mirror of
https://github.com/lllyasviel/stable-diffusion-webui-forge.git
synced 2026-02-26 01:33:56 +00:00
remove cn first
This commit is contained in:
185
extensions-builtin/sd_forge_controlnet/.gitignore
vendored
185
extensions-builtin/sd_forge_controlnet/.gitignore
vendored
@@ -1,185 +0,0 @@
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
cover/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
.pybuilder/
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
# For a library or package, you might want to ignore these files since the code is
|
||||
# intended to run in multiple environments; otherwise, check them in:
|
||||
# .python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# poetry
|
||||
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
||||
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
||||
# commonly ignored for libraries.
|
||||
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
||||
#poetry.lock
|
||||
|
||||
# pdm
|
||||
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
||||
#pdm.lock
|
||||
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
||||
# in version control.
|
||||
# https://pdm.fming.dev/#use-with-ide
|
||||
.pdm.toml
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# pytype static type analyzer
|
||||
.pytype/
|
||||
|
||||
# Cython debug symbols
|
||||
cython_debug/
|
||||
|
||||
# PyCharm
|
||||
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
#.idea
|
||||
*.pt
|
||||
*.pth
|
||||
*.ckpt
|
||||
*.bin
|
||||
*.safetensors
|
||||
|
||||
# Editor setting metadata
|
||||
.idea/
|
||||
.vscode/
|
||||
detected_maps/
|
||||
annotator/downloads/
|
||||
|
||||
# test results and expectations
|
||||
web_tests/results/
|
||||
web_tests/expectations/
|
||||
tests/web_api/full_coverage/results/
|
||||
tests/web_api/full_coverage/expectations/
|
||||
|
||||
*_diff.png
|
||||
|
||||
# Presets
|
||||
presets/
|
||||
|
||||
# Ignore existing dir of hand refiner if exists.
|
||||
annotator/hand_refiner_portable
|
||||
@@ -1,243 +0,0 @@
|
||||
# ControlNet for Stable Diffusion WebUI
|
||||
|
||||
The WebUI extension for ControlNet and other injection-based SD controls.
|
||||
|
||||
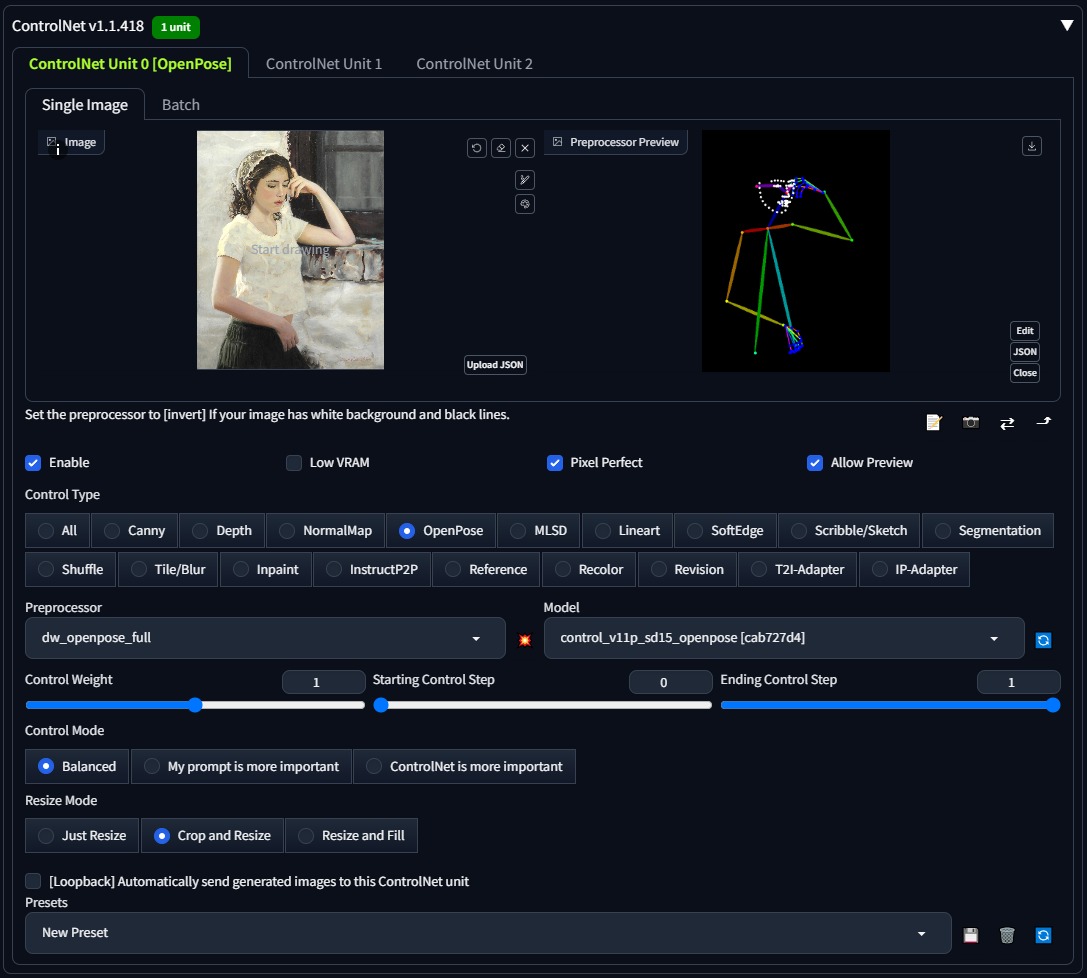
|
||||
|
||||
This extension is for AUTOMATIC1111's [Stable Diffusion web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui), allows the Web UI to add [ControlNet](https://github.com/lllyasviel/ControlNet) to the original Stable Diffusion model to generate images. The addition is on-the-fly, the merging is not required.
|
||||
|
||||
# Installation
|
||||
|
||||
1. Open "Extensions" tab.
|
||||
2. Open "Install from URL" tab in the tab.
|
||||
3. Enter `https://github.com/Mikubill/sd-webui-controlnet.git` to "URL for extension's git repository".
|
||||
4. Press "Install" button.
|
||||
5. Wait for 5 seconds, and you will see the message "Installed into stable-diffusion-webui\extensions\sd-webui-controlnet. Use Installed tab to restart".
|
||||
6. Go to "Installed" tab, click "Check for updates", and then click "Apply and restart UI". (The next time you can also use these buttons to update ControlNet.)
|
||||
7. Completely restart A1111 webui including your terminal. (If you do not know what is a "terminal", you can reboot your computer to achieve the same effect.)
|
||||
8. Download models (see below).
|
||||
9. After you put models in the correct folder, you may need to refresh to see the models. The refresh button is right to your "Model" dropdown.
|
||||
|
||||
# Download Models
|
||||
|
||||
Right now all the 14 models of ControlNet 1.1 are in the beta test.
|
||||
|
||||
Download the models from ControlNet 1.1: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
|
||||
|
||||
You need to download model files ending with ".pth" .
|
||||
|
||||
Put models in your "stable-diffusion-webui\extensions\sd-webui-controlnet\models". You only need to download "pth" files.
|
||||
|
||||
Do not right-click the filenames in HuggingFace website to download. Some users right-clicked those HuggingFace HTML websites and saved those HTML pages as PTH/YAML files. They are not downloading correct files. Instead, please click the small download arrow “↓” icon in HuggingFace to download.
|
||||
|
||||
# Download Models for SDXL
|
||||
|
||||
See instructions [here](https://github.com/Mikubill/sd-webui-controlnet/discussions/2039).
|
||||
|
||||
# Features in ControlNet 1.1
|
||||
|
||||
### Perfect Support for All ControlNet 1.0/1.1 and T2I Adapter Models.
|
||||
|
||||
Now we have perfect support all available models and preprocessors, including perfect support for T2I style adapter and ControlNet 1.1 Shuffle. (Make sure that your YAML file names and model file names are same, see also YAML files in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".)
|
||||
|
||||
### Perfect Support for A1111 High-Res. Fix
|
||||
|
||||
Now if you turn on High-Res Fix in A1111, each controlnet will output two different control images: a small one and a large one. The small one is for your basic generating, and the big one is for your High-Res Fix generating. The two control images are computed by a smart algorithm called "super high-quality control image resampling". This is turned on by default, and you do not need to change any setting.
|
||||
|
||||
### Perfect Support for All A1111 Img2Img or Inpaint Settings and All Mask Types
|
||||
|
||||
Now ControlNet is extensively tested with A1111's different types of masks, including "Inpaint masked"/"Inpaint not masked", and "Whole picture"/"Only masked", and "Only masked padding"&"Mask blur". The resizing perfectly matches A1111's "Just resize"/"Crop and resize"/"Resize and fill". This means you can use ControlNet in nearly everywhere in your A1111 UI without difficulty!
|
||||
|
||||
### The New "Pixel-Perfect" Mode
|
||||
|
||||
Now if you turn on pixel-perfect mode, you do not need to set preprocessor (annotator) resolutions manually. The ControlNet will automatically compute the best annotator resolution for you so that each pixel perfectly matches Stable Diffusion.
|
||||
|
||||
### User-Friendly GUI and Preprocessor Preview
|
||||
|
||||
We reorganized some previously confusing UI like "canvas width/height for new canvas" and it is in the 📝 button now. Now the preview GUI is controlled by the "allow preview" option and the trigger button 💥. The preview image size is better than before, and you do not need to scroll up and down - your a1111 GUI will not be messed up anymore!
|
||||
|
||||
### Support for Almost All Upscaling Scripts
|
||||
|
||||
Now ControlNet 1.1 can support almost all Upscaling/Tile methods. ControlNet 1.1 support the script "Ultimate SD upscale" and almost all other tile-based extensions. Please do not confuse ["Ultimate SD upscale"](https://github.com/Coyote-A/ultimate-upscale-for-automatic1111) with "SD upscale" - they are different scripts. Note that the most recommended upscaling method is ["Tiled VAE/Diffusion"](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111) but we test as many methods/extensions as possible. Note that "SD upscale" is supported since 1.1.117, and if you use it, you need to leave all ControlNet images as blank (We do not recommend "SD upscale" since it is somewhat buggy and cannot be maintained - use the "Ultimate SD upscale" instead).
|
||||
|
||||
### More Control Modes (previously called Guess Mode)
|
||||
|
||||
We have fixed many bugs in previous 1.0’s Guess Mode and now it is called Control Mode
|
||||
|
||||

|
||||
|
||||
Now you can control which aspect is more important (your prompt or your ControlNet):
|
||||
|
||||
* "Balanced": ControlNet on both sides of CFG scale, same as turning off "Guess Mode" in ControlNet 1.0
|
||||
|
||||
* "My prompt is more important": ControlNet on both sides of CFG scale, with progressively reduced SD U-Net injections (layer_weight*=0.825**I, where 0<=I <13, and the 13 means ControlNet injected SD 13 times). In this way, you can make sure that your prompts are perfectly displayed in your generated images.
|
||||
|
||||
* "ControlNet is more important": ControlNet only on the Conditional Side of CFG scale (the cond in A1111's batch-cond-uncond). This means the ControlNet will be X times stronger if your cfg-scale is X. For example, if your cfg-scale is 7, then ControlNet is 7 times stronger. Note that here the X times stronger is different from "Control Weights" since your weights are not modified. This "stronger" effect usually has less artifact and give ControlNet more room to guess what is missing from your prompts (and in the previous 1.0, it is called "Guess Mode").
|
||||
|
||||
<table width="100%">
|
||||
<tr>
|
||||
<td width="25%" style="text-align: center">Input (depth+canny+hed)</td>
|
||||
<td width="25%" style="text-align: center">"Balanced"</td>
|
||||
<td width="25%" style="text-align: center">"My prompt is more important"</td>
|
||||
<td width="25%" style="text-align: center">"ControlNet is more important"</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="25%" style="text-align: center"><img src="samples/cm1.png"></td>
|
||||
<td width="25%" style="text-align: center"><img src="samples/cm2.png"></td>
|
||||
<td width="25%" style="text-align: center"><img src="samples/cm3.png"></td>
|
||||
<td width="25%" style="text-align: center"><img src="samples/cm4.png"></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
### Reference-Only Control
|
||||
|
||||
Now we have a `reference-only` preprocessor that does not require any control models. It can guide the diffusion directly using images as references.
|
||||
|
||||
(Prompt "a dog running on grassland, best quality, ...")
|
||||
|
||||

|
||||
|
||||
This method is similar to inpaint-based reference but it does not make your image disordered.
|
||||
|
||||
Many professional A1111 users know a trick to diffuse image with references by inpaint. For example, if you have a 512x512 image of a dog, and want to generate another 512x512 image with the same dog, some users will connect the 512x512 dog image and a 512x512 blank image into a 1024x512 image, send to inpaint, and mask out the blank 512x512 part to diffuse a dog with similar appearance. However, that method is usually not very satisfying since images are connected and many distortions will appear.
|
||||
|
||||
This `reference-only` ControlNet can directly link the attention layers of your SD to any independent images, so that your SD will read arbitrary images for reference. You need at least ControlNet 1.1.153 to use it.
|
||||
|
||||
To use, just select `reference-only` as preprocessor and put an image. Your SD will just use the image as reference.
|
||||
|
||||
*Note that this method is as "non-opinioned" as possible. It only contains very basic connection codes, without any personal preferences, to connect the attention layers with your reference images. However, even if we tried best to not include any opinioned codes, we still need to write some subjective implementations to deal with weighting, cfg-scale, etc - tech report is on the way.*
|
||||
|
||||
More examples [here](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236).
|
||||
|
||||
# Technical Documents
|
||||
|
||||
See also the documents of ControlNet 1.1:
|
||||
|
||||
https://github.com/lllyasviel/ControlNet-v1-1-nightly#model-specification
|
||||
|
||||
# Default Setting
|
||||
|
||||
This is my setting. If you run into any problem, you can use this setting as a sanity check
|
||||
|
||||
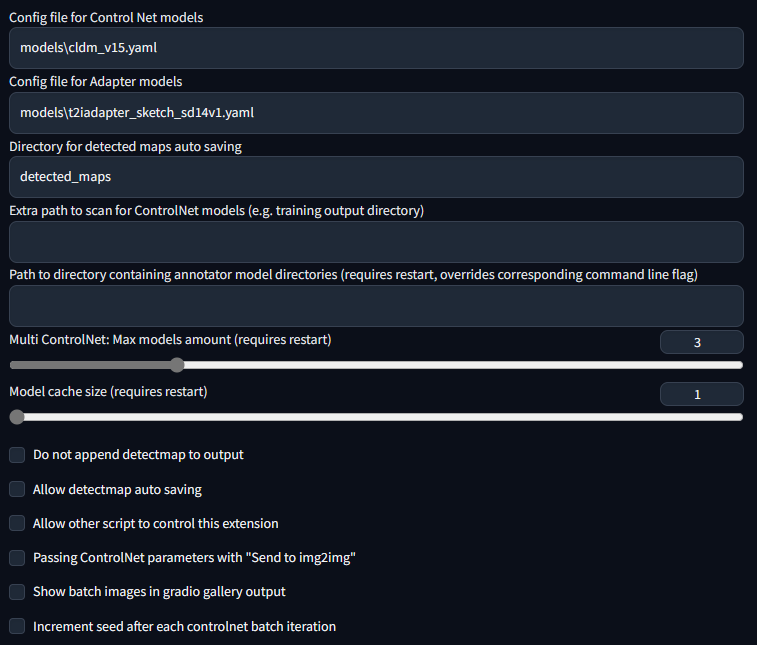
|
||||
|
||||
# Use Previous Models
|
||||
|
||||
### Use ControlNet 1.0 Models
|
||||
|
||||
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
|
||||
|
||||
You can still use all previous models in the previous ControlNet 1.0. Now, the previous "depth" is now called "depth_midas", the previous "normal" is called "normal_midas", the previous "hed" is called "softedge_hed". And starting from 1.1, all line maps, edge maps, lineart maps, boundary maps will have black background and white lines.
|
||||
|
||||
### Use T2I-Adapter Models
|
||||
|
||||
(From TencentARC/T2I-Adapter)
|
||||
|
||||
To use T2I-Adapter models:
|
||||
|
||||
1. Download files from https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
|
||||
2. Put them in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".
|
||||
3. Make sure that the file names of pth files and yaml files are consistent.
|
||||
|
||||
*Note that "CoAdapter" is not implemented yet.*
|
||||
|
||||
# Gallery
|
||||
|
||||
The below results are from ControlNet 1.0.
|
||||
|
||||
| Source | Input | Output |
|
||||
|:-------------------------:|:-------------------------:|:-------------------------:|
|
||||
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-source.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-gen.png?raw=true"> |
|
||||
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.png?raw=true"> |
|
||||
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_input.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_canny.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro-out.png?raw=true"> |
|
||||
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_hed.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_gen.png?raw=true"> |
|
||||
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-pose.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-gen.png?raw=true"> |
|
||||
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-src.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-dep.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-out.png?raw=true"> |
|
||||
|
||||
The below examples are from T2I-Adapter.
|
||||
|
||||
From `t2iadapter_color_sd14v1.pth` :
|
||||
|
||||
| Source | Input | Output |
|
||||
|:-------------------------:|:-------------------------:|:-------------------------:|
|
||||
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947435-1164e7d8-d857-42f9-ab10-2d4a4b25f33a.png"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947557-5520d5f8-88b4-474d-a576-5c9cd3acac3a.png"> |
|
||||
|
||||
From `t2iadapter_style_sd14v1.pth` :
|
||||
|
||||
| Source | Input | Output |
|
||||
|:-------------------------:|:-------------------------:|:-------------------------:|
|
||||
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | (clip, non-image) | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222965711-7b884c9e-7095-45cb-a91c-e50d296ba3a2.png"> |
|
||||
|
||||
# Minimum Requirements
|
||||
|
||||
* (Windows) (NVIDIA: Ampere) 4gb - with `--xformers` enabled, and `Low VRAM` mode ticked in the UI, goes up to 768x832
|
||||
|
||||
# Multi-ControlNet
|
||||
|
||||
This option allows multiple ControlNet inputs for a single generation. To enable this option, change `Multi ControlNet: Max models amount (requires restart)` in the settings. Note that you will need to restart the WebUI for changes to take effect.
|
||||
|
||||
<table width="100%">
|
||||
<tr>
|
||||
<td width="25%" style="text-align: center">Source A</td>
|
||||
<td width="25%" style="text-align: center">Source B</td>
|
||||
<td width="25%" style="text-align: center">Output</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448620-cd3ede92-8d3f-43d5-b771-32dd8417618f.png"></td>
|
||||
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448619-beed9bdb-f6bb-41c2-a7df-aa3ef1f653c5.png"></td>
|
||||
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448613-c99a9e04-0450-40fd-bc73-a9122cefaa2c.png"></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
# Control Weight/Start/End
|
||||
|
||||
Weight is the weight of the controlnet "influence". It's analogous to prompt attention/emphasis. E.g. (myprompt: 1.2). Technically, it's the factor by which to multiply the ControlNet outputs before merging them with original SD Unet.
|
||||
|
||||
Guidance Start/End is the percentage of total steps the controlnet applies (guidance strength = guidance end). It's analogous to prompt editing/shifting. E.g. \[myprompt::0.8\] (It applies from the beginning until 80% of total steps)
|
||||
|
||||
# Batch Mode
|
||||
|
||||
Put any unit into batch mode to activate batch mode for all units. Specify a batch directory for each unit, or use the new textbox in the img2img batch tab as a fallback. Although the textbox is located in the img2img batch tab, you can use it to generate images in the txt2img tab as well.
|
||||
|
||||
Note that this feature is only available in the gradio user interface. Call the APIs as many times as you want for custom batch scheduling.
|
||||
|
||||
# API and Script Access
|
||||
|
||||
This extension can accept txt2img or img2img tasks via API or external extension call. Note that you may need to enable `Allow other scripts to control this extension` in settings for external calls.
|
||||
|
||||
To use the API: start WebUI with argument `--api` and go to `http://webui-address/docs` for documents or checkout [examples](https://github.com/Mikubill/sd-webui-controlnet/blob/main/example/txt2img_example/api_txt2img.py).
|
||||
|
||||
To use external call: Checkout [Wiki](https://github.com/Mikubill/sd-webui-controlnet/wiki/API)
|
||||
|
||||
# Command Line Arguments
|
||||
|
||||
This extension adds these command line arguments to the webui:
|
||||
|
||||
```
|
||||
--controlnet-dir <path to directory with controlnet models> ADD a controlnet models directory
|
||||
--controlnet-annotator-models-path <path to directory with annotator model directories> SET the directory for annotator models
|
||||
--no-half-controlnet load controlnet models in full precision
|
||||
--controlnet-preprocessor-cache-size Cache size for controlnet preprocessor results
|
||||
--controlnet-loglevel Log level for the controlnet extension
|
||||
--controlnet-tracemalloc Enable malloc memory tracing
|
||||
```
|
||||
|
||||
# MacOS Support
|
||||
|
||||
Tested with pytorch nightly: https://github.com/Mikubill/sd-webui-controlnet/pull/143#issuecomment-1435058285
|
||||
|
||||
To use this extension with mps and normal pytorch, currently you may need to start WebUI with `--no-half`.
|
||||
|
||||
# Archive of Deprecated Versions
|
||||
|
||||
The previous version (sd-webui-controlnet 1.0) is archived in
|
||||
|
||||
https://github.com/lllyasviel/webui-controlnet-v1-archived
|
||||
|
||||
Using this version is not a temporary stop of updates. You will stop all updates forever.
|
||||
|
||||
Please consider this version if you work with professional studios that requires 100% reproducing of all previous results pixel by pixel.
|
||||
|
||||
# Thanks
|
||||
|
||||
This implementation is inspired by kohya-ss/sd-webui-additional-networks
|
||||
@@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2021 Miaomiao Li
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -1,172 +0,0 @@
|
||||
import os
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from PIL import Image
|
||||
import fnmatch
|
||||
import cv2
|
||||
|
||||
import sys
|
||||
|
||||
import numpy as np
|
||||
from modules import devices
|
||||
from einops import rearrange
|
||||
from annotator.annotator_path import models_path
|
||||
|
||||
import torchvision
|
||||
from torchvision.models import MobileNet_V2_Weights
|
||||
from torchvision import transforms
|
||||
|
||||
COLOR_BACKGROUND = (255,255,0)
|
||||
COLOR_HAIR = (0,0,255)
|
||||
COLOR_EYE = (255,0,0)
|
||||
COLOR_MOUTH = (255,255,255)
|
||||
COLOR_FACE = (0,255,0)
|
||||
COLOR_SKIN = (0,255,255)
|
||||
COLOR_CLOTHES = (255,0,255)
|
||||
PALETTE = [COLOR_BACKGROUND,COLOR_HAIR,COLOR_EYE,COLOR_MOUTH,COLOR_FACE,COLOR_SKIN,COLOR_CLOTHES]
|
||||
|
||||
class UNet(nn.Module):
|
||||
def __init__(self):
|
||||
super(UNet, self).__init__()
|
||||
self.NUM_SEG_CLASSES = 7 # Background, hair, face, eye, mouth, skin, clothes
|
||||
|
||||
mobilenet_v2 = torchvision.models.mobilenet_v2(weights=MobileNet_V2_Weights.IMAGENET1K_V1)
|
||||
mob_blocks = mobilenet_v2.features
|
||||
|
||||
# Encoder
|
||||
self.en_block0 = nn.Sequential( # in_ch=3 out_ch=16
|
||||
mob_blocks[0],
|
||||
mob_blocks[1]
|
||||
)
|
||||
self.en_block1 = nn.Sequential( # in_ch=16 out_ch=24
|
||||
mob_blocks[2],
|
||||
mob_blocks[3],
|
||||
)
|
||||
self.en_block2 = nn.Sequential( # in_ch=24 out_ch=32
|
||||
mob_blocks[4],
|
||||
mob_blocks[5],
|
||||
mob_blocks[6],
|
||||
)
|
||||
self.en_block3 = nn.Sequential( # in_ch=32 out_ch=96
|
||||
mob_blocks[7],
|
||||
mob_blocks[8],
|
||||
mob_blocks[9],
|
||||
mob_blocks[10],
|
||||
mob_blocks[11],
|
||||
mob_blocks[12],
|
||||
mob_blocks[13],
|
||||
)
|
||||
self.en_block4 = nn.Sequential( # in_ch=96 out_ch=160
|
||||
mob_blocks[14],
|
||||
mob_blocks[15],
|
||||
mob_blocks[16],
|
||||
)
|
||||
|
||||
# Decoder
|
||||
self.de_block4 = nn.Sequential( # in_ch=160 out_ch=96
|
||||
nn.UpsamplingNearest2d(scale_factor=2),
|
||||
nn.Conv2d(160, 96, kernel_size=3, padding=1),
|
||||
nn.InstanceNorm2d(96),
|
||||
nn.LeakyReLU(0.1),
|
||||
nn.Dropout(p=0.2)
|
||||
)
|
||||
self.de_block3 = nn.Sequential( # in_ch=96x2 out_ch=32
|
||||
nn.UpsamplingNearest2d(scale_factor=2),
|
||||
nn.Conv2d(96*2, 32, kernel_size=3, padding=1),
|
||||
nn.InstanceNorm2d(32),
|
||||
nn.LeakyReLU(0.1),
|
||||
nn.Dropout(p=0.2)
|
||||
)
|
||||
self.de_block2 = nn.Sequential( # in_ch=32x2 out_ch=24
|
||||
nn.UpsamplingNearest2d(scale_factor=2),
|
||||
nn.Conv2d(32*2, 24, kernel_size=3, padding=1),
|
||||
nn.InstanceNorm2d(24),
|
||||
nn.LeakyReLU(0.1),
|
||||
nn.Dropout(p=0.2)
|
||||
)
|
||||
self.de_block1 = nn.Sequential( # in_ch=24x2 out_ch=16
|
||||
nn.UpsamplingNearest2d(scale_factor=2),
|
||||
nn.Conv2d(24*2, 16, kernel_size=3, padding=1),
|
||||
nn.InstanceNorm2d(16),
|
||||
nn.LeakyReLU(0.1),
|
||||
nn.Dropout(p=0.2)
|
||||
)
|
||||
|
||||
self.de_block0 = nn.Sequential( # in_ch=16x2 out_ch=7
|
||||
nn.UpsamplingNearest2d(scale_factor=2),
|
||||
nn.Conv2d(16*2, self.NUM_SEG_CLASSES, kernel_size=3, padding=1),
|
||||
nn.Softmax2d()
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
e0 = self.en_block0(x)
|
||||
e1 = self.en_block1(e0)
|
||||
e2 = self.en_block2(e1)
|
||||
e3 = self.en_block3(e2)
|
||||
e4 = self.en_block4(e3)
|
||||
|
||||
d4 = self.de_block4(e4)
|
||||
d4 = F.interpolate(d4, size=e3.size()[2:], mode='bilinear', align_corners=True)
|
||||
c4 = torch.cat((d4,e3),1)
|
||||
|
||||
d3 = self.de_block3(c4)
|
||||
d3 = F.interpolate(d3, size=e2.size()[2:], mode='bilinear', align_corners=True)
|
||||
c3 = torch.cat((d3,e2),1)
|
||||
|
||||
d2 = self.de_block2(c3)
|
||||
d2 = F.interpolate(d2, size=e1.size()[2:], mode='bilinear', align_corners=True)
|
||||
c2 =torch.cat((d2,e1),1)
|
||||
|
||||
d1 = self.de_block1(c2)
|
||||
d1 = F.interpolate(d1, size=e0.size()[2:], mode='bilinear', align_corners=True)
|
||||
c1 = torch.cat((d1,e0),1)
|
||||
y = self.de_block0(c1)
|
||||
|
||||
return y
|
||||
|
||||
|
||||
class AnimeFaceSegment:
|
||||
|
||||
model_dir = os.path.join(models_path, "anime_face_segment")
|
||||
|
||||
def __init__(self):
|
||||
self.model = None
|
||||
self.device = devices.get_device_for("controlnet")
|
||||
|
||||
def load_model(self):
|
||||
remote_model_path = "https://huggingface.co/bdsqlsz/qinglong_controlnet-lllite/resolve/main/Annotators/UNet.pth"
|
||||
modelpath = os.path.join(self.model_dir, "UNet.pth")
|
||||
if not os.path.exists(modelpath):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=self.model_dir)
|
||||
net = UNet()
|
||||
ckpt = torch.load(modelpath, map_location=self.device)
|
||||
for key in list(ckpt.keys()):
|
||||
if 'module.' in key:
|
||||
ckpt[key.replace('module.', '')] = ckpt[key]
|
||||
del ckpt[key]
|
||||
net.load_state_dict(ckpt)
|
||||
net.eval()
|
||||
self.model = net.to(self.device)
|
||||
|
||||
def unload_model(self):
|
||||
if self.model is not None:
|
||||
self.model.cpu()
|
||||
|
||||
def __call__(self, input_image):
|
||||
|
||||
if self.model is None:
|
||||
self.load_model()
|
||||
self.model.to(self.device)
|
||||
transform = transforms.Compose([
|
||||
transforms.Resize(512,interpolation=transforms.InterpolationMode.BICUBIC),
|
||||
transforms.ToTensor(),])
|
||||
img = Image.fromarray(input_image)
|
||||
with torch.no_grad():
|
||||
img = transform(img).unsqueeze(dim=0).to(self.device)
|
||||
seg = self.model(img).squeeze(dim=0)
|
||||
seg = seg.cpu().detach().numpy()
|
||||
img = rearrange(seg,'h w c -> w c h')
|
||||
img = [[PALETTE[np.argmax(val)] for val in buf]for buf in img]
|
||||
return np.array(img).astype(np.uint8)
|
||||
@@ -1,22 +0,0 @@
|
||||
import os
|
||||
from modules import shared
|
||||
|
||||
models_path = shared.opts.data.get('control_net_modules_path', None)
|
||||
if not models_path:
|
||||
models_path = getattr(shared.cmd_opts, 'controlnet_annotator_models_path', None)
|
||||
if not models_path:
|
||||
models_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'downloads')
|
||||
|
||||
if not os.path.isabs(models_path):
|
||||
models_path = os.path.join(shared.data_path, models_path)
|
||||
|
||||
clip_vision_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'clip_vision')
|
||||
# clip vision is always inside controlnet "extensions\sd-webui-controlnet"
|
||||
# and any problem can be solved by removing controlnet and reinstall
|
||||
|
||||
models_path = os.path.realpath(models_path)
|
||||
os.makedirs(models_path, exist_ok=True)
|
||||
print(f'ControlNet preprocessor location: {models_path}')
|
||||
# Make sure that the default location is inside controlnet "extensions\sd-webui-controlnet"
|
||||
# so that any problem can be solved by removing controlnet and reinstall
|
||||
# if users do not change configs on their own (otherwise users will know what is wrong)
|
||||
@@ -1,14 +0,0 @@
|
||||
import cv2
|
||||
|
||||
|
||||
def apply_binary(img, bin_threshold):
|
||||
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
|
||||
|
||||
if bin_threshold == 0 or bin_threshold == 255:
|
||||
# Otsu's threshold
|
||||
otsu_threshold, img_bin = cv2.threshold(img_gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
|
||||
print("Otsu threshold:", otsu_threshold)
|
||||
else:
|
||||
_, img_bin = cv2.threshold(img_gray, bin_threshold, 255, cv2.THRESH_BINARY_INV)
|
||||
|
||||
return cv2.cvtColor(img_bin, cv2.COLOR_GRAY2RGB)
|
||||
@@ -1,5 +0,0 @@
|
||||
import cv2
|
||||
|
||||
|
||||
def apply_canny(img, low_threshold, high_threshold):
|
||||
return cv2.Canny(img, low_threshold, high_threshold)
|
||||
@@ -1,133 +0,0 @@
|
||||
import os
|
||||
import cv2
|
||||
import torch
|
||||
|
||||
from modules import devices
|
||||
from modules.modelloader import load_file_from_url
|
||||
from annotator.annotator_path import models_path
|
||||
from transformers import CLIPVisionModelWithProjection, CLIPVisionConfig, CLIPImageProcessor
|
||||
|
||||
|
||||
config_clip_g = {
|
||||
"attention_dropout": 0.0,
|
||||
"dropout": 0.0,
|
||||
"hidden_act": "gelu",
|
||||
"hidden_size": 1664,
|
||||
"image_size": 224,
|
||||
"initializer_factor": 1.0,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 8192,
|
||||
"layer_norm_eps": 1e-05,
|
||||
"model_type": "clip_vision_model",
|
||||
"num_attention_heads": 16,
|
||||
"num_channels": 3,
|
||||
"num_hidden_layers": 48,
|
||||
"patch_size": 14,
|
||||
"projection_dim": 1280,
|
||||
"torch_dtype": "float32"
|
||||
}
|
||||
|
||||
config_clip_h = {
|
||||
"attention_dropout": 0.0,
|
||||
"dropout": 0.0,
|
||||
"hidden_act": "gelu",
|
||||
"hidden_size": 1280,
|
||||
"image_size": 224,
|
||||
"initializer_factor": 1.0,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 5120,
|
||||
"layer_norm_eps": 1e-05,
|
||||
"model_type": "clip_vision_model",
|
||||
"num_attention_heads": 16,
|
||||
"num_channels": 3,
|
||||
"num_hidden_layers": 32,
|
||||
"patch_size": 14,
|
||||
"projection_dim": 1024,
|
||||
"torch_dtype": "float32"
|
||||
}
|
||||
|
||||
config_clip_vitl = {
|
||||
"attention_dropout": 0.0,
|
||||
"dropout": 0.0,
|
||||
"hidden_act": "quick_gelu",
|
||||
"hidden_size": 1024,
|
||||
"image_size": 224,
|
||||
"initializer_factor": 1.0,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 4096,
|
||||
"layer_norm_eps": 1e-05,
|
||||
"model_type": "clip_vision_model",
|
||||
"num_attention_heads": 16,
|
||||
"num_channels": 3,
|
||||
"num_hidden_layers": 24,
|
||||
"patch_size": 14,
|
||||
"projection_dim": 768,
|
||||
"torch_dtype": "float32"
|
||||
}
|
||||
|
||||
configs = {
|
||||
'clip_g': config_clip_g,
|
||||
'clip_h': config_clip_h,
|
||||
'clip_vitl': config_clip_vitl,
|
||||
}
|
||||
|
||||
downloads = {
|
||||
'clip_vitl': 'https://huggingface.co/openai/clip-vit-large-patch14/resolve/main/pytorch_model.bin',
|
||||
'clip_g': 'https://huggingface.co/lllyasviel/Annotators/resolve/main/clip_g.pth',
|
||||
'clip_h': 'https://huggingface.co/h94/IP-Adapter/resolve/main/models/image_encoder/pytorch_model.bin'
|
||||
}
|
||||
|
||||
|
||||
clip_vision_h_uc = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'clip_vision_h_uc.data')
|
||||
clip_vision_h_uc = torch.load(clip_vision_h_uc, map_location=torch.device('cuda' if torch.cuda.is_available() else 'cpu'))['uc']
|
||||
|
||||
clip_vision_vith_uc = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'clip_vision_vith_uc.data')
|
||||
clip_vision_vith_uc = torch.load(clip_vision_vith_uc, map_location=torch.device('cuda' if torch.cuda.is_available() else 'cpu'))['uc']
|
||||
|
||||
|
||||
class ClipVisionDetector:
|
||||
def __init__(self, config, low_vram: bool):
|
||||
assert config in downloads
|
||||
self.download_link = downloads[config]
|
||||
self.model_path = os.path.join(models_path, 'clip_vision')
|
||||
self.file_name = config + '.pth'
|
||||
self.config = configs[config]
|
||||
self.device = (
|
||||
torch.device("cpu") if low_vram else
|
||||
devices.get_device_for("controlnet")
|
||||
)
|
||||
os.makedirs(self.model_path, exist_ok=True)
|
||||
file_path = os.path.join(self.model_path, self.file_name)
|
||||
if not os.path.exists(file_path):
|
||||
load_file_from_url(url=self.download_link, model_dir=self.model_path, file_name=self.file_name)
|
||||
config = CLIPVisionConfig(**self.config)
|
||||
|
||||
self.model = CLIPVisionModelWithProjection(config)
|
||||
self.processor = CLIPImageProcessor(crop_size=224,
|
||||
do_center_crop=True,
|
||||
do_convert_rgb=True,
|
||||
do_normalize=True,
|
||||
do_resize=True,
|
||||
image_mean=[0.48145466, 0.4578275, 0.40821073],
|
||||
image_std=[0.26862954, 0.26130258, 0.27577711],
|
||||
resample=3,
|
||||
size=224)
|
||||
sd = torch.load(file_path, map_location=self.device)
|
||||
self.model.load_state_dict(sd, strict=False)
|
||||
del sd
|
||||
self.model.to(self.device)
|
||||
self.model.eval()
|
||||
|
||||
def unload_model(self):
|
||||
if self.model is not None:
|
||||
self.model.to('meta')
|
||||
|
||||
def __call__(self, input_image):
|
||||
with torch.no_grad():
|
||||
input_image = cv2.resize(input_image, (224, 224), interpolation=cv2.INTER_AREA)
|
||||
feat = self.processor(images=input_image, return_tensors="pt")
|
||||
feat['pixel_values'] = feat['pixel_values'].to(self.device)
|
||||
result = self.model(**feat, output_hidden_states=True)
|
||||
result['hidden_states'] = [v.to(self.device) for v in result['hidden_states']]
|
||||
result = {k: v.to(self.device) if isinstance(v, torch.Tensor) else v for k, v in result.items()}
|
||||
return result
|
||||
Binary file not shown.
Binary file not shown.
@@ -1,20 +0,0 @@
|
||||
import cv2
|
||||
|
||||
def cv2_resize_shortest_edge(image, size):
|
||||
h, w = image.shape[:2]
|
||||
if h < w:
|
||||
new_h = size
|
||||
new_w = int(round(w / h * size))
|
||||
else:
|
||||
new_w = size
|
||||
new_h = int(round(h / w * size))
|
||||
resized_image = cv2.resize(image, (new_w, new_h), interpolation=cv2.INTER_AREA)
|
||||
return resized_image
|
||||
|
||||
def apply_color(img, res=512):
|
||||
img = cv2_resize_shortest_edge(img, res)
|
||||
h, w = img.shape[:2]
|
||||
|
||||
input_img_color = cv2.resize(img, (w//64, h//64), interpolation=cv2.INTER_CUBIC)
|
||||
input_img_color = cv2.resize(input_img_color, (w, h), interpolation=cv2.INTER_NEAREST)
|
||||
return input_img_color
|
||||
@@ -1,57 +0,0 @@
|
||||
import torchvision # Fix issue Unknown builtin op: torchvision::nms
|
||||
import cv2
|
||||
import numpy as np
|
||||
import torch
|
||||
from einops import rearrange
|
||||
from .densepose import DensePoseMaskedColormapResultsVisualizer, _extract_i_from_iuvarr, densepose_chart_predictor_output_to_result_with_confidences
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
import os
|
||||
|
||||
N_PART_LABELS = 24
|
||||
result_visualizer = DensePoseMaskedColormapResultsVisualizer(
|
||||
alpha=1,
|
||||
data_extractor=_extract_i_from_iuvarr,
|
||||
segm_extractor=_extract_i_from_iuvarr,
|
||||
val_scale = 255.0 / N_PART_LABELS
|
||||
)
|
||||
remote_torchscript_path = "https://huggingface.co/LayerNorm/DensePose-TorchScript-with-hint-image/resolve/main/densepose_r50_fpn_dl.torchscript"
|
||||
torchscript_model = None
|
||||
model_dir = os.path.join(models_path, "densepose")
|
||||
|
||||
def apply_densepose(input_image, cmap="viridis"):
|
||||
global torchscript_model
|
||||
if torchscript_model is None:
|
||||
model_path = os.path.join(model_dir, "densepose_r50_fpn_dl.torchscript")
|
||||
if not os.path.exists(model_path):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_torchscript_path, model_dir=model_dir)
|
||||
torchscript_model = torch.jit.load(model_path, map_location="cpu").to(devices.get_device_for("controlnet")).eval()
|
||||
H, W = input_image.shape[:2]
|
||||
|
||||
hint_image_canvas = np.zeros([H, W], dtype=np.uint8)
|
||||
hint_image_canvas = np.tile(hint_image_canvas[:, :, np.newaxis], [1, 1, 3])
|
||||
input_image = rearrange(torch.from_numpy(input_image).to(devices.get_device_for("controlnet")), 'h w c -> c h w')
|
||||
pred_boxes, corase_segm, fine_segm, u, v = torchscript_model(input_image)
|
||||
|
||||
extractor = densepose_chart_predictor_output_to_result_with_confidences
|
||||
densepose_results = [extractor(pred_boxes[i:i+1], corase_segm[i:i+1], fine_segm[i:i+1], u[i:i+1], v[i:i+1]) for i in range(len(pred_boxes))]
|
||||
|
||||
if cmap=="viridis":
|
||||
result_visualizer.mask_visualizer.cmap = cv2.COLORMAP_VIRIDIS
|
||||
hint_image = result_visualizer.visualize(hint_image_canvas, densepose_results)
|
||||
hint_image = cv2.cvtColor(hint_image, cv2.COLOR_BGR2RGB)
|
||||
hint_image[:, :, 0][hint_image[:, :, 0] == 0] = 68
|
||||
hint_image[:, :, 1][hint_image[:, :, 1] == 0] = 1
|
||||
hint_image[:, :, 2][hint_image[:, :, 2] == 0] = 84
|
||||
else:
|
||||
result_visualizer.mask_visualizer.cmap = cv2.COLORMAP_PARULA
|
||||
hint_image = result_visualizer.visualize(hint_image_canvas, densepose_results)
|
||||
hint_image = cv2.cvtColor(hint_image, cv2.COLOR_BGR2RGB)
|
||||
|
||||
return hint_image
|
||||
|
||||
def unload_model():
|
||||
global torchscript_model
|
||||
if torchscript_model is not None:
|
||||
torchscript_model.cpu()
|
||||
@@ -1,347 +0,0 @@
|
||||
from typing import Tuple
|
||||
import math
|
||||
import numpy as np
|
||||
from enum import IntEnum
|
||||
from typing import List, Tuple, Union
|
||||
import torch
|
||||
from torch.nn import functional as F
|
||||
import logging
|
||||
import cv2
|
||||
|
||||
Image = np.ndarray
|
||||
Boxes = torch.Tensor
|
||||
ImageSizeType = Tuple[int, int]
|
||||
_RawBoxType = Union[List[float], Tuple[float, ...], torch.Tensor, np.ndarray]
|
||||
IntTupleBox = Tuple[int, int, int, int]
|
||||
|
||||
class BoxMode(IntEnum):
|
||||
"""
|
||||
Enum of different ways to represent a box.
|
||||
"""
|
||||
|
||||
XYXY_ABS = 0
|
||||
"""
|
||||
(x0, y0, x1, y1) in absolute floating points coordinates.
|
||||
The coordinates in range [0, width or height].
|
||||
"""
|
||||
XYWH_ABS = 1
|
||||
"""
|
||||
(x0, y0, w, h) in absolute floating points coordinates.
|
||||
"""
|
||||
XYXY_REL = 2
|
||||
"""
|
||||
Not yet supported!
|
||||
(x0, y0, x1, y1) in range [0, 1]. They are relative to the size of the image.
|
||||
"""
|
||||
XYWH_REL = 3
|
||||
"""
|
||||
Not yet supported!
|
||||
(x0, y0, w, h) in range [0, 1]. They are relative to the size of the image.
|
||||
"""
|
||||
XYWHA_ABS = 4
|
||||
"""
|
||||
(xc, yc, w, h, a) in absolute floating points coordinates.
|
||||
(xc, yc) is the center of the rotated box, and the angle a is in degrees ccw.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def convert(box: _RawBoxType, from_mode: "BoxMode", to_mode: "BoxMode") -> _RawBoxType:
|
||||
"""
|
||||
Args:
|
||||
box: can be a k-tuple, k-list or an Nxk array/tensor, where k = 4 or 5
|
||||
from_mode, to_mode (BoxMode)
|
||||
|
||||
Returns:
|
||||
The converted box of the same type.
|
||||
"""
|
||||
if from_mode == to_mode:
|
||||
return box
|
||||
|
||||
original_type = type(box)
|
||||
is_numpy = isinstance(box, np.ndarray)
|
||||
single_box = isinstance(box, (list, tuple))
|
||||
if single_box:
|
||||
assert len(box) == 4 or len(box) == 5, (
|
||||
"BoxMode.convert takes either a k-tuple/list or an Nxk array/tensor,"
|
||||
" where k == 4 or 5"
|
||||
)
|
||||
arr = torch.tensor(box)[None, :]
|
||||
else:
|
||||
# avoid modifying the input box
|
||||
if is_numpy:
|
||||
arr = torch.from_numpy(np.asarray(box)).clone()
|
||||
else:
|
||||
arr = box.clone()
|
||||
|
||||
assert to_mode not in [BoxMode.XYXY_REL, BoxMode.XYWH_REL] and from_mode not in [
|
||||
BoxMode.XYXY_REL,
|
||||
BoxMode.XYWH_REL,
|
||||
], "Relative mode not yet supported!"
|
||||
|
||||
if from_mode == BoxMode.XYWHA_ABS and to_mode == BoxMode.XYXY_ABS:
|
||||
assert (
|
||||
arr.shape[-1] == 5
|
||||
), "The last dimension of input shape must be 5 for XYWHA format"
|
||||
original_dtype = arr.dtype
|
||||
arr = arr.double()
|
||||
|
||||
w = arr[:, 2]
|
||||
h = arr[:, 3]
|
||||
a = arr[:, 4]
|
||||
c = torch.abs(torch.cos(a * math.pi / 180.0))
|
||||
s = torch.abs(torch.sin(a * math.pi / 180.0))
|
||||
# This basically computes the horizontal bounding rectangle of the rotated box
|
||||
new_w = c * w + s * h
|
||||
new_h = c * h + s * w
|
||||
|
||||
# convert center to top-left corner
|
||||
arr[:, 0] -= new_w / 2.0
|
||||
arr[:, 1] -= new_h / 2.0
|
||||
# bottom-right corner
|
||||
arr[:, 2] = arr[:, 0] + new_w
|
||||
arr[:, 3] = arr[:, 1] + new_h
|
||||
|
||||
arr = arr[:, :4].to(dtype=original_dtype)
|
||||
elif from_mode == BoxMode.XYWH_ABS and to_mode == BoxMode.XYWHA_ABS:
|
||||
original_dtype = arr.dtype
|
||||
arr = arr.double()
|
||||
arr[:, 0] += arr[:, 2] / 2.0
|
||||
arr[:, 1] += arr[:, 3] / 2.0
|
||||
angles = torch.zeros((arr.shape[0], 1), dtype=arr.dtype)
|
||||
arr = torch.cat((arr, angles), axis=1).to(dtype=original_dtype)
|
||||
else:
|
||||
if to_mode == BoxMode.XYXY_ABS and from_mode == BoxMode.XYWH_ABS:
|
||||
arr[:, 2] += arr[:, 0]
|
||||
arr[:, 3] += arr[:, 1]
|
||||
elif from_mode == BoxMode.XYXY_ABS and to_mode == BoxMode.XYWH_ABS:
|
||||
arr[:, 2] -= arr[:, 0]
|
||||
arr[:, 3] -= arr[:, 1]
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
"Conversion from BoxMode {} to {} is not supported yet".format(
|
||||
from_mode, to_mode
|
||||
)
|
||||
)
|
||||
|
||||
if single_box:
|
||||
return original_type(arr.flatten().tolist())
|
||||
if is_numpy:
|
||||
return arr.numpy()
|
||||
else:
|
||||
return arr
|
||||
|
||||
class MatrixVisualizer:
|
||||
"""
|
||||
Base visualizer for matrix data
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
inplace=True,
|
||||
cmap=cv2.COLORMAP_PARULA,
|
||||
val_scale=1.0,
|
||||
alpha=0.7,
|
||||
interp_method_matrix=cv2.INTER_LINEAR,
|
||||
interp_method_mask=cv2.INTER_NEAREST,
|
||||
):
|
||||
self.inplace = inplace
|
||||
self.cmap = cmap
|
||||
self.val_scale = val_scale
|
||||
self.alpha = alpha
|
||||
self.interp_method_matrix = interp_method_matrix
|
||||
self.interp_method_mask = interp_method_mask
|
||||
|
||||
def visualize(self, image_bgr, mask, matrix, bbox_xywh):
|
||||
self._check_image(image_bgr)
|
||||
self._check_mask_matrix(mask, matrix)
|
||||
if self.inplace:
|
||||
image_target_bgr = image_bgr
|
||||
else:
|
||||
image_target_bgr = image_bgr * 0
|
||||
x, y, w, h = [int(v) for v in bbox_xywh]
|
||||
if w <= 0 or h <= 0:
|
||||
return image_bgr
|
||||
mask, matrix = self._resize(mask, matrix, w, h)
|
||||
mask_bg = np.tile((mask == 0)[:, :, np.newaxis], [1, 1, 3])
|
||||
matrix_scaled = matrix.astype(np.float32) * self.val_scale
|
||||
_EPSILON = 1e-6
|
||||
if np.any(matrix_scaled > 255 + _EPSILON):
|
||||
logger = logging.getLogger(__name__)
|
||||
logger.warning(
|
||||
f"Matrix has values > {255 + _EPSILON} after " f"scaling, clipping to [0..255]"
|
||||
)
|
||||
matrix_scaled_8u = matrix_scaled.clip(0, 255).astype(np.uint8)
|
||||
matrix_vis = cv2.applyColorMap(matrix_scaled_8u, self.cmap)
|
||||
matrix_vis[mask_bg] = image_target_bgr[y : y + h, x : x + w, :][mask_bg]
|
||||
image_target_bgr[y : y + h, x : x + w, :] = (
|
||||
image_target_bgr[y : y + h, x : x + w, :] * (1.0 - self.alpha) + matrix_vis * self.alpha
|
||||
)
|
||||
return image_target_bgr.astype(np.uint8)
|
||||
|
||||
def _resize(self, mask, matrix, w, h):
|
||||
if (w != mask.shape[1]) or (h != mask.shape[0]):
|
||||
mask = cv2.resize(mask, (w, h), self.interp_method_mask)
|
||||
if (w != matrix.shape[1]) or (h != matrix.shape[0]):
|
||||
matrix = cv2.resize(matrix, (w, h), self.interp_method_matrix)
|
||||
return mask, matrix
|
||||
|
||||
def _check_image(self, image_rgb):
|
||||
assert len(image_rgb.shape) == 3
|
||||
assert image_rgb.shape[2] == 3
|
||||
assert image_rgb.dtype == np.uint8
|
||||
|
||||
def _check_mask_matrix(self, mask, matrix):
|
||||
assert len(matrix.shape) == 2
|
||||
assert len(mask.shape) == 2
|
||||
assert mask.dtype == np.uint8
|
||||
|
||||
class DensePoseResultsVisualizer:
|
||||
def visualize(
|
||||
self,
|
||||
image_bgr: Image,
|
||||
results,
|
||||
) -> Image:
|
||||
context = self.create_visualization_context(image_bgr)
|
||||
for i, result in enumerate(results):
|
||||
boxes_xywh, labels, uv = result
|
||||
iuv_array = torch.cat(
|
||||
(labels[None].type(torch.float32), uv * 255.0)
|
||||
).type(torch.uint8)
|
||||
self.visualize_iuv_arr(context, iuv_array.cpu().numpy(), boxes_xywh)
|
||||
image_bgr = self.context_to_image_bgr(context)
|
||||
return image_bgr
|
||||
|
||||
def create_visualization_context(self, image_bgr: Image):
|
||||
return image_bgr
|
||||
|
||||
def visualize_iuv_arr(self, context, iuv_arr: np.ndarray, bbox_xywh) -> None:
|
||||
pass
|
||||
|
||||
def context_to_image_bgr(self, context):
|
||||
return context
|
||||
|
||||
def get_image_bgr_from_context(self, context):
|
||||
return context
|
||||
|
||||
class DensePoseMaskedColormapResultsVisualizer(DensePoseResultsVisualizer):
|
||||
def __init__(
|
||||
self,
|
||||
data_extractor,
|
||||
segm_extractor,
|
||||
inplace=True,
|
||||
cmap=cv2.COLORMAP_PARULA,
|
||||
alpha=0.7,
|
||||
val_scale=1.0,
|
||||
**kwargs,
|
||||
):
|
||||
self.mask_visualizer = MatrixVisualizer(
|
||||
inplace=inplace, cmap=cmap, val_scale=val_scale, alpha=alpha
|
||||
)
|
||||
self.data_extractor = data_extractor
|
||||
self.segm_extractor = segm_extractor
|
||||
|
||||
def context_to_image_bgr(self, context):
|
||||
return context
|
||||
|
||||
def visualize_iuv_arr(self, context, iuv_arr: np.ndarray, bbox_xywh) -> None:
|
||||
image_bgr = self.get_image_bgr_from_context(context)
|
||||
matrix = self.data_extractor(iuv_arr)
|
||||
segm = self.segm_extractor(iuv_arr)
|
||||
mask = np.zeros(matrix.shape, dtype=np.uint8)
|
||||
mask[segm > 0] = 1
|
||||
image_bgr = self.mask_visualizer.visualize(image_bgr, mask, matrix, bbox_xywh)
|
||||
|
||||
|
||||
def _extract_i_from_iuvarr(iuv_arr):
|
||||
return iuv_arr[0, :, :]
|
||||
|
||||
|
||||
def _extract_u_from_iuvarr(iuv_arr):
|
||||
return iuv_arr[1, :, :]
|
||||
|
||||
|
||||
def _extract_v_from_iuvarr(iuv_arr):
|
||||
return iuv_arr[2, :, :]
|
||||
|
||||
def make_int_box(box: torch.Tensor) -> IntTupleBox:
|
||||
int_box = [0, 0, 0, 0]
|
||||
int_box[0], int_box[1], int_box[2], int_box[3] = tuple(box.long().tolist())
|
||||
return int_box[0], int_box[1], int_box[2], int_box[3]
|
||||
|
||||
def densepose_chart_predictor_output_to_result_with_confidences(
|
||||
boxes: Boxes,
|
||||
coarse_segm,
|
||||
fine_segm,
|
||||
u, v
|
||||
|
||||
):
|
||||
boxes_xyxy_abs = boxes.clone()
|
||||
boxes_xywh_abs = BoxMode.convert(boxes_xyxy_abs, BoxMode.XYXY_ABS, BoxMode.XYWH_ABS)
|
||||
box_xywh = make_int_box(boxes_xywh_abs[0])
|
||||
|
||||
labels = resample_fine_and_coarse_segm_tensors_to_bbox(fine_segm, coarse_segm, box_xywh).squeeze(0)
|
||||
uv = resample_uv_tensors_to_bbox(u, v, labels, box_xywh)
|
||||
confidences = []
|
||||
return box_xywh, labels, uv
|
||||
|
||||
def resample_fine_and_coarse_segm_tensors_to_bbox(
|
||||
fine_segm: torch.Tensor, coarse_segm: torch.Tensor, box_xywh_abs: IntTupleBox
|
||||
):
|
||||
"""
|
||||
Resample fine and coarse segmentation tensors to the given
|
||||
bounding box and derive labels for each pixel of the bounding box
|
||||
|
||||
Args:
|
||||
fine_segm: float tensor of shape [1, C, Hout, Wout]
|
||||
coarse_segm: float tensor of shape [1, K, Hout, Wout]
|
||||
box_xywh_abs (tuple of 4 int): bounding box given by its upper-left
|
||||
corner coordinates, width (W) and height (H)
|
||||
Return:
|
||||
Labels for each pixel of the bounding box, a long tensor of size [1, H, W]
|
||||
"""
|
||||
x, y, w, h = box_xywh_abs
|
||||
w = max(int(w), 1)
|
||||
h = max(int(h), 1)
|
||||
# coarse segmentation
|
||||
coarse_segm_bbox = F.interpolate(
|
||||
coarse_segm,
|
||||
(h, w),
|
||||
mode="bilinear",
|
||||
align_corners=False,
|
||||
).argmax(dim=1)
|
||||
# combined coarse and fine segmentation
|
||||
labels = (
|
||||
F.interpolate(fine_segm, (h, w), mode="bilinear", align_corners=False).argmax(dim=1)
|
||||
* (coarse_segm_bbox > 0).long()
|
||||
)
|
||||
return labels
|
||||
|
||||
def resample_uv_tensors_to_bbox(
|
||||
u: torch.Tensor,
|
||||
v: torch.Tensor,
|
||||
labels: torch.Tensor,
|
||||
box_xywh_abs: IntTupleBox,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Resamples U and V coordinate estimates for the given bounding box
|
||||
|
||||
Args:
|
||||
u (tensor [1, C, H, W] of float): U coordinates
|
||||
v (tensor [1, C, H, W] of float): V coordinates
|
||||
labels (tensor [H, W] of long): labels obtained by resampling segmentation
|
||||
outputs for the given bounding box
|
||||
box_xywh_abs (tuple of 4 int): bounding box that corresponds to predictor outputs
|
||||
Return:
|
||||
Resampled U and V coordinates - a tensor [2, H, W] of float
|
||||
"""
|
||||
x, y, w, h = box_xywh_abs
|
||||
w = max(int(w), 1)
|
||||
h = max(int(h), 1)
|
||||
u_bbox = F.interpolate(u, (h, w), mode="bilinear", align_corners=False)
|
||||
v_bbox = F.interpolate(v, (h, w), mode="bilinear", align_corners=False)
|
||||
uv = torch.zeros([2, h, w], dtype=torch.float32, device=u.device)
|
||||
for part_id in range(1, u_bbox.size(1)):
|
||||
uv[0][labels == part_id] = u_bbox[0, part_id][labels == part_id]
|
||||
uv[1][labels == part_id] = v_bbox[0, part_id][labels == part_id]
|
||||
return uv
|
||||
|
||||
@@ -1,79 +0,0 @@
|
||||
import os
|
||||
import torch
|
||||
import cv2
|
||||
import numpy as np
|
||||
import torch.nn.functional as F
|
||||
from torchvision.transforms import Compose
|
||||
|
||||
from depth_anything.dpt import DPT_DINOv2
|
||||
from depth_anything.util.transform import Resize, NormalizeImage, PrepareForNet
|
||||
from .util import load_model
|
||||
from .annotator_path import models_path
|
||||
|
||||
|
||||
transform = Compose(
|
||||
[
|
||||
Resize(
|
||||
width=518,
|
||||
height=518,
|
||||
resize_target=False,
|
||||
keep_aspect_ratio=True,
|
||||
ensure_multiple_of=14,
|
||||
resize_method="lower_bound",
|
||||
image_interpolation_method=cv2.INTER_CUBIC,
|
||||
),
|
||||
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
||||
PrepareForNet(),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
class DepthAnythingDetector:
|
||||
"""https://github.com/LiheYoung/Depth-Anything"""
|
||||
|
||||
model_dir = os.path.join(models_path, "depth_anything")
|
||||
|
||||
def __init__(self, device: torch.device):
|
||||
self.device = device
|
||||
self.model = (
|
||||
DPT_DINOv2(
|
||||
encoder="vitl",
|
||||
features=256,
|
||||
out_channels=[256, 512, 1024, 1024],
|
||||
localhub=False,
|
||||
)
|
||||
.to(device)
|
||||
.eval()
|
||||
)
|
||||
remote_url = os.environ.get(
|
||||
"CONTROLNET_DEPTH_ANYTHING_MODEL_URL",
|
||||
"https://huggingface.co/spaces/LiheYoung/Depth-Anything/resolve/main/checkpoints/depth_anything_vitl14.pth",
|
||||
)
|
||||
model_path = load_model(
|
||||
"depth_anything_vitl14.pth", remote_url=remote_url, model_dir=self.model_dir
|
||||
)
|
||||
self.model.load_state_dict(torch.load(model_path))
|
||||
|
||||
def __call__(self, image: np.ndarray, colored: bool = True) -> np.ndarray:
|
||||
self.model.to(self.device)
|
||||
h, w = image.shape[:2]
|
||||
|
||||
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) / 255.0
|
||||
image = transform({"image": image})["image"]
|
||||
image = torch.from_numpy(image).unsqueeze(0).to(self.device)
|
||||
@torch.no_grad()
|
||||
def predict_depth(model, image):
|
||||
return model(image)
|
||||
depth = predict_depth(self.model, image)
|
||||
depth = F.interpolate(
|
||||
depth[None], (h, w), mode="bilinear", align_corners=False
|
||||
)[0, 0]
|
||||
depth = (depth - depth.min()) / (depth.max() - depth.min()) * 255.0
|
||||
depth = depth.cpu().numpy().astype(np.uint8)
|
||||
if colored:
|
||||
return cv2.applyColorMap(depth, cv2.COLORMAP_INFERNO)[:, :, ::-1]
|
||||
else:
|
||||
return depth
|
||||
|
||||
def unload_model(self):
|
||||
self.model.to("cpu")
|
||||
@@ -1,98 +0,0 @@
|
||||
# This is an improved version and model of HED edge detection with Apache License, Version 2.0.
|
||||
# Please use this implementation in your products
|
||||
# This implementation may produce slightly different results from Saining Xie's official implementations,
|
||||
# but it generates smoother edges and is more suitable for ControlNet as well as other image-to-image translations.
|
||||
# Different from official models and other implementations, this is an RGB-input model (rather than BGR)
|
||||
# and in this way it works better for gradio's RGB protocol
|
||||
|
||||
import os
|
||||
import cv2
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
from einops import rearrange
|
||||
import os
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
from annotator.util import safe_step, nms
|
||||
|
||||
|
||||
class DoubleConvBlock(torch.nn.Module):
|
||||
def __init__(self, input_channel, output_channel, layer_number):
|
||||
super().__init__()
|
||||
self.convs = torch.nn.Sequential()
|
||||
self.convs.append(torch.nn.Conv2d(in_channels=input_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
|
||||
for i in range(1, layer_number):
|
||||
self.convs.append(torch.nn.Conv2d(in_channels=output_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
|
||||
self.projection = torch.nn.Conv2d(in_channels=output_channel, out_channels=1, kernel_size=(1, 1), stride=(1, 1), padding=0)
|
||||
|
||||
def __call__(self, x, down_sampling=False):
|
||||
h = x
|
||||
if down_sampling:
|
||||
h = torch.nn.functional.max_pool2d(h, kernel_size=(2, 2), stride=(2, 2))
|
||||
for conv in self.convs:
|
||||
h = conv(h)
|
||||
h = torch.nn.functional.relu(h)
|
||||
return h, self.projection(h)
|
||||
|
||||
|
||||
class ControlNetHED_Apache2(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.norm = torch.nn.Parameter(torch.zeros(size=(1, 3, 1, 1)))
|
||||
self.block1 = DoubleConvBlock(input_channel=3, output_channel=64, layer_number=2)
|
||||
self.block2 = DoubleConvBlock(input_channel=64, output_channel=128, layer_number=2)
|
||||
self.block3 = DoubleConvBlock(input_channel=128, output_channel=256, layer_number=3)
|
||||
self.block4 = DoubleConvBlock(input_channel=256, output_channel=512, layer_number=3)
|
||||
self.block5 = DoubleConvBlock(input_channel=512, output_channel=512, layer_number=3)
|
||||
|
||||
def __call__(self, x):
|
||||
h = x - self.norm
|
||||
h, projection1 = self.block1(h)
|
||||
h, projection2 = self.block2(h, down_sampling=True)
|
||||
h, projection3 = self.block3(h, down_sampling=True)
|
||||
h, projection4 = self.block4(h, down_sampling=True)
|
||||
h, projection5 = self.block5(h, down_sampling=True)
|
||||
return projection1, projection2, projection3, projection4, projection5
|
||||
|
||||
|
||||
netNetwork = None
|
||||
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/ControlNetHED.pth"
|
||||
modeldir = os.path.join(models_path, "hed")
|
||||
old_modeldir = os.path.dirname(os.path.realpath(__file__))
|
||||
|
||||
|
||||
def apply_hed(input_image, is_safe=False):
|
||||
global netNetwork
|
||||
if netNetwork is None:
|
||||
modelpath = os.path.join(modeldir, "ControlNetHED.pth")
|
||||
old_modelpath = os.path.join(old_modeldir, "ControlNetHED.pth")
|
||||
if os.path.exists(old_modelpath):
|
||||
modelpath = old_modelpath
|
||||
elif not os.path.exists(modelpath):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=modeldir)
|
||||
netNetwork = ControlNetHED_Apache2().to(devices.get_device_for("controlnet"))
|
||||
netNetwork.load_state_dict(torch.load(modelpath, map_location='cpu'))
|
||||
netNetwork.to(devices.get_device_for("controlnet")).float().eval()
|
||||
|
||||
assert input_image.ndim == 3
|
||||
H, W, C = input_image.shape
|
||||
with torch.no_grad():
|
||||
image_hed = torch.from_numpy(input_image.copy()).float().to(devices.get_device_for("controlnet"))
|
||||
image_hed = rearrange(image_hed, 'h w c -> 1 c h w')
|
||||
edges = netNetwork(image_hed)
|
||||
edges = [e.detach().cpu().numpy().astype(np.float32)[0, 0] for e in edges]
|
||||
edges = [cv2.resize(e, (W, H), interpolation=cv2.INTER_LINEAR) for e in edges]
|
||||
edges = np.stack(edges, axis=2)
|
||||
edge = 1 / (1 + np.exp(-np.mean(edges, axis=2).astype(np.float64)))
|
||||
if is_safe:
|
||||
edge = safe_step(edge)
|
||||
edge = (edge * 255.0).clip(0, 255).astype(np.uint8)
|
||||
return edge
|
||||
|
||||
|
||||
def unload_hed_model():
|
||||
global netNetwork
|
||||
if netNetwork is not None:
|
||||
netNetwork.cpu()
|
||||
@@ -1,212 +0,0 @@
|
||||
import numpy as np
|
||||
import cv2
|
||||
import torch
|
||||
|
||||
import os
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
|
||||
import mmcv
|
||||
from mmdet.apis import inference_detector, init_detector
|
||||
from mmpose.apis import inference_top_down_pose_model
|
||||
from mmpose.apis import init_pose_model, process_mmdet_results, vis_pose_result
|
||||
|
||||
|
||||
def preprocessing(image, device):
|
||||
# Resize
|
||||
scale = 640 / max(image.shape[:2])
|
||||
image = cv2.resize(image, dsize=None, fx=scale, fy=scale)
|
||||
raw_image = image.astype(np.uint8)
|
||||
|
||||
# Subtract mean values
|
||||
image = image.astype(np.float32)
|
||||
image -= np.array(
|
||||
[
|
||||
float(104.008),
|
||||
float(116.669),
|
||||
float(122.675),
|
||||
]
|
||||
)
|
||||
|
||||
# Convert to torch.Tensor and add "batch" axis
|
||||
image = torch.from_numpy(image.transpose(2, 0, 1)).float().unsqueeze(0)
|
||||
image = image.to(device)
|
||||
|
||||
return image, raw_image
|
||||
|
||||
|
||||
def imshow_keypoints(img,
|
||||
pose_result,
|
||||
skeleton=None,
|
||||
kpt_score_thr=0.1,
|
||||
pose_kpt_color=None,
|
||||
pose_link_color=None,
|
||||
radius=4,
|
||||
thickness=1):
|
||||
"""Draw keypoints and links on an image.
|
||||
Args:
|
||||
img (ndarry): The image to draw poses on.
|
||||
pose_result (list[kpts]): The poses to draw. Each element kpts is
|
||||
a set of K keypoints as an Kx3 numpy.ndarray, where each
|
||||
keypoint is represented as x, y, score.
|
||||
kpt_score_thr (float, optional): Minimum score of keypoints
|
||||
to be shown. Default: 0.3.
|
||||
pose_kpt_color (np.array[Nx3]`): Color of N keypoints. If None,
|
||||
the keypoint will not be drawn.
|
||||
pose_link_color (np.array[Mx3]): Color of M links. If None, the
|
||||
links will not be drawn.
|
||||
thickness (int): Thickness of lines.
|
||||
"""
|
||||
|
||||
img_h, img_w, _ = img.shape
|
||||
img = np.zeros(img.shape)
|
||||
|
||||
for idx, kpts in enumerate(pose_result):
|
||||
if idx > 1:
|
||||
continue
|
||||
kpts = kpts['keypoints']
|
||||
# print(kpts)
|
||||
kpts = np.array(kpts, copy=False)
|
||||
|
||||
# draw each point on image
|
||||
if pose_kpt_color is not None:
|
||||
assert len(pose_kpt_color) == len(kpts)
|
||||
|
||||
for kid, kpt in enumerate(kpts):
|
||||
x_coord, y_coord, kpt_score = int(kpt[0]), int(kpt[1]), kpt[2]
|
||||
|
||||
if kpt_score < kpt_score_thr or pose_kpt_color[kid] is None:
|
||||
# skip the point that should not be drawn
|
||||
continue
|
||||
|
||||
color = tuple(int(c) for c in pose_kpt_color[kid])
|
||||
cv2.circle(img, (int(x_coord), int(y_coord)),
|
||||
radius, color, -1)
|
||||
|
||||
# draw links
|
||||
if skeleton is not None and pose_link_color is not None:
|
||||
assert len(pose_link_color) == len(skeleton)
|
||||
|
||||
for sk_id, sk in enumerate(skeleton):
|
||||
pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
|
||||
pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
|
||||
|
||||
if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0 or pos1[1] >= img_h or pos2[0] <= 0
|
||||
or pos2[0] >= img_w or pos2[1] <= 0 or pos2[1] >= img_h or kpts[sk[0], 2] < kpt_score_thr
|
||||
or kpts[sk[1], 2] < kpt_score_thr or pose_link_color[sk_id] is None):
|
||||
# skip the link that should not be drawn
|
||||
continue
|
||||
color = tuple(int(c) for c in pose_link_color[sk_id])
|
||||
cv2.line(img, pos1, pos2, color, thickness=thickness)
|
||||
|
||||
return img
|
||||
|
||||
|
||||
human_det, pose_model = None, None
|
||||
det_model_path = "https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth"
|
||||
pose_model_path = "https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth"
|
||||
|
||||
modeldir = os.path.join(models_path, "keypose")
|
||||
old_modeldir = os.path.dirname(os.path.realpath(__file__))
|
||||
|
||||
det_config = 'faster_rcnn_r50_fpn_coco.py'
|
||||
pose_config = 'hrnet_w48_coco_256x192.py'
|
||||
|
||||
det_checkpoint = 'faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
|
||||
pose_checkpoint = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
|
||||
det_cat_id = 1
|
||||
bbox_thr = 0.2
|
||||
|
||||
skeleton = [
|
||||
[15, 13], [13, 11], [16, 14], [14, 12], [11, 12], [5, 11], [6, 12], [5, 6], [5, 7], [6, 8],
|
||||
[7, 9], [8, 10],
|
||||
[1, 2], [0, 1], [0, 2], [1, 3], [2, 4], [3, 5], [4, 6]
|
||||
]
|
||||
|
||||
pose_kpt_color = [
|
||||
[51, 153, 255], [51, 153, 255], [51, 153, 255], [51, 153, 255], [51, 153, 255],
|
||||
[0, 255, 0],
|
||||
[255, 128, 0], [0, 255, 0], [255, 128, 0], [0, 255, 0], [255, 128, 0], [0, 255, 0],
|
||||
[255, 128, 0],
|
||||
[0, 255, 0], [255, 128, 0], [0, 255, 0], [255, 128, 0]
|
||||
]
|
||||
|
||||
pose_link_color = [
|
||||
[0, 255, 0], [0, 255, 0], [255, 128, 0], [255, 128, 0],
|
||||
[51, 153, 255], [51, 153, 255], [51, 153, 255], [51, 153, 255], [0, 255, 0],
|
||||
[255, 128, 0],
|
||||
[0, 255, 0], [255, 128, 0], [51, 153, 255], [51, 153, 255], [51, 153, 255],
|
||||
[51, 153, 255],
|
||||
[51, 153, 255], [51, 153, 255], [51, 153, 255]
|
||||
]
|
||||
|
||||
def find_download_model(checkpoint, remote_path):
|
||||
modelpath = os.path.join(modeldir, checkpoint)
|
||||
old_modelpath = os.path.join(old_modeldir, checkpoint)
|
||||
|
||||
if os.path.exists(old_modelpath):
|
||||
modelpath = old_modelpath
|
||||
elif not os.path.exists(modelpath):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_path, model_dir=modeldir)
|
||||
|
||||
return modelpath
|
||||
|
||||
def apply_keypose(input_image):
|
||||
global human_det, pose_model
|
||||
if netNetwork is None:
|
||||
det_model_local = find_download_model(det_checkpoint, det_model_path)
|
||||
hrnet_model_local = find_download_model(pose_checkpoint, pose_model_path)
|
||||
det_config_mmcv = mmcv.Config.fromfile(det_config)
|
||||
pose_config_mmcv = mmcv.Config.fromfile(pose_config)
|
||||
human_det = init_detector(det_config_mmcv, det_model_local, device=devices.get_device_for("controlnet"))
|
||||
pose_model = init_pose_model(pose_config_mmcv, hrnet_model_local, device=devices.get_device_for("controlnet"))
|
||||
|
||||
assert input_image.ndim == 3
|
||||
input_image = input_image.copy()
|
||||
with torch.no_grad():
|
||||
image = torch.from_numpy(input_image).float().to(devices.get_device_for("controlnet"))
|
||||
image = image / 255.0
|
||||
mmdet_results = inference_detector(human_det, image)
|
||||
|
||||
# keep the person class bounding boxes.
|
||||
person_results = process_mmdet_results(mmdet_results, det_cat_id)
|
||||
|
||||
return_heatmap = False
|
||||
dataset = pose_model.cfg.data['test']['type']
|
||||
|
||||
# e.g. use ('backbone', ) to return backbone feature
|
||||
output_layer_names = None
|
||||
pose_results, _ = inference_top_down_pose_model(
|
||||
pose_model,
|
||||
image,
|
||||
person_results,
|
||||
bbox_thr=bbox_thr,
|
||||
format='xyxy',
|
||||
dataset=dataset,
|
||||
dataset_info=None,
|
||||
return_heatmap=return_heatmap,
|
||||
outputs=output_layer_names
|
||||
)
|
||||
|
||||
im_keypose_out = imshow_keypoints(
|
||||
image,
|
||||
pose_results,
|
||||
skeleton=skeleton,
|
||||
pose_kpt_color=pose_kpt_color,
|
||||
pose_link_color=pose_link_color,
|
||||
radius=2,
|
||||
thickness=2
|
||||
)
|
||||
im_keypose_out = im_keypose_out.astype(np.uint8)
|
||||
|
||||
# image_hed = rearrange(image_hed, 'h w c -> 1 c h w')
|
||||
# edge = netNetwork(image_hed)[0]
|
||||
# edge = (edge.cpu().numpy() * 255.0).clip(0, 255).astype(np.uint8)
|
||||
return im_keypose_out
|
||||
|
||||
|
||||
def unload_hed_model():
|
||||
global netNetwork
|
||||
if netNetwork is not None:
|
||||
netNetwork.cpu()
|
||||
@@ -1,182 +0,0 @@
|
||||
checkpoint_config = dict(interval=1)
|
||||
# yapf:disable
|
||||
log_config = dict(
|
||||
interval=50,
|
||||
hooks=[
|
||||
dict(type='TextLoggerHook'),
|
||||
# dict(type='TensorboardLoggerHook')
|
||||
])
|
||||
# yapf:enable
|
||||
dist_params = dict(backend='nccl')
|
||||
log_level = 'INFO'
|
||||
load_from = None
|
||||
resume_from = None
|
||||
workflow = [('train', 1)]
|
||||
# optimizer
|
||||
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
|
||||
optimizer_config = dict(grad_clip=None)
|
||||
# learning policy
|
||||
lr_config = dict(
|
||||
policy='step',
|
||||
warmup='linear',
|
||||
warmup_iters=500,
|
||||
warmup_ratio=0.001,
|
||||
step=[8, 11])
|
||||
total_epochs = 12
|
||||
|
||||
model = dict(
|
||||
type='FasterRCNN',
|
||||
pretrained='torchvision://resnet50',
|
||||
backbone=dict(
|
||||
type='ResNet',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
frozen_stages=1,
|
||||
norm_cfg=dict(type='BN', requires_grad=True),
|
||||
norm_eval=True,
|
||||
style='pytorch'),
|
||||
neck=dict(
|
||||
type='FPN',
|
||||
in_channels=[256, 512, 1024, 2048],
|
||||
out_channels=256,
|
||||
num_outs=5),
|
||||
rpn_head=dict(
|
||||
type='RPNHead',
|
||||
in_channels=256,
|
||||
feat_channels=256,
|
||||
anchor_generator=dict(
|
||||
type='AnchorGenerator',
|
||||
scales=[8],
|
||||
ratios=[0.5, 1.0, 2.0],
|
||||
strides=[4, 8, 16, 32, 64]),
|
||||
bbox_coder=dict(
|
||||
type='DeltaXYWHBBoxCoder',
|
||||
target_means=[.0, .0, .0, .0],
|
||||
target_stds=[1.0, 1.0, 1.0, 1.0]),
|
||||
loss_cls=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
|
||||
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
|
||||
roi_head=dict(
|
||||
type='StandardRoIHead',
|
||||
bbox_roi_extractor=dict(
|
||||
type='SingleRoIExtractor',
|
||||
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
|
||||
out_channels=256,
|
||||
featmap_strides=[4, 8, 16, 32]),
|
||||
bbox_head=dict(
|
||||
type='Shared2FCBBoxHead',
|
||||
in_channels=256,
|
||||
fc_out_channels=1024,
|
||||
roi_feat_size=7,
|
||||
num_classes=80,
|
||||
bbox_coder=dict(
|
||||
type='DeltaXYWHBBoxCoder',
|
||||
target_means=[0., 0., 0., 0.],
|
||||
target_stds=[0.1, 0.1, 0.2, 0.2]),
|
||||
reg_class_agnostic=False,
|
||||
loss_cls=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
|
||||
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
|
||||
# model training and testing settings
|
||||
train_cfg=dict(
|
||||
rpn=dict(
|
||||
assigner=dict(
|
||||
type='MaxIoUAssigner',
|
||||
pos_iou_thr=0.7,
|
||||
neg_iou_thr=0.3,
|
||||
min_pos_iou=0.3,
|
||||
match_low_quality=True,
|
||||
ignore_iof_thr=-1),
|
||||
sampler=dict(
|
||||
type='RandomSampler',
|
||||
num=256,
|
||||
pos_fraction=0.5,
|
||||
neg_pos_ub=-1,
|
||||
add_gt_as_proposals=False),
|
||||
allowed_border=-1,
|
||||
pos_weight=-1,
|
||||
debug=False),
|
||||
rpn_proposal=dict(
|
||||
nms_pre=2000,
|
||||
max_per_img=1000,
|
||||
nms=dict(type='nms', iou_threshold=0.7),
|
||||
min_bbox_size=0),
|
||||
rcnn=dict(
|
||||
assigner=dict(
|
||||
type='MaxIoUAssigner',
|
||||
pos_iou_thr=0.5,
|
||||
neg_iou_thr=0.5,
|
||||
min_pos_iou=0.5,
|
||||
match_low_quality=False,
|
||||
ignore_iof_thr=-1),
|
||||
sampler=dict(
|
||||
type='RandomSampler',
|
||||
num=512,
|
||||
pos_fraction=0.25,
|
||||
neg_pos_ub=-1,
|
||||
add_gt_as_proposals=True),
|
||||
pos_weight=-1,
|
||||
debug=False)),
|
||||
test_cfg=dict(
|
||||
rpn=dict(
|
||||
nms_pre=1000,
|
||||
max_per_img=1000,
|
||||
nms=dict(type='nms', iou_threshold=0.7),
|
||||
min_bbox_size=0),
|
||||
rcnn=dict(
|
||||
score_thr=0.05,
|
||||
nms=dict(type='nms', iou_threshold=0.5),
|
||||
max_per_img=100)
|
||||
# soft-nms is also supported for rcnn testing
|
||||
# e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
|
||||
))
|
||||
|
||||
dataset_type = 'CocoDataset'
|
||||
data_root = 'data/coco'
|
||||
img_norm_cfg = dict(
|
||||
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations', with_bbox=True),
|
||||
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
|
||||
dict(type='RandomFlip', flip_ratio=0.5),
|
||||
dict(type='Normalize', **img_norm_cfg),
|
||||
dict(type='Pad', size_divisor=32),
|
||||
dict(type='DefaultFormatBundle'),
|
||||
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(
|
||||
type='MultiScaleFlipAug',
|
||||
img_scale=(1333, 800),
|
||||
flip=False,
|
||||
transforms=[
|
||||
dict(type='Resize', keep_ratio=True),
|
||||
dict(type='RandomFlip'),
|
||||
dict(type='Normalize', **img_norm_cfg),
|
||||
dict(type='Pad', size_divisor=32),
|
||||
dict(type='DefaultFormatBundle'),
|
||||
dict(type='Collect', keys=['img']),
|
||||
])
|
||||
]
|
||||
data = dict(
|
||||
samples_per_gpu=2,
|
||||
workers_per_gpu=2,
|
||||
train=dict(
|
||||
type=dataset_type,
|
||||
ann_file=f'{data_root}/annotations/instances_train2017.json',
|
||||
img_prefix=f'{data_root}/train2017/',
|
||||
pipeline=train_pipeline),
|
||||
val=dict(
|
||||
type=dataset_type,
|
||||
ann_file=f'{data_root}/annotations/instances_val2017.json',
|
||||
img_prefix=f'{data_root}/val2017/',
|
||||
pipeline=test_pipeline),
|
||||
test=dict(
|
||||
type=dataset_type,
|
||||
ann_file=f'{data_root}/annotations/instances_val2017.json',
|
||||
img_prefix=f'{data_root}/val2017/',
|
||||
pipeline=test_pipeline))
|
||||
evaluation = dict(interval=1, metric='bbox')
|
||||
@@ -1,169 +0,0 @@
|
||||
# _base_ = [
|
||||
# '../../../../_base_/default_runtime.py',
|
||||
# '../../../../_base_/datasets/coco.py'
|
||||
# ]
|
||||
evaluation = dict(interval=10, metric='mAP', save_best='AP')
|
||||
|
||||
optimizer = dict(
|
||||
type='Adam',
|
||||
lr=5e-4,
|
||||
)
|
||||
optimizer_config = dict(grad_clip=None)
|
||||
# learning policy
|
||||
lr_config = dict(
|
||||
policy='step',
|
||||
warmup='linear',
|
||||
warmup_iters=500,
|
||||
warmup_ratio=0.001,
|
||||
step=[170, 200])
|
||||
total_epochs = 210
|
||||
channel_cfg = dict(
|
||||
num_output_channels=17,
|
||||
dataset_joints=17,
|
||||
dataset_channel=[
|
||||
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
|
||||
],
|
||||
inference_channel=[
|
||||
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
|
||||
])
|
||||
|
||||
# model settings
|
||||
model = dict(
|
||||
type='TopDown',
|
||||
pretrained='https://download.openmmlab.com/mmpose/'
|
||||
'pretrain_models/hrnet_w48-8ef0771d.pth',
|
||||
backbone=dict(
|
||||
type='HRNet',
|
||||
in_channels=3,
|
||||
extra=dict(
|
||||
stage1=dict(
|
||||
num_modules=1,
|
||||
num_branches=1,
|
||||
block='BOTTLENECK',
|
||||
num_blocks=(4, ),
|
||||
num_channels=(64, )),
|
||||
stage2=dict(
|
||||
num_modules=1,
|
||||
num_branches=2,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4),
|
||||
num_channels=(48, 96)),
|
||||
stage3=dict(
|
||||
num_modules=4,
|
||||
num_branches=3,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4, 4),
|
||||
num_channels=(48, 96, 192)),
|
||||
stage4=dict(
|
||||
num_modules=3,
|
||||
num_branches=4,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4, 4, 4),
|
||||
num_channels=(48, 96, 192, 384))),
|
||||
),
|
||||
keypoint_head=dict(
|
||||
type='TopdownHeatmapSimpleHead',
|
||||
in_channels=48,
|
||||
out_channels=channel_cfg['num_output_channels'],
|
||||
num_deconv_layers=0,
|
||||
extra=dict(final_conv_kernel=1, ),
|
||||
loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
|
||||
train_cfg=dict(),
|
||||
test_cfg=dict(
|
||||
flip_test=True,
|
||||
post_process='default',
|
||||
shift_heatmap=True,
|
||||
modulate_kernel=11))
|
||||
|
||||
data_cfg = dict(
|
||||
image_size=[192, 256],
|
||||
heatmap_size=[48, 64],
|
||||
num_output_channels=channel_cfg['num_output_channels'],
|
||||
num_joints=channel_cfg['dataset_joints'],
|
||||
dataset_channel=channel_cfg['dataset_channel'],
|
||||
inference_channel=channel_cfg['inference_channel'],
|
||||
soft_nms=False,
|
||||
nms_thr=1.0,
|
||||
oks_thr=0.9,
|
||||
vis_thr=0.2,
|
||||
use_gt_bbox=False,
|
||||
det_bbox_thr=0.0,
|
||||
bbox_file='data/coco/person_detection_results/'
|
||||
'COCO_val2017_detections_AP_H_56_person.json',
|
||||
)
|
||||
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='TopDownGetBboxCenterScale', padding=1.25),
|
||||
dict(type='TopDownRandomShiftBboxCenter', shift_factor=0.16, prob=0.3),
|
||||
dict(type='TopDownRandomFlip', flip_prob=0.5),
|
||||
dict(
|
||||
type='TopDownHalfBodyTransform',
|
||||
num_joints_half_body=8,
|
||||
prob_half_body=0.3),
|
||||
dict(
|
||||
type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
|
||||
dict(type='TopDownAffine'),
|
||||
dict(type='ToTensor'),
|
||||
dict(
|
||||
type='NormalizeTensor',
|
||||
mean=[0.485, 0.456, 0.406],
|
||||
std=[0.229, 0.224, 0.225]),
|
||||
dict(type='TopDownGenerateTarget', sigma=2),
|
||||
dict(
|
||||
type='Collect',
|
||||
keys=['img', 'target', 'target_weight'],
|
||||
meta_keys=[
|
||||
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
||||
'rotation', 'bbox_score', 'flip_pairs'
|
||||
]),
|
||||
]
|
||||
|
||||
val_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='TopDownGetBboxCenterScale', padding=1.25),
|
||||
dict(type='TopDownAffine'),
|
||||
dict(type='ToTensor'),
|
||||
dict(
|
||||
type='NormalizeTensor',
|
||||
mean=[0.485, 0.456, 0.406],
|
||||
std=[0.229, 0.224, 0.225]),
|
||||
dict(
|
||||
type='Collect',
|
||||
keys=['img'],
|
||||
meta_keys=[
|
||||
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
|
||||
'flip_pairs'
|
||||
]),
|
||||
]
|
||||
|
||||
test_pipeline = val_pipeline
|
||||
|
||||
data_root = 'data/coco'
|
||||
data = dict(
|
||||
samples_per_gpu=32,
|
||||
workers_per_gpu=2,
|
||||
val_dataloader=dict(samples_per_gpu=32),
|
||||
test_dataloader=dict(samples_per_gpu=32),
|
||||
train=dict(
|
||||
type='TopDownCocoDataset',
|
||||
ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
|
||||
img_prefix=f'{data_root}/train2017/',
|
||||
data_cfg=data_cfg,
|
||||
pipeline=train_pipeline,
|
||||
dataset_info={{_base_.dataset_info}}),
|
||||
val=dict(
|
||||
type='TopDownCocoDataset',
|
||||
ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
|
||||
img_prefix=f'{data_root}/val2017/',
|
||||
data_cfg=data_cfg,
|
||||
pipeline=val_pipeline,
|
||||
dataset_info={{_base_.dataset_info}}),
|
||||
test=dict(
|
||||
type='TopDownCocoDataset',
|
||||
ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
|
||||
img_prefix=f'{data_root}/val2017/',
|
||||
data_cfg=data_cfg,
|
||||
pipeline=test_pipeline,
|
||||
dataset_info={{_base_.dataset_info}}),
|
||||
)
|
||||
@@ -1,58 +0,0 @@
|
||||
# https://github.com/advimman/lama
|
||||
|
||||
import yaml
|
||||
import torch
|
||||
from omegaconf import OmegaConf
|
||||
import numpy as np
|
||||
|
||||
from einops import rearrange
|
||||
import os
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
from annotator.lama.saicinpainting.training.trainers import load_checkpoint
|
||||
|
||||
|
||||
class LamaInpainting:
|
||||
model_dir = os.path.join(models_path, "lama")
|
||||
|
||||
def __init__(self):
|
||||
self.model = None
|
||||
self.device = devices.get_device_for("controlnet")
|
||||
|
||||
def load_model(self):
|
||||
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/ControlNetLama.pth"
|
||||
modelpath = os.path.join(self.model_dir, "ControlNetLama.pth")
|
||||
if not os.path.exists(modelpath):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=self.model_dir)
|
||||
config_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'config.yaml')
|
||||
cfg = yaml.safe_load(open(config_path, 'rt'))
|
||||
cfg = OmegaConf.create(cfg)
|
||||
cfg.training_model.predict_only = True
|
||||
cfg.visualizer.kind = 'noop'
|
||||
self.model = load_checkpoint(cfg, os.path.abspath(modelpath), strict=False, map_location='cpu')
|
||||
self.model = self.model.to(self.device)
|
||||
self.model.eval()
|
||||
|
||||
def unload_model(self):
|
||||
if self.model is not None:
|
||||
self.model.cpu()
|
||||
|
||||
def __call__(self, input_image):
|
||||
if self.model is None:
|
||||
self.load_model()
|
||||
self.model.to(self.device)
|
||||
color = np.ascontiguousarray(input_image[:, :, 0:3]).astype(np.float32) / 255.0
|
||||
mask = np.ascontiguousarray(input_image[:, :, 3:4]).astype(np.float32) / 255.0
|
||||
with torch.no_grad():
|
||||
color = torch.from_numpy(color).float().to(self.device)
|
||||
mask = torch.from_numpy(mask).float().to(self.device)
|
||||
mask = (mask > 0.5).float()
|
||||
color = color * (1 - mask)
|
||||
image_feed = torch.cat([color, mask], dim=2)
|
||||
image_feed = rearrange(image_feed, 'h w c -> 1 c h w')
|
||||
result = self.model(image_feed)[0]
|
||||
result = rearrange(result, 'c h w -> h w c')
|
||||
result = result * mask + color * (1 - mask)
|
||||
result *= 255.0
|
||||
return result.detach().cpu().numpy().clip(0, 255).astype(np.uint8)
|
||||
@@ -1,157 +0,0 @@
|
||||
run_title: b18_ffc075_batch8x15
|
||||
training_model:
|
||||
kind: default
|
||||
visualize_each_iters: 1000
|
||||
concat_mask: true
|
||||
store_discr_outputs_for_vis: true
|
||||
losses:
|
||||
l1:
|
||||
weight_missing: 0
|
||||
weight_known: 10
|
||||
perceptual:
|
||||
weight: 0
|
||||
adversarial:
|
||||
kind: r1
|
||||
weight: 10
|
||||
gp_coef: 0.001
|
||||
mask_as_fake_target: true
|
||||
allow_scale_mask: true
|
||||
feature_matching:
|
||||
weight: 100
|
||||
resnet_pl:
|
||||
weight: 30
|
||||
weights_path: ${env:TORCH_HOME}
|
||||
|
||||
optimizers:
|
||||
generator:
|
||||
kind: adam
|
||||
lr: 0.001
|
||||
discriminator:
|
||||
kind: adam
|
||||
lr: 0.0001
|
||||
visualizer:
|
||||
key_order:
|
||||
- image
|
||||
- predicted_image
|
||||
- discr_output_fake
|
||||
- discr_output_real
|
||||
- inpainted
|
||||
rescale_keys:
|
||||
- discr_output_fake
|
||||
- discr_output_real
|
||||
kind: directory
|
||||
outdir: /group-volume/User-Driven-Content-Generation/r.suvorov/inpainting/experiments/r.suvorov_2021-04-30_14-41-12_train_simple_pix2pix2_gap_sdpl_novgg_large_b18_ffc075_batch8x15/samples
|
||||
location:
|
||||
data_root_dir: /group-volume/User-Driven-Content-Generation/datasets/inpainting_data_root_large
|
||||
out_root_dir: /group-volume/User-Driven-Content-Generation/${env:USER}/inpainting/experiments
|
||||
tb_dir: /group-volume/User-Driven-Content-Generation/${env:USER}/inpainting/tb_logs
|
||||
data:
|
||||
batch_size: 15
|
||||
val_batch_size: 2
|
||||
num_workers: 3
|
||||
train:
|
||||
indir: ${location.data_root_dir}/train
|
||||
out_size: 256
|
||||
mask_gen_kwargs:
|
||||
irregular_proba: 1
|
||||
irregular_kwargs:
|
||||
max_angle: 4
|
||||
max_len: 200
|
||||
max_width: 100
|
||||
max_times: 5
|
||||
min_times: 1
|
||||
box_proba: 1
|
||||
box_kwargs:
|
||||
margin: 10
|
||||
bbox_min_size: 30
|
||||
bbox_max_size: 150
|
||||
max_times: 3
|
||||
min_times: 1
|
||||
segm_proba: 0
|
||||
segm_kwargs:
|
||||
confidence_threshold: 0.5
|
||||
max_object_area: 0.5
|
||||
min_mask_area: 0.07
|
||||
downsample_levels: 6
|
||||
num_variants_per_mask: 1
|
||||
rigidness_mode: 1
|
||||
max_foreground_coverage: 0.3
|
||||
max_foreground_intersection: 0.7
|
||||
max_mask_intersection: 0.1
|
||||
max_hidden_area: 0.1
|
||||
max_scale_change: 0.25
|
||||
horizontal_flip: true
|
||||
max_vertical_shift: 0.2
|
||||
position_shuffle: true
|
||||
transform_variant: distortions
|
||||
dataloader_kwargs:
|
||||
batch_size: ${data.batch_size}
|
||||
shuffle: true
|
||||
num_workers: ${data.num_workers}
|
||||
val:
|
||||
indir: ${location.data_root_dir}/val
|
||||
img_suffix: .png
|
||||
dataloader_kwargs:
|
||||
batch_size: ${data.val_batch_size}
|
||||
shuffle: false
|
||||
num_workers: ${data.num_workers}
|
||||
visual_test:
|
||||
indir: ${location.data_root_dir}/korean_test
|
||||
img_suffix: _input.png
|
||||
pad_out_to_modulo: 32
|
||||
dataloader_kwargs:
|
||||
batch_size: 1
|
||||
shuffle: false
|
||||
num_workers: ${data.num_workers}
|
||||
generator:
|
||||
kind: ffc_resnet
|
||||
input_nc: 4
|
||||
output_nc: 3
|
||||
ngf: 64
|
||||
n_downsampling: 3
|
||||
n_blocks: 18
|
||||
add_out_act: sigmoid
|
||||
init_conv_kwargs:
|
||||
ratio_gin: 0
|
||||
ratio_gout: 0
|
||||
enable_lfu: false
|
||||
downsample_conv_kwargs:
|
||||
ratio_gin: ${generator.init_conv_kwargs.ratio_gout}
|
||||
ratio_gout: ${generator.downsample_conv_kwargs.ratio_gin}
|
||||
enable_lfu: false
|
||||
resnet_conv_kwargs:
|
||||
ratio_gin: 0.75
|
||||
ratio_gout: ${generator.resnet_conv_kwargs.ratio_gin}
|
||||
enable_lfu: false
|
||||
discriminator:
|
||||
kind: pix2pixhd_nlayer
|
||||
input_nc: 3
|
||||
ndf: 64
|
||||
n_layers: 4
|
||||
evaluator:
|
||||
kind: default
|
||||
inpainted_key: inpainted
|
||||
integral_kind: ssim_fid100_f1
|
||||
trainer:
|
||||
kwargs:
|
||||
gpus: -1
|
||||
accelerator: ddp
|
||||
max_epochs: 200
|
||||
gradient_clip_val: 1
|
||||
log_gpu_memory: None
|
||||
limit_train_batches: 25000
|
||||
val_check_interval: ${trainer.kwargs.limit_train_batches}
|
||||
log_every_n_steps: 1000
|
||||
precision: 32
|
||||
terminate_on_nan: false
|
||||
check_val_every_n_epoch: 1
|
||||
num_sanity_val_steps: 8
|
||||
limit_val_batches: 1000
|
||||
replace_sampler_ddp: false
|
||||
checkpoint_kwargs:
|
||||
verbose: true
|
||||
save_top_k: 5
|
||||
save_last: true
|
||||
period: 1
|
||||
monitor: val_ssim_fid100_f1_total_mean
|
||||
mode: max
|
||||
@@ -1,332 +0,0 @@
|
||||
import math
|
||||
import random
|
||||
import hashlib
|
||||
import logging
|
||||
from enum import Enum
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
# from annotator.lama.saicinpainting.evaluation.masks.mask import SegmentationMask
|
||||
from annotator.lama.saicinpainting.utils import LinearRamp
|
||||
|
||||
LOGGER = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class DrawMethod(Enum):
|
||||
LINE = 'line'
|
||||
CIRCLE = 'circle'
|
||||
SQUARE = 'square'
|
||||
|
||||
|
||||
def make_random_irregular_mask(shape, max_angle=4, max_len=60, max_width=20, min_times=0, max_times=10,
|
||||
draw_method=DrawMethod.LINE):
|
||||
draw_method = DrawMethod(draw_method)
|
||||
|
||||
height, width = shape
|
||||
mask = np.zeros((height, width), np.float32)
|
||||
times = np.random.randint(min_times, max_times + 1)
|
||||
for i in range(times):
|
||||
start_x = np.random.randint(width)
|
||||
start_y = np.random.randint(height)
|
||||
for j in range(1 + np.random.randint(5)):
|
||||
angle = 0.01 + np.random.randint(max_angle)
|
||||
if i % 2 == 0:
|
||||
angle = 2 * 3.1415926 - angle
|
||||
length = 10 + np.random.randint(max_len)
|
||||
brush_w = 5 + np.random.randint(max_width)
|
||||
end_x = np.clip((start_x + length * np.sin(angle)).astype(np.int32), 0, width)
|
||||
end_y = np.clip((start_y + length * np.cos(angle)).astype(np.int32), 0, height)
|
||||
if draw_method == DrawMethod.LINE:
|
||||
cv2.line(mask, (start_x, start_y), (end_x, end_y), 1.0, brush_w)
|
||||
elif draw_method == DrawMethod.CIRCLE:
|
||||
cv2.circle(mask, (start_x, start_y), radius=brush_w, color=1., thickness=-1)
|
||||
elif draw_method == DrawMethod.SQUARE:
|
||||
radius = brush_w // 2
|
||||
mask[start_y - radius:start_y + radius, start_x - radius:start_x + radius] = 1
|
||||
start_x, start_y = end_x, end_y
|
||||
return mask[None, ...]
|
||||
|
||||
|
||||
class RandomIrregularMaskGenerator:
|
||||
def __init__(self, max_angle=4, max_len=60, max_width=20, min_times=0, max_times=10, ramp_kwargs=None,
|
||||
draw_method=DrawMethod.LINE):
|
||||
self.max_angle = max_angle
|
||||
self.max_len = max_len
|
||||
self.max_width = max_width
|
||||
self.min_times = min_times
|
||||
self.max_times = max_times
|
||||
self.draw_method = draw_method
|
||||
self.ramp = LinearRamp(**ramp_kwargs) if ramp_kwargs is not None else None
|
||||
|
||||
def __call__(self, img, iter_i=None, raw_image=None):
|
||||
coef = self.ramp(iter_i) if (self.ramp is not None) and (iter_i is not None) else 1
|
||||
cur_max_len = int(max(1, self.max_len * coef))
|
||||
cur_max_width = int(max(1, self.max_width * coef))
|
||||
cur_max_times = int(self.min_times + 1 + (self.max_times - self.min_times) * coef)
|
||||
return make_random_irregular_mask(img.shape[1:], max_angle=self.max_angle, max_len=cur_max_len,
|
||||
max_width=cur_max_width, min_times=self.min_times, max_times=cur_max_times,
|
||||
draw_method=self.draw_method)
|
||||
|
||||
|
||||
def make_random_rectangle_mask(shape, margin=10, bbox_min_size=30, bbox_max_size=100, min_times=0, max_times=3):
|
||||
height, width = shape
|
||||
mask = np.zeros((height, width), np.float32)
|
||||
bbox_max_size = min(bbox_max_size, height - margin * 2, width - margin * 2)
|
||||
times = np.random.randint(min_times, max_times + 1)
|
||||
for i in range(times):
|
||||
box_width = np.random.randint(bbox_min_size, bbox_max_size)
|
||||
box_height = np.random.randint(bbox_min_size, bbox_max_size)
|
||||
start_x = np.random.randint(margin, width - margin - box_width + 1)
|
||||
start_y = np.random.randint(margin, height - margin - box_height + 1)
|
||||
mask[start_y:start_y + box_height, start_x:start_x + box_width] = 1
|
||||
return mask[None, ...]
|
||||
|
||||
|
||||
class RandomRectangleMaskGenerator:
|
||||
def __init__(self, margin=10, bbox_min_size=30, bbox_max_size=100, min_times=0, max_times=3, ramp_kwargs=None):
|
||||
self.margin = margin
|
||||
self.bbox_min_size = bbox_min_size
|
||||
self.bbox_max_size = bbox_max_size
|
||||
self.min_times = min_times
|
||||
self.max_times = max_times
|
||||
self.ramp = LinearRamp(**ramp_kwargs) if ramp_kwargs is not None else None
|
||||
|
||||
def __call__(self, img, iter_i=None, raw_image=None):
|
||||
coef = self.ramp(iter_i) if (self.ramp is not None) and (iter_i is not None) else 1
|
||||
cur_bbox_max_size = int(self.bbox_min_size + 1 + (self.bbox_max_size - self.bbox_min_size) * coef)
|
||||
cur_max_times = int(self.min_times + (self.max_times - self.min_times) * coef)
|
||||
return make_random_rectangle_mask(img.shape[1:], margin=self.margin, bbox_min_size=self.bbox_min_size,
|
||||
bbox_max_size=cur_bbox_max_size, min_times=self.min_times,
|
||||
max_times=cur_max_times)
|
||||
|
||||
|
||||
class RandomSegmentationMaskGenerator:
|
||||
def __init__(self, **kwargs):
|
||||
self.impl = None # will be instantiated in first call (effectively in subprocess)
|
||||
self.kwargs = kwargs
|
||||
|
||||
def __call__(self, img, iter_i=None, raw_image=None):
|
||||
if self.impl is None:
|
||||
self.impl = SegmentationMask(**self.kwargs)
|
||||
|
||||
masks = self.impl.get_masks(np.transpose(img, (1, 2, 0)))
|
||||
masks = [m for m in masks if len(np.unique(m)) > 1]
|
||||
return np.random.choice(masks)
|
||||
|
||||
|
||||
def make_random_superres_mask(shape, min_step=2, max_step=4, min_width=1, max_width=3):
|
||||
height, width = shape
|
||||
mask = np.zeros((height, width), np.float32)
|
||||
step_x = np.random.randint(min_step, max_step + 1)
|
||||
width_x = np.random.randint(min_width, min(step_x, max_width + 1))
|
||||
offset_x = np.random.randint(0, step_x)
|
||||
|
||||
step_y = np.random.randint(min_step, max_step + 1)
|
||||
width_y = np.random.randint(min_width, min(step_y, max_width + 1))
|
||||
offset_y = np.random.randint(0, step_y)
|
||||
|
||||
for dy in range(width_y):
|
||||
mask[offset_y + dy::step_y] = 1
|
||||
for dx in range(width_x):
|
||||
mask[:, offset_x + dx::step_x] = 1
|
||||
return mask[None, ...]
|
||||
|
||||
|
||||
class RandomSuperresMaskGenerator:
|
||||
def __init__(self, **kwargs):
|
||||
self.kwargs = kwargs
|
||||
|
||||
def __call__(self, img, iter_i=None):
|
||||
return make_random_superres_mask(img.shape[1:], **self.kwargs)
|
||||
|
||||
|
||||
class DumbAreaMaskGenerator:
|
||||
min_ratio = 0.1
|
||||
max_ratio = 0.35
|
||||
default_ratio = 0.225
|
||||
|
||||
def __init__(self, is_training):
|
||||
#Parameters:
|
||||
# is_training(bool): If true - random rectangular mask, if false - central square mask
|
||||
self.is_training = is_training
|
||||
|
||||
def _random_vector(self, dimension):
|
||||
if self.is_training:
|
||||
lower_limit = math.sqrt(self.min_ratio)
|
||||
upper_limit = math.sqrt(self.max_ratio)
|
||||
mask_side = round((random.random() * (upper_limit - lower_limit) + lower_limit) * dimension)
|
||||
u = random.randint(0, dimension-mask_side-1)
|
||||
v = u+mask_side
|
||||
else:
|
||||
margin = (math.sqrt(self.default_ratio) / 2) * dimension
|
||||
u = round(dimension/2 - margin)
|
||||
v = round(dimension/2 + margin)
|
||||
return u, v
|
||||
|
||||
def __call__(self, img, iter_i=None, raw_image=None):
|
||||
c, height, width = img.shape
|
||||
mask = np.zeros((height, width), np.float32)
|
||||
x1, x2 = self._random_vector(width)
|
||||
y1, y2 = self._random_vector(height)
|
||||
mask[x1:x2, y1:y2] = 1
|
||||
return mask[None, ...]
|
||||
|
||||
|
||||
class OutpaintingMaskGenerator:
|
||||
def __init__(self, min_padding_percent:float=0.04, max_padding_percent:int=0.25, left_padding_prob:float=0.5, top_padding_prob:float=0.5,
|
||||
right_padding_prob:float=0.5, bottom_padding_prob:float=0.5, is_fixed_randomness:bool=False):
|
||||
"""
|
||||
is_fixed_randomness - get identical paddings for the same image if args are the same
|
||||
"""
|
||||
self.min_padding_percent = min_padding_percent
|
||||
self.max_padding_percent = max_padding_percent
|
||||
self.probs = [left_padding_prob, top_padding_prob, right_padding_prob, bottom_padding_prob]
|
||||
self.is_fixed_randomness = is_fixed_randomness
|
||||
|
||||
assert self.min_padding_percent <= self.max_padding_percent
|
||||
assert self.max_padding_percent > 0
|
||||
assert len([x for x in [self.min_padding_percent, self.max_padding_percent] if (x>=0 and x<=1)]) == 2, f"Padding percentage should be in [0,1]"
|
||||
assert sum(self.probs) > 0, f"At least one of the padding probs should be greater than 0 - {self.probs}"
|
||||
assert len([x for x in self.probs if (x >= 0) and (x <= 1)]) == 4, f"At least one of padding probs is not in [0,1] - {self.probs}"
|
||||
if len([x for x in self.probs if x > 0]) == 1:
|
||||
LOGGER.warning(f"Only one padding prob is greater than zero - {self.probs}. That means that the outpainting masks will be always on the same side")
|
||||
|
||||
def apply_padding(self, mask, coord):
|
||||
mask[int(coord[0][0]*self.img_h):int(coord[1][0]*self.img_h),
|
||||
int(coord[0][1]*self.img_w):int(coord[1][1]*self.img_w)] = 1
|
||||
return mask
|
||||
|
||||
def get_padding(self, size):
|
||||
n1 = int(self.min_padding_percent*size)
|
||||
n2 = int(self.max_padding_percent*size)
|
||||
return self.rnd.randint(n1, n2) / size
|
||||
|
||||
@staticmethod
|
||||
def _img2rs(img):
|
||||
arr = np.ascontiguousarray(img.astype(np.uint8))
|
||||
str_hash = hashlib.sha1(arr).hexdigest()
|
||||
res = hash(str_hash)%(2**32)
|
||||
return res
|
||||
|
||||
def __call__(self, img, iter_i=None, raw_image=None):
|
||||
c, self.img_h, self.img_w = img.shape
|
||||
mask = np.zeros((self.img_h, self.img_w), np.float32)
|
||||
at_least_one_mask_applied = False
|
||||
|
||||
if self.is_fixed_randomness:
|
||||
assert raw_image is not None, f"Cant calculate hash on raw_image=None"
|
||||
rs = self._img2rs(raw_image)
|
||||
self.rnd = np.random.RandomState(rs)
|
||||
else:
|
||||
self.rnd = np.random
|
||||
|
||||
coords = [[
|
||||
(0,0),
|
||||
(1,self.get_padding(size=self.img_h))
|
||||
],
|
||||
[
|
||||
(0,0),
|
||||
(self.get_padding(size=self.img_w),1)
|
||||
],
|
||||
[
|
||||
(0,1-self.get_padding(size=self.img_h)),
|
||||
(1,1)
|
||||
],
|
||||
[
|
||||
(1-self.get_padding(size=self.img_w),0),
|
||||
(1,1)
|
||||
]]
|
||||
|
||||
for pp, coord in zip(self.probs, coords):
|
||||
if self.rnd.random() < pp:
|
||||
at_least_one_mask_applied = True
|
||||
mask = self.apply_padding(mask=mask, coord=coord)
|
||||
|
||||
if not at_least_one_mask_applied:
|
||||
idx = self.rnd.choice(range(len(coords)), p=np.array(self.probs)/sum(self.probs))
|
||||
mask = self.apply_padding(mask=mask, coord=coords[idx])
|
||||
return mask[None, ...]
|
||||
|
||||
|
||||
class MixedMaskGenerator:
|
||||
def __init__(self, irregular_proba=1/3, irregular_kwargs=None,
|
||||
box_proba=1/3, box_kwargs=None,
|
||||
segm_proba=1/3, segm_kwargs=None,
|
||||
squares_proba=0, squares_kwargs=None,
|
||||
superres_proba=0, superres_kwargs=None,
|
||||
outpainting_proba=0, outpainting_kwargs=None,
|
||||
invert_proba=0):
|
||||
self.probas = []
|
||||
self.gens = []
|
||||
|
||||
if irregular_proba > 0:
|
||||
self.probas.append(irregular_proba)
|
||||
if irregular_kwargs is None:
|
||||
irregular_kwargs = {}
|
||||
else:
|
||||
irregular_kwargs = dict(irregular_kwargs)
|
||||
irregular_kwargs['draw_method'] = DrawMethod.LINE
|
||||
self.gens.append(RandomIrregularMaskGenerator(**irregular_kwargs))
|
||||
|
||||
if box_proba > 0:
|
||||
self.probas.append(box_proba)
|
||||
if box_kwargs is None:
|
||||
box_kwargs = {}
|
||||
self.gens.append(RandomRectangleMaskGenerator(**box_kwargs))
|
||||
|
||||
if segm_proba > 0:
|
||||
self.probas.append(segm_proba)
|
||||
if segm_kwargs is None:
|
||||
segm_kwargs = {}
|
||||
self.gens.append(RandomSegmentationMaskGenerator(**segm_kwargs))
|
||||
|
||||
if squares_proba > 0:
|
||||
self.probas.append(squares_proba)
|
||||
if squares_kwargs is None:
|
||||
squares_kwargs = {}
|
||||
else:
|
||||
squares_kwargs = dict(squares_kwargs)
|
||||
squares_kwargs['draw_method'] = DrawMethod.SQUARE
|
||||
self.gens.append(RandomIrregularMaskGenerator(**squares_kwargs))
|
||||
|
||||
if superres_proba > 0:
|
||||
self.probas.append(superres_proba)
|
||||
if superres_kwargs is None:
|
||||
superres_kwargs = {}
|
||||
self.gens.append(RandomSuperresMaskGenerator(**superres_kwargs))
|
||||
|
||||
if outpainting_proba > 0:
|
||||
self.probas.append(outpainting_proba)
|
||||
if outpainting_kwargs is None:
|
||||
outpainting_kwargs = {}
|
||||
self.gens.append(OutpaintingMaskGenerator(**outpainting_kwargs))
|
||||
|
||||
self.probas = np.array(self.probas, dtype='float32')
|
||||
self.probas /= self.probas.sum()
|
||||
self.invert_proba = invert_proba
|
||||
|
||||
def __call__(self, img, iter_i=None, raw_image=None):
|
||||
kind = np.random.choice(len(self.probas), p=self.probas)
|
||||
gen = self.gens[kind]
|
||||
result = gen(img, iter_i=iter_i, raw_image=raw_image)
|
||||
if self.invert_proba > 0 and random.random() < self.invert_proba:
|
||||
result = 1 - result
|
||||
return result
|
||||
|
||||
|
||||
def get_mask_generator(kind, kwargs):
|
||||
if kind is None:
|
||||
kind = "mixed"
|
||||
if kwargs is None:
|
||||
kwargs = {}
|
||||
|
||||
if kind == "mixed":
|
||||
cl = MixedMaskGenerator
|
||||
elif kind == "outpainting":
|
||||
cl = OutpaintingMaskGenerator
|
||||
elif kind == "dumb":
|
||||
cl = DumbAreaMaskGenerator
|
||||
else:
|
||||
raise NotImplementedError(f"No such generator kind = {kind}")
|
||||
return cl(**kwargs)
|
||||
@@ -1,177 +0,0 @@
|
||||
from typing import Tuple, Dict, Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class BaseAdversarialLoss:
|
||||
def pre_generator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
generator: nn.Module, discriminator: nn.Module):
|
||||
"""
|
||||
Prepare for generator step
|
||||
:param real_batch: Tensor, a batch of real samples
|
||||
:param fake_batch: Tensor, a batch of samples produced by generator
|
||||
:param generator:
|
||||
:param discriminator:
|
||||
:return: None
|
||||
"""
|
||||
|
||||
def pre_discriminator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
generator: nn.Module, discriminator: nn.Module):
|
||||
"""
|
||||
Prepare for discriminator step
|
||||
:param real_batch: Tensor, a batch of real samples
|
||||
:param fake_batch: Tensor, a batch of samples produced by generator
|
||||
:param generator:
|
||||
:param discriminator:
|
||||
:return: None
|
||||
"""
|
||||
|
||||
def generator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
||||
mask: Optional[torch.Tensor] = None) \
|
||||
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
"""
|
||||
Calculate generator loss
|
||||
:param real_batch: Tensor, a batch of real samples
|
||||
:param fake_batch: Tensor, a batch of samples produced by generator
|
||||
:param discr_real_pred: Tensor, discriminator output for real_batch
|
||||
:param discr_fake_pred: Tensor, discriminator output for fake_batch
|
||||
:param mask: Tensor, actual mask, which was at input of generator when making fake_batch
|
||||
:return: total generator loss along with some values that might be interesting to log
|
||||
"""
|
||||
raise NotImplemented()
|
||||
|
||||
def discriminator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
||||
mask: Optional[torch.Tensor] = None) \
|
||||
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
"""
|
||||
Calculate discriminator loss and call .backward() on it
|
||||
:param real_batch: Tensor, a batch of real samples
|
||||
:param fake_batch: Tensor, a batch of samples produced by generator
|
||||
:param discr_real_pred: Tensor, discriminator output for real_batch
|
||||
:param discr_fake_pred: Tensor, discriminator output for fake_batch
|
||||
:param mask: Tensor, actual mask, which was at input of generator when making fake_batch
|
||||
:return: total discriminator loss along with some values that might be interesting to log
|
||||
"""
|
||||
raise NotImplemented()
|
||||
|
||||
def interpolate_mask(self, mask, shape):
|
||||
assert mask is not None
|
||||
assert self.allow_scale_mask or shape == mask.shape[-2:]
|
||||
if shape != mask.shape[-2:] and self.allow_scale_mask:
|
||||
if self.mask_scale_mode == 'maxpool':
|
||||
mask = F.adaptive_max_pool2d(mask, shape)
|
||||
else:
|
||||
mask = F.interpolate(mask, size=shape, mode=self.mask_scale_mode)
|
||||
return mask
|
||||
|
||||
def make_r1_gp(discr_real_pred, real_batch):
|
||||
if torch.is_grad_enabled():
|
||||
grad_real = torch.autograd.grad(outputs=discr_real_pred.sum(), inputs=real_batch, create_graph=True)[0]
|
||||
grad_penalty = (grad_real.view(grad_real.shape[0], -1).norm(2, dim=1) ** 2).mean()
|
||||
else:
|
||||
grad_penalty = 0
|
||||
real_batch.requires_grad = False
|
||||
|
||||
return grad_penalty
|
||||
|
||||
class NonSaturatingWithR1(BaseAdversarialLoss):
|
||||
def __init__(self, gp_coef=5, weight=1, mask_as_fake_target=False, allow_scale_mask=False,
|
||||
mask_scale_mode='nearest', extra_mask_weight_for_gen=0,
|
||||
use_unmasked_for_gen=True, use_unmasked_for_discr=True):
|
||||
self.gp_coef = gp_coef
|
||||
self.weight = weight
|
||||
# use for discr => use for gen;
|
||||
# otherwise we teach only the discr to pay attention to very small difference
|
||||
assert use_unmasked_for_gen or (not use_unmasked_for_discr)
|
||||
# mask as target => use unmasked for discr:
|
||||
# if we don't care about unmasked regions at all
|
||||
# then it doesn't matter if the value of mask_as_fake_target is true or false
|
||||
assert use_unmasked_for_discr or (not mask_as_fake_target)
|
||||
self.use_unmasked_for_gen = use_unmasked_for_gen
|
||||
self.use_unmasked_for_discr = use_unmasked_for_discr
|
||||
self.mask_as_fake_target = mask_as_fake_target
|
||||
self.allow_scale_mask = allow_scale_mask
|
||||
self.mask_scale_mode = mask_scale_mode
|
||||
self.extra_mask_weight_for_gen = extra_mask_weight_for_gen
|
||||
|
||||
def generator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
||||
mask=None) \
|
||||
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
fake_loss = F.softplus(-discr_fake_pred)
|
||||
if (self.mask_as_fake_target and self.extra_mask_weight_for_gen > 0) or \
|
||||
not self.use_unmasked_for_gen: # == if masked region should be treated differently
|
||||
mask = self.interpolate_mask(mask, discr_fake_pred.shape[-2:])
|
||||
if not self.use_unmasked_for_gen:
|
||||
fake_loss = fake_loss * mask
|
||||
else:
|
||||
pixel_weights = 1 + mask * self.extra_mask_weight_for_gen
|
||||
fake_loss = fake_loss * pixel_weights
|
||||
|
||||
return fake_loss.mean() * self.weight, dict()
|
||||
|
||||
def pre_discriminator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
generator: nn.Module, discriminator: nn.Module):
|
||||
real_batch.requires_grad = True
|
||||
|
||||
def discriminator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
||||
mask=None) \
|
||||
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
|
||||
real_loss = F.softplus(-discr_real_pred)
|
||||
grad_penalty = make_r1_gp(discr_real_pred, real_batch) * self.gp_coef
|
||||
fake_loss = F.softplus(discr_fake_pred)
|
||||
|
||||
if not self.use_unmasked_for_discr or self.mask_as_fake_target:
|
||||
# == if masked region should be treated differently
|
||||
mask = self.interpolate_mask(mask, discr_fake_pred.shape[-2:])
|
||||
# use_unmasked_for_discr=False only makes sense for fakes;
|
||||
# for reals there is no difference beetween two regions
|
||||
fake_loss = fake_loss * mask
|
||||
if self.mask_as_fake_target:
|
||||
fake_loss = fake_loss + (1 - mask) * F.softplus(-discr_fake_pred)
|
||||
|
||||
sum_discr_loss = real_loss + grad_penalty + fake_loss
|
||||
metrics = dict(discr_real_out=discr_real_pred.mean(),
|
||||
discr_fake_out=discr_fake_pred.mean(),
|
||||
discr_real_gp=grad_penalty)
|
||||
return sum_discr_loss.mean(), metrics
|
||||
|
||||
class BCELoss(BaseAdversarialLoss):
|
||||
def __init__(self, weight):
|
||||
self.weight = weight
|
||||
self.bce_loss = nn.BCEWithLogitsLoss()
|
||||
|
||||
def generator_loss(self, discr_fake_pred: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
real_mask_gt = torch.zeros(discr_fake_pred.shape).to(discr_fake_pred.device)
|
||||
fake_loss = self.bce_loss(discr_fake_pred, real_mask_gt) * self.weight
|
||||
return fake_loss, dict()
|
||||
|
||||
def pre_discriminator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
||||
generator: nn.Module, discriminator: nn.Module):
|
||||
real_batch.requires_grad = True
|
||||
|
||||
def discriminator_loss(self,
|
||||
mask: torch.Tensor,
|
||||
discr_real_pred: torch.Tensor,
|
||||
discr_fake_pred: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
|
||||
real_mask_gt = torch.zeros(discr_real_pred.shape).to(discr_real_pred.device)
|
||||
sum_discr_loss = (self.bce_loss(discr_real_pred, real_mask_gt) + self.bce_loss(discr_fake_pred, mask)) / 2
|
||||
metrics = dict(discr_real_out=discr_real_pred.mean(),
|
||||
discr_fake_out=discr_fake_pred.mean(),
|
||||
discr_real_gp=0)
|
||||
return sum_discr_loss, metrics
|
||||
|
||||
|
||||
def make_discrim_loss(kind, **kwargs):
|
||||
if kind == 'r1':
|
||||
return NonSaturatingWithR1(**kwargs)
|
||||
elif kind == 'bce':
|
||||
return BCELoss(**kwargs)
|
||||
raise ValueError(f'Unknown adversarial loss kind {kind}')
|
||||
@@ -1,152 +0,0 @@
|
||||
weights = {"ade20k":
|
||||
[6.34517766497462,
|
||||
9.328358208955224,
|
||||
11.389521640091116,
|
||||
16.10305958132045,
|
||||
20.833333333333332,
|
||||
22.22222222222222,
|
||||
25.125628140703515,
|
||||
43.29004329004329,
|
||||
50.5050505050505,
|
||||
54.6448087431694,
|
||||
55.24861878453038,
|
||||
60.24096385542168,
|
||||
62.5,
|
||||
66.2251655629139,
|
||||
84.74576271186442,
|
||||
90.90909090909092,
|
||||
91.74311926605505,
|
||||
96.15384615384616,
|
||||
96.15384615384616,
|
||||
97.08737864077669,
|
||||
102.04081632653062,
|
||||
135.13513513513513,
|
||||
149.2537313432836,
|
||||
153.84615384615384,
|
||||
163.93442622950818,
|
||||
166.66666666666666,
|
||||
188.67924528301887,
|
||||
192.30769230769232,
|
||||
217.3913043478261,
|
||||
227.27272727272725,
|
||||
227.27272727272725,
|
||||
227.27272727272725,
|
||||
303.03030303030306,
|
||||
322.5806451612903,
|
||||
333.3333333333333,
|
||||
370.3703703703703,
|
||||
384.61538461538464,
|
||||
416.6666666666667,
|
||||
416.6666666666667,
|
||||
434.7826086956522,
|
||||
434.7826086956522,
|
||||
454.5454545454545,
|
||||
454.5454545454545,
|
||||
500.0,
|
||||
526.3157894736842,
|
||||
526.3157894736842,
|
||||
555.5555555555555,
|
||||
555.5555555555555,
|
||||
555.5555555555555,
|
||||
555.5555555555555,
|
||||
555.5555555555555,
|
||||
555.5555555555555,
|
||||
555.5555555555555,
|
||||
588.2352941176471,
|
||||
588.2352941176471,
|
||||
588.2352941176471,
|
||||
588.2352941176471,
|
||||
588.2352941176471,
|
||||
666.6666666666666,
|
||||
666.6666666666666,
|
||||
666.6666666666666,
|
||||
666.6666666666666,
|
||||
714.2857142857143,
|
||||
714.2857142857143,
|
||||
714.2857142857143,
|
||||
714.2857142857143,
|
||||
714.2857142857143,
|
||||
769.2307692307693,
|
||||
769.2307692307693,
|
||||
769.2307692307693,
|
||||
833.3333333333334,
|
||||
833.3333333333334,
|
||||
833.3333333333334,
|
||||
833.3333333333334,
|
||||
909.090909090909,
|
||||
1000.0,
|
||||
1111.111111111111,
|
||||
1111.111111111111,
|
||||
1111.111111111111,
|
||||
1111.111111111111,
|
||||
1111.111111111111,
|
||||
1250.0,
|
||||
1250.0,
|
||||
1250.0,
|
||||
1250.0,
|
||||
1250.0,
|
||||
1428.5714285714287,
|
||||
1428.5714285714287,
|
||||
1428.5714285714287,
|
||||
1428.5714285714287,
|
||||
1428.5714285714287,
|
||||
1428.5714285714287,
|
||||
1428.5714285714287,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
1666.6666666666667,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2000.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
2500.0,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
3333.3333333333335,
|
||||
5000.0,
|
||||
5000.0,
|
||||
5000.0]
|
||||
}
|
||||
@@ -1,126 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torchvision
|
||||
|
||||
from annotator.lama.saicinpainting.training.losses.perceptual import IMAGENET_STD, IMAGENET_MEAN
|
||||
|
||||
|
||||
def dummy_distance_weighter(real_img, pred_img, mask):
|
||||
return mask
|
||||
|
||||
|
||||
def get_gauss_kernel(kernel_size, width_factor=1):
|
||||
coords = torch.stack(torch.meshgrid(torch.arange(kernel_size),
|
||||
torch.arange(kernel_size)),
|
||||
dim=0).float()
|
||||
diff = torch.exp(-((coords - kernel_size // 2) ** 2).sum(0) / kernel_size / width_factor)
|
||||
diff /= diff.sum()
|
||||
return diff
|
||||
|
||||
|
||||
class BlurMask(nn.Module):
|
||||
def __init__(self, kernel_size=5, width_factor=1):
|
||||
super().__init__()
|
||||
self.filter = nn.Conv2d(1, 1, kernel_size, padding=kernel_size // 2, padding_mode='replicate', bias=False)
|
||||
self.filter.weight.data.copy_(get_gauss_kernel(kernel_size, width_factor=width_factor))
|
||||
|
||||
def forward(self, real_img, pred_img, mask):
|
||||
with torch.no_grad():
|
||||
result = self.filter(mask) * mask
|
||||
return result
|
||||
|
||||
|
||||
class EmulatedEDTMask(nn.Module):
|
||||
def __init__(self, dilate_kernel_size=5, blur_kernel_size=5, width_factor=1):
|
||||
super().__init__()
|
||||
self.dilate_filter = nn.Conv2d(1, 1, dilate_kernel_size, padding=dilate_kernel_size// 2, padding_mode='replicate',
|
||||
bias=False)
|
||||
self.dilate_filter.weight.data.copy_(torch.ones(1, 1, dilate_kernel_size, dilate_kernel_size, dtype=torch.float))
|
||||
self.blur_filter = nn.Conv2d(1, 1, blur_kernel_size, padding=blur_kernel_size // 2, padding_mode='replicate', bias=False)
|
||||
self.blur_filter.weight.data.copy_(get_gauss_kernel(blur_kernel_size, width_factor=width_factor))
|
||||
|
||||
def forward(self, real_img, pred_img, mask):
|
||||
with torch.no_grad():
|
||||
known_mask = 1 - mask
|
||||
dilated_known_mask = (self.dilate_filter(known_mask) > 1).float()
|
||||
result = self.blur_filter(1 - dilated_known_mask) * mask
|
||||
return result
|
||||
|
||||
|
||||
class PropagatePerceptualSim(nn.Module):
|
||||
def __init__(self, level=2, max_iters=10, temperature=500, erode_mask_size=3):
|
||||
super().__init__()
|
||||
vgg = torchvision.models.vgg19(pretrained=True).features
|
||||
vgg_avg_pooling = []
|
||||
|
||||
for weights in vgg.parameters():
|
||||
weights.requires_grad = False
|
||||
|
||||
cur_level_i = 0
|
||||
for module in vgg.modules():
|
||||
if module.__class__.__name__ == 'Sequential':
|
||||
continue
|
||||
elif module.__class__.__name__ == 'MaxPool2d':
|
||||
vgg_avg_pooling.append(nn.AvgPool2d(kernel_size=2, stride=2, padding=0))
|
||||
else:
|
||||
vgg_avg_pooling.append(module)
|
||||
if module.__class__.__name__ == 'ReLU':
|
||||
cur_level_i += 1
|
||||
if cur_level_i == level:
|
||||
break
|
||||
|
||||
self.features = nn.Sequential(*vgg_avg_pooling)
|
||||
|
||||
self.max_iters = max_iters
|
||||
self.temperature = temperature
|
||||
self.do_erode = erode_mask_size > 0
|
||||
if self.do_erode:
|
||||
self.erode_mask = nn.Conv2d(1, 1, erode_mask_size, padding=erode_mask_size // 2, bias=False)
|
||||
self.erode_mask.weight.data.fill_(1)
|
||||
|
||||
def forward(self, real_img, pred_img, mask):
|
||||
with torch.no_grad():
|
||||
real_img = (real_img - IMAGENET_MEAN.to(real_img)) / IMAGENET_STD.to(real_img)
|
||||
real_feats = self.features(real_img)
|
||||
|
||||
vertical_sim = torch.exp(-(real_feats[:, :, 1:] - real_feats[:, :, :-1]).pow(2).sum(1, keepdim=True)
|
||||
/ self.temperature)
|
||||
horizontal_sim = torch.exp(-(real_feats[:, :, :, 1:] - real_feats[:, :, :, :-1]).pow(2).sum(1, keepdim=True)
|
||||
/ self.temperature)
|
||||
|
||||
mask_scaled = F.interpolate(mask, size=real_feats.shape[-2:], mode='bilinear', align_corners=False)
|
||||
if self.do_erode:
|
||||
mask_scaled = (self.erode_mask(mask_scaled) > 1).float()
|
||||
|
||||
cur_knowness = 1 - mask_scaled
|
||||
|
||||
for iter_i in range(self.max_iters):
|
||||
new_top_knowness = F.pad(cur_knowness[:, :, :-1] * vertical_sim, (0, 0, 1, 0), mode='replicate')
|
||||
new_bottom_knowness = F.pad(cur_knowness[:, :, 1:] * vertical_sim, (0, 0, 0, 1), mode='replicate')
|
||||
|
||||
new_left_knowness = F.pad(cur_knowness[:, :, :, :-1] * horizontal_sim, (1, 0, 0, 0), mode='replicate')
|
||||
new_right_knowness = F.pad(cur_knowness[:, :, :, 1:] * horizontal_sim, (0, 1, 0, 0), mode='replicate')
|
||||
|
||||
new_knowness = torch.stack([new_top_knowness, new_bottom_knowness,
|
||||
new_left_knowness, new_right_knowness],
|
||||
dim=0).max(0).values
|
||||
|
||||
cur_knowness = torch.max(cur_knowness, new_knowness)
|
||||
|
||||
cur_knowness = F.interpolate(cur_knowness, size=mask.shape[-2:], mode='bilinear')
|
||||
result = torch.min(mask, 1 - cur_knowness)
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def make_mask_distance_weighter(kind='none', **kwargs):
|
||||
if kind == 'none':
|
||||
return dummy_distance_weighter
|
||||
if kind == 'blur':
|
||||
return BlurMask(**kwargs)
|
||||
if kind == 'edt':
|
||||
return EmulatedEDTMask(**kwargs)
|
||||
if kind == 'pps':
|
||||
return PropagatePerceptualSim(**kwargs)
|
||||
raise ValueError(f'Unknown mask distance weighter kind {kind}')
|
||||
@@ -1,33 +0,0 @@
|
||||
from typing import List
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
def masked_l2_loss(pred, target, mask, weight_known, weight_missing):
|
||||
per_pixel_l2 = F.mse_loss(pred, target, reduction='none')
|
||||
pixel_weights = mask * weight_missing + (1 - mask) * weight_known
|
||||
return (pixel_weights * per_pixel_l2).mean()
|
||||
|
||||
|
||||
def masked_l1_loss(pred, target, mask, weight_known, weight_missing):
|
||||
per_pixel_l1 = F.l1_loss(pred, target, reduction='none')
|
||||
pixel_weights = mask * weight_missing + (1 - mask) * weight_known
|
||||
return (pixel_weights * per_pixel_l1).mean()
|
||||
|
||||
|
||||
def feature_matching_loss(fake_features: List[torch.Tensor], target_features: List[torch.Tensor], mask=None):
|
||||
if mask is None:
|
||||
res = torch.stack([F.mse_loss(fake_feat, target_feat)
|
||||
for fake_feat, target_feat in zip(fake_features, target_features)]).mean()
|
||||
else:
|
||||
res = 0
|
||||
norm = 0
|
||||
for fake_feat, target_feat in zip(fake_features, target_features):
|
||||
cur_mask = F.interpolate(mask, size=fake_feat.shape[-2:], mode='bilinear', align_corners=False)
|
||||
error_weights = 1 - cur_mask
|
||||
cur_val = ((fake_feat - target_feat).pow(2) * error_weights).mean()
|
||||
res = res + cur_val
|
||||
norm += 1
|
||||
res = res / norm
|
||||
return res
|
||||
@@ -1,113 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torchvision
|
||||
|
||||
# from models.ade20k import ModelBuilder
|
||||
from annotator.lama.saicinpainting.utils import check_and_warn_input_range
|
||||
|
||||
|
||||
IMAGENET_MEAN = torch.FloatTensor([0.485, 0.456, 0.406])[None, :, None, None]
|
||||
IMAGENET_STD = torch.FloatTensor([0.229, 0.224, 0.225])[None, :, None, None]
|
||||
|
||||
|
||||
class PerceptualLoss(nn.Module):
|
||||
def __init__(self, normalize_inputs=True):
|
||||
super(PerceptualLoss, self).__init__()
|
||||
|
||||
self.normalize_inputs = normalize_inputs
|
||||
self.mean_ = IMAGENET_MEAN
|
||||
self.std_ = IMAGENET_STD
|
||||
|
||||
vgg = torchvision.models.vgg19(pretrained=True).features
|
||||
vgg_avg_pooling = []
|
||||
|
||||
for weights in vgg.parameters():
|
||||
weights.requires_grad = False
|
||||
|
||||
for module in vgg.modules():
|
||||
if module.__class__.__name__ == 'Sequential':
|
||||
continue
|
||||
elif module.__class__.__name__ == 'MaxPool2d':
|
||||
vgg_avg_pooling.append(nn.AvgPool2d(kernel_size=2, stride=2, padding=0))
|
||||
else:
|
||||
vgg_avg_pooling.append(module)
|
||||
|
||||
self.vgg = nn.Sequential(*vgg_avg_pooling)
|
||||
|
||||
def do_normalize_inputs(self, x):
|
||||
return (x - self.mean_.to(x.device)) / self.std_.to(x.device)
|
||||
|
||||
def partial_losses(self, input, target, mask=None):
|
||||
check_and_warn_input_range(target, 0, 1, 'PerceptualLoss target in partial_losses')
|
||||
|
||||
# we expect input and target to be in [0, 1] range
|
||||
losses = []
|
||||
|
||||
if self.normalize_inputs:
|
||||
features_input = self.do_normalize_inputs(input)
|
||||
features_target = self.do_normalize_inputs(target)
|
||||
else:
|
||||
features_input = input
|
||||
features_target = target
|
||||
|
||||
for layer in self.vgg[:30]:
|
||||
|
||||
features_input = layer(features_input)
|
||||
features_target = layer(features_target)
|
||||
|
||||
if layer.__class__.__name__ == 'ReLU':
|
||||
loss = F.mse_loss(features_input, features_target, reduction='none')
|
||||
|
||||
if mask is not None:
|
||||
cur_mask = F.interpolate(mask, size=features_input.shape[-2:],
|
||||
mode='bilinear', align_corners=False)
|
||||
loss = loss * (1 - cur_mask)
|
||||
|
||||
loss = loss.mean(dim=tuple(range(1, len(loss.shape))))
|
||||
losses.append(loss)
|
||||
|
||||
return losses
|
||||
|
||||
def forward(self, input, target, mask=None):
|
||||
losses = self.partial_losses(input, target, mask=mask)
|
||||
return torch.stack(losses).sum(dim=0)
|
||||
|
||||
def get_global_features(self, input):
|
||||
check_and_warn_input_range(input, 0, 1, 'PerceptualLoss input in get_global_features')
|
||||
|
||||
if self.normalize_inputs:
|
||||
features_input = self.do_normalize_inputs(input)
|
||||
else:
|
||||
features_input = input
|
||||
|
||||
features_input = self.vgg(features_input)
|
||||
return features_input
|
||||
|
||||
|
||||
class ResNetPL(nn.Module):
|
||||
def __init__(self, weight=1,
|
||||
weights_path=None, arch_encoder='resnet50dilated', segmentation=True):
|
||||
super().__init__()
|
||||
self.impl = ModelBuilder.get_encoder(weights_path=weights_path,
|
||||
arch_encoder=arch_encoder,
|
||||
arch_decoder='ppm_deepsup',
|
||||
fc_dim=2048,
|
||||
segmentation=segmentation)
|
||||
self.impl.eval()
|
||||
for w in self.impl.parameters():
|
||||
w.requires_grad_(False)
|
||||
|
||||
self.weight = weight
|
||||
|
||||
def forward(self, pred, target):
|
||||
pred = (pred - IMAGENET_MEAN.to(pred)) / IMAGENET_STD.to(pred)
|
||||
target = (target - IMAGENET_MEAN.to(target)) / IMAGENET_STD.to(target)
|
||||
|
||||
pred_feats = self.impl(pred, return_feature_maps=True)
|
||||
target_feats = self.impl(target, return_feature_maps=True)
|
||||
|
||||
result = torch.stack([F.mse_loss(cur_pred, cur_target)
|
||||
for cur_pred, cur_target
|
||||
in zip(pred_feats, target_feats)]).sum() * self.weight
|
||||
return result
|
||||
@@ -1,43 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from .constants import weights as constant_weights
|
||||
|
||||
|
||||
class CrossEntropy2d(nn.Module):
|
||||
def __init__(self, reduction="mean", ignore_label=255, weights=None, *args, **kwargs):
|
||||
"""
|
||||
weight (Tensor, optional): a manual rescaling weight given to each class.
|
||||
If given, has to be a Tensor of size "nclasses"
|
||||
"""
|
||||
super(CrossEntropy2d, self).__init__()
|
||||
self.reduction = reduction
|
||||
self.ignore_label = ignore_label
|
||||
self.weights = weights
|
||||
if self.weights is not None:
|
||||
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
self.weights = torch.FloatTensor(constant_weights[weights]).to(device)
|
||||
|
||||
def forward(self, predict, target):
|
||||
"""
|
||||
Args:
|
||||
predict:(n, c, h, w)
|
||||
target:(n, 1, h, w)
|
||||
"""
|
||||
target = target.long()
|
||||
assert not target.requires_grad
|
||||
assert predict.dim() == 4, "{0}".format(predict.size())
|
||||
assert target.dim() == 4, "{0}".format(target.size())
|
||||
assert predict.size(0) == target.size(0), "{0} vs {1} ".format(predict.size(0), target.size(0))
|
||||
assert target.size(1) == 1, "{0}".format(target.size(1))
|
||||
assert predict.size(2) == target.size(2), "{0} vs {1} ".format(predict.size(2), target.size(2))
|
||||
assert predict.size(3) == target.size(3), "{0} vs {1} ".format(predict.size(3), target.size(3))
|
||||
target = target.squeeze(1)
|
||||
n, c, h, w = predict.size()
|
||||
target_mask = (target >= 0) * (target != self.ignore_label)
|
||||
target = target[target_mask]
|
||||
predict = predict.transpose(1, 2).transpose(2, 3).contiguous()
|
||||
predict = predict[target_mask.view(n, h, w, 1).repeat(1, 1, 1, c)].view(-1, c)
|
||||
loss = F.cross_entropy(predict, target, weight=self.weights, reduction=self.reduction)
|
||||
return loss
|
||||
@@ -1,155 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torchvision.models as models
|
||||
|
||||
|
||||
class PerceptualLoss(nn.Module):
|
||||
r"""
|
||||
Perceptual loss, VGG-based
|
||||
https://arxiv.org/abs/1603.08155
|
||||
https://github.com/dxyang/StyleTransfer/blob/master/utils.py
|
||||
"""
|
||||
|
||||
def __init__(self, weights=[1.0, 1.0, 1.0, 1.0, 1.0]):
|
||||
super(PerceptualLoss, self).__init__()
|
||||
self.add_module('vgg', VGG19())
|
||||
self.criterion = torch.nn.L1Loss()
|
||||
self.weights = weights
|
||||
|
||||
def __call__(self, x, y):
|
||||
# Compute features
|
||||
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
|
||||
|
||||
content_loss = 0.0
|
||||
content_loss += self.weights[0] * self.criterion(x_vgg['relu1_1'], y_vgg['relu1_1'])
|
||||
content_loss += self.weights[1] * self.criterion(x_vgg['relu2_1'], y_vgg['relu2_1'])
|
||||
content_loss += self.weights[2] * self.criterion(x_vgg['relu3_1'], y_vgg['relu3_1'])
|
||||
content_loss += self.weights[3] * self.criterion(x_vgg['relu4_1'], y_vgg['relu4_1'])
|
||||
content_loss += self.weights[4] * self.criterion(x_vgg['relu5_1'], y_vgg['relu5_1'])
|
||||
|
||||
|
||||
return content_loss
|
||||
|
||||
|
||||
class VGG19(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super(VGG19, self).__init__()
|
||||
features = models.vgg19(pretrained=True).features
|
||||
self.relu1_1 = torch.nn.Sequential()
|
||||
self.relu1_2 = torch.nn.Sequential()
|
||||
|
||||
self.relu2_1 = torch.nn.Sequential()
|
||||
self.relu2_2 = torch.nn.Sequential()
|
||||
|
||||
self.relu3_1 = torch.nn.Sequential()
|
||||
self.relu3_2 = torch.nn.Sequential()
|
||||
self.relu3_3 = torch.nn.Sequential()
|
||||
self.relu3_4 = torch.nn.Sequential()
|
||||
|
||||
self.relu4_1 = torch.nn.Sequential()
|
||||
self.relu4_2 = torch.nn.Sequential()
|
||||
self.relu4_3 = torch.nn.Sequential()
|
||||
self.relu4_4 = torch.nn.Sequential()
|
||||
|
||||
self.relu5_1 = torch.nn.Sequential()
|
||||
self.relu5_2 = torch.nn.Sequential()
|
||||
self.relu5_3 = torch.nn.Sequential()
|
||||
self.relu5_4 = torch.nn.Sequential()
|
||||
|
||||
for x in range(2):
|
||||
self.relu1_1.add_module(str(x), features[x])
|
||||
|
||||
for x in range(2, 4):
|
||||
self.relu1_2.add_module(str(x), features[x])
|
||||
|
||||
for x in range(4, 7):
|
||||
self.relu2_1.add_module(str(x), features[x])
|
||||
|
||||
for x in range(7, 9):
|
||||
self.relu2_2.add_module(str(x), features[x])
|
||||
|
||||
for x in range(9, 12):
|
||||
self.relu3_1.add_module(str(x), features[x])
|
||||
|
||||
for x in range(12, 14):
|
||||
self.relu3_2.add_module(str(x), features[x])
|
||||
|
||||
for x in range(14, 16):
|
||||
self.relu3_2.add_module(str(x), features[x])
|
||||
|
||||
for x in range(16, 18):
|
||||
self.relu3_4.add_module(str(x), features[x])
|
||||
|
||||
for x in range(18, 21):
|
||||
self.relu4_1.add_module(str(x), features[x])
|
||||
|
||||
for x in range(21, 23):
|
||||
self.relu4_2.add_module(str(x), features[x])
|
||||
|
||||
for x in range(23, 25):
|
||||
self.relu4_3.add_module(str(x), features[x])
|
||||
|
||||
for x in range(25, 27):
|
||||
self.relu4_4.add_module(str(x), features[x])
|
||||
|
||||
for x in range(27, 30):
|
||||
self.relu5_1.add_module(str(x), features[x])
|
||||
|
||||
for x in range(30, 32):
|
||||
self.relu5_2.add_module(str(x), features[x])
|
||||
|
||||
for x in range(32, 34):
|
||||
self.relu5_3.add_module(str(x), features[x])
|
||||
|
||||
for x in range(34, 36):
|
||||
self.relu5_4.add_module(str(x), features[x])
|
||||
|
||||
# don't need the gradients, just want the features
|
||||
for param in self.parameters():
|
||||
param.requires_grad = False
|
||||
|
||||
def forward(self, x):
|
||||
relu1_1 = self.relu1_1(x)
|
||||
relu1_2 = self.relu1_2(relu1_1)
|
||||
|
||||
relu2_1 = self.relu2_1(relu1_2)
|
||||
relu2_2 = self.relu2_2(relu2_1)
|
||||
|
||||
relu3_1 = self.relu3_1(relu2_2)
|
||||
relu3_2 = self.relu3_2(relu3_1)
|
||||
relu3_3 = self.relu3_3(relu3_2)
|
||||
relu3_4 = self.relu3_4(relu3_3)
|
||||
|
||||
relu4_1 = self.relu4_1(relu3_4)
|
||||
relu4_2 = self.relu4_2(relu4_1)
|
||||
relu4_3 = self.relu4_3(relu4_2)
|
||||
relu4_4 = self.relu4_4(relu4_3)
|
||||
|
||||
relu5_1 = self.relu5_1(relu4_4)
|
||||
relu5_2 = self.relu5_2(relu5_1)
|
||||
relu5_3 = self.relu5_3(relu5_2)
|
||||
relu5_4 = self.relu5_4(relu5_3)
|
||||
|
||||
out = {
|
||||
'relu1_1': relu1_1,
|
||||
'relu1_2': relu1_2,
|
||||
|
||||
'relu2_1': relu2_1,
|
||||
'relu2_2': relu2_2,
|
||||
|
||||
'relu3_1': relu3_1,
|
||||
'relu3_2': relu3_2,
|
||||
'relu3_3': relu3_3,
|
||||
'relu3_4': relu3_4,
|
||||
|
||||
'relu4_1': relu4_1,
|
||||
'relu4_2': relu4_2,
|
||||
'relu4_3': relu4_3,
|
||||
'relu4_4': relu4_4,
|
||||
|
||||
'relu5_1': relu5_1,
|
||||
'relu5_2': relu5_2,
|
||||
'relu5_3': relu5_3,
|
||||
'relu5_4': relu5_4,
|
||||
}
|
||||
return out
|
||||
@@ -1,31 +0,0 @@
|
||||
import logging
|
||||
|
||||
from annotator.lama.saicinpainting.training.modules.ffc import FFCResNetGenerator
|
||||
from annotator.lama.saicinpainting.training.modules.pix2pixhd import GlobalGenerator, MultiDilatedGlobalGenerator, \
|
||||
NLayerDiscriminator, MultidilatedNLayerDiscriminator
|
||||
|
||||
def make_generator(config, kind, **kwargs):
|
||||
logging.info(f'Make generator {kind}')
|
||||
|
||||
if kind == 'pix2pixhd_multidilated':
|
||||
return MultiDilatedGlobalGenerator(**kwargs)
|
||||
|
||||
if kind == 'pix2pixhd_global':
|
||||
return GlobalGenerator(**kwargs)
|
||||
|
||||
if kind == 'ffc_resnet':
|
||||
return FFCResNetGenerator(**kwargs)
|
||||
|
||||
raise ValueError(f'Unknown generator kind {kind}')
|
||||
|
||||
|
||||
def make_discriminator(kind, **kwargs):
|
||||
logging.info(f'Make discriminator {kind}')
|
||||
|
||||
if kind == 'pix2pixhd_nlayer_multidilated':
|
||||
return MultidilatedNLayerDiscriminator(**kwargs)
|
||||
|
||||
if kind == 'pix2pixhd_nlayer':
|
||||
return NLayerDiscriminator(**kwargs)
|
||||
|
||||
raise ValueError(f'Unknown discriminator kind {kind}')
|
||||
@@ -1,80 +0,0 @@
|
||||
import abc
|
||||
from typing import Tuple, List
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from annotator.lama.saicinpainting.training.modules.depthwise_sep_conv import DepthWiseSeperableConv
|
||||
from annotator.lama.saicinpainting.training.modules.multidilated_conv import MultidilatedConv
|
||||
|
||||
|
||||
class BaseDiscriminator(nn.Module):
|
||||
@abc.abstractmethod
|
||||
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
|
||||
"""
|
||||
Predict scores and get intermediate activations. Useful for feature matching loss
|
||||
:return tuple (scores, list of intermediate activations)
|
||||
"""
|
||||
raise NotImplemented()
|
||||
|
||||
|
||||
def get_conv_block_ctor(kind='default'):
|
||||
if not isinstance(kind, str):
|
||||
return kind
|
||||
if kind == 'default':
|
||||
return nn.Conv2d
|
||||
if kind == 'depthwise':
|
||||
return DepthWiseSeperableConv
|
||||
if kind == 'multidilated':
|
||||
return MultidilatedConv
|
||||
raise ValueError(f'Unknown convolutional block kind {kind}')
|
||||
|
||||
|
||||
def get_norm_layer(kind='bn'):
|
||||
if not isinstance(kind, str):
|
||||
return kind
|
||||
if kind == 'bn':
|
||||
return nn.BatchNorm2d
|
||||
if kind == 'in':
|
||||
return nn.InstanceNorm2d
|
||||
raise ValueError(f'Unknown norm block kind {kind}')
|
||||
|
||||
|
||||
def get_activation(kind='tanh'):
|
||||
if kind == 'tanh':
|
||||
return nn.Tanh()
|
||||
if kind == 'sigmoid':
|
||||
return nn.Sigmoid()
|
||||
if kind is False:
|
||||
return nn.Identity()
|
||||
raise ValueError(f'Unknown activation kind {kind}')
|
||||
|
||||
|
||||
class SimpleMultiStepGenerator(nn.Module):
|
||||
def __init__(self, steps: List[nn.Module]):
|
||||
super().__init__()
|
||||
self.steps = nn.ModuleList(steps)
|
||||
|
||||
def forward(self, x):
|
||||
cur_in = x
|
||||
outs = []
|
||||
for step in self.steps:
|
||||
cur_out = step(cur_in)
|
||||
outs.append(cur_out)
|
||||
cur_in = torch.cat((cur_in, cur_out), dim=1)
|
||||
return torch.cat(outs[::-1], dim=1)
|
||||
|
||||
def deconv_factory(kind, ngf, mult, norm_layer, activation, max_features):
|
||||
if kind == 'convtranspose':
|
||||
return [nn.ConvTranspose2d(min(max_features, ngf * mult),
|
||||
min(max_features, int(ngf * mult / 2)),
|
||||
kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
norm_layer(min(max_features, int(ngf * mult / 2))), activation]
|
||||
elif kind == 'bilinear':
|
||||
return [nn.Upsample(scale_factor=2, mode='bilinear'),
|
||||
DepthWiseSeperableConv(min(max_features, ngf * mult),
|
||||
min(max_features, int(ngf * mult / 2)),
|
||||
kernel_size=3, stride=1, padding=1),
|
||||
norm_layer(min(max_features, int(ngf * mult / 2))), activation]
|
||||
else:
|
||||
raise Exception(f"Invalid deconv kind: {kind}")
|
||||
@@ -1,17 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
class DepthWiseSeperableConv(nn.Module):
|
||||
def __init__(self, in_dim, out_dim, *args, **kwargs):
|
||||
super().__init__()
|
||||
if 'groups' in kwargs:
|
||||
# ignoring groups for Depthwise Sep Conv
|
||||
del kwargs['groups']
|
||||
|
||||
self.depthwise = nn.Conv2d(in_dim, in_dim, *args, groups=in_dim, **kwargs)
|
||||
self.pointwise = nn.Conv2d(in_dim, out_dim, kernel_size=1)
|
||||
|
||||
def forward(self, x):
|
||||
out = self.depthwise(x)
|
||||
out = self.pointwise(out)
|
||||
return out
|
||||
@@ -1,47 +0,0 @@
|
||||
import torch
|
||||
from kornia import SamplePadding
|
||||
from kornia.augmentation import RandomAffine, CenterCrop
|
||||
|
||||
|
||||
class FakeFakesGenerator:
|
||||
def __init__(self, aug_proba=0.5, img_aug_degree=30, img_aug_translate=0.2):
|
||||
self.grad_aug = RandomAffine(degrees=360,
|
||||
translate=0.2,
|
||||
padding_mode=SamplePadding.REFLECTION,
|
||||
keepdim=False,
|
||||
p=1)
|
||||
self.img_aug = RandomAffine(degrees=img_aug_degree,
|
||||
translate=img_aug_translate,
|
||||
padding_mode=SamplePadding.REFLECTION,
|
||||
keepdim=True,
|
||||
p=1)
|
||||
self.aug_proba = aug_proba
|
||||
|
||||
def __call__(self, input_images, masks):
|
||||
blend_masks = self._fill_masks_with_gradient(masks)
|
||||
blend_target = self._make_blend_target(input_images)
|
||||
result = input_images * (1 - blend_masks) + blend_target * blend_masks
|
||||
return result, blend_masks
|
||||
|
||||
def _make_blend_target(self, input_images):
|
||||
batch_size = input_images.shape[0]
|
||||
permuted = input_images[torch.randperm(batch_size)]
|
||||
augmented = self.img_aug(input_images)
|
||||
is_aug = (torch.rand(batch_size, device=input_images.device)[:, None, None, None] < self.aug_proba).float()
|
||||
result = augmented * is_aug + permuted * (1 - is_aug)
|
||||
return result
|
||||
|
||||
def _fill_masks_with_gradient(self, masks):
|
||||
batch_size, _, height, width = masks.shape
|
||||
grad = torch.linspace(0, 1, steps=width * 2, device=masks.device, dtype=masks.dtype) \
|
||||
.view(1, 1, 1, -1).expand(batch_size, 1, height * 2, width * 2)
|
||||
grad = self.grad_aug(grad)
|
||||
grad = CenterCrop((height, width))(grad)
|
||||
grad *= masks
|
||||
|
||||
grad_for_min = grad + (1 - masks) * 10
|
||||
grad -= grad_for_min.view(batch_size, -1).min(-1).values[:, None, None, None]
|
||||
grad /= grad.view(batch_size, -1).max(-1).values[:, None, None, None] + 1e-6
|
||||
grad.clamp_(min=0, max=1)
|
||||
|
||||
return grad
|
||||
@@ -1,485 +0,0 @@
|
||||
# Fast Fourier Convolution NeurIPS 2020
|
||||
# original implementation https://github.com/pkumivision/FFC/blob/main/model_zoo/ffc.py
|
||||
# paper https://proceedings.neurips.cc/paper/2020/file/2fd5d41ec6cfab47e32164d5624269b1-Paper.pdf
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from annotator.lama.saicinpainting.training.modules.base import get_activation, BaseDiscriminator
|
||||
from annotator.lama.saicinpainting.training.modules.spatial_transform import LearnableSpatialTransformWrapper
|
||||
from annotator.lama.saicinpainting.training.modules.squeeze_excitation import SELayer
|
||||
from annotator.lama.saicinpainting.utils import get_shape
|
||||
|
||||
|
||||
class FFCSE_block(nn.Module):
|
||||
|
||||
def __init__(self, channels, ratio_g):
|
||||
super(FFCSE_block, self).__init__()
|
||||
in_cg = int(channels * ratio_g)
|
||||
in_cl = channels - in_cg
|
||||
r = 16
|
||||
|
||||
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
|
||||
self.conv1 = nn.Conv2d(channels, channels // r,
|
||||
kernel_size=1, bias=True)
|
||||
self.relu1 = nn.ReLU(inplace=True)
|
||||
self.conv_a2l = None if in_cl == 0 else nn.Conv2d(
|
||||
channels // r, in_cl, kernel_size=1, bias=True)
|
||||
self.conv_a2g = None if in_cg == 0 else nn.Conv2d(
|
||||
channels // r, in_cg, kernel_size=1, bias=True)
|
||||
self.sigmoid = nn.Sigmoid()
|
||||
|
||||
def forward(self, x):
|
||||
x = x if type(x) is tuple else (x, 0)
|
||||
id_l, id_g = x
|
||||
|
||||
x = id_l if type(id_g) is int else torch.cat([id_l, id_g], dim=1)
|
||||
x = self.avgpool(x)
|
||||
x = self.relu1(self.conv1(x))
|
||||
|
||||
x_l = 0 if self.conv_a2l is None else id_l * \
|
||||
self.sigmoid(self.conv_a2l(x))
|
||||
x_g = 0 if self.conv_a2g is None else id_g * \
|
||||
self.sigmoid(self.conv_a2g(x))
|
||||
return x_l, x_g
|
||||
|
||||
|
||||
class FourierUnit(nn.Module):
|
||||
|
||||
def __init__(self, in_channels, out_channels, groups=1, spatial_scale_factor=None, spatial_scale_mode='bilinear',
|
||||
spectral_pos_encoding=False, use_se=False, se_kwargs=None, ffc3d=False, fft_norm='ortho'):
|
||||
# bn_layer not used
|
||||
super(FourierUnit, self).__init__()
|
||||
self.groups = groups
|
||||
|
||||
self.conv_layer = torch.nn.Conv2d(in_channels=in_channels * 2 + (2 if spectral_pos_encoding else 0),
|
||||
out_channels=out_channels * 2,
|
||||
kernel_size=1, stride=1, padding=0, groups=self.groups, bias=False)
|
||||
self.bn = torch.nn.BatchNorm2d(out_channels * 2)
|
||||
self.relu = torch.nn.ReLU(inplace=True)
|
||||
|
||||
# squeeze and excitation block
|
||||
self.use_se = use_se
|
||||
if use_se:
|
||||
if se_kwargs is None:
|
||||
se_kwargs = {}
|
||||
self.se = SELayer(self.conv_layer.in_channels, **se_kwargs)
|
||||
|
||||
self.spatial_scale_factor = spatial_scale_factor
|
||||
self.spatial_scale_mode = spatial_scale_mode
|
||||
self.spectral_pos_encoding = spectral_pos_encoding
|
||||
self.ffc3d = ffc3d
|
||||
self.fft_norm = fft_norm
|
||||
|
||||
def forward(self, x):
|
||||
batch = x.shape[0]
|
||||
|
||||
if self.spatial_scale_factor is not None:
|
||||
orig_size = x.shape[-2:]
|
||||
x = F.interpolate(x, scale_factor=self.spatial_scale_factor, mode=self.spatial_scale_mode, align_corners=False)
|
||||
|
||||
r_size = x.size()
|
||||
# (batch, c, h, w/2+1, 2)
|
||||
fft_dim = (-3, -2, -1) if self.ffc3d else (-2, -1)
|
||||
ffted = torch.fft.rfftn(x, dim=fft_dim, norm=self.fft_norm)
|
||||
ffted = torch.stack((ffted.real, ffted.imag), dim=-1)
|
||||
ffted = ffted.permute(0, 1, 4, 2, 3).contiguous() # (batch, c, 2, h, w/2+1)
|
||||
ffted = ffted.view((batch, -1,) + ffted.size()[3:])
|
||||
|
||||
if self.spectral_pos_encoding:
|
||||
height, width = ffted.shape[-2:]
|
||||
coords_vert = torch.linspace(0, 1, height)[None, None, :, None].expand(batch, 1, height, width).to(ffted)
|
||||
coords_hor = torch.linspace(0, 1, width)[None, None, None, :].expand(batch, 1, height, width).to(ffted)
|
||||
ffted = torch.cat((coords_vert, coords_hor, ffted), dim=1)
|
||||
|
||||
if self.use_se:
|
||||
ffted = self.se(ffted)
|
||||
|
||||
ffted = self.conv_layer(ffted) # (batch, c*2, h, w/2+1)
|
||||
ffted = self.relu(self.bn(ffted))
|
||||
|
||||
ffted = ffted.view((batch, -1, 2,) + ffted.size()[2:]).permute(
|
||||
0, 1, 3, 4, 2).contiguous() # (batch,c, t, h, w/2+1, 2)
|
||||
ffted = torch.complex(ffted[..., 0], ffted[..., 1])
|
||||
|
||||
ifft_shape_slice = x.shape[-3:] if self.ffc3d else x.shape[-2:]
|
||||
output = torch.fft.irfftn(ffted, s=ifft_shape_slice, dim=fft_dim, norm=self.fft_norm)
|
||||
|
||||
if self.spatial_scale_factor is not None:
|
||||
output = F.interpolate(output, size=orig_size, mode=self.spatial_scale_mode, align_corners=False)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
class SeparableFourierUnit(nn.Module):
|
||||
|
||||
def __init__(self, in_channels, out_channels, groups=1, kernel_size=3):
|
||||
# bn_layer not used
|
||||
super(SeparableFourierUnit, self).__init__()
|
||||
self.groups = groups
|
||||
row_out_channels = out_channels // 2
|
||||
col_out_channels = out_channels - row_out_channels
|
||||
self.row_conv = torch.nn.Conv2d(in_channels=in_channels * 2,
|
||||
out_channels=row_out_channels * 2,
|
||||
kernel_size=(kernel_size, 1), # kernel size is always like this, but the data will be transposed
|
||||
stride=1, padding=(kernel_size // 2, 0),
|
||||
padding_mode='reflect',
|
||||
groups=self.groups, bias=False)
|
||||
self.col_conv = torch.nn.Conv2d(in_channels=in_channels * 2,
|
||||
out_channels=col_out_channels * 2,
|
||||
kernel_size=(kernel_size, 1), # kernel size is always like this, but the data will be transposed
|
||||
stride=1, padding=(kernel_size // 2, 0),
|
||||
padding_mode='reflect',
|
||||
groups=self.groups, bias=False)
|
||||
self.row_bn = torch.nn.BatchNorm2d(row_out_channels * 2)
|
||||
self.col_bn = torch.nn.BatchNorm2d(col_out_channels * 2)
|
||||
self.relu = torch.nn.ReLU(inplace=True)
|
||||
|
||||
def process_branch(self, x, conv, bn):
|
||||
batch = x.shape[0]
|
||||
|
||||
r_size = x.size()
|
||||
# (batch, c, h, w/2+1, 2)
|
||||
ffted = torch.fft.rfft(x, norm="ortho")
|
||||
ffted = torch.stack((ffted.real, ffted.imag), dim=-1)
|
||||
ffted = ffted.permute(0, 1, 4, 2, 3).contiguous() # (batch, c, 2, h, w/2+1)
|
||||
ffted = ffted.view((batch, -1,) + ffted.size()[3:])
|
||||
|
||||
ffted = self.relu(bn(conv(ffted)))
|
||||
|
||||
ffted = ffted.view((batch, -1, 2,) + ffted.size()[2:]).permute(
|
||||
0, 1, 3, 4, 2).contiguous() # (batch,c, t, h, w/2+1, 2)
|
||||
ffted = torch.complex(ffted[..., 0], ffted[..., 1])
|
||||
|
||||
output = torch.fft.irfft(ffted, s=x.shape[-1:], norm="ortho")
|
||||
return output
|
||||
|
||||
|
||||
def forward(self, x):
|
||||
rowwise = self.process_branch(x, self.row_conv, self.row_bn)
|
||||
colwise = self.process_branch(x.permute(0, 1, 3, 2), self.col_conv, self.col_bn).permute(0, 1, 3, 2)
|
||||
out = torch.cat((rowwise, colwise), dim=1)
|
||||
return out
|
||||
|
||||
|
||||
class SpectralTransform(nn.Module):
|
||||
|
||||
def __init__(self, in_channels, out_channels, stride=1, groups=1, enable_lfu=True, separable_fu=False, **fu_kwargs):
|
||||
# bn_layer not used
|
||||
super(SpectralTransform, self).__init__()
|
||||
self.enable_lfu = enable_lfu
|
||||
if stride == 2:
|
||||
self.downsample = nn.AvgPool2d(kernel_size=(2, 2), stride=2)
|
||||
else:
|
||||
self.downsample = nn.Identity()
|
||||
|
||||
self.stride = stride
|
||||
self.conv1 = nn.Sequential(
|
||||
nn.Conv2d(in_channels, out_channels //
|
||||
2, kernel_size=1, groups=groups, bias=False),
|
||||
nn.BatchNorm2d(out_channels // 2),
|
||||
nn.ReLU(inplace=True)
|
||||
)
|
||||
fu_class = SeparableFourierUnit if separable_fu else FourierUnit
|
||||
self.fu = fu_class(
|
||||
out_channels // 2, out_channels // 2, groups, **fu_kwargs)
|
||||
if self.enable_lfu:
|
||||
self.lfu = fu_class(
|
||||
out_channels // 2, out_channels // 2, groups)
|
||||
self.conv2 = torch.nn.Conv2d(
|
||||
out_channels // 2, out_channels, kernel_size=1, groups=groups, bias=False)
|
||||
|
||||
def forward(self, x):
|
||||
|
||||
x = self.downsample(x)
|
||||
x = self.conv1(x)
|
||||
output = self.fu(x)
|
||||
|
||||
if self.enable_lfu:
|
||||
n, c, h, w = x.shape
|
||||
split_no = 2
|
||||
split_s = h // split_no
|
||||
xs = torch.cat(torch.split(
|
||||
x[:, :c // 4], split_s, dim=-2), dim=1).contiguous()
|
||||
xs = torch.cat(torch.split(xs, split_s, dim=-1),
|
||||
dim=1).contiguous()
|
||||
xs = self.lfu(xs)
|
||||
xs = xs.repeat(1, 1, split_no, split_no).contiguous()
|
||||
else:
|
||||
xs = 0
|
||||
|
||||
output = self.conv2(x + output + xs)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
class FFC(nn.Module):
|
||||
|
||||
def __init__(self, in_channels, out_channels, kernel_size,
|
||||
ratio_gin, ratio_gout, stride=1, padding=0,
|
||||
dilation=1, groups=1, bias=False, enable_lfu=True,
|
||||
padding_type='reflect', gated=False, **spectral_kwargs):
|
||||
super(FFC, self).__init__()
|
||||
|
||||
assert stride == 1 or stride == 2, "Stride should be 1 or 2."
|
||||
self.stride = stride
|
||||
|
||||
in_cg = int(in_channels * ratio_gin)
|
||||
in_cl = in_channels - in_cg
|
||||
out_cg = int(out_channels * ratio_gout)
|
||||
out_cl = out_channels - out_cg
|
||||
#groups_g = 1 if groups == 1 else int(groups * ratio_gout)
|
||||
#groups_l = 1 if groups == 1 else groups - groups_g
|
||||
|
||||
self.ratio_gin = ratio_gin
|
||||
self.ratio_gout = ratio_gout
|
||||
self.global_in_num = in_cg
|
||||
|
||||
module = nn.Identity if in_cl == 0 or out_cl == 0 else nn.Conv2d
|
||||
self.convl2l = module(in_cl, out_cl, kernel_size,
|
||||
stride, padding, dilation, groups, bias, padding_mode=padding_type)
|
||||
module = nn.Identity if in_cl == 0 or out_cg == 0 else nn.Conv2d
|
||||
self.convl2g = module(in_cl, out_cg, kernel_size,
|
||||
stride, padding, dilation, groups, bias, padding_mode=padding_type)
|
||||
module = nn.Identity if in_cg == 0 or out_cl == 0 else nn.Conv2d
|
||||
self.convg2l = module(in_cg, out_cl, kernel_size,
|
||||
stride, padding, dilation, groups, bias, padding_mode=padding_type)
|
||||
module = nn.Identity if in_cg == 0 or out_cg == 0 else SpectralTransform
|
||||
self.convg2g = module(
|
||||
in_cg, out_cg, stride, 1 if groups == 1 else groups // 2, enable_lfu, **spectral_kwargs)
|
||||
|
||||
self.gated = gated
|
||||
module = nn.Identity if in_cg == 0 or out_cl == 0 or not self.gated else nn.Conv2d
|
||||
self.gate = module(in_channels, 2, 1)
|
||||
|
||||
def forward(self, x):
|
||||
x_l, x_g = x if type(x) is tuple else (x, 0)
|
||||
out_xl, out_xg = 0, 0
|
||||
|
||||
if self.gated:
|
||||
total_input_parts = [x_l]
|
||||
if torch.is_tensor(x_g):
|
||||
total_input_parts.append(x_g)
|
||||
total_input = torch.cat(total_input_parts, dim=1)
|
||||
|
||||
gates = torch.sigmoid(self.gate(total_input))
|
||||
g2l_gate, l2g_gate = gates.chunk(2, dim=1)
|
||||
else:
|
||||
g2l_gate, l2g_gate = 1, 1
|
||||
|
||||
if self.ratio_gout != 1:
|
||||
out_xl = self.convl2l(x_l) + self.convg2l(x_g) * g2l_gate
|
||||
if self.ratio_gout != 0:
|
||||
out_xg = self.convl2g(x_l) * l2g_gate + self.convg2g(x_g)
|
||||
|
||||
return out_xl, out_xg
|
||||
|
||||
|
||||
class FFC_BN_ACT(nn.Module):
|
||||
|
||||
def __init__(self, in_channels, out_channels,
|
||||
kernel_size, ratio_gin, ratio_gout,
|
||||
stride=1, padding=0, dilation=1, groups=1, bias=False,
|
||||
norm_layer=nn.BatchNorm2d, activation_layer=nn.Identity,
|
||||
padding_type='reflect',
|
||||
enable_lfu=True, **kwargs):
|
||||
super(FFC_BN_ACT, self).__init__()
|
||||
self.ffc = FFC(in_channels, out_channels, kernel_size,
|
||||
ratio_gin, ratio_gout, stride, padding, dilation,
|
||||
groups, bias, enable_lfu, padding_type=padding_type, **kwargs)
|
||||
lnorm = nn.Identity if ratio_gout == 1 else norm_layer
|
||||
gnorm = nn.Identity if ratio_gout == 0 else norm_layer
|
||||
global_channels = int(out_channels * ratio_gout)
|
||||
self.bn_l = lnorm(out_channels - global_channels)
|
||||
self.bn_g = gnorm(global_channels)
|
||||
|
||||
lact = nn.Identity if ratio_gout == 1 else activation_layer
|
||||
gact = nn.Identity if ratio_gout == 0 else activation_layer
|
||||
self.act_l = lact(inplace=True)
|
||||
self.act_g = gact(inplace=True)
|
||||
|
||||
def forward(self, x):
|
||||
x_l, x_g = self.ffc(x)
|
||||
x_l = self.act_l(self.bn_l(x_l))
|
||||
x_g = self.act_g(self.bn_g(x_g))
|
||||
return x_l, x_g
|
||||
|
||||
|
||||
class FFCResnetBlock(nn.Module):
|
||||
def __init__(self, dim, padding_type, norm_layer, activation_layer=nn.ReLU, dilation=1,
|
||||
spatial_transform_kwargs=None, inline=False, **conv_kwargs):
|
||||
super().__init__()
|
||||
self.conv1 = FFC_BN_ACT(dim, dim, kernel_size=3, padding=dilation, dilation=dilation,
|
||||
norm_layer=norm_layer,
|
||||
activation_layer=activation_layer,
|
||||
padding_type=padding_type,
|
||||
**conv_kwargs)
|
||||
self.conv2 = FFC_BN_ACT(dim, dim, kernel_size=3, padding=dilation, dilation=dilation,
|
||||
norm_layer=norm_layer,
|
||||
activation_layer=activation_layer,
|
||||
padding_type=padding_type,
|
||||
**conv_kwargs)
|
||||
if spatial_transform_kwargs is not None:
|
||||
self.conv1 = LearnableSpatialTransformWrapper(self.conv1, **spatial_transform_kwargs)
|
||||
self.conv2 = LearnableSpatialTransformWrapper(self.conv2, **spatial_transform_kwargs)
|
||||
self.inline = inline
|
||||
|
||||
def forward(self, x):
|
||||
if self.inline:
|
||||
x_l, x_g = x[:, :-self.conv1.ffc.global_in_num], x[:, -self.conv1.ffc.global_in_num:]
|
||||
else:
|
||||
x_l, x_g = x if type(x) is tuple else (x, 0)
|
||||
|
||||
id_l, id_g = x_l, x_g
|
||||
|
||||
x_l, x_g = self.conv1((x_l, x_g))
|
||||
x_l, x_g = self.conv2((x_l, x_g))
|
||||
|
||||
x_l, x_g = id_l + x_l, id_g + x_g
|
||||
out = x_l, x_g
|
||||
if self.inline:
|
||||
out = torch.cat(out, dim=1)
|
||||
return out
|
||||
|
||||
|
||||
class ConcatTupleLayer(nn.Module):
|
||||
def forward(self, x):
|
||||
assert isinstance(x, tuple)
|
||||
x_l, x_g = x
|
||||
assert torch.is_tensor(x_l) or torch.is_tensor(x_g)
|
||||
if not torch.is_tensor(x_g):
|
||||
return x_l
|
||||
return torch.cat(x, dim=1)
|
||||
|
||||
|
||||
class FFCResNetGenerator(nn.Module):
|
||||
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
||||
padding_type='reflect', activation_layer=nn.ReLU,
|
||||
up_norm_layer=nn.BatchNorm2d, up_activation=nn.ReLU(True),
|
||||
init_conv_kwargs={}, downsample_conv_kwargs={}, resnet_conv_kwargs={},
|
||||
spatial_transform_layers=None, spatial_transform_kwargs={},
|
||||
add_out_act=True, max_features=1024, out_ffc=False, out_ffc_kwargs={}):
|
||||
assert (n_blocks >= 0)
|
||||
super().__init__()
|
||||
|
||||
model = [nn.ReflectionPad2d(3),
|
||||
FFC_BN_ACT(input_nc, ngf, kernel_size=7, padding=0, norm_layer=norm_layer,
|
||||
activation_layer=activation_layer, **init_conv_kwargs)]
|
||||
|
||||
### downsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** i
|
||||
if i == n_downsampling - 1:
|
||||
cur_conv_kwargs = dict(downsample_conv_kwargs)
|
||||
cur_conv_kwargs['ratio_gout'] = resnet_conv_kwargs.get('ratio_gin', 0)
|
||||
else:
|
||||
cur_conv_kwargs = downsample_conv_kwargs
|
||||
model += [FFC_BN_ACT(min(max_features, ngf * mult),
|
||||
min(max_features, ngf * mult * 2),
|
||||
kernel_size=3, stride=2, padding=1,
|
||||
norm_layer=norm_layer,
|
||||
activation_layer=activation_layer,
|
||||
**cur_conv_kwargs)]
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
feats_num_bottleneck = min(max_features, ngf * mult)
|
||||
|
||||
### resnet blocks
|
||||
for i in range(n_blocks):
|
||||
cur_resblock = FFCResnetBlock(feats_num_bottleneck, padding_type=padding_type, activation_layer=activation_layer,
|
||||
norm_layer=norm_layer, **resnet_conv_kwargs)
|
||||
if spatial_transform_layers is not None and i in spatial_transform_layers:
|
||||
cur_resblock = LearnableSpatialTransformWrapper(cur_resblock, **spatial_transform_kwargs)
|
||||
model += [cur_resblock]
|
||||
|
||||
model += [ConcatTupleLayer()]
|
||||
|
||||
### upsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** (n_downsampling - i)
|
||||
model += [nn.ConvTranspose2d(min(max_features, ngf * mult),
|
||||
min(max_features, int(ngf * mult / 2)),
|
||||
kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
up_norm_layer(min(max_features, int(ngf * mult / 2))),
|
||||
up_activation]
|
||||
|
||||
if out_ffc:
|
||||
model += [FFCResnetBlock(ngf, padding_type=padding_type, activation_layer=activation_layer,
|
||||
norm_layer=norm_layer, inline=True, **out_ffc_kwargs)]
|
||||
|
||||
model += [nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
||||
if add_out_act:
|
||||
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, input):
|
||||
return self.model(input)
|
||||
|
||||
|
||||
class FFCNLayerDiscriminator(BaseDiscriminator):
|
||||
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d, max_features=512,
|
||||
init_conv_kwargs={}, conv_kwargs={}):
|
||||
super().__init__()
|
||||
self.n_layers = n_layers
|
||||
|
||||
def _act_ctor(inplace=True):
|
||||
return nn.LeakyReLU(negative_slope=0.2, inplace=inplace)
|
||||
|
||||
kw = 3
|
||||
padw = int(np.ceil((kw-1.0)/2))
|
||||
sequence = [[FFC_BN_ACT(input_nc, ndf, kernel_size=kw, padding=padw, norm_layer=norm_layer,
|
||||
activation_layer=_act_ctor, **init_conv_kwargs)]]
|
||||
|
||||
nf = ndf
|
||||
for n in range(1, n_layers):
|
||||
nf_prev = nf
|
||||
nf = min(nf * 2, max_features)
|
||||
|
||||
cur_model = [
|
||||
FFC_BN_ACT(nf_prev, nf,
|
||||
kernel_size=kw, stride=2, padding=padw,
|
||||
norm_layer=norm_layer,
|
||||
activation_layer=_act_ctor,
|
||||
**conv_kwargs)
|
||||
]
|
||||
sequence.append(cur_model)
|
||||
|
||||
nf_prev = nf
|
||||
nf = min(nf * 2, 512)
|
||||
|
||||
cur_model = [
|
||||
FFC_BN_ACT(nf_prev, nf,
|
||||
kernel_size=kw, stride=1, padding=padw,
|
||||
norm_layer=norm_layer,
|
||||
activation_layer=lambda *args, **kwargs: nn.LeakyReLU(*args, negative_slope=0.2, **kwargs),
|
||||
**conv_kwargs),
|
||||
ConcatTupleLayer()
|
||||
]
|
||||
sequence.append(cur_model)
|
||||
|
||||
sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
|
||||
|
||||
for n in range(len(sequence)):
|
||||
setattr(self, 'model'+str(n), nn.Sequential(*sequence[n]))
|
||||
|
||||
def get_all_activations(self, x):
|
||||
res = [x]
|
||||
for n in range(self.n_layers + 2):
|
||||
model = getattr(self, 'model' + str(n))
|
||||
res.append(model(res[-1]))
|
||||
return res[1:]
|
||||
|
||||
def forward(self, x):
|
||||
act = self.get_all_activations(x)
|
||||
feats = []
|
||||
for out in act[:-1]:
|
||||
if isinstance(out, tuple):
|
||||
if torch.is_tensor(out[1]):
|
||||
out = torch.cat(out, dim=1)
|
||||
else:
|
||||
out = out[0]
|
||||
feats.append(out)
|
||||
return act[-1], feats
|
||||
@@ -1,98 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import random
|
||||
from annotator.lama.saicinpainting.training.modules.depthwise_sep_conv import DepthWiseSeperableConv
|
||||
|
||||
class MultidilatedConv(nn.Module):
|
||||
def __init__(self, in_dim, out_dim, kernel_size, dilation_num=3, comb_mode='sum', equal_dim=True,
|
||||
shared_weights=False, padding=1, min_dilation=1, shuffle_in_channels=False, use_depthwise=False, **kwargs):
|
||||
super().__init__()
|
||||
convs = []
|
||||
self.equal_dim = equal_dim
|
||||
assert comb_mode in ('cat_out', 'sum', 'cat_in', 'cat_both'), comb_mode
|
||||
if comb_mode in ('cat_out', 'cat_both'):
|
||||
self.cat_out = True
|
||||
if equal_dim:
|
||||
assert out_dim % dilation_num == 0
|
||||
out_dims = [out_dim // dilation_num] * dilation_num
|
||||
self.index = sum([[i + j * (out_dims[0]) for j in range(dilation_num)] for i in range(out_dims[0])], [])
|
||||
else:
|
||||
out_dims = [out_dim // 2 ** (i + 1) for i in range(dilation_num - 1)]
|
||||
out_dims.append(out_dim - sum(out_dims))
|
||||
index = []
|
||||
starts = [0] + out_dims[:-1]
|
||||
lengths = [out_dims[i] // out_dims[-1] for i in range(dilation_num)]
|
||||
for i in range(out_dims[-1]):
|
||||
for j in range(dilation_num):
|
||||
index += list(range(starts[j], starts[j] + lengths[j]))
|
||||
starts[j] += lengths[j]
|
||||
self.index = index
|
||||
assert(len(index) == out_dim)
|
||||
self.out_dims = out_dims
|
||||
else:
|
||||
self.cat_out = False
|
||||
self.out_dims = [out_dim] * dilation_num
|
||||
|
||||
if comb_mode in ('cat_in', 'cat_both'):
|
||||
if equal_dim:
|
||||
assert in_dim % dilation_num == 0
|
||||
in_dims = [in_dim // dilation_num] * dilation_num
|
||||
else:
|
||||
in_dims = [in_dim // 2 ** (i + 1) for i in range(dilation_num - 1)]
|
||||
in_dims.append(in_dim - sum(in_dims))
|
||||
self.in_dims = in_dims
|
||||
self.cat_in = True
|
||||
else:
|
||||
self.cat_in = False
|
||||
self.in_dims = [in_dim] * dilation_num
|
||||
|
||||
conv_type = DepthWiseSeperableConv if use_depthwise else nn.Conv2d
|
||||
dilation = min_dilation
|
||||
for i in range(dilation_num):
|
||||
if isinstance(padding, int):
|
||||
cur_padding = padding * dilation
|
||||
else:
|
||||
cur_padding = padding[i]
|
||||
convs.append(conv_type(
|
||||
self.in_dims[i], self.out_dims[i], kernel_size, padding=cur_padding, dilation=dilation, **kwargs
|
||||
))
|
||||
if i > 0 and shared_weights:
|
||||
convs[-1].weight = convs[0].weight
|
||||
convs[-1].bias = convs[0].bias
|
||||
dilation *= 2
|
||||
self.convs = nn.ModuleList(convs)
|
||||
|
||||
self.shuffle_in_channels = shuffle_in_channels
|
||||
if self.shuffle_in_channels:
|
||||
# shuffle list as shuffling of tensors is nondeterministic
|
||||
in_channels_permute = list(range(in_dim))
|
||||
random.shuffle(in_channels_permute)
|
||||
# save as buffer so it is saved and loaded with checkpoint
|
||||
self.register_buffer('in_channels_permute', torch.tensor(in_channels_permute))
|
||||
|
||||
def forward(self, x):
|
||||
if self.shuffle_in_channels:
|
||||
x = x[:, self.in_channels_permute]
|
||||
|
||||
outs = []
|
||||
if self.cat_in:
|
||||
if self.equal_dim:
|
||||
x = x.chunk(len(self.convs), dim=1)
|
||||
else:
|
||||
new_x = []
|
||||
start = 0
|
||||
for dim in self.in_dims:
|
||||
new_x.append(x[:, start:start+dim])
|
||||
start += dim
|
||||
x = new_x
|
||||
for i, conv in enumerate(self.convs):
|
||||
if self.cat_in:
|
||||
input = x[i]
|
||||
else:
|
||||
input = x
|
||||
outs.append(conv(input))
|
||||
if self.cat_out:
|
||||
out = torch.cat(outs, dim=1)[:, self.index]
|
||||
else:
|
||||
out = sum(outs)
|
||||
return out
|
||||
@@ -1,244 +0,0 @@
|
||||
from typing import List, Tuple, Union, Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from annotator.lama.saicinpainting.training.modules.base import get_conv_block_ctor, get_activation
|
||||
from annotator.lama.saicinpainting.training.modules.pix2pixhd import ResnetBlock
|
||||
|
||||
|
||||
class ResNetHead(nn.Module):
|
||||
def __init__(self, input_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
||||
padding_type='reflect', conv_kind='default', activation=nn.ReLU(True)):
|
||||
assert (n_blocks >= 0)
|
||||
super(ResNetHead, self).__init__()
|
||||
|
||||
conv_layer = get_conv_block_ctor(conv_kind)
|
||||
|
||||
model = [nn.ReflectionPad2d(3),
|
||||
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
||||
norm_layer(ngf),
|
||||
activation]
|
||||
|
||||
### downsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** i
|
||||
model += [conv_layer(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1),
|
||||
norm_layer(ngf * mult * 2),
|
||||
activation]
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
|
||||
### resnet blocks
|
||||
for i in range(n_blocks):
|
||||
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
||||
conv_kind=conv_kind)]
|
||||
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, input):
|
||||
return self.model(input)
|
||||
|
||||
|
||||
class ResNetTail(nn.Module):
|
||||
def __init__(self, output_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
||||
padding_type='reflect', conv_kind='default', activation=nn.ReLU(True),
|
||||
up_norm_layer=nn.BatchNorm2d, up_activation=nn.ReLU(True), add_out_act=False, out_extra_layers_n=0,
|
||||
add_in_proj=None):
|
||||
assert (n_blocks >= 0)
|
||||
super(ResNetTail, self).__init__()
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
|
||||
model = []
|
||||
|
||||
if add_in_proj is not None:
|
||||
model.append(nn.Conv2d(add_in_proj, ngf * mult, kernel_size=1))
|
||||
|
||||
### resnet blocks
|
||||
for i in range(n_blocks):
|
||||
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
||||
conv_kind=conv_kind)]
|
||||
|
||||
### upsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** (n_downsampling - i)
|
||||
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2), kernel_size=3, stride=2, padding=1,
|
||||
output_padding=1),
|
||||
up_norm_layer(int(ngf * mult / 2)),
|
||||
up_activation]
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
out_layers = []
|
||||
for _ in range(out_extra_layers_n):
|
||||
out_layers += [nn.Conv2d(ngf, ngf, kernel_size=1, padding=0),
|
||||
up_norm_layer(ngf),
|
||||
up_activation]
|
||||
out_layers += [nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
||||
|
||||
if add_out_act:
|
||||
out_layers.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
||||
|
||||
self.out_proj = nn.Sequential(*out_layers)
|
||||
|
||||
def forward(self, input, return_last_act=False):
|
||||
features = self.model(input)
|
||||
out = self.out_proj(features)
|
||||
if return_last_act:
|
||||
return out, features
|
||||
else:
|
||||
return out
|
||||
|
||||
|
||||
class MultiscaleResNet(nn.Module):
|
||||
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=2, n_blocks_head=2, n_blocks_tail=6, n_scales=3,
|
||||
norm_layer=nn.BatchNorm2d, padding_type='reflect', conv_kind='default', activation=nn.ReLU(True),
|
||||
up_norm_layer=nn.BatchNorm2d, up_activation=nn.ReLU(True), add_out_act=False, out_extra_layers_n=0,
|
||||
out_cumulative=False, return_only_hr=False):
|
||||
super().__init__()
|
||||
|
||||
self.heads = nn.ModuleList([ResNetHead(input_nc, ngf=ngf, n_downsampling=n_downsampling,
|
||||
n_blocks=n_blocks_head, norm_layer=norm_layer, padding_type=padding_type,
|
||||
conv_kind=conv_kind, activation=activation)
|
||||
for i in range(n_scales)])
|
||||
tail_in_feats = ngf * (2 ** n_downsampling) + ngf
|
||||
self.tails = nn.ModuleList([ResNetTail(output_nc,
|
||||
ngf=ngf, n_downsampling=n_downsampling,
|
||||
n_blocks=n_blocks_tail, norm_layer=norm_layer, padding_type=padding_type,
|
||||
conv_kind=conv_kind, activation=activation, up_norm_layer=up_norm_layer,
|
||||
up_activation=up_activation, add_out_act=add_out_act,
|
||||
out_extra_layers_n=out_extra_layers_n,
|
||||
add_in_proj=None if (i == n_scales - 1) else tail_in_feats)
|
||||
for i in range(n_scales)])
|
||||
|
||||
self.out_cumulative = out_cumulative
|
||||
self.return_only_hr = return_only_hr
|
||||
|
||||
@property
|
||||
def num_scales(self):
|
||||
return len(self.heads)
|
||||
|
||||
def forward(self, ms_inputs: List[torch.Tensor], smallest_scales_num: Optional[int] = None) \
|
||||
-> Union[torch.Tensor, List[torch.Tensor]]:
|
||||
"""
|
||||
:param ms_inputs: List of inputs of different resolutions from HR to LR
|
||||
:param smallest_scales_num: int or None, number of smallest scales to take at input
|
||||
:return: Depending on return_only_hr:
|
||||
True: Only the most HR output
|
||||
False: List of outputs of different resolutions from HR to LR
|
||||
"""
|
||||
if smallest_scales_num is None:
|
||||
assert len(self.heads) == len(ms_inputs), (len(self.heads), len(ms_inputs), smallest_scales_num)
|
||||
smallest_scales_num = len(self.heads)
|
||||
else:
|
||||
assert smallest_scales_num == len(ms_inputs) <= len(self.heads), (len(self.heads), len(ms_inputs), smallest_scales_num)
|
||||
|
||||
cur_heads = self.heads[-smallest_scales_num:]
|
||||
ms_features = [cur_head(cur_inp) for cur_head, cur_inp in zip(cur_heads, ms_inputs)]
|
||||
|
||||
all_outputs = []
|
||||
prev_tail_features = None
|
||||
for i in range(len(ms_features)):
|
||||
scale_i = -i - 1
|
||||
|
||||
cur_tail_input = ms_features[-i - 1]
|
||||
if prev_tail_features is not None:
|
||||
if prev_tail_features.shape != cur_tail_input.shape:
|
||||
prev_tail_features = F.interpolate(prev_tail_features, size=cur_tail_input.shape[2:],
|
||||
mode='bilinear', align_corners=False)
|
||||
cur_tail_input = torch.cat((cur_tail_input, prev_tail_features), dim=1)
|
||||
|
||||
cur_out, cur_tail_feats = self.tails[scale_i](cur_tail_input, return_last_act=True)
|
||||
|
||||
prev_tail_features = cur_tail_feats
|
||||
all_outputs.append(cur_out)
|
||||
|
||||
if self.out_cumulative:
|
||||
all_outputs_cum = [all_outputs[0]]
|
||||
for i in range(1, len(ms_features)):
|
||||
cur_out = all_outputs[i]
|
||||
cur_out_cum = cur_out + F.interpolate(all_outputs_cum[-1], size=cur_out.shape[2:],
|
||||
mode='bilinear', align_corners=False)
|
||||
all_outputs_cum.append(cur_out_cum)
|
||||
all_outputs = all_outputs_cum
|
||||
|
||||
if self.return_only_hr:
|
||||
return all_outputs[-1]
|
||||
else:
|
||||
return all_outputs[::-1]
|
||||
|
||||
|
||||
class MultiscaleDiscriminatorSimple(nn.Module):
|
||||
def __init__(self, ms_impl):
|
||||
super().__init__()
|
||||
self.ms_impl = nn.ModuleList(ms_impl)
|
||||
|
||||
@property
|
||||
def num_scales(self):
|
||||
return len(self.ms_impl)
|
||||
|
||||
def forward(self, ms_inputs: List[torch.Tensor], smallest_scales_num: Optional[int] = None) \
|
||||
-> List[Tuple[torch.Tensor, List[torch.Tensor]]]:
|
||||
"""
|
||||
:param ms_inputs: List of inputs of different resolutions from HR to LR
|
||||
:param smallest_scales_num: int or None, number of smallest scales to take at input
|
||||
:return: List of pairs (prediction, features) for different resolutions from HR to LR
|
||||
"""
|
||||
if smallest_scales_num is None:
|
||||
assert len(self.ms_impl) == len(ms_inputs), (len(self.ms_impl), len(ms_inputs), smallest_scales_num)
|
||||
smallest_scales_num = len(self.heads)
|
||||
else:
|
||||
assert smallest_scales_num == len(ms_inputs) <= len(self.ms_impl), \
|
||||
(len(self.ms_impl), len(ms_inputs), smallest_scales_num)
|
||||
|
||||
return [cur_discr(cur_input) for cur_discr, cur_input in zip(self.ms_impl[-smallest_scales_num:], ms_inputs)]
|
||||
|
||||
|
||||
class SingleToMultiScaleInputMixin:
|
||||
def forward(self, x: torch.Tensor) -> List:
|
||||
orig_height, orig_width = x.shape[2:]
|
||||
factors = [2 ** i for i in range(self.num_scales)]
|
||||
ms_inputs = [F.interpolate(x, size=(orig_height // f, orig_width // f), mode='bilinear', align_corners=False)
|
||||
for f in factors]
|
||||
return super().forward(ms_inputs)
|
||||
|
||||
|
||||
class GeneratorMultiToSingleOutputMixin:
|
||||
def forward(self, x):
|
||||
return super().forward(x)[0]
|
||||
|
||||
|
||||
class DiscriminatorMultiToSingleOutputMixin:
|
||||
def forward(self, x):
|
||||
out_feat_tuples = super().forward(x)
|
||||
return out_feat_tuples[0][0], [f for _, flist in out_feat_tuples for f in flist]
|
||||
|
||||
|
||||
class DiscriminatorMultiToSingleOutputStackedMixin:
|
||||
def __init__(self, *args, return_feats_only_levels=None, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.return_feats_only_levels = return_feats_only_levels
|
||||
|
||||
def forward(self, x):
|
||||
out_feat_tuples = super().forward(x)
|
||||
outs = [out for out, _ in out_feat_tuples]
|
||||
scaled_outs = [outs[0]] + [F.interpolate(cur_out, size=outs[0].shape[-2:],
|
||||
mode='bilinear', align_corners=False)
|
||||
for cur_out in outs[1:]]
|
||||
out = torch.cat(scaled_outs, dim=1)
|
||||
if self.return_feats_only_levels is not None:
|
||||
feat_lists = [out_feat_tuples[i][1] for i in self.return_feats_only_levels]
|
||||
else:
|
||||
feat_lists = [flist for _, flist in out_feat_tuples]
|
||||
feats = [f for flist in feat_lists for f in flist]
|
||||
return out, feats
|
||||
|
||||
|
||||
class MultiscaleDiscrSingleInput(SingleToMultiScaleInputMixin, DiscriminatorMultiToSingleOutputStackedMixin, MultiscaleDiscriminatorSimple):
|
||||
pass
|
||||
|
||||
|
||||
class MultiscaleResNetSingle(GeneratorMultiToSingleOutputMixin, SingleToMultiScaleInputMixin, MultiscaleResNet):
|
||||
pass
|
||||
@@ -1,669 +0,0 @@
|
||||
# original: https://github.com/NVIDIA/pix2pixHD/blob/master/models/networks.py
|
||||
import collections
|
||||
from functools import partial
|
||||
import functools
|
||||
import logging
|
||||
from collections import defaultdict
|
||||
|
||||
import numpy as np
|
||||
import torch.nn as nn
|
||||
|
||||
from annotator.lama.saicinpainting.training.modules.base import BaseDiscriminator, deconv_factory, get_conv_block_ctor, get_norm_layer, get_activation
|
||||
from annotator.lama.saicinpainting.training.modules.ffc import FFCResnetBlock
|
||||
from annotator.lama.saicinpainting.training.modules.multidilated_conv import MultidilatedConv
|
||||
|
||||
class DotDict(defaultdict):
|
||||
# https://stackoverflow.com/questions/2352181/how-to-use-a-dot-to-access-members-of-dictionary
|
||||
"""dot.notation access to dictionary attributes"""
|
||||
__getattr__ = defaultdict.get
|
||||
__setattr__ = defaultdict.__setitem__
|
||||
__delattr__ = defaultdict.__delitem__
|
||||
|
||||
class Identity(nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, x):
|
||||
return x
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
def __init__(self, dim, padding_type, norm_layer, activation=nn.ReLU(True), use_dropout=False, conv_kind='default',
|
||||
dilation=1, in_dim=None, groups=1, second_dilation=None):
|
||||
super(ResnetBlock, self).__init__()
|
||||
self.in_dim = in_dim
|
||||
self.dim = dim
|
||||
if second_dilation is None:
|
||||
second_dilation = dilation
|
||||
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, activation, use_dropout,
|
||||
conv_kind=conv_kind, dilation=dilation, in_dim=in_dim, groups=groups,
|
||||
second_dilation=second_dilation)
|
||||
|
||||
if self.in_dim is not None:
|
||||
self.input_conv = nn.Conv2d(in_dim, dim, 1)
|
||||
|
||||
self.out_channnels = dim
|
||||
|
||||
def build_conv_block(self, dim, padding_type, norm_layer, activation, use_dropout, conv_kind='default',
|
||||
dilation=1, in_dim=None, groups=1, second_dilation=1):
|
||||
conv_layer = get_conv_block_ctor(conv_kind)
|
||||
|
||||
conv_block = []
|
||||
p = 0
|
||||
if padding_type == 'reflect':
|
||||
conv_block += [nn.ReflectionPad2d(dilation)]
|
||||
elif padding_type == 'replicate':
|
||||
conv_block += [nn.ReplicationPad2d(dilation)]
|
||||
elif padding_type == 'zero':
|
||||
p = dilation
|
||||
else:
|
||||
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
||||
|
||||
if in_dim is None:
|
||||
in_dim = dim
|
||||
|
||||
conv_block += [conv_layer(in_dim, dim, kernel_size=3, padding=p, dilation=dilation),
|
||||
norm_layer(dim),
|
||||
activation]
|
||||
if use_dropout:
|
||||
conv_block += [nn.Dropout(0.5)]
|
||||
|
||||
p = 0
|
||||
if padding_type == 'reflect':
|
||||
conv_block += [nn.ReflectionPad2d(second_dilation)]
|
||||
elif padding_type == 'replicate':
|
||||
conv_block += [nn.ReplicationPad2d(second_dilation)]
|
||||
elif padding_type == 'zero':
|
||||
p = second_dilation
|
||||
else:
|
||||
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
||||
conv_block += [conv_layer(dim, dim, kernel_size=3, padding=p, dilation=second_dilation, groups=groups),
|
||||
norm_layer(dim)]
|
||||
|
||||
return nn.Sequential(*conv_block)
|
||||
|
||||
def forward(self, x):
|
||||
x_before = x
|
||||
if self.in_dim is not None:
|
||||
x = self.input_conv(x)
|
||||
out = x + self.conv_block(x_before)
|
||||
return out
|
||||
|
||||
class ResnetBlock5x5(nn.Module):
|
||||
def __init__(self, dim, padding_type, norm_layer, activation=nn.ReLU(True), use_dropout=False, conv_kind='default',
|
||||
dilation=1, in_dim=None, groups=1, second_dilation=None):
|
||||
super(ResnetBlock5x5, self).__init__()
|
||||
self.in_dim = in_dim
|
||||
self.dim = dim
|
||||
if second_dilation is None:
|
||||
second_dilation = dilation
|
||||
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, activation, use_dropout,
|
||||
conv_kind=conv_kind, dilation=dilation, in_dim=in_dim, groups=groups,
|
||||
second_dilation=second_dilation)
|
||||
|
||||
if self.in_dim is not None:
|
||||
self.input_conv = nn.Conv2d(in_dim, dim, 1)
|
||||
|
||||
self.out_channnels = dim
|
||||
|
||||
def build_conv_block(self, dim, padding_type, norm_layer, activation, use_dropout, conv_kind='default',
|
||||
dilation=1, in_dim=None, groups=1, second_dilation=1):
|
||||
conv_layer = get_conv_block_ctor(conv_kind)
|
||||
|
||||
conv_block = []
|
||||
p = 0
|
||||
if padding_type == 'reflect':
|
||||
conv_block += [nn.ReflectionPad2d(dilation * 2)]
|
||||
elif padding_type == 'replicate':
|
||||
conv_block += [nn.ReplicationPad2d(dilation * 2)]
|
||||
elif padding_type == 'zero':
|
||||
p = dilation * 2
|
||||
else:
|
||||
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
||||
|
||||
if in_dim is None:
|
||||
in_dim = dim
|
||||
|
||||
conv_block += [conv_layer(in_dim, dim, kernel_size=5, padding=p, dilation=dilation),
|
||||
norm_layer(dim),
|
||||
activation]
|
||||
if use_dropout:
|
||||
conv_block += [nn.Dropout(0.5)]
|
||||
|
||||
p = 0
|
||||
if padding_type == 'reflect':
|
||||
conv_block += [nn.ReflectionPad2d(second_dilation * 2)]
|
||||
elif padding_type == 'replicate':
|
||||
conv_block += [nn.ReplicationPad2d(second_dilation * 2)]
|
||||
elif padding_type == 'zero':
|
||||
p = second_dilation * 2
|
||||
else:
|
||||
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
||||
conv_block += [conv_layer(dim, dim, kernel_size=5, padding=p, dilation=second_dilation, groups=groups),
|
||||
norm_layer(dim)]
|
||||
|
||||
return nn.Sequential(*conv_block)
|
||||
|
||||
def forward(self, x):
|
||||
x_before = x
|
||||
if self.in_dim is not None:
|
||||
x = self.input_conv(x)
|
||||
out = x + self.conv_block(x_before)
|
||||
return out
|
||||
|
||||
|
||||
class MultidilatedResnetBlock(nn.Module):
|
||||
def __init__(self, dim, padding_type, conv_layer, norm_layer, activation=nn.ReLU(True), use_dropout=False):
|
||||
super().__init__()
|
||||
self.conv_block = self.build_conv_block(dim, padding_type, conv_layer, norm_layer, activation, use_dropout)
|
||||
|
||||
def build_conv_block(self, dim, padding_type, conv_layer, norm_layer, activation, use_dropout, dilation=1):
|
||||
conv_block = []
|
||||
conv_block += [conv_layer(dim, dim, kernel_size=3, padding_mode=padding_type),
|
||||
norm_layer(dim),
|
||||
activation]
|
||||
if use_dropout:
|
||||
conv_block += [nn.Dropout(0.5)]
|
||||
|
||||
conv_block += [conv_layer(dim, dim, kernel_size=3, padding_mode=padding_type),
|
||||
norm_layer(dim)]
|
||||
|
||||
return nn.Sequential(*conv_block)
|
||||
|
||||
def forward(self, x):
|
||||
out = x + self.conv_block(x)
|
||||
return out
|
||||
|
||||
|
||||
class MultiDilatedGlobalGenerator(nn.Module):
|
||||
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3,
|
||||
n_blocks=3, norm_layer=nn.BatchNorm2d,
|
||||
padding_type='reflect', conv_kind='default',
|
||||
deconv_kind='convtranspose', activation=nn.ReLU(True),
|
||||
up_norm_layer=nn.BatchNorm2d, affine=None, up_activation=nn.ReLU(True),
|
||||
add_out_act=True, max_features=1024, multidilation_kwargs={},
|
||||
ffc_positions=None, ffc_kwargs={}):
|
||||
assert (n_blocks >= 0)
|
||||
super().__init__()
|
||||
|
||||
conv_layer = get_conv_block_ctor(conv_kind)
|
||||
resnet_conv_layer = functools.partial(get_conv_block_ctor('multidilated'), **multidilation_kwargs)
|
||||
norm_layer = get_norm_layer(norm_layer)
|
||||
if affine is not None:
|
||||
norm_layer = partial(norm_layer, affine=affine)
|
||||
up_norm_layer = get_norm_layer(up_norm_layer)
|
||||
if affine is not None:
|
||||
up_norm_layer = partial(up_norm_layer, affine=affine)
|
||||
|
||||
model = [nn.ReflectionPad2d(3),
|
||||
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
||||
norm_layer(ngf),
|
||||
activation]
|
||||
|
||||
identity = Identity()
|
||||
### downsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** i
|
||||
|
||||
model += [conv_layer(min(max_features, ngf * mult),
|
||||
min(max_features, ngf * mult * 2),
|
||||
kernel_size=3, stride=2, padding=1),
|
||||
norm_layer(min(max_features, ngf * mult * 2)),
|
||||
activation]
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
feats_num_bottleneck = min(max_features, ngf * mult)
|
||||
|
||||
### resnet blocks
|
||||
for i in range(n_blocks):
|
||||
if ffc_positions is not None and i in ffc_positions:
|
||||
model += [FFCResnetBlock(feats_num_bottleneck, padding_type, norm_layer, activation_layer=nn.ReLU,
|
||||
inline=True, **ffc_kwargs)]
|
||||
model += [MultidilatedResnetBlock(feats_num_bottleneck, padding_type=padding_type,
|
||||
conv_layer=resnet_conv_layer, activation=activation,
|
||||
norm_layer=norm_layer)]
|
||||
|
||||
### upsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** (n_downsampling - i)
|
||||
model += deconv_factory(deconv_kind, ngf, mult, up_norm_layer, up_activation, max_features)
|
||||
model += [nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
||||
if add_out_act:
|
||||
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, input):
|
||||
return self.model(input)
|
||||
|
||||
class ConfigGlobalGenerator(nn.Module):
|
||||
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3,
|
||||
n_blocks=3, norm_layer=nn.BatchNorm2d,
|
||||
padding_type='reflect', conv_kind='default',
|
||||
deconv_kind='convtranspose', activation=nn.ReLU(True),
|
||||
up_norm_layer=nn.BatchNorm2d, affine=None, up_activation=nn.ReLU(True),
|
||||
add_out_act=True, max_features=1024,
|
||||
manual_block_spec=[],
|
||||
resnet_block_kind='multidilatedresnetblock',
|
||||
resnet_conv_kind='multidilated',
|
||||
resnet_dilation=1,
|
||||
multidilation_kwargs={}):
|
||||
assert (n_blocks >= 0)
|
||||
super().__init__()
|
||||
|
||||
conv_layer = get_conv_block_ctor(conv_kind)
|
||||
resnet_conv_layer = functools.partial(get_conv_block_ctor(resnet_conv_kind), **multidilation_kwargs)
|
||||
norm_layer = get_norm_layer(norm_layer)
|
||||
if affine is not None:
|
||||
norm_layer = partial(norm_layer, affine=affine)
|
||||
up_norm_layer = get_norm_layer(up_norm_layer)
|
||||
if affine is not None:
|
||||
up_norm_layer = partial(up_norm_layer, affine=affine)
|
||||
|
||||
model = [nn.ReflectionPad2d(3),
|
||||
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
||||
norm_layer(ngf),
|
||||
activation]
|
||||
|
||||
identity = Identity()
|
||||
|
||||
### downsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** i
|
||||
model += [conv_layer(min(max_features, ngf * mult),
|
||||
min(max_features, ngf * mult * 2),
|
||||
kernel_size=3, stride=2, padding=1),
|
||||
norm_layer(min(max_features, ngf * mult * 2)),
|
||||
activation]
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
feats_num_bottleneck = min(max_features, ngf * mult)
|
||||
|
||||
if len(manual_block_spec) == 0:
|
||||
manual_block_spec = [
|
||||
DotDict(lambda : None, {
|
||||
'n_blocks': n_blocks,
|
||||
'use_default': True})
|
||||
]
|
||||
|
||||
### resnet blocks
|
||||
for block_spec in manual_block_spec:
|
||||
def make_and_add_blocks(model, block_spec):
|
||||
block_spec = DotDict(lambda : None, block_spec)
|
||||
if not block_spec.use_default:
|
||||
resnet_conv_layer = functools.partial(get_conv_block_ctor(block_spec.resnet_conv_kind), **block_spec.multidilation_kwargs)
|
||||
resnet_conv_kind = block_spec.resnet_conv_kind
|
||||
resnet_block_kind = block_spec.resnet_block_kind
|
||||
if block_spec.resnet_dilation is not None:
|
||||
resnet_dilation = block_spec.resnet_dilation
|
||||
for i in range(block_spec.n_blocks):
|
||||
if resnet_block_kind == "multidilatedresnetblock":
|
||||
model += [MultidilatedResnetBlock(feats_num_bottleneck, padding_type=padding_type,
|
||||
conv_layer=resnet_conv_layer, activation=activation,
|
||||
norm_layer=norm_layer)]
|
||||
if resnet_block_kind == "resnetblock":
|
||||
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
||||
conv_kind=resnet_conv_kind)]
|
||||
if resnet_block_kind == "resnetblock5x5":
|
||||
model += [ResnetBlock5x5(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
||||
conv_kind=resnet_conv_kind)]
|
||||
if resnet_block_kind == "resnetblockdwdil":
|
||||
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
||||
conv_kind=resnet_conv_kind, dilation=resnet_dilation, second_dilation=resnet_dilation)]
|
||||
make_and_add_blocks(model, block_spec)
|
||||
|
||||
### upsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** (n_downsampling - i)
|
||||
model += deconv_factory(deconv_kind, ngf, mult, up_norm_layer, up_activation, max_features)
|
||||
model += [nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
||||
if add_out_act:
|
||||
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, input):
|
||||
return self.model(input)
|
||||
|
||||
|
||||
def make_dil_blocks(dilated_blocks_n, dilation_block_kind, dilated_block_kwargs):
|
||||
blocks = []
|
||||
for i in range(dilated_blocks_n):
|
||||
if dilation_block_kind == 'simple':
|
||||
blocks.append(ResnetBlock(**dilated_block_kwargs, dilation=2 ** (i + 1)))
|
||||
elif dilation_block_kind == 'multi':
|
||||
blocks.append(MultidilatedResnetBlock(**dilated_block_kwargs))
|
||||
else:
|
||||
raise ValueError(f'dilation_block_kind could not be "{dilation_block_kind}"')
|
||||
return blocks
|
||||
|
||||
|
||||
class GlobalGenerator(nn.Module):
|
||||
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
||||
padding_type='reflect', conv_kind='default', activation=nn.ReLU(True),
|
||||
up_norm_layer=nn.BatchNorm2d, affine=None,
|
||||
up_activation=nn.ReLU(True), dilated_blocks_n=0, dilated_blocks_n_start=0,
|
||||
dilated_blocks_n_middle=0,
|
||||
add_out_act=True,
|
||||
max_features=1024, is_resblock_depthwise=False,
|
||||
ffc_positions=None, ffc_kwargs={}, dilation=1, second_dilation=None,
|
||||
dilation_block_kind='simple', multidilation_kwargs={}):
|
||||
assert (n_blocks >= 0)
|
||||
super().__init__()
|
||||
|
||||
conv_layer = get_conv_block_ctor(conv_kind)
|
||||
norm_layer = get_norm_layer(norm_layer)
|
||||
if affine is not None:
|
||||
norm_layer = partial(norm_layer, affine=affine)
|
||||
up_norm_layer = get_norm_layer(up_norm_layer)
|
||||
if affine is not None:
|
||||
up_norm_layer = partial(up_norm_layer, affine=affine)
|
||||
|
||||
if ffc_positions is not None:
|
||||
ffc_positions = collections.Counter(ffc_positions)
|
||||
|
||||
model = [nn.ReflectionPad2d(3),
|
||||
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
||||
norm_layer(ngf),
|
||||
activation]
|
||||
|
||||
identity = Identity()
|
||||
### downsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** i
|
||||
|
||||
model += [conv_layer(min(max_features, ngf * mult),
|
||||
min(max_features, ngf * mult * 2),
|
||||
kernel_size=3, stride=2, padding=1),
|
||||
norm_layer(min(max_features, ngf * mult * 2)),
|
||||
activation]
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
feats_num_bottleneck = min(max_features, ngf * mult)
|
||||
|
||||
dilated_block_kwargs = dict(dim=feats_num_bottleneck, padding_type=padding_type,
|
||||
activation=activation, norm_layer=norm_layer)
|
||||
if dilation_block_kind == 'simple':
|
||||
dilated_block_kwargs['conv_kind'] = conv_kind
|
||||
elif dilation_block_kind == 'multi':
|
||||
dilated_block_kwargs['conv_layer'] = functools.partial(
|
||||
get_conv_block_ctor('multidilated'), **multidilation_kwargs)
|
||||
|
||||
# dilated blocks at the start of the bottleneck sausage
|
||||
if dilated_blocks_n_start is not None and dilated_blocks_n_start > 0:
|
||||
model += make_dil_blocks(dilated_blocks_n_start, dilation_block_kind, dilated_block_kwargs)
|
||||
|
||||
# resnet blocks
|
||||
for i in range(n_blocks):
|
||||
# dilated blocks at the middle of the bottleneck sausage
|
||||
if i == n_blocks // 2 and dilated_blocks_n_middle is not None and dilated_blocks_n_middle > 0:
|
||||
model += make_dil_blocks(dilated_blocks_n_middle, dilation_block_kind, dilated_block_kwargs)
|
||||
|
||||
if ffc_positions is not None and i in ffc_positions:
|
||||
for _ in range(ffc_positions[i]): # same position can occur more than once
|
||||
model += [FFCResnetBlock(feats_num_bottleneck, padding_type, norm_layer, activation_layer=nn.ReLU,
|
||||
inline=True, **ffc_kwargs)]
|
||||
|
||||
if is_resblock_depthwise:
|
||||
resblock_groups = feats_num_bottleneck
|
||||
else:
|
||||
resblock_groups = 1
|
||||
|
||||
model += [ResnetBlock(feats_num_bottleneck, padding_type=padding_type, activation=activation,
|
||||
norm_layer=norm_layer, conv_kind=conv_kind, groups=resblock_groups,
|
||||
dilation=dilation, second_dilation=second_dilation)]
|
||||
|
||||
|
||||
# dilated blocks at the end of the bottleneck sausage
|
||||
if dilated_blocks_n is not None and dilated_blocks_n > 0:
|
||||
model += make_dil_blocks(dilated_blocks_n, dilation_block_kind, dilated_block_kwargs)
|
||||
|
||||
# upsample
|
||||
for i in range(n_downsampling):
|
||||
mult = 2 ** (n_downsampling - i)
|
||||
model += [nn.ConvTranspose2d(min(max_features, ngf * mult),
|
||||
min(max_features, int(ngf * mult / 2)),
|
||||
kernel_size=3, stride=2, padding=1, output_padding=1),
|
||||
up_norm_layer(min(max_features, int(ngf * mult / 2))),
|
||||
up_activation]
|
||||
model += [nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
||||
if add_out_act:
|
||||
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, input):
|
||||
return self.model(input)
|
||||
|
||||
|
||||
class GlobalGeneratorGated(GlobalGenerator):
|
||||
def __init__(self, *args, **kwargs):
|
||||
real_kwargs=dict(
|
||||
conv_kind='gated_bn_relu',
|
||||
activation=nn.Identity(),
|
||||
norm_layer=nn.Identity
|
||||
)
|
||||
real_kwargs.update(kwargs)
|
||||
super().__init__(*args, **real_kwargs)
|
||||
|
||||
|
||||
class GlobalGeneratorFromSuperChannels(nn.Module):
|
||||
def __init__(self, input_nc, output_nc, n_downsampling, n_blocks, super_channels, norm_layer="bn", padding_type='reflect', add_out_act=True):
|
||||
super().__init__()
|
||||
self.n_downsampling = n_downsampling
|
||||
norm_layer = get_norm_layer(norm_layer)
|
||||
if type(norm_layer) == functools.partial:
|
||||
use_bias = (norm_layer.func == nn.InstanceNorm2d)
|
||||
else:
|
||||
use_bias = (norm_layer == nn.InstanceNorm2d)
|
||||
|
||||
channels = self.convert_super_channels(super_channels)
|
||||
self.channels = channels
|
||||
|
||||
model = [nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(input_nc, channels[0], kernel_size=7, padding=0, bias=use_bias),
|
||||
norm_layer(channels[0]),
|
||||
nn.ReLU(True)]
|
||||
|
||||
for i in range(n_downsampling): # add downsampling layers
|
||||
mult = 2 ** i
|
||||
model += [nn.Conv2d(channels[0+i], channels[1+i], kernel_size=3, stride=2, padding=1, bias=use_bias),
|
||||
norm_layer(channels[1+i]),
|
||||
nn.ReLU(True)]
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
|
||||
n_blocks1 = n_blocks // 3
|
||||
n_blocks2 = n_blocks1
|
||||
n_blocks3 = n_blocks - n_blocks1 - n_blocks2
|
||||
|
||||
for i in range(n_blocks1):
|
||||
c = n_downsampling
|
||||
dim = channels[c]
|
||||
model += [ResnetBlock(dim, padding_type=padding_type, norm_layer=norm_layer)]
|
||||
|
||||
for i in range(n_blocks2):
|
||||
c = n_downsampling+1
|
||||
dim = channels[c]
|
||||
kwargs = {}
|
||||
if i == 0:
|
||||
kwargs = {"in_dim": channels[c-1]}
|
||||
model += [ResnetBlock(dim, padding_type=padding_type, norm_layer=norm_layer, **kwargs)]
|
||||
|
||||
for i in range(n_blocks3):
|
||||
c = n_downsampling+2
|
||||
dim = channels[c]
|
||||
kwargs = {}
|
||||
if i == 0:
|
||||
kwargs = {"in_dim": channels[c-1]}
|
||||
model += [ResnetBlock(dim, padding_type=padding_type, norm_layer=norm_layer, **kwargs)]
|
||||
|
||||
for i in range(n_downsampling): # add upsampling layers
|
||||
mult = 2 ** (n_downsampling - i)
|
||||
model += [nn.ConvTranspose2d(channels[n_downsampling+3+i],
|
||||
channels[n_downsampling+3+i+1],
|
||||
kernel_size=3, stride=2,
|
||||
padding=1, output_padding=1,
|
||||
bias=use_bias),
|
||||
norm_layer(channels[n_downsampling+3+i+1]),
|
||||
nn.ReLU(True)]
|
||||
model += [nn.ReflectionPad2d(3)]
|
||||
model += [nn.Conv2d(channels[2*n_downsampling+3], output_nc, kernel_size=7, padding=0)]
|
||||
|
||||
if add_out_act:
|
||||
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def convert_super_channels(self, super_channels):
|
||||
n_downsampling = self.n_downsampling
|
||||
result = []
|
||||
cnt = 0
|
||||
|
||||
if n_downsampling == 2:
|
||||
N1 = 10
|
||||
elif n_downsampling == 3:
|
||||
N1 = 13
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
for i in range(0, N1):
|
||||
if i in [1,4,7,10]:
|
||||
channel = super_channels[cnt] * (2 ** cnt)
|
||||
config = {'channel': channel}
|
||||
result.append(channel)
|
||||
logging.info(f"Downsample channels {result[-1]}")
|
||||
cnt += 1
|
||||
|
||||
for i in range(3):
|
||||
for counter, j in enumerate(range(N1 + i * 3, N1 + 3 + i * 3)):
|
||||
if len(super_channels) == 6:
|
||||
channel = super_channels[3] * 4
|
||||
else:
|
||||
channel = super_channels[i + 3] * 4
|
||||
config = {'channel': channel}
|
||||
if counter == 0:
|
||||
result.append(channel)
|
||||
logging.info(f"Bottleneck channels {result[-1]}")
|
||||
cnt = 2
|
||||
|
||||
for i in range(N1+9, N1+21):
|
||||
if i in [22, 25,28]:
|
||||
cnt -= 1
|
||||
if len(super_channels) == 6:
|
||||
channel = super_channels[5 - cnt] * (2 ** cnt)
|
||||
else:
|
||||
channel = super_channels[7 - cnt] * (2 ** cnt)
|
||||
result.append(int(channel))
|
||||
logging.info(f"Upsample channels {result[-1]}")
|
||||
return result
|
||||
|
||||
def forward(self, input):
|
||||
return self.model(input)
|
||||
|
||||
|
||||
# Defines the PatchGAN discriminator with the specified arguments.
|
||||
class NLayerDiscriminator(BaseDiscriminator):
|
||||
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d,):
|
||||
super().__init__()
|
||||
self.n_layers = n_layers
|
||||
|
||||
kw = 4
|
||||
padw = int(np.ceil((kw-1.0)/2))
|
||||
sequence = [[nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
|
||||
nn.LeakyReLU(0.2, True)]]
|
||||
|
||||
nf = ndf
|
||||
for n in range(1, n_layers):
|
||||
nf_prev = nf
|
||||
nf = min(nf * 2, 512)
|
||||
|
||||
cur_model = []
|
||||
cur_model += [
|
||||
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=2, padding=padw),
|
||||
norm_layer(nf),
|
||||
nn.LeakyReLU(0.2, True)
|
||||
]
|
||||
sequence.append(cur_model)
|
||||
|
||||
nf_prev = nf
|
||||
nf = min(nf * 2, 512)
|
||||
|
||||
cur_model = []
|
||||
cur_model += [
|
||||
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=1, padding=padw),
|
||||
norm_layer(nf),
|
||||
nn.LeakyReLU(0.2, True)
|
||||
]
|
||||
sequence.append(cur_model)
|
||||
|
||||
sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
|
||||
|
||||
for n in range(len(sequence)):
|
||||
setattr(self, 'model'+str(n), nn.Sequential(*sequence[n]))
|
||||
|
||||
def get_all_activations(self, x):
|
||||
res = [x]
|
||||
for n in range(self.n_layers + 2):
|
||||
model = getattr(self, 'model' + str(n))
|
||||
res.append(model(res[-1]))
|
||||
return res[1:]
|
||||
|
||||
def forward(self, x):
|
||||
act = self.get_all_activations(x)
|
||||
return act[-1], act[:-1]
|
||||
|
||||
|
||||
class MultidilatedNLayerDiscriminator(BaseDiscriminator):
|
||||
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d, multidilation_kwargs={}):
|
||||
super().__init__()
|
||||
self.n_layers = n_layers
|
||||
|
||||
kw = 4
|
||||
padw = int(np.ceil((kw-1.0)/2))
|
||||
sequence = [[nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
|
||||
nn.LeakyReLU(0.2, True)]]
|
||||
|
||||
nf = ndf
|
||||
for n in range(1, n_layers):
|
||||
nf_prev = nf
|
||||
nf = min(nf * 2, 512)
|
||||
|
||||
cur_model = []
|
||||
cur_model += [
|
||||
MultidilatedConv(nf_prev, nf, kernel_size=kw, stride=2, padding=[2, 3], **multidilation_kwargs),
|
||||
norm_layer(nf),
|
||||
nn.LeakyReLU(0.2, True)
|
||||
]
|
||||
sequence.append(cur_model)
|
||||
|
||||
nf_prev = nf
|
||||
nf = min(nf * 2, 512)
|
||||
|
||||
cur_model = []
|
||||
cur_model += [
|
||||
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=1, padding=padw),
|
||||
norm_layer(nf),
|
||||
nn.LeakyReLU(0.2, True)
|
||||
]
|
||||
sequence.append(cur_model)
|
||||
|
||||
sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
|
||||
|
||||
for n in range(len(sequence)):
|
||||
setattr(self, 'model'+str(n), nn.Sequential(*sequence[n]))
|
||||
|
||||
def get_all_activations(self, x):
|
||||
res = [x]
|
||||
for n in range(self.n_layers + 2):
|
||||
model = getattr(self, 'model' + str(n))
|
||||
res.append(model(res[-1]))
|
||||
return res[1:]
|
||||
|
||||
def forward(self, x):
|
||||
act = self.get_all_activations(x)
|
||||
return act[-1], act[:-1]
|
||||
|
||||
|
||||
class NLayerDiscriminatorAsGen(NLayerDiscriminator):
|
||||
def forward(self, x):
|
||||
return super().forward(x)[0]
|
||||
@@ -1,49 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from kornia.geometry.transform import rotate
|
||||
|
||||
|
||||
class LearnableSpatialTransformWrapper(nn.Module):
|
||||
def __init__(self, impl, pad_coef=0.5, angle_init_range=80, train_angle=True):
|
||||
super().__init__()
|
||||
self.impl = impl
|
||||
self.angle = torch.rand(1) * angle_init_range
|
||||
if train_angle:
|
||||
self.angle = nn.Parameter(self.angle, requires_grad=True)
|
||||
self.pad_coef = pad_coef
|
||||
|
||||
def forward(self, x):
|
||||
if torch.is_tensor(x):
|
||||
return self.inverse_transform(self.impl(self.transform(x)), x)
|
||||
elif isinstance(x, tuple):
|
||||
x_trans = tuple(self.transform(elem) for elem in x)
|
||||
y_trans = self.impl(x_trans)
|
||||
return tuple(self.inverse_transform(elem, orig_x) for elem, orig_x in zip(y_trans, x))
|
||||
else:
|
||||
raise ValueError(f'Unexpected input type {type(x)}')
|
||||
|
||||
def transform(self, x):
|
||||
height, width = x.shape[2:]
|
||||
pad_h, pad_w = int(height * self.pad_coef), int(width * self.pad_coef)
|
||||
x_padded = F.pad(x, [pad_w, pad_w, pad_h, pad_h], mode='reflect')
|
||||
x_padded_rotated = rotate(x_padded, angle=self.angle.to(x_padded))
|
||||
return x_padded_rotated
|
||||
|
||||
def inverse_transform(self, y_padded_rotated, orig_x):
|
||||
height, width = orig_x.shape[2:]
|
||||
pad_h, pad_w = int(height * self.pad_coef), int(width * self.pad_coef)
|
||||
|
||||
y_padded = rotate(y_padded_rotated, angle=-self.angle.to(y_padded_rotated))
|
||||
y_height, y_width = y_padded.shape[2:]
|
||||
y = y_padded[:, :, pad_h : y_height - pad_h, pad_w : y_width - pad_w]
|
||||
return y
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
layer = LearnableSpatialTransformWrapper(nn.Identity())
|
||||
x = torch.arange(2* 3 * 15 * 15).view(2, 3, 15, 15).float()
|
||||
y = layer(x)
|
||||
assert x.shape == y.shape
|
||||
assert torch.allclose(x[:, :, 1:, 1:][:, :, :-1, :-1], y[:, :, 1:, 1:][:, :, :-1, :-1])
|
||||
print('all ok')
|
||||
@@ -1,20 +0,0 @@
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
class SELayer(nn.Module):
|
||||
def __init__(self, channel, reduction=16):
|
||||
super(SELayer, self).__init__()
|
||||
self.avg_pool = nn.AdaptiveAvgPool2d(1)
|
||||
self.fc = nn.Sequential(
|
||||
nn.Linear(channel, channel // reduction, bias=False),
|
||||
nn.ReLU(inplace=True),
|
||||
nn.Linear(channel // reduction, channel, bias=False),
|
||||
nn.Sigmoid()
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
b, c, _, _ = x.size()
|
||||
y = self.avg_pool(x).view(b, c)
|
||||
y = self.fc(y).view(b, c, 1, 1)
|
||||
res = x * y.expand_as(x)
|
||||
return res
|
||||
@@ -1,29 +0,0 @@
|
||||
import logging
|
||||
import torch
|
||||
from annotator.lama.saicinpainting.training.trainers.default import DefaultInpaintingTrainingModule
|
||||
|
||||
|
||||
def get_training_model_class(kind):
|
||||
if kind == 'default':
|
||||
return DefaultInpaintingTrainingModule
|
||||
|
||||
raise ValueError(f'Unknown trainer module {kind}')
|
||||
|
||||
|
||||
def make_training_model(config):
|
||||
kind = config.training_model.kind
|
||||
kwargs = dict(config.training_model)
|
||||
kwargs.pop('kind')
|
||||
kwargs['use_ddp'] = config.trainer.kwargs.get('accelerator', None) == 'ddp'
|
||||
|
||||
logging.info(f'Make training model {kind}')
|
||||
|
||||
cls = get_training_model_class(kind)
|
||||
return cls(config, **kwargs)
|
||||
|
||||
|
||||
def load_checkpoint(train_config, path, map_location='cuda', strict=True):
|
||||
model = make_training_model(train_config).generator
|
||||
state = torch.load(path, map_location=map_location)
|
||||
model.load_state_dict(state, strict=strict)
|
||||
return model
|
||||
@@ -1,293 +0,0 @@
|
||||
import copy
|
||||
import logging
|
||||
from typing import Dict, Tuple
|
||||
|
||||
import pandas as pd
|
||||
import pytorch_lightning as ptl
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
# from torch.utils.data import DistributedSampler
|
||||
|
||||
# from annotator.lama.saicinpainting.evaluation import make_evaluator
|
||||
# from annotator.lama.saicinpainting.training.data.datasets import make_default_train_dataloader, make_default_val_dataloader
|
||||
# from annotator.lama.saicinpainting.training.losses.adversarial import make_discrim_loss
|
||||
# from annotator.lama.saicinpainting.training.losses.perceptual import PerceptualLoss, ResNetPL
|
||||
from annotator.lama.saicinpainting.training.modules import make_generator #, make_discriminator
|
||||
# from annotator.lama.saicinpainting.training.visualizers import make_visualizer
|
||||
from annotator.lama.saicinpainting.utils import add_prefix_to_keys, average_dicts, set_requires_grad, flatten_dict, \
|
||||
get_has_ddp_rank
|
||||
|
||||
LOGGER = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def make_optimizer(parameters, kind='adamw', **kwargs):
|
||||
if kind == 'adam':
|
||||
optimizer_class = torch.optim.Adam
|
||||
elif kind == 'adamw':
|
||||
optimizer_class = torch.optim.AdamW
|
||||
else:
|
||||
raise ValueError(f'Unknown optimizer kind {kind}')
|
||||
return optimizer_class(parameters, **kwargs)
|
||||
|
||||
|
||||
def update_running_average(result: nn.Module, new_iterate_model: nn.Module, decay=0.999):
|
||||
with torch.no_grad():
|
||||
res_params = dict(result.named_parameters())
|
||||
new_params = dict(new_iterate_model.named_parameters())
|
||||
|
||||
for k in res_params.keys():
|
||||
res_params[k].data.mul_(decay).add_(new_params[k].data, alpha=1 - decay)
|
||||
|
||||
|
||||
def make_multiscale_noise(base_tensor, scales=6, scale_mode='bilinear'):
|
||||
batch_size, _, height, width = base_tensor.shape
|
||||
cur_height, cur_width = height, width
|
||||
result = []
|
||||
align_corners = False if scale_mode in ('bilinear', 'bicubic') else None
|
||||
for _ in range(scales):
|
||||
cur_sample = torch.randn(batch_size, 1, cur_height, cur_width, device=base_tensor.device)
|
||||
cur_sample_scaled = F.interpolate(cur_sample, size=(height, width), mode=scale_mode, align_corners=align_corners)
|
||||
result.append(cur_sample_scaled)
|
||||
cur_height //= 2
|
||||
cur_width //= 2
|
||||
return torch.cat(result, dim=1)
|
||||
|
||||
|
||||
class BaseInpaintingTrainingModule(ptl.LightningModule):
|
||||
def __init__(self, config, use_ddp, *args, predict_only=False, visualize_each_iters=100,
|
||||
average_generator=False, generator_avg_beta=0.999, average_generator_start_step=30000,
|
||||
average_generator_period=10, store_discr_outputs_for_vis=False,
|
||||
**kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
LOGGER.info('BaseInpaintingTrainingModule init called')
|
||||
|
||||
self.config = config
|
||||
|
||||
self.generator = make_generator(config, **self.config.generator)
|
||||
self.use_ddp = use_ddp
|
||||
|
||||
if not get_has_ddp_rank():
|
||||
LOGGER.info(f'Generator\n{self.generator}')
|
||||
|
||||
# if not predict_only:
|
||||
# self.save_hyperparameters(self.config)
|
||||
# self.discriminator = make_discriminator(**self.config.discriminator)
|
||||
# self.adversarial_loss = make_discrim_loss(**self.config.losses.adversarial)
|
||||
# self.visualizer = make_visualizer(**self.config.visualizer)
|
||||
# self.val_evaluator = make_evaluator(**self.config.evaluator)
|
||||
# self.test_evaluator = make_evaluator(**self.config.evaluator)
|
||||
#
|
||||
# if not get_has_ddp_rank():
|
||||
# LOGGER.info(f'Discriminator\n{self.discriminator}')
|
||||
#
|
||||
# extra_val = self.config.data.get('extra_val', ())
|
||||
# if extra_val:
|
||||
# self.extra_val_titles = list(extra_val)
|
||||
# self.extra_evaluators = nn.ModuleDict({k: make_evaluator(**self.config.evaluator)
|
||||
# for k in extra_val})
|
||||
# else:
|
||||
# self.extra_evaluators = {}
|
||||
#
|
||||
# self.average_generator = average_generator
|
||||
# self.generator_avg_beta = generator_avg_beta
|
||||
# self.average_generator_start_step = average_generator_start_step
|
||||
# self.average_generator_period = average_generator_period
|
||||
# self.generator_average = None
|
||||
# self.last_generator_averaging_step = -1
|
||||
# self.store_discr_outputs_for_vis = store_discr_outputs_for_vis
|
||||
#
|
||||
# if self.config.losses.get("l1", {"weight_known": 0})['weight_known'] > 0:
|
||||
# self.loss_l1 = nn.L1Loss(reduction='none')
|
||||
#
|
||||
# if self.config.losses.get("mse", {"weight": 0})['weight'] > 0:
|
||||
# self.loss_mse = nn.MSELoss(reduction='none')
|
||||
#
|
||||
# if self.config.losses.perceptual.weight > 0:
|
||||
# self.loss_pl = PerceptualLoss()
|
||||
#
|
||||
# # if self.config.losses.get("resnet_pl", {"weight": 0})['weight'] > 0:
|
||||
# # self.loss_resnet_pl = ResNetPL(**self.config.losses.resnet_pl)
|
||||
# # else:
|
||||
# # self.loss_resnet_pl = None
|
||||
#
|
||||
# self.loss_resnet_pl = None
|
||||
|
||||
self.visualize_each_iters = visualize_each_iters
|
||||
LOGGER.info('BaseInpaintingTrainingModule init done')
|
||||
|
||||
def configure_optimizers(self):
|
||||
discriminator_params = list(self.discriminator.parameters())
|
||||
return [
|
||||
dict(optimizer=make_optimizer(self.generator.parameters(), **self.config.optimizers.generator)),
|
||||
dict(optimizer=make_optimizer(discriminator_params, **self.config.optimizers.discriminator)),
|
||||
]
|
||||
|
||||
def train_dataloader(self):
|
||||
kwargs = dict(self.config.data.train)
|
||||
if self.use_ddp:
|
||||
kwargs['ddp_kwargs'] = dict(num_replicas=self.trainer.num_nodes * self.trainer.num_processes,
|
||||
rank=self.trainer.global_rank,
|
||||
shuffle=True)
|
||||
dataloader = make_default_train_dataloader(**self.config.data.train)
|
||||
return dataloader
|
||||
|
||||
def val_dataloader(self):
|
||||
res = [make_default_val_dataloader(**self.config.data.val)]
|
||||
|
||||
if self.config.data.visual_test is not None:
|
||||
res = res + [make_default_val_dataloader(**self.config.data.visual_test)]
|
||||
else:
|
||||
res = res + res
|
||||
|
||||
extra_val = self.config.data.get('extra_val', ())
|
||||
if extra_val:
|
||||
res += [make_default_val_dataloader(**extra_val[k]) for k in self.extra_val_titles]
|
||||
|
||||
return res
|
||||
|
||||
def training_step(self, batch, batch_idx, optimizer_idx=None):
|
||||
self._is_training_step = True
|
||||
return self._do_step(batch, batch_idx, mode='train', optimizer_idx=optimizer_idx)
|
||||
|
||||
def validation_step(self, batch, batch_idx, dataloader_idx):
|
||||
extra_val_key = None
|
||||
if dataloader_idx == 0:
|
||||
mode = 'val'
|
||||
elif dataloader_idx == 1:
|
||||
mode = 'test'
|
||||
else:
|
||||
mode = 'extra_val'
|
||||
extra_val_key = self.extra_val_titles[dataloader_idx - 2]
|
||||
self._is_training_step = False
|
||||
return self._do_step(batch, batch_idx, mode=mode, extra_val_key=extra_val_key)
|
||||
|
||||
def training_step_end(self, batch_parts_outputs):
|
||||
if self.training and self.average_generator \
|
||||
and self.global_step >= self.average_generator_start_step \
|
||||
and self.global_step >= self.last_generator_averaging_step + self.average_generator_period:
|
||||
if self.generator_average is None:
|
||||
self.generator_average = copy.deepcopy(self.generator)
|
||||
else:
|
||||
update_running_average(self.generator_average, self.generator, decay=self.generator_avg_beta)
|
||||
self.last_generator_averaging_step = self.global_step
|
||||
|
||||
full_loss = (batch_parts_outputs['loss'].mean()
|
||||
if torch.is_tensor(batch_parts_outputs['loss']) # loss is not tensor when no discriminator used
|
||||
else torch.tensor(batch_parts_outputs['loss']).float().requires_grad_(True))
|
||||
log_info = {k: v.mean() for k, v in batch_parts_outputs['log_info'].items()}
|
||||
self.log_dict(log_info, on_step=True, on_epoch=False)
|
||||
return full_loss
|
||||
|
||||
def validation_epoch_end(self, outputs):
|
||||
outputs = [step_out for out_group in outputs for step_out in out_group]
|
||||
averaged_logs = average_dicts(step_out['log_info'] for step_out in outputs)
|
||||
self.log_dict({k: v.mean() for k, v in averaged_logs.items()})
|
||||
|
||||
pd.set_option('display.max_columns', 500)
|
||||
pd.set_option('display.width', 1000)
|
||||
|
||||
# standard validation
|
||||
val_evaluator_states = [s['val_evaluator_state'] for s in outputs if 'val_evaluator_state' in s]
|
||||
val_evaluator_res = self.val_evaluator.evaluation_end(states=val_evaluator_states)
|
||||
val_evaluator_res_df = pd.DataFrame(val_evaluator_res).stack(1).unstack(0)
|
||||
val_evaluator_res_df.dropna(axis=1, how='all', inplace=True)
|
||||
LOGGER.info(f'Validation metrics after epoch #{self.current_epoch}, '
|
||||
f'total {self.global_step} iterations:\n{val_evaluator_res_df}')
|
||||
|
||||
for k, v in flatten_dict(val_evaluator_res).items():
|
||||
self.log(f'val_{k}', v)
|
||||
|
||||
# standard visual test
|
||||
test_evaluator_states = [s['test_evaluator_state'] for s in outputs
|
||||
if 'test_evaluator_state' in s]
|
||||
test_evaluator_res = self.test_evaluator.evaluation_end(states=test_evaluator_states)
|
||||
test_evaluator_res_df = pd.DataFrame(test_evaluator_res).stack(1).unstack(0)
|
||||
test_evaluator_res_df.dropna(axis=1, how='all', inplace=True)
|
||||
LOGGER.info(f'Test metrics after epoch #{self.current_epoch}, '
|
||||
f'total {self.global_step} iterations:\n{test_evaluator_res_df}')
|
||||
|
||||
for k, v in flatten_dict(test_evaluator_res).items():
|
||||
self.log(f'test_{k}', v)
|
||||
|
||||
# extra validations
|
||||
if self.extra_evaluators:
|
||||
for cur_eval_title, cur_evaluator in self.extra_evaluators.items():
|
||||
cur_state_key = f'extra_val_{cur_eval_title}_evaluator_state'
|
||||
cur_states = [s[cur_state_key] for s in outputs if cur_state_key in s]
|
||||
cur_evaluator_res = cur_evaluator.evaluation_end(states=cur_states)
|
||||
cur_evaluator_res_df = pd.DataFrame(cur_evaluator_res).stack(1).unstack(0)
|
||||
cur_evaluator_res_df.dropna(axis=1, how='all', inplace=True)
|
||||
LOGGER.info(f'Extra val {cur_eval_title} metrics after epoch #{self.current_epoch}, '
|
||||
f'total {self.global_step} iterations:\n{cur_evaluator_res_df}')
|
||||
for k, v in flatten_dict(cur_evaluator_res).items():
|
||||
self.log(f'extra_val_{cur_eval_title}_{k}', v)
|
||||
|
||||
def _do_step(self, batch, batch_idx, mode='train', optimizer_idx=None, extra_val_key=None):
|
||||
if optimizer_idx == 0: # step for generator
|
||||
set_requires_grad(self.generator, True)
|
||||
set_requires_grad(self.discriminator, False)
|
||||
elif optimizer_idx == 1: # step for discriminator
|
||||
set_requires_grad(self.generator, False)
|
||||
set_requires_grad(self.discriminator, True)
|
||||
|
||||
batch = self(batch)
|
||||
|
||||
total_loss = 0
|
||||
metrics = {}
|
||||
|
||||
if optimizer_idx is None or optimizer_idx == 0: # step for generator
|
||||
total_loss, metrics = self.generator_loss(batch)
|
||||
|
||||
elif optimizer_idx is None or optimizer_idx == 1: # step for discriminator
|
||||
if self.config.losses.adversarial.weight > 0:
|
||||
total_loss, metrics = self.discriminator_loss(batch)
|
||||
|
||||
if self.get_ddp_rank() in (None, 0) and (batch_idx % self.visualize_each_iters == 0 or mode == 'test'):
|
||||
if self.config.losses.adversarial.weight > 0:
|
||||
if self.store_discr_outputs_for_vis:
|
||||
with torch.no_grad():
|
||||
self.store_discr_outputs(batch)
|
||||
vis_suffix = f'_{mode}'
|
||||
if mode == 'extra_val':
|
||||
vis_suffix += f'_{extra_val_key}'
|
||||
self.visualizer(self.current_epoch, batch_idx, batch, suffix=vis_suffix)
|
||||
|
||||
metrics_prefix = f'{mode}_'
|
||||
if mode == 'extra_val':
|
||||
metrics_prefix += f'{extra_val_key}_'
|
||||
result = dict(loss=total_loss, log_info=add_prefix_to_keys(metrics, metrics_prefix))
|
||||
if mode == 'val':
|
||||
result['val_evaluator_state'] = self.val_evaluator.process_batch(batch)
|
||||
elif mode == 'test':
|
||||
result['test_evaluator_state'] = self.test_evaluator.process_batch(batch)
|
||||
elif mode == 'extra_val':
|
||||
result[f'extra_val_{extra_val_key}_evaluator_state'] = self.extra_evaluators[extra_val_key].process_batch(batch)
|
||||
|
||||
return result
|
||||
|
||||
def get_current_generator(self, no_average=False):
|
||||
if not no_average and not self.training and self.average_generator and self.generator_average is not None:
|
||||
return self.generator_average
|
||||
return self.generator
|
||||
|
||||
def forward(self, batch: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
|
||||
"""Pass data through generator and obtain at leas 'predicted_image' and 'inpainted' keys"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def generator_loss(self, batch) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
raise NotImplementedError()
|
||||
|
||||
def discriminator_loss(self, batch) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
||||
raise NotImplementedError()
|
||||
|
||||
def store_discr_outputs(self, batch):
|
||||
out_size = batch['image'].shape[2:]
|
||||
discr_real_out, _ = self.discriminator(batch['image'])
|
||||
discr_fake_out, _ = self.discriminator(batch['predicted_image'])
|
||||
batch['discr_output_real'] = F.interpolate(discr_real_out, size=out_size, mode='nearest')
|
||||
batch['discr_output_fake'] = F.interpolate(discr_fake_out, size=out_size, mode='nearest')
|
||||
batch['discr_output_diff'] = batch['discr_output_real'] - batch['discr_output_fake']
|
||||
|
||||
def get_ddp_rank(self):
|
||||
return self.trainer.global_rank if (self.trainer.num_nodes * self.trainer.num_processes) > 1 else None
|
||||
@@ -1,175 +0,0 @@
|
||||
import logging
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from omegaconf import OmegaConf
|
||||
|
||||
# from annotator.lama.saicinpainting.training.data.datasets import make_constant_area_crop_params
|
||||
from annotator.lama.saicinpainting.training.losses.distance_weighting import make_mask_distance_weighter
|
||||
from annotator.lama.saicinpainting.training.losses.feature_matching import feature_matching_loss, masked_l1_loss
|
||||
# from annotator.lama.saicinpainting.training.modules.fake_fakes import FakeFakesGenerator
|
||||
from annotator.lama.saicinpainting.training.trainers.base import BaseInpaintingTrainingModule, make_multiscale_noise
|
||||
from annotator.lama.saicinpainting.utils import add_prefix_to_keys, get_ramp
|
||||
|
||||
LOGGER = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def make_constant_area_crop_batch(batch, **kwargs):
|
||||
crop_y, crop_x, crop_height, crop_width = make_constant_area_crop_params(img_height=batch['image'].shape[2],
|
||||
img_width=batch['image'].shape[3],
|
||||
**kwargs)
|
||||
batch['image'] = batch['image'][:, :, crop_y : crop_y + crop_height, crop_x : crop_x + crop_width]
|
||||
batch['mask'] = batch['mask'][:, :, crop_y: crop_y + crop_height, crop_x: crop_x + crop_width]
|
||||
return batch
|
||||
|
||||
|
||||
class DefaultInpaintingTrainingModule(BaseInpaintingTrainingModule):
|
||||
def __init__(self, *args, concat_mask=True, rescale_scheduler_kwargs=None, image_to_discriminator='predicted_image',
|
||||
add_noise_kwargs=None, noise_fill_hole=False, const_area_crop_kwargs=None,
|
||||
distance_weighter_kwargs=None, distance_weighted_mask_for_discr=False,
|
||||
fake_fakes_proba=0, fake_fakes_generator_kwargs=None,
|
||||
**kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.concat_mask = concat_mask
|
||||
self.rescale_size_getter = get_ramp(**rescale_scheduler_kwargs) if rescale_scheduler_kwargs is not None else None
|
||||
self.image_to_discriminator = image_to_discriminator
|
||||
self.add_noise_kwargs = add_noise_kwargs
|
||||
self.noise_fill_hole = noise_fill_hole
|
||||
self.const_area_crop_kwargs = const_area_crop_kwargs
|
||||
self.refine_mask_for_losses = make_mask_distance_weighter(**distance_weighter_kwargs) \
|
||||
if distance_weighter_kwargs is not None else None
|
||||
self.distance_weighted_mask_for_discr = distance_weighted_mask_for_discr
|
||||
|
||||
self.fake_fakes_proba = fake_fakes_proba
|
||||
if self.fake_fakes_proba > 1e-3:
|
||||
self.fake_fakes_gen = FakeFakesGenerator(**(fake_fakes_generator_kwargs or {}))
|
||||
|
||||
def forward(self, batch):
|
||||
if self.training and self.rescale_size_getter is not None:
|
||||
cur_size = self.rescale_size_getter(self.global_step)
|
||||
batch['image'] = F.interpolate(batch['image'], size=cur_size, mode='bilinear', align_corners=False)
|
||||
batch['mask'] = F.interpolate(batch['mask'], size=cur_size, mode='nearest')
|
||||
|
||||
if self.training and self.const_area_crop_kwargs is not None:
|
||||
batch = make_constant_area_crop_batch(batch, **self.const_area_crop_kwargs)
|
||||
|
||||
img = batch['image']
|
||||
mask = batch['mask']
|
||||
|
||||
masked_img = img * (1 - mask)
|
||||
|
||||
if self.add_noise_kwargs is not None:
|
||||
noise = make_multiscale_noise(masked_img, **self.add_noise_kwargs)
|
||||
if self.noise_fill_hole:
|
||||
masked_img = masked_img + mask * noise[:, :masked_img.shape[1]]
|
||||
masked_img = torch.cat([masked_img, noise], dim=1)
|
||||
|
||||
if self.concat_mask:
|
||||
masked_img = torch.cat([masked_img, mask], dim=1)
|
||||
|
||||
batch['predicted_image'] = self.generator(masked_img)
|
||||
batch['inpainted'] = mask * batch['predicted_image'] + (1 - mask) * batch['image']
|
||||
|
||||
if self.fake_fakes_proba > 1e-3:
|
||||
if self.training and torch.rand(1).item() < self.fake_fakes_proba:
|
||||
batch['fake_fakes'], batch['fake_fakes_masks'] = self.fake_fakes_gen(img, mask)
|
||||
batch['use_fake_fakes'] = True
|
||||
else:
|
||||
batch['fake_fakes'] = torch.zeros_like(img)
|
||||
batch['fake_fakes_masks'] = torch.zeros_like(mask)
|
||||
batch['use_fake_fakes'] = False
|
||||
|
||||
batch['mask_for_losses'] = self.refine_mask_for_losses(img, batch['predicted_image'], mask) \
|
||||
if self.refine_mask_for_losses is not None and self.training \
|
||||
else mask
|
||||
|
||||
return batch
|
||||
|
||||
def generator_loss(self, batch):
|
||||
img = batch['image']
|
||||
predicted_img = batch[self.image_to_discriminator]
|
||||
original_mask = batch['mask']
|
||||
supervised_mask = batch['mask_for_losses']
|
||||
|
||||
# L1
|
||||
l1_value = masked_l1_loss(predicted_img, img, supervised_mask,
|
||||
self.config.losses.l1.weight_known,
|
||||
self.config.losses.l1.weight_missing)
|
||||
|
||||
total_loss = l1_value
|
||||
metrics = dict(gen_l1=l1_value)
|
||||
|
||||
# vgg-based perceptual loss
|
||||
if self.config.losses.perceptual.weight > 0:
|
||||
pl_value = self.loss_pl(predicted_img, img, mask=supervised_mask).sum() * self.config.losses.perceptual.weight
|
||||
total_loss = total_loss + pl_value
|
||||
metrics['gen_pl'] = pl_value
|
||||
|
||||
# discriminator
|
||||
# adversarial_loss calls backward by itself
|
||||
mask_for_discr = supervised_mask if self.distance_weighted_mask_for_discr else original_mask
|
||||
self.adversarial_loss.pre_generator_step(real_batch=img, fake_batch=predicted_img,
|
||||
generator=self.generator, discriminator=self.discriminator)
|
||||
discr_real_pred, discr_real_features = self.discriminator(img)
|
||||
discr_fake_pred, discr_fake_features = self.discriminator(predicted_img)
|
||||
adv_gen_loss, adv_metrics = self.adversarial_loss.generator_loss(real_batch=img,
|
||||
fake_batch=predicted_img,
|
||||
discr_real_pred=discr_real_pred,
|
||||
discr_fake_pred=discr_fake_pred,
|
||||
mask=mask_for_discr)
|
||||
total_loss = total_loss + adv_gen_loss
|
||||
metrics['gen_adv'] = adv_gen_loss
|
||||
metrics.update(add_prefix_to_keys(adv_metrics, 'adv_'))
|
||||
|
||||
# feature matching
|
||||
if self.config.losses.feature_matching.weight > 0:
|
||||
need_mask_in_fm = OmegaConf.to_container(self.config.losses.feature_matching).get('pass_mask', False)
|
||||
mask_for_fm = supervised_mask if need_mask_in_fm else None
|
||||
fm_value = feature_matching_loss(discr_fake_features, discr_real_features,
|
||||
mask=mask_for_fm) * self.config.losses.feature_matching.weight
|
||||
total_loss = total_loss + fm_value
|
||||
metrics['gen_fm'] = fm_value
|
||||
|
||||
if self.loss_resnet_pl is not None:
|
||||
resnet_pl_value = self.loss_resnet_pl(predicted_img, img)
|
||||
total_loss = total_loss + resnet_pl_value
|
||||
metrics['gen_resnet_pl'] = resnet_pl_value
|
||||
|
||||
return total_loss, metrics
|
||||
|
||||
def discriminator_loss(self, batch):
|
||||
total_loss = 0
|
||||
metrics = {}
|
||||
|
||||
predicted_img = batch[self.image_to_discriminator].detach()
|
||||
self.adversarial_loss.pre_discriminator_step(real_batch=batch['image'], fake_batch=predicted_img,
|
||||
generator=self.generator, discriminator=self.discriminator)
|
||||
discr_real_pred, discr_real_features = self.discriminator(batch['image'])
|
||||
discr_fake_pred, discr_fake_features = self.discriminator(predicted_img)
|
||||
adv_discr_loss, adv_metrics = self.adversarial_loss.discriminator_loss(real_batch=batch['image'],
|
||||
fake_batch=predicted_img,
|
||||
discr_real_pred=discr_real_pred,
|
||||
discr_fake_pred=discr_fake_pred,
|
||||
mask=batch['mask'])
|
||||
total_loss = total_loss + adv_discr_loss
|
||||
metrics['discr_adv'] = adv_discr_loss
|
||||
metrics.update(add_prefix_to_keys(adv_metrics, 'adv_'))
|
||||
|
||||
|
||||
if batch.get('use_fake_fakes', False):
|
||||
fake_fakes = batch['fake_fakes']
|
||||
self.adversarial_loss.pre_discriminator_step(real_batch=batch['image'], fake_batch=fake_fakes,
|
||||
generator=self.generator, discriminator=self.discriminator)
|
||||
discr_fake_fakes_pred, _ = self.discriminator(fake_fakes)
|
||||
fake_fakes_adv_discr_loss, fake_fakes_adv_metrics = self.adversarial_loss.discriminator_loss(
|
||||
real_batch=batch['image'],
|
||||
fake_batch=fake_fakes,
|
||||
discr_real_pred=discr_real_pred,
|
||||
discr_fake_pred=discr_fake_fakes_pred,
|
||||
mask=batch['mask']
|
||||
)
|
||||
total_loss = total_loss + fake_fakes_adv_discr_loss
|
||||
metrics['discr_adv_fake_fakes'] = fake_fakes_adv_discr_loss
|
||||
metrics.update(add_prefix_to_keys(fake_fakes_adv_metrics, 'adv_'))
|
||||
|
||||
return total_loss, metrics
|
||||
@@ -1,15 +0,0 @@
|
||||
import logging
|
||||
|
||||
from annotator.lama.saicinpainting.training.visualizers.directory import DirectoryVisualizer
|
||||
from annotator.lama.saicinpainting.training.visualizers.noop import NoopVisualizer
|
||||
|
||||
|
||||
def make_visualizer(kind, **kwargs):
|
||||
logging.info(f'Make visualizer {kind}')
|
||||
|
||||
if kind == 'directory':
|
||||
return DirectoryVisualizer(**kwargs)
|
||||
if kind == 'noop':
|
||||
return NoopVisualizer()
|
||||
|
||||
raise ValueError(f'Unknown visualizer kind {kind}')
|
||||
@@ -1,73 +0,0 @@
|
||||
import abc
|
||||
from typing import Dict, List
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from skimage import color
|
||||
from skimage.segmentation import mark_boundaries
|
||||
|
||||
from . import colors
|
||||
|
||||
COLORS, _ = colors.generate_colors(151) # 151 - max classes for semantic segmentation
|
||||
|
||||
|
||||
class BaseVisualizer:
|
||||
@abc.abstractmethod
|
||||
def __call__(self, epoch_i, batch_i, batch, suffix='', rank=None):
|
||||
"""
|
||||
Take a batch, make an image from it and visualize
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
def visualize_mask_and_images(images_dict: Dict[str, np.ndarray], keys: List[str],
|
||||
last_without_mask=True, rescale_keys=None, mask_only_first=None,
|
||||
black_mask=False) -> np.ndarray:
|
||||
mask = images_dict['mask'] > 0.5
|
||||
result = []
|
||||
for i, k in enumerate(keys):
|
||||
img = images_dict[k]
|
||||
img = np.transpose(img, (1, 2, 0))
|
||||
|
||||
if rescale_keys is not None and k in rescale_keys:
|
||||
img = img - img.min()
|
||||
img /= img.max() + 1e-5
|
||||
if len(img.shape) == 2:
|
||||
img = np.expand_dims(img, 2)
|
||||
|
||||
if img.shape[2] == 1:
|
||||
img = np.repeat(img, 3, axis=2)
|
||||
elif (img.shape[2] > 3):
|
||||
img_classes = img.argmax(2)
|
||||
img = color.label2rgb(img_classes, colors=COLORS)
|
||||
|
||||
if mask_only_first:
|
||||
need_mark_boundaries = i == 0
|
||||
else:
|
||||
need_mark_boundaries = i < len(keys) - 1 or not last_without_mask
|
||||
|
||||
if need_mark_boundaries:
|
||||
if black_mask:
|
||||
img = img * (1 - mask[0][..., None])
|
||||
img = mark_boundaries(img,
|
||||
mask[0],
|
||||
color=(1., 0., 0.),
|
||||
outline_color=(1., 1., 1.),
|
||||
mode='thick')
|
||||
result.append(img)
|
||||
return np.concatenate(result, axis=1)
|
||||
|
||||
|
||||
def visualize_mask_and_images_batch(batch: Dict[str, torch.Tensor], keys: List[str], max_items=10,
|
||||
last_without_mask=True, rescale_keys=None) -> np.ndarray:
|
||||
batch = {k: tens.detach().cpu().numpy() for k, tens in batch.items()
|
||||
if k in keys or k == 'mask'}
|
||||
|
||||
batch_size = next(iter(batch.values())).shape[0]
|
||||
items_to_vis = min(batch_size, max_items)
|
||||
result = []
|
||||
for i in range(items_to_vis):
|
||||
cur_dct = {k: tens[i] for k, tens in batch.items()}
|
||||
result.append(visualize_mask_and_images(cur_dct, keys, last_without_mask=last_without_mask,
|
||||
rescale_keys=rescale_keys))
|
||||
return np.concatenate(result, axis=0)
|
||||
@@ -1,76 +0,0 @@
|
||||
import random
|
||||
import colorsys
|
||||
|
||||
import numpy as np
|
||||
import matplotlib
|
||||
matplotlib.use('agg')
|
||||
import matplotlib.pyplot as plt
|
||||
from matplotlib.colors import LinearSegmentedColormap
|
||||
|
||||
|
||||
def generate_colors(nlabels, type='bright', first_color_black=False, last_color_black=True, verbose=False):
|
||||
# https://stackoverflow.com/questions/14720331/how-to-generate-random-colors-in-matplotlib
|
||||
"""
|
||||
Creates a random colormap to be used together with matplotlib. Useful for segmentation tasks
|
||||
:param nlabels: Number of labels (size of colormap)
|
||||
:param type: 'bright' for strong colors, 'soft' for pastel colors
|
||||
:param first_color_black: Option to use first color as black, True or False
|
||||
:param last_color_black: Option to use last color as black, True or False
|
||||
:param verbose: Prints the number of labels and shows the colormap. True or False
|
||||
:return: colormap for matplotlib
|
||||
"""
|
||||
if type not in ('bright', 'soft'):
|
||||
print ('Please choose "bright" or "soft" for type')
|
||||
return
|
||||
|
||||
if verbose:
|
||||
print('Number of labels: ' + str(nlabels))
|
||||
|
||||
# Generate color map for bright colors, based on hsv
|
||||
if type == 'bright':
|
||||
randHSVcolors = [(np.random.uniform(low=0.0, high=1),
|
||||
np.random.uniform(low=0.2, high=1),
|
||||
np.random.uniform(low=0.9, high=1)) for i in range(nlabels)]
|
||||
|
||||
# Convert HSV list to RGB
|
||||
randRGBcolors = []
|
||||
for HSVcolor in randHSVcolors:
|
||||
randRGBcolors.append(colorsys.hsv_to_rgb(HSVcolor[0], HSVcolor[1], HSVcolor[2]))
|
||||
|
||||
if first_color_black:
|
||||
randRGBcolors[0] = [0, 0, 0]
|
||||
|
||||
if last_color_black:
|
||||
randRGBcolors[-1] = [0, 0, 0]
|
||||
|
||||
random_colormap = LinearSegmentedColormap.from_list('new_map', randRGBcolors, N=nlabels)
|
||||
|
||||
# Generate soft pastel colors, by limiting the RGB spectrum
|
||||
if type == 'soft':
|
||||
low = 0.6
|
||||
high = 0.95
|
||||
randRGBcolors = [(np.random.uniform(low=low, high=high),
|
||||
np.random.uniform(low=low, high=high),
|
||||
np.random.uniform(low=low, high=high)) for i in range(nlabels)]
|
||||
|
||||
if first_color_black:
|
||||
randRGBcolors[0] = [0, 0, 0]
|
||||
|
||||
if last_color_black:
|
||||
randRGBcolors[-1] = [0, 0, 0]
|
||||
random_colormap = LinearSegmentedColormap.from_list('new_map', randRGBcolors, N=nlabels)
|
||||
|
||||
# Display colorbar
|
||||
if verbose:
|
||||
from matplotlib import colors, colorbar
|
||||
from matplotlib import pyplot as plt
|
||||
fig, ax = plt.subplots(1, 1, figsize=(15, 0.5))
|
||||
|
||||
bounds = np.linspace(0, nlabels, nlabels + 1)
|
||||
norm = colors.BoundaryNorm(bounds, nlabels)
|
||||
|
||||
cb = colorbar.ColorbarBase(ax, cmap=random_colormap, norm=norm, spacing='proportional', ticks=None,
|
||||
boundaries=bounds, format='%1i', orientation=u'horizontal')
|
||||
|
||||
return randRGBcolors, random_colormap
|
||||
|
||||
@@ -1,36 +0,0 @@
|
||||
import os
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
from annotator.lama.saicinpainting.training.visualizers.base import BaseVisualizer, visualize_mask_and_images_batch
|
||||
from annotator.lama.saicinpainting.utils import check_and_warn_input_range
|
||||
|
||||
|
||||
class DirectoryVisualizer(BaseVisualizer):
|
||||
DEFAULT_KEY_ORDER = 'image predicted_image inpainted'.split(' ')
|
||||
|
||||
def __init__(self, outdir, key_order=DEFAULT_KEY_ORDER, max_items_in_batch=10,
|
||||
last_without_mask=True, rescale_keys=None):
|
||||
self.outdir = outdir
|
||||
os.makedirs(self.outdir, exist_ok=True)
|
||||
self.key_order = key_order
|
||||
self.max_items_in_batch = max_items_in_batch
|
||||
self.last_without_mask = last_without_mask
|
||||
self.rescale_keys = rescale_keys
|
||||
|
||||
def __call__(self, epoch_i, batch_i, batch, suffix='', rank=None):
|
||||
check_and_warn_input_range(batch['image'], 0, 1, 'DirectoryVisualizer target image')
|
||||
vis_img = visualize_mask_and_images_batch(batch, self.key_order, max_items=self.max_items_in_batch,
|
||||
last_without_mask=self.last_without_mask,
|
||||
rescale_keys=self.rescale_keys)
|
||||
|
||||
vis_img = np.clip(vis_img * 255, 0, 255).astype('uint8')
|
||||
|
||||
curoutdir = os.path.join(self.outdir, f'epoch{epoch_i:04d}{suffix}')
|
||||
os.makedirs(curoutdir, exist_ok=True)
|
||||
rank_suffix = f'_r{rank}' if rank is not None else ''
|
||||
out_fname = os.path.join(curoutdir, f'batch{batch_i:07d}{rank_suffix}.jpg')
|
||||
|
||||
vis_img = cv2.cvtColor(vis_img, cv2.COLOR_RGB2BGR)
|
||||
cv2.imwrite(out_fname, vis_img)
|
||||
@@ -1,9 +0,0 @@
|
||||
from annotator.lama.saicinpainting.training.visualizers.base import BaseVisualizer
|
||||
|
||||
|
||||
class NoopVisualizer(BaseVisualizer):
|
||||
def __init__(self, *args, **kwargs):
|
||||
pass
|
||||
|
||||
def __call__(self, epoch_i, batch_i, batch, suffix='', rank=None):
|
||||
pass
|
||||
@@ -1,174 +0,0 @@
|
||||
import bisect
|
||||
import functools
|
||||
import logging
|
||||
import numbers
|
||||
import os
|
||||
import signal
|
||||
import sys
|
||||
import traceback
|
||||
import warnings
|
||||
|
||||
import torch
|
||||
from pytorch_lightning import seed_everything
|
||||
|
||||
LOGGER = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def check_and_warn_input_range(tensor, min_value, max_value, name):
|
||||
actual_min = tensor.min()
|
||||
actual_max = tensor.max()
|
||||
if actual_min < min_value or actual_max > max_value:
|
||||
warnings.warn(f"{name} must be in {min_value}..{max_value} range, but it ranges {actual_min}..{actual_max}")
|
||||
|
||||
|
||||
def sum_dict_with_prefix(target, cur_dict, prefix, default=0):
|
||||
for k, v in cur_dict.items():
|
||||
target_key = prefix + k
|
||||
target[target_key] = target.get(target_key, default) + v
|
||||
|
||||
|
||||
def average_dicts(dict_list):
|
||||
result = {}
|
||||
norm = 1e-3
|
||||
for dct in dict_list:
|
||||
sum_dict_with_prefix(result, dct, '')
|
||||
norm += 1
|
||||
for k in list(result):
|
||||
result[k] /= norm
|
||||
return result
|
||||
|
||||
|
||||
def add_prefix_to_keys(dct, prefix):
|
||||
return {prefix + k: v for k, v in dct.items()}
|
||||
|
||||
|
||||
def set_requires_grad(module, value):
|
||||
for param in module.parameters():
|
||||
param.requires_grad = value
|
||||
|
||||
|
||||
def flatten_dict(dct):
|
||||
result = {}
|
||||
for k, v in dct.items():
|
||||
if isinstance(k, tuple):
|
||||
k = '_'.join(k)
|
||||
if isinstance(v, dict):
|
||||
for sub_k, sub_v in flatten_dict(v).items():
|
||||
result[f'{k}_{sub_k}'] = sub_v
|
||||
else:
|
||||
result[k] = v
|
||||
return result
|
||||
|
||||
|
||||
class LinearRamp:
|
||||
def __init__(self, start_value=0, end_value=1, start_iter=-1, end_iter=0):
|
||||
self.start_value = start_value
|
||||
self.end_value = end_value
|
||||
self.start_iter = start_iter
|
||||
self.end_iter = end_iter
|
||||
|
||||
def __call__(self, i):
|
||||
if i < self.start_iter:
|
||||
return self.start_value
|
||||
if i >= self.end_iter:
|
||||
return self.end_value
|
||||
part = (i - self.start_iter) / (self.end_iter - self.start_iter)
|
||||
return self.start_value * (1 - part) + self.end_value * part
|
||||
|
||||
|
||||
class LadderRamp:
|
||||
def __init__(self, start_iters, values):
|
||||
self.start_iters = start_iters
|
||||
self.values = values
|
||||
assert len(values) == len(start_iters) + 1, (len(values), len(start_iters))
|
||||
|
||||
def __call__(self, i):
|
||||
segment_i = bisect.bisect_right(self.start_iters, i)
|
||||
return self.values[segment_i]
|
||||
|
||||
|
||||
def get_ramp(kind='ladder', **kwargs):
|
||||
if kind == 'linear':
|
||||
return LinearRamp(**kwargs)
|
||||
if kind == 'ladder':
|
||||
return LadderRamp(**kwargs)
|
||||
raise ValueError(f'Unexpected ramp kind: {kind}')
|
||||
|
||||
|
||||
def print_traceback_handler(sig, frame):
|
||||
LOGGER.warning(f'Received signal {sig}')
|
||||
bt = ''.join(traceback.format_stack())
|
||||
LOGGER.warning(f'Requested stack trace:\n{bt}')
|
||||
|
||||
|
||||
def register_debug_signal_handlers(sig=None, handler=print_traceback_handler):
|
||||
LOGGER.warning(f'Setting signal {sig} handler {handler}')
|
||||
signal.signal(sig, handler)
|
||||
|
||||
|
||||
def handle_deterministic_config(config):
|
||||
seed = dict(config).get('seed', None)
|
||||
if seed is None:
|
||||
return False
|
||||
|
||||
seed_everything(seed)
|
||||
return True
|
||||
|
||||
|
||||
def get_shape(t):
|
||||
if torch.is_tensor(t):
|
||||
return tuple(t.shape)
|
||||
elif isinstance(t, dict):
|
||||
return {n: get_shape(q) for n, q in t.items()}
|
||||
elif isinstance(t, (list, tuple)):
|
||||
return [get_shape(q) for q in t]
|
||||
elif isinstance(t, numbers.Number):
|
||||
return type(t)
|
||||
else:
|
||||
raise ValueError('unexpected type {}'.format(type(t)))
|
||||
|
||||
|
||||
def get_has_ddp_rank():
|
||||
master_port = os.environ.get('MASTER_PORT', None)
|
||||
node_rank = os.environ.get('NODE_RANK', None)
|
||||
local_rank = os.environ.get('LOCAL_RANK', None)
|
||||
world_size = os.environ.get('WORLD_SIZE', None)
|
||||
has_rank = master_port is not None or node_rank is not None or local_rank is not None or world_size is not None
|
||||
return has_rank
|
||||
|
||||
|
||||
def handle_ddp_subprocess():
|
||||
def main_decorator(main_func):
|
||||
@functools.wraps(main_func)
|
||||
def new_main(*args, **kwargs):
|
||||
# Trainer sets MASTER_PORT, NODE_RANK, LOCAL_RANK, WORLD_SIZE
|
||||
parent_cwd = os.environ.get('TRAINING_PARENT_WORK_DIR', None)
|
||||
has_parent = parent_cwd is not None
|
||||
has_rank = get_has_ddp_rank()
|
||||
assert has_parent == has_rank, f'Inconsistent state: has_parent={has_parent}, has_rank={has_rank}'
|
||||
|
||||
if has_parent:
|
||||
# we are in the worker
|
||||
sys.argv.extend([
|
||||
f'hydra.run.dir={parent_cwd}',
|
||||
# 'hydra/hydra_logging=disabled',
|
||||
# 'hydra/job_logging=disabled'
|
||||
])
|
||||
# do nothing if this is a top-level process
|
||||
# TRAINING_PARENT_WORK_DIR is set in handle_ddp_parent_process after hydra initialization
|
||||
|
||||
main_func(*args, **kwargs)
|
||||
return new_main
|
||||
return main_decorator
|
||||
|
||||
|
||||
def handle_ddp_parent_process():
|
||||
parent_cwd = os.environ.get('TRAINING_PARENT_WORK_DIR', None)
|
||||
has_parent = parent_cwd is not None
|
||||
has_rank = get_has_ddp_rank()
|
||||
assert has_parent == has_rank, f'Inconsistent state: has_parent={has_parent}, has_rank={has_rank}'
|
||||
|
||||
if parent_cwd is None:
|
||||
os.environ['TRAINING_PARENT_WORK_DIR'] = os.getcwd()
|
||||
|
||||
return has_parent
|
||||
@@ -1,113 +0,0 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
import torch
|
||||
import os
|
||||
from modules import devices, shared
|
||||
from annotator.annotator_path import models_path
|
||||
from torchvision.transforms import transforms
|
||||
|
||||
# AdelaiDepth/LeReS imports
|
||||
from .leres.depthmap import estimateleres, estimateboost
|
||||
from .leres.multi_depth_model_woauxi import RelDepthModel
|
||||
from .leres.net_tools import strip_prefix_if_present
|
||||
|
||||
# pix2pix/merge net imports
|
||||
from .pix2pix.options.test_options import TestOptions
|
||||
from .pix2pix.models.pix2pix4depth_model import Pix2Pix4DepthModel
|
||||
|
||||
base_model_path = os.path.join(models_path, "leres")
|
||||
old_modeldir = os.path.dirname(os.path.realpath(__file__))
|
||||
|
||||
remote_model_path_leres = "https://huggingface.co/lllyasviel/Annotators/resolve/main/res101.pth"
|
||||
remote_model_path_pix2pix = "https://huggingface.co/lllyasviel/Annotators/resolve/main/latest_net_G.pth"
|
||||
|
||||
model = None
|
||||
pix2pixmodel = None
|
||||
|
||||
def unload_leres_model():
|
||||
global model, pix2pixmodel
|
||||
if model is not None:
|
||||
model = model.cpu()
|
||||
if pix2pixmodel is not None:
|
||||
pix2pixmodel = pix2pixmodel.unload_network('G')
|
||||
|
||||
|
||||
def apply_leres(input_image, thr_a, thr_b, boost=False):
|
||||
global model, pix2pixmodel
|
||||
if model is None:
|
||||
model_path = os.path.join(base_model_path, "res101.pth")
|
||||
old_model_path = os.path.join(old_modeldir, "res101.pth")
|
||||
|
||||
if os.path.exists(old_model_path):
|
||||
model_path = old_model_path
|
||||
elif not os.path.exists(model_path):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path_leres, model_dir=base_model_path)
|
||||
|
||||
if torch.cuda.is_available():
|
||||
checkpoint = torch.load(model_path)
|
||||
else:
|
||||
checkpoint = torch.load(model_path, map_location=torch.device('cpu'))
|
||||
|
||||
model = RelDepthModel(backbone='resnext101')
|
||||
model.load_state_dict(strip_prefix_if_present(checkpoint['depth_model'], "module."), strict=True)
|
||||
del checkpoint
|
||||
|
||||
if boost and pix2pixmodel is None:
|
||||
pix2pixmodel_path = os.path.join(base_model_path, "latest_net_G.pth")
|
||||
if not os.path.exists(pix2pixmodel_path):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path_pix2pix, model_dir=base_model_path)
|
||||
|
||||
opt = TestOptions().parse()
|
||||
if not torch.cuda.is_available():
|
||||
opt.gpu_ids = [] # cpu mode
|
||||
pix2pixmodel = Pix2Pix4DepthModel(opt)
|
||||
pix2pixmodel.save_dir = base_model_path
|
||||
pix2pixmodel.load_networks('latest')
|
||||
pix2pixmodel.eval()
|
||||
|
||||
if devices.get_device_for("controlnet").type != 'mps':
|
||||
model = model.to(devices.get_device_for("controlnet"))
|
||||
|
||||
assert input_image.ndim == 3
|
||||
height, width, dim = input_image.shape
|
||||
|
||||
with torch.no_grad():
|
||||
|
||||
if boost:
|
||||
depth = estimateboost(input_image, model, 0, pix2pixmodel, max(width, height))
|
||||
else:
|
||||
depth = estimateleres(input_image, model, width, height)
|
||||
|
||||
numbytes=2
|
||||
depth_min = depth.min()
|
||||
depth_max = depth.max()
|
||||
max_val = (2**(8*numbytes))-1
|
||||
|
||||
# check output before normalizing and mapping to 16 bit
|
||||
if depth_max - depth_min > np.finfo("float").eps:
|
||||
out = max_val * (depth - depth_min) / (depth_max - depth_min)
|
||||
else:
|
||||
out = np.zeros(depth.shape)
|
||||
|
||||
# single channel, 16 bit image
|
||||
depth_image = out.astype("uint16")
|
||||
|
||||
# convert to uint8
|
||||
depth_image = cv2.convertScaleAbs(depth_image, alpha=(255.0/65535.0))
|
||||
|
||||
# remove near
|
||||
if thr_a != 0:
|
||||
thr_a = ((thr_a/100)*255)
|
||||
depth_image = cv2.threshold(depth_image, thr_a, 255, cv2.THRESH_TOZERO)[1]
|
||||
|
||||
# invert image
|
||||
depth_image = cv2.bitwise_not(depth_image)
|
||||
|
||||
# remove bg
|
||||
if thr_b != 0:
|
||||
thr_b = ((thr_b/100)*255)
|
||||
depth_image = cv2.threshold(depth_image, thr_b, 255, cv2.THRESH_TOZERO)[1]
|
||||
|
||||
return depth_image
|
||||
@@ -1,23 +0,0 @@
|
||||
https://github.com/thygate/stable-diffusion-webui-depthmap-script
|
||||
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2023 Bob Thiry
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -1,199 +0,0 @@
|
||||
import torch.nn as nn
|
||||
import torch.nn as NN
|
||||
|
||||
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
|
||||
'resnet152']
|
||||
|
||||
|
||||
model_urls = {
|
||||
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
|
||||
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
|
||||
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
|
||||
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
|
||||
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
|
||||
}
|
||||
|
||||
|
||||
def conv3x3(in_planes, out_planes, stride=1):
|
||||
"""3x3 convolution with padding"""
|
||||
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
|
||||
padding=1, bias=False)
|
||||
|
||||
|
||||
class BasicBlock(nn.Module):
|
||||
expansion = 1
|
||||
|
||||
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
||||
super(BasicBlock, self).__init__()
|
||||
self.conv1 = conv3x3(inplanes, planes, stride)
|
||||
self.bn1 = NN.BatchNorm2d(planes) #NN.BatchNorm2d
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.conv2 = conv3x3(planes, planes)
|
||||
self.bn2 = NN.BatchNorm2d(planes) #NN.BatchNorm2d
|
||||
self.downsample = downsample
|
||||
self.stride = stride
|
||||
|
||||
def forward(self, x):
|
||||
residual = x
|
||||
|
||||
out = self.conv1(x)
|
||||
out = self.bn1(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv2(out)
|
||||
out = self.bn2(out)
|
||||
|
||||
if self.downsample is not None:
|
||||
residual = self.downsample(x)
|
||||
|
||||
out += residual
|
||||
out = self.relu(out)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class Bottleneck(nn.Module):
|
||||
expansion = 4
|
||||
|
||||
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
||||
super(Bottleneck, self).__init__()
|
||||
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
|
||||
self.bn1 = NN.BatchNorm2d(planes) #NN.BatchNorm2d
|
||||
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
|
||||
padding=1, bias=False)
|
||||
self.bn2 = NN.BatchNorm2d(planes) #NN.BatchNorm2d
|
||||
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
|
||||
self.bn3 = NN.BatchNorm2d(planes * self.expansion) #NN.BatchNorm2d
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.downsample = downsample
|
||||
self.stride = stride
|
||||
|
||||
def forward(self, x):
|
||||
residual = x
|
||||
|
||||
out = self.conv1(x)
|
||||
out = self.bn1(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv2(out)
|
||||
out = self.bn2(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv3(out)
|
||||
out = self.bn3(out)
|
||||
|
||||
if self.downsample is not None:
|
||||
residual = self.downsample(x)
|
||||
|
||||
out += residual
|
||||
out = self.relu(out)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class ResNet(nn.Module):
|
||||
|
||||
def __init__(self, block, layers, num_classes=1000):
|
||||
self.inplanes = 64
|
||||
super(ResNet, self).__init__()
|
||||
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
|
||||
bias=False)
|
||||
self.bn1 = NN.BatchNorm2d(64) #NN.BatchNorm2d
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
||||
self.layer1 = self._make_layer(block, 64, layers[0])
|
||||
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
|
||||
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
|
||||
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
|
||||
#self.avgpool = nn.AvgPool2d(7, stride=1)
|
||||
#self.fc = nn.Linear(512 * block.expansion, num_classes)
|
||||
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
||||
elif isinstance(m, nn.BatchNorm2d):
|
||||
nn.init.constant_(m.weight, 1)
|
||||
nn.init.constant_(m.bias, 0)
|
||||
|
||||
def _make_layer(self, block, planes, blocks, stride=1):
|
||||
downsample = None
|
||||
if stride != 1 or self.inplanes != planes * block.expansion:
|
||||
downsample = nn.Sequential(
|
||||
nn.Conv2d(self.inplanes, planes * block.expansion,
|
||||
kernel_size=1, stride=stride, bias=False),
|
||||
NN.BatchNorm2d(planes * block.expansion), #NN.BatchNorm2d
|
||||
)
|
||||
|
||||
layers = []
|
||||
layers.append(block(self.inplanes, planes, stride, downsample))
|
||||
self.inplanes = planes * block.expansion
|
||||
for i in range(1, blocks):
|
||||
layers.append(block(self.inplanes, planes))
|
||||
|
||||
return nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
features = []
|
||||
|
||||
x = self.conv1(x)
|
||||
x = self.bn1(x)
|
||||
x = self.relu(x)
|
||||
x = self.maxpool(x)
|
||||
|
||||
x = self.layer1(x)
|
||||
features.append(x)
|
||||
x = self.layer2(x)
|
||||
features.append(x)
|
||||
x = self.layer3(x)
|
||||
features.append(x)
|
||||
x = self.layer4(x)
|
||||
features.append(x)
|
||||
|
||||
return features
|
||||
|
||||
|
||||
def resnet18(pretrained=True, **kwargs):
|
||||
"""Constructs a ResNet-18 model.
|
||||
Args:
|
||||
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||
"""
|
||||
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
|
||||
return model
|
||||
|
||||
|
||||
def resnet34(pretrained=True, **kwargs):
|
||||
"""Constructs a ResNet-34 model.
|
||||
Args:
|
||||
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||
"""
|
||||
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
|
||||
return model
|
||||
|
||||
|
||||
def resnet50(pretrained=True, **kwargs):
|
||||
"""Constructs a ResNet-50 model.
|
||||
Args:
|
||||
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||
"""
|
||||
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def resnet101(pretrained=True, **kwargs):
|
||||
"""Constructs a ResNet-101 model.
|
||||
Args:
|
||||
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||
"""
|
||||
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def resnet152(pretrained=True, **kwargs):
|
||||
"""Constructs a ResNet-152 model.
|
||||
Args:
|
||||
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||
"""
|
||||
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
|
||||
return model
|
||||
@@ -1,237 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# coding: utf-8
|
||||
import torch.nn as nn
|
||||
|
||||
try:
|
||||
from urllib import urlretrieve
|
||||
except ImportError:
|
||||
from urllib.request import urlretrieve
|
||||
|
||||
__all__ = ['resnext101_32x8d']
|
||||
|
||||
|
||||
model_urls = {
|
||||
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
|
||||
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
|
||||
}
|
||||
|
||||
|
||||
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
|
||||
"""3x3 convolution with padding"""
|
||||
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
|
||||
padding=dilation, groups=groups, bias=False, dilation=dilation)
|
||||
|
||||
|
||||
def conv1x1(in_planes, out_planes, stride=1):
|
||||
"""1x1 convolution"""
|
||||
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
|
||||
|
||||
|
||||
class BasicBlock(nn.Module):
|
||||
expansion = 1
|
||||
|
||||
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
|
||||
base_width=64, dilation=1, norm_layer=None):
|
||||
super(BasicBlock, self).__init__()
|
||||
if norm_layer is None:
|
||||
norm_layer = nn.BatchNorm2d
|
||||
if groups != 1 or base_width != 64:
|
||||
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
|
||||
if dilation > 1:
|
||||
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
|
||||
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
|
||||
self.conv1 = conv3x3(inplanes, planes, stride)
|
||||
self.bn1 = norm_layer(planes)
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.conv2 = conv3x3(planes, planes)
|
||||
self.bn2 = norm_layer(planes)
|
||||
self.downsample = downsample
|
||||
self.stride = stride
|
||||
|
||||
def forward(self, x):
|
||||
identity = x
|
||||
|
||||
out = self.conv1(x)
|
||||
out = self.bn1(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv2(out)
|
||||
out = self.bn2(out)
|
||||
|
||||
if self.downsample is not None:
|
||||
identity = self.downsample(x)
|
||||
|
||||
out += identity
|
||||
out = self.relu(out)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class Bottleneck(nn.Module):
|
||||
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
|
||||
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
|
||||
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
|
||||
# This variant is also known as ResNet V1.5 and improves accuracy according to
|
||||
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
|
||||
|
||||
expansion = 4
|
||||
|
||||
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
|
||||
base_width=64, dilation=1, norm_layer=None):
|
||||
super(Bottleneck, self).__init__()
|
||||
if norm_layer is None:
|
||||
norm_layer = nn.BatchNorm2d
|
||||
width = int(planes * (base_width / 64.)) * groups
|
||||
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
|
||||
self.conv1 = conv1x1(inplanes, width)
|
||||
self.bn1 = norm_layer(width)
|
||||
self.conv2 = conv3x3(width, width, stride, groups, dilation)
|
||||
self.bn2 = norm_layer(width)
|
||||
self.conv3 = conv1x1(width, planes * self.expansion)
|
||||
self.bn3 = norm_layer(planes * self.expansion)
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.downsample = downsample
|
||||
self.stride = stride
|
||||
|
||||
def forward(self, x):
|
||||
identity = x
|
||||
|
||||
out = self.conv1(x)
|
||||
out = self.bn1(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv2(out)
|
||||
out = self.bn2(out)
|
||||
out = self.relu(out)
|
||||
|
||||
out = self.conv3(out)
|
||||
out = self.bn3(out)
|
||||
|
||||
if self.downsample is not None:
|
||||
identity = self.downsample(x)
|
||||
|
||||
out += identity
|
||||
out = self.relu(out)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class ResNet(nn.Module):
|
||||
|
||||
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
|
||||
groups=1, width_per_group=64, replace_stride_with_dilation=None,
|
||||
norm_layer=None):
|
||||
super(ResNet, self).__init__()
|
||||
if norm_layer is None:
|
||||
norm_layer = nn.BatchNorm2d
|
||||
self._norm_layer = norm_layer
|
||||
|
||||
self.inplanes = 64
|
||||
self.dilation = 1
|
||||
if replace_stride_with_dilation is None:
|
||||
# each element in the tuple indicates if we should replace
|
||||
# the 2x2 stride with a dilated convolution instead
|
||||
replace_stride_with_dilation = [False, False, False]
|
||||
if len(replace_stride_with_dilation) != 3:
|
||||
raise ValueError("replace_stride_with_dilation should be None "
|
||||
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
|
||||
self.groups = groups
|
||||
self.base_width = width_per_group
|
||||
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
|
||||
bias=False)
|
||||
self.bn1 = norm_layer(self.inplanes)
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
||||
self.layer1 = self._make_layer(block, 64, layers[0])
|
||||
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
|
||||
dilate=replace_stride_with_dilation[0])
|
||||
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
|
||||
dilate=replace_stride_with_dilation[1])
|
||||
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
|
||||
dilate=replace_stride_with_dilation[2])
|
||||
#self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
|
||||
#self.fc = nn.Linear(512 * block.expansion, num_classes)
|
||||
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
||||
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
|
||||
nn.init.constant_(m.weight, 1)
|
||||
nn.init.constant_(m.bias, 0)
|
||||
|
||||
# Zero-initialize the last BN in each residual branch,
|
||||
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
|
||||
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
|
||||
if zero_init_residual:
|
||||
for m in self.modules():
|
||||
if isinstance(m, Bottleneck):
|
||||
nn.init.constant_(m.bn3.weight, 0)
|
||||
elif isinstance(m, BasicBlock):
|
||||
nn.init.constant_(m.bn2.weight, 0)
|
||||
|
||||
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
|
||||
norm_layer = self._norm_layer
|
||||
downsample = None
|
||||
previous_dilation = self.dilation
|
||||
if dilate:
|
||||
self.dilation *= stride
|
||||
stride = 1
|
||||
if stride != 1 or self.inplanes != planes * block.expansion:
|
||||
downsample = nn.Sequential(
|
||||
conv1x1(self.inplanes, planes * block.expansion, stride),
|
||||
norm_layer(planes * block.expansion),
|
||||
)
|
||||
|
||||
layers = []
|
||||
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
|
||||
self.base_width, previous_dilation, norm_layer))
|
||||
self.inplanes = planes * block.expansion
|
||||
for _ in range(1, blocks):
|
||||
layers.append(block(self.inplanes, planes, groups=self.groups,
|
||||
base_width=self.base_width, dilation=self.dilation,
|
||||
norm_layer=norm_layer))
|
||||
|
||||
return nn.Sequential(*layers)
|
||||
|
||||
def _forward_impl(self, x):
|
||||
# See note [TorchScript super()]
|
||||
features = []
|
||||
x = self.conv1(x)
|
||||
x = self.bn1(x)
|
||||
x = self.relu(x)
|
||||
x = self.maxpool(x)
|
||||
|
||||
x = self.layer1(x)
|
||||
features.append(x)
|
||||
|
||||
x = self.layer2(x)
|
||||
features.append(x)
|
||||
|
||||
x = self.layer3(x)
|
||||
features.append(x)
|
||||
|
||||
x = self.layer4(x)
|
||||
features.append(x)
|
||||
|
||||
#x = self.avgpool(x)
|
||||
#x = torch.flatten(x, 1)
|
||||
#x = self.fc(x)
|
||||
|
||||
return features
|
||||
|
||||
def forward(self, x):
|
||||
return self._forward_impl(x)
|
||||
|
||||
|
||||
|
||||
def resnext101_32x8d(pretrained=True, **kwargs):
|
||||
"""Constructs a ResNet-152 model.
|
||||
Args:
|
||||
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||
"""
|
||||
kwargs['groups'] = 32
|
||||
kwargs['width_per_group'] = 8
|
||||
|
||||
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
|
||||
return model
|
||||
|
||||
@@ -1,546 +0,0 @@
|
||||
# Author: thygate
|
||||
# https://github.com/thygate/stable-diffusion-webui-depthmap-script
|
||||
|
||||
from modules import devices
|
||||
from modules.shared import opts
|
||||
from torchvision.transforms import transforms
|
||||
from operator import getitem
|
||||
|
||||
import torch, gc
|
||||
import cv2
|
||||
import numpy as np
|
||||
import skimage.measure
|
||||
|
||||
whole_size_threshold = 1600 # R_max from the paper
|
||||
pix2pixsize = 1024
|
||||
|
||||
def scale_torch(img):
|
||||
"""
|
||||
Scale the image and output it in torch.tensor.
|
||||
:param img: input rgb is in shape [H, W, C], input depth/disp is in shape [H, W]
|
||||
:param scale: the scale factor. float
|
||||
:return: img. [C, H, W]
|
||||
"""
|
||||
if len(img.shape) == 2:
|
||||
img = img[np.newaxis, :, :]
|
||||
if img.shape[2] == 3:
|
||||
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406) , (0.229, 0.224, 0.225) )])
|
||||
img = transform(img.astype(np.float32))
|
||||
else:
|
||||
img = img.astype(np.float32)
|
||||
img = torch.from_numpy(img)
|
||||
return img
|
||||
|
||||
def estimateleres(img, model, w, h):
|
||||
# leres transform input
|
||||
rgb_c = img[:, :, ::-1].copy()
|
||||
A_resize = cv2.resize(rgb_c, (w, h))
|
||||
img_torch = scale_torch(A_resize)[None, :, :, :]
|
||||
|
||||
# compute
|
||||
with torch.no_grad():
|
||||
img_torch = img_torch.to(devices.get_device_for("controlnet"))
|
||||
prediction = model.depth_model(img_torch)
|
||||
|
||||
prediction = prediction.squeeze().cpu().numpy()
|
||||
prediction = cv2.resize(prediction, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
return prediction
|
||||
|
||||
def generatemask(size):
|
||||
# Generates a Guassian mask
|
||||
mask = np.zeros(size, dtype=np.float32)
|
||||
sigma = int(size[0]/16)
|
||||
k_size = int(2 * np.ceil(2 * int(size[0]/16)) + 1)
|
||||
mask[int(0.15*size[0]):size[0] - int(0.15*size[0]), int(0.15*size[1]): size[1] - int(0.15*size[1])] = 1
|
||||
mask = cv2.GaussianBlur(mask, (int(k_size), int(k_size)), sigma)
|
||||
mask = (mask - mask.min()) / (mask.max() - mask.min())
|
||||
mask = mask.astype(np.float32)
|
||||
return mask
|
||||
|
||||
def resizewithpool(img, size):
|
||||
i_size = img.shape[0]
|
||||
n = int(np.floor(i_size/size))
|
||||
|
||||
out = skimage.measure.block_reduce(img, (n, n), np.max)
|
||||
return out
|
||||
|
||||
def rgb2gray(rgb):
|
||||
# Converts rgb to gray
|
||||
return np.dot(rgb[..., :3], [0.2989, 0.5870, 0.1140])
|
||||
|
||||
def calculateprocessingres(img, basesize, confidence=0.1, scale_threshold=3, whole_size_threshold=3000):
|
||||
# Returns the R_x resolution described in section 5 of the main paper.
|
||||
|
||||
# Parameters:
|
||||
# img :input rgb image
|
||||
# basesize : size the dilation kernel which is equal to receptive field of the network.
|
||||
# confidence: value of x in R_x; allowed percentage of pixels that are not getting any contextual cue.
|
||||
# scale_threshold: maximum allowed upscaling on the input image ; it has been set to 3.
|
||||
# whole_size_threshold: maximum allowed resolution. (R_max from section 6 of the main paper)
|
||||
|
||||
# Returns:
|
||||
# outputsize_scale*speed_scale :The computed R_x resolution
|
||||
# patch_scale: K parameter from section 6 of the paper
|
||||
|
||||
# speed scale parameter is to process every image in a smaller size to accelerate the R_x resolution search
|
||||
speed_scale = 32
|
||||
image_dim = int(min(img.shape[0:2]))
|
||||
|
||||
gray = rgb2gray(img)
|
||||
grad = np.abs(cv2.Sobel(gray, cv2.CV_64F, 0, 1, ksize=3)) + np.abs(cv2.Sobel(gray, cv2.CV_64F, 1, 0, ksize=3))
|
||||
grad = cv2.resize(grad, (image_dim, image_dim), cv2.INTER_AREA)
|
||||
|
||||
# thresholding the gradient map to generate the edge-map as a proxy of the contextual cues
|
||||
m = grad.min()
|
||||
M = grad.max()
|
||||
middle = m + (0.4 * (M - m))
|
||||
grad[grad < middle] = 0
|
||||
grad[grad >= middle] = 1
|
||||
|
||||
# dilation kernel with size of the receptive field
|
||||
kernel = np.ones((int(basesize/speed_scale), int(basesize/speed_scale)), float)
|
||||
# dilation kernel with size of the a quarter of receptive field used to compute k
|
||||
# as described in section 6 of main paper
|
||||
kernel2 = np.ones((int(basesize / (4*speed_scale)), int(basesize / (4*speed_scale))), float)
|
||||
|
||||
# Output resolution limit set by the whole_size_threshold and scale_threshold.
|
||||
threshold = min(whole_size_threshold, scale_threshold * max(img.shape[:2]))
|
||||
|
||||
outputsize_scale = basesize / speed_scale
|
||||
for p_size in range(int(basesize/speed_scale), int(threshold/speed_scale), int(basesize / (2*speed_scale))):
|
||||
grad_resized = resizewithpool(grad, p_size)
|
||||
grad_resized = cv2.resize(grad_resized, (p_size, p_size), cv2.INTER_NEAREST)
|
||||
grad_resized[grad_resized >= 0.5] = 1
|
||||
grad_resized[grad_resized < 0.5] = 0
|
||||
|
||||
dilated = cv2.dilate(grad_resized, kernel, iterations=1)
|
||||
meanvalue = (1-dilated).mean()
|
||||
if meanvalue > confidence:
|
||||
break
|
||||
else:
|
||||
outputsize_scale = p_size
|
||||
|
||||
grad_region = cv2.dilate(grad_resized, kernel2, iterations=1)
|
||||
patch_scale = grad_region.mean()
|
||||
|
||||
return int(outputsize_scale*speed_scale), patch_scale
|
||||
|
||||
# Generate a double-input depth estimation
|
||||
def doubleestimate(img, size1, size2, pix2pixsize, model, net_type, pix2pixmodel):
|
||||
# Generate the low resolution estimation
|
||||
estimate1 = singleestimate(img, size1, model, net_type)
|
||||
# Resize to the inference size of merge network.
|
||||
estimate1 = cv2.resize(estimate1, (pix2pixsize, pix2pixsize), interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
# Generate the high resolution estimation
|
||||
estimate2 = singleestimate(img, size2, model, net_type)
|
||||
# Resize to the inference size of merge network.
|
||||
estimate2 = cv2.resize(estimate2, (pix2pixsize, pix2pixsize), interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
# Inference on the merge model
|
||||
pix2pixmodel.set_input(estimate1, estimate2)
|
||||
pix2pixmodel.test()
|
||||
visuals = pix2pixmodel.get_current_visuals()
|
||||
prediction_mapped = visuals['fake_B']
|
||||
prediction_mapped = (prediction_mapped+1)/2
|
||||
prediction_mapped = (prediction_mapped - torch.min(prediction_mapped)) / (
|
||||
torch.max(prediction_mapped) - torch.min(prediction_mapped))
|
||||
prediction_mapped = prediction_mapped.squeeze().cpu().numpy()
|
||||
|
||||
return prediction_mapped
|
||||
|
||||
# Generate a single-input depth estimation
|
||||
def singleestimate(img, msize, model, net_type):
|
||||
# if net_type == 0:
|
||||
return estimateleres(img, model, msize, msize)
|
||||
# else:
|
||||
# return estimatemidasBoost(img, model, msize, msize)
|
||||
|
||||
def applyGridpatch(blsize, stride, img, box):
|
||||
# Extract a simple grid patch.
|
||||
counter1 = 0
|
||||
patch_bound_list = {}
|
||||
for k in range(blsize, img.shape[1] - blsize, stride):
|
||||
for j in range(blsize, img.shape[0] - blsize, stride):
|
||||
patch_bound_list[str(counter1)] = {}
|
||||
patchbounds = [j - blsize, k - blsize, j - blsize + 2 * blsize, k - blsize + 2 * blsize]
|
||||
patch_bound = [box[0] + patchbounds[1], box[1] + patchbounds[0], patchbounds[3] - patchbounds[1],
|
||||
patchbounds[2] - patchbounds[0]]
|
||||
patch_bound_list[str(counter1)]['rect'] = patch_bound
|
||||
patch_bound_list[str(counter1)]['size'] = patch_bound[2]
|
||||
counter1 = counter1 + 1
|
||||
return patch_bound_list
|
||||
|
||||
# Generating local patches to perform the local refinement described in section 6 of the main paper.
|
||||
def generatepatchs(img, base_size):
|
||||
|
||||
# Compute the gradients as a proxy of the contextual cues.
|
||||
img_gray = rgb2gray(img)
|
||||
whole_grad = np.abs(cv2.Sobel(img_gray, cv2.CV_64F, 0, 1, ksize=3)) +\
|
||||
np.abs(cv2.Sobel(img_gray, cv2.CV_64F, 1, 0, ksize=3))
|
||||
|
||||
threshold = whole_grad[whole_grad > 0].mean()
|
||||
whole_grad[whole_grad < threshold] = 0
|
||||
|
||||
# We use the integral image to speed-up the evaluation of the amount of gradients for each patch.
|
||||
gf = whole_grad.sum()/len(whole_grad.reshape(-1))
|
||||
grad_integral_image = cv2.integral(whole_grad)
|
||||
|
||||
# Variables are selected such that the initial patch size would be the receptive field size
|
||||
# and the stride is set to 1/3 of the receptive field size.
|
||||
blsize = int(round(base_size/2))
|
||||
stride = int(round(blsize*0.75))
|
||||
|
||||
# Get initial Grid
|
||||
patch_bound_list = applyGridpatch(blsize, stride, img, [0, 0, 0, 0])
|
||||
|
||||
# Refine initial Grid of patches by discarding the flat (in terms of gradients of the rgb image) ones. Refine
|
||||
# each patch size to ensure that there will be enough depth cues for the network to generate a consistent depth map.
|
||||
print("Selecting patches ...")
|
||||
patch_bound_list = adaptiveselection(grad_integral_image, patch_bound_list, gf)
|
||||
|
||||
# Sort the patch list to make sure the merging operation will be done with the correct order: starting from biggest
|
||||
# patch
|
||||
patchset = sorted(patch_bound_list.items(), key=lambda x: getitem(x[1], 'size'), reverse=True)
|
||||
return patchset
|
||||
|
||||
def getGF_fromintegral(integralimage, rect):
|
||||
# Computes the gradient density of a given patch from the gradient integral image.
|
||||
x1 = rect[1]
|
||||
x2 = rect[1]+rect[3]
|
||||
y1 = rect[0]
|
||||
y2 = rect[0]+rect[2]
|
||||
value = integralimage[x2, y2]-integralimage[x1, y2]-integralimage[x2, y1]+integralimage[x1, y1]
|
||||
return value
|
||||
|
||||
# Adaptively select patches
|
||||
def adaptiveselection(integral_grad, patch_bound_list, gf):
|
||||
patchlist = {}
|
||||
count = 0
|
||||
height, width = integral_grad.shape
|
||||
|
||||
search_step = int(32/factor)
|
||||
|
||||
# Go through all patches
|
||||
for c in range(len(patch_bound_list)):
|
||||
# Get patch
|
||||
bbox = patch_bound_list[str(c)]['rect']
|
||||
|
||||
# Compute the amount of gradients present in the patch from the integral image.
|
||||
cgf = getGF_fromintegral(integral_grad, bbox)/(bbox[2]*bbox[3])
|
||||
|
||||
# Check if patching is beneficial by comparing the gradient density of the patch to
|
||||
# the gradient density of the whole image
|
||||
if cgf >= gf:
|
||||
bbox_test = bbox.copy()
|
||||
patchlist[str(count)] = {}
|
||||
|
||||
# Enlarge each patch until the gradient density of the patch is equal
|
||||
# to the whole image gradient density
|
||||
while True:
|
||||
|
||||
bbox_test[0] = bbox_test[0] - int(search_step/2)
|
||||
bbox_test[1] = bbox_test[1] - int(search_step/2)
|
||||
|
||||
bbox_test[2] = bbox_test[2] + search_step
|
||||
bbox_test[3] = bbox_test[3] + search_step
|
||||
|
||||
# Check if we are still within the image
|
||||
if bbox_test[0] < 0 or bbox_test[1] < 0 or bbox_test[1] + bbox_test[3] >= height \
|
||||
or bbox_test[0] + bbox_test[2] >= width:
|
||||
break
|
||||
|
||||
# Compare gradient density
|
||||
cgf = getGF_fromintegral(integral_grad, bbox_test)/(bbox_test[2]*bbox_test[3])
|
||||
if cgf < gf:
|
||||
break
|
||||
bbox = bbox_test.copy()
|
||||
|
||||
# Add patch to selected patches
|
||||
patchlist[str(count)]['rect'] = bbox
|
||||
patchlist[str(count)]['size'] = bbox[2]
|
||||
count = count + 1
|
||||
|
||||
# Return selected patches
|
||||
return patchlist
|
||||
|
||||
def impatch(image, rect):
|
||||
# Extract the given patch pixels from a given image.
|
||||
w1 = rect[0]
|
||||
h1 = rect[1]
|
||||
w2 = w1 + rect[2]
|
||||
h2 = h1 + rect[3]
|
||||
image_patch = image[h1:h2, w1:w2]
|
||||
return image_patch
|
||||
|
||||
class ImageandPatchs:
|
||||
def __init__(self, root_dir, name, patchsinfo, rgb_image, scale=1):
|
||||
self.root_dir = root_dir
|
||||
self.patchsinfo = patchsinfo
|
||||
self.name = name
|
||||
self.patchs = patchsinfo
|
||||
self.scale = scale
|
||||
|
||||
self.rgb_image = cv2.resize(rgb_image, (round(rgb_image.shape[1]*scale), round(rgb_image.shape[0]*scale)),
|
||||
interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
self.do_have_estimate = False
|
||||
self.estimation_updated_image = None
|
||||
self.estimation_base_image = None
|
||||
|
||||
def __len__(self):
|
||||
return len(self.patchs)
|
||||
|
||||
def set_base_estimate(self, est):
|
||||
self.estimation_base_image = est
|
||||
if self.estimation_updated_image is not None:
|
||||
self.do_have_estimate = True
|
||||
|
||||
def set_updated_estimate(self, est):
|
||||
self.estimation_updated_image = est
|
||||
if self.estimation_base_image is not None:
|
||||
self.do_have_estimate = True
|
||||
|
||||
def __getitem__(self, index):
|
||||
patch_id = int(self.patchs[index][0])
|
||||
rect = np.array(self.patchs[index][1]['rect'])
|
||||
msize = self.patchs[index][1]['size']
|
||||
|
||||
## applying scale to rect:
|
||||
rect = np.round(rect * self.scale)
|
||||
rect = rect.astype('int')
|
||||
msize = round(msize * self.scale)
|
||||
|
||||
patch_rgb = impatch(self.rgb_image, rect)
|
||||
if self.do_have_estimate:
|
||||
patch_whole_estimate_base = impatch(self.estimation_base_image, rect)
|
||||
patch_whole_estimate_updated = impatch(self.estimation_updated_image, rect)
|
||||
return {'patch_rgb': patch_rgb, 'patch_whole_estimate_base': patch_whole_estimate_base,
|
||||
'patch_whole_estimate_updated': patch_whole_estimate_updated, 'rect': rect,
|
||||
'size': msize, 'id': patch_id}
|
||||
else:
|
||||
return {'patch_rgb': patch_rgb, 'rect': rect, 'size': msize, 'id': patch_id}
|
||||
|
||||
def print_options(self, opt):
|
||||
"""Print and save options
|
||||
|
||||
It will print both current options and default values(if different).
|
||||
It will save options into a text file / [checkpoints_dir] / opt.txt
|
||||
"""
|
||||
message = ''
|
||||
message += '----------------- Options ---------------\n'
|
||||
for k, v in sorted(vars(opt).items()):
|
||||
comment = ''
|
||||
default = self.parser.get_default(k)
|
||||
if v != default:
|
||||
comment = '\t[default: %s]' % str(default)
|
||||
message += '{:>25}: {:<30}{}\n'.format(str(k), str(v), comment)
|
||||
message += '----------------- End -------------------'
|
||||
print(message)
|
||||
|
||||
# save to the disk
|
||||
"""
|
||||
expr_dir = os.path.join(opt.checkpoints_dir, opt.name)
|
||||
util.mkdirs(expr_dir)
|
||||
file_name = os.path.join(expr_dir, '{}_opt.txt'.format(opt.phase))
|
||||
with open(file_name, 'wt') as opt_file:
|
||||
opt_file.write(message)
|
||||
opt_file.write('\n')
|
||||
"""
|
||||
|
||||
def parse(self):
|
||||
"""Parse our options, create checkpoints directory suffix, and set up gpu device."""
|
||||
opt = self.gather_options()
|
||||
opt.isTrain = self.isTrain # train or test
|
||||
|
||||
# process opt.suffix
|
||||
if opt.suffix:
|
||||
suffix = ('_' + opt.suffix.format(**vars(opt))) if opt.suffix != '' else ''
|
||||
opt.name = opt.name + suffix
|
||||
|
||||
#self.print_options(opt)
|
||||
|
||||
# set gpu ids
|
||||
str_ids = opt.gpu_ids.split(',')
|
||||
opt.gpu_ids = []
|
||||
for str_id in str_ids:
|
||||
id = int(str_id)
|
||||
if id >= 0:
|
||||
opt.gpu_ids.append(id)
|
||||
#if len(opt.gpu_ids) > 0:
|
||||
# torch.cuda.set_device(opt.gpu_ids[0])
|
||||
|
||||
self.opt = opt
|
||||
return self.opt
|
||||
|
||||
|
||||
def estimateboost(img, model, model_type, pix2pixmodel, max_res=512):
|
||||
global whole_size_threshold
|
||||
|
||||
# get settings
|
||||
if hasattr(opts, 'depthmap_script_boost_rmax'):
|
||||
whole_size_threshold = opts.depthmap_script_boost_rmax
|
||||
|
||||
if model_type == 0: #leres
|
||||
net_receptive_field_size = 448
|
||||
patch_netsize = 2 * net_receptive_field_size
|
||||
elif model_type == 1: #dpt_beit_large_512
|
||||
net_receptive_field_size = 512
|
||||
patch_netsize = 2 * net_receptive_field_size
|
||||
else: #other midas
|
||||
net_receptive_field_size = 384
|
||||
patch_netsize = 2 * net_receptive_field_size
|
||||
|
||||
gc.collect()
|
||||
devices.torch_gc()
|
||||
|
||||
# Generate mask used to smoothly blend the local pathc estimations to the base estimate.
|
||||
# It is arbitrarily large to avoid artifacts during rescaling for each crop.
|
||||
mask_org = generatemask((3000, 3000))
|
||||
mask = mask_org.copy()
|
||||
|
||||
# Value x of R_x defined in the section 5 of the main paper.
|
||||
r_threshold_value = 0.2
|
||||
#if R0:
|
||||
# r_threshold_value = 0
|
||||
|
||||
input_resolution = img.shape
|
||||
scale_threshold = 3 # Allows up-scaling with a scale up to 3
|
||||
|
||||
# Find the best input resolution R-x. The resolution search described in section 5-double estimation of the main paper and section B of the
|
||||
# supplementary material.
|
||||
whole_image_optimal_size, patch_scale = calculateprocessingres(img, net_receptive_field_size, r_threshold_value, scale_threshold, whole_size_threshold)
|
||||
|
||||
# print('wholeImage being processed in :', whole_image_optimal_size)
|
||||
|
||||
# Generate the base estimate using the double estimation.
|
||||
whole_estimate = doubleestimate(img, net_receptive_field_size, whole_image_optimal_size, pix2pixsize, model, model_type, pix2pixmodel)
|
||||
|
||||
# Compute the multiplier described in section 6 of the main paper to make sure our initial patch can select
|
||||
# small high-density regions of the image.
|
||||
global factor
|
||||
factor = max(min(1, 4 * patch_scale * whole_image_optimal_size / whole_size_threshold), 0.2)
|
||||
# print('Adjust factor is:', 1/factor)
|
||||
|
||||
# Check if Local boosting is beneficial.
|
||||
if max_res < whole_image_optimal_size:
|
||||
# print("No Local boosting. Specified Max Res is smaller than R20, Returning doubleestimate result")
|
||||
return cv2.resize(whole_estimate, (input_resolution[1], input_resolution[0]), interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
# Compute the default target resolution.
|
||||
if img.shape[0] > img.shape[1]:
|
||||
a = 2 * whole_image_optimal_size
|
||||
b = round(2 * whole_image_optimal_size * img.shape[1] / img.shape[0])
|
||||
else:
|
||||
a = round(2 * whole_image_optimal_size * img.shape[0] / img.shape[1])
|
||||
b = 2 * whole_image_optimal_size
|
||||
b = int(round(b / factor))
|
||||
a = int(round(a / factor))
|
||||
|
||||
"""
|
||||
# recompute a, b and saturate to max res.
|
||||
if max(a,b) > max_res:
|
||||
print('Default Res is higher than max-res: Reducing final resolution')
|
||||
if img.shape[0] > img.shape[1]:
|
||||
a = max_res
|
||||
b = round(max_res * img.shape[1] / img.shape[0])
|
||||
else:
|
||||
a = round(max_res * img.shape[0] / img.shape[1])
|
||||
b = max_res
|
||||
b = int(b)
|
||||
a = int(a)
|
||||
"""
|
||||
|
||||
img = cv2.resize(img, (b, a), interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
# Extract selected patches for local refinement
|
||||
base_size = net_receptive_field_size * 2
|
||||
patchset = generatepatchs(img, base_size)
|
||||
|
||||
# print('Target resolution: ', img.shape)
|
||||
|
||||
# Computing a scale in case user prompted to generate the results as the same resolution of the input.
|
||||
# Notice that our method output resolution is independent of the input resolution and this parameter will only
|
||||
# enable a scaling operation during the local patch merge implementation to generate results with the same resolution
|
||||
# as the input.
|
||||
"""
|
||||
if output_resolution == 1:
|
||||
mergein_scale = input_resolution[0] / img.shape[0]
|
||||
print('Dynamicly change merged-in resolution; scale:', mergein_scale)
|
||||
else:
|
||||
mergein_scale = 1
|
||||
"""
|
||||
# always rescale to input res for now
|
||||
mergein_scale = input_resolution[0] / img.shape[0]
|
||||
|
||||
imageandpatchs = ImageandPatchs('', '', patchset, img, mergein_scale)
|
||||
whole_estimate_resized = cv2.resize(whole_estimate, (round(img.shape[1]*mergein_scale),
|
||||
round(img.shape[0]*mergein_scale)), interpolation=cv2.INTER_CUBIC)
|
||||
imageandpatchs.set_base_estimate(whole_estimate_resized.copy())
|
||||
imageandpatchs.set_updated_estimate(whole_estimate_resized.copy())
|
||||
|
||||
print('Resulting depthmap resolution will be :', whole_estimate_resized.shape[:2])
|
||||
print('Patches to process: '+str(len(imageandpatchs)))
|
||||
|
||||
# Enumerate through all patches, generate their estimations and refining the base estimate.
|
||||
for patch_ind in range(len(imageandpatchs)):
|
||||
|
||||
# Get patch information
|
||||
patch = imageandpatchs[patch_ind] # patch object
|
||||
patch_rgb = patch['patch_rgb'] # rgb patch
|
||||
patch_whole_estimate_base = patch['patch_whole_estimate_base'] # corresponding patch from base
|
||||
rect = patch['rect'] # patch size and location
|
||||
patch_id = patch['id'] # patch ID
|
||||
org_size = patch_whole_estimate_base.shape # the original size from the unscaled input
|
||||
print('\t Processing patch', patch_ind, '/', len(imageandpatchs)-1, '|', rect)
|
||||
|
||||
# We apply double estimation for patches. The high resolution value is fixed to twice the receptive
|
||||
# field size of the network for patches to accelerate the process.
|
||||
patch_estimation = doubleestimate(patch_rgb, net_receptive_field_size, patch_netsize, pix2pixsize, model, model_type, pix2pixmodel)
|
||||
patch_estimation = cv2.resize(patch_estimation, (pix2pixsize, pix2pixsize), interpolation=cv2.INTER_CUBIC)
|
||||
patch_whole_estimate_base = cv2.resize(patch_whole_estimate_base, (pix2pixsize, pix2pixsize), interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
# Merging the patch estimation into the base estimate using our merge network:
|
||||
# We feed the patch estimation and the same region from the updated base estimate to the merge network
|
||||
# to generate the target estimate for the corresponding region.
|
||||
pix2pixmodel.set_input(patch_whole_estimate_base, patch_estimation)
|
||||
|
||||
# Run merging network
|
||||
pix2pixmodel.test()
|
||||
visuals = pix2pixmodel.get_current_visuals()
|
||||
|
||||
prediction_mapped = visuals['fake_B']
|
||||
prediction_mapped = (prediction_mapped+1)/2
|
||||
prediction_mapped = prediction_mapped.squeeze().cpu().numpy()
|
||||
|
||||
mapped = prediction_mapped
|
||||
|
||||
# We use a simple linear polynomial to make sure the result of the merge network would match the values of
|
||||
# base estimate
|
||||
p_coef = np.polyfit(mapped.reshape(-1), patch_whole_estimate_base.reshape(-1), deg=1)
|
||||
merged = np.polyval(p_coef, mapped.reshape(-1)).reshape(mapped.shape)
|
||||
|
||||
merged = cv2.resize(merged, (org_size[1],org_size[0]), interpolation=cv2.INTER_CUBIC)
|
||||
|
||||
# Get patch size and location
|
||||
w1 = rect[0]
|
||||
h1 = rect[1]
|
||||
w2 = w1 + rect[2]
|
||||
h2 = h1 + rect[3]
|
||||
|
||||
# To speed up the implementation, we only generate the Gaussian mask once with a sufficiently large size
|
||||
# and resize it to our needed size while merging the patches.
|
||||
if mask.shape != org_size:
|
||||
mask = cv2.resize(mask_org, (org_size[1],org_size[0]), interpolation=cv2.INTER_LINEAR)
|
||||
|
||||
tobemergedto = imageandpatchs.estimation_updated_image
|
||||
|
||||
# Update the whole estimation:
|
||||
# We use a simple Gaussian mask to blend the merged patch region with the base estimate to ensure seamless
|
||||
# blending at the boundaries of the patch region.
|
||||
tobemergedto[h1:h2, w1:w2] = np.multiply(tobemergedto[h1:h2, w1:w2], 1 - mask) + np.multiply(merged, mask)
|
||||
imageandpatchs.set_updated_estimate(tobemergedto)
|
||||
|
||||
# output
|
||||
return cv2.resize(imageandpatchs.estimation_updated_image, (input_resolution[1], input_resolution[0]), interpolation=cv2.INTER_CUBIC)
|
||||
@@ -1,34 +0,0 @@
|
||||
from . import network_auxi as network
|
||||
from .net_tools import get_func
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from modules import devices
|
||||
|
||||
class RelDepthModel(nn.Module):
|
||||
def __init__(self, backbone='resnet50'):
|
||||
super(RelDepthModel, self).__init__()
|
||||
if backbone == 'resnet50':
|
||||
encoder = 'resnet50_stride32'
|
||||
elif backbone == 'resnext101':
|
||||
encoder = 'resnext101_stride32x8d'
|
||||
self.depth_model = DepthModel(encoder)
|
||||
|
||||
def inference(self, rgb):
|
||||
with torch.no_grad():
|
||||
input = rgb.to(self.depth_model.device)
|
||||
depth = self.depth_model(input)
|
||||
#pred_depth_out = depth - depth.min() + 0.01
|
||||
return depth #pred_depth_out
|
||||
|
||||
|
||||
class DepthModel(nn.Module):
|
||||
def __init__(self, encoder):
|
||||
super(DepthModel, self).__init__()
|
||||
backbone = network.__name__.split('.')[-1] + '.' + encoder
|
||||
self.encoder_modules = get_func(backbone)()
|
||||
self.decoder_modules = network.Decoder()
|
||||
|
||||
def forward(self, x):
|
||||
lateral_out = self.encoder_modules(x)
|
||||
out_logit = self.decoder_modules(lateral_out)
|
||||
return out_logit
|
||||
@@ -1,54 +0,0 @@
|
||||
import importlib
|
||||
import torch
|
||||
import os
|
||||
from collections import OrderedDict
|
||||
|
||||
|
||||
def get_func(func_name):
|
||||
"""Helper to return a function object by name. func_name must identify a
|
||||
function in this module or the path to a function relative to the base
|
||||
'modeling' module.
|
||||
"""
|
||||
if func_name == '':
|
||||
return None
|
||||
try:
|
||||
parts = func_name.split('.')
|
||||
# Refers to a function in this module
|
||||
if len(parts) == 1:
|
||||
return globals()[parts[0]]
|
||||
# Otherwise, assume we're referencing a module under modeling
|
||||
module_name = 'annotator.leres.leres.' + '.'.join(parts[:-1])
|
||||
module = importlib.import_module(module_name)
|
||||
return getattr(module, parts[-1])
|
||||
except Exception:
|
||||
print('Failed to f1ind function: %s', func_name)
|
||||
raise
|
||||
|
||||
def load_ckpt(args, depth_model, shift_model, focal_model):
|
||||
"""
|
||||
Load checkpoint.
|
||||
"""
|
||||
if os.path.isfile(args.load_ckpt):
|
||||
print("loading checkpoint %s" % args.load_ckpt)
|
||||
checkpoint = torch.load(args.load_ckpt)
|
||||
if shift_model is not None:
|
||||
shift_model.load_state_dict(strip_prefix_if_present(checkpoint['shift_model'], 'module.'),
|
||||
strict=True)
|
||||
if focal_model is not None:
|
||||
focal_model.load_state_dict(strip_prefix_if_present(checkpoint['focal_model'], 'module.'),
|
||||
strict=True)
|
||||
depth_model.load_state_dict(strip_prefix_if_present(checkpoint['depth_model'], "module."),
|
||||
strict=True)
|
||||
del checkpoint
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
def strip_prefix_if_present(state_dict, prefix):
|
||||
keys = sorted(state_dict.keys())
|
||||
if not all(key.startswith(prefix) for key in keys):
|
||||
return state_dict
|
||||
stripped_state_dict = OrderedDict()
|
||||
for key, value in state_dict.items():
|
||||
stripped_state_dict[key.replace(prefix, "")] = value
|
||||
return stripped_state_dict
|
||||
@@ -1,417 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.init as init
|
||||
|
||||
from . import Resnet, Resnext_torch
|
||||
|
||||
|
||||
def resnet50_stride32():
|
||||
return DepthNet(backbone='resnet', depth=50, upfactors=[2, 2, 2, 2])
|
||||
|
||||
def resnext101_stride32x8d():
|
||||
return DepthNet(backbone='resnext101_32x8d', depth=101, upfactors=[2, 2, 2, 2])
|
||||
|
||||
|
||||
class Decoder(nn.Module):
|
||||
def __init__(self):
|
||||
super(Decoder, self).__init__()
|
||||
self.inchannels = [256, 512, 1024, 2048]
|
||||
self.midchannels = [256, 256, 256, 512]
|
||||
self.upfactors = [2,2,2,2]
|
||||
self.outchannels = 1
|
||||
|
||||
self.conv = FTB(inchannels=self.inchannels[3], midchannels=self.midchannels[3])
|
||||
self.conv1 = nn.Conv2d(in_channels=self.midchannels[3], out_channels=self.midchannels[2], kernel_size=3, padding=1, stride=1, bias=True)
|
||||
self.upsample = nn.Upsample(scale_factor=self.upfactors[3], mode='bilinear', align_corners=True)
|
||||
|
||||
self.ffm2 = FFM(inchannels=self.inchannels[2], midchannels=self.midchannels[2], outchannels = self.midchannels[2], upfactor=self.upfactors[2])
|
||||
self.ffm1 = FFM(inchannels=self.inchannels[1], midchannels=self.midchannels[1], outchannels = self.midchannels[1], upfactor=self.upfactors[1])
|
||||
self.ffm0 = FFM(inchannels=self.inchannels[0], midchannels=self.midchannels[0], outchannels = self.midchannels[0], upfactor=self.upfactors[0])
|
||||
|
||||
self.outconv = AO(inchannels=self.midchannels[0], outchannels=self.outchannels, upfactor=2)
|
||||
self._init_params()
|
||||
|
||||
def _init_params(self):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d): #NN.BatchNorm2d
|
||||
init.constant_(m.weight, 1)
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
|
||||
def forward(self, features):
|
||||
x_32x = self.conv(features[3]) # 1/32
|
||||
x_32 = self.conv1(x_32x)
|
||||
x_16 = self.upsample(x_32) # 1/16
|
||||
|
||||
x_8 = self.ffm2(features[2], x_16) # 1/8
|
||||
x_4 = self.ffm1(features[1], x_8) # 1/4
|
||||
x_2 = self.ffm0(features[0], x_4) # 1/2
|
||||
#-----------------------------------------
|
||||
x = self.outconv(x_2) # original size
|
||||
return x
|
||||
|
||||
class DepthNet(nn.Module):
|
||||
__factory = {
|
||||
18: Resnet.resnet18,
|
||||
34: Resnet.resnet34,
|
||||
50: Resnet.resnet50,
|
||||
101: Resnet.resnet101,
|
||||
152: Resnet.resnet152
|
||||
}
|
||||
def __init__(self,
|
||||
backbone='resnet',
|
||||
depth=50,
|
||||
upfactors=[2, 2, 2, 2]):
|
||||
super(DepthNet, self).__init__()
|
||||
self.backbone = backbone
|
||||
self.depth = depth
|
||||
self.pretrained = False
|
||||
self.inchannels = [256, 512, 1024, 2048]
|
||||
self.midchannels = [256, 256, 256, 512]
|
||||
self.upfactors = upfactors
|
||||
self.outchannels = 1
|
||||
|
||||
# Build model
|
||||
if self.backbone == 'resnet':
|
||||
if self.depth not in DepthNet.__factory:
|
||||
raise KeyError("Unsupported depth:", self.depth)
|
||||
self.encoder = DepthNet.__factory[depth](pretrained=self.pretrained)
|
||||
elif self.backbone == 'resnext101_32x8d':
|
||||
self.encoder = Resnext_torch.resnext101_32x8d(pretrained=self.pretrained)
|
||||
else:
|
||||
self.encoder = Resnext_torch.resnext101(pretrained=self.pretrained)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.encoder(x) # 1/32, 1/16, 1/8, 1/4
|
||||
return x
|
||||
|
||||
|
||||
class FTB(nn.Module):
|
||||
def __init__(self, inchannels, midchannels=512):
|
||||
super(FTB, self).__init__()
|
||||
self.in1 = inchannels
|
||||
self.mid = midchannels
|
||||
self.conv1 = nn.Conv2d(in_channels=self.in1, out_channels=self.mid, kernel_size=3, padding=1, stride=1,
|
||||
bias=True)
|
||||
# NN.BatchNorm2d
|
||||
self.conv_branch = nn.Sequential(nn.ReLU(inplace=True), \
|
||||
nn.Conv2d(in_channels=self.mid, out_channels=self.mid, kernel_size=3,
|
||||
padding=1, stride=1, bias=True), \
|
||||
nn.BatchNorm2d(num_features=self.mid), \
|
||||
nn.ReLU(inplace=True), \
|
||||
nn.Conv2d(in_channels=self.mid, out_channels=self.mid, kernel_size=3,
|
||||
padding=1, stride=1, bias=True))
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
|
||||
self.init_params()
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv1(x)
|
||||
x = x + self.conv_branch(x)
|
||||
x = self.relu(x)
|
||||
|
||||
return x
|
||||
|
||||
def init_params(self):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d): # NN.BatchNorm2d
|
||||
init.constant_(m.weight, 1)
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
|
||||
|
||||
class ATA(nn.Module):
|
||||
def __init__(self, inchannels, reduction=8):
|
||||
super(ATA, self).__init__()
|
||||
self.inchannels = inchannels
|
||||
self.avg_pool = nn.AdaptiveAvgPool2d(1)
|
||||
self.fc = nn.Sequential(nn.Linear(self.inchannels * 2, self.inchannels // reduction),
|
||||
nn.ReLU(inplace=True),
|
||||
nn.Linear(self.inchannels // reduction, self.inchannels),
|
||||
nn.Sigmoid())
|
||||
self.init_params()
|
||||
|
||||
def forward(self, low_x, high_x):
|
||||
n, c, _, _ = low_x.size()
|
||||
x = torch.cat([low_x, high_x], 1)
|
||||
x = self.avg_pool(x)
|
||||
x = x.view(n, -1)
|
||||
x = self.fc(x).view(n, c, 1, 1)
|
||||
x = low_x * x + high_x
|
||||
|
||||
return x
|
||||
|
||||
def init_params(self):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
# init.normal(m.weight, std=0.01)
|
||||
init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
# init.normal_(m.weight, std=0.01)
|
||||
init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d): # NN.BatchNorm2d
|
||||
init.constant_(m.weight, 1)
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
|
||||
|
||||
class FFM(nn.Module):
|
||||
def __init__(self, inchannels, midchannels, outchannels, upfactor=2):
|
||||
super(FFM, self).__init__()
|
||||
self.inchannels = inchannels
|
||||
self.midchannels = midchannels
|
||||
self.outchannels = outchannels
|
||||
self.upfactor = upfactor
|
||||
|
||||
self.ftb1 = FTB(inchannels=self.inchannels, midchannels=self.midchannels)
|
||||
# self.ata = ATA(inchannels = self.midchannels)
|
||||
self.ftb2 = FTB(inchannels=self.midchannels, midchannels=self.outchannels)
|
||||
|
||||
self.upsample = nn.Upsample(scale_factor=self.upfactor, mode='bilinear', align_corners=True)
|
||||
|
||||
self.init_params()
|
||||
|
||||
def forward(self, low_x, high_x):
|
||||
x = self.ftb1(low_x)
|
||||
x = x + high_x
|
||||
x = self.ftb2(x)
|
||||
x = self.upsample(x)
|
||||
|
||||
return x
|
||||
|
||||
def init_params(self):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d): # NN.Batchnorm2d
|
||||
init.constant_(m.weight, 1)
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
|
||||
|
||||
class AO(nn.Module):
|
||||
# Adaptive output module
|
||||
def __init__(self, inchannels, outchannels, upfactor=2):
|
||||
super(AO, self).__init__()
|
||||
self.inchannels = inchannels
|
||||
self.outchannels = outchannels
|
||||
self.upfactor = upfactor
|
||||
|
||||
self.adapt_conv = nn.Sequential(
|
||||
nn.Conv2d(in_channels=self.inchannels, out_channels=self.inchannels // 2, kernel_size=3, padding=1,
|
||||
stride=1, bias=True), \
|
||||
nn.BatchNorm2d(num_features=self.inchannels // 2), \
|
||||
nn.ReLU(inplace=True), \
|
||||
nn.Conv2d(in_channels=self.inchannels // 2, out_channels=self.outchannels, kernel_size=3, padding=1,
|
||||
stride=1, bias=True), \
|
||||
nn.Upsample(scale_factor=self.upfactor, mode='bilinear', align_corners=True))
|
||||
|
||||
self.init_params()
|
||||
|
||||
def forward(self, x):
|
||||
x = self.adapt_conv(x)
|
||||
return x
|
||||
|
||||
def init_params(self):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d): # NN.Batchnorm2d
|
||||
init.constant_(m.weight, 1)
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
|
||||
|
||||
|
||||
# ==============================================================================================================
|
||||
|
||||
|
||||
class ResidualConv(nn.Module):
|
||||
def __init__(self, inchannels):
|
||||
super(ResidualConv, self).__init__()
|
||||
# NN.BatchNorm2d
|
||||
self.conv = nn.Sequential(
|
||||
# nn.BatchNorm2d(num_features=inchannels),
|
||||
nn.ReLU(inplace=False),
|
||||
# nn.Conv2d(in_channels=inchannels, out_channels=inchannels, kernel_size=3, padding=1, stride=1, groups=inchannels,bias=True),
|
||||
# nn.Conv2d(in_channels=inchannels, out_channels=inchannels, kernel_size=1, padding=0, stride=1, groups=1,bias=True)
|
||||
nn.Conv2d(in_channels=inchannels, out_channels=inchannels / 2, kernel_size=3, padding=1, stride=1,
|
||||
bias=False),
|
||||
nn.BatchNorm2d(num_features=inchannels / 2),
|
||||
nn.ReLU(inplace=False),
|
||||
nn.Conv2d(in_channels=inchannels / 2, out_channels=inchannels, kernel_size=3, padding=1, stride=1,
|
||||
bias=False)
|
||||
)
|
||||
self.init_params()
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv(x) + x
|
||||
return x
|
||||
|
||||
def init_params(self):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d): # NN.BatchNorm2d
|
||||
init.constant_(m.weight, 1)
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
|
||||
|
||||
class FeatureFusion(nn.Module):
|
||||
def __init__(self, inchannels, outchannels):
|
||||
super(FeatureFusion, self).__init__()
|
||||
self.conv = ResidualConv(inchannels=inchannels)
|
||||
# NN.BatchNorm2d
|
||||
self.up = nn.Sequential(ResidualConv(inchannels=inchannels),
|
||||
nn.ConvTranspose2d(in_channels=inchannels, out_channels=outchannels, kernel_size=3,
|
||||
stride=2, padding=1, output_padding=1),
|
||||
nn.BatchNorm2d(num_features=outchannels),
|
||||
nn.ReLU(inplace=True))
|
||||
|
||||
def forward(self, lowfeat, highfeat):
|
||||
return self.up(highfeat + self.conv(lowfeat))
|
||||
|
||||
def init_params(self):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
# init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
init.normal_(m.weight, std=0.01)
|
||||
# init.xavier_normal_(m.weight)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d): # NN.BatchNorm2d
|
||||
init.constant_(m.weight, 1)
|
||||
init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
init.normal_(m.weight, std=0.01)
|
||||
if m.bias is not None:
|
||||
init.constant_(m.bias, 0)
|
||||
|
||||
|
||||
class SenceUnderstand(nn.Module):
|
||||
def __init__(self, channels):
|
||||
super(SenceUnderstand, self).__init__()
|
||||
self.channels = channels
|
||||
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
|
||||
nn.ReLU(inplace=True))
|
||||
self.pool = nn.AdaptiveAvgPool2d(8)
|
||||
self.fc = nn.Sequential(nn.Linear(512 * 8 * 8, self.channels),
|
||||
nn.ReLU(inplace=True))
|
||||
self.conv2 = nn.Sequential(
|
||||
nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=1, padding=0),
|
||||
nn.ReLU(inplace=True))
|
||||
self.initial_params()
|
||||
|
||||
def forward(self, x):
|
||||
n, c, h, w = x.size()
|
||||
x = self.conv1(x)
|
||||
x = self.pool(x)
|
||||
x = x.view(n, -1)
|
||||
x = self.fc(x)
|
||||
x = x.view(n, self.channels, 1, 1)
|
||||
x = self.conv2(x)
|
||||
x = x.repeat(1, 1, h, w)
|
||||
return x
|
||||
|
||||
def initial_params(self, dev=0.01):
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
# print torch.sum(m.weight)
|
||||
m.weight.data.normal_(0, dev)
|
||||
if m.bias is not None:
|
||||
m.bias.data.fill_(0)
|
||||
elif isinstance(m, nn.ConvTranspose2d):
|
||||
# print torch.sum(m.weight)
|
||||
m.weight.data.normal_(0, dev)
|
||||
if m.bias is not None:
|
||||
m.bias.data.fill_(0)
|
||||
elif isinstance(m, nn.Linear):
|
||||
m.weight.data.normal_(0, dev)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
net = DepthNet(depth=50, pretrained=True)
|
||||
print(net)
|
||||
inputs = torch.ones(4,3,128,128)
|
||||
out = net(inputs)
|
||||
print(out.size())
|
||||
|
||||
@@ -1,19 +0,0 @@
|
||||
https://github.com/compphoto/BoostingMonocularDepth
|
||||
|
||||
Copyright 2021, Seyed Mahdi Hosseini Miangoleh, Sebastian Dille, Computational Photography Laboratory. All rights reserved.
|
||||
|
||||
This software is for academic use only. A redistribution of this
|
||||
software, with or without modifications, has to be for academic
|
||||
use only, while giving the appropriate credit to the original
|
||||
authors of the software. The methods implemented as a part of
|
||||
this software may be covered under patents or patent applications.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE AUTHOR ''AS IS'' AND ANY EXPRESS OR IMPLIED
|
||||
WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND
|
||||
FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR
|
||||
CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
|
||||
CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
||||
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
|
||||
ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
|
||||
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF
|
||||
ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
@@ -1,67 +0,0 @@
|
||||
"""This package contains modules related to objective functions, optimizations, and network architectures.
|
||||
|
||||
To add a custom model class called 'dummy', you need to add a file called 'dummy_model.py' and define a subclass DummyModel inherited from BaseModel.
|
||||
You need to implement the following five functions:
|
||||
-- <__init__>: initialize the class; first call BaseModel.__init__(self, opt).
|
||||
-- <set_input>: unpack data from dataset and apply preprocessing.
|
||||
-- <forward>: produce intermediate results.
|
||||
-- <optimize_parameters>: calculate loss, gradients, and update network weights.
|
||||
-- <modify_commandline_options>: (optionally) add model-specific options and set default options.
|
||||
|
||||
In the function <__init__>, you need to define four lists:
|
||||
-- self.loss_names (str list): specify the training losses that you want to plot and save.
|
||||
-- self.model_names (str list): define networks used in our training.
|
||||
-- self.visual_names (str list): specify the images that you want to display and save.
|
||||
-- self.optimizers (optimizer list): define and initialize optimizers. You can define one optimizer for each network. If two networks are updated at the same time, you can use itertools.chain to group them. See cycle_gan_model.py for an usage.
|
||||
|
||||
Now you can use the model class by specifying flag '--model dummy'.
|
||||
See our template model class 'template_model.py' for more details.
|
||||
"""
|
||||
|
||||
import importlib
|
||||
from .base_model import BaseModel
|
||||
|
||||
|
||||
def find_model_using_name(model_name):
|
||||
"""Import the module "models/[model_name]_model.py".
|
||||
|
||||
In the file, the class called DatasetNameModel() will
|
||||
be instantiated. It has to be a subclass of BaseModel,
|
||||
and it is case-insensitive.
|
||||
"""
|
||||
model_filename = "annotator.leres.pix2pix.models." + model_name + "_model"
|
||||
modellib = importlib.import_module(model_filename)
|
||||
model = None
|
||||
target_model_name = model_name.replace('_', '') + 'model'
|
||||
for name, cls in modellib.__dict__.items():
|
||||
if name.lower() == target_model_name.lower() \
|
||||
and issubclass(cls, BaseModel):
|
||||
model = cls
|
||||
|
||||
if model is None:
|
||||
print("In %s.py, there should be a subclass of BaseModel with class name that matches %s in lowercase." % (model_filename, target_model_name))
|
||||
exit(0)
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def get_option_setter(model_name):
|
||||
"""Return the static method <modify_commandline_options> of the model class."""
|
||||
model_class = find_model_using_name(model_name)
|
||||
return model_class.modify_commandline_options
|
||||
|
||||
|
||||
def create_model(opt):
|
||||
"""Create a model given the option.
|
||||
|
||||
This function warps the class CustomDatasetDataLoader.
|
||||
This is the main interface between this package and 'train.py'/'test.py'
|
||||
|
||||
Example:
|
||||
>>> from models import create_model
|
||||
>>> model = create_model(opt)
|
||||
"""
|
||||
model = find_model_using_name(opt.model)
|
||||
instance = model(opt)
|
||||
print("model [%s] was created" % type(instance).__name__)
|
||||
return instance
|
||||
@@ -1,241 +0,0 @@
|
||||
import os
|
||||
import torch, gc
|
||||
from modules import devices
|
||||
from collections import OrderedDict
|
||||
from abc import ABC, abstractmethod
|
||||
from . import networks
|
||||
|
||||
|
||||
class BaseModel(ABC):
|
||||
"""This class is an abstract base class (ABC) for models.
|
||||
To create a subclass, you need to implement the following five functions:
|
||||
-- <__init__>: initialize the class; first call BaseModel.__init__(self, opt).
|
||||
-- <set_input>: unpack data from dataset and apply preprocessing.
|
||||
-- <forward>: produce intermediate results.
|
||||
-- <optimize_parameters>: calculate losses, gradients, and update network weights.
|
||||
-- <modify_commandline_options>: (optionally) add model-specific options and set default options.
|
||||
"""
|
||||
|
||||
def __init__(self, opt):
|
||||
"""Initialize the BaseModel class.
|
||||
|
||||
Parameters:
|
||||
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
|
||||
|
||||
When creating your custom class, you need to implement your own initialization.
|
||||
In this function, you should first call <BaseModel.__init__(self, opt)>
|
||||
Then, you need to define four lists:
|
||||
-- self.loss_names (str list): specify the training losses that you want to plot and save.
|
||||
-- self.model_names (str list): define networks used in our training.
|
||||
-- self.visual_names (str list): specify the images that you want to display and save.
|
||||
-- self.optimizers (optimizer list): define and initialize optimizers. You can define one optimizer for each network. If two networks are updated at the same time, you can use itertools.chain to group them. See cycle_gan_model.py for an example.
|
||||
"""
|
||||
self.opt = opt
|
||||
self.gpu_ids = opt.gpu_ids
|
||||
self.isTrain = opt.isTrain
|
||||
self.device = torch.device('cuda:{}'.format(self.gpu_ids[0])) if self.gpu_ids else torch.device('cpu') # get device name: CPU or GPU
|
||||
self.save_dir = os.path.join(opt.checkpoints_dir, opt.name) # save all the checkpoints to save_dir
|
||||
if opt.preprocess != 'scale_width': # with [scale_width], input images might have different sizes, which hurts the performance of cudnn.benchmark.
|
||||
torch.backends.cudnn.benchmark = True
|
||||
self.loss_names = []
|
||||
self.model_names = []
|
||||
self.visual_names = []
|
||||
self.optimizers = []
|
||||
self.image_paths = []
|
||||
self.metric = 0 # used for learning rate policy 'plateau'
|
||||
|
||||
@staticmethod
|
||||
def modify_commandline_options(parser, is_train):
|
||||
"""Add new model-specific options, and rewrite default values for existing options.
|
||||
|
||||
Parameters:
|
||||
parser -- original option parser
|
||||
is_train (bool) -- whether training phase or test phase. You can use this flag to add training-specific or test-specific options.
|
||||
|
||||
Returns:
|
||||
the modified parser.
|
||||
"""
|
||||
return parser
|
||||
|
||||
@abstractmethod
|
||||
def set_input(self, input):
|
||||
"""Unpack input data from the dataloader and perform necessary pre-processing steps.
|
||||
|
||||
Parameters:
|
||||
input (dict): includes the data itself and its metadata information.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def forward(self):
|
||||
"""Run forward pass; called by both functions <optimize_parameters> and <test>."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def optimize_parameters(self):
|
||||
"""Calculate losses, gradients, and update network weights; called in every training iteration"""
|
||||
pass
|
||||
|
||||
def setup(self, opt):
|
||||
"""Load and print networks; create schedulers
|
||||
|
||||
Parameters:
|
||||
opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
|
||||
"""
|
||||
if self.isTrain:
|
||||
self.schedulers = [networks.get_scheduler(optimizer, opt) for optimizer in self.optimizers]
|
||||
if not self.isTrain or opt.continue_train:
|
||||
load_suffix = 'iter_%d' % opt.load_iter if opt.load_iter > 0 else opt.epoch
|
||||
self.load_networks(load_suffix)
|
||||
self.print_networks(opt.verbose)
|
||||
|
||||
def eval(self):
|
||||
"""Make models eval mode during test time"""
|
||||
for name in self.model_names:
|
||||
if isinstance(name, str):
|
||||
net = getattr(self, 'net' + name)
|
||||
net.eval()
|
||||
|
||||
def test(self):
|
||||
"""Forward function used in test time.
|
||||
|
||||
This function wraps <forward> function in no_grad() so we don't save intermediate steps for backprop
|
||||
It also calls <compute_visuals> to produce additional visualization results
|
||||
"""
|
||||
with torch.no_grad():
|
||||
self.forward()
|
||||
self.compute_visuals()
|
||||
|
||||
def compute_visuals(self):
|
||||
"""Calculate additional output images for visdom and HTML visualization"""
|
||||
pass
|
||||
|
||||
def get_image_paths(self):
|
||||
""" Return image paths that are used to load current data"""
|
||||
return self.image_paths
|
||||
|
||||
def update_learning_rate(self):
|
||||
"""Update learning rates for all the networks; called at the end of every epoch"""
|
||||
old_lr = self.optimizers[0].param_groups[0]['lr']
|
||||
for scheduler in self.schedulers:
|
||||
if self.opt.lr_policy == 'plateau':
|
||||
scheduler.step(self.metric)
|
||||
else:
|
||||
scheduler.step()
|
||||
|
||||
lr = self.optimizers[0].param_groups[0]['lr']
|
||||
print('learning rate %.7f -> %.7f' % (old_lr, lr))
|
||||
|
||||
def get_current_visuals(self):
|
||||
"""Return visualization images. train.py will display these images with visdom, and save the images to a HTML"""
|
||||
visual_ret = OrderedDict()
|
||||
for name in self.visual_names:
|
||||
if isinstance(name, str):
|
||||
visual_ret[name] = getattr(self, name)
|
||||
return visual_ret
|
||||
|
||||
def get_current_losses(self):
|
||||
"""Return traning losses / errors. train.py will print out these errors on console, and save them to a file"""
|
||||
errors_ret = OrderedDict()
|
||||
for name in self.loss_names:
|
||||
if isinstance(name, str):
|
||||
errors_ret[name] = float(getattr(self, 'loss_' + name)) # float(...) works for both scalar tensor and float number
|
||||
return errors_ret
|
||||
|
||||
def save_networks(self, epoch):
|
||||
"""Save all the networks to the disk.
|
||||
|
||||
Parameters:
|
||||
epoch (int) -- current epoch; used in the file name '%s_net_%s.pth' % (epoch, name)
|
||||
"""
|
||||
for name in self.model_names:
|
||||
if isinstance(name, str):
|
||||
save_filename = '%s_net_%s.pth' % (epoch, name)
|
||||
save_path = os.path.join(self.save_dir, save_filename)
|
||||
net = getattr(self, 'net' + name)
|
||||
|
||||
if len(self.gpu_ids) > 0 and torch.cuda.is_available():
|
||||
torch.save(net.module.cpu().state_dict(), save_path)
|
||||
net.cuda(self.gpu_ids[0])
|
||||
else:
|
||||
torch.save(net.cpu().state_dict(), save_path)
|
||||
|
||||
def unload_network(self, name):
|
||||
"""Unload network and gc.
|
||||
"""
|
||||
if isinstance(name, str):
|
||||
net = getattr(self, 'net' + name)
|
||||
del net
|
||||
gc.collect()
|
||||
devices.torch_gc()
|
||||
return None
|
||||
|
||||
def __patch_instance_norm_state_dict(self, state_dict, module, keys, i=0):
|
||||
"""Fix InstanceNorm checkpoints incompatibility (prior to 0.4)"""
|
||||
key = keys[i]
|
||||
if i + 1 == len(keys): # at the end, pointing to a parameter/buffer
|
||||
if module.__class__.__name__.startswith('InstanceNorm') and \
|
||||
(key == 'running_mean' or key == 'running_var'):
|
||||
if getattr(module, key) is None:
|
||||
state_dict.pop('.'.join(keys))
|
||||
if module.__class__.__name__.startswith('InstanceNorm') and \
|
||||
(key == 'num_batches_tracked'):
|
||||
state_dict.pop('.'.join(keys))
|
||||
else:
|
||||
self.__patch_instance_norm_state_dict(state_dict, getattr(module, key), keys, i + 1)
|
||||
|
||||
def load_networks(self, epoch):
|
||||
"""Load all the networks from the disk.
|
||||
|
||||
Parameters:
|
||||
epoch (int) -- current epoch; used in the file name '%s_net_%s.pth' % (epoch, name)
|
||||
"""
|
||||
for name in self.model_names:
|
||||
if isinstance(name, str):
|
||||
load_filename = '%s_net_%s.pth' % (epoch, name)
|
||||
load_path = os.path.join(self.save_dir, load_filename)
|
||||
net = getattr(self, 'net' + name)
|
||||
if isinstance(net, torch.nn.DataParallel):
|
||||
net = net.module
|
||||
# print('Loading depth boost model from %s' % load_path)
|
||||
# if you are using PyTorch newer than 0.4 (e.g., built from
|
||||
# GitHub source), you can remove str() on self.device
|
||||
state_dict = torch.load(load_path, map_location=str(self.device))
|
||||
if hasattr(state_dict, '_metadata'):
|
||||
del state_dict._metadata
|
||||
|
||||
# patch InstanceNorm checkpoints prior to 0.4
|
||||
for key in list(state_dict.keys()): # need to copy keys here because we mutate in loop
|
||||
self.__patch_instance_norm_state_dict(state_dict, net, key.split('.'))
|
||||
net.load_state_dict(state_dict)
|
||||
|
||||
def print_networks(self, verbose):
|
||||
"""Print the total number of parameters in the network and (if verbose) network architecture
|
||||
|
||||
Parameters:
|
||||
verbose (bool) -- if verbose: print the network architecture
|
||||
"""
|
||||
print('---------- Networks initialized -------------')
|
||||
for name in self.model_names:
|
||||
if isinstance(name, str):
|
||||
net = getattr(self, 'net' + name)
|
||||
num_params = 0
|
||||
for param in net.parameters():
|
||||
num_params += param.numel()
|
||||
if verbose:
|
||||
print(net)
|
||||
print('[Network %s] Total number of parameters : %.3f M' % (name, num_params / 1e6))
|
||||
print('-----------------------------------------------')
|
||||
|
||||
def set_requires_grad(self, nets, requires_grad=False):
|
||||
"""Set requies_grad=Fasle for all the networks to avoid unnecessary computations
|
||||
Parameters:
|
||||
nets (network list) -- a list of networks
|
||||
requires_grad (bool) -- whether the networks require gradients or not
|
||||
"""
|
||||
if not isinstance(nets, list):
|
||||
nets = [nets]
|
||||
for net in nets:
|
||||
if net is not None:
|
||||
for param in net.parameters():
|
||||
param.requires_grad = requires_grad
|
||||
@@ -1,58 +0,0 @@
|
||||
import os
|
||||
import torch
|
||||
|
||||
class BaseModelHG():
|
||||
def name(self):
|
||||
return 'BaseModel'
|
||||
|
||||
def initialize(self, opt):
|
||||
self.opt = opt
|
||||
self.gpu_ids = opt.gpu_ids
|
||||
self.isTrain = opt.isTrain
|
||||
self.Tensor = torch.cuda.FloatTensor if self.gpu_ids else torch.Tensor
|
||||
self.save_dir = os.path.join(opt.checkpoints_dir, opt.name)
|
||||
|
||||
def set_input(self, input):
|
||||
self.input = input
|
||||
|
||||
def forward(self):
|
||||
pass
|
||||
|
||||
# used in test time, no backprop
|
||||
def test(self):
|
||||
pass
|
||||
|
||||
def get_image_paths(self):
|
||||
pass
|
||||
|
||||
def optimize_parameters(self):
|
||||
pass
|
||||
|
||||
def get_current_visuals(self):
|
||||
return self.input
|
||||
|
||||
def get_current_errors(self):
|
||||
return {}
|
||||
|
||||
def save(self, label):
|
||||
pass
|
||||
|
||||
# helper saving function that can be used by subclasses
|
||||
def save_network(self, network, network_label, epoch_label, gpu_ids):
|
||||
save_filename = '_%s_net_%s.pth' % (epoch_label, network_label)
|
||||
save_path = os.path.join(self.save_dir, save_filename)
|
||||
torch.save(network.cpu().state_dict(), save_path)
|
||||
if len(gpu_ids) and torch.cuda.is_available():
|
||||
network.cuda(device_id=gpu_ids[0])
|
||||
|
||||
# helper loading function that can be used by subclasses
|
||||
def load_network(self, network, network_label, epoch_label):
|
||||
save_filename = '%s_net_%s.pth' % (epoch_label, network_label)
|
||||
save_path = os.path.join(self.save_dir, save_filename)
|
||||
print(save_path)
|
||||
model = torch.load(save_path)
|
||||
return model
|
||||
# network.load_state_dict(torch.load(save_path))
|
||||
|
||||
def update_learning_rate():
|
||||
pass
|
||||
@@ -1,623 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from torch.nn import init
|
||||
import functools
|
||||
from torch.optim import lr_scheduler
|
||||
|
||||
|
||||
###############################################################################
|
||||
# Helper Functions
|
||||
###############################################################################
|
||||
|
||||
|
||||
class Identity(nn.Module):
|
||||
def forward(self, x):
|
||||
return x
|
||||
|
||||
|
||||
def get_norm_layer(norm_type='instance'):
|
||||
"""Return a normalization layer
|
||||
|
||||
Parameters:
|
||||
norm_type (str) -- the name of the normalization layer: batch | instance | none
|
||||
|
||||
For BatchNorm, we use learnable affine parameters and track running statistics (mean/stddev).
|
||||
For InstanceNorm, we do not use learnable affine parameters. We do not track running statistics.
|
||||
"""
|
||||
if norm_type == 'batch':
|
||||
norm_layer = functools.partial(nn.BatchNorm2d, affine=True, track_running_stats=True)
|
||||
elif norm_type == 'instance':
|
||||
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
|
||||
elif norm_type == 'none':
|
||||
def norm_layer(x): return Identity()
|
||||
else:
|
||||
raise NotImplementedError('normalization layer [%s] is not found' % norm_type)
|
||||
return norm_layer
|
||||
|
||||
|
||||
def get_scheduler(optimizer, opt):
|
||||
"""Return a learning rate scheduler
|
||||
|
||||
Parameters:
|
||||
optimizer -- the optimizer of the network
|
||||
opt (option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions.
|
||||
opt.lr_policy is the name of learning rate policy: linear | step | plateau | cosine
|
||||
|
||||
For 'linear', we keep the same learning rate for the first <opt.n_epochs> epochs
|
||||
and linearly decay the rate to zero over the next <opt.n_epochs_decay> epochs.
|
||||
For other schedulers (step, plateau, and cosine), we use the default PyTorch schedulers.
|
||||
See https://pytorch.org/docs/stable/optim.html for more details.
|
||||
"""
|
||||
if opt.lr_policy == 'linear':
|
||||
def lambda_rule(epoch):
|
||||
lr_l = 1.0 - max(0, epoch + opt.epoch_count - opt.n_epochs) / float(opt.n_epochs_decay + 1)
|
||||
return lr_l
|
||||
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_rule)
|
||||
elif opt.lr_policy == 'step':
|
||||
scheduler = lr_scheduler.StepLR(optimizer, step_size=opt.lr_decay_iters, gamma=0.1)
|
||||
elif opt.lr_policy == 'plateau':
|
||||
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.2, threshold=0.01, patience=5)
|
||||
elif opt.lr_policy == 'cosine':
|
||||
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=opt.n_epochs, eta_min=0)
|
||||
else:
|
||||
return NotImplementedError('learning rate policy [%s] is not implemented', opt.lr_policy)
|
||||
return scheduler
|
||||
|
||||
|
||||
def init_weights(net, init_type='normal', init_gain=0.02):
|
||||
"""Initialize network weights.
|
||||
|
||||
Parameters:
|
||||
net (network) -- network to be initialized
|
||||
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
|
||||
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
|
||||
|
||||
We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
|
||||
work better for some applications. Feel free to try yourself.
|
||||
"""
|
||||
def init_func(m): # define the initialization function
|
||||
classname = m.__class__.__name__
|
||||
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
|
||||
if init_type == 'normal':
|
||||
init.normal_(m.weight.data, 0.0, init_gain)
|
||||
elif init_type == 'xavier':
|
||||
init.xavier_normal_(m.weight.data, gain=init_gain)
|
||||
elif init_type == 'kaiming':
|
||||
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
|
||||
elif init_type == 'orthogonal':
|
||||
init.orthogonal_(m.weight.data, gain=init_gain)
|
||||
else:
|
||||
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
|
||||
if hasattr(m, 'bias') and m.bias is not None:
|
||||
init.constant_(m.bias.data, 0.0)
|
||||
elif classname.find('BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
|
||||
init.normal_(m.weight.data, 1.0, init_gain)
|
||||
init.constant_(m.bias.data, 0.0)
|
||||
|
||||
# print('initialize network with %s' % init_type)
|
||||
net.apply(init_func) # apply the initialization function <init_func>
|
||||
|
||||
|
||||
def init_net(net, init_type='normal', init_gain=0.02, gpu_ids=[]):
|
||||
"""Initialize a network: 1. register CPU/GPU device (with multi-GPU support); 2. initialize the network weights
|
||||
Parameters:
|
||||
net (network) -- the network to be initialized
|
||||
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
|
||||
gain (float) -- scaling factor for normal, xavier and orthogonal.
|
||||
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
|
||||
|
||||
Return an initialized network.
|
||||
"""
|
||||
if len(gpu_ids) > 0:
|
||||
assert(torch.cuda.is_available())
|
||||
net.to(gpu_ids[0])
|
||||
net = torch.nn.DataParallel(net, gpu_ids) # multi-GPUs
|
||||
init_weights(net, init_type, init_gain=init_gain)
|
||||
return net
|
||||
|
||||
|
||||
def define_G(input_nc, output_nc, ngf, netG, norm='batch', use_dropout=False, init_type='normal', init_gain=0.02, gpu_ids=[]):
|
||||
"""Create a generator
|
||||
|
||||
Parameters:
|
||||
input_nc (int) -- the number of channels in input images
|
||||
output_nc (int) -- the number of channels in output images
|
||||
ngf (int) -- the number of filters in the last conv layer
|
||||
netG (str) -- the architecture's name: resnet_9blocks | resnet_6blocks | unet_256 | unet_128
|
||||
norm (str) -- the name of normalization layers used in the network: batch | instance | none
|
||||
use_dropout (bool) -- if use dropout layers.
|
||||
init_type (str) -- the name of our initialization method.
|
||||
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
|
||||
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
|
||||
|
||||
Returns a generator
|
||||
|
||||
Our current implementation provides two types of generators:
|
||||
U-Net: [unet_128] (for 128x128 input images) and [unet_256] (for 256x256 input images)
|
||||
The original U-Net paper: https://arxiv.org/abs/1505.04597
|
||||
|
||||
Resnet-based generator: [resnet_6blocks] (with 6 Resnet blocks) and [resnet_9blocks] (with 9 Resnet blocks)
|
||||
Resnet-based generator consists of several Resnet blocks between a few downsampling/upsampling operations.
|
||||
We adapt Torch code from Justin Johnson's neural style transfer project (https://github.com/jcjohnson/fast-neural-style).
|
||||
|
||||
|
||||
The generator has been initialized by <init_net>. It uses RELU for non-linearity.
|
||||
"""
|
||||
net = None
|
||||
norm_layer = get_norm_layer(norm_type=norm)
|
||||
|
||||
if netG == 'resnet_9blocks':
|
||||
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=9)
|
||||
elif netG == 'resnet_6blocks':
|
||||
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=6)
|
||||
elif netG == 'resnet_12blocks':
|
||||
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=12)
|
||||
elif netG == 'unet_128':
|
||||
net = UnetGenerator(input_nc, output_nc, 7, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
|
||||
elif netG == 'unet_256':
|
||||
net = UnetGenerator(input_nc, output_nc, 8, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
|
||||
elif netG == 'unet_672':
|
||||
net = UnetGenerator(input_nc, output_nc, 5, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
|
||||
elif netG == 'unet_960':
|
||||
net = UnetGenerator(input_nc, output_nc, 6, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
|
||||
elif netG == 'unet_1024':
|
||||
net = UnetGenerator(input_nc, output_nc, 10, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
|
||||
else:
|
||||
raise NotImplementedError('Generator model name [%s] is not recognized' % netG)
|
||||
return init_net(net, init_type, init_gain, gpu_ids)
|
||||
|
||||
|
||||
def define_D(input_nc, ndf, netD, n_layers_D=3, norm='batch', init_type='normal', init_gain=0.02, gpu_ids=[]):
|
||||
"""Create a discriminator
|
||||
|
||||
Parameters:
|
||||
input_nc (int) -- the number of channels in input images
|
||||
ndf (int) -- the number of filters in the first conv layer
|
||||
netD (str) -- the architecture's name: basic | n_layers | pixel
|
||||
n_layers_D (int) -- the number of conv layers in the discriminator; effective when netD=='n_layers'
|
||||
norm (str) -- the type of normalization layers used in the network.
|
||||
init_type (str) -- the name of the initialization method.
|
||||
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
|
||||
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
|
||||
|
||||
Returns a discriminator
|
||||
|
||||
Our current implementation provides three types of discriminators:
|
||||
[basic]: 'PatchGAN' classifier described in the original pix2pix paper.
|
||||
It can classify whether 70×70 overlapping patches are real or fake.
|
||||
Such a patch-level discriminator architecture has fewer parameters
|
||||
than a full-image discriminator and can work on arbitrarily-sized images
|
||||
in a fully convolutional fashion.
|
||||
|
||||
[n_layers]: With this mode, you can specify the number of conv layers in the discriminator
|
||||
with the parameter <n_layers_D> (default=3 as used in [basic] (PatchGAN).)
|
||||
|
||||
[pixel]: 1x1 PixelGAN discriminator can classify whether a pixel is real or not.
|
||||
It encourages greater color diversity but has no effect on spatial statistics.
|
||||
|
||||
The discriminator has been initialized by <init_net>. It uses Leakly RELU for non-linearity.
|
||||
"""
|
||||
net = None
|
||||
norm_layer = get_norm_layer(norm_type=norm)
|
||||
|
||||
if netD == 'basic': # default PatchGAN classifier
|
||||
net = NLayerDiscriminator(input_nc, ndf, n_layers=3, norm_layer=norm_layer)
|
||||
elif netD == 'n_layers': # more options
|
||||
net = NLayerDiscriminator(input_nc, ndf, n_layers_D, norm_layer=norm_layer)
|
||||
elif netD == 'pixel': # classify if each pixel is real or fake
|
||||
net = PixelDiscriminator(input_nc, ndf, norm_layer=norm_layer)
|
||||
else:
|
||||
raise NotImplementedError('Discriminator model name [%s] is not recognized' % netD)
|
||||
return init_net(net, init_type, init_gain, gpu_ids)
|
||||
|
||||
|
||||
##############################################################################
|
||||
# Classes
|
||||
##############################################################################
|
||||
class GANLoss(nn.Module):
|
||||
"""Define different GAN objectives.
|
||||
|
||||
The GANLoss class abstracts away the need to create the target label tensor
|
||||
that has the same size as the input.
|
||||
"""
|
||||
|
||||
def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0):
|
||||
""" Initialize the GANLoss class.
|
||||
|
||||
Parameters:
|
||||
gan_mode (str) - - the type of GAN objective. It currently supports vanilla, lsgan, and wgangp.
|
||||
target_real_label (bool) - - label for a real image
|
||||
target_fake_label (bool) - - label of a fake image
|
||||
|
||||
Note: Do not use sigmoid as the last layer of Discriminator.
|
||||
LSGAN needs no sigmoid. vanilla GANs will handle it with BCEWithLogitsLoss.
|
||||
"""
|
||||
super(GANLoss, self).__init__()
|
||||
self.register_buffer('real_label', torch.tensor(target_real_label))
|
||||
self.register_buffer('fake_label', torch.tensor(target_fake_label))
|
||||
self.gan_mode = gan_mode
|
||||
if gan_mode == 'lsgan':
|
||||
self.loss = nn.MSELoss()
|
||||
elif gan_mode == 'vanilla':
|
||||
self.loss = nn.BCEWithLogitsLoss()
|
||||
elif gan_mode in ['wgangp']:
|
||||
self.loss = None
|
||||
else:
|
||||
raise NotImplementedError('gan mode %s not implemented' % gan_mode)
|
||||
|
||||
def get_target_tensor(self, prediction, target_is_real):
|
||||
"""Create label tensors with the same size as the input.
|
||||
|
||||
Parameters:
|
||||
prediction (tensor) - - tpyically the prediction from a discriminator
|
||||
target_is_real (bool) - - if the ground truth label is for real images or fake images
|
||||
|
||||
Returns:
|
||||
A label tensor filled with ground truth label, and with the size of the input
|
||||
"""
|
||||
|
||||
if target_is_real:
|
||||
target_tensor = self.real_label
|
||||
else:
|
||||
target_tensor = self.fake_label
|
||||
return target_tensor.expand_as(prediction)
|
||||
|
||||
def __call__(self, prediction, target_is_real):
|
||||
"""Calculate loss given Discriminator's output and grount truth labels.
|
||||
|
||||
Parameters:
|
||||
prediction (tensor) - - tpyically the prediction output from a discriminator
|
||||
target_is_real (bool) - - if the ground truth label is for real images or fake images
|
||||
|
||||
Returns:
|
||||
the calculated loss.
|
||||
"""
|
||||
if self.gan_mode in ['lsgan', 'vanilla']:
|
||||
target_tensor = self.get_target_tensor(prediction, target_is_real)
|
||||
loss = self.loss(prediction, target_tensor)
|
||||
elif self.gan_mode == 'wgangp':
|
||||
if target_is_real:
|
||||
loss = -prediction.mean()
|
||||
else:
|
||||
loss = prediction.mean()
|
||||
return loss
|
||||
|
||||
|
||||
def cal_gradient_penalty(netD, real_data, fake_data, device, type='mixed', constant=1.0, lambda_gp=10.0):
|
||||
"""Calculate the gradient penalty loss, used in WGAN-GP paper https://arxiv.org/abs/1704.00028
|
||||
|
||||
Arguments:
|
||||
netD (network) -- discriminator network
|
||||
real_data (tensor array) -- real images
|
||||
fake_data (tensor array) -- generated images from the generator
|
||||
device (str) -- GPU / CPU: from torch.device('cuda:{}'.format(self.gpu_ids[0])) if self.gpu_ids else torch.device('cpu')
|
||||
type (str) -- if we mix real and fake data or not [real | fake | mixed].
|
||||
constant (float) -- the constant used in formula ( ||gradient||_2 - constant)^2
|
||||
lambda_gp (float) -- weight for this loss
|
||||
|
||||
Returns the gradient penalty loss
|
||||
"""
|
||||
if lambda_gp > 0.0:
|
||||
if type == 'real': # either use real images, fake images, or a linear interpolation of two.
|
||||
interpolatesv = real_data
|
||||
elif type == 'fake':
|
||||
interpolatesv = fake_data
|
||||
elif type == 'mixed':
|
||||
alpha = torch.rand(real_data.shape[0], 1, device=device)
|
||||
alpha = alpha.expand(real_data.shape[0], real_data.nelement() // real_data.shape[0]).contiguous().view(*real_data.shape)
|
||||
interpolatesv = alpha * real_data + ((1 - alpha) * fake_data)
|
||||
else:
|
||||
raise NotImplementedError('{} not implemented'.format(type))
|
||||
interpolatesv.requires_grad_(True)
|
||||
disc_interpolates = netD(interpolatesv)
|
||||
gradients = torch.autograd.grad(outputs=disc_interpolates, inputs=interpolatesv,
|
||||
grad_outputs=torch.ones(disc_interpolates.size()).to(device),
|
||||
create_graph=True, retain_graph=True, only_inputs=True)
|
||||
gradients = gradients[0].view(real_data.size(0), -1) # flat the data
|
||||
gradient_penalty = (((gradients + 1e-16).norm(2, dim=1) - constant) ** 2).mean() * lambda_gp # added eps
|
||||
return gradient_penalty, gradients
|
||||
else:
|
||||
return 0.0, None
|
||||
|
||||
|
||||
class ResnetGenerator(nn.Module):
|
||||
"""Resnet-based generator that consists of Resnet blocks between a few downsampling/upsampling operations.
|
||||
|
||||
We adapt Torch code and idea from Justin Johnson's neural style transfer project(https://github.com/jcjohnson/fast-neural-style)
|
||||
"""
|
||||
|
||||
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6, padding_type='reflect'):
|
||||
"""Construct a Resnet-based generator
|
||||
|
||||
Parameters:
|
||||
input_nc (int) -- the number of channels in input images
|
||||
output_nc (int) -- the number of channels in output images
|
||||
ngf (int) -- the number of filters in the last conv layer
|
||||
norm_layer -- normalization layer
|
||||
use_dropout (bool) -- if use dropout layers
|
||||
n_blocks (int) -- the number of ResNet blocks
|
||||
padding_type (str) -- the name of padding layer in conv layers: reflect | replicate | zero
|
||||
"""
|
||||
assert(n_blocks >= 0)
|
||||
super(ResnetGenerator, self).__init__()
|
||||
if type(norm_layer) == functools.partial:
|
||||
use_bias = norm_layer.func == nn.InstanceNorm2d
|
||||
else:
|
||||
use_bias = norm_layer == nn.InstanceNorm2d
|
||||
|
||||
model = [nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),
|
||||
norm_layer(ngf),
|
||||
nn.ReLU(True)]
|
||||
|
||||
n_downsampling = 2
|
||||
for i in range(n_downsampling): # add downsampling layers
|
||||
mult = 2 ** i
|
||||
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),
|
||||
norm_layer(ngf * mult * 2),
|
||||
nn.ReLU(True)]
|
||||
|
||||
mult = 2 ** n_downsampling
|
||||
for i in range(n_blocks): # add ResNet blocks
|
||||
|
||||
model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
|
||||
|
||||
for i in range(n_downsampling): # add upsampling layers
|
||||
mult = 2 ** (n_downsampling - i)
|
||||
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
|
||||
kernel_size=3, stride=2,
|
||||
padding=1, output_padding=1,
|
||||
bias=use_bias),
|
||||
norm_layer(int(ngf * mult / 2)),
|
||||
nn.ReLU(True)]
|
||||
model += [nn.ReflectionPad2d(3)]
|
||||
model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
||||
model += [nn.Tanh()]
|
||||
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, input):
|
||||
"""Standard forward"""
|
||||
return self.model(input)
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
"""Define a Resnet block"""
|
||||
|
||||
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
|
||||
"""Initialize the Resnet block
|
||||
|
||||
A resnet block is a conv block with skip connections
|
||||
We construct a conv block with build_conv_block function,
|
||||
and implement skip connections in <forward> function.
|
||||
Original Resnet paper: https://arxiv.org/pdf/1512.03385.pdf
|
||||
"""
|
||||
super(ResnetBlock, self).__init__()
|
||||
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias)
|
||||
|
||||
def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias):
|
||||
"""Construct a convolutional block.
|
||||
|
||||
Parameters:
|
||||
dim (int) -- the number of channels in the conv layer.
|
||||
padding_type (str) -- the name of padding layer: reflect | replicate | zero
|
||||
norm_layer -- normalization layer
|
||||
use_dropout (bool) -- if use dropout layers.
|
||||
use_bias (bool) -- if the conv layer uses bias or not
|
||||
|
||||
Returns a conv block (with a conv layer, a normalization layer, and a non-linearity layer (ReLU))
|
||||
"""
|
||||
conv_block = []
|
||||
p = 0
|
||||
if padding_type == 'reflect':
|
||||
conv_block += [nn.ReflectionPad2d(1)]
|
||||
elif padding_type == 'replicate':
|
||||
conv_block += [nn.ReplicationPad2d(1)]
|
||||
elif padding_type == 'zero':
|
||||
p = 1
|
||||
else:
|
||||
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
||||
|
||||
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
|
||||
if use_dropout:
|
||||
conv_block += [nn.Dropout(0.5)]
|
||||
|
||||
p = 0
|
||||
if padding_type == 'reflect':
|
||||
conv_block += [nn.ReflectionPad2d(1)]
|
||||
elif padding_type == 'replicate':
|
||||
conv_block += [nn.ReplicationPad2d(1)]
|
||||
elif padding_type == 'zero':
|
||||
p = 1
|
||||
else:
|
||||
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
||||
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
|
||||
|
||||
return nn.Sequential(*conv_block)
|
||||
|
||||
def forward(self, x):
|
||||
"""Forward function (with skip connections)"""
|
||||
out = x + self.conv_block(x) # add skip connections
|
||||
return out
|
||||
|
||||
|
||||
class UnetGenerator(nn.Module):
|
||||
"""Create a Unet-based generator"""
|
||||
|
||||
def __init__(self, input_nc, output_nc, num_downs, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False):
|
||||
"""Construct a Unet generator
|
||||
Parameters:
|
||||
input_nc (int) -- the number of channels in input images
|
||||
output_nc (int) -- the number of channels in output images
|
||||
num_downs (int) -- the number of downsamplings in UNet. For example, # if |num_downs| == 7,
|
||||
image of size 128x128 will become of size 1x1 # at the bottleneck
|
||||
ngf (int) -- the number of filters in the last conv layer
|
||||
norm_layer -- normalization layer
|
||||
|
||||
We construct the U-Net from the innermost layer to the outermost layer.
|
||||
It is a recursive process.
|
||||
"""
|
||||
super(UnetGenerator, self).__init__()
|
||||
# construct unet structure
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=None, norm_layer=norm_layer, innermost=True) # add the innermost layer
|
||||
for i in range(num_downs - 5): # add intermediate layers with ngf * 8 filters
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer, use_dropout=use_dropout)
|
||||
# gradually reduce the number of filters from ngf * 8 to ngf
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 4, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 2, ngf * 4, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
||||
unet_block = UnetSkipConnectionBlock(ngf, ngf * 2, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
||||
self.model = UnetSkipConnectionBlock(output_nc, ngf, input_nc=input_nc, submodule=unet_block, outermost=True, norm_layer=norm_layer) # add the outermost layer
|
||||
|
||||
def forward(self, input):
|
||||
"""Standard forward"""
|
||||
return self.model(input)
|
||||
|
||||
|
||||
class UnetSkipConnectionBlock(nn.Module):
|
||||
"""Defines the Unet submodule with skip connection.
|
||||
X -------------------identity----------------------
|
||||
|-- downsampling -- |submodule| -- upsampling --|
|
||||
"""
|
||||
|
||||
def __init__(self, outer_nc, inner_nc, input_nc=None,
|
||||
submodule=None, outermost=False, innermost=False, norm_layer=nn.BatchNorm2d, use_dropout=False):
|
||||
"""Construct a Unet submodule with skip connections.
|
||||
|
||||
Parameters:
|
||||
outer_nc (int) -- the number of filters in the outer conv layer
|
||||
inner_nc (int) -- the number of filters in the inner conv layer
|
||||
input_nc (int) -- the number of channels in input images/features
|
||||
submodule (UnetSkipConnectionBlock) -- previously defined submodules
|
||||
outermost (bool) -- if this module is the outermost module
|
||||
innermost (bool) -- if this module is the innermost module
|
||||
norm_layer -- normalization layer
|
||||
use_dropout (bool) -- if use dropout layers.
|
||||
"""
|
||||
super(UnetSkipConnectionBlock, self).__init__()
|
||||
self.outermost = outermost
|
||||
if type(norm_layer) == functools.partial:
|
||||
use_bias = norm_layer.func == nn.InstanceNorm2d
|
||||
else:
|
||||
use_bias = norm_layer == nn.InstanceNorm2d
|
||||
if input_nc is None:
|
||||
input_nc = outer_nc
|
||||
downconv = nn.Conv2d(input_nc, inner_nc, kernel_size=4,
|
||||
stride=2, padding=1, bias=use_bias)
|
||||
downrelu = nn.LeakyReLU(0.2, True)
|
||||
downnorm = norm_layer(inner_nc)
|
||||
uprelu = nn.ReLU(True)
|
||||
upnorm = norm_layer(outer_nc)
|
||||
|
||||
if outermost:
|
||||
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
|
||||
kernel_size=4, stride=2,
|
||||
padding=1)
|
||||
down = [downconv]
|
||||
up = [uprelu, upconv, nn.Tanh()]
|
||||
model = down + [submodule] + up
|
||||
elif innermost:
|
||||
upconv = nn.ConvTranspose2d(inner_nc, outer_nc,
|
||||
kernel_size=4, stride=2,
|
||||
padding=1, bias=use_bias)
|
||||
down = [downrelu, downconv]
|
||||
up = [uprelu, upconv, upnorm]
|
||||
model = down + up
|
||||
else:
|
||||
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
|
||||
kernel_size=4, stride=2,
|
||||
padding=1, bias=use_bias)
|
||||
down = [downrelu, downconv, downnorm]
|
||||
up = [uprelu, upconv, upnorm]
|
||||
|
||||
if use_dropout:
|
||||
model = down + [submodule] + up + [nn.Dropout(0.5)]
|
||||
else:
|
||||
model = down + [submodule] + up
|
||||
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, x):
|
||||
if self.outermost:
|
||||
return self.model(x)
|
||||
else: # add skip connections
|
||||
return torch.cat([x, self.model(x)], 1)
|
||||
|
||||
|
||||
class NLayerDiscriminator(nn.Module):
|
||||
"""Defines a PatchGAN discriminator"""
|
||||
|
||||
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):
|
||||
"""Construct a PatchGAN discriminator
|
||||
|
||||
Parameters:
|
||||
input_nc (int) -- the number of channels in input images
|
||||
ndf (int) -- the number of filters in the last conv layer
|
||||
n_layers (int) -- the number of conv layers in the discriminator
|
||||
norm_layer -- normalization layer
|
||||
"""
|
||||
super(NLayerDiscriminator, self).__init__()
|
||||
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
|
||||
use_bias = norm_layer.func == nn.InstanceNorm2d
|
||||
else:
|
||||
use_bias = norm_layer == nn.InstanceNorm2d
|
||||
|
||||
kw = 4
|
||||
padw = 1
|
||||
sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
|
||||
nf_mult = 1
|
||||
nf_mult_prev = 1
|
||||
for n in range(1, n_layers): # gradually increase the number of filters
|
||||
nf_mult_prev = nf_mult
|
||||
nf_mult = min(2 ** n, 8)
|
||||
sequence += [
|
||||
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
|
||||
norm_layer(ndf * nf_mult),
|
||||
nn.LeakyReLU(0.2, True)
|
||||
]
|
||||
|
||||
nf_mult_prev = nf_mult
|
||||
nf_mult = min(2 ** n_layers, 8)
|
||||
sequence += [
|
||||
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
|
||||
norm_layer(ndf * nf_mult),
|
||||
nn.LeakyReLU(0.2, True)
|
||||
]
|
||||
|
||||
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
|
||||
self.model = nn.Sequential(*sequence)
|
||||
|
||||
def forward(self, input):
|
||||
"""Standard forward."""
|
||||
return self.model(input)
|
||||
|
||||
|
||||
class PixelDiscriminator(nn.Module):
|
||||
"""Defines a 1x1 PatchGAN discriminator (pixelGAN)"""
|
||||
|
||||
def __init__(self, input_nc, ndf=64, norm_layer=nn.BatchNorm2d):
|
||||
"""Construct a 1x1 PatchGAN discriminator
|
||||
|
||||
Parameters:
|
||||
input_nc (int) -- the number of channels in input images
|
||||
ndf (int) -- the number of filters in the last conv layer
|
||||
norm_layer -- normalization layer
|
||||
"""
|
||||
super(PixelDiscriminator, self).__init__()
|
||||
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
|
||||
use_bias = norm_layer.func == nn.InstanceNorm2d
|
||||
else:
|
||||
use_bias = norm_layer == nn.InstanceNorm2d
|
||||
|
||||
self.net = [
|
||||
nn.Conv2d(input_nc, ndf, kernel_size=1, stride=1, padding=0),
|
||||
nn.LeakyReLU(0.2, True),
|
||||
nn.Conv2d(ndf, ndf * 2, kernel_size=1, stride=1, padding=0, bias=use_bias),
|
||||
norm_layer(ndf * 2),
|
||||
nn.LeakyReLU(0.2, True),
|
||||
nn.Conv2d(ndf * 2, 1, kernel_size=1, stride=1, padding=0, bias=use_bias)]
|
||||
|
||||
self.net = nn.Sequential(*self.net)
|
||||
|
||||
def forward(self, input):
|
||||
"""Standard forward."""
|
||||
return self.net(input)
|
||||
@@ -1,155 +0,0 @@
|
||||
import torch
|
||||
from .base_model import BaseModel
|
||||
from . import networks
|
||||
|
||||
|
||||
class Pix2Pix4DepthModel(BaseModel):
|
||||
""" This class implements the pix2pix model, for learning a mapping from input images to output images given paired data.
|
||||
|
||||
The model training requires '--dataset_mode aligned' dataset.
|
||||
By default, it uses a '--netG unet256' U-Net generator,
|
||||
a '--netD basic' discriminator (PatchGAN),
|
||||
and a '--gan_mode' vanilla GAN loss (the cross-entropy objective used in the orignal GAN paper).
|
||||
|
||||
pix2pix paper: https://arxiv.org/pdf/1611.07004.pdf
|
||||
"""
|
||||
@staticmethod
|
||||
def modify_commandline_options(parser, is_train=True):
|
||||
"""Add new dataset-specific options, and rewrite default values for existing options.
|
||||
|
||||
Parameters:
|
||||
parser -- original option parser
|
||||
is_train (bool) -- whether training phase or test phase. You can use this flag to add training-specific or test-specific options.
|
||||
|
||||
Returns:
|
||||
the modified parser.
|
||||
|
||||
For pix2pix, we do not use image buffer
|
||||
The training objective is: GAN Loss + lambda_L1 * ||G(A)-B||_1
|
||||
By default, we use vanilla GAN loss, UNet with batchnorm, and aligned datasets.
|
||||
"""
|
||||
# changing the default values to match the pix2pix paper (https://phillipi.github.io/pix2pix/)
|
||||
parser.set_defaults(input_nc=2,output_nc=1,norm='none', netG='unet_1024', dataset_mode='depthmerge')
|
||||
if is_train:
|
||||
parser.set_defaults(pool_size=0, gan_mode='vanilla',)
|
||||
parser.add_argument('--lambda_L1', type=float, default=1000, help='weight for L1 loss')
|
||||
return parser
|
||||
|
||||
def __init__(self, opt):
|
||||
"""Initialize the pix2pix class.
|
||||
|
||||
Parameters:
|
||||
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
|
||||
"""
|
||||
BaseModel.__init__(self, opt)
|
||||
# specify the training losses you want to print out. The training/test scripts will call <BaseModel.get_current_losses>
|
||||
|
||||
self.loss_names = ['G_GAN', 'G_L1', 'D_real', 'D_fake']
|
||||
# self.loss_names = ['G_L1']
|
||||
|
||||
# specify the images you want to save/display. The training/test scripts will call <BaseModel.get_current_visuals>
|
||||
if self.isTrain:
|
||||
self.visual_names = ['outer','inner', 'fake_B', 'real_B']
|
||||
else:
|
||||
self.visual_names = ['fake_B']
|
||||
|
||||
# specify the models you want to save to the disk. The training/test scripts will call <BaseModel.save_networks> and <BaseModel.load_networks>
|
||||
if self.isTrain:
|
||||
self.model_names = ['G','D']
|
||||
else: # during test time, only load G
|
||||
self.model_names = ['G']
|
||||
|
||||
# define networks (both generator and discriminator)
|
||||
self.netG = networks.define_G(opt.input_nc, opt.output_nc, 64, 'unet_1024', 'none',
|
||||
False, 'normal', 0.02, self.gpu_ids)
|
||||
|
||||
if self.isTrain: # define a discriminator; conditional GANs need to take both input and output images; Therefore, #channels for D is input_nc + output_nc
|
||||
self.netD = networks.define_D(opt.input_nc + opt.output_nc, opt.ndf, opt.netD,
|
||||
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
|
||||
|
||||
if self.isTrain:
|
||||
# define loss functions
|
||||
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device)
|
||||
self.criterionL1 = torch.nn.L1Loss()
|
||||
# initialize optimizers; schedulers will be automatically created by function <BaseModel.setup>.
|
||||
self.optimizer_G = torch.optim.Adam(self.netG.parameters(), lr=1e-4, betas=(opt.beta1, 0.999))
|
||||
self.optimizer_D = torch.optim.Adam(self.netD.parameters(), lr=2e-06, betas=(opt.beta1, 0.999))
|
||||
self.optimizers.append(self.optimizer_G)
|
||||
self.optimizers.append(self.optimizer_D)
|
||||
|
||||
def set_input_train(self, input):
|
||||
self.outer = input['data_outer'].to(self.device)
|
||||
self.outer = torch.nn.functional.interpolate(self.outer,(1024,1024),mode='bilinear',align_corners=False)
|
||||
|
||||
self.inner = input['data_inner'].to(self.device)
|
||||
self.inner = torch.nn.functional.interpolate(self.inner,(1024,1024),mode='bilinear',align_corners=False)
|
||||
|
||||
self.image_paths = input['image_path']
|
||||
|
||||
if self.isTrain:
|
||||
self.gtfake = input['data_gtfake'].to(self.device)
|
||||
self.gtfake = torch.nn.functional.interpolate(self.gtfake, (1024, 1024), mode='bilinear', align_corners=False)
|
||||
self.real_B = self.gtfake
|
||||
|
||||
self.real_A = torch.cat((self.outer, self.inner), 1)
|
||||
|
||||
def set_input(self, outer, inner):
|
||||
inner = torch.from_numpy(inner).unsqueeze(0).unsqueeze(0)
|
||||
outer = torch.from_numpy(outer).unsqueeze(0).unsqueeze(0)
|
||||
|
||||
inner = (inner - torch.min(inner))/(torch.max(inner)-torch.min(inner))
|
||||
outer = (outer - torch.min(outer))/(torch.max(outer)-torch.min(outer))
|
||||
|
||||
inner = self.normalize(inner)
|
||||
outer = self.normalize(outer)
|
||||
|
||||
self.real_A = torch.cat((outer, inner), 1).to(self.device)
|
||||
|
||||
|
||||
def normalize(self, input):
|
||||
input = input * 2
|
||||
input = input - 1
|
||||
return input
|
||||
|
||||
def forward(self):
|
||||
"""Run forward pass; called by both functions <optimize_parameters> and <test>."""
|
||||
self.fake_B = self.netG(self.real_A) # G(A)
|
||||
|
||||
def backward_D(self):
|
||||
"""Calculate GAN loss for the discriminator"""
|
||||
# Fake; stop backprop to the generator by detaching fake_B
|
||||
fake_AB = torch.cat((self.real_A, self.fake_B), 1) # we use conditional GANs; we need to feed both input and output to the discriminator
|
||||
pred_fake = self.netD(fake_AB.detach())
|
||||
self.loss_D_fake = self.criterionGAN(pred_fake, False)
|
||||
# Real
|
||||
real_AB = torch.cat((self.real_A, self.real_B), 1)
|
||||
pred_real = self.netD(real_AB)
|
||||
self.loss_D_real = self.criterionGAN(pred_real, True)
|
||||
# combine loss and calculate gradients
|
||||
self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5
|
||||
self.loss_D.backward()
|
||||
|
||||
def backward_G(self):
|
||||
"""Calculate GAN and L1 loss for the generator"""
|
||||
# First, G(A) should fake the discriminator
|
||||
fake_AB = torch.cat((self.real_A, self.fake_B), 1)
|
||||
pred_fake = self.netD(fake_AB)
|
||||
self.loss_G_GAN = self.criterionGAN(pred_fake, True)
|
||||
# Second, G(A) = B
|
||||
self.loss_G_L1 = self.criterionL1(self.fake_B, self.real_B) * self.opt.lambda_L1
|
||||
# combine loss and calculate gradients
|
||||
self.loss_G = self.loss_G_L1 + self.loss_G_GAN
|
||||
self.loss_G.backward()
|
||||
|
||||
def optimize_parameters(self):
|
||||
self.forward() # compute fake images: G(A)
|
||||
# update D
|
||||
self.set_requires_grad(self.netD, True) # enable backprop for D
|
||||
self.optimizer_D.zero_grad() # set D's gradients to zero
|
||||
self.backward_D() # calculate gradients for D
|
||||
self.optimizer_D.step() # update D's weights
|
||||
# update G
|
||||
self.set_requires_grad(self.netD, False) # D requires no gradients when optimizing G
|
||||
self.optimizer_G.zero_grad() # set G's gradients to zero
|
||||
self.backward_G() # calculate graidents for G
|
||||
self.optimizer_G.step() # udpate G's weights
|
||||
@@ -1 +0,0 @@
|
||||
"""This package options includes option modules: training options, test options, and basic options (used in both training and test)."""
|
||||
@@ -1,156 +0,0 @@
|
||||
import argparse
|
||||
import os
|
||||
from ...pix2pix.util import util
|
||||
# import torch
|
||||
from ...pix2pix import models
|
||||
# import pix2pix.data
|
||||
import numpy as np
|
||||
|
||||
class BaseOptions():
|
||||
"""This class defines options used during both training and test time.
|
||||
|
||||
It also implements several helper functions such as parsing, printing, and saving the options.
|
||||
It also gathers additional options defined in <modify_commandline_options> functions in both dataset class and model class.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
"""Reset the class; indicates the class hasn't been initailized"""
|
||||
self.initialized = False
|
||||
|
||||
def initialize(self, parser):
|
||||
"""Define the common options that are used in both training and test."""
|
||||
# basic parameters
|
||||
parser.add_argument('--dataroot', help='path to images (should have subfolders trainA, trainB, valA, valB, etc)')
|
||||
parser.add_argument('--name', type=str, default='void', help='mahdi_unet_new, scaled_unet')
|
||||
parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
|
||||
parser.add_argument('--checkpoints_dir', type=str, default='./pix2pix/checkpoints', help='models are saved here')
|
||||
# model parameters
|
||||
parser.add_argument('--model', type=str, default='cycle_gan', help='chooses which model to use. [cycle_gan | pix2pix | test | colorization]')
|
||||
parser.add_argument('--input_nc', type=int, default=2, help='# of input image channels: 3 for RGB and 1 for grayscale')
|
||||
parser.add_argument('--output_nc', type=int, default=1, help='# of output image channels: 3 for RGB and 1 for grayscale')
|
||||
parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in the last conv layer')
|
||||
parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in the first conv layer')
|
||||
parser.add_argument('--netD', type=str, default='basic', help='specify discriminator architecture [basic | n_layers | pixel]. The basic model is a 70x70 PatchGAN. n_layers allows you to specify the layers in the discriminator')
|
||||
parser.add_argument('--netG', type=str, default='resnet_9blocks', help='specify generator architecture [resnet_9blocks | resnet_6blocks | unet_256 | unet_128]')
|
||||
parser.add_argument('--n_layers_D', type=int, default=3, help='only used if netD==n_layers')
|
||||
parser.add_argument('--norm', type=str, default='instance', help='instance normalization or batch normalization [instance | batch | none]')
|
||||
parser.add_argument('--init_type', type=str, default='normal', help='network initialization [normal | xavier | kaiming | orthogonal]')
|
||||
parser.add_argument('--init_gain', type=float, default=0.02, help='scaling factor for normal, xavier and orthogonal.')
|
||||
parser.add_argument('--no_dropout', action='store_true', help='no dropout for the generator')
|
||||
# dataset parameters
|
||||
parser.add_argument('--dataset_mode', type=str, default='unaligned', help='chooses how datasets are loaded. [unaligned | aligned | single | colorization]')
|
||||
parser.add_argument('--direction', type=str, default='AtoB', help='AtoB or BtoA')
|
||||
parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
|
||||
parser.add_argument('--num_threads', default=4, type=int, help='# threads for loading data')
|
||||
parser.add_argument('--batch_size', type=int, default=1, help='input batch size')
|
||||
parser.add_argument('--load_size', type=int, default=672, help='scale images to this size')
|
||||
parser.add_argument('--crop_size', type=int, default=672, help='then crop to this size')
|
||||
parser.add_argument('--max_dataset_size', type=int, default=10000, help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
|
||||
parser.add_argument('--preprocess', type=str, default='resize_and_crop', help='scaling and cropping of images at load time [resize_and_crop | crop | scale_width | scale_width_and_crop | none]')
|
||||
parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data augmentation')
|
||||
parser.add_argument('--display_winsize', type=int, default=256, help='display window size for both visdom and HTML')
|
||||
# additional parameters
|
||||
parser.add_argument('--epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
|
||||
parser.add_argument('--load_iter', type=int, default='0', help='which iteration to load? if load_iter > 0, the code will load models by iter_[load_iter]; otherwise, the code will load models by [epoch]')
|
||||
parser.add_argument('--verbose', action='store_true', help='if specified, print more debugging information')
|
||||
parser.add_argument('--suffix', default='', type=str, help='customized suffix: opt.name = opt.name + suffix: e.g., {model}_{netG}_size{load_size}')
|
||||
|
||||
parser.add_argument('--data_dir', type=str, required=False,
|
||||
help='input files directory images can be .png .jpg .tiff')
|
||||
parser.add_argument('--output_dir', type=str, required=False,
|
||||
help='result dir. result depth will be png. vides are JMPG as avi')
|
||||
parser.add_argument('--savecrops', type=int, required=False)
|
||||
parser.add_argument('--savewholeest', type=int, required=False)
|
||||
parser.add_argument('--output_resolution', type=int, required=False,
|
||||
help='0 for no restriction 1 for resize to input size')
|
||||
parser.add_argument('--net_receptive_field_size', type=int, required=False)
|
||||
parser.add_argument('--pix2pixsize', type=int, required=False)
|
||||
parser.add_argument('--generatevideo', type=int, required=False)
|
||||
parser.add_argument('--depthNet', type=int, required=False, help='0: midas 1:strurturedRL')
|
||||
parser.add_argument('--R0', action='store_true')
|
||||
parser.add_argument('--R20', action='store_true')
|
||||
parser.add_argument('--Final', action='store_true')
|
||||
parser.add_argument('--colorize_results', action='store_true')
|
||||
parser.add_argument('--max_res', type=float, default=np.inf)
|
||||
|
||||
self.initialized = True
|
||||
return parser
|
||||
|
||||
def gather_options(self):
|
||||
"""Initialize our parser with basic options(only once).
|
||||
Add additional model-specific and dataset-specific options.
|
||||
These options are defined in the <modify_commandline_options> function
|
||||
in model and dataset classes.
|
||||
"""
|
||||
if not self.initialized: # check if it has been initialized
|
||||
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
||||
parser = self.initialize(parser)
|
||||
|
||||
# get the basic options
|
||||
opt, _ = parser.parse_known_args()
|
||||
|
||||
# modify model-related parser options
|
||||
model_name = opt.model
|
||||
model_option_setter = models.get_option_setter(model_name)
|
||||
parser = model_option_setter(parser, self.isTrain)
|
||||
opt, _ = parser.parse_known_args() # parse again with new defaults
|
||||
|
||||
# modify dataset-related parser options
|
||||
# dataset_name = opt.dataset_mode
|
||||
# dataset_option_setter = pix2pix.data.get_option_setter(dataset_name)
|
||||
# parser = dataset_option_setter(parser, self.isTrain)
|
||||
|
||||
# save and return the parser
|
||||
self.parser = parser
|
||||
#return parser.parse_args() #EVIL
|
||||
return opt
|
||||
|
||||
def print_options(self, opt):
|
||||
"""Print and save options
|
||||
|
||||
It will print both current options and default values(if different).
|
||||
It will save options into a text file / [checkpoints_dir] / opt.txt
|
||||
"""
|
||||
message = ''
|
||||
message += '----------------- Options ---------------\n'
|
||||
for k, v in sorted(vars(opt).items()):
|
||||
comment = ''
|
||||
default = self.parser.get_default(k)
|
||||
if v != default:
|
||||
comment = '\t[default: %s]' % str(default)
|
||||
message += '{:>25}: {:<30}{}\n'.format(str(k), str(v), comment)
|
||||
message += '----------------- End -------------------'
|
||||
print(message)
|
||||
|
||||
# save to the disk
|
||||
expr_dir = os.path.join(opt.checkpoints_dir, opt.name)
|
||||
util.mkdirs(expr_dir)
|
||||
file_name = os.path.join(expr_dir, '{}_opt.txt'.format(opt.phase))
|
||||
with open(file_name, 'wt') as opt_file:
|
||||
opt_file.write(message)
|
||||
opt_file.write('\n')
|
||||
|
||||
def parse(self):
|
||||
"""Parse our options, create checkpoints directory suffix, and set up gpu device."""
|
||||
opt = self.gather_options()
|
||||
opt.isTrain = self.isTrain # train or test
|
||||
|
||||
# process opt.suffix
|
||||
if opt.suffix:
|
||||
suffix = ('_' + opt.suffix.format(**vars(opt))) if opt.suffix != '' else ''
|
||||
opt.name = opt.name + suffix
|
||||
|
||||
#self.print_options(opt)
|
||||
|
||||
# set gpu ids
|
||||
str_ids = opt.gpu_ids.split(',')
|
||||
opt.gpu_ids = []
|
||||
for str_id in str_ids:
|
||||
id = int(str_id)
|
||||
if id >= 0:
|
||||
opt.gpu_ids.append(id)
|
||||
#if len(opt.gpu_ids) > 0:
|
||||
# torch.cuda.set_device(opt.gpu_ids[0])
|
||||
|
||||
self.opt = opt
|
||||
return self.opt
|
||||
@@ -1,22 +0,0 @@
|
||||
from .base_options import BaseOptions
|
||||
|
||||
|
||||
class TestOptions(BaseOptions):
|
||||
"""This class includes test options.
|
||||
|
||||
It also includes shared options defined in BaseOptions.
|
||||
"""
|
||||
|
||||
def initialize(self, parser):
|
||||
parser = BaseOptions.initialize(self, parser) # define shared options
|
||||
parser.add_argument('--aspect_ratio', type=float, default=1.0, help='aspect ratio of result images')
|
||||
parser.add_argument('--phase', type=str, default='test', help='train, val, test, etc')
|
||||
# Dropout and Batchnorm has different behavioir during training and test.
|
||||
parser.add_argument('--eval', action='store_true', help='use eval mode during test time.')
|
||||
parser.add_argument('--num_test', type=int, default=50, help='how many test images to run')
|
||||
# rewrite devalue values
|
||||
parser.set_defaults(model='pix2pix4depth')
|
||||
# To avoid cropping, the load_size should be the same as crop_size
|
||||
parser.set_defaults(load_size=parser.get_default('crop_size'))
|
||||
self.isTrain = False
|
||||
return parser
|
||||
@@ -1 +0,0 @@
|
||||
"""This package includes a miscellaneous collection of useful helper functions."""
|
||||
@@ -1,110 +0,0 @@
|
||||
from __future__ import print_function
|
||||
import os
|
||||
import tarfile
|
||||
import requests
|
||||
from warnings import warn
|
||||
from zipfile import ZipFile
|
||||
from bs4 import BeautifulSoup
|
||||
from os.path import abspath, isdir, join, basename
|
||||
|
||||
|
||||
class GetData(object):
|
||||
"""A Python script for downloading CycleGAN or pix2pix datasets.
|
||||
|
||||
Parameters:
|
||||
technique (str) -- One of: 'cyclegan' or 'pix2pix'.
|
||||
verbose (bool) -- If True, print additional information.
|
||||
|
||||
Examples:
|
||||
>>> from util.get_data import GetData
|
||||
>>> gd = GetData(technique='cyclegan')
|
||||
>>> new_data_path = gd.get(save_path='./datasets') # options will be displayed.
|
||||
|
||||
Alternatively, You can use bash scripts: 'scripts/download_pix2pix_model.sh'
|
||||
and 'scripts/download_cyclegan_model.sh'.
|
||||
"""
|
||||
|
||||
def __init__(self, technique='cyclegan', verbose=True):
|
||||
url_dict = {
|
||||
'pix2pix': 'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/',
|
||||
'cyclegan': 'https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets'
|
||||
}
|
||||
self.url = url_dict.get(technique.lower())
|
||||
self._verbose = verbose
|
||||
|
||||
def _print(self, text):
|
||||
if self._verbose:
|
||||
print(text)
|
||||
|
||||
@staticmethod
|
||||
def _get_options(r):
|
||||
soup = BeautifulSoup(r.text, 'lxml')
|
||||
options = [h.text for h in soup.find_all('a', href=True)
|
||||
if h.text.endswith(('.zip', 'tar.gz'))]
|
||||
return options
|
||||
|
||||
def _present_options(self):
|
||||
r = requests.get(self.url)
|
||||
options = self._get_options(r)
|
||||
print('Options:\n')
|
||||
for i, o in enumerate(options):
|
||||
print("{0}: {1}".format(i, o))
|
||||
choice = input("\nPlease enter the number of the "
|
||||
"dataset above you wish to download:")
|
||||
return options[int(choice)]
|
||||
|
||||
def _download_data(self, dataset_url, save_path):
|
||||
if not isdir(save_path):
|
||||
os.makedirs(save_path)
|
||||
|
||||
base = basename(dataset_url)
|
||||
temp_save_path = join(save_path, base)
|
||||
|
||||
with open(temp_save_path, "wb") as f:
|
||||
r = requests.get(dataset_url)
|
||||
f.write(r.content)
|
||||
|
||||
if base.endswith('.tar.gz'):
|
||||
obj = tarfile.open(temp_save_path)
|
||||
elif base.endswith('.zip'):
|
||||
obj = ZipFile(temp_save_path, 'r')
|
||||
else:
|
||||
raise ValueError("Unknown File Type: {0}.".format(base))
|
||||
|
||||
self._print("Unpacking Data...")
|
||||
obj.extractall(save_path)
|
||||
obj.close()
|
||||
os.remove(temp_save_path)
|
||||
|
||||
def get(self, save_path, dataset=None):
|
||||
"""
|
||||
|
||||
Download a dataset.
|
||||
|
||||
Parameters:
|
||||
save_path (str) -- A directory to save the data to.
|
||||
dataset (str) -- (optional). A specific dataset to download.
|
||||
Note: this must include the file extension.
|
||||
If None, options will be presented for you
|
||||
to choose from.
|
||||
|
||||
Returns:
|
||||
save_path_full (str) -- the absolute path to the downloaded data.
|
||||
|
||||
"""
|
||||
if dataset is None:
|
||||
selected_dataset = self._present_options()
|
||||
else:
|
||||
selected_dataset = dataset
|
||||
|
||||
save_path_full = join(save_path, selected_dataset.split('.')[0])
|
||||
|
||||
if isdir(save_path_full):
|
||||
warn("\n'{0}' already exists. Voiding Download.".format(
|
||||
save_path_full))
|
||||
else:
|
||||
self._print('Downloading Data...')
|
||||
url = "{0}/{1}".format(self.url, selected_dataset)
|
||||
self._download_data(url, save_path=save_path)
|
||||
|
||||
return abspath(save_path_full)
|
||||
@@ -1,47 +0,0 @@
|
||||
import numpy as np
|
||||
|
||||
class GuidedFilter():
|
||||
def __init__(self, source, reference, r=64, eps= 0.05**2):
|
||||
self.source = source;
|
||||
self.reference = reference;
|
||||
self.r = r
|
||||
self.eps = eps
|
||||
|
||||
self.smooth = self.guidedfilter(self.source,self.reference,self.r,self.eps)
|
||||
|
||||
def boxfilter(self,img, r):
|
||||
(rows, cols) = img.shape
|
||||
imDst = np.zeros_like(img)
|
||||
|
||||
imCum = np.cumsum(img, 0)
|
||||
imDst[0 : r+1, :] = imCum[r : 2*r+1, :]
|
||||
imDst[r+1 : rows-r, :] = imCum[2*r+1 : rows, :] - imCum[0 : rows-2*r-1, :]
|
||||
imDst[rows-r: rows, :] = np.tile(imCum[rows-1, :], [r, 1]) - imCum[rows-2*r-1 : rows-r-1, :]
|
||||
|
||||
imCum = np.cumsum(imDst, 1)
|
||||
imDst[:, 0 : r+1] = imCum[:, r : 2*r+1]
|
||||
imDst[:, r+1 : cols-r] = imCum[:, 2*r+1 : cols] - imCum[:, 0 : cols-2*r-1]
|
||||
imDst[:, cols-r: cols] = np.tile(imCum[:, cols-1], [r, 1]).T - imCum[:, cols-2*r-1 : cols-r-1]
|
||||
|
||||
return imDst
|
||||
|
||||
def guidedfilter(self,I, p, r, eps):
|
||||
(rows, cols) = I.shape
|
||||
N = self.boxfilter(np.ones([rows, cols]), r)
|
||||
|
||||
meanI = self.boxfilter(I, r) / N
|
||||
meanP = self.boxfilter(p, r) / N
|
||||
meanIp = self.boxfilter(I * p, r) / N
|
||||
covIp = meanIp - meanI * meanP
|
||||
|
||||
meanII = self.boxfilter(I * I, r) / N
|
||||
varI = meanII - meanI * meanI
|
||||
|
||||
a = covIp / (varI + eps)
|
||||
b = meanP - a * meanI
|
||||
|
||||
meanA = self.boxfilter(a, r) / N
|
||||
meanB = self.boxfilter(b, r) / N
|
||||
|
||||
q = meanA * I + meanB
|
||||
return q
|
||||
@@ -1,86 +0,0 @@
|
||||
import dominate
|
||||
from dominate.tags import meta, h3, table, tr, td, p, a, img, br
|
||||
import os
|
||||
|
||||
|
||||
class HTML:
|
||||
"""This HTML class allows us to save images and write texts into a single HTML file.
|
||||
|
||||
It consists of functions such as <add_header> (add a text header to the HTML file),
|
||||
<add_images> (add a row of images to the HTML file), and <save> (save the HTML to the disk).
|
||||
It is based on Python library 'dominate', a Python library for creating and manipulating HTML documents using a DOM API.
|
||||
"""
|
||||
|
||||
def __init__(self, web_dir, title, refresh=0):
|
||||
"""Initialize the HTML classes
|
||||
|
||||
Parameters:
|
||||
web_dir (str) -- a directory that stores the webpage. HTML file will be created at <web_dir>/index.html; images will be saved at <web_dir/images/
|
||||
title (str) -- the webpage name
|
||||
refresh (int) -- how often the website refresh itself; if 0; no refreshing
|
||||
"""
|
||||
self.title = title
|
||||
self.web_dir = web_dir
|
||||
self.img_dir = os.path.join(self.web_dir, 'images')
|
||||
if not os.path.exists(self.web_dir):
|
||||
os.makedirs(self.web_dir)
|
||||
if not os.path.exists(self.img_dir):
|
||||
os.makedirs(self.img_dir)
|
||||
|
||||
self.doc = dominate.document(title=title)
|
||||
if refresh > 0:
|
||||
with self.doc.head:
|
||||
meta(http_equiv="refresh", content=str(refresh))
|
||||
|
||||
def get_image_dir(self):
|
||||
"""Return the directory that stores images"""
|
||||
return self.img_dir
|
||||
|
||||
def add_header(self, text):
|
||||
"""Insert a header to the HTML file
|
||||
|
||||
Parameters:
|
||||
text (str) -- the header text
|
||||
"""
|
||||
with self.doc:
|
||||
h3(text)
|
||||
|
||||
def add_images(self, ims, txts, links, width=400):
|
||||
"""add images to the HTML file
|
||||
|
||||
Parameters:
|
||||
ims (str list) -- a list of image paths
|
||||
txts (str list) -- a list of image names shown on the website
|
||||
links (str list) -- a list of hyperref links; when you click an image, it will redirect you to a new page
|
||||
"""
|
||||
self.t = table(border=1, style="table-layout: fixed;") # Insert a table
|
||||
self.doc.add(self.t)
|
||||
with self.t:
|
||||
with tr():
|
||||
for im, txt, link in zip(ims, txts, links):
|
||||
with td(style="word-wrap: break-word;", halign="center", valign="top"):
|
||||
with p():
|
||||
with a(href=os.path.join('images', link)):
|
||||
img(style="width:%dpx" % width, src=os.path.join('images', im))
|
||||
br()
|
||||
p(txt)
|
||||
|
||||
def save(self):
|
||||
"""save the current content to the HMTL file"""
|
||||
html_file = '%s/index.html' % self.web_dir
|
||||
f = open(html_file, 'wt')
|
||||
f.write(self.doc.render())
|
||||
f.close()
|
||||
|
||||
|
||||
if __name__ == '__main__': # we show an example usage here.
|
||||
html = HTML('web/', 'test_html')
|
||||
html.add_header('hello world')
|
||||
|
||||
ims, txts, links = [], [], []
|
||||
for n in range(4):
|
||||
ims.append('image_%d.png' % n)
|
||||
txts.append('text_%d' % n)
|
||||
links.append('image_%d.png' % n)
|
||||
html.add_images(ims, txts, links)
|
||||
html.save()
|
||||
@@ -1,54 +0,0 @@
|
||||
import random
|
||||
import torch
|
||||
|
||||
|
||||
class ImagePool():
|
||||
"""This class implements an image buffer that stores previously generated images.
|
||||
|
||||
This buffer enables us to update discriminators using a history of generated images
|
||||
rather than the ones produced by the latest generators.
|
||||
"""
|
||||
|
||||
def __init__(self, pool_size):
|
||||
"""Initialize the ImagePool class
|
||||
|
||||
Parameters:
|
||||
pool_size (int) -- the size of image buffer, if pool_size=0, no buffer will be created
|
||||
"""
|
||||
self.pool_size = pool_size
|
||||
if self.pool_size > 0: # create an empty pool
|
||||
self.num_imgs = 0
|
||||
self.images = []
|
||||
|
||||
def query(self, images):
|
||||
"""Return an image from the pool.
|
||||
|
||||
Parameters:
|
||||
images: the latest generated images from the generator
|
||||
|
||||
Returns images from the buffer.
|
||||
|
||||
By 50/100, the buffer will return input images.
|
||||
By 50/100, the buffer will return images previously stored in the buffer,
|
||||
and insert the current images to the buffer.
|
||||
"""
|
||||
if self.pool_size == 0: # if the buffer size is 0, do nothing
|
||||
return images
|
||||
return_images = []
|
||||
for image in images:
|
||||
image = torch.unsqueeze(image.data, 0)
|
||||
if self.num_imgs < self.pool_size: # if the buffer is not full; keep inserting current images to the buffer
|
||||
self.num_imgs = self.num_imgs + 1
|
||||
self.images.append(image)
|
||||
return_images.append(image)
|
||||
else:
|
||||
p = random.uniform(0, 1)
|
||||
if p > 0.5: # by 50% chance, the buffer will return a previously stored image, and insert the current image into the buffer
|
||||
random_id = random.randint(0, self.pool_size - 1) # randint is inclusive
|
||||
tmp = self.images[random_id].clone()
|
||||
self.images[random_id] = image
|
||||
return_images.append(tmp)
|
||||
else: # by another 50% chance, the buffer will return the current image
|
||||
return_images.append(image)
|
||||
return_images = torch.cat(return_images, 0) # collect all the images and return
|
||||
return return_images
|
||||
@@ -1,105 +0,0 @@
|
||||
"""This module contains simple helper functions """
|
||||
from __future__ import print_function
|
||||
import torch
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import os
|
||||
|
||||
|
||||
def tensor2im(input_image, imtype=np.uint16):
|
||||
""""Converts a Tensor array into a numpy image array.
|
||||
|
||||
Parameters:
|
||||
input_image (tensor) -- the input image tensor array
|
||||
imtype (type) -- the desired type of the converted numpy array
|
||||
"""
|
||||
if not isinstance(input_image, np.ndarray):
|
||||
if isinstance(input_image, torch.Tensor): # get the data from a variable
|
||||
image_tensor = input_image.data
|
||||
else:
|
||||
return input_image
|
||||
image_numpy = torch.squeeze(image_tensor).cpu().numpy() # convert it into a numpy array
|
||||
image_numpy = (image_numpy + 1) / 2.0 * (2**16-1) #
|
||||
else: # if it is a numpy array, do nothing
|
||||
image_numpy = input_image
|
||||
return image_numpy.astype(imtype)
|
||||
|
||||
|
||||
def diagnose_network(net, name='network'):
|
||||
"""Calculate and print the mean of average absolute(gradients)
|
||||
|
||||
Parameters:
|
||||
net (torch network) -- Torch network
|
||||
name (str) -- the name of the network
|
||||
"""
|
||||
mean = 0.0
|
||||
count = 0
|
||||
for param in net.parameters():
|
||||
if param.grad is not None:
|
||||
mean += torch.mean(torch.abs(param.grad.data))
|
||||
count += 1
|
||||
if count > 0:
|
||||
mean = mean / count
|
||||
print(name)
|
||||
print(mean)
|
||||
|
||||
|
||||
def save_image(image_numpy, image_path, aspect_ratio=1.0):
|
||||
"""Save a numpy image to the disk
|
||||
|
||||
Parameters:
|
||||
image_numpy (numpy array) -- input numpy array
|
||||
image_path (str) -- the path of the image
|
||||
"""
|
||||
image_pil = Image.fromarray(image_numpy)
|
||||
|
||||
image_pil = image_pil.convert('I;16')
|
||||
|
||||
# image_pil = Image.fromarray(image_numpy)
|
||||
# h, w, _ = image_numpy.shape
|
||||
#
|
||||
# if aspect_ratio > 1.0:
|
||||
# image_pil = image_pil.resize((h, int(w * aspect_ratio)), Image.BICUBIC)
|
||||
# if aspect_ratio < 1.0:
|
||||
# image_pil = image_pil.resize((int(h / aspect_ratio), w), Image.BICUBIC)
|
||||
|
||||
image_pil.save(image_path)
|
||||
|
||||
|
||||
def print_numpy(x, val=True, shp=False):
|
||||
"""Print the mean, min, max, median, std, and size of a numpy array
|
||||
|
||||
Parameters:
|
||||
val (bool) -- if print the values of the numpy array
|
||||
shp (bool) -- if print the shape of the numpy array
|
||||
"""
|
||||
x = x.astype(np.float64)
|
||||
if shp:
|
||||
print('shape,', x.shape)
|
||||
if val:
|
||||
x = x.flatten()
|
||||
print('mean = %3.3f, min = %3.3f, max = %3.3f, median = %3.3f, std=%3.3f' % (
|
||||
np.mean(x), np.min(x), np.max(x), np.median(x), np.std(x)))
|
||||
|
||||
|
||||
def mkdirs(paths):
|
||||
"""create empty directories if they don't exist
|
||||
|
||||
Parameters:
|
||||
paths (str list) -- a list of directory paths
|
||||
"""
|
||||
if isinstance(paths, list) and not isinstance(paths, str):
|
||||
for path in paths:
|
||||
mkdir(path)
|
||||
else:
|
||||
mkdir(paths)
|
||||
|
||||
|
||||
def mkdir(path):
|
||||
"""create a single empty directory if it didn't exist
|
||||
|
||||
Parameters:
|
||||
path (str) -- a single directory path
|
||||
"""
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
@@ -1,166 +0,0 @@
|
||||
import numpy as np
|
||||
import os
|
||||
import sys
|
||||
import ntpath
|
||||
import time
|
||||
from . import util, html
|
||||
from subprocess import Popen, PIPE
|
||||
import torch
|
||||
|
||||
|
||||
if sys.version_info[0] == 2:
|
||||
VisdomExceptionBase = Exception
|
||||
else:
|
||||
VisdomExceptionBase = ConnectionError
|
||||
|
||||
|
||||
def save_images(webpage, visuals, image_path, aspect_ratio=1.0, width=256):
|
||||
"""Save images to the disk.
|
||||
|
||||
Parameters:
|
||||
webpage (the HTML class) -- the HTML webpage class that stores these imaegs (see html.py for more details)
|
||||
visuals (OrderedDict) -- an ordered dictionary that stores (name, images (either tensor or numpy) ) pairs
|
||||
image_path (str) -- the string is used to create image paths
|
||||
aspect_ratio (float) -- the aspect ratio of saved images
|
||||
width (int) -- the images will be resized to width x width
|
||||
|
||||
This function will save images stored in 'visuals' to the HTML file specified by 'webpage'.
|
||||
"""
|
||||
image_dir = webpage.get_image_dir()
|
||||
short_path = ntpath.basename(image_path[0])
|
||||
name = os.path.splitext(short_path)[0]
|
||||
|
||||
webpage.add_header(name)
|
||||
ims, txts, links = [], [], []
|
||||
|
||||
for label, im_data in visuals.items():
|
||||
im = util.tensor2im(im_data)
|
||||
image_name = '%s_%s.png' % (name, label)
|
||||
save_path = os.path.join(image_dir, image_name)
|
||||
util.save_image(im, save_path, aspect_ratio=aspect_ratio)
|
||||
ims.append(image_name)
|
||||
txts.append(label)
|
||||
links.append(image_name)
|
||||
webpage.add_images(ims, txts, links, width=width)
|
||||
|
||||
|
||||
class Visualizer():
|
||||
"""This class includes several functions that can display/save images and print/save logging information.
|
||||
|
||||
It uses a Python library 'visdom' for display, and a Python library 'dominate' (wrapped in 'HTML') for creating HTML files with images.
|
||||
"""
|
||||
|
||||
def __init__(self, opt):
|
||||
"""Initialize the Visualizer class
|
||||
|
||||
Parameters:
|
||||
opt -- stores all the experiment flags; needs to be a subclass of BaseOptions
|
||||
Step 1: Cache the training/test options
|
||||
Step 2: connect to a visdom server
|
||||
Step 3: create an HTML object for saveing HTML filters
|
||||
Step 4: create a logging file to store training losses
|
||||
"""
|
||||
self.opt = opt # cache the option
|
||||
self.display_id = opt.display_id
|
||||
self.use_html = opt.isTrain and not opt.no_html
|
||||
self.win_size = opt.display_winsize
|
||||
self.name = opt.name
|
||||
self.port = opt.display_port
|
||||
self.saved = False
|
||||
|
||||
if self.use_html: # create an HTML object at <checkpoints_dir>/web/; images will be saved under <checkpoints_dir>/web/images/
|
||||
self.web_dir = os.path.join(opt.checkpoints_dir, opt.name, 'web')
|
||||
self.img_dir = os.path.join(self.web_dir, 'images')
|
||||
print('create web directory %s...' % self.web_dir)
|
||||
util.mkdirs([self.web_dir, self.img_dir])
|
||||
# create a logging file to store training losses
|
||||
self.log_name = os.path.join(opt.checkpoints_dir, opt.name, 'loss_log.txt')
|
||||
with open(self.log_name, "a") as log_file:
|
||||
now = time.strftime("%c")
|
||||
log_file.write('================ Training Loss (%s) ================\n' % now)
|
||||
|
||||
def reset(self):
|
||||
"""Reset the self.saved status"""
|
||||
self.saved = False
|
||||
|
||||
def create_visdom_connections(self):
|
||||
"""If the program could not connect to Visdom server, this function will start a new server at port < self.port > """
|
||||
cmd = sys.executable + ' -m visdom.server -p %d &>/dev/null &' % self.port
|
||||
print('\n\nCould not connect to Visdom server. \n Trying to start a server....')
|
||||
print('Command: %s' % cmd)
|
||||
Popen(cmd, shell=True, stdout=PIPE, stderr=PIPE)
|
||||
|
||||
def display_current_results(self, visuals, epoch, save_result):
|
||||
"""Display current results on visdom; save current results to an HTML file.
|
||||
|
||||
Parameters:
|
||||
visuals (OrderedDict) - - dictionary of images to display or save
|
||||
epoch (int) - - the current epoch
|
||||
save_result (bool) - - if save the current results to an HTML file
|
||||
"""
|
||||
if self.use_html and (save_result or not self.saved): # save images to an HTML file if they haven't been saved.
|
||||
self.saved = True
|
||||
# save images to the disk
|
||||
for label, image in visuals.items():
|
||||
image_numpy = util.tensor2im(image)
|
||||
img_path = os.path.join(self.img_dir, 'epoch%.3d_%s.png' % (epoch, label))
|
||||
util.save_image(image_numpy, img_path)
|
||||
|
||||
# update website
|
||||
webpage = html.HTML(self.web_dir, 'Experiment name = %s' % self.name, refresh=1)
|
||||
for n in range(epoch, 0, -1):
|
||||
webpage.add_header('epoch [%d]' % n)
|
||||
ims, txts, links = [], [], []
|
||||
|
||||
for label, image_numpy in visuals.items():
|
||||
# image_numpy = util.tensor2im(image)
|
||||
img_path = 'epoch%.3d_%s.png' % (n, label)
|
||||
ims.append(img_path)
|
||||
txts.append(label)
|
||||
links.append(img_path)
|
||||
webpage.add_images(ims, txts, links, width=self.win_size)
|
||||
webpage.save()
|
||||
|
||||
# def plot_current_losses(self, epoch, counter_ratio, losses):
|
||||
# """display the current losses on visdom display: dictionary of error labels and values
|
||||
#
|
||||
# Parameters:
|
||||
# epoch (int) -- current epoch
|
||||
# counter_ratio (float) -- progress (percentage) in the current epoch, between 0 to 1
|
||||
# losses (OrderedDict) -- training losses stored in the format of (name, float) pairs
|
||||
# """
|
||||
# if not hasattr(self, 'plot_data'):
|
||||
# self.plot_data = {'X': [], 'Y': [], 'legend': list(losses.keys())}
|
||||
# self.plot_data['X'].append(epoch + counter_ratio)
|
||||
# self.plot_data['Y'].append([losses[k] for k in self.plot_data['legend']])
|
||||
# try:
|
||||
# self.vis.line(
|
||||
# X=np.stack([np.array(self.plot_data['X'])] * len(self.plot_data['legend']), 1),
|
||||
# Y=np.array(self.plot_data['Y']),
|
||||
# opts={
|
||||
# 'title': self.name + ' loss over time',
|
||||
# 'legend': self.plot_data['legend'],
|
||||
# 'xlabel': 'epoch',
|
||||
# 'ylabel': 'loss'},
|
||||
# win=self.display_id)
|
||||
# except VisdomExceptionBase:
|
||||
# self.create_visdom_connections()
|
||||
|
||||
# losses: same format as |losses| of plot_current_losses
|
||||
def print_current_losses(self, epoch, iters, losses, t_comp, t_data):
|
||||
"""print current losses on console; also save the losses to the disk
|
||||
|
||||
Parameters:
|
||||
epoch (int) -- current epoch
|
||||
iters (int) -- current training iteration during this epoch (reset to 0 at the end of every epoch)
|
||||
losses (OrderedDict) -- training losses stored in the format of (name, float) pairs
|
||||
t_comp (float) -- computational time per data point (normalized by batch_size)
|
||||
t_data (float) -- data loading time per data point (normalized by batch_size)
|
||||
"""
|
||||
message = '(epoch: %d, iters: %d, time: %.3f, data: %.3f) ' % (epoch, iters, t_comp, t_data)
|
||||
for k, v in losses.items():
|
||||
message += '%s: %.3f ' % (k, v)
|
||||
|
||||
print(message) # print the message
|
||||
with open(self.log_name, "a") as log_file:
|
||||
log_file.write('%s\n' % message) # save the message
|
||||
@@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2022 Caroline Chan
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -1,133 +0,0 @@
|
||||
import os
|
||||
import cv2
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
|
||||
|
||||
norm_layer = nn.InstanceNorm2d
|
||||
|
||||
|
||||
class ResidualBlock(nn.Module):
|
||||
def __init__(self, in_features):
|
||||
super(ResidualBlock, self).__init__()
|
||||
|
||||
conv_block = [ nn.ReflectionPad2d(1),
|
||||
nn.Conv2d(in_features, in_features, 3),
|
||||
norm_layer(in_features),
|
||||
nn.ReLU(inplace=True),
|
||||
nn.ReflectionPad2d(1),
|
||||
nn.Conv2d(in_features, in_features, 3),
|
||||
norm_layer(in_features)
|
||||
]
|
||||
|
||||
self.conv_block = nn.Sequential(*conv_block)
|
||||
|
||||
def forward(self, x):
|
||||
return x + self.conv_block(x)
|
||||
|
||||
|
||||
class Generator(nn.Module):
|
||||
def __init__(self, input_nc, output_nc, n_residual_blocks=9, sigmoid=True):
|
||||
super(Generator, self).__init__()
|
||||
|
||||
# Initial convolution block
|
||||
model0 = [ nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(input_nc, 64, 7),
|
||||
norm_layer(64),
|
||||
nn.ReLU(inplace=True) ]
|
||||
self.model0 = nn.Sequential(*model0)
|
||||
|
||||
# Downsampling
|
||||
model1 = []
|
||||
in_features = 64
|
||||
out_features = in_features*2
|
||||
for _ in range(2):
|
||||
model1 += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
|
||||
norm_layer(out_features),
|
||||
nn.ReLU(inplace=True) ]
|
||||
in_features = out_features
|
||||
out_features = in_features*2
|
||||
self.model1 = nn.Sequential(*model1)
|
||||
|
||||
model2 = []
|
||||
# Residual blocks
|
||||
for _ in range(n_residual_blocks):
|
||||
model2 += [ResidualBlock(in_features)]
|
||||
self.model2 = nn.Sequential(*model2)
|
||||
|
||||
# Upsampling
|
||||
model3 = []
|
||||
out_features = in_features//2
|
||||
for _ in range(2):
|
||||
model3 += [ nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1),
|
||||
norm_layer(out_features),
|
||||
nn.ReLU(inplace=True) ]
|
||||
in_features = out_features
|
||||
out_features = in_features//2
|
||||
self.model3 = nn.Sequential(*model3)
|
||||
|
||||
# Output layer
|
||||
model4 = [ nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(64, output_nc, 7)]
|
||||
if sigmoid:
|
||||
model4 += [nn.Sigmoid()]
|
||||
|
||||
self.model4 = nn.Sequential(*model4)
|
||||
|
||||
def forward(self, x, cond=None):
|
||||
out = self.model0(x)
|
||||
out = self.model1(out)
|
||||
out = self.model2(out)
|
||||
out = self.model3(out)
|
||||
out = self.model4(out)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class LineartDetector:
|
||||
model_dir = os.path.join(models_path, "lineart")
|
||||
model_default = 'sk_model.pth'
|
||||
model_coarse = 'sk_model2.pth'
|
||||
|
||||
def __init__(self, model_name):
|
||||
self.model = None
|
||||
self.model_name = model_name
|
||||
self.device = devices.get_device_for("controlnet")
|
||||
|
||||
def load_model(self, name):
|
||||
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/" + name
|
||||
model_path = os.path.join(self.model_dir, name)
|
||||
if not os.path.exists(model_path):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=self.model_dir)
|
||||
model = Generator(3, 1, 3)
|
||||
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
|
||||
model.eval()
|
||||
self.model = model.to(self.device)
|
||||
|
||||
def unload_model(self):
|
||||
if self.model is not None:
|
||||
self.model.cpu()
|
||||
|
||||
def __call__(self, input_image):
|
||||
if self.model is None:
|
||||
self.load_model(self.model_name)
|
||||
self.model.to(self.device)
|
||||
|
||||
assert input_image.ndim == 3
|
||||
image = input_image
|
||||
with torch.no_grad():
|
||||
image = torch.from_numpy(image).float().to(self.device)
|
||||
image = image / 255.0
|
||||
image = rearrange(image, 'h w c -> 1 c h w')
|
||||
line = self.model(image)[0][0]
|
||||
|
||||
line = line.cpu().numpy()
|
||||
line = (line * 255.0).clip(0, 255).astype(np.uint8)
|
||||
|
||||
return line
|
||||
@@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2022 Caroline Chan
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -1,161 +0,0 @@
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import functools
|
||||
|
||||
import os
|
||||
import cv2
|
||||
from einops import rearrange
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
|
||||
|
||||
class UnetGenerator(nn.Module):
|
||||
"""Create a Unet-based generator"""
|
||||
|
||||
def __init__(self, input_nc, output_nc, num_downs, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False):
|
||||
"""Construct a Unet generator
|
||||
Parameters:
|
||||
input_nc (int) -- the number of channels in input images
|
||||
output_nc (int) -- the number of channels in output images
|
||||
num_downs (int) -- the number of downsamplings in UNet. For example, # if |num_downs| == 7,
|
||||
image of size 128x128 will become of size 1x1 # at the bottleneck
|
||||
ngf (int) -- the number of filters in the last conv layer
|
||||
norm_layer -- normalization layer
|
||||
We construct the U-Net from the innermost layer to the outermost layer.
|
||||
It is a recursive process.
|
||||
"""
|
||||
super(UnetGenerator, self).__init__()
|
||||
# construct unet structure
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=None, norm_layer=norm_layer, innermost=True) # add the innermost layer
|
||||
for _ in range(num_downs - 5): # add intermediate layers with ngf * 8 filters
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer, use_dropout=use_dropout)
|
||||
# gradually reduce the number of filters from ngf * 8 to ngf
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 4, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
||||
unet_block = UnetSkipConnectionBlock(ngf * 2, ngf * 4, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
||||
unet_block = UnetSkipConnectionBlock(ngf, ngf * 2, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
|
||||
self.model = UnetSkipConnectionBlock(output_nc, ngf, input_nc=input_nc, submodule=unet_block, outermost=True, norm_layer=norm_layer) # add the outermost layer
|
||||
|
||||
def forward(self, input):
|
||||
"""Standard forward"""
|
||||
return self.model(input)
|
||||
|
||||
|
||||
class UnetSkipConnectionBlock(nn.Module):
|
||||
"""Defines the Unet submodule with skip connection.
|
||||
X -------------------identity----------------------
|
||||
|-- downsampling -- |submodule| -- upsampling --|
|
||||
"""
|
||||
|
||||
def __init__(self, outer_nc, inner_nc, input_nc=None,
|
||||
submodule=None, outermost=False, innermost=False, norm_layer=nn.BatchNorm2d, use_dropout=False):
|
||||
"""Construct a Unet submodule with skip connections.
|
||||
Parameters:
|
||||
outer_nc (int) -- the number of filters in the outer conv layer
|
||||
inner_nc (int) -- the number of filters in the inner conv layer
|
||||
input_nc (int) -- the number of channels in input images/features
|
||||
submodule (UnetSkipConnectionBlock) -- previously defined submodules
|
||||
outermost (bool) -- if this module is the outermost module
|
||||
innermost (bool) -- if this module is the innermost module
|
||||
norm_layer -- normalization layer
|
||||
use_dropout (bool) -- if use dropout layers.
|
||||
"""
|
||||
super(UnetSkipConnectionBlock, self).__init__()
|
||||
self.outermost = outermost
|
||||
if type(norm_layer) == functools.partial:
|
||||
use_bias = norm_layer.func == nn.InstanceNorm2d
|
||||
else:
|
||||
use_bias = norm_layer == nn.InstanceNorm2d
|
||||
if input_nc is None:
|
||||
input_nc = outer_nc
|
||||
downconv = nn.Conv2d(input_nc, inner_nc, kernel_size=4,
|
||||
stride=2, padding=1, bias=use_bias)
|
||||
downrelu = nn.LeakyReLU(0.2, True)
|
||||
downnorm = norm_layer(inner_nc)
|
||||
uprelu = nn.ReLU(True)
|
||||
upnorm = norm_layer(outer_nc)
|
||||
|
||||
if outermost:
|
||||
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
|
||||
kernel_size=4, stride=2,
|
||||
padding=1)
|
||||
down = [downconv]
|
||||
up = [uprelu, upconv, nn.Tanh()]
|
||||
model = down + [submodule] + up
|
||||
elif innermost:
|
||||
upconv = nn.ConvTranspose2d(inner_nc, outer_nc,
|
||||
kernel_size=4, stride=2,
|
||||
padding=1, bias=use_bias)
|
||||
down = [downrelu, downconv]
|
||||
up = [uprelu, upconv, upnorm]
|
||||
model = down + up
|
||||
else:
|
||||
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
|
||||
kernel_size=4, stride=2,
|
||||
padding=1, bias=use_bias)
|
||||
down = [downrelu, downconv, downnorm]
|
||||
up = [uprelu, upconv, upnorm]
|
||||
|
||||
if use_dropout:
|
||||
model = down + [submodule] + up + [nn.Dropout(0.5)]
|
||||
else:
|
||||
model = down + [submodule] + up
|
||||
|
||||
self.model = nn.Sequential(*model)
|
||||
|
||||
def forward(self, x):
|
||||
if self.outermost:
|
||||
return self.model(x)
|
||||
else: # add skip connections
|
||||
return torch.cat([x, self.model(x)], 1)
|
||||
|
||||
|
||||
class LineartAnimeDetector:
|
||||
model_dir = os.path.join(models_path, "lineart_anime")
|
||||
|
||||
def __init__(self):
|
||||
self.model = None
|
||||
self.device = devices.get_device_for("controlnet")
|
||||
|
||||
def load_model(self):
|
||||
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/netG.pth"
|
||||
modelpath = os.path.join(self.model_dir, "netG.pth")
|
||||
if not os.path.exists(modelpath):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=self.model_dir)
|
||||
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
|
||||
net = UnetGenerator(3, 1, 8, 64, norm_layer=norm_layer, use_dropout=False)
|
||||
ckpt = torch.load(modelpath)
|
||||
for key in list(ckpt.keys()):
|
||||
if 'module.' in key:
|
||||
ckpt[key.replace('module.', '')] = ckpt[key]
|
||||
del ckpt[key]
|
||||
net.load_state_dict(ckpt)
|
||||
net.eval()
|
||||
self.model = net.to(self.device)
|
||||
|
||||
def unload_model(self):
|
||||
if self.model is not None:
|
||||
self.model.cpu()
|
||||
|
||||
def __call__(self, input_image):
|
||||
if self.model is None:
|
||||
self.load_model()
|
||||
self.model.to(self.device)
|
||||
|
||||
H, W, C = input_image.shape
|
||||
Hn = 256 * int(np.ceil(float(H) / 256.0))
|
||||
Wn = 256 * int(np.ceil(float(W) / 256.0))
|
||||
img = cv2.resize(input_image, (Wn, Hn), interpolation=cv2.INTER_CUBIC)
|
||||
with torch.no_grad():
|
||||
image_feed = torch.from_numpy(img).float().to(self.device)
|
||||
image_feed = image_feed / 127.5 - 1.0
|
||||
image_feed = rearrange(image_feed, 'h w c -> 1 c h w')
|
||||
|
||||
line = self.model(image_feed)[0, 0] * 127.5 + 127.5
|
||||
line = line.cpu().numpy()
|
||||
|
||||
line = cv2.resize(line, (W, H), interpolation=cv2.INTER_CUBIC)
|
||||
line = line.clip(0, 255).astype(np.uint8)
|
||||
return line
|
||||
|
||||
@@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2021 Miaomiao Li
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -1,248 +0,0 @@
|
||||
import os
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from PIL import Image
|
||||
import fnmatch
|
||||
import cv2
|
||||
|
||||
import sys
|
||||
|
||||
import numpy as np
|
||||
from einops import rearrange
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
|
||||
|
||||
class _bn_relu_conv(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, fw, fh, subsample=1):
|
||||
super(_bn_relu_conv, self).__init__()
|
||||
self.model = nn.Sequential(
|
||||
nn.BatchNorm2d(in_filters, eps=1e-3),
|
||||
nn.LeakyReLU(0.2),
|
||||
nn.Conv2d(in_filters, nb_filters, (fw, fh), stride=subsample, padding=(fw//2, fh//2), padding_mode='zeros')
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
return self.model(x)
|
||||
|
||||
# the following are for debugs
|
||||
print("****", np.max(x.cpu().numpy()), np.min(x.cpu().numpy()), np.mean(x.cpu().numpy()), np.std(x.cpu().numpy()), x.shape)
|
||||
for i,layer in enumerate(self.model):
|
||||
if i != 2:
|
||||
x = layer(x)
|
||||
else:
|
||||
x = layer(x)
|
||||
#x = nn.functional.pad(x, (1, 1, 1, 1), mode='constant', value=0)
|
||||
print("____", np.max(x.cpu().numpy()), np.min(x.cpu().numpy()), np.mean(x.cpu().numpy()), np.std(x.cpu().numpy()), x.shape)
|
||||
print(x[0])
|
||||
return x
|
||||
|
||||
class _u_bn_relu_conv(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, fw, fh, subsample=1):
|
||||
super(_u_bn_relu_conv, self).__init__()
|
||||
self.model = nn.Sequential(
|
||||
nn.BatchNorm2d(in_filters, eps=1e-3),
|
||||
nn.LeakyReLU(0.2),
|
||||
nn.Conv2d(in_filters, nb_filters, (fw, fh), stride=subsample, padding=(fw//2, fh//2)),
|
||||
nn.Upsample(scale_factor=2, mode='nearest')
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
return self.model(x)
|
||||
|
||||
|
||||
|
||||
class _shortcut(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, subsample=1):
|
||||
super(_shortcut, self).__init__()
|
||||
self.process = False
|
||||
self.model = None
|
||||
if in_filters != nb_filters or subsample != 1:
|
||||
self.process = True
|
||||
self.model = nn.Sequential(
|
||||
nn.Conv2d(in_filters, nb_filters, (1, 1), stride=subsample)
|
||||
)
|
||||
|
||||
def forward(self, x, y):
|
||||
#print(x.size(), y.size(), self.process)
|
||||
if self.process:
|
||||
y0 = self.model(x)
|
||||
#print("merge+", torch.max(y0+y), torch.min(y0+y),torch.mean(y0+y), torch.std(y0+y), y0.shape)
|
||||
return y0 + y
|
||||
else:
|
||||
#print("merge", torch.max(x+y), torch.min(x+y),torch.mean(x+y), torch.std(x+y), y.shape)
|
||||
return x + y
|
||||
|
||||
class _u_shortcut(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, subsample):
|
||||
super(_u_shortcut, self).__init__()
|
||||
self.process = False
|
||||
self.model = None
|
||||
if in_filters != nb_filters:
|
||||
self.process = True
|
||||
self.model = nn.Sequential(
|
||||
nn.Conv2d(in_filters, nb_filters, (1, 1), stride=subsample, padding_mode='zeros'),
|
||||
nn.Upsample(scale_factor=2, mode='nearest')
|
||||
)
|
||||
|
||||
def forward(self, x, y):
|
||||
if self.process:
|
||||
return self.model(x) + y
|
||||
else:
|
||||
return x + y
|
||||
|
||||
|
||||
class basic_block(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, init_subsample=1):
|
||||
super(basic_block, self).__init__()
|
||||
self.conv1 = _bn_relu_conv(in_filters, nb_filters, 3, 3, subsample=init_subsample)
|
||||
self.residual = _bn_relu_conv(nb_filters, nb_filters, 3, 3)
|
||||
self.shortcut = _shortcut(in_filters, nb_filters, subsample=init_subsample)
|
||||
|
||||
def forward(self, x):
|
||||
x1 = self.conv1(x)
|
||||
x2 = self.residual(x1)
|
||||
return self.shortcut(x, x2)
|
||||
|
||||
class _u_basic_block(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, init_subsample=1):
|
||||
super(_u_basic_block, self).__init__()
|
||||
self.conv1 = _u_bn_relu_conv(in_filters, nb_filters, 3, 3, subsample=init_subsample)
|
||||
self.residual = _bn_relu_conv(nb_filters, nb_filters, 3, 3)
|
||||
self.shortcut = _u_shortcut(in_filters, nb_filters, subsample=init_subsample)
|
||||
|
||||
def forward(self, x):
|
||||
y = self.residual(self.conv1(x))
|
||||
return self.shortcut(x, y)
|
||||
|
||||
|
||||
class _residual_block(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, repetitions, is_first_layer=False):
|
||||
super(_residual_block, self).__init__()
|
||||
layers = []
|
||||
for i in range(repetitions):
|
||||
init_subsample = 1
|
||||
if i == repetitions - 1 and not is_first_layer:
|
||||
init_subsample = 2
|
||||
if i == 0:
|
||||
l = basic_block(in_filters=in_filters, nb_filters=nb_filters, init_subsample=init_subsample)
|
||||
else:
|
||||
l = basic_block(in_filters=nb_filters, nb_filters=nb_filters, init_subsample=init_subsample)
|
||||
layers.append(l)
|
||||
|
||||
self.model = nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
return self.model(x)
|
||||
|
||||
|
||||
class _upsampling_residual_block(nn.Module):
|
||||
def __init__(self, in_filters, nb_filters, repetitions):
|
||||
super(_upsampling_residual_block, self).__init__()
|
||||
layers = []
|
||||
for i in range(repetitions):
|
||||
l = None
|
||||
if i == 0:
|
||||
l = _u_basic_block(in_filters=in_filters, nb_filters=nb_filters)#(input)
|
||||
else:
|
||||
l = basic_block(in_filters=nb_filters, nb_filters=nb_filters)#(input)
|
||||
layers.append(l)
|
||||
|
||||
self.model = nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
return self.model(x)
|
||||
|
||||
|
||||
class res_skip(nn.Module):
|
||||
|
||||
def __init__(self):
|
||||
super(res_skip, self).__init__()
|
||||
self.block0 = _residual_block(in_filters=1, nb_filters=24, repetitions=2, is_first_layer=True)#(input)
|
||||
self.block1 = _residual_block(in_filters=24, nb_filters=48, repetitions=3)#(block0)
|
||||
self.block2 = _residual_block(in_filters=48, nb_filters=96, repetitions=5)#(block1)
|
||||
self.block3 = _residual_block(in_filters=96, nb_filters=192, repetitions=7)#(block2)
|
||||
self.block4 = _residual_block(in_filters=192, nb_filters=384, repetitions=12)#(block3)
|
||||
|
||||
self.block5 = _upsampling_residual_block(in_filters=384, nb_filters=192, repetitions=7)#(block4)
|
||||
self.res1 = _shortcut(in_filters=192, nb_filters=192)#(block3, block5, subsample=(1,1))
|
||||
|
||||
self.block6 = _upsampling_residual_block(in_filters=192, nb_filters=96, repetitions=5)#(res1)
|
||||
self.res2 = _shortcut(in_filters=96, nb_filters=96)#(block2, block6, subsample=(1,1))
|
||||
|
||||
self.block7 = _upsampling_residual_block(in_filters=96, nb_filters=48, repetitions=3)#(res2)
|
||||
self.res3 = _shortcut(in_filters=48, nb_filters=48)#(block1, block7, subsample=(1,1))
|
||||
|
||||
self.block8 = _upsampling_residual_block(in_filters=48, nb_filters=24, repetitions=2)#(res3)
|
||||
self.res4 = _shortcut(in_filters=24, nb_filters=24)#(block0,block8, subsample=(1,1))
|
||||
|
||||
self.block9 = _residual_block(in_filters=24, nb_filters=16, repetitions=2, is_first_layer=True)#(res4)
|
||||
self.conv15 = _bn_relu_conv(in_filters=16, nb_filters=1, fh=1, fw=1, subsample=1)#(block7)
|
||||
|
||||
def forward(self, x):
|
||||
x0 = self.block0(x)
|
||||
x1 = self.block1(x0)
|
||||
x2 = self.block2(x1)
|
||||
x3 = self.block3(x2)
|
||||
x4 = self.block4(x3)
|
||||
|
||||
x5 = self.block5(x4)
|
||||
res1 = self.res1(x3, x5)
|
||||
|
||||
x6 = self.block6(res1)
|
||||
res2 = self.res2(x2, x6)
|
||||
|
||||
x7 = self.block7(res2)
|
||||
res3 = self.res3(x1, x7)
|
||||
|
||||
x8 = self.block8(res3)
|
||||
res4 = self.res4(x0, x8)
|
||||
|
||||
x9 = self.block9(res4)
|
||||
y = self.conv15(x9)
|
||||
|
||||
return y
|
||||
|
||||
|
||||
class MangaLineExtration:
|
||||
model_dir = os.path.join(models_path, "manga_line")
|
||||
|
||||
def __init__(self):
|
||||
self.model = None
|
||||
self.device = devices.get_device_for("controlnet")
|
||||
|
||||
def load_model(self):
|
||||
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/erika.pth"
|
||||
modelpath = os.path.join(self.model_dir, "erika.pth")
|
||||
if not os.path.exists(modelpath):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=self.model_dir)
|
||||
#norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
|
||||
net = res_skip()
|
||||
ckpt = torch.load(modelpath)
|
||||
for key in list(ckpt.keys()):
|
||||
if 'module.' in key:
|
||||
ckpt[key.replace('module.', '')] = ckpt[key]
|
||||
del ckpt[key]
|
||||
net.load_state_dict(ckpt)
|
||||
net.eval()
|
||||
self.model = net.to(self.device)
|
||||
|
||||
def unload_model(self):
|
||||
if self.model is not None:
|
||||
self.model.cpu()
|
||||
|
||||
def __call__(self, input_image):
|
||||
if self.model is None:
|
||||
self.load_model()
|
||||
self.model.to(self.device)
|
||||
img = cv2.cvtColor(input_image, cv2.COLOR_RGB2GRAY)
|
||||
img = np.ascontiguousarray(img.copy()).copy()
|
||||
with torch.no_grad():
|
||||
image_feed = torch.from_numpy(img).float().to(self.device)
|
||||
image_feed = rearrange(image_feed, 'h w -> 1 1 h w')
|
||||
line = self.model(image_feed)
|
||||
line = 255 - line.cpu().numpy()[0, 0]
|
||||
return line.clip(0, 255).astype(np.uint8)
|
||||
|
||||
|
||||
@@ -1,5 +0,0 @@
|
||||
from .mediapipe_face_common import generate_annotation
|
||||
|
||||
|
||||
def apply_mediapipe_face(image, max_faces: int = 1, min_confidence: float = 0.5):
|
||||
return generate_annotation(image, max_faces, min_confidence)
|
||||
@@ -1,155 +0,0 @@
|
||||
from typing import Mapping
|
||||
|
||||
import mediapipe as mp
|
||||
import numpy
|
||||
|
||||
|
||||
mp_drawing = mp.solutions.drawing_utils
|
||||
mp_drawing_styles = mp.solutions.drawing_styles
|
||||
mp_face_detection = mp.solutions.face_detection # Only for counting faces.
|
||||
mp_face_mesh = mp.solutions.face_mesh
|
||||
mp_face_connections = mp.solutions.face_mesh_connections.FACEMESH_TESSELATION
|
||||
mp_hand_connections = mp.solutions.hands_connections.HAND_CONNECTIONS
|
||||
mp_body_connections = mp.solutions.pose_connections.POSE_CONNECTIONS
|
||||
|
||||
DrawingSpec = mp.solutions.drawing_styles.DrawingSpec
|
||||
PoseLandmark = mp.solutions.drawing_styles.PoseLandmark
|
||||
|
||||
min_face_size_pixels: int = 64
|
||||
f_thick = 2
|
||||
f_rad = 1
|
||||
right_iris_draw = DrawingSpec(color=(10, 200, 250), thickness=f_thick, circle_radius=f_rad)
|
||||
right_eye_draw = DrawingSpec(color=(10, 200, 180), thickness=f_thick, circle_radius=f_rad)
|
||||
right_eyebrow_draw = DrawingSpec(color=(10, 220, 180), thickness=f_thick, circle_radius=f_rad)
|
||||
left_iris_draw = DrawingSpec(color=(250, 200, 10), thickness=f_thick, circle_radius=f_rad)
|
||||
left_eye_draw = DrawingSpec(color=(180, 200, 10), thickness=f_thick, circle_radius=f_rad)
|
||||
left_eyebrow_draw = DrawingSpec(color=(180, 220, 10), thickness=f_thick, circle_radius=f_rad)
|
||||
mouth_draw = DrawingSpec(color=(10, 180, 10), thickness=f_thick, circle_radius=f_rad)
|
||||
head_draw = DrawingSpec(color=(10, 200, 10), thickness=f_thick, circle_radius=f_rad)
|
||||
|
||||
# mp_face_mesh.FACEMESH_CONTOURS has all the items we care about.
|
||||
face_connection_spec = {}
|
||||
for edge in mp_face_mesh.FACEMESH_FACE_OVAL:
|
||||
face_connection_spec[edge] = head_draw
|
||||
for edge in mp_face_mesh.FACEMESH_LEFT_EYE:
|
||||
face_connection_spec[edge] = left_eye_draw
|
||||
for edge in mp_face_mesh.FACEMESH_LEFT_EYEBROW:
|
||||
face_connection_spec[edge] = left_eyebrow_draw
|
||||
# for edge in mp_face_mesh.FACEMESH_LEFT_IRIS:
|
||||
# face_connection_spec[edge] = left_iris_draw
|
||||
for edge in mp_face_mesh.FACEMESH_RIGHT_EYE:
|
||||
face_connection_spec[edge] = right_eye_draw
|
||||
for edge in mp_face_mesh.FACEMESH_RIGHT_EYEBROW:
|
||||
face_connection_spec[edge] = right_eyebrow_draw
|
||||
# for edge in mp_face_mesh.FACEMESH_RIGHT_IRIS:
|
||||
# face_connection_spec[edge] = right_iris_draw
|
||||
for edge in mp_face_mesh.FACEMESH_LIPS:
|
||||
face_connection_spec[edge] = mouth_draw
|
||||
iris_landmark_spec = {468: right_iris_draw, 473: left_iris_draw}
|
||||
|
||||
|
||||
def draw_pupils(image, landmark_list, drawing_spec, halfwidth: int = 2):
|
||||
"""We have a custom function to draw the pupils because the mp.draw_landmarks method requires a parameter for all
|
||||
landmarks. Until our PR is merged into mediapipe, we need this separate method."""
|
||||
if len(image.shape) != 3:
|
||||
raise ValueError("Input image must be H,W,C.")
|
||||
image_rows, image_cols, image_channels = image.shape
|
||||
if image_channels != 3: # BGR channels
|
||||
raise ValueError('Input image must contain three channel bgr data.')
|
||||
for idx, landmark in enumerate(landmark_list.landmark):
|
||||
if (
|
||||
(landmark.HasField('visibility') and landmark.visibility < 0.9) or
|
||||
(landmark.HasField('presence') and landmark.presence < 0.5)
|
||||
):
|
||||
continue
|
||||
if landmark.x >= 1.0 or landmark.x < 0 or landmark.y >= 1.0 or landmark.y < 0:
|
||||
continue
|
||||
image_x = int(image_cols*landmark.x)
|
||||
image_y = int(image_rows*landmark.y)
|
||||
draw_color = None
|
||||
if isinstance(drawing_spec, Mapping):
|
||||
if drawing_spec.get(idx) is None:
|
||||
continue
|
||||
else:
|
||||
draw_color = drawing_spec[idx].color
|
||||
elif isinstance(drawing_spec, DrawingSpec):
|
||||
draw_color = drawing_spec.color
|
||||
image[image_y-halfwidth:image_y+halfwidth, image_x-halfwidth:image_x+halfwidth, :] = draw_color
|
||||
|
||||
|
||||
def reverse_channels(image):
|
||||
"""Given a numpy array in RGB form, convert to BGR. Will also convert from BGR to RGB."""
|
||||
# im[:,:,::-1] is a neat hack to convert BGR to RGB by reversing the indexing order.
|
||||
# im[:,:,::[2,1,0]] would also work but makes a copy of the data.
|
||||
return image[:, :, ::-1]
|
||||
|
||||
|
||||
def generate_annotation(
|
||||
img_rgb,
|
||||
max_faces: int,
|
||||
min_confidence: float
|
||||
):
|
||||
"""
|
||||
Find up to 'max_faces' inside the provided input image.
|
||||
If min_face_size_pixels is provided and nonzero it will be used to filter faces that occupy less than this many
|
||||
pixels in the image.
|
||||
"""
|
||||
with mp_face_mesh.FaceMesh(
|
||||
static_image_mode=True,
|
||||
max_num_faces=max_faces,
|
||||
refine_landmarks=True,
|
||||
min_detection_confidence=min_confidence,
|
||||
) as facemesh:
|
||||
img_height, img_width, img_channels = img_rgb.shape
|
||||
assert(img_channels == 3)
|
||||
|
||||
results = facemesh.process(img_rgb).multi_face_landmarks
|
||||
|
||||
if results is None:
|
||||
print("No faces detected in controlnet image for Mediapipe face annotator.")
|
||||
return numpy.zeros_like(img_rgb)
|
||||
|
||||
# Filter faces that are too small
|
||||
filtered_landmarks = []
|
||||
for lm in results:
|
||||
landmarks = lm.landmark
|
||||
face_rect = [
|
||||
landmarks[0].x,
|
||||
landmarks[0].y,
|
||||
landmarks[0].x,
|
||||
landmarks[0].y,
|
||||
] # Left, up, right, down.
|
||||
for i in range(len(landmarks)):
|
||||
face_rect[0] = min(face_rect[0], landmarks[i].x)
|
||||
face_rect[1] = min(face_rect[1], landmarks[i].y)
|
||||
face_rect[2] = max(face_rect[2], landmarks[i].x)
|
||||
face_rect[3] = max(face_rect[3], landmarks[i].y)
|
||||
if min_face_size_pixels > 0:
|
||||
face_width = abs(face_rect[2] - face_rect[0])
|
||||
face_height = abs(face_rect[3] - face_rect[1])
|
||||
face_width_pixels = face_width * img_width
|
||||
face_height_pixels = face_height * img_height
|
||||
face_size = min(face_width_pixels, face_height_pixels)
|
||||
if face_size >= min_face_size_pixels:
|
||||
filtered_landmarks.append(lm)
|
||||
else:
|
||||
filtered_landmarks.append(lm)
|
||||
|
||||
# Annotations are drawn in BGR for some reason, but we don't need to flip a zero-filled image at the start.
|
||||
empty = numpy.zeros_like(img_rgb)
|
||||
|
||||
# Draw detected faces:
|
||||
for face_landmarks in filtered_landmarks:
|
||||
mp_drawing.draw_landmarks(
|
||||
empty,
|
||||
face_landmarks,
|
||||
connections=face_connection_spec.keys(),
|
||||
landmark_drawing_spec=None,
|
||||
connection_drawing_spec=face_connection_spec
|
||||
)
|
||||
draw_pupils(empty, face_landmarks, iris_landmark_spec, 2)
|
||||
|
||||
# Flip BGR back to RGB.
|
||||
empty = reverse_channels(empty).copy()
|
||||
|
||||
return empty
|
||||
@@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2019 Intel ISL (Intel Intelligent Systems Lab)
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -1,49 +0,0 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from einops import rearrange
|
||||
from .api import MiDaSInference
|
||||
from modules import devices
|
||||
|
||||
model = None
|
||||
|
||||
def unload_midas_model():
|
||||
global model
|
||||
if model is not None:
|
||||
model = model.cpu()
|
||||
|
||||
def apply_midas(input_image, a=np.pi * 2.0, bg_th=0.1):
|
||||
global model
|
||||
if model is None:
|
||||
model = MiDaSInference(model_type="dpt_hybrid")
|
||||
if devices.get_device_for("controlnet").type != 'mps':
|
||||
model = model.to(devices.get_device_for("controlnet"))
|
||||
|
||||
assert input_image.ndim == 3
|
||||
image_depth = input_image
|
||||
with torch.no_grad():
|
||||
image_depth = torch.from_numpy(image_depth).float()
|
||||
if devices.get_device_for("controlnet").type != 'mps':
|
||||
image_depth = image_depth.to(devices.get_device_for("controlnet"))
|
||||
image_depth = image_depth / 127.5 - 1.0
|
||||
image_depth = rearrange(image_depth, 'h w c -> 1 c h w')
|
||||
depth = model(image_depth)[0]
|
||||
|
||||
depth_pt = depth.clone()
|
||||
depth_pt -= torch.min(depth_pt)
|
||||
depth_pt /= torch.max(depth_pt)
|
||||
depth_pt = depth_pt.cpu().numpy()
|
||||
depth_image = (depth_pt * 255.0).clip(0, 255).astype(np.uint8)
|
||||
|
||||
depth_np = depth.cpu().numpy()
|
||||
x = cv2.Sobel(depth_np, cv2.CV_32F, 1, 0, ksize=3)
|
||||
y = cv2.Sobel(depth_np, cv2.CV_32F, 0, 1, ksize=3)
|
||||
z = np.ones_like(x) * a
|
||||
x[depth_pt < bg_th] = 0
|
||||
y[depth_pt < bg_th] = 0
|
||||
normal = np.stack([x, y, z], axis=2)
|
||||
normal /= np.sum(normal ** 2.0, axis=2, keepdims=True) ** 0.5
|
||||
normal_image = (normal * 127.5 + 127.5).clip(0, 255).astype(np.uint8)[:, :, ::-1]
|
||||
|
||||
return depth_image, normal_image
|
||||
@@ -1,181 +0,0 @@
|
||||
# based on https://github.com/isl-org/MiDaS
|
||||
|
||||
import cv2
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import os
|
||||
from annotator.annotator_path import models_path
|
||||
|
||||
from torchvision.transforms import Compose
|
||||
|
||||
from .midas.dpt_depth import DPTDepthModel
|
||||
from .midas.midas_net import MidasNet
|
||||
from .midas.midas_net_custom import MidasNet_small
|
||||
from .midas.transforms import Resize, NormalizeImage, PrepareForNet
|
||||
|
||||
base_model_path = os.path.join(models_path, "midas")
|
||||
old_modeldir = os.path.dirname(os.path.realpath(__file__))
|
||||
remote_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/dpt_hybrid-midas-501f0c75.pt"
|
||||
|
||||
ISL_PATHS = {
|
||||
"dpt_large": os.path.join(base_model_path, "dpt_large-midas-2f21e586.pt"),
|
||||
"dpt_hybrid": os.path.join(base_model_path, "dpt_hybrid-midas-501f0c75.pt"),
|
||||
"midas_v21": "",
|
||||
"midas_v21_small": "",
|
||||
}
|
||||
|
||||
OLD_ISL_PATHS = {
|
||||
"dpt_large": os.path.join(old_modeldir, "dpt_large-midas-2f21e586.pt"),
|
||||
"dpt_hybrid": os.path.join(old_modeldir, "dpt_hybrid-midas-501f0c75.pt"),
|
||||
"midas_v21": "",
|
||||
"midas_v21_small": "",
|
||||
}
|
||||
|
||||
|
||||
def disabled_train(self, mode=True):
|
||||
"""Overwrite model.train with this function to make sure train/eval mode
|
||||
does not change anymore."""
|
||||
return self
|
||||
|
||||
|
||||
def load_midas_transform(model_type):
|
||||
# https://github.com/isl-org/MiDaS/blob/master/run.py
|
||||
# load transform only
|
||||
if model_type == "dpt_large": # DPT-Large
|
||||
net_w, net_h = 384, 384
|
||||
resize_mode = "minimal"
|
||||
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
||||
|
||||
elif model_type == "dpt_hybrid": # DPT-Hybrid
|
||||
net_w, net_h = 384, 384
|
||||
resize_mode = "minimal"
|
||||
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
||||
|
||||
elif model_type == "midas_v21":
|
||||
net_w, net_h = 384, 384
|
||||
resize_mode = "upper_bound"
|
||||
normalization = NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
|
||||
|
||||
elif model_type == "midas_v21_small":
|
||||
net_w, net_h = 256, 256
|
||||
resize_mode = "upper_bound"
|
||||
normalization = NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
|
||||
|
||||
else:
|
||||
assert False, f"model_type '{model_type}' not implemented, use: --model_type large"
|
||||
|
||||
transform = Compose(
|
||||
[
|
||||
Resize(
|
||||
net_w,
|
||||
net_h,
|
||||
resize_target=None,
|
||||
keep_aspect_ratio=True,
|
||||
ensure_multiple_of=32,
|
||||
resize_method=resize_mode,
|
||||
image_interpolation_method=cv2.INTER_CUBIC,
|
||||
),
|
||||
normalization,
|
||||
PrepareForNet(),
|
||||
]
|
||||
)
|
||||
|
||||
return transform
|
||||
|
||||
|
||||
def load_model(model_type):
|
||||
# https://github.com/isl-org/MiDaS/blob/master/run.py
|
||||
# load network
|
||||
model_path = ISL_PATHS[model_type]
|
||||
old_model_path = OLD_ISL_PATHS[model_type]
|
||||
if model_type == "dpt_large": # DPT-Large
|
||||
model = DPTDepthModel(
|
||||
path=model_path,
|
||||
backbone="vitl16_384",
|
||||
non_negative=True,
|
||||
)
|
||||
net_w, net_h = 384, 384
|
||||
resize_mode = "minimal"
|
||||
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
||||
|
||||
elif model_type == "dpt_hybrid": # DPT-Hybrid
|
||||
if os.path.exists(old_model_path):
|
||||
model_path = old_model_path
|
||||
elif not os.path.exists(model_path):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=base_model_path)
|
||||
|
||||
model = DPTDepthModel(
|
||||
path=model_path,
|
||||
backbone="vitb_rn50_384",
|
||||
non_negative=True,
|
||||
)
|
||||
net_w, net_h = 384, 384
|
||||
resize_mode = "minimal"
|
||||
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
||||
|
||||
elif model_type == "midas_v21":
|
||||
model = MidasNet(model_path, non_negative=True)
|
||||
net_w, net_h = 384, 384
|
||||
resize_mode = "upper_bound"
|
||||
normalization = NormalizeImage(
|
||||
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
||||
)
|
||||
|
||||
elif model_type == "midas_v21_small":
|
||||
model = MidasNet_small(model_path, features=64, backbone="efficientnet_lite3", exportable=True,
|
||||
non_negative=True, blocks={'expand': True})
|
||||
net_w, net_h = 256, 256
|
||||
resize_mode = "upper_bound"
|
||||
normalization = NormalizeImage(
|
||||
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
||||
)
|
||||
|
||||
else:
|
||||
print(f"model_type '{model_type}' not implemented, use: --model_type large")
|
||||
assert False
|
||||
|
||||
transform = Compose(
|
||||
[
|
||||
Resize(
|
||||
net_w,
|
||||
net_h,
|
||||
resize_target=None,
|
||||
keep_aspect_ratio=True,
|
||||
ensure_multiple_of=32,
|
||||
resize_method=resize_mode,
|
||||
image_interpolation_method=cv2.INTER_CUBIC,
|
||||
),
|
||||
normalization,
|
||||
PrepareForNet(),
|
||||
]
|
||||
)
|
||||
|
||||
return model.eval(), transform
|
||||
|
||||
|
||||
class MiDaSInference(nn.Module):
|
||||
MODEL_TYPES_TORCH_HUB = [
|
||||
"DPT_Large",
|
||||
"DPT_Hybrid",
|
||||
"MiDaS_small"
|
||||
]
|
||||
MODEL_TYPES_ISL = [
|
||||
"dpt_large",
|
||||
"dpt_hybrid",
|
||||
"midas_v21",
|
||||
"midas_v21_small",
|
||||
]
|
||||
|
||||
def __init__(self, model_type):
|
||||
super().__init__()
|
||||
assert (model_type in self.MODEL_TYPES_ISL)
|
||||
model, _ = load_model(model_type)
|
||||
self.model = model
|
||||
self.model.train = disabled_train
|
||||
|
||||
def forward(self, x):
|
||||
with torch.no_grad():
|
||||
prediction = self.model(x)
|
||||
return prediction
|
||||
|
||||
@@ -1,16 +0,0 @@
|
||||
import torch
|
||||
|
||||
|
||||
class BaseModel(torch.nn.Module):
|
||||
def load(self, path):
|
||||
"""Load model from file.
|
||||
|
||||
Args:
|
||||
path (str): file path
|
||||
"""
|
||||
parameters = torch.load(path, map_location=torch.device('cpu'))
|
||||
|
||||
if "optimizer" in parameters:
|
||||
parameters = parameters["model"]
|
||||
|
||||
self.load_state_dict(parameters)
|
||||
@@ -1,342 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from .vit import (
|
||||
_make_pretrained_vitb_rn50_384,
|
||||
_make_pretrained_vitl16_384,
|
||||
_make_pretrained_vitb16_384,
|
||||
forward_vit,
|
||||
)
|
||||
|
||||
def _make_encoder(backbone, features, use_pretrained, groups=1, expand=False, exportable=True, hooks=None, use_vit_only=False, use_readout="ignore",):
|
||||
if backbone == "vitl16_384":
|
||||
pretrained = _make_pretrained_vitl16_384(
|
||||
use_pretrained, hooks=hooks, use_readout=use_readout
|
||||
)
|
||||
scratch = _make_scratch(
|
||||
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
||||
) # ViT-L/16 - 85.0% Top1 (backbone)
|
||||
elif backbone == "vitb_rn50_384":
|
||||
pretrained = _make_pretrained_vitb_rn50_384(
|
||||
use_pretrained,
|
||||
hooks=hooks,
|
||||
use_vit_only=use_vit_only,
|
||||
use_readout=use_readout,
|
||||
)
|
||||
scratch = _make_scratch(
|
||||
[256, 512, 768, 768], features, groups=groups, expand=expand
|
||||
) # ViT-H/16 - 85.0% Top1 (backbone)
|
||||
elif backbone == "vitb16_384":
|
||||
pretrained = _make_pretrained_vitb16_384(
|
||||
use_pretrained, hooks=hooks, use_readout=use_readout
|
||||
)
|
||||
scratch = _make_scratch(
|
||||
[96, 192, 384, 768], features, groups=groups, expand=expand
|
||||
) # ViT-B/16 - 84.6% Top1 (backbone)
|
||||
elif backbone == "resnext101_wsl":
|
||||
pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
|
||||
scratch = _make_scratch([256, 512, 1024, 2048], features, groups=groups, expand=expand) # efficientnet_lite3
|
||||
elif backbone == "efficientnet_lite3":
|
||||
pretrained = _make_pretrained_efficientnet_lite3(use_pretrained, exportable=exportable)
|
||||
scratch = _make_scratch([32, 48, 136, 384], features, groups=groups, expand=expand) # efficientnet_lite3
|
||||
else:
|
||||
print(f"Backbone '{backbone}' not implemented")
|
||||
assert False
|
||||
|
||||
return pretrained, scratch
|
||||
|
||||
|
||||
def _make_scratch(in_shape, out_shape, groups=1, expand=False):
|
||||
scratch = nn.Module()
|
||||
|
||||
out_shape1 = out_shape
|
||||
out_shape2 = out_shape
|
||||
out_shape3 = out_shape
|
||||
out_shape4 = out_shape
|
||||
if expand==True:
|
||||
out_shape1 = out_shape
|
||||
out_shape2 = out_shape*2
|
||||
out_shape3 = out_shape*4
|
||||
out_shape4 = out_shape*8
|
||||
|
||||
scratch.layer1_rn = nn.Conv2d(
|
||||
in_shape[0], out_shape1, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
||||
)
|
||||
scratch.layer2_rn = nn.Conv2d(
|
||||
in_shape[1], out_shape2, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
||||
)
|
||||
scratch.layer3_rn = nn.Conv2d(
|
||||
in_shape[2], out_shape3, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
||||
)
|
||||
scratch.layer4_rn = nn.Conv2d(
|
||||
in_shape[3], out_shape4, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
||||
)
|
||||
|
||||
return scratch
|
||||
|
||||
|
||||
def _make_pretrained_efficientnet_lite3(use_pretrained, exportable=False):
|
||||
efficientnet = torch.hub.load(
|
||||
"rwightman/gen-efficientnet-pytorch",
|
||||
"tf_efficientnet_lite3",
|
||||
pretrained=use_pretrained,
|
||||
exportable=exportable
|
||||
)
|
||||
return _make_efficientnet_backbone(efficientnet)
|
||||
|
||||
|
||||
def _make_efficientnet_backbone(effnet):
|
||||
pretrained = nn.Module()
|
||||
|
||||
pretrained.layer1 = nn.Sequential(
|
||||
effnet.conv_stem, effnet.bn1, effnet.act1, *effnet.blocks[0:2]
|
||||
)
|
||||
pretrained.layer2 = nn.Sequential(*effnet.blocks[2:3])
|
||||
pretrained.layer3 = nn.Sequential(*effnet.blocks[3:5])
|
||||
pretrained.layer4 = nn.Sequential(*effnet.blocks[5:9])
|
||||
|
||||
return pretrained
|
||||
|
||||
|
||||
def _make_resnet_backbone(resnet):
|
||||
pretrained = nn.Module()
|
||||
pretrained.layer1 = nn.Sequential(
|
||||
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1
|
||||
)
|
||||
|
||||
pretrained.layer2 = resnet.layer2
|
||||
pretrained.layer3 = resnet.layer3
|
||||
pretrained.layer4 = resnet.layer4
|
||||
|
||||
return pretrained
|
||||
|
||||
|
||||
def _make_pretrained_resnext101_wsl(use_pretrained):
|
||||
resnet = torch.hub.load("facebookresearch/WSL-Images", "resnext101_32x8d_wsl")
|
||||
return _make_resnet_backbone(resnet)
|
||||
|
||||
|
||||
|
||||
class Interpolate(nn.Module):
|
||||
"""Interpolation module.
|
||||
"""
|
||||
|
||||
def __init__(self, scale_factor, mode, align_corners=False):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
scale_factor (float): scaling
|
||||
mode (str): interpolation mode
|
||||
"""
|
||||
super(Interpolate, self).__init__()
|
||||
|
||||
self.interp = nn.functional.interpolate
|
||||
self.scale_factor = scale_factor
|
||||
self.mode = mode
|
||||
self.align_corners = align_corners
|
||||
|
||||
def forward(self, x):
|
||||
"""Forward pass.
|
||||
|
||||
Args:
|
||||
x (tensor): input
|
||||
|
||||
Returns:
|
||||
tensor: interpolated data
|
||||
"""
|
||||
|
||||
x = self.interp(
|
||||
x, scale_factor=self.scale_factor, mode=self.mode, align_corners=self.align_corners
|
||||
)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class ResidualConvUnit(nn.Module):
|
||||
"""Residual convolution module.
|
||||
"""
|
||||
|
||||
def __init__(self, features):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
features (int): number of features
|
||||
"""
|
||||
super().__init__()
|
||||
|
||||
self.conv1 = nn.Conv2d(
|
||||
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
||||
)
|
||||
|
||||
self.conv2 = nn.Conv2d(
|
||||
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
||||
)
|
||||
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
|
||||
def forward(self, x):
|
||||
"""Forward pass.
|
||||
|
||||
Args:
|
||||
x (tensor): input
|
||||
|
||||
Returns:
|
||||
tensor: output
|
||||
"""
|
||||
out = self.relu(x)
|
||||
out = self.conv1(out)
|
||||
out = self.relu(out)
|
||||
out = self.conv2(out)
|
||||
|
||||
return out + x
|
||||
|
||||
|
||||
class FeatureFusionBlock(nn.Module):
|
||||
"""Feature fusion block.
|
||||
"""
|
||||
|
||||
def __init__(self, features):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
features (int): number of features
|
||||
"""
|
||||
super(FeatureFusionBlock, self).__init__()
|
||||
|
||||
self.resConfUnit1 = ResidualConvUnit(features)
|
||||
self.resConfUnit2 = ResidualConvUnit(features)
|
||||
|
||||
def forward(self, *xs):
|
||||
"""Forward pass.
|
||||
|
||||
Returns:
|
||||
tensor: output
|
||||
"""
|
||||
output = xs[0]
|
||||
|
||||
if len(xs) == 2:
|
||||
output += self.resConfUnit1(xs[1])
|
||||
|
||||
output = self.resConfUnit2(output)
|
||||
|
||||
output = nn.functional.interpolate(
|
||||
output, scale_factor=2, mode="bilinear", align_corners=True
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
|
||||
|
||||
class ResidualConvUnit_custom(nn.Module):
|
||||
"""Residual convolution module.
|
||||
"""
|
||||
|
||||
def __init__(self, features, activation, bn):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
features (int): number of features
|
||||
"""
|
||||
super().__init__()
|
||||
|
||||
self.bn = bn
|
||||
|
||||
self.groups=1
|
||||
|
||||
self.conv1 = nn.Conv2d(
|
||||
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
||||
)
|
||||
|
||||
self.conv2 = nn.Conv2d(
|
||||
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
||||
)
|
||||
|
||||
if self.bn==True:
|
||||
self.bn1 = nn.BatchNorm2d(features)
|
||||
self.bn2 = nn.BatchNorm2d(features)
|
||||
|
||||
self.activation = activation
|
||||
|
||||
self.skip_add = nn.quantized.FloatFunctional()
|
||||
|
||||
def forward(self, x):
|
||||
"""Forward pass.
|
||||
|
||||
Args:
|
||||
x (tensor): input
|
||||
|
||||
Returns:
|
||||
tensor: output
|
||||
"""
|
||||
|
||||
out = self.activation(x)
|
||||
out = self.conv1(out)
|
||||
if self.bn==True:
|
||||
out = self.bn1(out)
|
||||
|
||||
out = self.activation(out)
|
||||
out = self.conv2(out)
|
||||
if self.bn==True:
|
||||
out = self.bn2(out)
|
||||
|
||||
if self.groups > 1:
|
||||
out = self.conv_merge(out)
|
||||
|
||||
return self.skip_add.add(out, x)
|
||||
|
||||
# return out + x
|
||||
|
||||
|
||||
class FeatureFusionBlock_custom(nn.Module):
|
||||
"""Feature fusion block.
|
||||
"""
|
||||
|
||||
def __init__(self, features, activation, deconv=False, bn=False, expand=False, align_corners=True):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
features (int): number of features
|
||||
"""
|
||||
super(FeatureFusionBlock_custom, self).__init__()
|
||||
|
||||
self.deconv = deconv
|
||||
self.align_corners = align_corners
|
||||
|
||||
self.groups=1
|
||||
|
||||
self.expand = expand
|
||||
out_features = features
|
||||
if self.expand==True:
|
||||
out_features = features//2
|
||||
|
||||
self.out_conv = nn.Conv2d(features, out_features, kernel_size=1, stride=1, padding=0, bias=True, groups=1)
|
||||
|
||||
self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
|
||||
self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
|
||||
|
||||
self.skip_add = nn.quantized.FloatFunctional()
|
||||
|
||||
def forward(self, *xs):
|
||||
"""Forward pass.
|
||||
|
||||
Returns:
|
||||
tensor: output
|
||||
"""
|
||||
output = xs[0]
|
||||
|
||||
if len(xs) == 2:
|
||||
res = self.resConfUnit1(xs[1])
|
||||
output = self.skip_add.add(output, res)
|
||||
# output += res
|
||||
|
||||
output = self.resConfUnit2(output)
|
||||
|
||||
output = nn.functional.interpolate(
|
||||
output, scale_factor=2, mode="bilinear", align_corners=self.align_corners
|
||||
)
|
||||
|
||||
output = self.out_conv(output)
|
||||
|
||||
return output
|
||||
|
||||
@@ -1,109 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from .base_model import BaseModel
|
||||
from .blocks import (
|
||||
FeatureFusionBlock,
|
||||
FeatureFusionBlock_custom,
|
||||
Interpolate,
|
||||
_make_encoder,
|
||||
forward_vit,
|
||||
)
|
||||
|
||||
|
||||
def _make_fusion_block(features, use_bn):
|
||||
return FeatureFusionBlock_custom(
|
||||
features,
|
||||
nn.ReLU(False),
|
||||
deconv=False,
|
||||
bn=use_bn,
|
||||
expand=False,
|
||||
align_corners=True,
|
||||
)
|
||||
|
||||
|
||||
class DPT(BaseModel):
|
||||
def __init__(
|
||||
self,
|
||||
head,
|
||||
features=256,
|
||||
backbone="vitb_rn50_384",
|
||||
readout="project",
|
||||
channels_last=False,
|
||||
use_bn=False,
|
||||
):
|
||||
|
||||
super(DPT, self).__init__()
|
||||
|
||||
self.channels_last = channels_last
|
||||
|
||||
hooks = {
|
||||
"vitb_rn50_384": [0, 1, 8, 11],
|
||||
"vitb16_384": [2, 5, 8, 11],
|
||||
"vitl16_384": [5, 11, 17, 23],
|
||||
}
|
||||
|
||||
# Instantiate backbone and reassemble blocks
|
||||
self.pretrained, self.scratch = _make_encoder(
|
||||
backbone,
|
||||
features,
|
||||
False, # Set to true of you want to train from scratch, uses ImageNet weights
|
||||
groups=1,
|
||||
expand=False,
|
||||
exportable=False,
|
||||
hooks=hooks[backbone],
|
||||
use_readout=readout,
|
||||
)
|
||||
|
||||
self.scratch.refinenet1 = _make_fusion_block(features, use_bn)
|
||||
self.scratch.refinenet2 = _make_fusion_block(features, use_bn)
|
||||
self.scratch.refinenet3 = _make_fusion_block(features, use_bn)
|
||||
self.scratch.refinenet4 = _make_fusion_block(features, use_bn)
|
||||
|
||||
self.scratch.output_conv = head
|
||||
|
||||
|
||||
def forward(self, x):
|
||||
if self.channels_last == True:
|
||||
x.contiguous(memory_format=torch.channels_last)
|
||||
|
||||
layer_1, layer_2, layer_3, layer_4 = forward_vit(self.pretrained, x)
|
||||
|
||||
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
||||
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
||||
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
||||
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
||||
|
||||
path_4 = self.scratch.refinenet4(layer_4_rn)
|
||||
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
||||
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
||||
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
||||
|
||||
out = self.scratch.output_conv(path_1)
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class DPTDepthModel(DPT):
|
||||
def __init__(self, path=None, non_negative=True, **kwargs):
|
||||
features = kwargs["features"] if "features" in kwargs else 256
|
||||
|
||||
head = nn.Sequential(
|
||||
nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1),
|
||||
Interpolate(scale_factor=2, mode="bilinear", align_corners=True),
|
||||
nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
|
||||
nn.ReLU(True),
|
||||
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
||||
nn.ReLU(True) if non_negative else nn.Identity(),
|
||||
nn.Identity(),
|
||||
)
|
||||
|
||||
super().__init__(head, **kwargs)
|
||||
|
||||
if path is not None:
|
||||
self.load(path)
|
||||
|
||||
def forward(self, x):
|
||||
return super().forward(x).squeeze(dim=1)
|
||||
|
||||
@@ -1,76 +0,0 @@
|
||||
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
||||
This file contains code that is adapted from
|
||||
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
||||
"""
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from .base_model import BaseModel
|
||||
from .blocks import FeatureFusionBlock, Interpolate, _make_encoder
|
||||
|
||||
|
||||
class MidasNet(BaseModel):
|
||||
"""Network for monocular depth estimation.
|
||||
"""
|
||||
|
||||
def __init__(self, path=None, features=256, non_negative=True):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
path (str, optional): Path to saved model. Defaults to None.
|
||||
features (int, optional): Number of features. Defaults to 256.
|
||||
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
||||
"""
|
||||
print("Loading weights: ", path)
|
||||
|
||||
super(MidasNet, self).__init__()
|
||||
|
||||
use_pretrained = False if path is None else True
|
||||
|
||||
self.pretrained, self.scratch = _make_encoder(backbone="resnext101_wsl", features=features, use_pretrained=use_pretrained)
|
||||
|
||||
self.scratch.refinenet4 = FeatureFusionBlock(features)
|
||||
self.scratch.refinenet3 = FeatureFusionBlock(features)
|
||||
self.scratch.refinenet2 = FeatureFusionBlock(features)
|
||||
self.scratch.refinenet1 = FeatureFusionBlock(features)
|
||||
|
||||
self.scratch.output_conv = nn.Sequential(
|
||||
nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1),
|
||||
Interpolate(scale_factor=2, mode="bilinear"),
|
||||
nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1),
|
||||
nn.ReLU(True),
|
||||
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
||||
nn.ReLU(True) if non_negative else nn.Identity(),
|
||||
)
|
||||
|
||||
if path:
|
||||
self.load(path)
|
||||
|
||||
def forward(self, x):
|
||||
"""Forward pass.
|
||||
|
||||
Args:
|
||||
x (tensor): input data (image)
|
||||
|
||||
Returns:
|
||||
tensor: depth
|
||||
"""
|
||||
|
||||
layer_1 = self.pretrained.layer1(x)
|
||||
layer_2 = self.pretrained.layer2(layer_1)
|
||||
layer_3 = self.pretrained.layer3(layer_2)
|
||||
layer_4 = self.pretrained.layer4(layer_3)
|
||||
|
||||
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
||||
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
||||
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
||||
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
||||
|
||||
path_4 = self.scratch.refinenet4(layer_4_rn)
|
||||
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
||||
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
||||
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
||||
|
||||
out = self.scratch.output_conv(path_1)
|
||||
|
||||
return torch.squeeze(out, dim=1)
|
||||
@@ -1,128 +0,0 @@
|
||||
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
||||
This file contains code that is adapted from
|
||||
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
||||
"""
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from .base_model import BaseModel
|
||||
from .blocks import FeatureFusionBlock, FeatureFusionBlock_custom, Interpolate, _make_encoder
|
||||
|
||||
|
||||
class MidasNet_small(BaseModel):
|
||||
"""Network for monocular depth estimation.
|
||||
"""
|
||||
|
||||
def __init__(self, path=None, features=64, backbone="efficientnet_lite3", non_negative=True, exportable=True, channels_last=False, align_corners=True,
|
||||
blocks={'expand': True}):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
path (str, optional): Path to saved model. Defaults to None.
|
||||
features (int, optional): Number of features. Defaults to 256.
|
||||
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
||||
"""
|
||||
print("Loading weights: ", path)
|
||||
|
||||
super(MidasNet_small, self).__init__()
|
||||
|
||||
use_pretrained = False if path else True
|
||||
|
||||
self.channels_last = channels_last
|
||||
self.blocks = blocks
|
||||
self.backbone = backbone
|
||||
|
||||
self.groups = 1
|
||||
|
||||
features1=features
|
||||
features2=features
|
||||
features3=features
|
||||
features4=features
|
||||
self.expand = False
|
||||
if "expand" in self.blocks and self.blocks['expand'] == True:
|
||||
self.expand = True
|
||||
features1=features
|
||||
features2=features*2
|
||||
features3=features*4
|
||||
features4=features*8
|
||||
|
||||
self.pretrained, self.scratch = _make_encoder(self.backbone, features, use_pretrained, groups=self.groups, expand=self.expand, exportable=exportable)
|
||||
|
||||
self.scratch.activation = nn.ReLU(False)
|
||||
|
||||
self.scratch.refinenet4 = FeatureFusionBlock_custom(features4, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
||||
self.scratch.refinenet3 = FeatureFusionBlock_custom(features3, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
||||
self.scratch.refinenet2 = FeatureFusionBlock_custom(features2, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
||||
self.scratch.refinenet1 = FeatureFusionBlock_custom(features1, self.scratch.activation, deconv=False, bn=False, align_corners=align_corners)
|
||||
|
||||
|
||||
self.scratch.output_conv = nn.Sequential(
|
||||
nn.Conv2d(features, features//2, kernel_size=3, stride=1, padding=1, groups=self.groups),
|
||||
Interpolate(scale_factor=2, mode="bilinear"),
|
||||
nn.Conv2d(features//2, 32, kernel_size=3, stride=1, padding=1),
|
||||
self.scratch.activation,
|
||||
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
||||
nn.ReLU(True) if non_negative else nn.Identity(),
|
||||
nn.Identity(),
|
||||
)
|
||||
|
||||
if path:
|
||||
self.load(path)
|
||||
|
||||
|
||||
def forward(self, x):
|
||||
"""Forward pass.
|
||||
|
||||
Args:
|
||||
x (tensor): input data (image)
|
||||
|
||||
Returns:
|
||||
tensor: depth
|
||||
"""
|
||||
if self.channels_last==True:
|
||||
print("self.channels_last = ", self.channels_last)
|
||||
x.contiguous(memory_format=torch.channels_last)
|
||||
|
||||
|
||||
layer_1 = self.pretrained.layer1(x)
|
||||
layer_2 = self.pretrained.layer2(layer_1)
|
||||
layer_3 = self.pretrained.layer3(layer_2)
|
||||
layer_4 = self.pretrained.layer4(layer_3)
|
||||
|
||||
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
||||
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
||||
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
||||
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
||||
|
||||
|
||||
path_4 = self.scratch.refinenet4(layer_4_rn)
|
||||
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
||||
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
||||
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
||||
|
||||
out = self.scratch.output_conv(path_1)
|
||||
|
||||
return torch.squeeze(out, dim=1)
|
||||
|
||||
|
||||
|
||||
def fuse_model(m):
|
||||
prev_previous_type = nn.Identity()
|
||||
prev_previous_name = ''
|
||||
previous_type = nn.Identity()
|
||||
previous_name = ''
|
||||
for name, module in m.named_modules():
|
||||
if prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d and type(module) == nn.ReLU:
|
||||
# print("FUSED ", prev_previous_name, previous_name, name)
|
||||
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name, name], inplace=True)
|
||||
elif prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d:
|
||||
# print("FUSED ", prev_previous_name, previous_name)
|
||||
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name], inplace=True)
|
||||
# elif previous_type == nn.Conv2d and type(module) == nn.ReLU:
|
||||
# print("FUSED ", previous_name, name)
|
||||
# torch.quantization.fuse_modules(m, [previous_name, name], inplace=True)
|
||||
|
||||
prev_previous_type = previous_type
|
||||
prev_previous_name = previous_name
|
||||
previous_type = type(module)
|
||||
previous_name = name
|
||||
@@ -1,234 +0,0 @@
|
||||
import numpy as np
|
||||
import cv2
|
||||
import math
|
||||
|
||||
|
||||
def apply_min_size(sample, size, image_interpolation_method=cv2.INTER_AREA):
|
||||
"""Rezise the sample to ensure the given size. Keeps aspect ratio.
|
||||
|
||||
Args:
|
||||
sample (dict): sample
|
||||
size (tuple): image size
|
||||
|
||||
Returns:
|
||||
tuple: new size
|
||||
"""
|
||||
shape = list(sample["disparity"].shape)
|
||||
|
||||
if shape[0] >= size[0] and shape[1] >= size[1]:
|
||||
return sample
|
||||
|
||||
scale = [0, 0]
|
||||
scale[0] = size[0] / shape[0]
|
||||
scale[1] = size[1] / shape[1]
|
||||
|
||||
scale = max(scale)
|
||||
|
||||
shape[0] = math.ceil(scale * shape[0])
|
||||
shape[1] = math.ceil(scale * shape[1])
|
||||
|
||||
# resize
|
||||
sample["image"] = cv2.resize(
|
||||
sample["image"], tuple(shape[::-1]), interpolation=image_interpolation_method
|
||||
)
|
||||
|
||||
sample["disparity"] = cv2.resize(
|
||||
sample["disparity"], tuple(shape[::-1]), interpolation=cv2.INTER_NEAREST
|
||||
)
|
||||
sample["mask"] = cv2.resize(
|
||||
sample["mask"].astype(np.float32),
|
||||
tuple(shape[::-1]),
|
||||
interpolation=cv2.INTER_NEAREST,
|
||||
)
|
||||
sample["mask"] = sample["mask"].astype(bool)
|
||||
|
||||
return tuple(shape)
|
||||
|
||||
|
||||
class Resize(object):
|
||||
"""Resize sample to given size (width, height).
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
width,
|
||||
height,
|
||||
resize_target=True,
|
||||
keep_aspect_ratio=False,
|
||||
ensure_multiple_of=1,
|
||||
resize_method="lower_bound",
|
||||
image_interpolation_method=cv2.INTER_AREA,
|
||||
):
|
||||
"""Init.
|
||||
|
||||
Args:
|
||||
width (int): desired output width
|
||||
height (int): desired output height
|
||||
resize_target (bool, optional):
|
||||
True: Resize the full sample (image, mask, target).
|
||||
False: Resize image only.
|
||||
Defaults to True.
|
||||
keep_aspect_ratio (bool, optional):
|
||||
True: Keep the aspect ratio of the input sample.
|
||||
Output sample might not have the given width and height, and
|
||||
resize behaviour depends on the parameter 'resize_method'.
|
||||
Defaults to False.
|
||||
ensure_multiple_of (int, optional):
|
||||
Output width and height is constrained to be multiple of this parameter.
|
||||
Defaults to 1.
|
||||
resize_method (str, optional):
|
||||
"lower_bound": Output will be at least as large as the given size.
|
||||
"upper_bound": Output will be at max as large as the given size. (Output size might be smaller than given size.)
|
||||
"minimal": Scale as least as possible. (Output size might be smaller than given size.)
|
||||
Defaults to "lower_bound".
|
||||
"""
|
||||
self.__width = width
|
||||
self.__height = height
|
||||
|
||||
self.__resize_target = resize_target
|
||||
self.__keep_aspect_ratio = keep_aspect_ratio
|
||||
self.__multiple_of = ensure_multiple_of
|
||||
self.__resize_method = resize_method
|
||||
self.__image_interpolation_method = image_interpolation_method
|
||||
|
||||
def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
|
||||
y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
||||
|
||||
if max_val is not None and y > max_val:
|
||||
y = (np.floor(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
||||
|
||||
if y < min_val:
|
||||
y = (np.ceil(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
||||
|
||||
return y
|
||||
|
||||
def get_size(self, width, height):
|
||||
# determine new height and width
|
||||
scale_height = self.__height / height
|
||||
scale_width = self.__width / width
|
||||
|
||||
if self.__keep_aspect_ratio:
|
||||
if self.__resize_method == "lower_bound":
|
||||
# scale such that output size is lower bound
|
||||
if scale_width > scale_height:
|
||||
# fit width
|
||||
scale_height = scale_width
|
||||
else:
|
||||
# fit height
|
||||
scale_width = scale_height
|
||||
elif self.__resize_method == "upper_bound":
|
||||
# scale such that output size is upper bound
|
||||
if scale_width < scale_height:
|
||||
# fit width
|
||||
scale_height = scale_width
|
||||
else:
|
||||
# fit height
|
||||
scale_width = scale_height
|
||||
elif self.__resize_method == "minimal":
|
||||
# scale as least as possbile
|
||||
if abs(1 - scale_width) < abs(1 - scale_height):
|
||||
# fit width
|
||||
scale_height = scale_width
|
||||
else:
|
||||
# fit height
|
||||
scale_width = scale_height
|
||||
else:
|
||||
raise ValueError(
|
||||
f"resize_method {self.__resize_method} not implemented"
|
||||
)
|
||||
|
||||
if self.__resize_method == "lower_bound":
|
||||
new_height = self.constrain_to_multiple_of(
|
||||
scale_height * height, min_val=self.__height
|
||||
)
|
||||
new_width = self.constrain_to_multiple_of(
|
||||
scale_width * width, min_val=self.__width
|
||||
)
|
||||
elif self.__resize_method == "upper_bound":
|
||||
new_height = self.constrain_to_multiple_of(
|
||||
scale_height * height, max_val=self.__height
|
||||
)
|
||||
new_width = self.constrain_to_multiple_of(
|
||||
scale_width * width, max_val=self.__width
|
||||
)
|
||||
elif self.__resize_method == "minimal":
|
||||
new_height = self.constrain_to_multiple_of(scale_height * height)
|
||||
new_width = self.constrain_to_multiple_of(scale_width * width)
|
||||
else:
|
||||
raise ValueError(f"resize_method {self.__resize_method} not implemented")
|
||||
|
||||
return (new_width, new_height)
|
||||
|
||||
def __call__(self, sample):
|
||||
width, height = self.get_size(
|
||||
sample["image"].shape[1], sample["image"].shape[0]
|
||||
)
|
||||
|
||||
# resize sample
|
||||
sample["image"] = cv2.resize(
|
||||
sample["image"],
|
||||
(width, height),
|
||||
interpolation=self.__image_interpolation_method,
|
||||
)
|
||||
|
||||
if self.__resize_target:
|
||||
if "disparity" in sample:
|
||||
sample["disparity"] = cv2.resize(
|
||||
sample["disparity"],
|
||||
(width, height),
|
||||
interpolation=cv2.INTER_NEAREST,
|
||||
)
|
||||
|
||||
if "depth" in sample:
|
||||
sample["depth"] = cv2.resize(
|
||||
sample["depth"], (width, height), interpolation=cv2.INTER_NEAREST
|
||||
)
|
||||
|
||||
sample["mask"] = cv2.resize(
|
||||
sample["mask"].astype(np.float32),
|
||||
(width, height),
|
||||
interpolation=cv2.INTER_NEAREST,
|
||||
)
|
||||
sample["mask"] = sample["mask"].astype(bool)
|
||||
|
||||
return sample
|
||||
|
||||
|
||||
class NormalizeImage(object):
|
||||
"""Normlize image by given mean and std.
|
||||
"""
|
||||
|
||||
def __init__(self, mean, std):
|
||||
self.__mean = mean
|
||||
self.__std = std
|
||||
|
||||
def __call__(self, sample):
|
||||
sample["image"] = (sample["image"] - self.__mean) / self.__std
|
||||
|
||||
return sample
|
||||
|
||||
|
||||
class PrepareForNet(object):
|
||||
"""Prepare sample for usage as network input.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
def __call__(self, sample):
|
||||
image = np.transpose(sample["image"], (2, 0, 1))
|
||||
sample["image"] = np.ascontiguousarray(image).astype(np.float32)
|
||||
|
||||
if "mask" in sample:
|
||||
sample["mask"] = sample["mask"].astype(np.float32)
|
||||
sample["mask"] = np.ascontiguousarray(sample["mask"])
|
||||
|
||||
if "disparity" in sample:
|
||||
disparity = sample["disparity"].astype(np.float32)
|
||||
sample["disparity"] = np.ascontiguousarray(disparity)
|
||||
|
||||
if "depth" in sample:
|
||||
depth = sample["depth"].astype(np.float32)
|
||||
sample["depth"] = np.ascontiguousarray(depth)
|
||||
|
||||
return sample
|
||||
@@ -1,491 +0,0 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import timm
|
||||
import types
|
||||
import math
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class Slice(nn.Module):
|
||||
def __init__(self, start_index=1):
|
||||
super(Slice, self).__init__()
|
||||
self.start_index = start_index
|
||||
|
||||
def forward(self, x):
|
||||
return x[:, self.start_index :]
|
||||
|
||||
|
||||
class AddReadout(nn.Module):
|
||||
def __init__(self, start_index=1):
|
||||
super(AddReadout, self).__init__()
|
||||
self.start_index = start_index
|
||||
|
||||
def forward(self, x):
|
||||
if self.start_index == 2:
|
||||
readout = (x[:, 0] + x[:, 1]) / 2
|
||||
else:
|
||||
readout = x[:, 0]
|
||||
return x[:, self.start_index :] + readout.unsqueeze(1)
|
||||
|
||||
|
||||
class ProjectReadout(nn.Module):
|
||||
def __init__(self, in_features, start_index=1):
|
||||
super(ProjectReadout, self).__init__()
|
||||
self.start_index = start_index
|
||||
|
||||
self.project = nn.Sequential(nn.Linear(2 * in_features, in_features), nn.GELU())
|
||||
|
||||
def forward(self, x):
|
||||
readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index :])
|
||||
features = torch.cat((x[:, self.start_index :], readout), -1)
|
||||
|
||||
return self.project(features)
|
||||
|
||||
|
||||
class Transpose(nn.Module):
|
||||
def __init__(self, dim0, dim1):
|
||||
super(Transpose, self).__init__()
|
||||
self.dim0 = dim0
|
||||
self.dim1 = dim1
|
||||
|
||||
def forward(self, x):
|
||||
x = x.transpose(self.dim0, self.dim1)
|
||||
return x
|
||||
|
||||
|
||||
def forward_vit(pretrained, x):
|
||||
b, c, h, w = x.shape
|
||||
|
||||
glob = pretrained.model.forward_flex(x)
|
||||
|
||||
layer_1 = pretrained.activations["1"]
|
||||
layer_2 = pretrained.activations["2"]
|
||||
layer_3 = pretrained.activations["3"]
|
||||
layer_4 = pretrained.activations["4"]
|
||||
|
||||
layer_1 = pretrained.act_postprocess1[0:2](layer_1)
|
||||
layer_2 = pretrained.act_postprocess2[0:2](layer_2)
|
||||
layer_3 = pretrained.act_postprocess3[0:2](layer_3)
|
||||
layer_4 = pretrained.act_postprocess4[0:2](layer_4)
|
||||
|
||||
unflatten = nn.Sequential(
|
||||
nn.Unflatten(
|
||||
2,
|
||||
torch.Size(
|
||||
[
|
||||
h // pretrained.model.patch_size[1],
|
||||
w // pretrained.model.patch_size[0],
|
||||
]
|
||||
),
|
||||
)
|
||||
)
|
||||
|
||||
if layer_1.ndim == 3:
|
||||
layer_1 = unflatten(layer_1)
|
||||
if layer_2.ndim == 3:
|
||||
layer_2 = unflatten(layer_2)
|
||||
if layer_3.ndim == 3:
|
||||
layer_3 = unflatten(layer_3)
|
||||
if layer_4.ndim == 3:
|
||||
layer_4 = unflatten(layer_4)
|
||||
|
||||
layer_1 = pretrained.act_postprocess1[3 : len(pretrained.act_postprocess1)](layer_1)
|
||||
layer_2 = pretrained.act_postprocess2[3 : len(pretrained.act_postprocess2)](layer_2)
|
||||
layer_3 = pretrained.act_postprocess3[3 : len(pretrained.act_postprocess3)](layer_3)
|
||||
layer_4 = pretrained.act_postprocess4[3 : len(pretrained.act_postprocess4)](layer_4)
|
||||
|
||||
return layer_1, layer_2, layer_3, layer_4
|
||||
|
||||
|
||||
def _resize_pos_embed(self, posemb, gs_h, gs_w):
|
||||
posemb_tok, posemb_grid = (
|
||||
posemb[:, : self.start_index],
|
||||
posemb[0, self.start_index :],
|
||||
)
|
||||
|
||||
gs_old = int(math.sqrt(len(posemb_grid)))
|
||||
|
||||
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
|
||||
posemb_grid = F.interpolate(posemb_grid, size=(gs_h, gs_w), mode="bilinear")
|
||||
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_h * gs_w, -1)
|
||||
|
||||
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
|
||||
|
||||
return posemb
|
||||
|
||||
|
||||
def forward_flex(self, x):
|
||||
b, c, h, w = x.shape
|
||||
|
||||
pos_embed = self._resize_pos_embed(
|
||||
self.pos_embed, h // self.patch_size[1], w // self.patch_size[0]
|
||||
)
|
||||
|
||||
B = x.shape[0]
|
||||
|
||||
if hasattr(self.patch_embed, "backbone"):
|
||||
x = self.patch_embed.backbone(x)
|
||||
if isinstance(x, (list, tuple)):
|
||||
x = x[-1] # last feature if backbone outputs list/tuple of features
|
||||
|
||||
x = self.patch_embed.proj(x).flatten(2).transpose(1, 2)
|
||||
|
||||
if getattr(self, "dist_token", None) is not None:
|
||||
cls_tokens = self.cls_token.expand(
|
||||
B, -1, -1
|
||||
) # stole cls_tokens impl from Phil Wang, thanks
|
||||
dist_token = self.dist_token.expand(B, -1, -1)
|
||||
x = torch.cat((cls_tokens, dist_token, x), dim=1)
|
||||
else:
|
||||
cls_tokens = self.cls_token.expand(
|
||||
B, -1, -1
|
||||
) # stole cls_tokens impl from Phil Wang, thanks
|
||||
x = torch.cat((cls_tokens, x), dim=1)
|
||||
|
||||
x = x + pos_embed
|
||||
x = self.pos_drop(x)
|
||||
|
||||
for blk in self.blocks:
|
||||
x = blk(x)
|
||||
|
||||
x = self.norm(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
activations = {}
|
||||
|
||||
|
||||
def get_activation(name):
|
||||
def hook(model, input, output):
|
||||
activations[name] = output
|
||||
|
||||
return hook
|
||||
|
||||
|
||||
def get_readout_oper(vit_features, features, use_readout, start_index=1):
|
||||
if use_readout == "ignore":
|
||||
readout_oper = [Slice(start_index)] * len(features)
|
||||
elif use_readout == "add":
|
||||
readout_oper = [AddReadout(start_index)] * len(features)
|
||||
elif use_readout == "project":
|
||||
readout_oper = [
|
||||
ProjectReadout(vit_features, start_index) for out_feat in features
|
||||
]
|
||||
else:
|
||||
assert (
|
||||
False
|
||||
), "wrong operation for readout token, use_readout can be 'ignore', 'add', or 'project'"
|
||||
|
||||
return readout_oper
|
||||
|
||||
|
||||
def _make_vit_b16_backbone(
|
||||
model,
|
||||
features=[96, 192, 384, 768],
|
||||
size=[384, 384],
|
||||
hooks=[2, 5, 8, 11],
|
||||
vit_features=768,
|
||||
use_readout="ignore",
|
||||
start_index=1,
|
||||
):
|
||||
pretrained = nn.Module()
|
||||
|
||||
pretrained.model = model
|
||||
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
||||
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
||||
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
||||
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
||||
|
||||
pretrained.activations = activations
|
||||
|
||||
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
||||
|
||||
# 32, 48, 136, 384
|
||||
pretrained.act_postprocess1 = nn.Sequential(
|
||||
readout_oper[0],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[0],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
nn.ConvTranspose2d(
|
||||
in_channels=features[0],
|
||||
out_channels=features[0],
|
||||
kernel_size=4,
|
||||
stride=4,
|
||||
padding=0,
|
||||
bias=True,
|
||||
dilation=1,
|
||||
groups=1,
|
||||
),
|
||||
)
|
||||
|
||||
pretrained.act_postprocess2 = nn.Sequential(
|
||||
readout_oper[1],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[1],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
nn.ConvTranspose2d(
|
||||
in_channels=features[1],
|
||||
out_channels=features[1],
|
||||
kernel_size=2,
|
||||
stride=2,
|
||||
padding=0,
|
||||
bias=True,
|
||||
dilation=1,
|
||||
groups=1,
|
||||
),
|
||||
)
|
||||
|
||||
pretrained.act_postprocess3 = nn.Sequential(
|
||||
readout_oper[2],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[2],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
)
|
||||
|
||||
pretrained.act_postprocess4 = nn.Sequential(
|
||||
readout_oper[3],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[3],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
nn.Conv2d(
|
||||
in_channels=features[3],
|
||||
out_channels=features[3],
|
||||
kernel_size=3,
|
||||
stride=2,
|
||||
padding=1,
|
||||
),
|
||||
)
|
||||
|
||||
pretrained.model.start_index = start_index
|
||||
pretrained.model.patch_size = [16, 16]
|
||||
|
||||
# We inject this function into the VisionTransformer instances so that
|
||||
# we can use it with interpolated position embeddings without modifying the library source.
|
||||
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
||||
pretrained.model._resize_pos_embed = types.MethodType(
|
||||
_resize_pos_embed, pretrained.model
|
||||
)
|
||||
|
||||
return pretrained
|
||||
|
||||
|
||||
def _make_pretrained_vitl16_384(pretrained, use_readout="ignore", hooks=None):
|
||||
model = timm.create_model("vit_large_patch16_384", pretrained=pretrained)
|
||||
|
||||
hooks = [5, 11, 17, 23] if hooks == None else hooks
|
||||
return _make_vit_b16_backbone(
|
||||
model,
|
||||
features=[256, 512, 1024, 1024],
|
||||
hooks=hooks,
|
||||
vit_features=1024,
|
||||
use_readout=use_readout,
|
||||
)
|
||||
|
||||
|
||||
def _make_pretrained_vitb16_384(pretrained, use_readout="ignore", hooks=None):
|
||||
model = timm.create_model("vit_base_patch16_384", pretrained=pretrained)
|
||||
|
||||
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
||||
return _make_vit_b16_backbone(
|
||||
model, features=[96, 192, 384, 768], hooks=hooks, use_readout=use_readout
|
||||
)
|
||||
|
||||
|
||||
def _make_pretrained_deitb16_384(pretrained, use_readout="ignore", hooks=None):
|
||||
model = timm.create_model("vit_deit_base_patch16_384", pretrained=pretrained)
|
||||
|
||||
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
||||
return _make_vit_b16_backbone(
|
||||
model, features=[96, 192, 384, 768], hooks=hooks, use_readout=use_readout
|
||||
)
|
||||
|
||||
|
||||
def _make_pretrained_deitb16_distil_384(pretrained, use_readout="ignore", hooks=None):
|
||||
model = timm.create_model(
|
||||
"vit_deit_base_distilled_patch16_384", pretrained=pretrained
|
||||
)
|
||||
|
||||
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
||||
return _make_vit_b16_backbone(
|
||||
model,
|
||||
features=[96, 192, 384, 768],
|
||||
hooks=hooks,
|
||||
use_readout=use_readout,
|
||||
start_index=2,
|
||||
)
|
||||
|
||||
|
||||
def _make_vit_b_rn50_backbone(
|
||||
model,
|
||||
features=[256, 512, 768, 768],
|
||||
size=[384, 384],
|
||||
hooks=[0, 1, 8, 11],
|
||||
vit_features=768,
|
||||
use_vit_only=False,
|
||||
use_readout="ignore",
|
||||
start_index=1,
|
||||
):
|
||||
pretrained = nn.Module()
|
||||
|
||||
pretrained.model = model
|
||||
|
||||
if use_vit_only == True:
|
||||
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
||||
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
||||
else:
|
||||
pretrained.model.patch_embed.backbone.stages[0].register_forward_hook(
|
||||
get_activation("1")
|
||||
)
|
||||
pretrained.model.patch_embed.backbone.stages[1].register_forward_hook(
|
||||
get_activation("2")
|
||||
)
|
||||
|
||||
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
||||
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
||||
|
||||
pretrained.activations = activations
|
||||
|
||||
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
||||
|
||||
if use_vit_only == True:
|
||||
pretrained.act_postprocess1 = nn.Sequential(
|
||||
readout_oper[0],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[0],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
nn.ConvTranspose2d(
|
||||
in_channels=features[0],
|
||||
out_channels=features[0],
|
||||
kernel_size=4,
|
||||
stride=4,
|
||||
padding=0,
|
||||
bias=True,
|
||||
dilation=1,
|
||||
groups=1,
|
||||
),
|
||||
)
|
||||
|
||||
pretrained.act_postprocess2 = nn.Sequential(
|
||||
readout_oper[1],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[1],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
nn.ConvTranspose2d(
|
||||
in_channels=features[1],
|
||||
out_channels=features[1],
|
||||
kernel_size=2,
|
||||
stride=2,
|
||||
padding=0,
|
||||
bias=True,
|
||||
dilation=1,
|
||||
groups=1,
|
||||
),
|
||||
)
|
||||
else:
|
||||
pretrained.act_postprocess1 = nn.Sequential(
|
||||
nn.Identity(), nn.Identity(), nn.Identity()
|
||||
)
|
||||
pretrained.act_postprocess2 = nn.Sequential(
|
||||
nn.Identity(), nn.Identity(), nn.Identity()
|
||||
)
|
||||
|
||||
pretrained.act_postprocess3 = nn.Sequential(
|
||||
readout_oper[2],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[2],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
)
|
||||
|
||||
pretrained.act_postprocess4 = nn.Sequential(
|
||||
readout_oper[3],
|
||||
Transpose(1, 2),
|
||||
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
||||
nn.Conv2d(
|
||||
in_channels=vit_features,
|
||||
out_channels=features[3],
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
),
|
||||
nn.Conv2d(
|
||||
in_channels=features[3],
|
||||
out_channels=features[3],
|
||||
kernel_size=3,
|
||||
stride=2,
|
||||
padding=1,
|
||||
),
|
||||
)
|
||||
|
||||
pretrained.model.start_index = start_index
|
||||
pretrained.model.patch_size = [16, 16]
|
||||
|
||||
# We inject this function into the VisionTransformer instances so that
|
||||
# we can use it with interpolated position embeddings without modifying the library source.
|
||||
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
||||
|
||||
# We inject this function into the VisionTransformer instances so that
|
||||
# we can use it with interpolated position embeddings without modifying the library source.
|
||||
pretrained.model._resize_pos_embed = types.MethodType(
|
||||
_resize_pos_embed, pretrained.model
|
||||
)
|
||||
|
||||
return pretrained
|
||||
|
||||
|
||||
def _make_pretrained_vitb_rn50_384(
|
||||
pretrained, use_readout="ignore", hooks=None, use_vit_only=False
|
||||
):
|
||||
model = timm.create_model("vit_base_resnet50_384", pretrained=pretrained)
|
||||
|
||||
hooks = [0, 1, 8, 11] if hooks == None else hooks
|
||||
return _make_vit_b_rn50_backbone(
|
||||
model,
|
||||
features=[256, 512, 768, 768],
|
||||
size=[384, 384],
|
||||
hooks=hooks,
|
||||
use_vit_only=use_vit_only,
|
||||
use_readout=use_readout,
|
||||
)
|
||||
@@ -1,189 +0,0 @@
|
||||
"""Utils for monoDepth."""
|
||||
import sys
|
||||
import re
|
||||
import numpy as np
|
||||
import cv2
|
||||
import torch
|
||||
|
||||
|
||||
def read_pfm(path):
|
||||
"""Read pfm file.
|
||||
|
||||
Args:
|
||||
path (str): path to file
|
||||
|
||||
Returns:
|
||||
tuple: (data, scale)
|
||||
"""
|
||||
with open(path, "rb") as file:
|
||||
|
||||
color = None
|
||||
width = None
|
||||
height = None
|
||||
scale = None
|
||||
endian = None
|
||||
|
||||
header = file.readline().rstrip()
|
||||
if header.decode("ascii") == "PF":
|
||||
color = True
|
||||
elif header.decode("ascii") == "Pf":
|
||||
color = False
|
||||
else:
|
||||
raise Exception("Not a PFM file: " + path)
|
||||
|
||||
dim_match = re.match(r"^(\d+)\s(\d+)\s$", file.readline().decode("ascii"))
|
||||
if dim_match:
|
||||
width, height = list(map(int, dim_match.groups()))
|
||||
else:
|
||||
raise Exception("Malformed PFM header.")
|
||||
|
||||
scale = float(file.readline().decode("ascii").rstrip())
|
||||
if scale < 0:
|
||||
# little-endian
|
||||
endian = "<"
|
||||
scale = -scale
|
||||
else:
|
||||
# big-endian
|
||||
endian = ">"
|
||||
|
||||
data = np.fromfile(file, endian + "f")
|
||||
shape = (height, width, 3) if color else (height, width)
|
||||
|
||||
data = np.reshape(data, shape)
|
||||
data = np.flipud(data)
|
||||
|
||||
return data, scale
|
||||
|
||||
|
||||
def write_pfm(path, image, scale=1):
|
||||
"""Write pfm file.
|
||||
|
||||
Args:
|
||||
path (str): pathto file
|
||||
image (array): data
|
||||
scale (int, optional): Scale. Defaults to 1.
|
||||
"""
|
||||
|
||||
with open(path, "wb") as file:
|
||||
color = None
|
||||
|
||||
if image.dtype.name != "float32":
|
||||
raise Exception("Image dtype must be float32.")
|
||||
|
||||
image = np.flipud(image)
|
||||
|
||||
if len(image.shape) == 3 and image.shape[2] == 3: # color image
|
||||
color = True
|
||||
elif (
|
||||
len(image.shape) == 2 or len(image.shape) == 3 and image.shape[2] == 1
|
||||
): # greyscale
|
||||
color = False
|
||||
else:
|
||||
raise Exception("Image must have H x W x 3, H x W x 1 or H x W dimensions.")
|
||||
|
||||
file.write("PF\n" if color else "Pf\n".encode())
|
||||
file.write("%d %d\n".encode() % (image.shape[1], image.shape[0]))
|
||||
|
||||
endian = image.dtype.byteorder
|
||||
|
||||
if endian == "<" or endian == "=" and sys.byteorder == "little":
|
||||
scale = -scale
|
||||
|
||||
file.write("%f\n".encode() % scale)
|
||||
|
||||
image.tofile(file)
|
||||
|
||||
|
||||
def read_image(path):
|
||||
"""Read image and output RGB image (0-1).
|
||||
|
||||
Args:
|
||||
path (str): path to file
|
||||
|
||||
Returns:
|
||||
array: RGB image (0-1)
|
||||
"""
|
||||
img = cv2.imread(path)
|
||||
|
||||
if img.ndim == 2:
|
||||
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
||||
|
||||
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) / 255.0
|
||||
|
||||
return img
|
||||
|
||||
|
||||
def resize_image(img):
|
||||
"""Resize image and make it fit for network.
|
||||
|
||||
Args:
|
||||
img (array): image
|
||||
|
||||
Returns:
|
||||
tensor: data ready for network
|
||||
"""
|
||||
height_orig = img.shape[0]
|
||||
width_orig = img.shape[1]
|
||||
|
||||
if width_orig > height_orig:
|
||||
scale = width_orig / 384
|
||||
else:
|
||||
scale = height_orig / 384
|
||||
|
||||
height = (np.ceil(height_orig / scale / 32) * 32).astype(int)
|
||||
width = (np.ceil(width_orig / scale / 32) * 32).astype(int)
|
||||
|
||||
img_resized = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA)
|
||||
|
||||
img_resized = (
|
||||
torch.from_numpy(np.transpose(img_resized, (2, 0, 1))).contiguous().float()
|
||||
)
|
||||
img_resized = img_resized.unsqueeze(0)
|
||||
|
||||
return img_resized
|
||||
|
||||
|
||||
def resize_depth(depth, width, height):
|
||||
"""Resize depth map and bring to CPU (numpy).
|
||||
|
||||
Args:
|
||||
depth (tensor): depth
|
||||
width (int): image width
|
||||
height (int): image height
|
||||
|
||||
Returns:
|
||||
array: processed depth
|
||||
"""
|
||||
depth = torch.squeeze(depth[0, :, :, :]).to("cpu")
|
||||
|
||||
depth_resized = cv2.resize(
|
||||
depth.numpy(), (width, height), interpolation=cv2.INTER_CUBIC
|
||||
)
|
||||
|
||||
return depth_resized
|
||||
|
||||
def write_depth(path, depth, bits=1):
|
||||
"""Write depth map to pfm and png file.
|
||||
|
||||
Args:
|
||||
path (str): filepath without extension
|
||||
depth (array): depth
|
||||
"""
|
||||
write_pfm(path + ".pfm", depth.astype(np.float32))
|
||||
|
||||
depth_min = depth.min()
|
||||
depth_max = depth.max()
|
||||
|
||||
max_val = (2**(8*bits))-1
|
||||
|
||||
if depth_max - depth_min > np.finfo("float").eps:
|
||||
out = max_val * (depth - depth_min) / (depth_max - depth_min)
|
||||
else:
|
||||
out = np.zeros(depth.shape, dtype=depth.type)
|
||||
|
||||
if bits == 1:
|
||||
cv2.imwrite(path + ".png", out.astype("uint8"))
|
||||
elif bits == 2:
|
||||
cv2.imwrite(path + ".png", out.astype("uint16"))
|
||||
|
||||
return
|
||||
@@ -1,201 +0,0 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "{}"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright 2021-present NAVER Corp.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
@@ -1,49 +0,0 @@
|
||||
import cv2
|
||||
import numpy as np
|
||||
import torch
|
||||
import os
|
||||
|
||||
from einops import rearrange
|
||||
from .models.mbv2_mlsd_tiny import MobileV2_MLSD_Tiny
|
||||
from .models.mbv2_mlsd_large import MobileV2_MLSD_Large
|
||||
from .utils import pred_lines
|
||||
from modules import devices
|
||||
from annotator.annotator_path import models_path
|
||||
|
||||
mlsdmodel = None
|
||||
remote_model_path = "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/mlsd_large_512_fp32.pth"
|
||||
old_modeldir = os.path.dirname(os.path.realpath(__file__))
|
||||
modeldir = os.path.join(models_path, "mlsd")
|
||||
|
||||
def unload_mlsd_model():
|
||||
global mlsdmodel
|
||||
if mlsdmodel is not None:
|
||||
mlsdmodel = mlsdmodel.cpu()
|
||||
|
||||
def apply_mlsd(input_image, thr_v, thr_d):
|
||||
global modelpath, mlsdmodel
|
||||
if mlsdmodel is None:
|
||||
modelpath = os.path.join(modeldir, "mlsd_large_512_fp32.pth")
|
||||
old_modelpath = os.path.join(old_modeldir, "mlsd_large_512_fp32.pth")
|
||||
if os.path.exists(old_modelpath):
|
||||
modelpath = old_modelpath
|
||||
elif not os.path.exists(modelpath):
|
||||
from basicsr.utils.download_util import load_file_from_url
|
||||
load_file_from_url(remote_model_path, model_dir=modeldir)
|
||||
mlsdmodel = MobileV2_MLSD_Large()
|
||||
mlsdmodel.load_state_dict(torch.load(modelpath), strict=True)
|
||||
mlsdmodel = mlsdmodel.to(devices.get_device_for("controlnet")).eval()
|
||||
|
||||
model = mlsdmodel
|
||||
assert input_image.ndim == 3
|
||||
img = input_image
|
||||
img_output = np.zeros_like(img)
|
||||
try:
|
||||
with torch.no_grad():
|
||||
lines = pred_lines(img, model, [img.shape[0], img.shape[1]], thr_v, thr_d)
|
||||
for line in lines:
|
||||
x_start, y_start, x_end, y_end = [int(val) for val in line]
|
||||
cv2.line(img_output, (x_start, y_start), (x_end, y_end), [255, 255, 255], 1)
|
||||
except Exception as e:
|
||||
pass
|
||||
return img_output[:, :, 0]
|
||||
@@ -1,292 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.model_zoo as model_zoo
|
||||
from torch.nn import functional as F
|
||||
|
||||
|
||||
class BlockTypeA(nn.Module):
|
||||
def __init__(self, in_c1, in_c2, out_c1, out_c2, upscale = True):
|
||||
super(BlockTypeA, self).__init__()
|
||||
self.conv1 = nn.Sequential(
|
||||
nn.Conv2d(in_c2, out_c2, kernel_size=1),
|
||||
nn.BatchNorm2d(out_c2),
|
||||
nn.ReLU(inplace=True)
|
||||
)
|
||||
self.conv2 = nn.Sequential(
|
||||
nn.Conv2d(in_c1, out_c1, kernel_size=1),
|
||||
nn.BatchNorm2d(out_c1),
|
||||
nn.ReLU(inplace=True)
|
||||
)
|
||||
self.upscale = upscale
|
||||
|
||||
def forward(self, a, b):
|
||||
b = self.conv1(b)
|
||||
a = self.conv2(a)
|
||||
if self.upscale:
|
||||
b = F.interpolate(b, scale_factor=2.0, mode='bilinear', align_corners=True)
|
||||
return torch.cat((a, b), dim=1)
|
||||
|
||||
|
||||
class BlockTypeB(nn.Module):
|
||||
def __init__(self, in_c, out_c):
|
||||
super(BlockTypeB, self).__init__()
|
||||
self.conv1 = nn.Sequential(
|
||||
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
||||
nn.BatchNorm2d(in_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
self.conv2 = nn.Sequential(
|
||||
nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
|
||||
nn.BatchNorm2d(out_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv1(x) + x
|
||||
x = self.conv2(x)
|
||||
return x
|
||||
|
||||
class BlockTypeC(nn.Module):
|
||||
def __init__(self, in_c, out_c):
|
||||
super(BlockTypeC, self).__init__()
|
||||
self.conv1 = nn.Sequential(
|
||||
nn.Conv2d(in_c, in_c, kernel_size=3, padding=5, dilation=5),
|
||||
nn.BatchNorm2d(in_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
self.conv2 = nn.Sequential(
|
||||
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
||||
nn.BatchNorm2d(in_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv1(x)
|
||||
x = self.conv2(x)
|
||||
x = self.conv3(x)
|
||||
return x
|
||||
|
||||
def _make_divisible(v, divisor, min_value=None):
|
||||
"""
|
||||
This function is taken from the original tf repo.
|
||||
It ensures that all layers have a channel number that is divisible by 8
|
||||
It can be seen here:
|
||||
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
|
||||
:param v:
|
||||
:param divisor:
|
||||
:param min_value:
|
||||
:return:
|
||||
"""
|
||||
if min_value is None:
|
||||
min_value = divisor
|
||||
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
|
||||
# Make sure that round down does not go down by more than 10%.
|
||||
if new_v < 0.9 * v:
|
||||
new_v += divisor
|
||||
return new_v
|
||||
|
||||
|
||||
class ConvBNReLU(nn.Sequential):
|
||||
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
|
||||
self.channel_pad = out_planes - in_planes
|
||||
self.stride = stride
|
||||
#padding = (kernel_size - 1) // 2
|
||||
|
||||
# TFLite uses slightly different padding than PyTorch
|
||||
if stride == 2:
|
||||
padding = 0
|
||||
else:
|
||||
padding = (kernel_size - 1) // 2
|
||||
|
||||
super(ConvBNReLU, self).__init__(
|
||||
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
|
||||
nn.BatchNorm2d(out_planes),
|
||||
nn.ReLU6(inplace=True)
|
||||
)
|
||||
self.max_pool = nn.MaxPool2d(kernel_size=stride, stride=stride)
|
||||
|
||||
|
||||
def forward(self, x):
|
||||
# TFLite uses different padding
|
||||
if self.stride == 2:
|
||||
x = F.pad(x, (0, 1, 0, 1), "constant", 0)
|
||||
#print(x.shape)
|
||||
|
||||
for module in self:
|
||||
if not isinstance(module, nn.MaxPool2d):
|
||||
x = module(x)
|
||||
return x
|
||||
|
||||
|
||||
class InvertedResidual(nn.Module):
|
||||
def __init__(self, inp, oup, stride, expand_ratio):
|
||||
super(InvertedResidual, self).__init__()
|
||||
self.stride = stride
|
||||
assert stride in [1, 2]
|
||||
|
||||
hidden_dim = int(round(inp * expand_ratio))
|
||||
self.use_res_connect = self.stride == 1 and inp == oup
|
||||
|
||||
layers = []
|
||||
if expand_ratio != 1:
|
||||
# pw
|
||||
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
|
||||
layers.extend([
|
||||
# dw
|
||||
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
|
||||
# pw-linear
|
||||
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
|
||||
nn.BatchNorm2d(oup),
|
||||
])
|
||||
self.conv = nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_res_connect:
|
||||
return x + self.conv(x)
|
||||
else:
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
class MobileNetV2(nn.Module):
|
||||
def __init__(self, pretrained=True):
|
||||
"""
|
||||
MobileNet V2 main class
|
||||
Args:
|
||||
num_classes (int): Number of classes
|
||||
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
|
||||
inverted_residual_setting: Network structure
|
||||
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
|
||||
Set to 1 to turn off rounding
|
||||
block: Module specifying inverted residual building block for mobilenet
|
||||
"""
|
||||
super(MobileNetV2, self).__init__()
|
||||
|
||||
block = InvertedResidual
|
||||
input_channel = 32
|
||||
last_channel = 1280
|
||||
width_mult = 1.0
|
||||
round_nearest = 8
|
||||
|
||||
inverted_residual_setting = [
|
||||
# t, c, n, s
|
||||
[1, 16, 1, 1],
|
||||
[6, 24, 2, 2],
|
||||
[6, 32, 3, 2],
|
||||
[6, 64, 4, 2],
|
||||
[6, 96, 3, 1],
|
||||
#[6, 160, 3, 2],
|
||||
#[6, 320, 1, 1],
|
||||
]
|
||||
|
||||
# only check the first element, assuming user knows t,c,n,s are required
|
||||
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
|
||||
raise ValueError("inverted_residual_setting should be non-empty "
|
||||
"or a 4-element list, got {}".format(inverted_residual_setting))
|
||||
|
||||
# building first layer
|
||||
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
|
||||
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
|
||||
features = [ConvBNReLU(4, input_channel, stride=2)]
|
||||
# building inverted residual blocks
|
||||
for t, c, n, s in inverted_residual_setting:
|
||||
output_channel = _make_divisible(c * width_mult, round_nearest)
|
||||
for i in range(n):
|
||||
stride = s if i == 0 else 1
|
||||
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
|
||||
input_channel = output_channel
|
||||
|
||||
self.features = nn.Sequential(*features)
|
||||
self.fpn_selected = [1, 3, 6, 10, 13]
|
||||
# weight initialization
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
nn.init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
if m.bias is not None:
|
||||
nn.init.zeros_(m.bias)
|
||||
elif isinstance(m, nn.BatchNorm2d):
|
||||
nn.init.ones_(m.weight)
|
||||
nn.init.zeros_(m.bias)
|
||||
elif isinstance(m, nn.Linear):
|
||||
nn.init.normal_(m.weight, 0, 0.01)
|
||||
nn.init.zeros_(m.bias)
|
||||
if pretrained:
|
||||
self._load_pretrained_model()
|
||||
|
||||
def _forward_impl(self, x):
|
||||
# This exists since TorchScript doesn't support inheritance, so the superclass method
|
||||
# (this one) needs to have a name other than `forward` that can be accessed in a subclass
|
||||
fpn_features = []
|
||||
for i, f in enumerate(self.features):
|
||||
if i > self.fpn_selected[-1]:
|
||||
break
|
||||
x = f(x)
|
||||
if i in self.fpn_selected:
|
||||
fpn_features.append(x)
|
||||
|
||||
c1, c2, c3, c4, c5 = fpn_features
|
||||
return c1, c2, c3, c4, c5
|
||||
|
||||
|
||||
def forward(self, x):
|
||||
return self._forward_impl(x)
|
||||
|
||||
def _load_pretrained_model(self):
|
||||
pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/mobilenet_v2-b0353104.pth')
|
||||
model_dict = {}
|
||||
state_dict = self.state_dict()
|
||||
for k, v in pretrain_dict.items():
|
||||
if k in state_dict:
|
||||
model_dict[k] = v
|
||||
state_dict.update(model_dict)
|
||||
self.load_state_dict(state_dict)
|
||||
|
||||
|
||||
class MobileV2_MLSD_Large(nn.Module):
|
||||
def __init__(self):
|
||||
super(MobileV2_MLSD_Large, self).__init__()
|
||||
|
||||
self.backbone = MobileNetV2(pretrained=False)
|
||||
## A, B
|
||||
self.block15 = BlockTypeA(in_c1= 64, in_c2= 96,
|
||||
out_c1= 64, out_c2=64,
|
||||
upscale=False)
|
||||
self.block16 = BlockTypeB(128, 64)
|
||||
|
||||
## A, B
|
||||
self.block17 = BlockTypeA(in_c1 = 32, in_c2 = 64,
|
||||
out_c1= 64, out_c2= 64)
|
||||
self.block18 = BlockTypeB(128, 64)
|
||||
|
||||
## A, B
|
||||
self.block19 = BlockTypeA(in_c1=24, in_c2=64,
|
||||
out_c1=64, out_c2=64)
|
||||
self.block20 = BlockTypeB(128, 64)
|
||||
|
||||
## A, B, C
|
||||
self.block21 = BlockTypeA(in_c1=16, in_c2=64,
|
||||
out_c1=64, out_c2=64)
|
||||
self.block22 = BlockTypeB(128, 64)
|
||||
|
||||
self.block23 = BlockTypeC(64, 16)
|
||||
|
||||
def forward(self, x):
|
||||
c1, c2, c3, c4, c5 = self.backbone(x)
|
||||
|
||||
x = self.block15(c4, c5)
|
||||
x = self.block16(x)
|
||||
|
||||
x = self.block17(c3, x)
|
||||
x = self.block18(x)
|
||||
|
||||
x = self.block19(c2, x)
|
||||
x = self.block20(x)
|
||||
|
||||
x = self.block21(c1, x)
|
||||
x = self.block22(x)
|
||||
x = self.block23(x)
|
||||
x = x[:, 7:, :, :]
|
||||
|
||||
return x
|
||||
@@ -1,275 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.model_zoo as model_zoo
|
||||
from torch.nn import functional as F
|
||||
|
||||
|
||||
class BlockTypeA(nn.Module):
|
||||
def __init__(self, in_c1, in_c2, out_c1, out_c2, upscale = True):
|
||||
super(BlockTypeA, self).__init__()
|
||||
self.conv1 = nn.Sequential(
|
||||
nn.Conv2d(in_c2, out_c2, kernel_size=1),
|
||||
nn.BatchNorm2d(out_c2),
|
||||
nn.ReLU(inplace=True)
|
||||
)
|
||||
self.conv2 = nn.Sequential(
|
||||
nn.Conv2d(in_c1, out_c1, kernel_size=1),
|
||||
nn.BatchNorm2d(out_c1),
|
||||
nn.ReLU(inplace=True)
|
||||
)
|
||||
self.upscale = upscale
|
||||
|
||||
def forward(self, a, b):
|
||||
b = self.conv1(b)
|
||||
a = self.conv2(a)
|
||||
b = F.interpolate(b, scale_factor=2.0, mode='bilinear', align_corners=True)
|
||||
return torch.cat((a, b), dim=1)
|
||||
|
||||
|
||||
class BlockTypeB(nn.Module):
|
||||
def __init__(self, in_c, out_c):
|
||||
super(BlockTypeB, self).__init__()
|
||||
self.conv1 = nn.Sequential(
|
||||
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
||||
nn.BatchNorm2d(in_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
self.conv2 = nn.Sequential(
|
||||
nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
|
||||
nn.BatchNorm2d(out_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv1(x) + x
|
||||
x = self.conv2(x)
|
||||
return x
|
||||
|
||||
class BlockTypeC(nn.Module):
|
||||
def __init__(self, in_c, out_c):
|
||||
super(BlockTypeC, self).__init__()
|
||||
self.conv1 = nn.Sequential(
|
||||
nn.Conv2d(in_c, in_c, kernel_size=3, padding=5, dilation=5),
|
||||
nn.BatchNorm2d(in_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
self.conv2 = nn.Sequential(
|
||||
nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
|
||||
nn.BatchNorm2d(in_c),
|
||||
nn.ReLU()
|
||||
)
|
||||
self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv1(x)
|
||||
x = self.conv2(x)
|
||||
x = self.conv3(x)
|
||||
return x
|
||||
|
||||
def _make_divisible(v, divisor, min_value=None):
|
||||
"""
|
||||
This function is taken from the original tf repo.
|
||||
It ensures that all layers have a channel number that is divisible by 8
|
||||
It can be seen here:
|
||||
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
|
||||
:param v:
|
||||
:param divisor:
|
||||
:param min_value:
|
||||
:return:
|
||||
"""
|
||||
if min_value is None:
|
||||
min_value = divisor
|
||||
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
|
||||
# Make sure that round down does not go down by more than 10%.
|
||||
if new_v < 0.9 * v:
|
||||
new_v += divisor
|
||||
return new_v
|
||||
|
||||
|
||||
class ConvBNReLU(nn.Sequential):
|
||||
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
|
||||
self.channel_pad = out_planes - in_planes
|
||||
self.stride = stride
|
||||
#padding = (kernel_size - 1) // 2
|
||||
|
||||
# TFLite uses slightly different padding than PyTorch
|
||||
if stride == 2:
|
||||
padding = 0
|
||||
else:
|
||||
padding = (kernel_size - 1) // 2
|
||||
|
||||
super(ConvBNReLU, self).__init__(
|
||||
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
|
||||
nn.BatchNorm2d(out_planes),
|
||||
nn.ReLU6(inplace=True)
|
||||
)
|
||||
self.max_pool = nn.MaxPool2d(kernel_size=stride, stride=stride)
|
||||
|
||||
|
||||
def forward(self, x):
|
||||
# TFLite uses different padding
|
||||
if self.stride == 2:
|
||||
x = F.pad(x, (0, 1, 0, 1), "constant", 0)
|
||||
#print(x.shape)
|
||||
|
||||
for module in self:
|
||||
if not isinstance(module, nn.MaxPool2d):
|
||||
x = module(x)
|
||||
return x
|
||||
|
||||
|
||||
class InvertedResidual(nn.Module):
|
||||
def __init__(self, inp, oup, stride, expand_ratio):
|
||||
super(InvertedResidual, self).__init__()
|
||||
self.stride = stride
|
||||
assert stride in [1, 2]
|
||||
|
||||
hidden_dim = int(round(inp * expand_ratio))
|
||||
self.use_res_connect = self.stride == 1 and inp == oup
|
||||
|
||||
layers = []
|
||||
if expand_ratio != 1:
|
||||
# pw
|
||||
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
|
||||
layers.extend([
|
||||
# dw
|
||||
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
|
||||
# pw-linear
|
||||
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
|
||||
nn.BatchNorm2d(oup),
|
||||
])
|
||||
self.conv = nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_res_connect:
|
||||
return x + self.conv(x)
|
||||
else:
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
class MobileNetV2(nn.Module):
|
||||
def __init__(self, pretrained=True):
|
||||
"""
|
||||
MobileNet V2 main class
|
||||
Args:
|
||||
num_classes (int): Number of classes
|
||||
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
|
||||
inverted_residual_setting: Network structure
|
||||
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
|
||||
Set to 1 to turn off rounding
|
||||
block: Module specifying inverted residual building block for mobilenet
|
||||
"""
|
||||
super(MobileNetV2, self).__init__()
|
||||
|
||||
block = InvertedResidual
|
||||
input_channel = 32
|
||||
last_channel = 1280
|
||||
width_mult = 1.0
|
||||
round_nearest = 8
|
||||
|
||||
inverted_residual_setting = [
|
||||
# t, c, n, s
|
||||
[1, 16, 1, 1],
|
||||
[6, 24, 2, 2],
|
||||
[6, 32, 3, 2],
|
||||
[6, 64, 4, 2],
|
||||
#[6, 96, 3, 1],
|
||||
#[6, 160, 3, 2],
|
||||
#[6, 320, 1, 1],
|
||||
]
|
||||
|
||||
# only check the first element, assuming user knows t,c,n,s are required
|
||||
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
|
||||
raise ValueError("inverted_residual_setting should be non-empty "
|
||||
"or a 4-element list, got {}".format(inverted_residual_setting))
|
||||
|
||||
# building first layer
|
||||
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
|
||||
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
|
||||
features = [ConvBNReLU(4, input_channel, stride=2)]
|
||||
# building inverted residual blocks
|
||||
for t, c, n, s in inverted_residual_setting:
|
||||
output_channel = _make_divisible(c * width_mult, round_nearest)
|
||||
for i in range(n):
|
||||
stride = s if i == 0 else 1
|
||||
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
|
||||
input_channel = output_channel
|
||||
self.features = nn.Sequential(*features)
|
||||
|
||||
self.fpn_selected = [3, 6, 10]
|
||||
# weight initialization
|
||||
for m in self.modules():
|
||||
if isinstance(m, nn.Conv2d):
|
||||
nn.init.kaiming_normal_(m.weight, mode='fan_out')
|
||||
if m.bias is not None:
|
||||
nn.init.zeros_(m.bias)
|
||||
elif isinstance(m, nn.BatchNorm2d):
|
||||
nn.init.ones_(m.weight)
|
||||
nn.init.zeros_(m.bias)
|
||||
elif isinstance(m, nn.Linear):
|
||||
nn.init.normal_(m.weight, 0, 0.01)
|
||||
nn.init.zeros_(m.bias)
|
||||
|
||||
#if pretrained:
|
||||
# self._load_pretrained_model()
|
||||
|
||||
def _forward_impl(self, x):
|
||||
# This exists since TorchScript doesn't support inheritance, so the superclass method
|
||||
# (this one) needs to have a name other than `forward` that can be accessed in a subclass
|
||||
fpn_features = []
|
||||
for i, f in enumerate(self.features):
|
||||
if i > self.fpn_selected[-1]:
|
||||
break
|
||||
x = f(x)
|
||||
if i in self.fpn_selected:
|
||||
fpn_features.append(x)
|
||||
|
||||
c2, c3, c4 = fpn_features
|
||||
return c2, c3, c4
|
||||
|
||||
|
||||
def forward(self, x):
|
||||
return self._forward_impl(x)
|
||||
|
||||
def _load_pretrained_model(self):
|
||||
pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/mobilenet_v2-b0353104.pth')
|
||||
model_dict = {}
|
||||
state_dict = self.state_dict()
|
||||
for k, v in pretrain_dict.items():
|
||||
if k in state_dict:
|
||||
model_dict[k] = v
|
||||
state_dict.update(model_dict)
|
||||
self.load_state_dict(state_dict)
|
||||
|
||||
|
||||
class MobileV2_MLSD_Tiny(nn.Module):
|
||||
def __init__(self):
|
||||
super(MobileV2_MLSD_Tiny, self).__init__()
|
||||
|
||||
self.backbone = MobileNetV2(pretrained=True)
|
||||
|
||||
self.block12 = BlockTypeA(in_c1= 32, in_c2= 64,
|
||||
out_c1= 64, out_c2=64)
|
||||
self.block13 = BlockTypeB(128, 64)
|
||||
|
||||
self.block14 = BlockTypeA(in_c1 = 24, in_c2 = 64,
|
||||
out_c1= 32, out_c2= 32)
|
||||
self.block15 = BlockTypeB(64, 64)
|
||||
|
||||
self.block16 = BlockTypeC(64, 16)
|
||||
|
||||
def forward(self, x):
|
||||
c2, c3, c4 = self.backbone(x)
|
||||
|
||||
x = self.block12(c3, c4)
|
||||
x = self.block13(x)
|
||||
x = self.block14(c2, x)
|
||||
x = self.block15(x)
|
||||
x = self.block16(x)
|
||||
x = x[:, 7:, :, :]
|
||||
#print(x.shape)
|
||||
x = F.interpolate(x, scale_factor=2.0, mode='bilinear', align_corners=True)
|
||||
|
||||
return x
|
||||
@@ -1,581 +0,0 @@
|
||||
'''
|
||||
modified by lihaoweicv
|
||||
pytorch version
|
||||
'''
|
||||
|
||||
'''
|
||||
M-LSD
|
||||
Copyright 2021-present NAVER Corp.
|
||||
Apache License v2.0
|
||||
'''
|
||||
|
||||
import os
|
||||
import numpy as np
|
||||
import cv2
|
||||
import torch
|
||||
from torch.nn import functional as F
|
||||
from modules import devices
|
||||
|
||||
|
||||
def deccode_output_score_and_ptss(tpMap, topk_n = 200, ksize = 5):
|
||||
'''
|
||||
tpMap:
|
||||
center: tpMap[1, 0, :, :]
|
||||
displacement: tpMap[1, 1:5, :, :]
|
||||
'''
|
||||
b, c, h, w = tpMap.shape
|
||||
assert b==1, 'only support bsize==1'
|
||||
displacement = tpMap[:, 1:5, :, :][0]
|
||||
center = tpMap[:, 0, :, :]
|
||||
heat = torch.sigmoid(center)
|
||||
hmax = F.max_pool2d( heat, (ksize, ksize), stride=1, padding=(ksize-1)//2)
|
||||
keep = (hmax == heat).float()
|
||||
heat = heat * keep
|
||||
heat = heat.reshape(-1, )
|
||||
|
||||
scores, indices = torch.topk(heat, topk_n, dim=-1, largest=True)
|
||||
yy = torch.floor_divide(indices, w).unsqueeze(-1)
|
||||
xx = torch.fmod(indices, w).unsqueeze(-1)
|
||||
ptss = torch.cat((yy, xx),dim=-1)
|
||||
|
||||
ptss = ptss.detach().cpu().numpy()
|
||||
scores = scores.detach().cpu().numpy()
|
||||
displacement = displacement.detach().cpu().numpy()
|
||||
displacement = displacement.transpose((1,2,0))
|
||||
return ptss, scores, displacement
|
||||
|
||||
|
||||
def pred_lines(image, model,
|
||||
input_shape=[512, 512],
|
||||
score_thr=0.10,
|
||||
dist_thr=20.0):
|
||||
h, w, _ = image.shape
|
||||
h_ratio, w_ratio = [h / input_shape[0], w / input_shape[1]]
|
||||
|
||||
resized_image = np.concatenate([cv2.resize(image, (input_shape[1], input_shape[0]), interpolation=cv2.INTER_AREA),
|
||||
np.ones([input_shape[0], input_shape[1], 1])], axis=-1)
|
||||
|
||||
resized_image = resized_image.transpose((2,0,1))
|
||||
batch_image = np.expand_dims(resized_image, axis=0).astype('float32')
|
||||
batch_image = (batch_image / 127.5) - 1.0
|
||||
|
||||
batch_image = torch.from_numpy(batch_image).float().to(devices.get_device_for("controlnet"))
|
||||
outputs = model(batch_image)
|
||||
pts, pts_score, vmap = deccode_output_score_and_ptss(outputs, 200, 3)
|
||||
start = vmap[:, :, :2]
|
||||
end = vmap[:, :, 2:]
|
||||
dist_map = np.sqrt(np.sum((start - end) ** 2, axis=-1))
|
||||
|
||||
segments_list = []
|
||||
for center, score in zip(pts, pts_score):
|
||||
y, x = center
|
||||
distance = dist_map[y, x]
|
||||
if score > score_thr and distance > dist_thr:
|
||||
disp_x_start, disp_y_start, disp_x_end, disp_y_end = vmap[y, x, :]
|
||||
x_start = x + disp_x_start
|
||||
y_start = y + disp_y_start
|
||||
x_end = x + disp_x_end
|
||||
y_end = y + disp_y_end
|
||||
segments_list.append([x_start, y_start, x_end, y_end])
|
||||
|
||||
lines = 2 * np.array(segments_list) # 256 > 512
|
||||
lines[:, 0] = lines[:, 0] * w_ratio
|
||||
lines[:, 1] = lines[:, 1] * h_ratio
|
||||
lines[:, 2] = lines[:, 2] * w_ratio
|
||||
lines[:, 3] = lines[:, 3] * h_ratio
|
||||
|
||||
return lines
|
||||
|
||||
|
||||
def pred_squares(image,
|
||||
model,
|
||||
input_shape=[512, 512],
|
||||
params={'score': 0.06,
|
||||
'outside_ratio': 0.28,
|
||||
'inside_ratio': 0.45,
|
||||
'w_overlap': 0.0,
|
||||
'w_degree': 1.95,
|
||||
'w_length': 0.0,
|
||||
'w_area': 1.86,
|
||||
'w_center': 0.14}):
|
||||
'''
|
||||
shape = [height, width]
|
||||
'''
|
||||
h, w, _ = image.shape
|
||||
original_shape = [h, w]
|
||||
|
||||
resized_image = np.concatenate([cv2.resize(image, (input_shape[0], input_shape[1]), interpolation=cv2.INTER_AREA),
|
||||
np.ones([input_shape[0], input_shape[1], 1])], axis=-1)
|
||||
resized_image = resized_image.transpose((2, 0, 1))
|
||||
batch_image = np.expand_dims(resized_image, axis=0).astype('float32')
|
||||
batch_image = (batch_image / 127.5) - 1.0
|
||||
|
||||
batch_image = torch.from_numpy(batch_image).float().to(devices.get_device_for("controlnet"))
|
||||
outputs = model(batch_image)
|
||||
|
||||
pts, pts_score, vmap = deccode_output_score_and_ptss(outputs, 200, 3)
|
||||
start = vmap[:, :, :2] # (x, y)
|
||||
end = vmap[:, :, 2:] # (x, y)
|
||||
dist_map = np.sqrt(np.sum((start - end) ** 2, axis=-1))
|
||||
|
||||
junc_list = []
|
||||
segments_list = []
|
||||
for junc, score in zip(pts, pts_score):
|
||||
y, x = junc
|
||||
distance = dist_map[y, x]
|
||||
if score > params['score'] and distance > 20.0:
|
||||
junc_list.append([x, y])
|
||||
disp_x_start, disp_y_start, disp_x_end, disp_y_end = vmap[y, x, :]
|
||||
d_arrow = 1.0
|
||||
x_start = x + d_arrow * disp_x_start
|
||||
y_start = y + d_arrow * disp_y_start
|
||||
x_end = x + d_arrow * disp_x_end
|
||||
y_end = y + d_arrow * disp_y_end
|
||||
segments_list.append([x_start, y_start, x_end, y_end])
|
||||
|
||||
segments = np.array(segments_list)
|
||||
|
||||
####### post processing for squares
|
||||
# 1. get unique lines
|
||||
point = np.array([[0, 0]])
|
||||
point = point[0]
|
||||
start = segments[:, :2]
|
||||
end = segments[:, 2:]
|
||||
diff = start - end
|
||||
a = diff[:, 1]
|
||||
b = -diff[:, 0]
|
||||
c = a * start[:, 0] + b * start[:, 1]
|
||||
|
||||
d = np.abs(a * point[0] + b * point[1] - c) / np.sqrt(a ** 2 + b ** 2 + 1e-10)
|
||||
theta = np.arctan2(diff[:, 0], diff[:, 1]) * 180 / np.pi
|
||||
theta[theta < 0.0] += 180
|
||||
hough = np.concatenate([d[:, None], theta[:, None]], axis=-1)
|
||||
|
||||
d_quant = 1
|
||||
theta_quant = 2
|
||||
hough[:, 0] //= d_quant
|
||||
hough[:, 1] //= theta_quant
|
||||
_, indices, counts = np.unique(hough, axis=0, return_index=True, return_counts=True)
|
||||
|
||||
acc_map = np.zeros([512 // d_quant + 1, 360 // theta_quant + 1], dtype='float32')
|
||||
idx_map = np.zeros([512 // d_quant + 1, 360 // theta_quant + 1], dtype='int32') - 1
|
||||
yx_indices = hough[indices, :].astype('int32')
|
||||
acc_map[yx_indices[:, 0], yx_indices[:, 1]] = counts
|
||||
idx_map[yx_indices[:, 0], yx_indices[:, 1]] = indices
|
||||
|
||||
acc_map_np = acc_map
|
||||
# acc_map = acc_map[None, :, :, None]
|
||||
#
|
||||
# ### fast suppression using tensorflow op
|
||||
# acc_map = tf.constant(acc_map, dtype=tf.float32)
|
||||
# max_acc_map = tf.keras.layers.MaxPool2D(pool_size=(5, 5), strides=1, padding='same')(acc_map)
|
||||
# acc_map = acc_map * tf.cast(tf.math.equal(acc_map, max_acc_map), tf.float32)
|
||||
# flatten_acc_map = tf.reshape(acc_map, [1, -1])
|
||||
# topk_values, topk_indices = tf.math.top_k(flatten_acc_map, k=len(pts))
|
||||
# _, h, w, _ = acc_map.shape
|
||||
# y = tf.expand_dims(topk_indices // w, axis=-1)
|
||||
# x = tf.expand_dims(topk_indices % w, axis=-1)
|
||||
# yx = tf.concat([y, x], axis=-1)
|
||||
|
||||
### fast suppression using pytorch op
|
||||
acc_map = torch.from_numpy(acc_map_np).unsqueeze(0).unsqueeze(0)
|
||||
_,_, h, w = acc_map.shape
|
||||
max_acc_map = F.max_pool2d(acc_map,kernel_size=5, stride=1, padding=2)
|
||||
acc_map = acc_map * ( (acc_map == max_acc_map).float() )
|
||||
flatten_acc_map = acc_map.reshape([-1, ])
|
||||
|
||||
scores, indices = torch.topk(flatten_acc_map, len(pts), dim=-1, largest=True)
|
||||
yy = torch.div(indices, w, rounding_mode='floor').unsqueeze(-1)
|
||||
xx = torch.fmod(indices, w).unsqueeze(-1)
|
||||
yx = torch.cat((yy, xx), dim=-1)
|
||||
|
||||
yx = yx.detach().cpu().numpy()
|
||||
|
||||
topk_values = scores.detach().cpu().numpy()
|
||||
indices = idx_map[yx[:, 0], yx[:, 1]]
|
||||
basis = 5 // 2
|
||||
|
||||
merged_segments = []
|
||||
for yx_pt, max_indice, value in zip(yx, indices, topk_values):
|
||||
y, x = yx_pt
|
||||
if max_indice == -1 or value == 0:
|
||||
continue
|
||||
segment_list = []
|
||||
for y_offset in range(-basis, basis + 1):
|
||||
for x_offset in range(-basis, basis + 1):
|
||||
indice = idx_map[y + y_offset, x + x_offset]
|
||||
cnt = int(acc_map_np[y + y_offset, x + x_offset])
|
||||
if indice != -1:
|
||||
segment_list.append(segments[indice])
|
||||
if cnt > 1:
|
||||
check_cnt = 1
|
||||
current_hough = hough[indice]
|
||||
for new_indice, new_hough in enumerate(hough):
|
||||
if (current_hough == new_hough).all() and indice != new_indice:
|
||||
segment_list.append(segments[new_indice])
|
||||
check_cnt += 1
|
||||
if check_cnt == cnt:
|
||||
break
|
||||
group_segments = np.array(segment_list).reshape([-1, 2])
|
||||
sorted_group_segments = np.sort(group_segments, axis=0)
|
||||
x_min, y_min = sorted_group_segments[0, :]
|
||||
x_max, y_max = sorted_group_segments[-1, :]
|
||||
|
||||
deg = theta[max_indice]
|
||||
if deg >= 90:
|
||||
merged_segments.append([x_min, y_max, x_max, y_min])
|
||||
else:
|
||||
merged_segments.append([x_min, y_min, x_max, y_max])
|
||||
|
||||
# 2. get intersections
|
||||
new_segments = np.array(merged_segments) # (x1, y1, x2, y2)
|
||||
start = new_segments[:, :2] # (x1, y1)
|
||||
end = new_segments[:, 2:] # (x2, y2)
|
||||
new_centers = (start + end) / 2.0
|
||||
diff = start - end
|
||||
dist_segments = np.sqrt(np.sum(diff ** 2, axis=-1))
|
||||
|
||||
# ax + by = c
|
||||
a = diff[:, 1]
|
||||
b = -diff[:, 0]
|
||||
c = a * start[:, 0] + b * start[:, 1]
|
||||
pre_det = a[:, None] * b[None, :]
|
||||
det = pre_det - np.transpose(pre_det)
|
||||
|
||||
pre_inter_y = a[:, None] * c[None, :]
|
||||
inter_y = (pre_inter_y - np.transpose(pre_inter_y)) / (det + 1e-10)
|
||||
pre_inter_x = c[:, None] * b[None, :]
|
||||
inter_x = (pre_inter_x - np.transpose(pre_inter_x)) / (det + 1e-10)
|
||||
inter_pts = np.concatenate([inter_x[:, :, None], inter_y[:, :, None]], axis=-1).astype('int32')
|
||||
|
||||
# 3. get corner information
|
||||
# 3.1 get distance
|
||||
'''
|
||||
dist_segments:
|
||||
| dist(0), dist(1), dist(2), ...|
|
||||
dist_inter_to_segment1:
|
||||
| dist(inter,0), dist(inter,0), dist(inter,0), ... |
|
||||
| dist(inter,1), dist(inter,1), dist(inter,1), ... |
|
||||
...
|
||||
dist_inter_to_semgnet2:
|
||||
| dist(inter,0), dist(inter,1), dist(inter,2), ... |
|
||||
| dist(inter,0), dist(inter,1), dist(inter,2), ... |
|
||||
...
|
||||
'''
|
||||
|
||||
dist_inter_to_segment1_start = np.sqrt(
|
||||
np.sum(((inter_pts - start[:, None, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
||||
dist_inter_to_segment1_end = np.sqrt(
|
||||
np.sum(((inter_pts - end[:, None, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
||||
dist_inter_to_segment2_start = np.sqrt(
|
||||
np.sum(((inter_pts - start[None, :, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
||||
dist_inter_to_segment2_end = np.sqrt(
|
||||
np.sum(((inter_pts - end[None, :, :]) ** 2), axis=-1, keepdims=True)) # [n_batch, n_batch, 1]
|
||||
|
||||
# sort ascending
|
||||
dist_inter_to_segment1 = np.sort(
|
||||
np.concatenate([dist_inter_to_segment1_start, dist_inter_to_segment1_end], axis=-1),
|
||||
axis=-1) # [n_batch, n_batch, 2]
|
||||
dist_inter_to_segment2 = np.sort(
|
||||
np.concatenate([dist_inter_to_segment2_start, dist_inter_to_segment2_end], axis=-1),
|
||||
axis=-1) # [n_batch, n_batch, 2]
|
||||
|
||||
# 3.2 get degree
|
||||
inter_to_start = new_centers[:, None, :] - inter_pts
|
||||
deg_inter_to_start = np.arctan2(inter_to_start[:, :, 1], inter_to_start[:, :, 0]) * 180 / np.pi
|
||||
deg_inter_to_start[deg_inter_to_start < 0.0] += 360
|
||||
inter_to_end = new_centers[None, :, :] - inter_pts
|
||||
deg_inter_to_end = np.arctan2(inter_to_end[:, :, 1], inter_to_end[:, :, 0]) * 180 / np.pi
|
||||
deg_inter_to_end[deg_inter_to_end < 0.0] += 360
|
||||
|
||||
'''
|
||||
B -- G
|
||||
| |
|
||||
C -- R
|
||||
B : blue / G: green / C: cyan / R: red
|
||||
|
||||
0 -- 1
|
||||
| |
|
||||
3 -- 2
|
||||
'''
|
||||
# rename variables
|
||||
deg1_map, deg2_map = deg_inter_to_start, deg_inter_to_end
|
||||
# sort deg ascending
|
||||
deg_sort = np.sort(np.concatenate([deg1_map[:, :, None], deg2_map[:, :, None]], axis=-1), axis=-1)
|
||||
|
||||
deg_diff_map = np.abs(deg1_map - deg2_map)
|
||||
# we only consider the smallest degree of intersect
|
||||
deg_diff_map[deg_diff_map > 180] = 360 - deg_diff_map[deg_diff_map > 180]
|
||||
|
||||
# define available degree range
|
||||
deg_range = [60, 120]
|
||||
|
||||
corner_dict = {corner_info: [] for corner_info in range(4)}
|
||||
inter_points = []
|
||||
for i in range(inter_pts.shape[0]):
|
||||
for j in range(i + 1, inter_pts.shape[1]):
|
||||
# i, j > line index, always i < j
|
||||
x, y = inter_pts[i, j, :]
|
||||
deg1, deg2 = deg_sort[i, j, :]
|
||||
deg_diff = deg_diff_map[i, j]
|
||||
|
||||
check_degree = deg_diff > deg_range[0] and deg_diff < deg_range[1]
|
||||
|
||||
outside_ratio = params['outside_ratio'] # over ratio >>> drop it!
|
||||
inside_ratio = params['inside_ratio'] # over ratio >>> drop it!
|
||||
check_distance = ((dist_inter_to_segment1[i, j, 1] >= dist_segments[i] and \
|
||||
dist_inter_to_segment1[i, j, 0] <= dist_segments[i] * outside_ratio) or \
|
||||
(dist_inter_to_segment1[i, j, 1] <= dist_segments[i] and \
|
||||
dist_inter_to_segment1[i, j, 0] <= dist_segments[i] * inside_ratio)) and \
|
||||
((dist_inter_to_segment2[i, j, 1] >= dist_segments[j] and \
|
||||
dist_inter_to_segment2[i, j, 0] <= dist_segments[j] * outside_ratio) or \
|
||||
(dist_inter_to_segment2[i, j, 1] <= dist_segments[j] and \
|
||||
dist_inter_to_segment2[i, j, 0] <= dist_segments[j] * inside_ratio))
|
||||
|
||||
if check_degree and check_distance:
|
||||
corner_info = None
|
||||
|
||||
if (deg1 >= 0 and deg1 <= 45 and deg2 >= 45 and deg2 <= 120) or \
|
||||
(deg2 >= 315 and deg1 >= 45 and deg1 <= 120):
|
||||
corner_info, color_info = 0, 'blue'
|
||||
elif (deg1 >= 45 and deg1 <= 125 and deg2 >= 125 and deg2 <= 225):
|
||||
corner_info, color_info = 1, 'green'
|
||||
elif (deg1 >= 125 and deg1 <= 225 and deg2 >= 225 and deg2 <= 315):
|
||||
corner_info, color_info = 2, 'black'
|
||||
elif (deg1 >= 0 and deg1 <= 45 and deg2 >= 225 and deg2 <= 315) or \
|
||||
(deg2 >= 315 and deg1 >= 225 and deg1 <= 315):
|
||||
corner_info, color_info = 3, 'cyan'
|
||||
else:
|
||||
corner_info, color_info = 4, 'red' # we don't use it
|
||||
continue
|
||||
|
||||
corner_dict[corner_info].append([x, y, i, j])
|
||||
inter_points.append([x, y])
|
||||
|
||||
square_list = []
|
||||
connect_list = []
|
||||
segments_list = []
|
||||
for corner0 in corner_dict[0]:
|
||||
for corner1 in corner_dict[1]:
|
||||
connect01 = False
|
||||
for corner0_line in corner0[2:]:
|
||||
if corner0_line in corner1[2:]:
|
||||
connect01 = True
|
||||
break
|
||||
if connect01:
|
||||
for corner2 in corner_dict[2]:
|
||||
connect12 = False
|
||||
for corner1_line in corner1[2:]:
|
||||
if corner1_line in corner2[2:]:
|
||||
connect12 = True
|
||||
break
|
||||
if connect12:
|
||||
for corner3 in corner_dict[3]:
|
||||
connect23 = False
|
||||
for corner2_line in corner2[2:]:
|
||||
if corner2_line in corner3[2:]:
|
||||
connect23 = True
|
||||
break
|
||||
if connect23:
|
||||
for corner3_line in corner3[2:]:
|
||||
if corner3_line in corner0[2:]:
|
||||
# SQUARE!!!
|
||||
'''
|
||||
0 -- 1
|
||||
| |
|
||||
3 -- 2
|
||||
square_list:
|
||||
order: 0 > 1 > 2 > 3
|
||||
| x0, y0, x1, y1, x2, y2, x3, y3 |
|
||||
| x0, y0, x1, y1, x2, y2, x3, y3 |
|
||||
...
|
||||
connect_list:
|
||||
order: 01 > 12 > 23 > 30
|
||||
| line_idx01, line_idx12, line_idx23, line_idx30 |
|
||||
| line_idx01, line_idx12, line_idx23, line_idx30 |
|
||||
...
|
||||
segments_list:
|
||||
order: 0 > 1 > 2 > 3
|
||||
| line_idx0_i, line_idx0_j, line_idx1_i, line_idx1_j, line_idx2_i, line_idx2_j, line_idx3_i, line_idx3_j |
|
||||
| line_idx0_i, line_idx0_j, line_idx1_i, line_idx1_j, line_idx2_i, line_idx2_j, line_idx3_i, line_idx3_j |
|
||||
...
|
||||
'''
|
||||
square_list.append(corner0[:2] + corner1[:2] + corner2[:2] + corner3[:2])
|
||||
connect_list.append([corner0_line, corner1_line, corner2_line, corner3_line])
|
||||
segments_list.append(corner0[2:] + corner1[2:] + corner2[2:] + corner3[2:])
|
||||
|
||||
def check_outside_inside(segments_info, connect_idx):
|
||||
# return 'outside or inside', min distance, cover_param, peri_param
|
||||
if connect_idx == segments_info[0]:
|
||||
check_dist_mat = dist_inter_to_segment1
|
||||
else:
|
||||
check_dist_mat = dist_inter_to_segment2
|
||||
|
||||
i, j = segments_info
|
||||
min_dist, max_dist = check_dist_mat[i, j, :]
|
||||
connect_dist = dist_segments[connect_idx]
|
||||
if max_dist > connect_dist:
|
||||
return 'outside', min_dist, 0, 1
|
||||
else:
|
||||
return 'inside', min_dist, -1, -1
|
||||
|
||||
top_square = None
|
||||
|
||||
try:
|
||||
map_size = input_shape[0] / 2
|
||||
squares = np.array(square_list).reshape([-1, 4, 2])
|
||||
score_array = []
|
||||
connect_array = np.array(connect_list)
|
||||
segments_array = np.array(segments_list).reshape([-1, 4, 2])
|
||||
|
||||
# get degree of corners:
|
||||
squares_rollup = np.roll(squares, 1, axis=1)
|
||||
squares_rolldown = np.roll(squares, -1, axis=1)
|
||||
vec1 = squares_rollup - squares
|
||||
normalized_vec1 = vec1 / (np.linalg.norm(vec1, axis=-1, keepdims=True) + 1e-10)
|
||||
vec2 = squares_rolldown - squares
|
||||
normalized_vec2 = vec2 / (np.linalg.norm(vec2, axis=-1, keepdims=True) + 1e-10)
|
||||
inner_products = np.sum(normalized_vec1 * normalized_vec2, axis=-1) # [n_squares, 4]
|
||||
squares_degree = np.arccos(inner_products) * 180 / np.pi # [n_squares, 4]
|
||||
|
||||
# get square score
|
||||
overlap_scores = []
|
||||
degree_scores = []
|
||||
length_scores = []
|
||||
|
||||
for connects, segments, square, degree in zip(connect_array, segments_array, squares, squares_degree):
|
||||
'''
|
||||
0 -- 1
|
||||
| |
|
||||
3 -- 2
|
||||
|
||||
# segments: [4, 2]
|
||||
# connects: [4]
|
||||
'''
|
||||
|
||||
###################################### OVERLAP SCORES
|
||||
cover = 0
|
||||
perimeter = 0
|
||||
# check 0 > 1 > 2 > 3
|
||||
square_length = []
|
||||
|
||||
for start_idx in range(4):
|
||||
end_idx = (start_idx + 1) % 4
|
||||
|
||||
connect_idx = connects[start_idx] # segment idx of segment01
|
||||
start_segments = segments[start_idx]
|
||||
end_segments = segments[end_idx]
|
||||
|
||||
start_point = square[start_idx]
|
||||
end_point = square[end_idx]
|
||||
|
||||
# check whether outside or inside
|
||||
start_position, start_min, start_cover_param, start_peri_param = check_outside_inside(start_segments,
|
||||
connect_idx)
|
||||
end_position, end_min, end_cover_param, end_peri_param = check_outside_inside(end_segments, connect_idx)
|
||||
|
||||
cover += dist_segments[connect_idx] + start_cover_param * start_min + end_cover_param * end_min
|
||||
perimeter += dist_segments[connect_idx] + start_peri_param * start_min + end_peri_param * end_min
|
||||
|
||||
square_length.append(
|
||||
dist_segments[connect_idx] + start_peri_param * start_min + end_peri_param * end_min)
|
||||
|
||||
overlap_scores.append(cover / perimeter)
|
||||
######################################
|
||||
###################################### DEGREE SCORES
|
||||
'''
|
||||
deg0 vs deg2
|
||||
deg1 vs deg3
|
||||
'''
|
||||
deg0, deg1, deg2, deg3 = degree
|
||||
deg_ratio1 = deg0 / deg2
|
||||
if deg_ratio1 > 1.0:
|
||||
deg_ratio1 = 1 / deg_ratio1
|
||||
deg_ratio2 = deg1 / deg3
|
||||
if deg_ratio2 > 1.0:
|
||||
deg_ratio2 = 1 / deg_ratio2
|
||||
degree_scores.append((deg_ratio1 + deg_ratio2) / 2)
|
||||
######################################
|
||||
###################################### LENGTH SCORES
|
||||
'''
|
||||
len0 vs len2
|
||||
len1 vs len3
|
||||
'''
|
||||
len0, len1, len2, len3 = square_length
|
||||
len_ratio1 = len0 / len2 if len2 > len0 else len2 / len0
|
||||
len_ratio2 = len1 / len3 if len3 > len1 else len3 / len1
|
||||
length_scores.append((len_ratio1 + len_ratio2) / 2)
|
||||
|
||||
######################################
|
||||
|
||||
overlap_scores = np.array(overlap_scores)
|
||||
overlap_scores /= np.max(overlap_scores)
|
||||
|
||||
degree_scores = np.array(degree_scores)
|
||||
# degree_scores /= np.max(degree_scores)
|
||||
|
||||
length_scores = np.array(length_scores)
|
||||
|
||||
###################################### AREA SCORES
|
||||
area_scores = np.reshape(squares, [-1, 4, 2])
|
||||
area_x = area_scores[:, :, 0]
|
||||
area_y = area_scores[:, :, 1]
|
||||
correction = area_x[:, -1] * area_y[:, 0] - area_y[:, -1] * area_x[:, 0]
|
||||
area_scores = np.sum(area_x[:, :-1] * area_y[:, 1:], axis=-1) - np.sum(area_y[:, :-1] * area_x[:, 1:], axis=-1)
|
||||
area_scores = 0.5 * np.abs(area_scores + correction)
|
||||
area_scores /= (map_size * map_size) # np.max(area_scores)
|
||||
######################################
|
||||
|
||||
###################################### CENTER SCORES
|
||||
centers = np.array([[256 // 2, 256 // 2]], dtype='float32') # [1, 2]
|
||||
# squares: [n, 4, 2]
|
||||
square_centers = np.mean(squares, axis=1) # [n, 2]
|
||||
center2center = np.sqrt(np.sum((centers - square_centers) ** 2))
|
||||
center_scores = center2center / (map_size / np.sqrt(2.0))
|
||||
|
||||
'''
|
||||
score_w = [overlap, degree, area, center, length]
|
||||
'''
|
||||
score_w = [0.0, 1.0, 10.0, 0.5, 1.0]
|
||||
score_array = params['w_overlap'] * overlap_scores \
|
||||
+ params['w_degree'] * degree_scores \
|
||||
+ params['w_area'] * area_scores \
|
||||
- params['w_center'] * center_scores \
|
||||
+ params['w_length'] * length_scores
|
||||
|
||||
best_square = []
|
||||
|
||||
sorted_idx = np.argsort(score_array)[::-1]
|
||||
score_array = score_array[sorted_idx]
|
||||
squares = squares[sorted_idx]
|
||||
|
||||
except Exception as e:
|
||||
pass
|
||||
|
||||
'''return list
|
||||
merged_lines, squares, scores
|
||||
'''
|
||||
|
||||
try:
|
||||
new_segments[:, 0] = new_segments[:, 0] * 2 / input_shape[1] * original_shape[1]
|
||||
new_segments[:, 1] = new_segments[:, 1] * 2 / input_shape[0] * original_shape[0]
|
||||
new_segments[:, 2] = new_segments[:, 2] * 2 / input_shape[1] * original_shape[1]
|
||||
new_segments[:, 3] = new_segments[:, 3] * 2 / input_shape[0] * original_shape[0]
|
||||
except:
|
||||
new_segments = []
|
||||
|
||||
try:
|
||||
squares[:, :, 0] = squares[:, :, 0] * 2 / input_shape[1] * original_shape[1]
|
||||
squares[:, :, 1] = squares[:, :, 1] * 2 / input_shape[0] * original_shape[0]
|
||||
except:
|
||||
squares = []
|
||||
score_array = []
|
||||
|
||||
try:
|
||||
inter_points = np.array(inter_points)
|
||||
inter_points[:, 0] = inter_points[:, 0] * 2 / input_shape[1] * original_shape[1]
|
||||
inter_points[:, 1] = inter_points[:, 1] * 2 / input_shape[0] * original_shape[0]
|
||||
except:
|
||||
inter_points = []
|
||||
|
||||
return new_segments, squares, score_array, inter_points
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user