 +
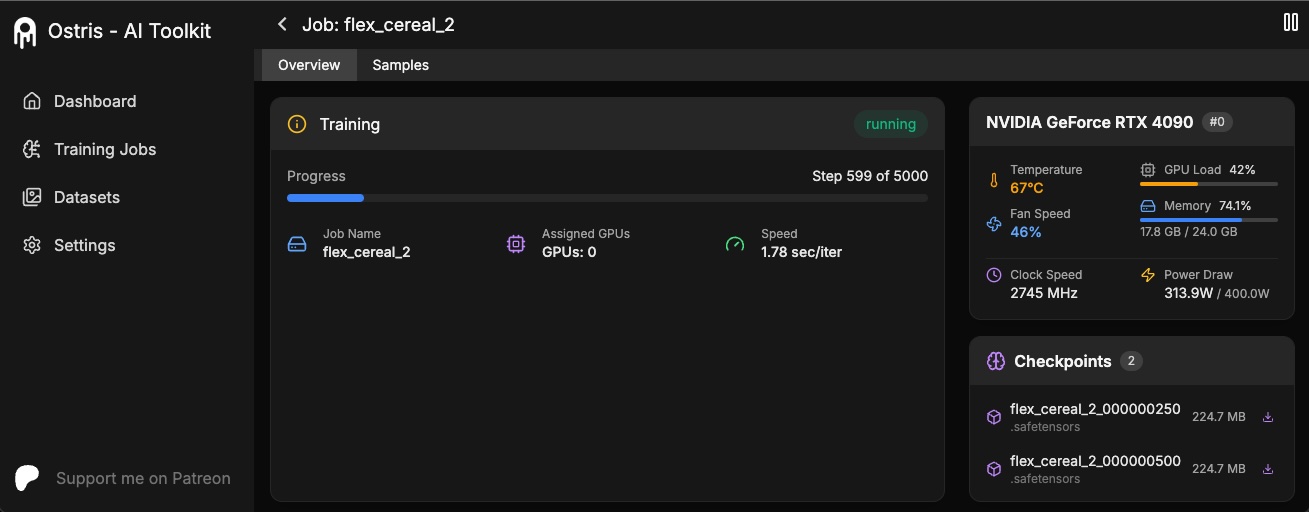
+The AI Toolkit UI is a web interface for the AI Toolkit. It allows you to easily start, stop, and monitor jobs. It also allows you to easily train models with a few clicks. It is still in early beta and will likely have bugs and frequent breaking changes. It is currently only tested on linux for now.
+
+
+WARNING: The UI is not secure and should not be exposed to the internet. It is only meant to be run locally or on a server that does not have ports exposed. Adding additional security is on the roadmap.
+
+## Installing the UI
+
+Requirements:
+- Node.js > 18
+
+You will need to do this with every update as well.
+
+```bash
+cd ui
+npm install
+npm run build
+npm run update_db
+```
+
+## Running the UI
+
+Make sure you built it as shown above. The UI does not need to be kept running for the jobs to run. It is only needed to start/stop/monitor jobs.
+
+```bash
+cd ui
+npm run start
+```
+
+You can now access the UI at `http://localhost:8675` or `http://
+
+The AI Toolkit UI is a web interface for the AI Toolkit. It allows you to easily start, stop, and monitor jobs. It also allows you to easily train models with a few clicks. It is still in early beta and will likely have bugs and frequent breaking changes. It is currently only tested on linux for now.
+
+
+WARNING: The UI is not secure and should not be exposed to the internet. It is only meant to be run locally or on a server that does not have ports exposed. Adding additional security is on the roadmap.
+
+## Installing the UI
+
+Requirements:
+- Node.js > 18
+
+You will need to do this with every update as well.
+
+```bash
+cd ui
+npm install
+npm run build
+npm run update_db
+```
+
+## Running the UI
+
+Make sure you built it as shown above. The UI does not need to be kept running for the jobs to run. It is only needed to start/stop/monitor jobs.
+
+```bash
+cd ui
+npm run start
+```
+
+You can now access the UI at `http://localhost:8675` or `http:// -
----
-
-## TODO
-- [X] Add proper regs on sliders
-- [X] Add SDXL support (base model only for now)
-- [ ] Add plain erasing
-- [ ] Make Textual inversion network trainer (network that spits out TI embeddings)
-
----
-
-## Change Log
-
-#### 2023-08-05
- - Huge memory rework and slider rework. Slider training is better thant ever with no more
-ram spikes. I also made it so all 4 parts of the slider algorythm run in one batch so they share gradient
-accumulation. This makes it much faster and more stable.
- - Updated the example config to be something more practical and more updated to current methods. It is now
-a detail slide and shows how to train one without a subject. 512x512 slider training for 1.5 should work on
-6GB gpu now. Will test soon to verify.
-
-
-#### 2021-10-20
- - Windows support bug fixes
- - Extensions! Added functionality to make and share custom extensions for training, merging, whatever.
-check out the example in the `extensions` folder. Read more about that above.
- - Model Merging, provided via the example extension.
-
-#### 2023-08-03
-Another big refactor to make SD more modular.
-
-Made batch image generation script
-
-#### 2023-08-01
-Major changes and update. New LoRA rescale tool, look above for details. Added better metadata so
-Automatic1111 knows what the base model is. Added some experiments and a ton of updates. This thing is still unstable
-at the moment, so hopefully there are not breaking changes.
-
-Unfortunately, I am too lazy to write a proper changelog with all the changes.
-
-I added SDXL training to sliders... but.. it does not work properly.
-The slider training relies on a model's ability to understand that an unconditional (negative prompt)
-means you do not want that concept in the output. SDXL does not understand this for whatever reason,
-which makes separating out
-concepts within the model hard. I am sure the community will find a way to fix this
-over time, but for now, it is not
-going to work properly. And if any of you are thinking "Could we maybe fix it by adding 1 or 2 more text
-encoders to the model as well as a few more entirely separate diffusion networks?" No. God no. It just needs a little
-training without every experimental new paper added to it. The KISS principal.
-
-
-#### 2023-07-30
-Added "anchors" to the slider trainer. This allows you to set a prompt that will be used as a
-regularizer. You can set the network multiplier to force spread consistency at high weights
-
diff --git a/extensions_built_in/sd_trainer/UITrainer.py b/extensions_built_in/sd_trainer/UITrainer.py
new file mode 100644
index 00000000..f0fdba68
--- /dev/null
+++ b/extensions_built_in/sd_trainer/UITrainer.py
@@ -0,0 +1,227 @@
+from collections import OrderedDict
+import os
+import sqlite3
+import asyncio
+import concurrent.futures
+from extensions_built_in.sd_trainer.SDTrainer import SDTrainer
+from typing import Literal, Optional
+
+
+AITK_Status = Literal["running", "stopped", "error", "completed"]
+
+
+class UITrainer(SDTrainer):
+ def __init__(self, process_id: int, job, config: OrderedDict, **kwargs):
+ super(UITrainer, self).__init__(process_id, job, config, **kwargs)
+ self.sqlite_db_path = self.config.get("sqlite_db_path", "./aitk_db.db")
+ print(f"Using SQLite database at {self.sqlite_db_path}")
+ self.job_id = os.environ.get("AITK_JOB_ID", None)
+ if self.job_id is None:
+ raise Exception("AITK_JOB_ID not set")
+ self.is_stopping = False
+ # Create a thread pool for database operations
+ self.thread_pool = concurrent.futures.ThreadPoolExecutor(max_workers=1)
+ # Track all async tasks
+ self._async_tasks = []
+ # Initialize the status
+ self._run_async_operation(self._update_status("running", "Starting"))
+
+ def _run_async_operation(self, coro):
+ """Helper method to run an async coroutine and track the task."""
+ try:
+ loop = asyncio.get_event_loop()
+ except RuntimeError:
+ # No event loop exists, create a new one
+ loop = asyncio.new_event_loop()
+ asyncio.set_event_loop(loop)
+
+ # Create a task and track it
+ if loop.is_running():
+ task = asyncio.run_coroutine_threadsafe(coro, loop)
+ self._async_tasks.append(asyncio.wrap_future(task))
+ else:
+ task = loop.create_task(coro)
+ self._async_tasks.append(task)
+ loop.run_until_complete(task)
+
+ async def _execute_db_operation(self, operation_func):
+ """Execute a database operation in a separate thread to avoid blocking."""
+ loop = asyncio.get_event_loop()
+ return await loop.run_in_executor(self.thread_pool, operation_func)
+
+ def _db_connect(self):
+ """Create a new connection for each operation to avoid locking."""
+ conn = sqlite3.connect(self.sqlite_db_path, timeout=10.0)
+ conn.isolation_level = None # Enable autocommit mode
+ return conn
+
+ def should_stop(self):
+ def _check_stop():
+ with self._db_connect() as conn:
+ cursor = conn.cursor()
+ cursor.execute(
+ "SELECT stop FROM Job WHERE id = ?", (self.job_id,))
+ stop = cursor.fetchone()
+ return False if stop is None else stop[0] == 1
+
+ return _check_stop()
+
+ def maybe_stop(self):
+ if self.should_stop():
+ self._run_async_operation(
+ self._update_status("stopped", "Job stopped"))
+ self.is_stopping = True
+ raise Exception("Job stopped")
+
+ async def _update_key(self, key, value):
+ if not self.accelerator.is_main_process:
+ return
+
+ def _do_update():
+ with self._db_connect() as conn:
+ cursor = conn.cursor()
+ cursor.execute("BEGIN IMMEDIATE")
+ try:
+ # Convert the value to string if it's not already
+ if isinstance(value, str):
+ value_to_insert = value
+ else:
+ value_to_insert = str(value)
+
+ # Use parameterized query for both the column name and value
+ update_query = f"UPDATE Job SET {key} = ? WHERE id = ?"
+ cursor.execute(
+ update_query, (value_to_insert, self.job_id))
+ finally:
+ cursor.execute("COMMIT")
+
+ await self._execute_db_operation(_do_update)
+
+ def update_step(self):
+ """Non-blocking update of the step count."""
+ if self.accelerator.is_main_process:
+ self._run_async_operation(self._update_key("step", self.step_num))
+
+ def update_db_key(self, key, value):
+ """Non-blocking update a key in the database."""
+ if self.accelerator.is_main_process:
+ self._run_async_operation(self._update_key(key, value))
+
+ async def _update_status(self, status: AITK_Status, info: Optional[str] = None):
+ if not self.accelerator.is_main_process:
+ return
+
+ def _do_update():
+ with self._db_connect() as conn:
+ cursor = conn.cursor()
+ cursor.execute("BEGIN IMMEDIATE")
+ try:
+ if info is not None:
+ cursor.execute(
+ "UPDATE Job SET status = ?, info = ? WHERE id = ?",
+ (status, info, self.job_id)
+ )
+ else:
+ cursor.execute(
+ "UPDATE Job SET status = ? WHERE id = ?",
+ (status, self.job_id)
+ )
+ finally:
+ cursor.execute("COMMIT")
+
+ await self._execute_db_operation(_do_update)
+
+ def update_status(self, status: AITK_Status, info: Optional[str] = None):
+ """Non-blocking update of status."""
+ if self.accelerator.is_main_process:
+ self._run_async_operation(self._update_status(status, info))
+
+ async def wait_for_all_async(self):
+ """Wait for all tracked async operations to complete."""
+ if not self._async_tasks:
+ return
+
+ try:
+ await asyncio.gather(*self._async_tasks)
+ finally:
+ # Clear the task list after completion
+ self._async_tasks.clear()
+
+ def on_error(self, e: Exception):
+ super(UITrainer, self).on_error(e)
+ if self.accelerator.is_main_process and not self.is_stopping:
+ self.update_status("error", str(e))
+ self.update_db_key("step", self.last_save_step)
+ asyncio.run(self.wait_for_all_async())
+ self.thread_pool.shutdown(wait=True)
+
+ def handle_timing_print_hook(self, timing_dict):
+ if "train_loop" not in timing_dict:
+ print("train_loop not found in timing_dict", timing_dict)
+ return
+ seconds_per_iter = timing_dict["train_loop"]
+ # determine iter/sec or sec/iter
+ if seconds_per_iter < 1:
+ iters_per_sec = 1 / seconds_per_iter
+ self.update_db_key("speed_string", f"{iters_per_sec:.2f} iter/sec")
+ else:
+ self.update_db_key(
+ "speed_string", f"{seconds_per_iter:.2f} sec/iter")
+
+ def done_hook(self):
+ super(UITrainer, self).done_hook()
+ self.update_status("completed", "Training completed")
+ # Wait for all async operations to finish before shutting down
+ asyncio.run(self.wait_for_all_async())
+ self.thread_pool.shutdown(wait=True)
+
+ def end_step_hook(self):
+ super(UITrainer, self).end_step_hook()
+ self.update_step()
+ self.maybe_stop()
+
+ def hook_before_model_load(self):
+ super().hook_before_model_load()
+ self.maybe_stop()
+ self.update_status("running", "Loading model")
+
+ def before_dataset_load(self):
+ super().before_dataset_load()
+ self.maybe_stop()
+ self.update_status("running", "Loading dataset")
+
+ def hook_before_train_loop(self):
+ super().hook_before_train_loop()
+ self.maybe_stop()
+ self.update_step()
+ self.update_status("running", "Training")
+ self.timer.add_after_print_hook(self.handle_timing_print_hook)
+
+ def status_update_hook_func(self, string):
+ self.update_status("running", string)
+
+ def hook_after_sd_init_before_load(self):
+ super().hook_after_sd_init_before_load()
+ self.maybe_stop()
+ self.sd.add_status_update_hook(self.status_update_hook_func)
+
+ def sample_step_hook(self, img_num, total_imgs):
+ super().sample_step_hook(img_num, total_imgs)
+ self.maybe_stop()
+ self.update_status(
+ "running", f"Generating images - {img_num + 1}/{total_imgs}")
+
+ def sample(self, step=None, is_first=False):
+ self.maybe_stop()
+ total_imgs = len(self.sample_config.prompts)
+ self.update_status("running", f"Generating images - 0/{total_imgs}")
+ super().sample(step, is_first)
+ self.maybe_stop()
+ self.update_status("running", "Training")
+
+ def save(self, step=None):
+ self.maybe_stop()
+ self.update_status("running", "Saving model")
+ super().save(step)
+ self.maybe_stop()
+ self.update_status("running", "Training")
diff --git a/extensions_built_in/sd_trainer/__init__.py b/extensions_built_in/sd_trainer/__init__.py
index 45aa841e..47c84fa1 100644
--- a/extensions_built_in/sd_trainer/__init__.py
+++ b/extensions_built_in/sd_trainer/__init__.py
@@ -18,6 +18,22 @@ class SDTrainerExtension(Extension):
from .SDTrainer import SDTrainer
return SDTrainer
+# This is for generic training (LoRA, Dreambooth, FineTuning)
+class UITrainerExtension(Extension):
+ # uid must be unique, it is how the extension is identified
+ uid = "ui_trainer"
+
+ # name is the name of the extension for printing
+ name = "UI Trainer"
+
+ # This is where your process class is loaded
+ # keep your imports in here so they don't slow down the rest of the program
+ @classmethod
+ def get_process(cls):
+ # import your process class here so it is only loaded when needed and return it
+ from .UITrainer import UITrainer
+ return UITrainer
+
# for backwards compatability
class TextualInversionTrainer(SDTrainerExtension):
@@ -26,5 +42,5 @@ class TextualInversionTrainer(SDTrainerExtension):
AI_TOOLKIT_EXTENSIONS = [
# you can put a list of extensions here
- SDTrainerExtension, TextualInversionTrainer
+ SDTrainerExtension, TextualInversionTrainer, UITrainerExtension
]
diff --git a/jobs/process/BaseProcess.py b/jobs/process/BaseProcess.py
index f0644607..c58724c9 100644
--- a/jobs/process/BaseProcess.py
+++ b/jobs/process/BaseProcess.py
@@ -24,6 +24,9 @@ class BaseProcess(object):
self.performance_log_every = self.get_conf('performance_log_every', 0)
print(json.dumps(self.config, indent=4))
+
+ def on_error(self, e: Exception):
+ pass
def get_conf(self, key, default=None, required=False, as_type=None):
# split key by '.' and recursively get the value
diff --git a/jobs/process/BaseSDTrainProcess.py b/jobs/process/BaseSDTrainProcess.py
index e30ddae0..2482c26d 100644
--- a/jobs/process/BaseSDTrainProcess.py
+++ b/jobs/process/BaseSDTrainProcess.py
@@ -92,6 +92,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.step_num = 0
self.start_step = 0
self.epoch_num = 0
+ self.last_save_step = 0
# start at 1 so we can do a sample at the start
self.grad_accumulation_step = 1
# if true, then we do not do an optimizer step. We are accumulating gradients
@@ -439,6 +440,12 @@ class BaseSDTrainProcess(BaseTrainProcess):
def post_save_hook(self, save_path):
# override in subclass
pass
+
+ def done_hook(self):
+ pass
+
+ def end_step_hook(self):
+ pass
def save(self, step=None):
if not self.accelerator.is_main_process:
@@ -453,6 +460,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
step_num = ''
if step is not None:
+ self.last_save_step = step
# zeropad 9 digits
step_num = f"_{str(step).zfill(9)}"
@@ -648,6 +656,8 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.logger.start()
self.prepare_accelerator()
+ def sample_step_hook(self, img_num, total_imgs):
+ pass
def prepare_accelerator(self):
# set some config
@@ -722,6 +732,9 @@ class BaseSDTrainProcess(BaseTrainProcess):
def hook_train_loop(self, batch):
# return loss
return 0.0
+
+ def hook_after_sd_init_before_load(self):
+ pass
def get_latest_save_path(self, name=None, post=''):
if name == None:
@@ -1417,8 +1430,12 @@ class BaseSDTrainProcess(BaseTrainProcess):
custom_pipeline=self.custom_pipeline,
noise_scheduler=sampler,
)
+
+ self.hook_after_sd_init_before_load()
# run base sd process run
self.sd.load_model()
+
+ self.sd.add_after_sample_image_hook(self.sample_step_hook)
dtype = get_torch_dtype(self.train_config.dtype)
@@ -1812,6 +1829,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.sd)
flush()
+ self.last_save_step = self.step_num
### HOOK ###
self.hook_before_train_loop()
@@ -2091,6 +2109,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
# update various steps
self.step_num = step + 1
self.grad_accumulation_step += 1
+ self.end_step_hook()
###################################################################
@@ -2110,13 +2129,15 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.logger.finish()
self.accelerator.end_training()
- if self.save_config.push_to_hub:
- if("HF_TOKEN" not in os.environ):
- interpreter_login(new_session=False, write_permission=True)
- self.push_to_hub(
- repo_id=self.save_config.hf_repo_id,
- private=self.save_config.hf_private
- )
+ if self.accelerator.is_main_process:
+ # push to hub
+ if self.save_config.push_to_hub:
+ if("HF_TOKEN" not in os.environ):
+ interpreter_login(new_session=False, write_permission=True)
+ self.push_to_hub(
+ repo_id=self.save_config.hf_repo_id,
+ private=self.save_config.hf_private
+ )
del (
self.sd,
unet,
@@ -2128,6 +2149,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
)
flush()
+ self.done_hook()
def push_to_hub(
self,
diff --git a/requirements.txt b/requirements.txt
index 4040e760..abf9bc64 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -32,4 +32,5 @@ sentencepiece
huggingface_hub
peft
gradio
-python-slugify
\ No newline at end of file
+python-slugify
+sqlite3
\ No newline at end of file
diff --git a/run.py b/run.py
index 9a3e57fd..d4ccda2a 100644
--- a/run.py
+++ b/run.py
@@ -88,6 +88,10 @@ def main():
except Exception as e:
print_acc(f"Error running job: {e}")
jobs_failed += 1
+ try:
+ job.process[0].on_error(e)
+ except Exception as e2:
+ print_acc(f"Error running on_error: {e2}")
if not args.recover:
print_end_message(jobs_completed, jobs_failed)
raise e
diff --git a/toolkit/config_modules.py b/toolkit/config_modules.py
index dfffae7c..ee4b6e72 100644
--- a/toolkit/config_modules.py
+++ b/toolkit/config_modules.py
@@ -379,7 +379,8 @@ class TrainConfig:
self.do_prior_divergence = kwargs.get('do_prior_divergence', False)
ema_config: Union[Dict, None] = kwargs.get('ema_config', None)
- if ema_config is not None:
+ # if it is set explicitly to false, leave it false.
+ if ema_config is not None and ema_config.get('use_ema', None) is not None:
ema_config['use_ema'] = True
print(f"Using EMA")
else:
diff --git a/toolkit/lora_special.py b/toolkit/lora_special.py
index 27317be9..b37ed098 100644
--- a/toolkit/lora_special.py
+++ b/toolkit/lora_special.py
@@ -9,6 +9,7 @@ from typing import List, Optional, Dict, Type, Union
import torch
from diffusers import UNet2DConditionModel, PixArtTransformer2DModel, AuraFlowTransformer2DModel
from transformers import CLIPTextModel
+from toolkit.models.lokr import LokrModule
from .config_modules import NetworkConfig
from .lorm import count_parameters
diff --git a/toolkit/models/lokr.py b/toolkit/models/lokr.py
new file mode 100644
index 00000000..b736406e
--- /dev/null
+++ b/toolkit/models/lokr.py
@@ -0,0 +1,282 @@
+# based heavily on https://github.com/KohakuBlueleaf/LyCORIS/blob/eb460098187f752a5d66406d3affade6f0a07ece/lycoris/modules/lokr.py
+
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from toolkit.network_mixins import ToolkitModuleMixin
+
+from typing import TYPE_CHECKING, Union, List
+
+if TYPE_CHECKING:
+
+ from toolkit.lora_special import LoRASpecialNetwork
+
+# 4, build custom backward function
+# -
+
+
+def factorization(dimension: int, factor:int=-1) -> tuple[int, int]:
+ '''
+ return a tuple of two value of input dimension decomposed by the number closest to factor
+ second value is higher or equal than first value.
+
+ In LoRA with Kroneckor Product, first value is a value for weight scale.
+ secon value is a value for weight.
+
+ Becuase of non-commutative property, A⊗B ≠ B⊗A. Meaning of two matrices is slightly different.
+
+ examples)
+ factor
+ -1 2 4 8 16 ...
+ 127 -> 127, 1 127 -> 127, 1 127 -> 127, 1 127 -> 127, 1 127 -> 127, 1
+ 128 -> 16, 8 128 -> 64, 2 128 -> 32, 4 128 -> 16, 8 128 -> 16, 8
+ 250 -> 125, 2 250 -> 125, 2 250 -> 125, 2 250 -> 125, 2 250 -> 125, 2
+ 360 -> 45, 8 360 -> 180, 2 360 -> 90, 4 360 -> 45, 8 360 -> 45, 8
+ 512 -> 32, 16 512 -> 256, 2 512 -> 128, 4 512 -> 64, 8 512 -> 32, 16
+ 1024 -> 32, 32 1024 -> 512, 2 1024 -> 256, 4 1024 -> 128, 8 1024 -> 64, 16
+ '''
+
+ if factor > 0 and (dimension % factor) == 0:
+ m = factor
+ n = dimension // factor
+ return m, n
+ if factor == -1:
+ factor = dimension
+ m, n = 1, dimension
+ length = m + n
+ while m
-
----
-
-## TODO
-- [X] Add proper regs on sliders
-- [X] Add SDXL support (base model only for now)
-- [ ] Add plain erasing
-- [ ] Make Textual inversion network trainer (network that spits out TI embeddings)
-
----
-
-## Change Log
-
-#### 2023-08-05
- - Huge memory rework and slider rework. Slider training is better thant ever with no more
-ram spikes. I also made it so all 4 parts of the slider algorythm run in one batch so they share gradient
-accumulation. This makes it much faster and more stable.
- - Updated the example config to be something more practical and more updated to current methods. It is now
-a detail slide and shows how to train one without a subject. 512x512 slider training for 1.5 should work on
-6GB gpu now. Will test soon to verify.
-
-
-#### 2021-10-20
- - Windows support bug fixes
- - Extensions! Added functionality to make and share custom extensions for training, merging, whatever.
-check out the example in the `extensions` folder. Read more about that above.
- - Model Merging, provided via the example extension.
-
-#### 2023-08-03
-Another big refactor to make SD more modular.
-
-Made batch image generation script
-
-#### 2023-08-01
-Major changes and update. New LoRA rescale tool, look above for details. Added better metadata so
-Automatic1111 knows what the base model is. Added some experiments and a ton of updates. This thing is still unstable
-at the moment, so hopefully there are not breaking changes.
-
-Unfortunately, I am too lazy to write a proper changelog with all the changes.
-
-I added SDXL training to sliders... but.. it does not work properly.
-The slider training relies on a model's ability to understand that an unconditional (negative prompt)
-means you do not want that concept in the output. SDXL does not understand this for whatever reason,
-which makes separating out
-concepts within the model hard. I am sure the community will find a way to fix this
-over time, but for now, it is not
-going to work properly. And if any of you are thinking "Could we maybe fix it by adding 1 or 2 more text
-encoders to the model as well as a few more entirely separate diffusion networks?" No. God no. It just needs a little
-training without every experimental new paper added to it. The KISS principal.
-
-
-#### 2023-07-30
-Added "anchors" to the slider trainer. This allows you to set a prompt that will be used as a
-regularizer. You can set the network multiplier to force spread consistency at high weights
-
diff --git a/extensions_built_in/sd_trainer/UITrainer.py b/extensions_built_in/sd_trainer/UITrainer.py
new file mode 100644
index 00000000..f0fdba68
--- /dev/null
+++ b/extensions_built_in/sd_trainer/UITrainer.py
@@ -0,0 +1,227 @@
+from collections import OrderedDict
+import os
+import sqlite3
+import asyncio
+import concurrent.futures
+from extensions_built_in.sd_trainer.SDTrainer import SDTrainer
+from typing import Literal, Optional
+
+
+AITK_Status = Literal["running", "stopped", "error", "completed"]
+
+
+class UITrainer(SDTrainer):
+ def __init__(self, process_id: int, job, config: OrderedDict, **kwargs):
+ super(UITrainer, self).__init__(process_id, job, config, **kwargs)
+ self.sqlite_db_path = self.config.get("sqlite_db_path", "./aitk_db.db")
+ print(f"Using SQLite database at {self.sqlite_db_path}")
+ self.job_id = os.environ.get("AITK_JOB_ID", None)
+ if self.job_id is None:
+ raise Exception("AITK_JOB_ID not set")
+ self.is_stopping = False
+ # Create a thread pool for database operations
+ self.thread_pool = concurrent.futures.ThreadPoolExecutor(max_workers=1)
+ # Track all async tasks
+ self._async_tasks = []
+ # Initialize the status
+ self._run_async_operation(self._update_status("running", "Starting"))
+
+ def _run_async_operation(self, coro):
+ """Helper method to run an async coroutine and track the task."""
+ try:
+ loop = asyncio.get_event_loop()
+ except RuntimeError:
+ # No event loop exists, create a new one
+ loop = asyncio.new_event_loop()
+ asyncio.set_event_loop(loop)
+
+ # Create a task and track it
+ if loop.is_running():
+ task = asyncio.run_coroutine_threadsafe(coro, loop)
+ self._async_tasks.append(asyncio.wrap_future(task))
+ else:
+ task = loop.create_task(coro)
+ self._async_tasks.append(task)
+ loop.run_until_complete(task)
+
+ async def _execute_db_operation(self, operation_func):
+ """Execute a database operation in a separate thread to avoid blocking."""
+ loop = asyncio.get_event_loop()
+ return await loop.run_in_executor(self.thread_pool, operation_func)
+
+ def _db_connect(self):
+ """Create a new connection for each operation to avoid locking."""
+ conn = sqlite3.connect(self.sqlite_db_path, timeout=10.0)
+ conn.isolation_level = None # Enable autocommit mode
+ return conn
+
+ def should_stop(self):
+ def _check_stop():
+ with self._db_connect() as conn:
+ cursor = conn.cursor()
+ cursor.execute(
+ "SELECT stop FROM Job WHERE id = ?", (self.job_id,))
+ stop = cursor.fetchone()
+ return False if stop is None else stop[0] == 1
+
+ return _check_stop()
+
+ def maybe_stop(self):
+ if self.should_stop():
+ self._run_async_operation(
+ self._update_status("stopped", "Job stopped"))
+ self.is_stopping = True
+ raise Exception("Job stopped")
+
+ async def _update_key(self, key, value):
+ if not self.accelerator.is_main_process:
+ return
+
+ def _do_update():
+ with self._db_connect() as conn:
+ cursor = conn.cursor()
+ cursor.execute("BEGIN IMMEDIATE")
+ try:
+ # Convert the value to string if it's not already
+ if isinstance(value, str):
+ value_to_insert = value
+ else:
+ value_to_insert = str(value)
+
+ # Use parameterized query for both the column name and value
+ update_query = f"UPDATE Job SET {key} = ? WHERE id = ?"
+ cursor.execute(
+ update_query, (value_to_insert, self.job_id))
+ finally:
+ cursor.execute("COMMIT")
+
+ await self._execute_db_operation(_do_update)
+
+ def update_step(self):
+ """Non-blocking update of the step count."""
+ if self.accelerator.is_main_process:
+ self._run_async_operation(self._update_key("step", self.step_num))
+
+ def update_db_key(self, key, value):
+ """Non-blocking update a key in the database."""
+ if self.accelerator.is_main_process:
+ self._run_async_operation(self._update_key(key, value))
+
+ async def _update_status(self, status: AITK_Status, info: Optional[str] = None):
+ if not self.accelerator.is_main_process:
+ return
+
+ def _do_update():
+ with self._db_connect() as conn:
+ cursor = conn.cursor()
+ cursor.execute("BEGIN IMMEDIATE")
+ try:
+ if info is not None:
+ cursor.execute(
+ "UPDATE Job SET status = ?, info = ? WHERE id = ?",
+ (status, info, self.job_id)
+ )
+ else:
+ cursor.execute(
+ "UPDATE Job SET status = ? WHERE id = ?",
+ (status, self.job_id)
+ )
+ finally:
+ cursor.execute("COMMIT")
+
+ await self._execute_db_operation(_do_update)
+
+ def update_status(self, status: AITK_Status, info: Optional[str] = None):
+ """Non-blocking update of status."""
+ if self.accelerator.is_main_process:
+ self._run_async_operation(self._update_status(status, info))
+
+ async def wait_for_all_async(self):
+ """Wait for all tracked async operations to complete."""
+ if not self._async_tasks:
+ return
+
+ try:
+ await asyncio.gather(*self._async_tasks)
+ finally:
+ # Clear the task list after completion
+ self._async_tasks.clear()
+
+ def on_error(self, e: Exception):
+ super(UITrainer, self).on_error(e)
+ if self.accelerator.is_main_process and not self.is_stopping:
+ self.update_status("error", str(e))
+ self.update_db_key("step", self.last_save_step)
+ asyncio.run(self.wait_for_all_async())
+ self.thread_pool.shutdown(wait=True)
+
+ def handle_timing_print_hook(self, timing_dict):
+ if "train_loop" not in timing_dict:
+ print("train_loop not found in timing_dict", timing_dict)
+ return
+ seconds_per_iter = timing_dict["train_loop"]
+ # determine iter/sec or sec/iter
+ if seconds_per_iter < 1:
+ iters_per_sec = 1 / seconds_per_iter
+ self.update_db_key("speed_string", f"{iters_per_sec:.2f} iter/sec")
+ else:
+ self.update_db_key(
+ "speed_string", f"{seconds_per_iter:.2f} sec/iter")
+
+ def done_hook(self):
+ super(UITrainer, self).done_hook()
+ self.update_status("completed", "Training completed")
+ # Wait for all async operations to finish before shutting down
+ asyncio.run(self.wait_for_all_async())
+ self.thread_pool.shutdown(wait=True)
+
+ def end_step_hook(self):
+ super(UITrainer, self).end_step_hook()
+ self.update_step()
+ self.maybe_stop()
+
+ def hook_before_model_load(self):
+ super().hook_before_model_load()
+ self.maybe_stop()
+ self.update_status("running", "Loading model")
+
+ def before_dataset_load(self):
+ super().before_dataset_load()
+ self.maybe_stop()
+ self.update_status("running", "Loading dataset")
+
+ def hook_before_train_loop(self):
+ super().hook_before_train_loop()
+ self.maybe_stop()
+ self.update_step()
+ self.update_status("running", "Training")
+ self.timer.add_after_print_hook(self.handle_timing_print_hook)
+
+ def status_update_hook_func(self, string):
+ self.update_status("running", string)
+
+ def hook_after_sd_init_before_load(self):
+ super().hook_after_sd_init_before_load()
+ self.maybe_stop()
+ self.sd.add_status_update_hook(self.status_update_hook_func)
+
+ def sample_step_hook(self, img_num, total_imgs):
+ super().sample_step_hook(img_num, total_imgs)
+ self.maybe_stop()
+ self.update_status(
+ "running", f"Generating images - {img_num + 1}/{total_imgs}")
+
+ def sample(self, step=None, is_first=False):
+ self.maybe_stop()
+ total_imgs = len(self.sample_config.prompts)
+ self.update_status("running", f"Generating images - 0/{total_imgs}")
+ super().sample(step, is_first)
+ self.maybe_stop()
+ self.update_status("running", "Training")
+
+ def save(self, step=None):
+ self.maybe_stop()
+ self.update_status("running", "Saving model")
+ super().save(step)
+ self.maybe_stop()
+ self.update_status("running", "Training")
diff --git a/extensions_built_in/sd_trainer/__init__.py b/extensions_built_in/sd_trainer/__init__.py
index 45aa841e..47c84fa1 100644
--- a/extensions_built_in/sd_trainer/__init__.py
+++ b/extensions_built_in/sd_trainer/__init__.py
@@ -18,6 +18,22 @@ class SDTrainerExtension(Extension):
from .SDTrainer import SDTrainer
return SDTrainer
+# This is for generic training (LoRA, Dreambooth, FineTuning)
+class UITrainerExtension(Extension):
+ # uid must be unique, it is how the extension is identified
+ uid = "ui_trainer"
+
+ # name is the name of the extension for printing
+ name = "UI Trainer"
+
+ # This is where your process class is loaded
+ # keep your imports in here so they don't slow down the rest of the program
+ @classmethod
+ def get_process(cls):
+ # import your process class here so it is only loaded when needed and return it
+ from .UITrainer import UITrainer
+ return UITrainer
+
# for backwards compatability
class TextualInversionTrainer(SDTrainerExtension):
@@ -26,5 +42,5 @@ class TextualInversionTrainer(SDTrainerExtension):
AI_TOOLKIT_EXTENSIONS = [
# you can put a list of extensions here
- SDTrainerExtension, TextualInversionTrainer
+ SDTrainerExtension, TextualInversionTrainer, UITrainerExtension
]
diff --git a/jobs/process/BaseProcess.py b/jobs/process/BaseProcess.py
index f0644607..c58724c9 100644
--- a/jobs/process/BaseProcess.py
+++ b/jobs/process/BaseProcess.py
@@ -24,6 +24,9 @@ class BaseProcess(object):
self.performance_log_every = self.get_conf('performance_log_every', 0)
print(json.dumps(self.config, indent=4))
+
+ def on_error(self, e: Exception):
+ pass
def get_conf(self, key, default=None, required=False, as_type=None):
# split key by '.' and recursively get the value
diff --git a/jobs/process/BaseSDTrainProcess.py b/jobs/process/BaseSDTrainProcess.py
index e30ddae0..2482c26d 100644
--- a/jobs/process/BaseSDTrainProcess.py
+++ b/jobs/process/BaseSDTrainProcess.py
@@ -92,6 +92,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.step_num = 0
self.start_step = 0
self.epoch_num = 0
+ self.last_save_step = 0
# start at 1 so we can do a sample at the start
self.grad_accumulation_step = 1
# if true, then we do not do an optimizer step. We are accumulating gradients
@@ -439,6 +440,12 @@ class BaseSDTrainProcess(BaseTrainProcess):
def post_save_hook(self, save_path):
# override in subclass
pass
+
+ def done_hook(self):
+ pass
+
+ def end_step_hook(self):
+ pass
def save(self, step=None):
if not self.accelerator.is_main_process:
@@ -453,6 +460,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
step_num = ''
if step is not None:
+ self.last_save_step = step
# zeropad 9 digits
step_num = f"_{str(step).zfill(9)}"
@@ -648,6 +656,8 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.logger.start()
self.prepare_accelerator()
+ def sample_step_hook(self, img_num, total_imgs):
+ pass
def prepare_accelerator(self):
# set some config
@@ -722,6 +732,9 @@ class BaseSDTrainProcess(BaseTrainProcess):
def hook_train_loop(self, batch):
# return loss
return 0.0
+
+ def hook_after_sd_init_before_load(self):
+ pass
def get_latest_save_path(self, name=None, post=''):
if name == None:
@@ -1417,8 +1430,12 @@ class BaseSDTrainProcess(BaseTrainProcess):
custom_pipeline=self.custom_pipeline,
noise_scheduler=sampler,
)
+
+ self.hook_after_sd_init_before_load()
# run base sd process run
self.sd.load_model()
+
+ self.sd.add_after_sample_image_hook(self.sample_step_hook)
dtype = get_torch_dtype(self.train_config.dtype)
@@ -1812,6 +1829,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.sd)
flush()
+ self.last_save_step = self.step_num
### HOOK ###
self.hook_before_train_loop()
@@ -2091,6 +2109,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
# update various steps
self.step_num = step + 1
self.grad_accumulation_step += 1
+ self.end_step_hook()
###################################################################
@@ -2110,13 +2129,15 @@ class BaseSDTrainProcess(BaseTrainProcess):
self.logger.finish()
self.accelerator.end_training()
- if self.save_config.push_to_hub:
- if("HF_TOKEN" not in os.environ):
- interpreter_login(new_session=False, write_permission=True)
- self.push_to_hub(
- repo_id=self.save_config.hf_repo_id,
- private=self.save_config.hf_private
- )
+ if self.accelerator.is_main_process:
+ # push to hub
+ if self.save_config.push_to_hub:
+ if("HF_TOKEN" not in os.environ):
+ interpreter_login(new_session=False, write_permission=True)
+ self.push_to_hub(
+ repo_id=self.save_config.hf_repo_id,
+ private=self.save_config.hf_private
+ )
del (
self.sd,
unet,
@@ -2128,6 +2149,7 @@ class BaseSDTrainProcess(BaseTrainProcess):
)
flush()
+ self.done_hook()
def push_to_hub(
self,
diff --git a/requirements.txt b/requirements.txt
index 4040e760..abf9bc64 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -32,4 +32,5 @@ sentencepiece
huggingface_hub
peft
gradio
-python-slugify
\ No newline at end of file
+python-slugify
+sqlite3
\ No newline at end of file
diff --git a/run.py b/run.py
index 9a3e57fd..d4ccda2a 100644
--- a/run.py
+++ b/run.py
@@ -88,6 +88,10 @@ def main():
except Exception as e:
print_acc(f"Error running job: {e}")
jobs_failed += 1
+ try:
+ job.process[0].on_error(e)
+ except Exception as e2:
+ print_acc(f"Error running on_error: {e2}")
if not args.recover:
print_end_message(jobs_completed, jobs_failed)
raise e
diff --git a/toolkit/config_modules.py b/toolkit/config_modules.py
index dfffae7c..ee4b6e72 100644
--- a/toolkit/config_modules.py
+++ b/toolkit/config_modules.py
@@ -379,7 +379,8 @@ class TrainConfig:
self.do_prior_divergence = kwargs.get('do_prior_divergence', False)
ema_config: Union[Dict, None] = kwargs.get('ema_config', None)
- if ema_config is not None:
+ # if it is set explicitly to false, leave it false.
+ if ema_config is not None and ema_config.get('use_ema', None) is not None:
ema_config['use_ema'] = True
print(f"Using EMA")
else:
diff --git a/toolkit/lora_special.py b/toolkit/lora_special.py
index 27317be9..b37ed098 100644
--- a/toolkit/lora_special.py
+++ b/toolkit/lora_special.py
@@ -9,6 +9,7 @@ from typing import List, Optional, Dict, Type, Union
import torch
from diffusers import UNet2DConditionModel, PixArtTransformer2DModel, AuraFlowTransformer2DModel
from transformers import CLIPTextModel
+from toolkit.models.lokr import LokrModule
from .config_modules import NetworkConfig
from .lorm import count_parameters
diff --git a/toolkit/models/lokr.py b/toolkit/models/lokr.py
new file mode 100644
index 00000000..b736406e
--- /dev/null
+++ b/toolkit/models/lokr.py
@@ -0,0 +1,282 @@
+# based heavily on https://github.com/KohakuBlueleaf/LyCORIS/blob/eb460098187f752a5d66406d3affade6f0a07ece/lycoris/modules/lokr.py
+
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from toolkit.network_mixins import ToolkitModuleMixin
+
+from typing import TYPE_CHECKING, Union, List
+
+if TYPE_CHECKING:
+
+ from toolkit.lora_special import LoRASpecialNetwork
+
+# 4, build custom backward function
+# -
+
+
+def factorization(dimension: int, factor:int=-1) -> tuple[int, int]:
+ '''
+ return a tuple of two value of input dimension decomposed by the number closest to factor
+ second value is higher or equal than first value.
+
+ In LoRA with Kroneckor Product, first value is a value for weight scale.
+ secon value is a value for weight.
+
+ Becuase of non-commutative property, A⊗B ≠ B⊗A. Meaning of two matrices is slightly different.
+
+ examples)
+ factor
+ -1 2 4 8 16 ...
+ 127 -> 127, 1 127 -> 127, 1 127 -> 127, 1 127 -> 127, 1 127 -> 127, 1
+ 128 -> 16, 8 128 -> 64, 2 128 -> 32, 4 128 -> 16, 8 128 -> 16, 8
+ 250 -> 125, 2 250 -> 125, 2 250 -> 125, 2 250 -> 125, 2 250 -> 125, 2
+ 360 -> 45, 8 360 -> 180, 2 360 -> 90, 4 360 -> 45, 8 360 -> 45, 8
+ 512 -> 32, 16 512 -> 256, 2 512 -> 128, 4 512 -> 64, 8 512 -> 32, 16
+ 1024 -> 32, 32 1024 -> 512, 2 1024 -> 256, 4 1024 -> 128, 8 1024 -> 64, 16
+ '''
+
+ if factor > 0 and (dimension % factor) == 0:
+ m = factor
+ n = dimension // factor
+ return m, n
+ if factor == -1:
+ factor = dimension
+ m, n = 1, dimension
+ length = m + n
+ while m
+
+
+ Dashboard
+
+
+
+
+ Active Jobs
+
+ View All
+
+
+
+
+
+
+
+ Dataset: {datasetName}
+
+
+
+ Loading...
} + {status === 'error' &&Error fetching images
} + {status === 'success' && ( +
+ {imgList.length === 0 && refreshImageList(datasetName)}
+ />
+ ))}
+
+ )}
+ No images found
} + {imgList.map(img => ( +
+
+
+ Datasets
+
+
+
+
+
+
+
+
+
+
+
+
+ {job && (
+ Job: {job?.name}
+Loading...
} + {status === 'error' && job == null &&Error fetching job
} + {job && ( + <> + {pageKey === 'overview' &&
+ {pages.map(page => (
+
+ ))}
+
+
+ );
+}
diff --git a/ui/src/app/jobs/new/jobConfig.ts b/ui/src/app/jobs/new/jobConfig.ts
new file mode 100644
index 00000000..91b65540
--- /dev/null
+++ b/ui/src/app/jobs/new/jobConfig.ts
@@ -0,0 +1,101 @@
+import { JobConfig, DatasetConfig } from '@/types';
+
+export const defaultDatasetConfig: DatasetConfig = {
+ folder_path: '/path/to/images/folder',
+ mask_path: null,
+ mask_min_value: 0.1,
+ default_caption: '',
+ caption_ext: 'txt',
+ caption_dropout_rate: 0.05,
+ cache_latents_to_disk: false,
+ is_reg: false,
+ network_weight: 1,
+ resolution: [512, 768, 1024],
+};
+
+export const defaultJobConfig: JobConfig = {
+ job: 'extension',
+ config: {
+ name: 'my_first_flex_lora_v1',
+ process: [
+ {
+ type: 'ui_trainer',
+ training_folder: 'output',
+ sqlite_db_path: './aitk_db.db',
+ device: 'cuda:0',
+ trigger_word: null,
+ performance_log_every: 10,
+ network: {
+ type: 'lora',
+ linear: 16,
+ linear_alpha: 16,
+ },
+ save: {
+ dtype: 'bf16',
+ save_every: 250,
+ max_step_saves_to_keep: 4,
+ save_format: 'diffusers',
+ push_to_hub: false,
+ },
+ datasets: [
+ defaultDatasetConfig
+ ],
+ train: {
+ batch_size: 1,
+ bypass_guidance_embedding: true,
+ steps: 2000,
+ gradient_accumulation: 1,
+ train_unet: true,
+ train_text_encoder: false,
+ gradient_checkpointing: true,
+ noise_scheduler: 'flowmatch',
+ optimizer: 'adamw8bit',
+ timestep_type: 'sigmoid',
+ content_or_style: 'balanced',
+ optimizer_params: {
+ weight_decay: 1e-4
+ },
+ lr: 0.0001,
+ ema_config: {
+ use_ema: true,
+ ema_decay: 0.99,
+ },
+ dtype: 'bf16',
+ },
+ model: {
+ name_or_path: 'ostris/Flex.1-alpha',
+ is_flux: true,
+ quantize: true,
+ quantize_te: true
+ },
+ sample: {
+ sampler: 'flowmatch',
+ sample_every: 250,
+ width: 1024,
+ height: 1024,
+ prompts: [
+ 'woman with red hair, playing chess at the park, bomb going off in the background',
+ 'a woman holding a coffee cup, in a beanie, sitting at a cafe',
+ 'a horse is a DJ at a night club, fish eye lens, smoke machine, lazer lights, holding a martini',
+ 'a man showing off his cool new t shirt at the beach, a shark is jumping out of the water in the background',
+ 'a bear building a log cabin in the snow covered mountains',
+ 'woman playing the guitar, on stage, singing a song, laser lights, punk rocker',
+ 'hipster man with a beard, building a chair, in a wood shop',
+ 'photo of a man, white background, medium shot, modeling clothing, studio lighting, white backdrop',
+ "a man holding a sign that says, 'this is a sign'",
+ 'a bulldog, in a post apocalyptic world, with a shotgun, in a leather jacket, in a desert, with a motorcycle',
+ ],
+ neg: '',
+ seed: 42,
+ walk_seed: true,
+ guidance_scale: 4,
+ sample_steps: 25,
+ },
+ },
+ ],
+ },
+ meta: {
+ name: '[name]',
+ version: '1.0',
+ },
+};
diff --git a/ui/src/app/jobs/new/options.ts b/ui/src/app/jobs/new/options.ts
new file mode 100644
index 00000000..f856f21a
--- /dev/null
+++ b/ui/src/app/jobs/new/options.ts
@@ -0,0 +1,41 @@
+export interface Model {
+ name_or_path: string;
+ defaults?: { [key: string]: any };
+}
+
+export interface Option {
+ model: Model[];
+}
+
+export const options = {
+ model: [
+ {
+ name_or_path: 'ostris/Flex.1-alpha',
+ defaults: {
+ // default updates when [selected, unselected] in the UI
+ 'config.process[0].model.quantize': [true, false],
+ 'config.process[0].model.quantize_te': [true, false],
+ 'config.process[0].model.is_flux': [true, false],
+ 'config.process[0].train.bypass_guidance_embedding': [true, false],
+ },
+ },
+ {
+ name_or_path: 'black-forest-labs/FLUX.1-dev',
+ defaults: {
+ // default updates when [selected, unselected] in the UI
+ 'config.process[0].model.quantize': [true, false],
+ 'config.process[0].model.quantize_te': [true, false],
+ 'config.process[0].model.is_flux': [true, false],
+ },
+ },
+ {
+ name_or_path: 'Alpha-VLLM/Lumina-Image-2.0',
+ defaults: {
+ // default updates when [selected, unselected] in the UI
+ 'config.process[0].model.quantize': [false, false],
+ 'config.process[0].model.quantize_te': [true, false],
+ 'config.process[0].model.is_lumina2': [true, false],
+ },
+ },
+ ],
+} as Option;
diff --git a/ui/src/app/jobs/new/page.tsx b/ui/src/app/jobs/new/page.tsx
new file mode 100644
index 00000000..e539ef4f
--- /dev/null
+++ b/ui/src/app/jobs/new/page.tsx
@@ -0,0 +1,618 @@
+'use client';
+
+import { useEffect, useState } from 'react';
+import { useSearchParams, useRouter } from 'next/navigation';
+import { options } from './options';
+import { defaultJobConfig, defaultDatasetConfig } from './jobConfig';
+import { JobConfig } from '@/types';
+import { objectCopy } from '@/utils/basic';
+import { useNestedState } from '@/utils/hooks';
+import { TextInput, SelectInput, Checkbox, FormGroup, NumberInput } from '@/components/formInputs';
+import Card from '@/components/Card';
+import { X } from 'lucide-react';
+import useSettings from '@/hooks/useSettings';
+import useGPUInfo from '@/hooks/useGPUInfo';
+import useDatasetList from '@/hooks/useDatasetList';
+import path from 'path';
+import { TopBar, MainContent } from '@/components/layout';
+import { Button } from '@headlessui/react';
+import { FaChevronLeft } from 'react-icons/fa';
+
+export default function TrainingForm() {
+ const router = useRouter();
+ const searchParams = useSearchParams();
+ const runId = searchParams.get('id');
+ const [gpuIDs, setGpuIDs] = useState
+
+
+
+
+
+ {runId ? 'Edit Training Job' : 'New Training Job'}
+
+
+
+
+
+
+ Training Jobs
+
+
+ New Training Job
+
+
+
+
+ {children}
+
+
+
+
+
+ Settings
+{title}
} + {children ? children : null} +
+ {/* Square image container */}
+
+
+
+ {/* Text area below the image */}
+
+ {isVisible && (
+ }`}) + )}
+ {children &&
+ )}
+ {children &&
+
+ )}
+ {children && {children}
}
+
+
+
+
+ {isVisible && isCaptionLoaded && (
+