mirror of
https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
synced 2026-03-15 01:48:20 +00:00
Extensions and Scripts Categorization
98
Extensions-Generation.md
Normal file
98
Extensions-Generation.md
Normal file
@@ -0,0 +1,98 @@
|
||||
# Generation Extensions
|
||||
|
||||
## Latent Mirroring
|
||||
https://github.com/dfaker/SD-latent-mirroring
|
||||
|
||||
Applies mirroring and flips to the latent images to produce anything from subtle balanced compositions to perfect reflections
|
||||
|
||||

|
||||
|
||||
## seed travel
|
||||
https://github.com/yownas/seed_travel
|
||||
|
||||
Small script for AUTOMATIC1111/stable-diffusion-webui to create images that exists between seeds.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://github.com/ClashSAN/bloated-gifs/blob/main/seedtravel.gif" width="512" height="512" />
|
||||
</details>
|
||||
|
||||
## Detection Detailer
|
||||
https://github.com/dustysys/ddetailer
|
||||
|
||||
An object detection and auto-mask extension for Stable Diffusion web UI.
|
||||
|
||||
<img src="https://github.com/dustysys/ddetailer/raw/master/misc/ddetailer_example_3.gif"/>
|
||||
|
||||
## conditioning-highres-fix
|
||||
https://github.com/klimaleksus/stable-diffusion-webui-conditioning-highres-fix
|
||||
|
||||
This is Extension for rewriting Inpainting conditioning mask strength value relative to Denoising strength at runtime. This is useful for Inpainting models such as sd-v1-5-inpainting.ckpt
|
||||
|
||||

|
||||
|
||||
## multi-subject-render
|
||||
https://github.com/Extraltodeus/multi-subject-render
|
||||
|
||||
It is a depth aware extension that can help to create multiple complex subjects on a single image. It generates a background, then multiple foreground subjects, cuts their backgrounds after a depth analysis, paste them onto the background and finally does an img2img for a clean finish.
|
||||
|
||||

|
||||
|
||||
## depthmap2mask
|
||||
https://github.com/Extraltodeus/depthmap2mask
|
||||
|
||||
Create masks for img2img based on a depth estimation made by MiDaS.
|
||||
|
||||

|
||||
|
||||
## Save Intermediate Images
|
||||
https://github.com/AlUlkesh/sd_save_intermediate_images
|
||||
|
||||
Implements saving intermediate images, with more advanced features.
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
## Enhanced-img2img
|
||||
https://github.com/OedoSoldier/enhanced-img2img
|
||||
An extension with support for batched and better inpainting. See [readme](https://github.com/OedoSoldier/enhanced-img2img#usage) for more details.
|
||||

|
||||
|
||||
## Kohya-ss Additional Networks
|
||||
https://github.com/kohya-ss/sd-webui-additional-networks
|
||||
|
||||
Allows the Web UI to use networks (LoRA) trained by their scripts to generate images.
|
||||
|
||||
## Multiple hypernetworks
|
||||
https://github.com/antis0007/sd-webui-multiple-hypernetworks
|
||||
|
||||
Extension that allows the use of multiple hypernetworks at once
|
||||
|
||||

|
||||
|
||||
|
||||
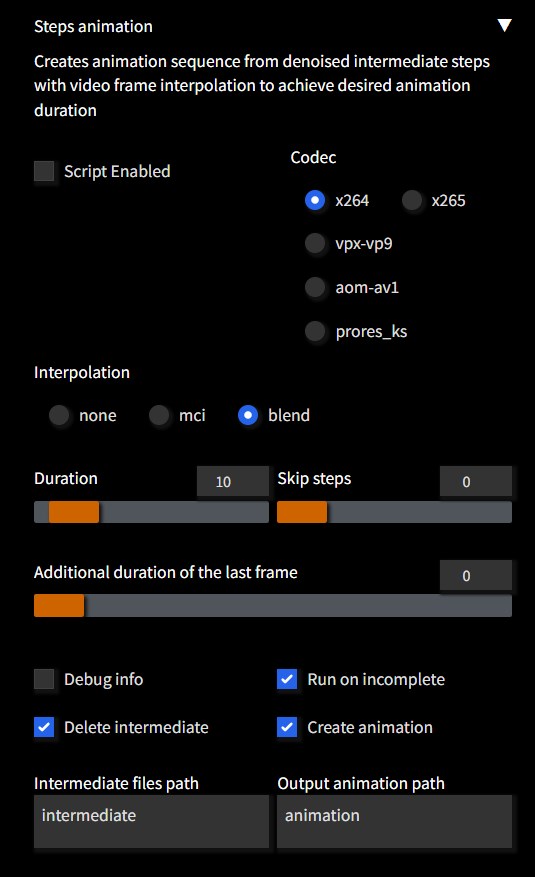
## Steps Animation
|
||||
https://github.com/vladmandic/sd-extension-steps-animation
|
||||
|
||||
Extension to create animation sequence from denoised intermediate steps
|
||||
Registers a script in **txt2img** and **img2img** tabs
|
||||
|
||||
Creating animation has minimum impact on overall performance as it does not require separate runs
|
||||
except adding overhead of saving each intermediate step as image plus few seconds to actually create movie file
|
||||
|
||||
Supports **color** and **motion** interpolation to achieve animation of desired duration from any number of interim steps
|
||||
Resulting movie fiels are typically very small (*~1MB being average*) due to optimized codec settings
|
||||
|
||||
|
||||
|
||||
### [Example](https://user-images.githubusercontent.com/57876960/212490617-f0444799-50e5-485e-bc5d-9c24a9146d38.mp4)
|
||||
|
||||
## Instruct-pix2pix
|
||||
https://github.com/Klace/stable-diffusion-webui-instruct-pix2pix
|
||||
|
||||
Adds a tab for doing img2img editing with the instruct-pix2pix model.
|
||||
|
||||
## anti-burn
|
||||
https://github.com/klimaleksus/stable-diffusion-webui-anti-burn
|
||||
|
||||
Smoothing generated images by skipping a few very last steps and averaging together some images before them
|
||||
163
Extensions-Integration.md
Normal file
163
Extensions-Integration.md
Normal file
@@ -0,0 +1,163 @@
|
||||
# Integration Extensions
|
||||
|
||||
## auto-sd-paint-ext
|
||||
|
||||
https://github.com/Interpause/auto-sd-paint-ext
|
||||
>Extension for AUTOMATIC1111's webUI with Krita Plugin (other drawing studios soon?)
|
||||

|
||||
- Optimized workflow (txt2img, img2img, inpaint, upscale) & UI design.
|
||||
- Only drawing studio plugin that exposes the Script API.
|
||||
See https://github.com/Interpause/auto-sd-paint-ext/issues/41 for planned developments.
|
||||
See [CHANGELOG.md](https://github.com/Interpause/auto-sd-paint-ext/blob/main/CHANGELOG.md) for the full changelog.
|
||||
|
||||
## openOutpaint extension
|
||||
https://github.com/zero01101/openOutpaint-webUI-extension
|
||||
|
||||
A tab with the full openOutpaint UI. Run with the --api flag.
|
||||
|
||||

|
||||
|
||||
## DAAM
|
||||
https://github.com/kousw/stable-diffusion-webui-daam
|
||||
|
||||
DAAM stands for Diffusion Attentive Attribution Maps. Enter the attention text (must be a string contained in the prompt) and run. An overlapping image with a heatmap for each attention will be generated along with the original image.
|
||||
|
||||

|
||||
|
||||
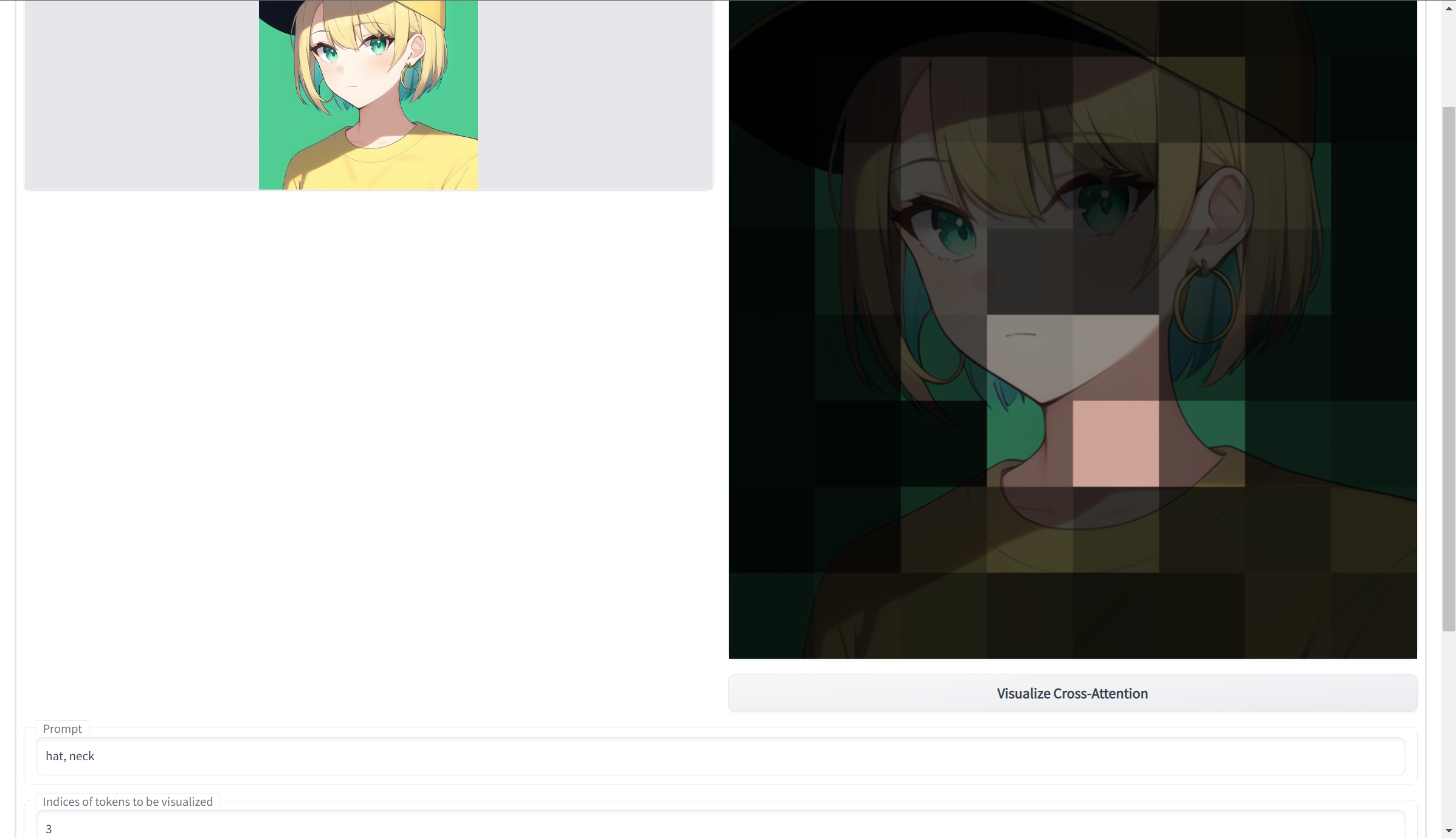
## Visualize Cross-Attention
|
||||
https://github.com/benkyoujouzu/stable-diffusion-webui-visualize-cross-attention-extension
|
||||
|
||||
|
||||
|
||||
Generates highlighted sectors of a submitted input image, based on input prompts. Use with tokenizer extension. See the readme for more info.
|
||||
|
||||
## Deforum
|
||||
https://github.com/deforum-art/deforum-for-automatic1111-webui
|
||||
|
||||
|
||||
The official port of Deforum, an extensive script for 2D and 3D animations, supporting keyframable sequences, dynamic math parameters (even inside the prompts), dynamic masking, depth estimation and warping.
|
||||
|
||||

|
||||
|
||||
## Push to 🤗 Hugging Face
|
||||
|
||||
https://github.com/camenduru/stable-diffusion-webui-huggingface
|
||||
|
||||

|
||||
|
||||
To install it, clone the repo into the `extensions` directory and restart the web ui:
|
||||
|
||||
`git clone https://github.com/camenduru/stable-diffusion-webui-huggingface`
|
||||
|
||||
`pip install huggingface-hub`
|
||||
|
||||
## Auto TLS-HTTPS
|
||||
https://github.com/papuSpartan/stable-diffusion-webui-auto-tls-https
|
||||
|
||||
Allows you to easily, or even completely automatically start using HTTPS.
|
||||
|
||||
## NSFW checker
|
||||
https://github.com/AUTOMATIC1111/stable-diffusion-webui-nsfw-censor
|
||||
|
||||
Replaces NSFW images with black.
|
||||
|
||||
## DH Patch
|
||||
https://github.com/d8ahazard/sd_auto_fix
|
||||
|
||||
Random patches by D8ahazard. Auto-load config YAML files for v2, 2.1 models; patch latent-diffusion to fix attention on 2.1 models (black boxes without no-half), whatever else I come up with.
|
||||
|
||||
## Stable Horde
|
||||
|
||||
### Stable Horde Client
|
||||
https://github.com/natanjunges/stable-diffusion-webui-stable-horde
|
||||
|
||||
Generate pictures using other user's PC. You should be able to recieve images from the stable horde with anonymous `0000000000` api key, however it is recommended to get your own - https://stablehorde.net/register
|
||||
|
||||
Note: Retrieving Images may take 2 minutes or more, especially if you have no kudos.
|
||||
|
||||
## Stable Horde Worker
|
||||
https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker
|
||||
|
||||
An unofficial [Stable Horde](https://stablehorde.net/) worker bridge as a [Stable Diffusion WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) extension.
|
||||
|
||||
### Features
|
||||
|
||||
**This extension is still WORKING IN PROGRESS**, and is not ready for production use.
|
||||
|
||||
- Get jobs from Stable Horde, generate images and submit generations
|
||||
- Configurable interval between every jobs
|
||||
- Enable and disable extension whenever
|
||||
- Detect current model and fetch corresponding jobs on the fly
|
||||
- Show generation images in the Stable Diffusion WebUI
|
||||
- Save generation images with png info text to local
|
||||
|
||||
### Install
|
||||
|
||||
- Run the following command in the root directory of your Stable Diffusion WebUI installation:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker.git extensions/stable-horde-worker
|
||||
```
|
||||
|
||||
- Launch the Stable Diffusion WebUI, You would see the `Stable Horde Worker` tab page.
|
||||
|
||||

|
||||
|
||||
- Register an account on [Stable Horde](https://stablehorde.net/) and get your `API key` if you don't have one.
|
||||
|
||||
**Note**: the default anonymous key `00000000` is not working for a worker, you need to register an account and get your own key.
|
||||
|
||||
- Setup your `API key` here.
|
||||
- Setup `Worker name` here with a proper name.
|
||||
- Make sure `Enable` is checked.
|
||||
- Click the `Apply settings` buttons.
|
||||
|
||||
## Discord Rich Presence
|
||||
https://github.com/kabachuha/discord-rpc-for-automatic1111-webui
|
||||
|
||||
Provides connection to Discord RPC, showing a fancy table in the user profile.
|
||||
|
||||
## Aesthetic Image Scorer
|
||||
https://github.com/tsngo/stable-diffusion-webui-aesthetic-image-scorer
|
||||
|
||||
Extension for https://github.com/AUTOMATIC1111/stable-diffusion-webui
|
||||
|
||||
Calculates aesthetic score for generated images using [CLIP+MLP Aesthetic Score Predictor](https://github.com/christophschuhmann/improved-aesthetic-predictor) based on [Chad Scorer](https://github.com/grexzen/SD-Chad/blob/main/chad_scorer.py)
|
||||
|
||||
See [Discussions](https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/1831)
|
||||
|
||||
Saves score to windows tags with other options planned
|
||||
|
||||

|
||||
|
||||
|
||||
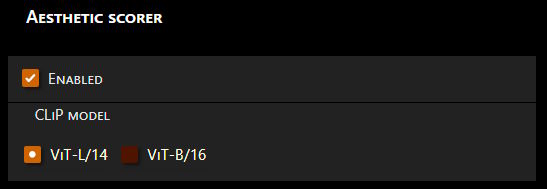
## Aesthetic Scorer
|
||||
https://github.com/vladmandic/sd-extension-aesthetic-scorer
|
||||
|
||||
Uses existing CLiP model with an additional small pretrained to calculate perceived aesthetic score of an image
|
||||
|
||||
Enable or disable via `Settings` -> `Aesthetic scorer`
|
||||
|
||||
This is an *"invisible"* extension, it runs in the background before any image save and
|
||||
appends **`score`** as *PNG info section* and/or *EXIF comments* field
|
||||
|
||||
### Notes
|
||||
|
||||
- Configuration via **Settings** → **Aesthetic scorer**
|
||||
|
||||
- Extension obeys existing **Move VAE and CLiP to RAM** settings
|
||||
- Models will be auto-downloaded upon first usage (small)
|
||||
- Score values are `0..10`
|
||||
- Supports both `CLiP-ViT-L/14` and `CLiP-ViT-B/16`
|
||||
- Cross-platform!
|
||||
|
||||
## cafe-aesthetic
|
||||
https://github.com/p1atdev/stable-diffusion-webui-cafe-aesthetic
|
||||
|
||||
Pre-trained model, determines if aesthetic/non-aesthetic, does 5 different style recognition modes, and Waifu confirmation. Also has a tab with Batch processing.
|
||||
|
||||
## Stable Diffusion Aesthetic Scorer
|
||||
https://github.com/grexzen/SD-Chad
|
||||
|
||||
Rates your images.
|
||||
|
||||
80
Extensions-Post-Processing.md
Normal file
80
Extensions-Post-Processing.md
Normal file
@@ -0,0 +1,80 @@
|
||||
# Post-Processing Extensions
|
||||
|
||||
## Smart Process
|
||||
https://github.com/d8ahazard/sd_smartprocess
|
||||
|
||||
Intelligent cropping, captioning, and image enhancement.
|
||||
|
||||

|
||||
|
||||
## Depth Maps
|
||||
https://github.com/thygate/stable-diffusion-webui-depthmap-script
|
||||
|
||||
Creates depthmaps from the generated images. The result can be viewed on 3D or holographic devices like VR headsets or lookingglass display, used in Render or Game- Engines on a plane with a displacement modifier, and maybe even 3D printed.
|
||||
|
||||

|
||||
|
||||
## ABG_extension
|
||||
https://github.com/KutsuyaYuki/ABG_extension
|
||||
|
||||
Automatically remove backgrounds. Uses an onnx model fine-tuned for anime images. Runs on GPU.
|
||||
|
||||
|  |  |  |  |
|
||||
| :---: | :---: | :---: | :---: |
|
||||
|  |  |  |  |
|
||||
|
||||
## Ultimate SD Upscaler
|
||||
https://github.com/Coyote-A/ultimate-upscale-for-automatic1111
|
||||
|
||||
More advanced options for SD Upscale, less artifacts than original using higher denoise ratio (0.3-0.5).
|
||||
|
||||
## Add image number to grid
|
||||
https://github.com/AlUlkesh/sd_grid_add_image_number
|
||||
|
||||
Add the image's number to its picture in the grid.
|
||||
|
||||
## haku-img
|
||||
https://github.com/KohakuBlueleaf/a1111-sd-webui-haku-img
|
||||
|
||||
Image utils extension. Allows blending, layering, hue and color adjustments, blurring and sketch effects, and basic pixelization.
|
||||
|
||||
## Pixelization
|
||||
https://github.com/AUTOMATIC1111/stable-diffusion-webui-pixelization
|
||||
|
||||
Using pre-trained models, produce pixel art out of images in the extras tab.
|
||||
|
||||
|
||||
## Txt2VectorGraphics
|
||||
https://github.com/GeorgLegato/Txt2Vectorgraphics
|
||||
|
||||
Create custom, scaleable icons from your prompts as SVG or PDF.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
|
||||
| prompt |PNG |SVG |
|
||||
| :-------- | :-----------------: | :---------------------: |
|
||||
| Happy Einstein | <img src="https://user-images.githubusercontent.com/7210708/193370360-506eb6b5-4fa7-4b2a-9fec-6430f6d027f5.png" width="40%" /> | <img src="https://user-images.githubusercontent.com/7210708/193370379-2680aa2a-f460-44e7-9c4e-592cf096de71.svg" width=30%/> |
|
||||
| Mountainbike Downhill | <img src="https://user-images.githubusercontent.com/7210708/193371353-f0f5ff6f-12f7-423b-a481-f9bd119631dd.png" width=40%/> | <img src="https://user-images.githubusercontent.com/7210708/193371585-68dea4ca-6c1a-4d31-965d-c1b5f145bb6f.svg" width=30%/> |
|
||||
coffe mug in shape of a heart | <img src="https://user-images.githubusercontent.com/7210708/193374299-98379ca1-3106-4ceb-bcd3-fa129e30817a.png" width=40%/> | <img src="https://user-images.githubusercontent.com/7210708/193374525-460395af-9588-476e-bcf6-6a8ad426be8e.svg" width=30%/> |
|
||||
| Headphones | <img src="https://user-images.githubusercontent.com/7210708/193376238-5c4d4a8f-1f06-4ba4-b780-d2fa2e794eda.png" width=40%/> | <img src="https://user-images.githubusercontent.com/7210708/193376255-80e25271-6313-4bff-a98e-ba3ae48538ca.svg" width=30%/> |
|
||||
|
||||
</details>
|
||||
|
||||
## Pixel Art
|
||||
https://github.com/C10udburst/stable-diffusion-webui-scripts
|
||||
|
||||
Simple script which resizes images by a variable amount, also converts image to use a color palette of a given size.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
|
||||
| Disabled | Enabled x8, no resize back, no color palette | Enabled x8, no color palette | Enabled x8, 16 color palette |
|
||||
| :---: | :---: | :---: | :---: |
|
||||
| |  |  |  |
|
||||
|
||||
[model used](https://publicprompts.art/all-in-one-pixel-art-dreambooth-model/)
|
||||
```text
|
||||
japanese pagoda with blossoming cherry trees, full body game asset, in pixelsprite style
|
||||
Steps: 20, Sampler: DDIM, CFG scale: 7, Seed: 4288895889, Size: 512x512, Model hash: 916ea38c, Batch size: 4
|
||||
```
|
||||
|
||||
</details>
|
||||
172
Extensions-Prompt.md
Normal file
172
Extensions-Prompt.md
Normal file
@@ -0,0 +1,172 @@
|
||||
# Prompt / Generation parameters Extensions
|
||||
|
||||
## Wildcards
|
||||
https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards
|
||||
|
||||
Allows you to use `__name__` syntax in your prompt to get a random line from a file named `name.txt` in the wildcards directory.
|
||||
|
||||
## Dynamic Prompts
|
||||
https://github.com/adieyal/sd-dynamic-prompts
|
||||
|
||||
A custom extension for [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) that implements an expressive template language for random or combinatorial prompt generation along with features to support deep wildcard directory structures.
|
||||
|
||||
More features and additions are shown in the [readme](https://github.com/adieyal/sd-dynamic-prompts).
|
||||
|
||||

|
||||
|
||||
Using this extension, the prompt:
|
||||
|
||||
`A {house|apartment|lodge|cottage} in {summer|winter|autumn|spring} by {2$$artist1|artist2|artist3}`
|
||||
|
||||
Will any of the following prompts:
|
||||
|
||||
- A house in summer by artist1, artist2
|
||||
- A lodge in autumn by artist3, artist1
|
||||
- A cottage in winter by artist2, artist3
|
||||
- ...
|
||||
|
||||
This is especially useful if you are searching for interesting combinations of artists and styles.
|
||||
|
||||
You can also pick a random string from a file. Assuming you have the file seasons.txt in WILDCARD_DIR (see below), then:
|
||||
|
||||
`__seasons__ is coming`
|
||||
|
||||
Might generate the following:
|
||||
|
||||
- Winter is coming
|
||||
- Spring is coming
|
||||
- ...
|
||||
|
||||
You can also use the same wildcard twice
|
||||
|
||||
`I love __seasons__ better than __seasons__`
|
||||
|
||||
- I love Winter better than Summer
|
||||
- I love Spring better than Spring
|
||||
|
||||
## Unprompted
|
||||
https://github.com/ThereforeGames/unprompted
|
||||
|
||||
Supercharge your prompt workflow with this powerful scripting language!
|
||||
|
||||

|
||||
|
||||
**Unprompted** is a highly modular extension for [AUTOMATIC1111's Stable Diffusion Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) that allows you to include various shortcodes in your prompts. You can pull text from files, set up your own variables, process text through conditional functions, and so much more - it's like wildcards on steroids.
|
||||
|
||||
While the intended usecase is Stable Diffusion, **this engine is also flexible enough to serve as an all-purpose text generator.**
|
||||
|
||||
## Booru tag autocompletion
|
||||
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
|
||||
Displays autocompletion hints for tags from "image booru" boards such as Danbooru. Uses local tag CSV files and includes a config for customization.
|
||||
|
||||

|
||||
|
||||
## novelai-2-local-prompt
|
||||
https://github.com/animerl/novelai-2-local-prompt
|
||||
|
||||
Add a button to convert the prompts used in NovelAI for use in the WebUI. In addition, add a button that allows you to recall a previously used prompt.
|
||||
|
||||

|
||||
|
||||
## StylePile
|
||||
https://github.com/some9000/StylePile
|
||||
|
||||
An easy way to mix and match elements to prompts that affect the style of the result.
|
||||
|
||||

|
||||
|
||||
## shift-attention
|
||||
https://github.com/yownas/shift-attention
|
||||
|
||||
Generate a sequence of images shifting attention in the prompt. This script enables you to give a range to the weight of tokens in a prompt and then generate a sequence of images stepping from the first one to the second.
|
||||
|
||||
https://user-images.githubusercontent.com/13150150/193368939-c0a57440-1955-417c-898a-ccd102e207a5.mp4
|
||||
|
||||
## prompt travel
|
||||
https://github.com/Kahsolt/stable-diffusion-webui-prompt-travel
|
||||
|
||||
Extension script for AUTOMATIC1111/stable-diffusion-webui to travel between prompts in latent space.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://github.com/ClashSAN/bloated-gifs/blob/main/prompt_travel.gif" width="512" height="512" />
|
||||
</details>
|
||||
|
||||
## Sonar
|
||||
https://github.com/Kahsolt/stable-diffusion-webui-sonar
|
||||
|
||||
Improve the generated image quality, searches for similar (yet even better!) images in the neighborhood of some known image, focuses on single prompt optimization rather than traveling between multiple prompts.
|
||||
|
||||

|
||||
|
||||
## Randomize
|
||||
~~https://github.com/stysmmaker/stable-diffusion-webui-randomize~~
|
||||
fork: https://github.com/innightwolfsleep/stable-diffusion-webui-randomize
|
||||
|
||||
Allows for random parameters during txt2img generation. This script is processed for all generations, regardless of the script selected, meaning this script will function with others as well, such as AUTOMATIC1111/stable-diffusion-webui-wildcards.
|
||||
|
||||
## booru2prompt
|
||||
https://github.com/Malisius/booru2prompt
|
||||
|
||||
This SD extension allows you to turn posts from various image boorus into stable diffusion prompts. It does so by pulling a list of tags down from their API. You can copy-paste in a link to the post you want yourself, or use the built-in search feature to do it all without leaving SD.
|
||||
|
||||

|
||||
|
||||
also see:\
|
||||
https://github.com/stysmmaker/stable-diffusion-webui-booru-prompt
|
||||
|
||||
## gelbooru-prompt
|
||||
https://github.com/antis0007/sd-webui-gelbooru-prompt
|
||||
|
||||
Fetch tags using your image's hash.
|
||||
|
||||
## Infinity Grid Generator
|
||||
https://github.com/mcmonkeyprojects/sd-infinity-grid-generator-script
|
||||
|
||||
Build a yaml file with your chosen parameters, and generate infinite-dimensional grids. Built-in ability to add description text to fields. See readme for usage details.
|
||||
|
||||

|
||||
|
||||
## Diffusion Defender
|
||||
https://github.com/WildBanjos/DiffusionDefender
|
||||
|
||||
Prompt blacklist, find and replace, for semi-private and public instances.
|
||||
|
||||
## Config-Presets
|
||||
https://github.com/Zyin055/Config-Presets
|
||||
|
||||
Adds a configurable dropdown to allow you to change UI preset settings in the txt2img and img2img tabs.
|
||||
|
||||

|
||||
|
||||
## Riffusion
|
||||
https://github.com/enlyth/sd-webui-riffusion
|
||||
|
||||
Use Riffusion model to produce music in gradio. To replicate [original](https://www.riffusion.com/about) interpolation technique, input the [prompt travel extension](https://github.com/Kahsolt/stable-diffusion-webui-prompt-travel) output frames into the riffusion tab.
|
||||
|
||||

|
||||
|
||||
## model-keyword
|
||||
https://github.com/mix1009/model-keyword
|
||||
|
||||
Inserts matching keyword(s) to the prompt automatically. Update extension to get the latest model+keyword mappings.
|
||||
|
||||

|
||||
|
||||
## Prompt Generator
|
||||
https://github.com/imrayya/stable-diffusion-webui-Prompt_Generator
|
||||
|
||||
Adds a tab to the webui that allows the user to generate a prompt from a small base prompt. Based on [FredZhang7/distilgpt2-stable-diffusion-v2](https://huggingface.co/FredZhang7/distilgpt2-stable-diffusion-v2).
|
||||
|
||||

|
||||
|
||||
## Promptgen
|
||||
https://github.com/AUTOMATIC1111/stable-diffusion-webui-promptgen
|
||||
|
||||
Use transformers models to generate prompts.
|
||||
|
||||
## Fusion
|
||||
https://github.com/ljleb/prompt-fusion-extension
|
||||
|
||||
Adds prompt-travel and shift-attention-like interpolations (see exts), but during/within the sampling steps. Always-on + works w/ existing prompt-editing syntax. Various interpolation modes. See their wiki for more info.
|
||||
|
||||
114
Extensions-Training.md
Normal file
114
Extensions-Training.md
Normal file
@@ -0,0 +1,114 @@
|
||||
# Training Extensions
|
||||
|
||||
## Aesthetic Gradients
|
||||
https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
|
||||
|
||||
Create an embedding from one or few pictures and use it to apply their style to generated images.
|
||||
|
||||

|
||||
|
||||
|
||||
## Dreambooth
|
||||
https://github.com/d8ahazard/sd_dreambooth_extension
|
||||
|
||||
Dreambooth in the UI. Refer to the project readme for tuning and configuration requirements. Includes [LoRA](https://github.com/cloneofsimo/lora) (Low Rank Adaptation)
|
||||
|
||||
Based on ShivamShiaro's repo.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Dataset Tag Editor
|
||||
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
|
||||
|
||||
[日本語 Readme](https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor/blob/main/README-JP.md)
|
||||
|
||||
This is an extension to edit captions in training dataset for [Stable Diffusion web UI by AUTOMATIC1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui).
|
||||
|
||||
It works well with text captions in comma-separated style (such as the tags generated by DeepBooru interrogator).
|
||||
|
||||
Caption in the filenames of images can be loaded, but edited captions can only be saved in the form of text files.
|
||||
|
||||

|
||||
|
||||
## training-picker
|
||||
https://github.com/Maurdekye/training-picker
|
||||
|
||||
Adds a tab to the webui that allows the user to automatically extract keyframes from video, and manually extract 512x512 crops of those frames for use in model training.
|
||||
|
||||

|
||||
|
||||
**Installation**
|
||||
|
||||
- Install [AUTOMATIC1111's Stable Diffusion Webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||
- Install [ffmpeg](https://ffmpeg.org/) for your operating system
|
||||
- Clone this repository into the extensions folder inside the webui
|
||||
- Drop videos you want to extract cropped frames from into the training-picker/videos folder
|
||||
|
||||
## Embeddings editor
|
||||
https://github.com/CodeExplode/stable-diffusion-webui-embedding-editor
|
||||
|
||||
Allows you to manually edit textual inversion embeddings using sliders.
|
||||
|
||||

|
||||
|
||||
## DreamArtist
|
||||
https://github.com/7eu7d7/DreamArtist-sd-webui-extension
|
||||
|
||||
Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning.
|
||||
|
||||

|
||||
|
||||
## WD 1.4 Tagger
|
||||
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
|
||||
|
||||
Uses a trained model file, produces WD 1.4 Tags. Model link - https://mega.nz/file/ptA2jSSB#G4INKHQG2x2pGAVQBn-yd_U5dMgevGF8YYM9CR_R1SY
|
||||
|
||||

|
||||
|
||||
## Merge Board
|
||||
https://github.com/bbc-mc/sdweb-merge-board
|
||||
|
||||
Multiple lane merge support(up to 10). Save and Load your merging combination as Recipes, which is simple text.
|
||||
|
||||

|
||||
|
||||
also see:\
|
||||
https://github.com/Maurdekye/model-kitchen
|
||||
|
||||
## embedding-inspector
|
||||
https://github.com/tkalayci71/embedding-inspector
|
||||
|
||||
Inspect any token(a word) or Textual-Inversion embeddings and find out which embeddings are similar. You can mix, modify, or create the embeddings in seconds. Much more intriguing options have since been released, see [here.](https://github.com/tkalayci71/embedding-inspector#whats-new)
|
||||
|
||||

|
||||
|
||||
## Model Converter
|
||||
https://github.com/Akegarasu/sd-webui-model-converter
|
||||
|
||||
Model convert extension, supports convert fp16/bf16 no-ema/ema-only safetensors.
|
||||
|
||||
## Hypernetwork-Monkeypatch-Extension
|
||||
https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension
|
||||
|
||||
Extension that provides additional training features for hypernetwork training, and supports multiple hypernetworks.
|
||||
|
||||

|
||||
|
||||
## Merge Block Weighted
|
||||
https://github.com/bbc-mc/sdweb-merge-block-weighted-gui
|
||||
|
||||
Merge models with separate rate for each 25 U-Net block (input, middle, output).
|
||||
|
||||
## Custom Diffusion
|
||||
https://github.com/guaneec/custom-diffusion-webui
|
||||
|
||||
Custom Diffusion is, in short, finetuning-lite with TI, instead of tuning the whole model. Similar speed and memory requirements to TI and supposedly gives better results in less steps.
|
||||
|
||||
## Embedding Merge
|
||||
https://github.com/klimaleksus/stable-diffusion-webui-embedding-merge
|
||||
|
||||
Merging Textual Inversion embeddings at runtime from string literals.
|
||||
|
||||
82
Extensions-UI.md
Normal file
82
Extensions-UI.md
Normal file
@@ -0,0 +1,82 @@
|
||||
# UI Extensions
|
||||
|
||||
## Image Browser
|
||||
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
|
||||
|
||||
Provides an interface to browse created images in the web browser, allows for sorting and filtering by EXIF data.
|
||||
|
||||

|
||||
|
||||
## Inspiration
|
||||
https://github.com/yfszzx/stable-diffusion-webui-inspiration
|
||||
|
||||
Randomly display the pictures of the artist's or artistic genres typical style, more pictures of this artist or genre is displayed after selecting. So you don't have to worry about how hard it is to choose the right style of art when you create.
|
||||
|
||||

|
||||
|
||||
## Artists to study
|
||||
https://github.com/camenduru/stable-diffusion-webui-artists-to-study
|
||||
|
||||
https://artiststostudy.pages.dev/ adapted to an extension for [web ui](https://github.com/AUTOMATIC1111/stable-diffusion-webui).
|
||||
|
||||
To install it, clone the repo into the `extensions` directory and restart the web ui:
|
||||
|
||||
`git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study`
|
||||
|
||||
You can add the artist name to the clipboard by clicking on it. (thanks for the idea @gmaciocci)
|
||||
|
||||

|
||||
|
||||
## Tokenizer
|
||||
https://github.com/AUTOMATIC1111/stable-diffusion-webui-tokenizer
|
||||
|
||||
Adds a tab that lets you preview how CLIP model would tokenize your text.
|
||||
|
||||

|
||||
|
||||
## Prompt Gallery
|
||||
https://github.com/dr413677671/PromptGallery-stable-diffusion-webui
|
||||
|
||||
Build a yaml file filled with prompts of your character, hit generate, and quickly preview them by their word attributes and modifiers.
|
||||
|
||||

|
||||
|
||||
## Preset Utilities
|
||||
https://github.com/Gerschel/sd_web_ui_preset_utils
|
||||
|
||||
Preset tool for UI. Supports presets for some custom scripts.
|
||||
|
||||

|
||||
|
||||
## sd-model-preview
|
||||
https://github.com/Vetchems/sd-model-preview
|
||||
|
||||
Allows you to create a txt file and jpg/png's with the same name as your model and have this info easily displayed for later reference in webui.
|
||||
|
||||

|
||||
|
||||
## quick-css
|
||||
https://github.com/Gerschel/sd-web-ui-quickcss
|
||||
|
||||
Extension for quickly selecting and applying custom.css files, for customizing look and placement of elements in ui.
|
||||
|
||||

|
||||
|
||||
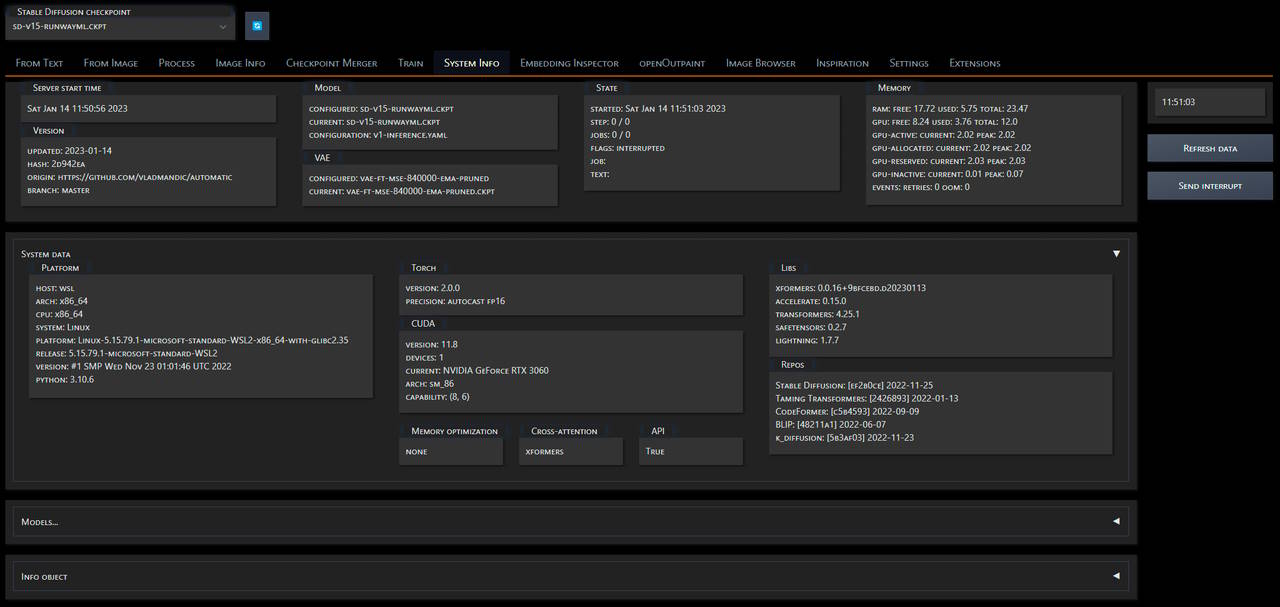
## System Info
|
||||
https://github.com/vladmandic/sd-extension-system-info
|
||||
|
||||
Creates a top-level **System Info** tab in Automatic WebUI with
|
||||
|
||||
*Note*:
|
||||
- State & memory info are auto-updated every second if tab is visible
|
||||
(no updates are performed when tab is not visible)
|
||||
- All other information is updated once upon WebUI load and
|
||||
can be force refreshed if required
|
||||
|
||||
|
||||
|
||||
## Catppuccin themes
|
||||
https://github.com/catppuccin/stable-diffusion-webui
|
||||
|
||||
Catppuccin is a community-driven pastel theme that aims to be the middle ground between low and high contrast themes. Adds set of themes which are in compliance with catppucin guidebook.
|
||||
|
||||
160
Scripts-Generation.md
Normal file
160
Scripts-Generation.md
Normal file
@@ -0,0 +1,160 @@
|
||||
# Generation Scripts
|
||||
|
||||
## txt2img2img
|
||||
https://github.com/ThereforeGames/txt2img2img
|
||||
|
||||
Greatly improve the editability of any character/subject while retaining their likeness. The main motivation for this script is improving the editability of embeddings created through [Textual Inversion](https://textual-inversion.github.io/).
|
||||
|
||||
(be careful with cloning as it has a bit of venv checked in)
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/98228077/200106431-21a22657-db24-4e9c-b7fa-e3a8e9096b89.png" width="624" height="312" />
|
||||
</details>
|
||||
|
||||
## txt2mask
|
||||
https://github.com/ThereforeGames/txt2mask
|
||||
|
||||
Allows you to specify an inpainting mask with text, as opposed to the brush.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/95403634/190878562-d020887c-ccb0-411c-ab37-38e2115552eb.png" width="674" height="312" />
|
||||
</details>
|
||||
|
||||
## Mask drawing UI
|
||||
https://github.com/dfaker/stable-diffusion-webui-cv2-external-masking-script
|
||||
|
||||
Provides a local popup window powered by CV2 that allows addition of a mask before processing.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/98228077/200109495-3d6741f1-0e25-4ae5-9f84-d93f886f302a.png" width="302" height="312" />
|
||||
</details>
|
||||
|
||||
## Img2img Video
|
||||
https://github.com/memes-forever/Stable-diffusion-webui-video
|
||||
|
||||
Using img2img, generates pictures one after another.
|
||||
|
||||
## Advanced Seed Blending
|
||||
https://github.com/amotile/stable-diffusion-backend/tree/master/src/process/implementations/automatic1111_scripts
|
||||
|
||||
This script allows you to base the initial noise on multiple weighted seeds.
|
||||
|
||||
Ex. `seed1:2, seed2:1, seed3:1`
|
||||
|
||||
The weights are normalized so you can use bigger once like above, or you can do floating point numbers:
|
||||
|
||||
Ex. `seed1:0.5, seed2:0.25, seed3:0.25`
|
||||
|
||||
## Prompt Blending
|
||||
https://github.com/amotile/stable-diffusion-backend/tree/master/src/process/implementations/automatic1111_scripts
|
||||
|
||||
This script allows you to combine multiple weighted prompts together by mathematically combining their textual embeddings before generating the image.
|
||||
|
||||
Ex.
|
||||
|
||||
`Crystal containing elemental {fire|ice}`
|
||||
|
||||
It supports nested definitions so you can do this as well:
|
||||
|
||||
`Crystal containing elemental {{fire:5|ice}|earth}`
|
||||
|
||||
## Animator
|
||||
https://github.com/Animator-Anon/Animator
|
||||
|
||||
A basic img2img script that will dump frames and build a video file. Suitable for creating interesting zoom in warping movies, but not too much else at this time.
|
||||
|
||||
## Alternate Noise Schedules
|
||||
https://gist.github.com/dfaker/f88aa62e3a14b559fe4e5f6b345db664
|
||||
|
||||
Uses alternate generators for the sampler's sigma schedule.
|
||||
|
||||
Allows access to Karras, Exponential and Variance Preserving schedules from crowsonkb/k-diffusion along with their parameters.
|
||||
|
||||
## Vid2Vid
|
||||
https://github.com/Filarius/stable-diffusion-webui/blob/master/scripts/vid2vid.py
|
||||
|
||||
From real video, img2img the frames and stitch them together. Does not unpack frames to hard drive.
|
||||
|
||||
## Force Symmetry
|
||||
https://gist.github.com/1ort/2fe6214cf1abe4c07087aac8d91d0d8a
|
||||
|
||||
see https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/2441
|
||||
|
||||
applies symmetry to the image every n steps and sends the result further to img2img.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/83316072/196016119-0a03664b-c3e4-49f0-81ac-a9e719b24bd1.png" width="624" height="312" />
|
||||
</details>
|
||||
|
||||
## txt2palette
|
||||
https://github.com/1ort/txt2palette
|
||||
|
||||
Generate palettes by text description. This script takes the generated images and converts them into color palettes.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/83316072/199360686-62f0f5ec-ed3d-4c0f-95b4-af9c67d1e248.png" width="352" height="312" />
|
||||
</details>
|
||||
|
||||
## img2tiles
|
||||
https://github.com/arcanite24/img2tiles
|
||||
|
||||
generate tiles from a base image. Based on SD upscale script.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://github.com/arcanite24/img2tiles/raw/master/examples/example5.png" width="312" height="312" />
|
||||
</details>
|
||||
|
||||
## img2mosiac
|
||||
https://github.com/1ort/img2mosaic
|
||||
|
||||
Generate mosaics from images. The script cuts the image into tiles and processes each tile separately. The size of each tile is chosen randomly.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/83316072/200170569-0e7131e4-1da8-4caf-9cd9-5b785c9d21b0.png" width="758" height="312" />
|
||||
</details>
|
||||
|
||||
## gif2gif
|
||||
https://github.com/LonicaMewinsky/gif2gif
|
||||
|
||||
The purpose of this script is to accept an animated gif as input, process frames as img2img typically would, and recombine them back into an animated gif. Not intended to have extensive functionality. Referenced code from prompts_from_file.
|
||||
|
||||
## Saving steps of the sampling process
|
||||
|
||||
This script will save steps of the sampling process to a directory.
|
||||
```python
|
||||
import os.path
|
||||
|
||||
import modules.scripts as scripts
|
||||
import gradio as gr
|
||||
|
||||
from modules import sd_samplers, shared
|
||||
from modules.processing import Processed, process_images
|
||||
|
||||
|
||||
class Script(scripts.Script):
|
||||
def title(self):
|
||||
return "Save steps of the sampling process to files"
|
||||
|
||||
def ui(self, is_img2img):
|
||||
path = gr.Textbox(label="Save images to path")
|
||||
return [path]
|
||||
|
||||
def run(self, p, path):
|
||||
index = [0]
|
||||
|
||||
def store_latent(x):
|
||||
image = shared.state.current_image = sd_samplers.sample_to_image(x)
|
||||
image.save(os.path.join(path, f"sample-{index[0]:05}.png"))
|
||||
index[0] += 1
|
||||
fun(x)
|
||||
|
||||
fun = sd_samplers.store_latent
|
||||
sd_samplers.store_latent = store_latent
|
||||
|
||||
try:
|
||||
proc = process_images(p)
|
||||
finally:
|
||||
sd_samplers.store_latent = fun
|
||||
|
||||
return Processed(p, proc.images, p.seed, "")
|
||||
```
|
||||
179
Scripts-Prompt.md
Normal file
179
Scripts-Prompt.md
Normal file
@@ -0,0 +1,179 @@
|
||||
# Prompt Scripts
|
||||
|
||||
## Improved prompt matrix
|
||||
https://github.com/ArrowM/auto1111-improved-prompt-matrix
|
||||
|
||||
This script is [advanced-prompt-matrix](https://github.com/GRMrGecko/stable-diffusion-webui-automatic/blob/advanced_matrix/scripts/advanced_prompt_matrix.py) modified to support `batch count`. Grids are not created.
|
||||
|
||||
**Usage:**
|
||||
|
||||
Use `<` `>` to create a group of alternate texts. Separate text options with `|`. Multiple groups and multiple options can be used. For example:
|
||||
|
||||
An input of `a <corgi|cat> wearing <goggles|a hat>`
|
||||
Will output 4 prompts: `a corgi wearing goggles`, `a corgi wearing a hat`, `a cat wearing goggles`, `a cat wearing a hat`
|
||||
|
||||
When using a `batch count` > 1, each prompt variation will be generated for each seed. `batch size` is ignored.
|
||||
|
||||
## Parameter Sequencer
|
||||
https://github.com/rewbs/sd-parseq
|
||||
|
||||
Generate videos with tight control and flexible interpolation over many Stable Diffusion parameters (such as seed, scale, prompt weights, denoising strength...), as well as input processing parameter (such as zoom, pan, 3D rotation...)
|
||||
|
||||
## Loopback and Superimpose
|
||||
https://github.com/DiceOwl/StableDiffusionStuff
|
||||
|
||||
https://github.com/DiceOwl/StableDiffusionStuff/blob/main/loopback_superimpose.py
|
||||
|
||||
Mixes output of img2img with original input image at strength alpha. The result is fed into img2img again (at loop>=2), and this procedure repeats. Tends to sharpen the image, improve consistency, reduce creativity and reduce fine detail.
|
||||
|
||||
## Interpolate
|
||||
https://github.com/DiceOwl/StableDiffusionStuff
|
||||
|
||||
https://github.com/DiceOwl/StableDiffusionStuff/blob/main/interpolate.py
|
||||
|
||||
An img2img script to produce in-between images. Allows two input images for interpolation. More features shown in the [readme](https://github.com/DiceOwl/StableDiffusionStuff).
|
||||
|
||||
## Run n times
|
||||
https://gist.github.com/camenduru/9ec5f8141db9902e375967e93250860f
|
||||
|
||||
Run n times with random seed.
|
||||
|
||||
## Advanced Loopback
|
||||
https://github.com/Extraltodeus/advanced-loopback-for-sd-webui
|
||||
|
||||
Dynamic zoom loopback with parameters variations and prompt switching amongst other features!
|
||||
|
||||
## prompt-morph
|
||||
https://github.com/feffy380/prompt-morph
|
||||
|
||||
Generate morph sequences with Stable Diffusion. Interpolate between two or more prompts and create an image at each step.
|
||||
|
||||
Uses the new AND keyword and can optionally export the sequence as a video.
|
||||
|
||||
## prompt interpolation
|
||||
https://github.com/EugeoSynthesisThirtyTwo/prompt-interpolation-script-for-sd-webui
|
||||
|
||||
With this script, you can interpolate between two prompts (using the "AND" keyword), generate as many images as you want.
|
||||
You can also generate a gif with the result. Works for both txt2img and img2img.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
## Asymmetric Tiling
|
||||
https://github.com/tjm35/asymmetric-tiling-sd-webui/
|
||||
|
||||
Control horizontal/vertical seamless tiling independently of each other.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/19196175/195132862-8c050327-92f3-44a4-9c02-0f11cce0b609.png" width="624" height="312" />
|
||||
</details>
|
||||
|
||||
|
||||
## XYZ Plot Script
|
||||
https://github.com/xrpgame/xyz_plot_script
|
||||
|
||||
Generates an .html file to interactively browse the imageset. Use the scroll wheel or arrow keys to move in the Z dimension.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://raw.githubusercontent.com/xrpgame/xyz_plot_script/master/example1.png" width="522" height="312" />
|
||||
</details>
|
||||
|
||||
## Expanded-XY-grid
|
||||
https://github.com/0xALIVEBEEF/Expanded-XY-grid
|
||||
|
||||
Custom script for AUTOMATIC1111's stable-diffusion-webui that adds more features to the standard xy grid:
|
||||
|
||||
- Multitool: Allows multiple parameters in one axis, theoretically allows unlimited parameters to be adjusted in one xy grid
|
||||
|
||||
- Customizable prompt matrix
|
||||
|
||||
- Group files in a directory
|
||||
|
||||
- S/R Placeholder - replace a placeholder value (the first value in the list of parameters) with desired values.
|
||||
|
||||
- Add PNGinfo to grid image
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/80003301/202277871-a4a3341b-13f7-42f4-a3e6-ca8f8cd8250a.png" width="574" height="197" />
|
||||
|
||||
Example images: Prompt: "darth vader riding a bicycle, modifier"; X: Multitool: "Prompt S/R: bicycle, motorcycle | CFG scale: 7.5, 10 | Prompt S/R Placeholder: modifier, 4k, artstation"; Y: Multitool: "Sampler: Euler, Euler a | Steps: 20, 50"
|
||||
|
||||
</details>
|
||||
|
||||
## Embedding to PNG
|
||||
https://github.com/dfaker/embedding-to-png-script
|
||||
|
||||
Converts existing embeddings to the shareable image versions.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/35278260/196052398-268a3a3e-0fad-46cd-b37d-9808480ceb18.png" width="263" height="256" />
|
||||
</details>
|
||||
|
||||
## Alpha Canvas
|
||||
https://github.com/TKoestlerx/sdexperiments
|
||||
|
||||
Outpaint a region. Infinite outpainting concept, used the two existing outpainting scripts from the AUTOMATIC1111 repo as a basis.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/86352149/199517938-3430170b-adca-487c-992b-eb89b3b63681.jpg" width="446" height="312" />
|
||||
</details>
|
||||
|
||||
## Random grid
|
||||
https://github.com/lilly1987/AI-WEBUI-scripts-Random
|
||||
|
||||
Randomly enter xy grid values.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/20321215/197346726-f93b7e84-f808-4167-9969-dc42763eeff1.png" width="198" height="312" />
|
||||
|
||||
Basic logic is same as x/y plot, only internally, x type is fixed as step, and type y is fixed as cfg.
|
||||
Generates x values as many as the number of step counts (10) within the range of step1|2 values (10-30)
|
||||
Generates x values as many as the number of cfg counts (10) within the range of cfg1|2 values (6-15)
|
||||
Even if you put the 1|2 range cap upside down, it will automatically change it.
|
||||
In the case of the cfg value, it is treated as an int type and the decimal value is not read.
|
||||
</details>
|
||||
|
||||
## Random
|
||||
https://github.com/lilly1987/AI-WEBUI-scripts-Random
|
||||
|
||||
Repeat a simple number of times without a grid.
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
<img src="https://user-images.githubusercontent.com/20321215/197346617-0ed1cd09-0ddd-48ad-8161-bc1540d628ad.png" width="258" height="312" />
|
||||
</details>
|
||||
|
||||
## Test my prompt
|
||||
https://github.com/Extraltodeus/test_my_prompt
|
||||
|
||||
Have you ever used a very long prompt full of words that you are not sure have any actual impact on your image? Did you lose the courage to try to remove them one by one to test if their effects are worthy of your pwescious GPU?
|
||||
|
||||
WELL now you don't need any courage as this script has been MADE FOR YOU!
|
||||
|
||||
It generates as many images as there are words in your prompt (you can select the separator of course).
|
||||
|
||||
<details><summary>Example: (Click to expand:)</summary>
|
||||
|
||||
Here the prompt is simply : "**banana, on fire, snow**" and so as you can see it has generated each image without each description in it.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/15731540/200349119-e45d3cfb-39f0-4999-a8f0-4671a6393824.png" width="512" height="512" />
|
||||
|
||||
You can also test your negative prompt.
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
## Scripts by FartyPants
|
||||
https://github.com/FartyPants/sd_web_ui_scripts
|
||||
|
||||
### Hallucinate
|
||||
|
||||
- swaps negative and positive prompts
|
||||
|
||||
### Mr. Negativity
|
||||
|
||||
- more advanced script that swaps negative and positive tokens depending on Mr. negativity rage
|
||||
|
||||
Reference in New Issue
Block a user