![]()
![]()
![]()
![]()
![]()
![]()

|
Vulkan KomputeThe General Purpose Vulkan Compute Framework. |
Blazing fast, lightweight, mobile-enabled, and optimized for advanced GPU processing usecases.
🔋 Documentation 💻 Import to your project ⌨ Tutorials 💾
Principles & Features
- Single header library for simple import to your project
- Documentation leveraging doxygen and sphinx
- BYOV: Bring-your-own-Vulkan design to play nice with existing Vulkan applications
- Non-Vulkan core naming conventions to disambiguate Vulkan vs Kompute components
- Fast development cycles with shader tooling, but robust static shader binary bundles for prod
- Explicit relationships for GPU and host memory ownership and memory management
- Providing simple usecases as well as advanced machine learning & data processing examples

Getting Started
Setup
Kompute is provided as a single header file Kompute.hpp that can be simply included in your code and integrated with the shared library.
This project is built using cmake providing a simple way to integrate as static or shared library.
Your first Kompute
Pass compute shader data in glsl/hlsl text or compiled SPIR-V format (or as path to the file).
int main() {
// You can allow Kompute to create the Vulkan components, or pass your existing ones
kp::Manager mgr; // Selects device 0 unless explicitly requested
auto tensorA = std::make_shared<kp::Tensor>(kp::Tensor({ 0, 1, 2 }));
auto tensorRhs = std::make_shared<kp::Tensor>(kp::Tensor({ 2, 4, 6 }));
// Define your shader as a string (using string literals for simplicity)
// (You can also pass the raw compiled bytes, or even path to file)
std::string shader(R"(
#version 450
layout (local_size_x = 1) in;
layout(set = 0, binding = 0) buffer a { float pa[]; };
layout(set = 0, binding = 1) buffer b { float pb[]; };
void main() {
uint index = gl_GlobalInvocationID.x;
pb[index] = pa[index];
pa[index] = index;
}
)");
// Create tensor data in GPU
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorA, tensorB });
// Run Kompute operation on the parameters provided with dispatch layout
mgr.evalOpDefault<kp::OpMult<3, 1, 1>>(
{ tensorLhs, tensorRhs, tensorOut },
true, // Whether to retrieve the output from GPU memory
std::vector<char>(shader.begin(), shader.end()));
// Prints the output which is A: { 0, 1, 2 } B: { 3, 4, 5 }
std::cout << fmt::format("A: {}, B: {}",
tensorA.data(), tensorB.data()) << std::endl;
}
Build your own pre-compiled operations for domain specific workflows.
We also provide tools that allow you to convert shaders into C++ headers.
template<uint32_t tX = 0, uint32_t tY = 0, uint32_t tZ = 0>
class OpMyCustom : public OpAlgoBase<tX, tY, tZ>
{
public:
OpMult(std::shared_ptr<vk::PhysicalDevice> physicalDevice,
std::shared_ptr<vk::Device> device,
std::shared_ptr<vk::CommandBuffer> commandBuffer,
std::vector<std::shared_ptr<Tensor>> tensors)
: OpAlgoBase<tX, tY, tZ>(physicalDevice, device, commandBuffer, tensors, true, "")
{
// Perform your custom steps such as reading from a shader file
this->mShaderFilePath = "shaders/glsl/opmult.comp";
}
}
int main() {
kp::Manager mgr; // Automatically selects Device 0
// Create 3 tensors of default type float
auto tensorLhs = std::make_shared<kp::Tensor>(kp::Tensor({ 0., 1., 2. }));
auto tensorRhs = std::make_shared<kp::Tensor>(kp::Tensor({ 2., 4., 6. }));
auto tensorOut = std::make_shared<kp::Tensor>(kp::Tensor({ 0., 0., 0. }));
// Create tensors data in GPU
mgr.evalOpDefault<kp::OpTensorCreate>({ tensorLhs, tensorRhs, tensorOut });
// Run Kompute operation on the parameters provided with dispatch layout
mgr.evalOpDefault<kp::OpMyCustom<3, 1, 1>>(
{ tensorLhs, tensorRhs, tensorOut });
// Prints the output which is { 0, 4, 12 }
std::cout << fmt::format("Output: {}", tensorOutput.data()) << std::endl;
}
Record commands in a single submit by using a Sequence to send in batch to GPU.
int main() {
kp::Manager mgr;
std::shared_ptr<kp::Tensor> tensorLHS{ new kp::Tensor({ 1., 1., 1. }) };
std::shared_ptr<kp::Tensor> tensorRHS{ new kp::Tensor( { 2., 2., 2. }) };
std::shared_ptr<kp::Tensor> tensorOutput{ new kp::Tensor({ 0., 0., 0. }) };
// Create all the tensors in memory
mgr.evalOpDefault<kp::OpCreateTensor>({tensorLHS, tensorRHS, tensorOutput});
// Create a new sequence
std::weak_ptr<kp::Sequence> sqWeakPtr = mgr.getOrCreateManagedSequence();
if (std::shared_ptr<kp::Sequence> sq = sqWeakPtr.lock())
{
// Begin recording commands
sq.begin();
// Record batch commands to send to GPU
sq.record<kp::OpMult<>>({ tensorLHS, tensorRHS, tensorOutput });
sq.record<kp::OpTensorCopy>({tensorOutput, tensorLHS, tensorRHS});
// Stop recording
sq.end();
// Submit multiple batch operations to GPU
size_t ITERATIONS = 5;
for (size_t i = 0; i < ITERATIONS; i++) {
sq.eval();
}
}
// Print the output which iterates through OpMult 5 times
// in this case the output is {32, 32 , 32}
std::cout << fmt::format("Output: {}", tensorOutput.data()) << std::endl;
}
Advanced Examples
We cover more advanced examples and applications of Vulkan Kompute, such as machine learning algorithms built on top of Kompute.
You can find these in the advanced examples documentation section, such as the logistic regression example.
Motivations
Vulkan Kompute was created after identifying the challenge most GPU processing projects with Vulkan undergo - namely having to build extensive boilerplate for Vulkan and create abstractions and interfaces that expose the core compute capabilities. It is only after a few thousand lines of code that it's possible to start building the application-specific logic.
We believe Vulkan has an excellent design in its way to interact with the GPU, so by no means we aim to abstract or hide any complexity, but instead we want to provide a baseline of tools and interfaces that allow Vulkan Compute developers to focus on the higher level computational complexities of the application.
It is because of this that we have adopted development principles for the project that ensure the Vulkan API is augmented specifically for computation, whilst speeding development iterations and opening the doors to further use-cases.
Components & Architecture
The core architecture of Kompute include the following:
- Kompute Manager - Base orchestrator which creates and manages device and child components
- Kompute Sequence - Container of operations that can be sent to GPU as batch
- Kompute Operation - Individual operation which performs actions on top of tensors and (opt) algorithms
- Kompute Tensor - Tensor structured data used in GPU operations
- Kompute Algorithm - Abstraction for (shader) code executed in the GPU
- Kompute ParameterGroup - Container that can group tensors to be fed into an algorithm
To see a full breakdown you can read further in the documentation.
| Full Vulkan Components | Simplified Kompute Components |
|---|---|
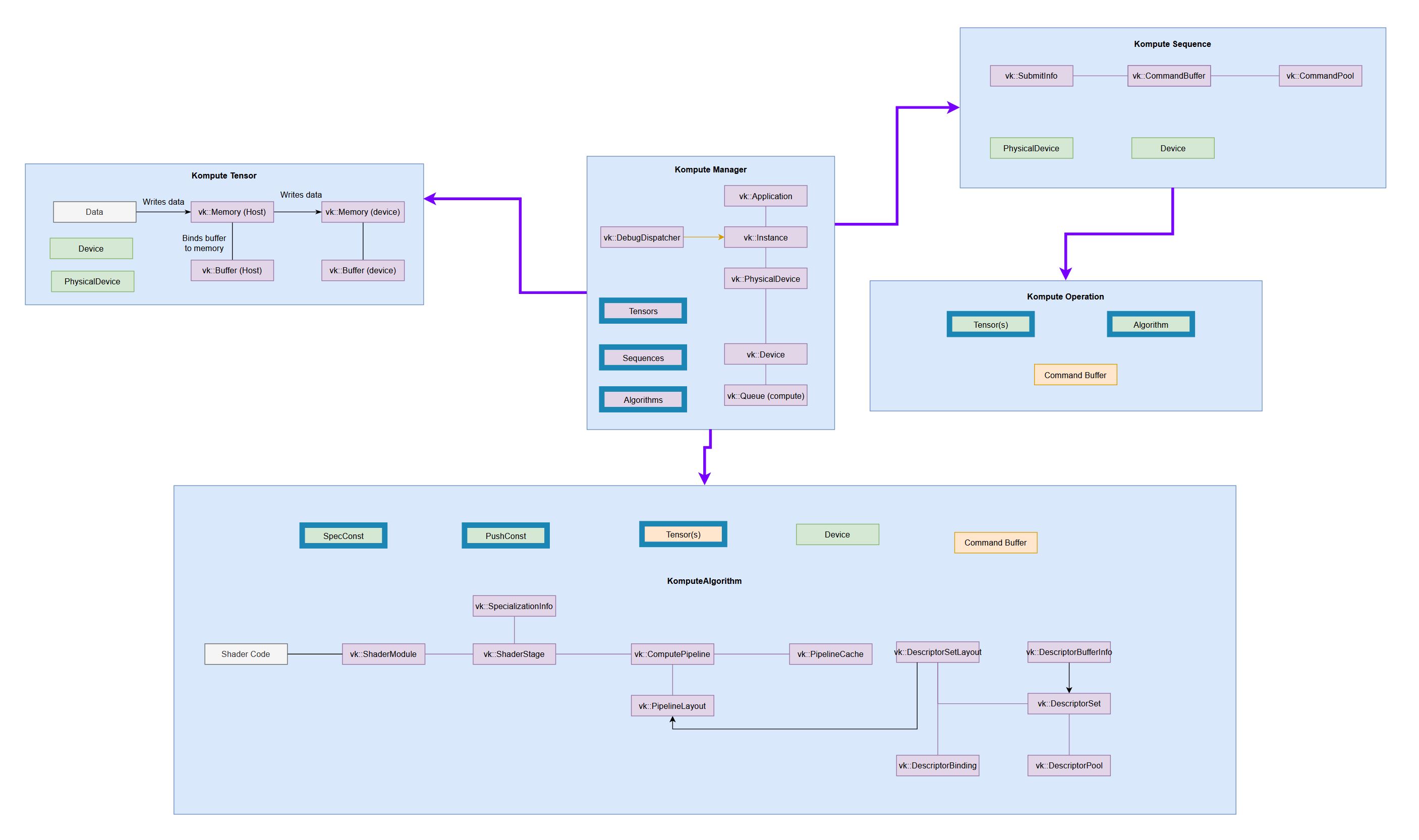
(very tiny, check the docs to for details) 
|
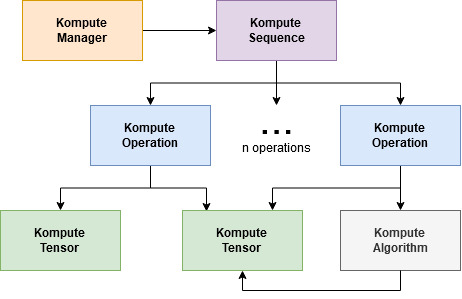
|
Build Overview
Dependencies
Given Kompute is expected to be used across a broad range of architectures and hardware, it will be important to make sure we are able to minimise dependencies.
Required dependencies
The only required dependency in the build is Vulkan (vulkan.h and vulkan.hpp which are both part of the Vulkan SDK).
Optional dependencies
SPDLOG is the preferred logging library, however by default Vulkan Kompute runs without SPDLOG by overriding the macros. It also provides an easy way to override the macros if you prefer to bring your own logging framework. The macro override is the following:
#ifndef KOMPUTE_LOG_OVERRIDE // Use this if you want to define custom macro overrides
#if KOMPUTE_SPDLOG_ENABLED // Use this if you want to enable SPDLOG
#include <spdlog/spdlog.h>
#endif //KOMPUTE_SPDLOG_ENABLED
// ... Otherwise it adds macros that use std::cout (and only print first element)
#endif // KOMPUTE_LOG_OVERRIDE
You can choose to build with or without SPDLOG by using the cmake flag KOMPUTE_OPT_ENABLE_SPDLOG.
Finally, remember that you will still need to set both the compile time log level with SPDLOG_ACTIVE_LEVEL, and the runtime log level with spdlog::set_level(spdlog::level::debug);.
Kompute Development
We appreciate PRs and Issues. If you want to contribute try checking the "Good first issue" tag, but even using Vulkan Kompute and reporting issues is a great contribution!
Contributing
Dev Dependencies
- Testing
- GTest
- Documentation
- Doxygen (with Dot)
- Sphynx
Development
- Follows Mozilla C++ Style Guide https://www-archive.mozilla.org/hacking/mozilla-style-guide.html
- Uses post-commit hook to run the linter, you can set it up so it runs the linter before commit
- All dependencies are defined in vcpkg.json
- Uses cmake as build system, and provides a top level makefile with recommended command
- Uses xxd (or xxd.exe windows 64bit port) to convert shader spirv to header files
- Uses doxygen and sphinx for documentation and autodocs
- Uses vcpkg for finding the dependencies, it's the recommanded set up to retrieve the libraries
Updating documentation
To update the documentation will need to:
- Run the gendoxygen target in the build system
- Run the gensphynx target in the buildsystem
- Push to github pages with
make push_docs_to_ghpages
Running tests
To run tests you can use the helper top level Makefile
For visual studio you can run
make vs_cmake
make vs_run_tests VS_BUILD_TYPE="Release"
For unix you can run
make mk_cmake MK_BUILD_TYPE="Release"
make mk_run_tests