* [feat]: redesign kt run interactive configuration with i18n support - Redesign kt run with 8-step interactive flow (model selection, inference method, NUMA/CPU, GPU experts, KV cache, GPU/TP selection, parsers, host/port) - Add configuration save/load system (~/.ktransformers/run_configs.yaml) - Add i18n support for kt chat (en/zh translations) - Add universal input validators with auto-retry and Chinese comma support - Add port availability checker with auto-suggestion - Add parser configuration (--tool-call-parser, --reasoning-parser) - Remove tuna command and clean up redundant files - Fix: variable reference bug in run.py, filter to show only MoE models * [feat]: unify model selection UI and enable shared experts fusion by default - Unify kt run model selection table with kt model list display * Add Total size, MoE Size, Repo, and SHA256 status columns * Use consistent formatting and styling * Improve user decision-making with more information - Enable --disable-shared-experts-fusion by default * Change default value from False to True * Users can still override with --enable-shared-experts-fusion * [feat]: improve kt chat with performance metrics and better CJK support - Add performance metrics display after each response * Total time, TTFT (Time To First Token), TPOT (Time Per Output Token) * Accurate input/output token counts using model tokenizer * Fallback to estimation if tokenizer unavailable * Metrics shown in dim style (not prominent) - Fix Chinese character input issues * Replace Prompt.ask() with console.input() for better CJK support * Fixes backspace deletion showing half-characters - Suppress NumPy subnormal warnings * Filter "The value of the smallest subnormal" warnings * Cleaner CLI output on certain hardware environments * [fix]: correct TTFT measurement in kt chat - Move start_time initialization before API call - Previously start_time was set when receiving first chunk, causing TTFT ≈ 0ms - Now correctly measures time from request sent to first token received * [docs]: 添加 Clawdbot 集成指南 - KTransformers 企业级 AI 助手部署方案 * [docs]: 强调推荐使用 Kimi K2.5 作为核心模型,突出企业级推理能力 * [docs]: 添加 Clawdbot 飞书接入教程链接 * [feat]: improve CLI table display, model verification, and chat experience - Add sequence number (#) column to all model tables by default - Filter kt edit to show only MoE GPU models (exclude AMX) - Extend kt model verify to check *.json and *.py files in addition to weights - Fix re-verification bug where repaired files caused false failures - Suppress tokenizer debug output in kt chat token counting * [fix]: fix cpu cores. --------- Co-authored-by: skqliao <skqliao@gmail.com>
A Flexible Framework for Experiencing Cutting-edge LLM Inference/Fine-tune Optimizations
🎯 Overview | 🚀 kt-kernel | 🎓 kt-sft | 🔥 Citation | 🚀 Roadmap(2025Q4)🎯 Overview
KTransformers is a research project focused on efficient inference and fine-tuning of large language models through CPU-GPU heterogeneous computing. The project has evolved into two core modules: kt-kernel and kt-sft.
🔥 Updates
- Jan 27, 2026: Kimi-K2.5 Day0 Support! (Tutorial) (SFT Tutorial)
- Jan 22, 2026: Support CPU-GPU Expert Scheduling, Native BF16 and FP8 per channel Precision and AutoDL unified fine-tuning and inference
- Dec 24, 2025: Support Native MiniMax-M2.1 inference. (Tutorial)
- Dec 22, 2025: Support RL-DPO fine-tuning with LLaMA-Factory. (Tutorial)
- Dec 5, 2025: Support Native Kimi-K2-Thinking inference (Tutorial)
- Nov 6, 2025: Support Kimi-K2-Thinking inference (Tutorial) and fine-tune (Tutorial)
- Nov 4, 2025: KTransformers Fine-Tuning × LLaMA-Factory Integration. (Tutorial)
- Oct 27, 2025: Support Ascend NPU. (Tutorial)
- Oct 10, 2025: Integrating into SGLang. (Roadmap, Blog)
- Sept 11, 2025: Support Qwen3-Next. (Tutorial)
- Sept 05, 2025: Support Kimi-K2-0905. (Tutorial)
- July 26, 2025: Support SmallThinker and GLM4-MoE. (Tutorial)
- July 11, 2025: Support Kimi-K2. (Tutorial)
- June 30, 2025: Support 3-layer (GPU-CPU-Disk) prefix cache reuse.
- May 14, 2025: Support Intel Arc GPU (Tutorial).
- Apr 29, 2025: Support AMX-Int8、 AMX-BF16 and Qwen3MoE (Tutorial)
- Apr 9, 2025: Experimental support for LLaMA 4 models (Tutorial).
- Apr 2, 2025: Support Multi-concurrency. (Tutorial).
- Mar 15, 2025: Support ROCm on AMD GPU (Tutorial).
- Mar 5, 2025: Support unsloth 1.58/2.51 bits weights and IQ1_S/FP8 hybrid weights. Support 139K Longer Context for DeepSeek-V3 and R1 in 24GB VRAM.
- Feb 25, 2025: Support FP8 GPU kernel for DeepSeek-V3 and R1; Longer Context.
- Feb 15, 2025: Longer Context (from 4K to 8K for 24GB VRAM) & Slightly Faster Speed (+15%, up to 16 Tokens/s), update docs and online books.
- Feb 10, 2025: Support Deepseek-R1 and V3 on single (24GB VRAM)/multi gpu and 382G DRAM, up to 3~28x speedup. For detailed show case and reproduction tutorial, see here.
- Aug 28, 2024: Decrease DeepseekV2's required VRAM from 21G to 11G.
- Aug 15, 2024: Update detailed tutorial for injection and multi-GPU.
- Aug 14, 2024: Support llamfile as linear backend.
- Aug 12, 2024: Support multiple GPU; Support new model: mixtral 8*7B and 8*22B; Support q2k, q3k, q5k dequant on gpu.
- Aug 9, 2024: Support windows native.
📦 Core Modules
🚀 kt-kernel - High-Performance Inference Kernels
CPU-optimized kernel operations for heterogeneous LLM inference.
Key Features:
- AMX/AVX Acceleration: Intel AMX and AVX512/AVX2 optimized kernels for INT4/INT8 quantized inference
- MoE Optimization: Efficient Mixture-of-Experts inference with NUMA-aware memory management
- Quantization Support: CPU-side INT4/INT8 quantized weights, GPU-side GPTQ support
- Easy Integration: Clean Python API for SGLang and other frameworks
Quick Start:
cd kt-kernel
pip install .
Use Cases:
- CPU-GPU hybrid inference for large MoE models
- Integration with SGLang for production serving
- Heterogeneous expert placement (hot experts on GPU, cold experts on CPU)
Performance Examples:
| Model | Hardware Configuration | Total Throughput | Output Throughput |
|---|---|---|---|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s (8-way concurrency) |
🎓 kt-sft - Fine-Tuning Framework
KTransformers × LLaMA-Factory integration for ultra-large MoE model fine-tuning.
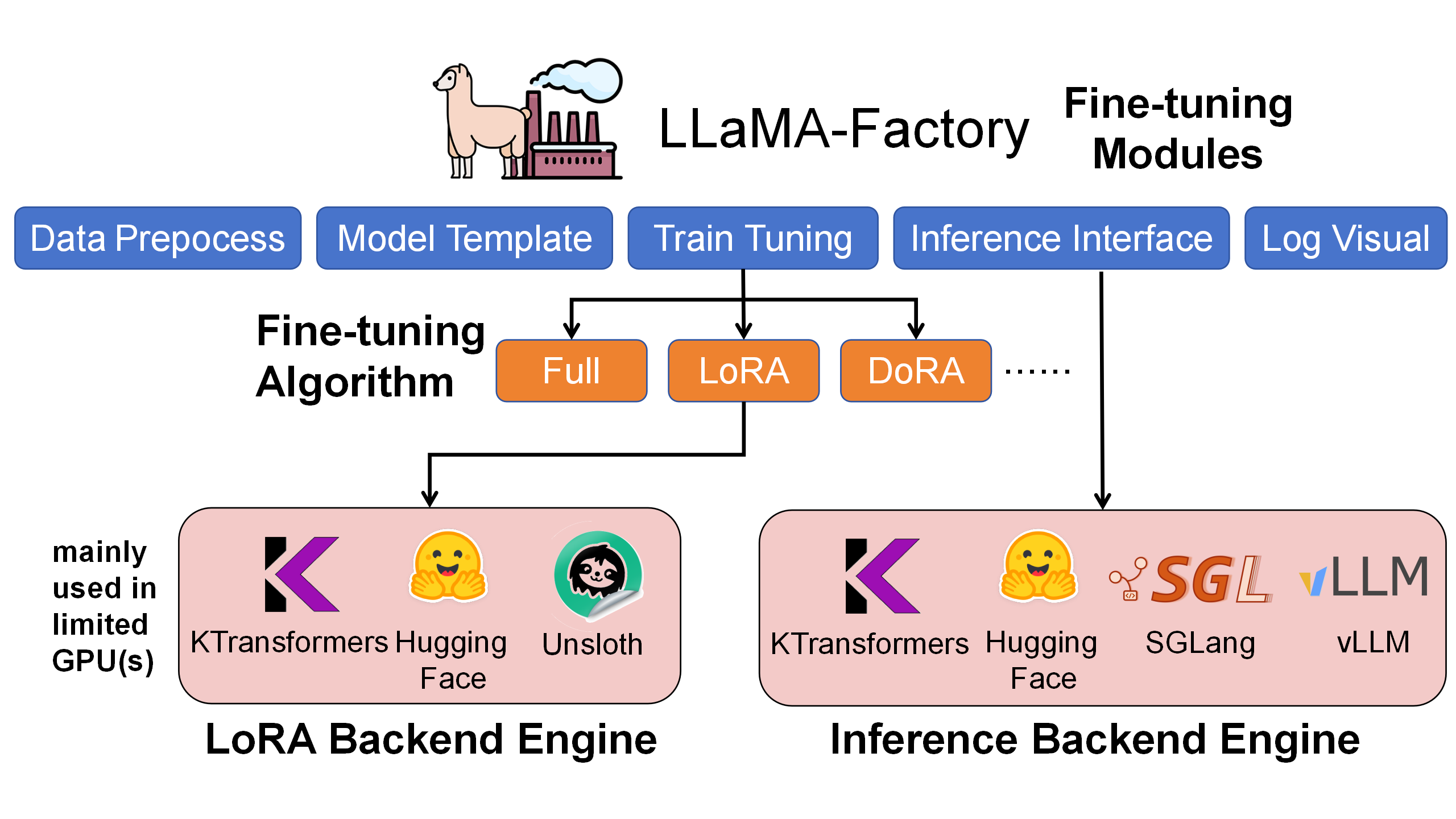
Key Features:
- Resource Efficient: Fine-tune 671B DeepSeek-V3 with just 70GB GPU memory + 1.3TB RAM
- LoRA Support: Full LoRA fine-tuning with heterogeneous acceleration
- LLaMA-Factory Integration: Seamless integration with popular fine-tuning framework
- Production Ready: Chat, batch inference, and metrics evaluation
Performance Examples:
| Model | Configuration | Throughput | GPU Memory |
|---|---|---|---|
| DeepSeek-V3 (671B) | LoRA + AMX | ~40 tokens/s | 70GB (multi-GPU) |
| DeepSeek-V2-Lite (14B) | LoRA + AMX | ~530 tokens/s | 6GB |
Quick Start:
cd kt-sft
# Install environment following kt-sft/README.md
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
🔥 Citation
If you use KTransformers in your research, please cite our paper:
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
👥 Contributors & Team
Developed and maintained by:
- MADSys Lab @ Tsinghua University
- Approaching.AI
- 9#AISoft
- Community contributors
We welcome contributions! Please feel free to submit issues and pull requests.
💬 Community & Support
- GitHub Issues: Report bugs or request features
- WeChat Group: See archive/WeChatGroup.png
{kind=link}
📦 KT original Code
The original integrated KTransformers framework has been archived to the archive/ directory for reference. The project now focuses on the two core modules above for better modularity and maintainability.
For the original documentation with full quick-start guides and examples, see:
- archive/README.md (English)
- archive/README_ZH.md (中文)