34848 status=404 method="GET" path="/api/tags" params={} INFO [ log_server_request] request | tid="139671027822592" timestamp=1752269512 remote_addr="127.0.0.1" remote_port=34850 status=200 method="GET" path="/v1/models" params={} INFO [ print_timings] prompt eval time = 439232.04 ms / 54460 tokens ( 8.07 ms per token, 123.99 tokens per second) | tid="139673445285888" timestamp=1752269666 id_slot=0 id_task=0 t_prompt_processing=439232.043 n_prompt_tokens_processed=54460 t_token=8.06522297098788 n_tokens_second=123.98913255060492 INFO [ print_timings] generation eval time = 797787.57 ms / 5293 runs ( 150.73 ms per token, 6.63 tokens per second) | tid="139673445285888" timestamp=1752269666 id_slot=0 id_task=0 t_token_generation=797787.566 n_decoded=5293 t_token=150.7250266389571 n_tokens_second=6.634598263468047 INFO [ print_timings] total time = 1237019.61 ms | tid="139673445285888" timestamp=1752269666 id_slot=0 id_task=0 t_prompt_processing=439232.043 t_token_generation=797787.566 t_total=1237019.609cpu mhz during benchmarking:
cat /proc/cpuinfo | grep MHz | awk '{print $4}' | cut -d. -f1 | sort | uniq -c 1 3795 1 3845 3 3846 1 3847 23 3848 29 3850 1 3863 1 3866 1 3882 1 3901 1 3916 3 3936 4 3937 1 3938 1 3949 1 3962 55 550benchmarking (unfortunately have to terminate the full-context test because the nvme drives under the gpus are getting hot -- have to use the risers to take them out): [EDIT]: I think I was using mla=2 here, not mla=3. So that resulted in fast prefill, but lower decode. Next time I will include what version is used.
main: n_kv_max = 153600, n_batch = 4096, n_ubatch = 4096, flash_attn = 1, n_gpu_layers = 99, n_threads = 64, n_threads_batch = 64 | PP | TG | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | |-------|--------|--------|----------|----------|----------|----------| | 4096 | 1024 | 0 | 19.069 | 214.79 | 93.736 | 10.92 | | 4096 | 1024 | 4096 | 20.307 | 201.70 | 97.358 | 10.52 | | 4096 | 1024 | 8192 | 21.737 | 188.43 | 101.818 | 10.06 | | 4096 | 1024 | 12288 | 24.293 | 168.61 | 105.518 | 9.70 | | 4096 | 1024 | 16384 | 26.821 | 152.71 | 109.751 | 9.33 | | 4096 | 1024 | 20480 | 29.469 | 138.99 | 113.723 | 9.00 | | 4096 | 1024 | 24576 | 31.962 | 128.15 | 117.694 | 8.70 | | 4096 | 1024 | 28672 | 34.693 | 118.06 | 122.337 | 8.37 | | 4096 | 1024 | 32768 | 38.113 | 107.47 | 125.174 | 8.18 | | 4096 | 1024 | 36864 | 40.758 | 100.49 | 129.472 | 7.91 | | 4096 | 1024 | 40960 | 42.524 | 96.32 | 132.479 | 7.73 | | 4096 | 1024 | 45056 | 45.471 | 90.08 | 137.050 | 7.47 | | 4096 | 1024 | 49152 | 48.498 | 84.46 | 140.497 | 7.29 | | 4096 | 1024 | 53248 | 50.349 | 81.35 | 145.521 | 7.04 | | 4096 | 1024 | 57344 | 53.210 | 76.98 | 148.478 | 6.90 | | 4096 | 1024 | 61440 | 56.849 | 72.05 | 151.928 | 6.74 | | 4096 | 1024 | 65536 | 62.658 | 65.37 | 156.614 | 6.54 | | 4096 | 1024 | 69632 | 63.486 | 64.52 | 159.997 | 6.40 |👤 magikRUKKOLA replied the 2025-07-11 at 21:56:58:
Ha! The current results are pretty promising. The prefill of 200 tps on a small context is great! And the ability to go as much as 150k tokens is great too! Amazing that nothing is crashing and the --seed and the powerful benchmarking is implemented too!What a great job, guys! Congrads!
👤 ubergarm replied the 2025-07-12 at 05:06:25:
150k context with -b 4096 -ub 4096 is achieved!
Sweeet! You got it going and have a variety of models to choose trading off speed and accuracy as desired. Really interesting to see the benchmarks, and cool to see the
IQ4_KS_R4speed quite comparable with the more traditional quant types used inUD-Q4_K_XL!the nvme drives under the gpus are getting hot
These are some interesting workloads to run for sure! 🔥 Once again great job getting your hardware together, figuring out how to adjust all the command arguments, and doing the tuning to share these great results!
👤 magikRUKKOLA replied the 2025-07-12 at 06:28:45:
I could not find the perplexity for the UD-Q4_K_XL at the graphs so I am posting it here:DeepSeek-R1-0528-GGUF/UD-Q4_K_XL Final estimate: PPL = 3.2483 +/- 0.01726So the IQ4_KS_R4 is better in terms of perplexity.
[EDIT]:
UD_Q2_K_XL: Final estimate: PPL = 3.5278 +/- 0.01920👤 Panchovix replied the 2025-07-12 at 06:30:57:
I could not find the perplexity for the UD-Q4_K_XL at the graphs so I am posting it here:
DeepSeek-R1-0528-GGUF/UD-Q4_K_XL Final estimate: PPL = 3.2483 +/- 0.01726So the IQ4_KS_R4 is better in terms of perplexity.
Hello there! Wondering, what was your command to test PPL? I want to try with some models I have but I get just "nan" for some reason, so maybe it's an issue on my end (highly factible). And these models work perfectly on normal usage.
👤 magikRUKKOLA replied the 2025-07-12 at 06:50:36:
You just get what?The docs on Perplexity is in this current thread (see above). quote:
Perplexity
# Test your quant against known quants # Lower is Better # https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2701019253 # example command: https://github.com/ikawrakow/ik_llama.cpp/pull/239#issuecomment-2708537247 wget https://github.com/user-attachments/files/19090237/wiki.test.raw.gz gunzip wiki.test.raw.gz # this can takes an hour or more for full run # but only really need first ~25 points or so # also some quants give nan results even on vanilla llama.cpp # *NOTE* I don't think `-ctk q8_0 -ctv q8_0` are valid with `-mla 2 -fa` yet so take this with a grain of salt. CUDA_VISIBLE_DEVICES="0," \ ./build/bin/llama-perplexity \ --model /mnt/raid/models/ubergarm/DeepSeek-R1-GGUF/DeepSeek-R1-IQ2_XS_R4.gguf \ -ctk q8_0 \ -mla 2 -fa \ -amb 512 \ -fmoe \ --ctx-size 512 \ --ubatch-size 512 \ -f wiki.test.raw \ --n-gpu-layers 63 \ --override-tensor exps=CPU \ --threads 24👤 ikawrakow replied the 2025-07-12 at 10:02:21:
The quoted comments about NaNs and-mla 2are hopelessly outdated.👤 ubergarm replied the 2025-07-12 at 15:57:40:
Thanks for the result on that perplexity score @magikRUKKOLA it lines up with my own estimates of the smaller quants. That guide is indeed hopelessly outdated already haha.. Using q8_0 quantized cache will drop the score just a tiny bit, and mla 3 is pretty much always the way to go now.Here is an example of what I've been using lately for smaller models and two CUDA GPUs:
./build/bin/llama-perplexity \ --model "$model" \ -f wiki.test.raw \ --seed 1337 \ -fa \ -mla 3 -fmoe -amb 512 \ -ctk f16 \ -ngl 99 \ -ot "blk\.(3|4|5|6|7|8|9|10|11|12|13|14|15)\.ffn_.*=CUDA0" \ -ot "blk\.(16|17|18|19|20|21|22|23|24|25|26|27|28)\.ffn_.*=CUDA1" \ -ot exps=CPU \ --threads 24👤 Panchovix replied the 2025-07-12 at 18:53:08:
Many thanks to all! I did re test and finally worked, after months haha.Finally could test R1 0525 IQ4_XS, from unsloth.
Result is
DeepSeek-R1-0528-IQ4_XS-merged.gguf Final estimate: PPL = 3.2598 +/- 0.01727So it is surprisingly close to Q4_K_XL, but probably is slower for TG.
Also both are really close to Q8 (3.2119), by 1-2%.
Finally I will be able to test V3 0324 quants PPL, but I don't have the Q8 ppl sadly haha.