mirror of
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
synced 2026-01-27 03:29:55 +00:00
Compare commits
20 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
2dc1dfea86 | ||
|
|
18556c6115 | ||
|
|
82355cdb60 | ||
|
|
2c6b6e7f13 | ||
|
|
abb5625e55 | ||
|
|
d5de786d07 | ||
|
|
f8a9223c29 | ||
|
|
61a97175a7 | ||
|
|
92a08205d0 | ||
|
|
372a499615 | ||
|
|
ca717948a4 | ||
|
|
6c6999d5f1 | ||
|
|
f7f5101f62 | ||
|
|
e49862d422 | ||
|
|
524514bd46 | ||
|
|
106fa13f65 | ||
|
|
a038664616 | ||
|
|
789f44d52a | ||
|
|
59ec54b171 | ||
|
|
983da36329 |
129
README.md
129
README.md
@@ -9,20 +9,13 @@ This custom script serves as a drop-in extension for the popular [AUTOMATIC1111
|
||||
It displays autocompletion hints for recognized tags from "image booru" boards such as Danbooru, which are primarily used for browsing Anime-style illustrations.
|
||||
Since some Stable Diffusion models were trained using this information, for example [Waifu Diffusion](https://github.com/harubaru/waifu-diffusion), using exact tags in prompts can often improve composition and help to achieve a wanted look.
|
||||
|
||||
I created this script as a convenience tool since it reduces the need of switching back and forth between the web UI and a booru site to copy-paste tags.
|
||||
|
||||
You can either clone / download the files manually as described [below](#installation), or use a pre-packaged version from [Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases).
|
||||
|
||||
## Common Problems & Known Issues:
|
||||
- The browser might cache old versions of the script, config, or embedding/wildcard lists. Try hitting `CTRL+F5` to clear the cache.
|
||||
- If `replaceUnderscores` is active, the script will currently only partly replace edited tags containing multiple words in brackets.
|
||||
- The browser might cache old versions of the script, config, or embedding/wildcard lists. Try hitting `CTRL+F5` to clear the cache if you have issues.
|
||||
- If `replaceUnderscores` is active, the script will currently only partially replace edited tags containing multiple words in brackets.
|
||||
For example, editing `atago (azur lane)`, it would be replaced with e.g. `taihou (azur lane), lane)`, since the script currently doesn't see the second part of the bracket as the same tag. So in those cases you should delete the old tag beforehand.
|
||||
|
||||
### Wildcard & Embedding support
|
||||
Autocompletion also works with wildcard files used by [this script](https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py) of the same name (demo video further down). This enables you to either insert categories to be replaced by the script, or even replace them with the actual wildcard file content in the same step. Wildcards are searched for in every extension folder as well as the `scripts/wildcards` folder to support legacy versions. This means that you can combine wildcards from multiple extensions. Nested folders are also supported if you have grouped your wildcards in that way.
|
||||
|
||||
It also scans the embeddings folder and displays completion hints for the names of all .pt and .bin files inside if you start typing `<`. Note that some normal tags also use < in Kaomoji (like ">_<" for example), so the results will contain both.
|
||||
|
||||
## Screenshots
|
||||
Demo video (with keyboard navigation):
|
||||
|
||||
@@ -58,6 +51,11 @@ After scanning for embeddings and wildcards, the script will also create a `temp
|
||||
### Important:
|
||||
The script needs **all three folders** to work properly.
|
||||
|
||||
## Wildcard & Embedding support
|
||||
Autocompletion also works with wildcard files used by [this script](https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py) of the same name or other similar scripts/extensions. This enables you to either insert categories to be replaced by the script, or even replace them with the actual wildcard file content in the same step. Wildcards are searched for in every extension folder as well as the `scripts/wildcards` folder to support legacy versions. This means that you can combine wildcards from multiple extensions. Nested folders are also supported if you have grouped your wildcards in that way.
|
||||
|
||||
It also scans the embeddings folder and displays completion hints for the names of all .pt and .bin files inside if you start typing `<`. Note that some normal tags also use < in Kaomoji (like ">_<" for example), so the results will contain both.
|
||||
|
||||
## Config
|
||||
The config contains the following settings and defaults:
|
||||
```json
|
||||
@@ -68,24 +66,33 @@ The config contains the following settings and defaults:
|
||||
"img2img": true,
|
||||
"negativePrompts": true
|
||||
},
|
||||
"hideUIOptions": false,
|
||||
"maxResults": 5,
|
||||
"resultStepLength": 500,
|
||||
"delayTime": 100,
|
||||
"showAllResults": false,
|
||||
"useLeftRightArrowKeys": false,
|
||||
"replaceUnderscores": true,
|
||||
"escapeParentheses": true,
|
||||
"appendComma": true,
|
||||
"useWildcards": true,
|
||||
"useEmbeddings": true,
|
||||
"alias": {
|
||||
"searchByAlias": true,
|
||||
"onlyShowAlias": false
|
||||
},
|
||||
"translation": {
|
||||
"searchByTranslation": true,
|
||||
"onlyShowTranslation": false
|
||||
"translationFile": "",
|
||||
"oldFormat": false,
|
||||
"searchByTranslation": true
|
||||
},
|
||||
"extra": {
|
||||
"extraFile": "",
|
||||
"onlyTranslationExtraFile": false
|
||||
"onlyAliasExtraFile": false
|
||||
},
|
||||
"colors": {
|
||||
"danbooru": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
@@ -110,74 +117,92 @@ The config contains the following settings and defaults:
|
||||
|---------|-------------|
|
||||
| tagFile | Specifies the tag file to use. You can provide a custom tag database of your liking, but since the script was developed with Danbooru tags in mind, it might not work properly with other configurations.|
|
||||
| activeIn | Allows to selectively (de)activate the script for txt2img, img2img, and the negative prompts for both. |
|
||||
| hideUIOptions | Allows to hide the added GUI options at the top of the page to adjust active and comma settings without restarting. |
|
||||
| maxResults | How many results to show max. For the default tag set, the results are ordered by occurence count. For embeddings and wildcards it will show all results in a scrollable list. |
|
||||
| resultStepLength | Allows to load results in smaller batches of the specified size for better performance in long lists or if showAllResults is true. |
|
||||
| delayTime | Specifies how much to wait in milliseconds before triggering autocomplete. Helps prevent too frequent updates while typing. |
|
||||
| showAllResults | If true, will ignore maxResults and show all results in a scrollable list. **Warning:** can lag your browser for long lists. |
|
||||
| useLeftRightArrowKeys | If true, left and right arrows will select the first/last result in the popup instead of moving the cursor in the textbox. |
|
||||
| replaceUnderscores | If true, undescores are replaced with spaces on clicking a tag. Might work better for some models. |
|
||||
| escapeParentheses | If true, escapes tags containing () so they don't contribute to the web UI's prompt weighting functionality. |
|
||||
| appendComma | Specifies the starting value of the "Append commas" UI switch. If UI options are disabled, this will always be used. |
|
||||
| useWildcards | Used to toggle the wildcard completion functionality. |
|
||||
| useEmbeddings | Used to toggle the embedding completion functionality. |
|
||||
| translation | Options for translating tags. More info in the section below. |
|
||||
| extras | Options for additional tag files / translations. More info in the section below. |
|
||||
| alias | Options for aliases. More info in the section below. |
|
||||
| translation | Options for translations. More info in the section below. |
|
||||
| extras | Options for additional tag files / aliases / translations. More info in the section below. |
|
||||
| colors | Contains customizable colors for the tag types, you can add new ones here for custom tag files (same name as filename, without the .csv). The first value is for dark, the second for light mode. Color names and hex codes should both work.|
|
||||
|
||||
### Translations & Extra tags
|
||||
With the recent update it is now possible to add translations to the tags. These will be searchable / shown according to the settings in `config.json`:
|
||||
- `searchByTranslation` - Whether to search for the translated term as well or only the English tag.
|
||||
- `onlyShowTranslation` - Replaces the English tag with its translation if it has one. Only for displaying, the inserted text at the end is still the English tag.
|
||||
### Aliases, Translations & Extra tags
|
||||
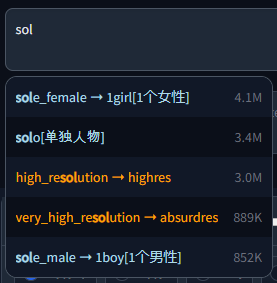
#### Aliases
|
||||
Like on Booru sites, tags can have one or multiple aliases which redirect to the actual value on completion. These will be searchable / shown according to the settings in `config.json`:
|
||||
- `searchByAlias` - Whether to also search for the alias or only the actual tag.
|
||||
- `onlyShowAlias` - Shows only the alias instead of `alias -> actual`. Only for displaying, the inserted text at the end is still the actual tag.
|
||||
|
||||
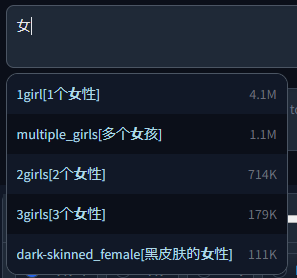
Example with full and partial chinese tag sets:
|
||||
#### Translations
|
||||
An additional file can be added in the translation section, which will be used to translate both tags and aliases and also enables searching by translation.
|
||||
This file needs to be a CSV in the format `<English tag/alias>,<Translation>`, but for backwards compatibility with older extra files that used a three column format, you can turn on `oldFormat` to use that instead.
|
||||
|
||||

|
||||

|
||||
Example with chinese translation:
|
||||
|
||||
Translations can be added in multiple ways, which is where the "Extra" file comes into play.
|
||||
1. Directly in the main tag file. Simply add a third value, separated by comma, containing the translation for the tag in that row.
|
||||
2. As an extra file containing only the translated tag rows (so still including the english Tag name and tag type). Will be matched to the English tags in the main file based on the name & type, so might be slow for large translation files.
|
||||
3. As an extra file with `onlyTranslationExtraFile` true. With this configuration, the extra file has to include *only* the translation itself. That means it is purely index based, assigning the translations to the main tags is really fast but also needs the lines to match (including empty lines). If the order or amount in the main file changes, the translations will potentially not match anymore.
|
||||
|
||||
|
||||
|
||||
**Important**
|
||||
As of a recent update, translations added in the old Extra file way will only work as an alias and not be visible anymore if typing the English tag for that translation.
|
||||
|
||||
#### Extra file
|
||||
Aliases can be added in multiple ways, which is where the "Extra" file comes into play.
|
||||
1. As an extra file containing tag, category, optional count and the new alias. Will be matched to the English tags in the main file based on the name & type, so might be slow for large files.
|
||||
2. As an extra file with `onlyAliasExtraFile` true. With this configuration, the extra file has to include *only* the alias itself. That means it is purely index based, assigning the aliases to the main tags is really fast but also needs the lines to match (including empty lines). If the order or amount in the main file changes, the translations will potentially not match anymore. Not recommended.
|
||||
|
||||
So your CSV values would look like this for each method:
|
||||
| | 1 | 2 | 3 |
|
||||
|------------|---------------------|--------------------|---------------|
|
||||
| Main file | `tag,0,translation` | `tag,0` | `tag,0` |
|
||||
| Extra file | - | `tag,0,translation`| `translation` |
|
||||
| | 1 | 2 |
|
||||
|------------|--------------------------|--------------------------|
|
||||
| Main file | `tag,type,count,(alias)` | `tag,type,count,(alias)` |
|
||||
| Extra file | `tag,type,(count),alias` | `alias` |
|
||||
|
||||
Methods 1 & 2 can also be mixed, in which case translations in the extra file will have priority over those in the main file if they translate the same tag.
|
||||
Count in the extra file is optional, since there isn't always a post count for custom tag sets.
|
||||
|
||||
The extra files can also be used to just add new / custom tags not included in the main set, provided `onlyTranslationExtraFile` is false.
|
||||
If an extra tag doesn't match any existing tag, it will be added to the list as a new tag instead.
|
||||
The extra files can also be used to just add new / custom tags not included in the main set, provided `onlyAliasExtraFile` is false.
|
||||
If an extra tag doesn't match any existing tag, it will be added to the list as a new tag instead. For this, it will need to include the post count and alias columns even if they don't contain anything, so it could be in the form of `tag,type,,`.
|
||||
|
||||
## CSV tag data
|
||||
The script expects a CSV file with tags saved in the following way:
|
||||
```csv
|
||||
1girl,0
|
||||
solo,0
|
||||
highres,5
|
||||
long_hair,0
|
||||
<name>,<type>,<postCount>,"<aliases>"
|
||||
```
|
||||
Notably, it does not expect column names in the first row.
|
||||
The first value needs to be the tag name, while the second value specifies the tag type. An optional third value will be interpreted as a translation as described in the section above.
|
||||
Example:
|
||||
```csv
|
||||
1girl,0,4114588,"1girls,sole_female"
|
||||
solo,0,3426446,"female_solo,solo_female"
|
||||
highres,5,3008413,"high_res,high_resolution,hires"
|
||||
long_hair,0,2898315,longhair
|
||||
commentary_request,5,2610959,
|
||||
```
|
||||
Notably, it does not expect column names in the first row and both count and aliases are technically optional,
|
||||
although count is always included in the default data. Multiple aliases need to be comma separated as well, but encased in string quotes to not break the CSV parsing.
|
||||
|
||||
The numbering system follows the [tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags) of Danbooru:
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Meta |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Meta |
|
||||
|
||||
or of e621:
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|-1 | Invalid |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Species |
|
||||
|6 | Invalid |
|
||||
|7 | Meta |
|
||||
|8 | Lore |
|
||||
|-1 | Invalid |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Species |
|
||||
|6 | Invalid |
|
||||
|7 | Meta |
|
||||
|8 | Lore |
|
||||
|
||||
The tag type is used for coloring entries in the result list.
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
var acConfig = null;
|
||||
var acActive = true;
|
||||
var acAppendComma = false;
|
||||
|
||||
// Style for new elements. Gets appended to the Gradio root.
|
||||
let autocompleteCSS_dark = `
|
||||
@@ -26,6 +27,22 @@ let autocompleteCSS_dark = `
|
||||
.autocompleteResultsList > li.selected {
|
||||
background-color: #374151;
|
||||
}
|
||||
.resultsFlexContainer {
|
||||
display: flex;
|
||||
}
|
||||
.acListItem {
|
||||
max-width: 400px;
|
||||
overflow: hidden;
|
||||
white-space: nowrap;
|
||||
text-overflow: ellipsis;
|
||||
}
|
||||
.acPostCount {
|
||||
position: relative;
|
||||
text-align: end;
|
||||
padding: 0 0 0 15px;
|
||||
flex-grow: 1;
|
||||
color: #6b6f7b;
|
||||
}
|
||||
`;
|
||||
let autocompleteCSS_light = `
|
||||
.autocompleteResults {
|
||||
@@ -51,6 +68,22 @@ let autocompleteCSS_light = `
|
||||
.autocompleteResultsList > li.selected {
|
||||
background-color: #e5e7eb;
|
||||
}
|
||||
.resultsFlexContainer {
|
||||
display: flex;
|
||||
}
|
||||
.acListItem {
|
||||
max-width: 400px;
|
||||
overflow: hidden;
|
||||
white-space: nowrap;
|
||||
text-overflow: ellipsis;
|
||||
}
|
||||
.acPostCount {
|
||||
position: relative;
|
||||
text-align: end;
|
||||
padding: 0 0 0 15px;
|
||||
flex-grow: 1;
|
||||
color: #a2a9b4;
|
||||
}
|
||||
`;
|
||||
|
||||
// Parse the CSV file into a 2D array. Doesn't use regex, so it is very lightweight.
|
||||
@@ -92,15 +125,24 @@ function parseCSV(str) {
|
||||
|
||||
// Load file
|
||||
function readFile(filePath) {
|
||||
let request = new XMLHttpRequest();
|
||||
request.open("GET", filePath, false);
|
||||
request.send(null);
|
||||
return request.responseText;
|
||||
return new Promise(function (resolve, reject) {
|
||||
let request = new XMLHttpRequest();
|
||||
request.open("GET", filePath, true);
|
||||
request.onload = function () {
|
||||
var status = request.status;
|
||||
if (status == 200) {
|
||||
resolve(request.responseText);
|
||||
} else {
|
||||
reject(status);
|
||||
}
|
||||
};
|
||||
request.send(null);
|
||||
});
|
||||
}
|
||||
|
||||
// Load CSV
|
||||
function loadCSV(path) {
|
||||
let text = readFile(path);
|
||||
async function loadCSV(path) {
|
||||
let text = await readFile(path);
|
||||
return parseCSV(text);
|
||||
}
|
||||
|
||||
@@ -176,7 +218,7 @@ function createResultsDiv(textArea) {
|
||||
}
|
||||
|
||||
// Create the checkbox to enable/disable autocomplete
|
||||
function createCheckbox() {
|
||||
function createCheckbox(text) {
|
||||
let label = document.createElement("label");
|
||||
let input = document.createElement("input");
|
||||
let span = document.createElement("span");
|
||||
@@ -187,7 +229,7 @@ function createCheckbox() {
|
||||
input.setAttribute('class', 'gr-check-radio gr-checkbox')
|
||||
span.setAttribute('class', 'ml-2');
|
||||
|
||||
span.textContent = "Enable Autocomplete";
|
||||
span.textContent = text;
|
||||
|
||||
label.appendChild(input);
|
||||
label.appendChild(span);
|
||||
@@ -219,7 +261,14 @@ function hideResults(textArea) {
|
||||
function escapeRegExp(string) {
|
||||
return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string
|
||||
}
|
||||
function escapeHTML(unsafeText) {
|
||||
let div = document.createElement('div');
|
||||
div.textContent = unsafeText;
|
||||
return div.innerHTML;
|
||||
}
|
||||
|
||||
const WEIGHT_REGEX = /[([]([^,()[\]:| ]+)(?::(?:\d+(?:\.\d+)?|\.\d+))?[)\]]/g;
|
||||
const TAG_REGEX = /([^\s,|]+)/g
|
||||
let hideBlocked = false;
|
||||
|
||||
// On click, insert the tag into the prompt textbox with respect to the cursor position
|
||||
@@ -259,8 +308,8 @@ function insertTextAtCursor(textArea, result, tagword) {
|
||||
let afterInsertCursorPos = editStart + match.index + sanitizedText.length;
|
||||
|
||||
var optionalComma = "";
|
||||
if (tagType !== "wildcardFile") {
|
||||
optionalComma = surrounding.match(new RegExp(escapeRegExp(`${tagword},`), "i")) !== null ? "" : ", ";
|
||||
if (acAppendComma && tagType !== "wildcardFile") {
|
||||
optionalComma = surrounding.match(new RegExp(`${escapeRegExp(tagword)}[,:]`, "i")) !== null ? "" : ", ";
|
||||
}
|
||||
|
||||
// Replace partial tag word with new text, add comma if needed
|
||||
@@ -277,7 +326,13 @@ function insertTextAtCursor(textArea, result, tagword) {
|
||||
textArea.dispatchEvent(new Event("input", { bubbles: true }));
|
||||
|
||||
// Update previous tags with the edited prompt to prevent re-searching the same term
|
||||
let tags = newPrompt.match(/[^,\n\r ]+/g);
|
||||
let weightedTags = [...newPrompt.matchAll(WEIGHT_REGEX)]
|
||||
.map(match => match[1]);
|
||||
let tags = newPrompt.match(TAG_REGEX)
|
||||
if (weightedTags !== null) {
|
||||
tags = tags.filter(tag => !weightedTags.some(weighted => tag.includes(weighted)))
|
||||
.concat(weightedTags);
|
||||
}
|
||||
previousTags = tags;
|
||||
|
||||
// Hide results after inserting
|
||||
@@ -314,25 +369,79 @@ function addResultsToList(textArea, results, tagword, resetList) {
|
||||
let result = results[i];
|
||||
let li = document.createElement("li");
|
||||
|
||||
//suppost only show the translation to result
|
||||
if (result[2]) {
|
||||
li.textContent = result[2];
|
||||
if (!acConfig.translation.onlyShowTranslation) {
|
||||
li.textContent += " >> " + result[0];
|
||||
let flexDiv = document.createElement("div");
|
||||
flexDiv.classList.add("resultsFlexContainer");
|
||||
li.appendChild(flexDiv);
|
||||
|
||||
let itemText = document.createElement("div");
|
||||
itemText.classList.add("acListItem");
|
||||
flexDiv.appendChild(itemText);
|
||||
|
||||
let displayText = "";
|
||||
// If the tag matches the tagword, we don't need to display the alias
|
||||
if (result[3] && !result[0].includes(tagword)) { // Alias
|
||||
let splitAliases = result[3].split(",");
|
||||
let bestAlias = splitAliases.find(a => a.toLowerCase().includes(tagword));
|
||||
|
||||
// search in translations if no alias matches
|
||||
if (!bestAlias) {
|
||||
var translationKey = [...translations].find(pair => pair[0] === result[0] && pair[1].includes(tagword))[0];
|
||||
bestAlias = translationKey// ? translations.get(translationKey) : null;
|
||||
}
|
||||
} else {
|
||||
li.textContent = result[0];
|
||||
|
||||
displayText = escapeHTML(bestAlias);
|
||||
|
||||
// Append translation for alias if it exists and is not what the user typed
|
||||
if (translations.has(bestAlias) && translations.get(bestAlias) !== bestAlias && bestAlias !== result[0])
|
||||
displayText += `[${translations.get(bestAlias)}]`;
|
||||
|
||||
if (!acConfig.alias.onlyShowAlias && result[0] !== bestAlias)
|
||||
displayText += " ➝ " + result[0];
|
||||
} else { // No alias
|
||||
displayText = escapeHTML(result[0]);
|
||||
}
|
||||
|
||||
// Append translation for result if it exists
|
||||
if (translations.has(result[0]))
|
||||
displayText += `[${translations.get(result[0])}]`;
|
||||
|
||||
// Print search term bolded in result
|
||||
itemText.innerHTML = displayText.replace(tagword, `<b>${tagword}</b>`);
|
||||
|
||||
// Add post count & color if it's a tag
|
||||
// Wildcards & Embeds have no tag type
|
||||
if (!result[1].startsWith("wildcard") && result[1] !== "embedding") {
|
||||
// Set the color of the tag
|
||||
let tagType = result[1];
|
||||
let colorGroup = tagColors[tagFileName];
|
||||
// Default to danbooru scheme if no matching one is found
|
||||
if (colorGroup === undefined) colorGroup = tagColors["danbooru"];
|
||||
if (!colorGroup)
|
||||
colorGroup = tagColors["danbooru"];
|
||||
|
||||
li.style = `color: ${colorGroup[tagType][mode]};`;
|
||||
// Set tag type to invalid if not found
|
||||
if (!colorGroup[tagType])
|
||||
tagType = "-1";
|
||||
|
||||
itemText.style = `color: ${colorGroup[tagType][mode]};`;
|
||||
|
||||
// Post count
|
||||
if (result[2] && !isNaN(result[2])) {
|
||||
let postCount = result[2];
|
||||
let formatter;
|
||||
|
||||
// Danbooru formats numbers with a padded fraction for 1M or 1k, but not for 10/100k
|
||||
if (postCount >= 1000000 || (postCount >= 1000 && postCount < 10000))
|
||||
formatter = Intl.NumberFormat("en", { notation: "compact", minimumFractionDigits: 1, maximumFractionDigits: 1 });
|
||||
else
|
||||
formatter = Intl.NumberFormat("en", {notation: "compact"});
|
||||
|
||||
let formattedCount = formatter.format(postCount);
|
||||
|
||||
let countDiv = document.createElement("div");
|
||||
countDiv.textContent = formattedCount;
|
||||
countDiv.classList.add("acPostCount");
|
||||
flexDiv.appendChild(countDiv);
|
||||
}
|
||||
}
|
||||
|
||||
// Add listener
|
||||
@@ -369,10 +478,11 @@ var wildcardFiles = [];
|
||||
var wildcardExtFiles = [];
|
||||
var embeddings = [];
|
||||
var allTags = [];
|
||||
var translations = new Map();
|
||||
var results = [];
|
||||
var tagword = "";
|
||||
var resultCount = 0;
|
||||
function autocomplete(textArea, prompt, fixedTag = null) {
|
||||
async function autocomplete(textArea, prompt, fixedTag = null) {
|
||||
// Return if the function is deactivated in the UI
|
||||
if (!acActive) return;
|
||||
|
||||
@@ -384,12 +494,21 @@ function autocomplete(textArea, prompt, fixedTag = null) {
|
||||
|
||||
if (fixedTag === null) {
|
||||
// Match tags with RegEx to get the last edited one
|
||||
let tags = prompt.match(/[^,\n\r ]+/g);
|
||||
let diff = difference(tags, previousTags)
|
||||
// We also match for the weighting format (e.g. "tag:1.0") here, and combine the two to get the full tag word set
|
||||
let weightedTags = [...prompt.matchAll(WEIGHT_REGEX)]
|
||||
.map(match => match[1]);
|
||||
let tags = prompt.match(TAG_REGEX)
|
||||
if (weightedTags !== null) {
|
||||
tags = tags.filter(tag => !weightedTags.some(weighted => tag.includes(weighted)))
|
||||
.concat(weightedTags);
|
||||
}
|
||||
|
||||
let tagCountChange = tags.length - previousTags.length;
|
||||
let diff = difference(tags, previousTags);
|
||||
previousTags = tags;
|
||||
|
||||
// Guard for no difference / only whitespace remaining
|
||||
if (diff === null || diff.length === 0) {
|
||||
// Guard for no difference / only whitespace remaining / last edited tag was fully removed
|
||||
if (diff === null || diff.length === 0 || (diff.length === 1 && tagCountChange < 0)) {
|
||||
if (!hideBlocked) hideResults(textArea);
|
||||
return;
|
||||
}
|
||||
@@ -405,7 +524,7 @@ function autocomplete(textArea, prompt, fixedTag = null) {
|
||||
tagword = fixedTag;
|
||||
}
|
||||
|
||||
tagword = tagword.toLowerCase().trim();
|
||||
tagword = tagword.toLowerCase().replace(/[\n\r]/g, "");
|
||||
|
||||
if (acConfig.useWildcards && [...tagword.matchAll(/\b__([^, ]+)__([^, ]*)\b/g)].length > 0) {
|
||||
// Show wildcards from a file with that name
|
||||
@@ -421,8 +540,8 @@ function autocomplete(textArea, prompt, fixedTag = null) {
|
||||
else // Look in extensions wildcard files
|
||||
wcPair = wildcardExtFiles.find(x => x[1].toLowerCase() === wcFile);
|
||||
|
||||
let wildcards = readFile(`file/${wcPair[0]}/${wcPair[1]}.txt`).split("\n")
|
||||
.filter(x => x.trim().length > 0); // Remove empty lines
|
||||
let wildcards = (await readFile(`file/${wcPair[0]}/${wcPair[1]}.txt?${new Date().getTime()}`)).split("\n")
|
||||
.filter(x => x.trim().length > 0 && !x.startsWith('#')); // Remove empty lines and comments
|
||||
|
||||
results = wildcards.filter(x => (wcWord !== null && wcWord.length > 0) ? x.toLowerCase().includes(wcWord) : x) // Filter by tagword
|
||||
.map(x => [wcFile + ": " + x.trim(), "wildcardTag"]); // Mark as wildcard
|
||||
@@ -448,17 +567,29 @@ function autocomplete(textArea, prompt, fixedTag = null) {
|
||||
genericResults = allTags.filter(x => x[0].toLowerCase().includes(tagword)).slice(0, acConfig.maxResults);
|
||||
results = genericResults.concat(tempResults.map(x => ["Embeddings: " + x.trim(), "embedding"])); // Mark as embedding
|
||||
} else {
|
||||
if (acConfig.translation.searchByTranslation) {
|
||||
results = allTags.filter(x => x[2] && x[2].toLowerCase().includes(tagword)); // check have translation
|
||||
// if search by [a~z],first list the translations, and then search English if it is not enough
|
||||
// if only show translation,it is unnecessary to list English results
|
||||
if (!acConfig.translation.onlyShowTranslation) {
|
||||
results = results.concat(allTags.filter(x => x[0].toLowerCase().includes(tagword) && !results.includes(x)));
|
||||
}
|
||||
// If onlyShowAlias is enabled, we don't need to include normal results
|
||||
if (acConfig.alias.onlyShowAlias) {
|
||||
results = allTags.filter(x => x[3] && x[3].toLowerCase().includes(tagword));
|
||||
} else {
|
||||
results = allTags.filter(x => x[0].toLowerCase().includes(tagword));
|
||||
// Else both normal tags and aliases/translations are included depending on the config
|
||||
let baseFilter = (x) => x[0].toLowerCase().includes(tagword);
|
||||
let aliasFilter = (x) => x[3] && x[3].toLowerCase().includes(tagword);
|
||||
let translationFilter = (x) => (translations.has(x[0]) && translations.get(x[0]).toLowerCase().includes(tagword))
|
||||
|| x[3] && x[3].split(",").some(y => translations.has(y) && translations.get(y).toLowerCase().includes(tagword));
|
||||
|
||||
let fil;
|
||||
if (acConfig.alias.searchByAlias && acConfig.translation.searchByTranslation)
|
||||
fil = (x) => baseFilter(x) || aliasFilter(x) || translationFilter(x);
|
||||
else if (acConfig.alias.searchByAlias && !acConfig.translation.searchByTranslation)
|
||||
fil = (x) => baseFilter(x) || aliasFilter(x);
|
||||
else if (acConfig.translation.searchByTranslation && !acConfig.alias.searchByAlias)
|
||||
fil = (x) => baseFilter(x) || translationFilter(x);
|
||||
else
|
||||
fil = (x) => baseFilter(x);
|
||||
|
||||
results = allTags.filter(fil);
|
||||
}
|
||||
// it's good to show all results
|
||||
// Slice if the user has set a max result count
|
||||
if (!acConfig.showAllResults) {
|
||||
results = results.slice(0, acConfig.maxResults);
|
||||
}
|
||||
@@ -559,70 +690,95 @@ function navigateInList(textArea, event) {
|
||||
event.stopPropagation();
|
||||
}
|
||||
|
||||
var styleAdded = false;
|
||||
onUiUpdate(function () {
|
||||
// One-time setup
|
||||
document.addEventListener("DOMContentLoaded", async () => {
|
||||
// Get our tag base path from the temp file
|
||||
let tagBasePath = readFile("file/tmp/tagAutocompletePath.txt");
|
||||
let tagBasePath = await readFile(`file/tmp/tagAutocompletePath.txt?${new Date().getTime()}`);
|
||||
|
||||
// Load config
|
||||
if (acConfig === null) {
|
||||
try {
|
||||
acConfig = JSON.parse(readFile(`file/${tagBasePath}/config.json`));
|
||||
if (acConfig.translation.onlyShowTranslation) {
|
||||
acConfig.translation.searchByTranslation = true; // if only show translation, enable search by translation is necessary
|
||||
acConfig = JSON.parse(await readFile(`file/${tagBasePath}/config.json?${new Date().getTime()}`));
|
||||
if (acConfig.alias.onlyShowAlias) {
|
||||
acConfig.alias.searchByAlias = true; // if only show translation, enable search by translation is necessary
|
||||
}
|
||||
} catch (e) {
|
||||
console.error("Error loading config.json: " + e);
|
||||
return;
|
||||
}
|
||||
}
|
||||
// Load main tags and translations
|
||||
// Load main tags and aliases
|
||||
if (allTags.length === 0) {
|
||||
try {
|
||||
allTags = loadCSV(`file/${tagBasePath}/${acConfig.tagFile}`);
|
||||
allTags = await loadCSV(`file/${tagBasePath}/${acConfig.tagFile}?${new Date().getTime()}`);
|
||||
} catch (e) {
|
||||
console.error("Error loading tags file: " + e);
|
||||
return;
|
||||
}
|
||||
if (acConfig.extra.extraFile) {
|
||||
try {
|
||||
extras = loadCSV(`file/${tagBasePath}/${acConfig.extra.extraFile}`);
|
||||
if (acConfig.extra.onlyTranslationExtraFile) {
|
||||
extras = await loadCSV(`file/${tagBasePath}/${acConfig.extra.extraFile}?${new Date().getTime()}`);
|
||||
if (acConfig.extra.onlyAliasExtraFile) {
|
||||
// This works purely on index, so it's not very robust. But a lot faster.
|
||||
for (let i = 0, n = extras.length; i < n; i++) {
|
||||
if (extras[i][0]) {
|
||||
allTags[i][2] = extras[i][0];
|
||||
let aliasStr = allTags[i][3] || "";
|
||||
let optComma = aliasStr.length > 0 ? "," : "";
|
||||
allTags[i][3] = aliasStr + optComma + extras[i][0];
|
||||
}
|
||||
}
|
||||
} else {
|
||||
extras.forEach(e => {
|
||||
// Check if a tag in allTags has the same name as the extra tag
|
||||
let hasCount = e[2] && e[3] || (!isNaN(e[2]) && !e[3]);
|
||||
// Check if a tag in allTags has the same name & category as the extra tag
|
||||
if (tag = allTags.find(t => t[0] === e[0] && t[1] == e[1])) {
|
||||
if (e[2]) // If the extra tag has a translation, add it to the tag
|
||||
tag[2] = e[2];
|
||||
if (hasCount && e[3] || isNaN(e[2])) { // If the extra tag has a translation / alias, add it to the normal tag
|
||||
let aliasStr = tag[3] || "";
|
||||
let optComma = aliasStr.length > 0 ? "," : "";
|
||||
let alias = hasCount && e[3] || isNaN(e[2]) ? e[2] : e[3];
|
||||
tag[3] = aliasStr + optComma + alias;
|
||||
}
|
||||
} else {
|
||||
let count = hasCount ? e[2] : null;
|
||||
let aliases = hasCount && e[3] ? e[3] : e[2];
|
||||
// If the tag doesn't exist, add it to allTags
|
||||
allTags.push(e);
|
||||
let newTag = [e[0], e[1], count, aliases];
|
||||
allTags.push(newTag);
|
||||
}
|
||||
});
|
||||
}
|
||||
} catch (e) {
|
||||
console.error("Error loading extra translation file: " + e);
|
||||
console.error("Error loading extra file: " + e);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
// Load wildcards
|
||||
if (wildcardFiles.length === 0 && acConfig.useWildcards) {
|
||||
// Load translations
|
||||
if (acConfig.translation.translationFile) {
|
||||
try {
|
||||
let wcFileArr = readFile(`file/${tagBasePath}/temp/wc.txt`).split("\n");
|
||||
let tArray = await loadCSV(`file/${tagBasePath}/${acConfig.translation.translationFile}?${new Date().getTime()}`);
|
||||
tArray.forEach(t => {
|
||||
if (acConfig.translation.oldFormat)
|
||||
translations.set(t[0], t[2]);
|
||||
else
|
||||
translations.set(t[0], t[1]);
|
||||
});
|
||||
} catch (e) {
|
||||
console.error("Error loading translations file: " + e);
|
||||
return;
|
||||
}
|
||||
}
|
||||
// Load wildcards
|
||||
if (acConfig.useWildcards && wildcardFiles.length === 0) {
|
||||
try {
|
||||
let wcFileArr = (await readFile(`file/${tagBasePath}/temp/wc.txt?${new Date().getTime()}`)).split("\n");
|
||||
let wcBasePath = wcFileArr[0].trim(); // First line should be the base path
|
||||
wildcardFiles = wcFileArr.slice(1)
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => [wcBasePath, x.trim().replace(".txt", "")]); // Remove file extension & newlines
|
||||
|
||||
// To support multiple sources, we need to separate them using the provided "-----" strings
|
||||
let wcExtFileArr = readFile(`file/${tagBasePath}/temp/wce.txt`).split("\n");
|
||||
let wcExtFileArr = (await readFile(`file/${tagBasePath}/temp/wce.txt?${new Date().getTime()}`)).split("\n");
|
||||
let splitIndices = [];
|
||||
for (let index = 0; index < wcExtFileArr.length; index++) {
|
||||
if (wcExtFileArr[index].trim() === "-----") {
|
||||
@@ -649,9 +805,9 @@ onUiUpdate(function () {
|
||||
}
|
||||
}
|
||||
// Load embeddings
|
||||
if (embeddings.length === 0 && acConfig.useEmbeddings) {
|
||||
if (acConfig.useEmbeddings && embeddings.length === 0) {
|
||||
try {
|
||||
embeddings = readFile(`file/${tagBasePath}/temp/emb.txt`).split("\n")
|
||||
embeddings = (await readFile(`file/${tagBasePath}/temp/emb.txt?${new Date().getTime()}`)).split("\n")
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => x.replace(".bin", "").replace(".pt", "").replace(".png", "")); // Remove file extensions
|
||||
} catch (e) {
|
||||
@@ -680,7 +836,6 @@ onUiUpdate(function () {
|
||||
}
|
||||
|
||||
textAreas.forEach(area => {
|
||||
|
||||
// Return if autocomplete is disabled for the current area type in config
|
||||
let textAreaId = getTextAreaIdentifier(area);
|
||||
if ((!acConfig.activeIn.img2img && textAreaId.includes("img2img"))
|
||||
@@ -703,23 +858,54 @@ onUiUpdate(function () {
|
||||
area.addEventListener('focusout', debounce(() => hideResults(area), 400));
|
||||
// Add up and down arrow event listener
|
||||
area.addEventListener('keydown', (e) => navigateInList(area, e));
|
||||
// CompositionEnd fires after the user has finished IME composing
|
||||
// We need to block hide here to prevent the enter key from insta-closing the results
|
||||
area.addEventListener('compositionend', () => {
|
||||
hideBlocked = true;
|
||||
setTimeout(() => { hideBlocked = false; }, 100);
|
||||
});
|
||||
|
||||
// Add class so we know we've already added the listeners
|
||||
area.classList.add('autocomplete');
|
||||
}
|
||||
});
|
||||
|
||||
if (gradioApp().querySelector("#acActiveCheckbox") === null) {
|
||||
acAppendComma = acConfig.appendComma;
|
||||
// Add our custom options elements
|
||||
if (!acConfig.hideUIOptions && gradioApp().querySelector("#tagAutocompleteOptions") === null) {
|
||||
let optionsDiv = document.createElement("div");
|
||||
optionsDiv.id = "tagAutocompleteOptions";
|
||||
optionsDiv.classList.add("flex", "flex-col", "p-1", "px-1", "relative", "text-sm");
|
||||
|
||||
let optionsInner = document.createElement("div");
|
||||
optionsInner.classList.add("flex", "flex-row", "p-1", "gap-4", "text-gray-700");
|
||||
|
||||
// Add label
|
||||
let title = document.createElement("p");
|
||||
title.textContent = "Autocomplete options";
|
||||
optionsDiv.appendChild(title);
|
||||
|
||||
// Add toggle switch
|
||||
let cb = createCheckbox();
|
||||
cb.querySelector("input").checked = acActive;
|
||||
cb.querySelector("input").addEventListener("change", (e) => {
|
||||
let cbActive = createCheckbox("Enable Autocomplete");
|
||||
cbActive.querySelector("input").checked = acActive;
|
||||
cbActive.querySelector("input").addEventListener("change", (e) => {
|
||||
acActive = e.target.checked;
|
||||
});
|
||||
quicksettings.parentNode.insertBefore(cb, quicksettings.nextSibling);
|
||||
}
|
||||
// Add comma switch
|
||||
let cbComma = createCheckbox("Append commas");
|
||||
cbComma.querySelector("input").checked = acAppendComma;
|
||||
cbComma.querySelector("input").addEventListener("change", (e) => {
|
||||
acAppendComma = e.target.checked;
|
||||
});
|
||||
|
||||
if (styleAdded) return;
|
||||
// Add options to optionsDiv
|
||||
optionsInner.appendChild(cbActive);
|
||||
optionsInner.appendChild(cbComma);
|
||||
optionsDiv.appendChild(optionsInner);
|
||||
|
||||
// Add options div to DOM
|
||||
quicksettings.parentNode.insertBefore(optionsDiv, quicksettings.nextSibling);
|
||||
}
|
||||
|
||||
// Add style to dom
|
||||
let acStyle = document.createElement('style');
|
||||
@@ -731,4 +917,4 @@ onUiUpdate(function () {
|
||||
}
|
||||
gradioApp().appendChild(acStyle);
|
||||
styleAdded = true;
|
||||
});
|
||||
});
|
||||
|
||||
@@ -11,17 +11,7 @@ FILE_DIR = Path().absolute()
|
||||
EXT_PATH = FILE_DIR.joinpath('extensions')
|
||||
|
||||
# Tags base path
|
||||
|
||||
|
||||
def get_tags_base_path():
|
||||
script_path = Path(scripts.basedir())
|
||||
if (script_path.is_relative_to(EXT_PATH)):
|
||||
return script_path.joinpath('tags')
|
||||
else:
|
||||
return FILE_DIR.joinpath('tags')
|
||||
|
||||
|
||||
TAGS_PATH = get_tags_base_path()
|
||||
TAGS_PATH = Path(scripts.basedir()).joinpath('tags')
|
||||
|
||||
# The path to the folder containing the wildcards and embeddings
|
||||
WILDCARD_PATH = FILE_DIR.joinpath('scripts/wildcards')
|
||||
@@ -30,7 +20,7 @@ EMB_PATH = FILE_DIR.joinpath('embeddings')
|
||||
|
||||
def find_ext_wildcard_paths():
|
||||
"""Returns the path to the extension wildcards folder"""
|
||||
found = list(EXT_PATH.rglob('**/wildcards/'))
|
||||
found = list(EXT_PATH.glob('*/wildcards/'))
|
||||
return found
|
||||
|
||||
|
||||
@@ -38,7 +28,8 @@ def find_ext_wildcard_paths():
|
||||
WILDCARD_EXT_PATHS = find_ext_wildcard_paths()
|
||||
|
||||
# The path to the temporary files
|
||||
TEMP_PATH = TAGS_PATH.joinpath('temp')
|
||||
STATIC_TEMP_PATH = FILE_DIR.joinpath('tmp') # In the webui root, on windows it exists by default, on linux it doesn't
|
||||
TEMP_PATH = TAGS_PATH.joinpath('temp') # Extension specific temp files
|
||||
|
||||
|
||||
def get_wildcards():
|
||||
@@ -55,8 +46,7 @@ def get_ext_wildcards():
|
||||
|
||||
for path in WILDCARD_EXT_PATHS:
|
||||
wildcard_files.append(path.relative_to(FILE_DIR).as_posix())
|
||||
wildcard_files.extend(p.relative_to(path).as_posix() for p in path.rglob(
|
||||
"*.txt") if p.name != "put wildcards here.txt")
|
||||
wildcard_files.extend(p.relative_to(path).as_posix() for p in path.rglob("*.txt") if p.name != "put wildcards here.txt")
|
||||
wildcard_files.append("-----")
|
||||
|
||||
return wildcard_files
|
||||
@@ -69,7 +59,7 @@ def get_embeddings():
|
||||
|
||||
def write_tag_base_path():
|
||||
"""Writes the tag base path to a fixed location temporary file"""
|
||||
with open(FILE_DIR.joinpath('tmp/tagAutocompletePath.txt'), 'w', encoding="utf-8") as f:
|
||||
with open(STATIC_TEMP_PATH.joinpath('tagAutocompletePath.txt'), 'w', encoding="utf-8") as f:
|
||||
f.write(TAGS_PATH.relative_to(FILE_DIR).as_posix())
|
||||
|
||||
|
||||
@@ -81,6 +71,9 @@ def write_to_temp_file(name, data):
|
||||
|
||||
# Write the tag base path to a fixed location temporary file
|
||||
# to enable the javascript side to find our files regardless of extension folder name
|
||||
if not STATIC_TEMP_PATH.exists():
|
||||
STATIC_TEMP_PATH.mkdir(exist_ok=True)
|
||||
|
||||
write_tag_base_path()
|
||||
|
||||
# Check if the temp path exists and create it if not
|
||||
@@ -95,8 +88,7 @@ write_to_temp_file('emb.txt', [])
|
||||
|
||||
# Write wildcards to wc.txt if found
|
||||
if WILDCARD_PATH.exists():
|
||||
wildcards = [WILDCARD_PATH.relative_to(
|
||||
FILE_DIR).as_posix()] + get_wildcards()
|
||||
wildcards = [WILDCARD_PATH.relative_to(FILE_DIR).as_posix()] + get_wildcards()
|
||||
if wildcards:
|
||||
write_to_temp_file('wc.txt', wildcards)
|
||||
|
||||
|
||||
@@ -5,6 +5,7 @@
|
||||
"img2img": true,
|
||||
"negativePrompts": true
|
||||
},
|
||||
"hideUIOptions": false,
|
||||
"maxResults": 5,
|
||||
"resultStepLength": 500,
|
||||
"delayTime": 100,
|
||||
@@ -12,18 +13,25 @@
|
||||
"useLeftRightArrowKeys": false,
|
||||
"replaceUnderscores": true,
|
||||
"escapeParentheses": true,
|
||||
"appendComma": true,
|
||||
"useWildcards": true,
|
||||
"useEmbeddings": true,
|
||||
"alias": {
|
||||
"searchByAlias": true,
|
||||
"onlyShowAlias": false
|
||||
},
|
||||
"translation": {
|
||||
"searchByTranslation": true,
|
||||
"onlyShowTranslation": false
|
||||
"translationFile": "",
|
||||
"oldFormat": false,
|
||||
"searchByTranslation": true
|
||||
},
|
||||
"extra": {
|
||||
"extraFile": "",
|
||||
"onlyTranslationExtraFile": false
|
||||
"onlyAliasExtraFile": false
|
||||
},
|
||||
"colors": {
|
||||
"danbooru": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
|
||||
209721
tags/danbooru.csv
209721
tags/danbooru.csv
File diff suppressed because it is too large
Load Diff
166094
tags/e621.csv
166094
tags/e621.csv
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user