mirror of
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
synced 2026-04-25 08:48:54 +00:00
Update README_ZH.md
This commit is contained in:
24
README_ZH.md
24
README_ZH.md
@@ -124,24 +124,20 @@ git clone "https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git" extens
|
||||
|
||||
|
||||
|
||||
**重要的是**
|
||||
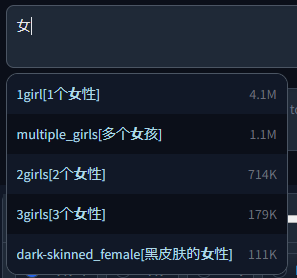
从最近的更新来看,用旧的Extra文件方式添加的翻译只能作为一个别名使用,如果输入该翻译的英文标签,将不再可见。
|
||||
#### Extra文件
|
||||
额外文件可以用来添加未包含在主集中的新的/自定义标签。
|
||||
其格式与下面 [CSV tag data](#csv-tag-data) 中的正常标签格式相同,但有一个例外。
|
||||
由于自定义标签没有帖子计数,第三列(如果从零开始计算,则为第二列)用于显示标签旁边的灰色元文本。
|
||||
如果留空,它将显示 "Custom tag"。
|
||||
|
||||
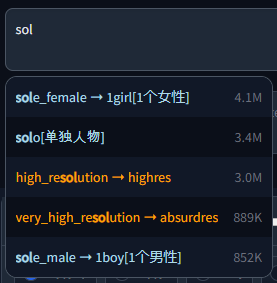
可以通过多种方式添加别名,这就是额外文件发挥作用的地方。
|
||||
1. 作为仅包含已翻译标签行的额外文件(因此仍包括英文标签名称和标签类型)。将根据名称和类型与主文件中的英文标签匹配,因此对于大型翻译文件可能会很慢。
|
||||
2. 作为 `onlyAliasExtraFile` 为 true 的额外文件。使用此配置,额外文件必须包含*仅*翻译本身。这意味着它完全基于索引,将翻译分配给主要标签非常快,但也需要匹配行(包括空行)。如果主文件中的顺序或数量发生变化,则翻译可能不再匹配。
|
||||
以默认的(非常基本的)extra-quality-tags.csv为例:
|
||||
|
||||
因此,对于每种方法,您的 CSV 值将如下所示:
|
||||
| | 1 | 2 |
|
||||
|------------|--------------------------|--------------------------|
|
||||
| Main file | `tag,type,count,(alias)` | `tag,type,count,(alias)` |
|
||||
| Extra file | `tag,type,(count),alias` | `alias` |
|
||||
|
||||
|
||||
额外文件中的计数是可选的,因为自定义标签集并不总是有帖子计数。
|
||||
如果额外的标签与任何现有标签都不匹配,它将作为新标签添加到列表中。
|
||||
你可以在设置中选择自定义标签是否应该加在常规标签之前或之后。
|
||||
|
||||
### CSV tag data
|
||||
本脚本的Tag文件格式如下,你可以安装这个格式制作自己的Tag文件:
|
||||
本脚本的Tag文件格式如下,你可以安装这个格式制作自己的Tag文件:
|
||||
```csv
|
||||
1girl,0,4114588,"1girls,sole_female"
|
||||
solo,0,3426446,"female_solo,solo_female"
|
||||
@@ -151,7 +147,7 @@ commentary_request,5,2610959,
|
||||
```
|
||||
值得注意的是,不希望在第一行有列名,而且count和aliases在技术上都是可选的。
|
||||
尽管count总是包含在默认数据中。多个别名也需要用逗号分隔,但要用字符串引号包裹,以免破坏CSV解析。
|
||||
编号系统遵循 Danbooru 的 [tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags):
|
||||
编号系统遵循 Danbooru 的 [tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags):
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|0 | General |
|
||||
|
||||
Reference in New Issue
Block a user