mirror of
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
synced 2026-01-27 03:29:55 +00:00
Compare commits
110 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
8d9c0c7bb7 | ||
|
|
1c22a22abe | ||
|
|
f38c5df257 | ||
|
|
3332d62639 | ||
|
|
b159efe74e | ||
|
|
3789457702 | ||
|
|
35875a07a8 | ||
|
|
77c6a2b950 | ||
|
|
bc80b3ea2c | ||
|
|
a4e0b69d26 | ||
|
|
4f68a50a25 | ||
|
|
05c11c9781 | ||
|
|
def6ebb798 | ||
|
|
e4a8ee7439 | ||
|
|
1c3e60cfb2 | ||
|
|
fc4484ddc6 | ||
|
|
d6eb751e4b | ||
|
|
894335f1de | ||
|
|
2d45d6c796 | ||
|
|
dba4046064 | ||
|
|
ca8a0c433e | ||
|
|
535c2a6753 | ||
|
|
e86c604903 | ||
|
|
4eabf00f01 | ||
|
|
a39b0d0742 | ||
|
|
ecc71902cd | ||
|
|
2dc1dfea86 | ||
|
|
18556c6115 | ||
|
|
82355cdb60 | ||
|
|
2c6b6e7f13 | ||
|
|
abb5625e55 | ||
|
|
d5de786d07 | ||
|
|
f8a9223c29 | ||
|
|
61a97175a7 | ||
|
|
92a08205d0 | ||
|
|
372a499615 | ||
|
|
ca717948a4 | ||
|
|
6c6999d5f1 | ||
|
|
f7f5101f62 | ||
|
|
e49862d422 | ||
|
|
524514bd46 | ||
|
|
106fa13f65 | ||
|
|
a038664616 | ||
|
|
789f44d52a | ||
|
|
59ec54b171 | ||
|
|
983da36329 | ||
|
|
48bd3d7b51 | ||
|
|
c6c9e01410 | ||
|
|
bf5bb34605 | ||
|
|
860fd34fb4 | ||
|
|
886de4df29 | ||
|
|
3e71890489 | ||
|
|
dc77b3f17f | ||
|
|
40d53d89d1 | ||
|
|
c733b836e8 | ||
|
|
b537ca3938 | ||
|
|
cb08b8467f | ||
|
|
522989da8a | ||
|
|
e8cf50cdaa | ||
|
|
4af8d5285d | ||
|
|
3759ec055a | ||
|
|
ced6676aa6 | ||
|
|
6b3b8ccf45 | ||
|
|
353cb1937e | ||
|
|
c8c857f2cc | ||
|
|
0112acb820 | ||
|
|
896533c986 | ||
|
|
9fc9f1ab7d | ||
|
|
1d12fdcc6a | ||
|
|
1387351d4d | ||
|
|
4593a9a4e1 | ||
|
|
d5636f9026 | ||
|
|
59ccb7ac19 | ||
|
|
d8ec8793fa | ||
|
|
b0bc2d9b0b | ||
|
|
c67fd336fd | ||
|
|
5bf0451432 | ||
|
|
046e2d99fb | ||
|
|
cb31b072b4 | ||
|
|
b858370acf | ||
|
|
854b1952db | ||
|
|
f77283342e | ||
|
|
ae1ed19b7d | ||
|
|
5f1b8c8da3 | ||
|
|
db6dcc9568 | ||
|
|
53899093c8 | ||
|
|
f9d98740f4 | ||
|
|
534f07225e | ||
|
|
b8b0673e2d | ||
|
|
2f0d18a73f | ||
|
|
e68e7389dd | ||
|
|
b5cecc4e8d | ||
|
|
96828c241c | ||
|
|
07d7eddf66 | ||
|
|
08c10928f8 | ||
|
|
a628d96a41 | ||
|
|
3a47a9b010 | ||
|
|
fbfc988fe5 | ||
|
|
a93a209e7e | ||
|
|
f5c00d8de4 | ||
|
|
0b7bb146a5 | ||
|
|
f098b14248 | ||
|
|
9710eef4cc | ||
|
|
db29a6a84a | ||
|
|
4785142549 | ||
|
|
cddd9da700 | ||
|
|
ae02c749e9 | ||
|
|
fca985ba39 | ||
|
|
fff756cb86 | ||
|
|
7c21452560 |
1
.gitignore
vendored
Normal file
1
.gitignore
vendored
Normal file
@@ -0,0 +1 @@
|
||||
tags/temp/
|
||||
215
README.md
215
README.md
@@ -1,104 +1,181 @@
|
||||
# Booru tag autocompletion for A1111
|
||||
|
||||
[](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)
|
||||
|
||||
## [中文文档](./README_ZH.md)
|
||||
|
||||
This custom script serves as a drop-in extension for the popular [AUTOMATIC1111 web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) for Stable Diffusion.
|
||||
|
||||
It displays autocompletion hints for recognized tags from "image booru" boards such as Danbooru, which are primarily used for browsing Anime-style illustrations.
|
||||
Since some Stable Diffusion models were trained using this information, for example [Waifu Diffusion](https://github.com/harubaru/waifu-diffusion), using exact tags in prompts can often improve composition and help to achieve a wanted look.
|
||||
|
||||
I created this script as a convenience tool since it reduces the need of switching back and forth between the web UI and a booru site to copy-paste tags.
|
||||
You can install it using the inbuilt available extensions list, clone the files manually as described [below](#installation), or use a pre-packaged version from [Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases).
|
||||
|
||||
You can either download the files manually as described below, or use a pre-packaged version from [Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases).
|
||||
|
||||
### Disclaimer:
|
||||
This script is definitely not optimized, and it's not very intelligent. The tags are simply recommended based on their natural order in the CSV, which is their respective image count for the default Danbooru tag list. Also, at least for now, completion for negative or img2img prompt textboxes isn't supported, and there's no way to turn the script off from the ui, but I plan to get around to those features eventually.
|
||||
|
||||
### Known Issues:
|
||||
If `replaceUnderscores` is active, the script will currently only partly replace edited tags containing multiple words in brackets.
|
||||
## Common Problems & Known Issues:
|
||||
- If `replaceUnderscores` is active, the script will currently only partially replace edited tags containing multiple words in brackets.
|
||||
For example, editing `atago (azur lane)`, it would be replaced with e.g. `taihou (azur lane), lane)`, since the script currently doesn't see the second part of the bracket as the same tag. So in those cases you should delete the old tag beforehand.
|
||||
|
||||
## Screenshots
|
||||
Demo video (with keyboard navigation):
|
||||
|
||||
https://user-images.githubusercontent.com/34448969/195344430-2b5f9945-b98b-4943-9fbc-82cf633321b1.mp4
|
||||
https://user-images.githubusercontent.com/34448969/200128020-10d9a8b2-cea6-4e3f-bcd2-8c40c8c73233.mp4
|
||||
|
||||
Wildcard script support:
|
||||
|
||||
https://user-images.githubusercontent.com/34448969/200128031-22dd7c33-71d1-464f-ae36-5f6c8fd49df0.mp4
|
||||
|
||||
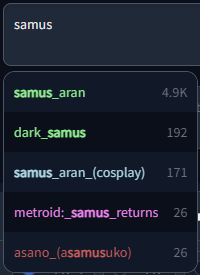
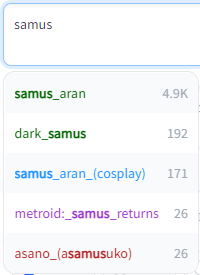
Dark and Light mode supported, including tag colors:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
## Installation
|
||||
Simply put `tagAutocomplete.js` into the `javascript` folder of your web UI installation. It will run automatically the next time the web UI is started.
|
||||
For the script to work, you also need to download the `tags` folder from this repo and paste it and its contents into the web UI root, or create them there manually.
|
||||
|
||||
The tags folder contains `config.json` and the tag data the script uses for autocompletion. By default, Danbooru and e621 tags are included.
|
||||
|
||||
### Config
|
||||
The config contains the following settings and defaults:
|
||||
```json
|
||||
{
|
||||
"tagFile": "danbooru.csv",
|
||||
"maxResults": 5,
|
||||
"replaceUnderscores": true,
|
||||
"colors": {
|
||||
"danbooru": {
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["orange", "darkorange"]
|
||||
},
|
||||
"e621": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["gold", "goldenrod"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["tomato", "darksalmon"],
|
||||
"6": ["red", "maroon"],
|
||||
"7": ["whitesmoke", "black"],
|
||||
"8": ["seagreen", "darkseagreen"]
|
||||
}
|
||||
}
|
||||
}
|
||||
### As an extension (recommended)
|
||||
Either clone the repo into your extensions folder:
|
||||
```bash
|
||||
git clone "https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git" extensions/tag-autocomplete
|
||||
```
|
||||
(The second argument specifies the name of the folder, you can choose whatever you like).
|
||||
|
||||
Or create a folder there manually and place the `javascript`, `scripts` and `tags` folders in it.
|
||||
|
||||
### In the root folder (old)
|
||||
Copy the `javascript`, `scripts` and `tags` folder into your web UI installation root. It will run automatically the next time the web UI is started.
|
||||
|
||||
---
|
||||
|
||||
In both configurations, the `tags` folder contains `colors.json` and the tag data the script uses for autocompletion. By default, Danbooru and e621 tags are included.
|
||||
After scanning for embeddings and wildcards, the script will also create a `temp` directory here which lists the found files so they can be accessed in the browser side of the script. You can delete the temp folder without consequences as it will be recreated on the next startup.
|
||||
|
||||
### Important:
|
||||
The script needs **all three folders** to work properly.
|
||||
|
||||
## Wildcard & Embedding support
|
||||
Autocompletion also works with wildcard files used by [this script](https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py) of the same name or other similar scripts/extensions. This enables you to either insert categories to be replaced by the script, or even replace them with the actual wildcard file content in the same step. Wildcards are searched for in every extension folder as well as the `scripts/wildcards` folder to support legacy versions. This means that you can combine wildcards from multiple extensions. Nested folders are also supported if you have grouped your wildcards in that way.
|
||||
|
||||
It also scans the embeddings folder and displays completion hints for the names of all .pt, .bin and .png files inside if you start typing `<`. Note that some normal tags also use < in Kaomoji (like ">_<" for example), so the results will contain both.
|
||||
|
||||
## Settings
|
||||
|
||||
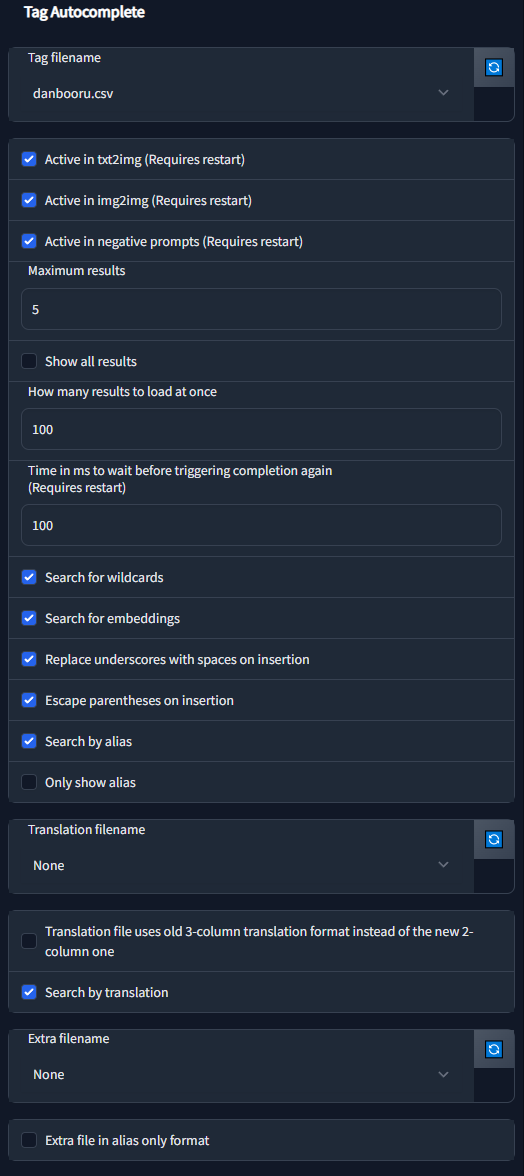
The extension has a large amount of configuration & customizability built in:
|
||||
|
||||
|
||||
|
||||
| Setting | Description |
|
||||
|---------|-------------|
|
||||
| tagFile | Specifies the tag file to use. You can provide a custom tag database of your liking, but since the script was developed with Danbooru tags in mind, it might not work properly with other configurations.|
|
||||
| maxResults | How many results to show max. For the default tag set, the results are ordered by occurence count. |
|
||||
| activeIn | Allows to selectively (de)activate the script for txt2img, img2img, and the negative prompts for both. |
|
||||
| maxResults | How many results to show max. For the default tag set, the results are ordered by occurence count. For embeddings and wildcards it will show all results in a scrollable list. |
|
||||
| resultStepLength | Allows to load results in smaller batches of the specified size for better performance in long lists or if showAllResults is true. |
|
||||
| delayTime | Specifies how much to wait in milliseconds before triggering autocomplete. Helps prevent too frequent updates while typing. |
|
||||
| showAllResults | If true, will ignore maxResults and show all results in a scrollable list. **Warning:** can lag your browser for long lists. |
|
||||
| replaceUnderscores | If true, undescores are replaced with spaces on clicking a tag. Might work better for some models. |
|
||||
| colors | Contains customizable colors for the tag types, you can add new ones here for custom tag files (same name as filename, without the .csv). The first value is for dark, the second for light mode. Color names and hex codes should both work.|
|
||||
| escapeParentheses | If true, escapes tags containing () so they don't contribute to the web UI's prompt weighting functionality. |
|
||||
| appendComma | Specifies the starting value of the "Append commas" UI switch. If UI options are disabled, this will always be used. |
|
||||
| useWildcards | Used to toggle the wildcard completion functionality. |
|
||||
| useEmbeddings | Used to toggle the embedding completion functionality. |
|
||||
| alias | Options for aliases. More info in the section below. |
|
||||
| translation | Options for translations. More info in the section below. |
|
||||
| extras | Options for additional tag files / aliases / translations. More info in the section below. |
|
||||
|
||||
### CSV tag data
|
||||
### colors.json
|
||||
Additionally, tag type colors can be specified using the separate `colors.json` file in the extension's `tags` folder.
|
||||
You can also add new ones here for custom tag files (same name as filename, without the .csv). The first value is for dark, the second for light mode. Color names and hex codes should both work.
|
||||
```json
|
||||
{
|
||||
"danbooru": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["orange", "darkorange"]
|
||||
},
|
||||
"e621": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["gold", "goldenrod"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["tomato", "darksalmon"],
|
||||
"6": ["red", "maroon"],
|
||||
"7": ["whitesmoke", "black"],
|
||||
"8": ["seagreen", "darkseagreen"]
|
||||
}
|
||||
}
|
||||
```
|
||||
The numbers are specifying the tag type, which is dependent on the tag source. For an example, see [CSV tag data](#csv-tag-data).
|
||||
|
||||
### Aliases, Translations & Extra tags
|
||||
#### Aliases
|
||||
Like on Booru sites, tags can have one or multiple aliases which redirect to the actual value on completion. These will be searchable / shown according to the settings in `config.json`:
|
||||
- `searchByAlias` - Whether to also search for the alias or only the actual tag.
|
||||
- `onlyShowAlias` - Shows only the alias instead of `alias -> actual`. Only for displaying, the inserted text at the end is still the actual tag.
|
||||
|
||||
#### Translations
|
||||
An additional file can be added in the translation section, which will be used to translate both tags and aliases and also enables searching by translation.
|
||||
This file needs to be a CSV in the format `<English tag/alias>,<Translation>`, but for backwards compatibility with older extra files that used a three column format, you can turn on `oldFormat` to use that instead.
|
||||
|
||||
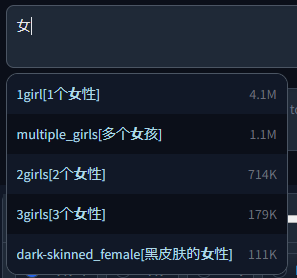
Example with chinese translation:
|
||||
|
||||
|
||||
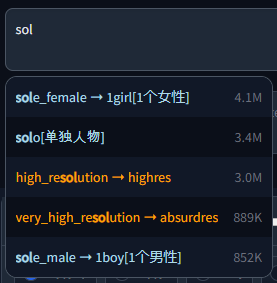
|
||||
|
||||
**Important**
|
||||
As of a recent update, translations added in the old Extra file way will only work as an alias and not be visible anymore if typing the English tag for that translation.
|
||||
|
||||
#### Extra file
|
||||
Aliases can be added in multiple ways, which is where the "Extra" file comes into play.
|
||||
1. As an extra file containing tag, category, optional count and the new alias. Will be matched to the English tags in the main file based on the name & type, so might be slow for large files.
|
||||
2. As an extra file with `onlyAliasExtraFile` true. With this configuration, the extra file has to include *only* the alias itself. That means it is purely index based, assigning the aliases to the main tags is really fast but also needs the lines to match (including empty lines). If the order or amount in the main file changes, the translations will potentially not match anymore. Not recommended.
|
||||
|
||||
So your CSV values would look like this for each method:
|
||||
| | 1 | 2 |
|
||||
|------------|--------------------------|--------------------------|
|
||||
| Main file | `tag,type,count,(alias)` | `tag,type,count,(alias)` |
|
||||
| Extra file | `tag,type,(count),alias` | `alias` |
|
||||
|
||||
Count in the extra file is optional, since there isn't always a post count for custom tag sets.
|
||||
|
||||
The extra files can also be used to just add new / custom tags not included in the main set, provided `onlyAliasExtraFile` is false.
|
||||
If an extra tag doesn't match any existing tag, it will be added to the list as a new tag instead. For this, it will need to include the post count and alias columns even if they don't contain anything, so it could be in the form of `tag,type,,`.
|
||||
|
||||
## CSV tag data
|
||||
The script expects a CSV file with tags saved in the following way:
|
||||
```csv
|
||||
1girl,0
|
||||
solo,0
|
||||
highres,5
|
||||
long_hair,0
|
||||
<name>,<type>,<postCount>,"<aliases>"
|
||||
```
|
||||
Notably, it does not expect column names in the first row.
|
||||
The first value needs to be the tag name, while the second value specifies the tag type.
|
||||
Example:
|
||||
```csv
|
||||
1girl,0,4114588,"1girls,sole_female"
|
||||
solo,0,3426446,"female_solo,solo_female"
|
||||
highres,5,3008413,"high_res,high_resolution,hires"
|
||||
long_hair,0,2898315,longhair
|
||||
commentary_request,5,2610959,
|
||||
```
|
||||
Notably, it does not expect column names in the first row and both count and aliases are technically optional,
|
||||
although count is always included in the default data. Multiple aliases need to be comma separated as well, but encased in string quotes to not break the CSV parsing.
|
||||
|
||||
The numbering system follows the [tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags) of Danbooru:
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Meta |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Meta |
|
||||
|
||||
or of e621:
|
||||
or similarly for e621:
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|-1 | Invalid |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Species |
|
||||
|6 | Invalid |
|
||||
|7 | Meta |
|
||||
|8 | Lore |
|
||||
|-1 | Invalid |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Species |
|
||||
|6 | Invalid |
|
||||
|7 | Meta |
|
||||
|8 | Lore |
|
||||
|
||||
The tag type is used for coloring entries in the result list.
|
||||
|
||||
174
README_ZH.md
Normal file
174
README_ZH.md
Normal file
@@ -0,0 +1,174 @@
|
||||
# Booru tag autocompletion for A1111
|
||||
|
||||
[](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)
|
||||
## [English Document](./README.md)
|
||||
|
||||
## 功能概述
|
||||
|
||||
本脚本为 [AUTOMATIC1111 web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)的自定义脚本,能在输入Tag时提供booru风格(如Danbooru)的TAG自动补全。因为有一些模型是基于这种TAG风格训练的(例如[Waifu Diffusion](https://github.com/harubaru/waifu-diffusion)),因此使用这些Tag能获得较为精确的效果。
|
||||
|
||||
这个脚本的创建是为了减少因复制Tag在Web UI和 booru网站的反复切换。
|
||||
你可以按照[以下方法](#installation)下载或拷贝文件,也可以使用[Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)中打包好的文件。
|
||||
|
||||
## 常见问题 & 已知缺陷:
|
||||
- 当`replaceUnderscores`选项开启时, 脚本只会替换Tag的一部分如果Tag包含多个单词,比如将`atago (azur lane)`修改`atago`为`taihou`并使用自动补全时.会得到 `taihou (azur lane), lane)`的结果, 因为脚本没有把后面的部分认为成同一个Tag。
|
||||
|
||||
## 演示与截图
|
||||
演示视频(使用了键盘导航):
|
||||
|
||||
https://user-images.githubusercontent.com/34448969/200128020-10d9a8b2-cea6-4e3f-bcd2-8c40c8c73233.mp4
|
||||
|
||||
Wildcard支持演示:
|
||||
|
||||
https://user-images.githubusercontent.com/34448969/200128031-22dd7c33-71d1-464f-ae36-5f6c8fd49df0.mp4
|
||||
|
||||
深浅色主题支持,包括Tag的颜色:
|
||||
|
||||

|
||||

|
||||
|
||||
## 安装
|
||||
### 作为一种扩展(推荐)
|
||||
要么把它克隆到你的扩展文件夹里
|
||||
```bash
|
||||
git clone "https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git" extensions/tag-autocomplete
|
||||
```
|
||||
(第二个参数指定文件夹的名称,你可以选择任何你喜欢的东西)。
|
||||
|
||||
或者手动创建一个文件夹,将 `javascript`、`scripts`和`tags`文件夹放在其中。
|
||||
|
||||
### 在根目录下(旧方法)
|
||||
只需要将`javascript`,`scripts`和`tags`文件夹复制到你的Web UI安装根目录下.下次启动Web UI时它将自动启动。
|
||||
|
||||
---
|
||||
在这两种配置中,标签文件夹包含`colors.json`和脚本用于自动完成的标签数据。
|
||||
默认情况下,Tag数据包括`Danbooru.csv`和`e621.csv`。
|
||||
|
||||
在扫描过`/embeddings`和wildcards后,会将列表存放在`tags/temp`文件夹下。删除该文件夹不会有任何影响,下次启动时它会重新创建。
|
||||
|
||||
### 注意:
|
||||
本脚本的允许需要**全部的三个文件夹**。
|
||||
|
||||
## [Wildcard](https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py) & Embedding 支持
|
||||
自动补全同样适用于 [Wildcard](https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py)中所述的通配符文件(后面有演示视频)。这将使你能够插入Wildcard脚本需要的通配符,更进一步的,你还可以插入通配符文件内的某个具体Tag。
|
||||
|
||||
当输入`__`字符时,`/scripts/wildcards`文件夹下的通配符文件会列出到自动补全,当你选择某个具体通配符文件时,会列出其中的所有的具体Tag,但如果你仅需要选择某个通配符,请按下空格。
|
||||
|
||||
当输入`<`字符时,`embeddings`文件夹下的`.pt`和`.bin`文件会列出到自动完成。需要注意的是,一些颜文字也会包含`<`(比如`>_<`),所以它们也会出现在结果中。
|
||||
|
||||
现在这项功能默认是启用的,并会自动扫描`/embeddings`和`/scripts/wildcards`文件夹,不再需要使用`tags/wildcardNames.txt`文件了,早期版本的用户可以将它删除。
|
||||
|
||||
## 配置文件
|
||||
该扩展有大量的配置和可定制性的内建:
|
||||
|
||||

|
||||
|
||||
| 设置 | 描述 |
|
||||
|---------|-------------|
|
||||
| tagFile | 指定要使用的标记文件。您可以提供您喜欢的自定义标签数据库,但由于该脚本是在考虑 Danbooru 标签的情况下开发的,因此它可能无法与其他配置一起正常工作。|
|
||||
| activeIn | 允许有选择地(取消)激活 txt2img、img2img 和两者的否定提示的脚本。|
|
||||
| maxResults | 最多显示多少个结果。对于默认标记集,结果按出现次数排序。对于嵌入和通配符,它将在可滚动列表中显示所有结果。 |
|
||||
| showAllResults | 如果为真,将忽略 maxResults 并在可滚动列表中显示所有结果。 **警告:** 对于长列表,您的浏览器可能会滞后。 |
|
||||
| resultStepLength | 允许以指定大小的小批次加载结果,以便在长列表中获得更好的性能,或者在showAllResults为真时。 |
|
||||
| delayTime | 指定在触发自动完成之前要等待多少毫秒。有助于防止打字时过于频繁的更新。 |
|
||||
| replaceUnderscores | 如果为 true,则在单击标签时将取消划线替换为空格。对于某些型号可能会更好。|
|
||||
| escapeParentheses | 如果为 true,则转义包含 () 的标签,因此它们不会对 Web UI 的提示权重功能做出贡献。 |
|
||||
| useWildcards | 用于切换通配符完成功能。 |
|
||||
| useEmbeddings | 用于切换嵌入完成功能。 |
|
||||
| alias | 标签别名的选项。更多信息在下面的部分。 |
|
||||
| translation | 用于翻译标签的选项。更多信息在下面的部分。 |
|
||||
| extras | 附加标签文件/翻译的选项。更多信息在下面的部分。|
|
||||
|
||||
### colors.json (标签颜色)
|
||||
此外,标签类型的颜色可以使用扩展的`tags`文件夹中单独的`colors.json`文件来指定。
|
||||
你也可以在这里为自定义标签文件添加新的(与文件名相同,不带 .csv)。第一个值是暗模式,第二个值是亮模式。颜色名称和十六进制代码都被支持。
|
||||
```json
|
||||
{
|
||||
"danbooru": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["orange", "darkorange"]
|
||||
},
|
||||
"e621": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["gold", "goldenrod"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["tomato", "darksalmon"],
|
||||
"6": ["red", "maroon"],
|
||||
"7": ["whitesmoke", "black"],
|
||||
"8": ["seagreen", "darkseagreen"]
|
||||
}
|
||||
}
|
||||
```
|
||||
数字是指定标签的类型,这取决于标签的来源。例如,见[CSV tag data](#csv-tag-data)。
|
||||
|
||||
### 别名,翻译&新增Tag
|
||||
#### 别名
|
||||
像Booru网站一样,标签可以有一个或多个别名,完成后重定向到实际值。这些将根据`config.json`中的设置进行搜索/显示。
|
||||
- `searchByAlias` - 是否也要搜索别名,或只搜索实际的标签。
|
||||
- `onlyShowAlias` - 只显示别名,不显示 `别名->实际`。仅用于显示,最后的文本仍然是实际的标签。
|
||||
|
||||
#### 翻译
|
||||
可以在翻译部分添加一个额外的文件,它将被用来翻译标签和别名,同时也可以通过翻译进行搜索。
|
||||
这个文件需要是CSV格式的`<英语标签/别名>,<翻译>`,但为了向后兼容使用三栏格式的旧的额外文件,你可以打开`oldFormat`来代替它。
|
||||
|
||||
完整和部分中文标签集的示例:
|
||||
|
||||

|
||||

|
||||
|
||||
**重要的是**
|
||||
从最近的更新来看,用旧的Extra文件方式添加的翻译只能作为一个别名使用,如果输入该翻译的英文标签,将不再可见。
|
||||
|
||||
可以通过多种方式添加别名,这就是额外文件发挥作用的地方。
|
||||
1. 作为仅包含已翻译标签行的额外文件(因此仍包括英文标签名称和标签类型)。将根据名称和类型与主文件中的英文标签匹配,因此对于大型翻译文件可能会很慢。
|
||||
2. 作为 `onlyAliasExtraFile` 为 true 的额外文件。使用此配置,额外文件必须包含*仅*翻译本身。这意味着它完全基于索引,将翻译分配给主要标签非常快,但也需要匹配行(包括空行)。如果主文件中的顺序或数量发生变化,则翻译可能不再匹配。
|
||||
|
||||
因此,对于每种方法,您的 CSV 值将如下所示:
|
||||
| | 1 | 2 |
|
||||
|------------|--------------------------|--------------------------|
|
||||
| Main file | `tag,type,count,(alias)` | `tag,type,count,(alias)` |
|
||||
| Extra file | `tag,type,(count),alias` | `alias` |
|
||||
|
||||
额外文件中的计数是可选的,因为自定义标签集并不总是有帖子计数。
|
||||
如果额外的标签与任何现有标签都不匹配,它将作为新标签添加到列表中。
|
||||
|
||||
### CSV tag data
|
||||
本脚本的Tag文件格式如下,你可以安装这个格式制作自己的Tag文件:
|
||||
```csv
|
||||
1girl,0,4114588,"1girls,sole_female"
|
||||
solo,0,3426446,"female_solo,solo_female"
|
||||
highres,5,3008413,"high_res,high_resolution,hires"
|
||||
long_hair,0,2898315,longhair
|
||||
commentary_request,5,2610959,
|
||||
```
|
||||
值得注意的是,不希望在第一行有列名,而且count和aliases在技术上都是可选的。
|
||||
尽管count总是包含在默认数据中。多个别名也需要用逗号分隔,但要用字符串引号包裹,以免破坏CSV解析。
|
||||
编号系统遵循 Danbooru 的 [tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags):
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Meta |
|
||||
|
||||
类似的还有e621:
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|-1 | Invalid |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Species |
|
||||
|6 | Invalid |
|
||||
|7 | Meta |
|
||||
|8 | Lore |
|
||||
|
||||
标记类型用于为结果列表中的条目着色.
|
||||
80
javascript/_textAreas.js
Normal file
80
javascript/_textAreas.js
Normal file
@@ -0,0 +1,80 @@
|
||||
// Utility functions to select text areas the script should work on,
|
||||
// including third party options.
|
||||
// Supported third party options so far:
|
||||
// - Dataset Tag Editor
|
||||
|
||||
// Core text area selectors
|
||||
const core = [
|
||||
"#txt2img_prompt > label > textarea",
|
||||
"#img2img_prompt > label > textarea",
|
||||
"#txt2img_neg_prompt > label > textarea",
|
||||
"#img2img_neg_prompt > label > textarea"
|
||||
];
|
||||
|
||||
// Third party text area selectors
|
||||
const thirdParty = {
|
||||
"dataset-tag-editor": {
|
||||
"base": "#tab_dataset_tag_editor_interface",
|
||||
"hasIds": false,
|
||||
"selectors": [
|
||||
"Caption of Selected Image",
|
||||
"Interrogate Result",
|
||||
"Edit Caption",
|
||||
"Edit Tags"
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
function getTextAreas() {
|
||||
// First get all core text areas
|
||||
let textAreas = [...gradioApp().querySelectorAll(core.join(", "))];
|
||||
|
||||
for (const [key, entry] of Object.entries(thirdParty)) {
|
||||
if (entry.hasIds) { // If the entry has proper ids, we can just select them
|
||||
textAreas = textAreas.concat([...gradioApp().querySelectorAll(entry.selectors.join(", "))]);
|
||||
} else { // Otherwise, we have to find the text areas by their adjacent labels
|
||||
let base = gradioApp().querySelector(entry.base);
|
||||
let allTextAreas = [...base.querySelectorAll("textarea")];
|
||||
|
||||
// Filter the text areas where the adjacent label matches one of the selectors
|
||||
let matchingTextAreas = allTextAreas.filter(ta => [...ta.parentElement.childNodes].some(x => entry.selectors.includes(x.innerText)));
|
||||
textAreas = textAreas.concat(matchingTextAreas);
|
||||
}
|
||||
};
|
||||
|
||||
return textAreas;
|
||||
}
|
||||
|
||||
const thirdPartyIdSet = new Set();
|
||||
// Get the identifier for the text area to differentiate between positive and negative
|
||||
function getTextAreaIdentifier(textArea) {
|
||||
let txt2img_p = gradioApp().querySelector('#txt2img_prompt > label > textarea');
|
||||
let txt2img_n = gradioApp().querySelector('#txt2img_neg_prompt > label > textarea');
|
||||
let img2img_p = gradioApp().querySelector('#img2img_prompt > label > textarea');
|
||||
let img2img_n = gradioApp().querySelector('#img2img_neg_prompt > label > textarea');
|
||||
|
||||
let modifier = "";
|
||||
switch (textArea) {
|
||||
case txt2img_p:
|
||||
modifier = ".txt2img.p";
|
||||
break;
|
||||
case txt2img_n:
|
||||
modifier = ".txt2img.n";
|
||||
break;
|
||||
case img2img_p:
|
||||
modifier = ".img2img.p";
|
||||
break;
|
||||
case img2img_n:
|
||||
modifier = ".img2img.n";
|
||||
break;
|
||||
default:
|
||||
// If the text area is not a core text area, it must be a third party text area
|
||||
// Add it to the set of third party text areas and get its index as a unique identifier
|
||||
if (!thirdPartyIdSet.has(textArea))
|
||||
thirdPartyIdSet.add(textArea);
|
||||
|
||||
modifier = `.thirdParty.ta${[...thirdPartyIdSet].indexOf(textArea)}`;
|
||||
break;
|
||||
}
|
||||
return modifier;
|
||||
}
|
||||
939
javascript/tagAutocomplete.js
Normal file
939
javascript/tagAutocomplete.js
Normal file
@@ -0,0 +1,939 @@
|
||||
var CFG = null;
|
||||
|
||||
const styleColors = {
|
||||
"--results-bg": ["#0b0f19", "#ffffff"],
|
||||
"--results-border-color": ["#4b5563", "#e5e7eb"],
|
||||
"--results-border-width": ["1px", "1.5px"],
|
||||
"--results-bg-odd": ["#111827", "#f9fafb"],
|
||||
"--results-hover": ["#1f2937", "#f5f6f8"],
|
||||
"--results-selected": ["#374151", "#e5e7eb"],
|
||||
"--post-count-color": ["#6b6f7b", "#a2a9b4"]
|
||||
}
|
||||
const browserVars = {
|
||||
"--results-overflow-y": {
|
||||
"firefox": "scroll",
|
||||
"other": "auto"
|
||||
}
|
||||
}
|
||||
// Style for new elements. Gets appended to the Gradio root.
|
||||
const autocompleteCSS = `
|
||||
#quicksettings [id^=setting_tac] {
|
||||
background-color: transparent;
|
||||
min-width: fit-content;
|
||||
align-self: center;
|
||||
margin: 0 5px;
|
||||
}
|
||||
[id^=refresh_tac] {
|
||||
max-width: 2.5em;
|
||||
min-width: 2.5em;
|
||||
height: 2.4em;
|
||||
}
|
||||
.autocompleteResults {
|
||||
position: absolute;
|
||||
z-index: 999;
|
||||
margin: 5px 0 0 0;
|
||||
background-color: var(--results-bg) !important;
|
||||
border: var(--results-border-width) solid var(--results-border-color) !important;
|
||||
border-radius: 12px !important;
|
||||
overflow-y: var(--results-overflow-y);
|
||||
overflow-x: hidden;
|
||||
}
|
||||
.autocompleteResultsList > li:nth-child(odd) {
|
||||
background-color: var(--results-bg-odd);
|
||||
}
|
||||
.autocompleteResultsList > li {
|
||||
list-style-type: none;
|
||||
padding: 10px;
|
||||
cursor: pointer;
|
||||
}
|
||||
.autocompleteResultsList > li:hover {
|
||||
background-color: var(--results-hover);
|
||||
}
|
||||
.autocompleteResultsList > li.selected {
|
||||
background-color: var(--results-selected);
|
||||
}
|
||||
.resultsFlexContainer {
|
||||
display: flex;
|
||||
}
|
||||
.acListItem {
|
||||
overflow: hidden;
|
||||
white-space: nowrap;
|
||||
}
|
||||
.acPostCount {
|
||||
position: relative;
|
||||
text-align: end;
|
||||
padding: 0 0 0 15px;
|
||||
flex-grow: 1;
|
||||
color: var(--post-count-color);
|
||||
}
|
||||
`;
|
||||
|
||||
// Parse the CSV file into a 2D array. Doesn't use regex, so it is very lightweight.
|
||||
function parseCSV(str) {
|
||||
var arr = [];
|
||||
var quote = false; // 'true' means we're inside a quoted field
|
||||
|
||||
// Iterate over each character, keep track of current row and column (of the returned array)
|
||||
for (var row = 0, col = 0, c = 0; c < str.length; c++) {
|
||||
var cc = str[c], nc = str[c + 1]; // Current character, next character
|
||||
arr[row] = arr[row] || []; // Create a new row if necessary
|
||||
arr[row][col] = arr[row][col] || ''; // Create a new column (start with empty string) if necessary
|
||||
|
||||
// If the current character is a quotation mark, and we're inside a
|
||||
// quoted field, and the next character is also a quotation mark,
|
||||
// add a quotation mark to the current column and skip the next character
|
||||
if (cc == '"' && quote && nc == '"') { arr[row][col] += cc; ++c; continue; }
|
||||
|
||||
// If it's just one quotation mark, begin/end quoted field
|
||||
if (cc == '"') { quote = !quote; continue; }
|
||||
|
||||
// If it's a comma and we're not in a quoted field, move on to the next column
|
||||
if (cc == ',' && !quote) { ++col; continue; }
|
||||
|
||||
// If it's a newline (CRLF) and we're not in a quoted field, skip the next character
|
||||
// and move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\r' && nc == '\n' && !quote) { ++row; col = 0; ++c; continue; }
|
||||
|
||||
// If it's a newline (LF or CR) and we're not in a quoted field,
|
||||
// move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\n' && !quote) { ++row; col = 0; continue; }
|
||||
if (cc == '\r' && !quote) { ++row; col = 0; continue; }
|
||||
|
||||
// Otherwise, append the current character to the current column
|
||||
arr[row][col] += cc;
|
||||
}
|
||||
return arr;
|
||||
}
|
||||
|
||||
// Load file
|
||||
async function readFile(filePath, json = false) {
|
||||
let response = await fetch(`file=${filePath}`);
|
||||
|
||||
if (response.status != 200) {
|
||||
console.error(`Error loading file "${filePath}": ` + response.status, response.statusText);
|
||||
return null;
|
||||
}
|
||||
|
||||
if (json)
|
||||
return await response.json();
|
||||
else
|
||||
return await response.text();
|
||||
}
|
||||
|
||||
// Load CSV
|
||||
async function loadCSV(path) {
|
||||
let text = await readFile(path);
|
||||
return parseCSV(text);
|
||||
}
|
||||
|
||||
var tagBasePath = "";
|
||||
var allTags = [];
|
||||
var translations = new Map();
|
||||
|
||||
async function loadTags(c) {
|
||||
// Load main tags and aliases
|
||||
if (allTags.length === 0) {
|
||||
try {
|
||||
allTags = await loadCSV(`${tagBasePath}/${c.tagFile}?${new Date().getTime()}`);
|
||||
} catch (e) {
|
||||
console.error("Error loading tags file: " + e);
|
||||
return;
|
||||
}
|
||||
if (c.extra.extraFile && c.extra.extraFile !== "None") {
|
||||
try {
|
||||
extras = await loadCSV(`${tagBasePath}/${c.extra.extraFile}?${new Date().getTime()}`);
|
||||
if (c.extra.onlyAliasExtraFile) {
|
||||
// This works purely on index, so it's not very robust. But a lot faster.
|
||||
for (let i = 0, n = extras.length; i < n; i++) {
|
||||
if (extras[i][0]) {
|
||||
let aliasStr = allTags[i][3] || "";
|
||||
let optComma = aliasStr.length > 0 ? "," : "";
|
||||
allTags[i][3] = aliasStr + optComma + extras[i][0];
|
||||
}
|
||||
}
|
||||
} else {
|
||||
extras.forEach(e => {
|
||||
let hasCount = e[2] && e[3] || (!isNaN(e[2]) && !e[3]);
|
||||
// Check if a tag in allTags has the same name & category as the extra tag
|
||||
if (tag = allTags.find(t => t[0] === e[0] && t[1] == e[1])) {
|
||||
if (hasCount && e[3] || isNaN(e[2])) { // If the extra tag has a translation / alias, add it to the normal tag
|
||||
let aliasStr = tag[3] || "";
|
||||
let optComma = aliasStr.length > 0 ? "," : "";
|
||||
let alias = hasCount && e[3] || isNaN(e[2]) ? e[2] : e[3];
|
||||
tag[3] = aliasStr + optComma + alias;
|
||||
}
|
||||
} else {
|
||||
let count = hasCount ? e[2] : null;
|
||||
let aliases = hasCount && e[3] ? e[3] : e[2];
|
||||
// If the tag doesn't exist, add it to allTags
|
||||
let newTag = [e[0], e[1], count, aliases];
|
||||
allTags.push(newTag);
|
||||
}
|
||||
});
|
||||
}
|
||||
} catch (e) {
|
||||
console.error("Error loading extra file: " + e);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
async function loadTranslations(c) {
|
||||
if (c.translation.translationFile && c.translation.translationFile !== "None") {
|
||||
try {
|
||||
let tArray = await loadCSV(`${tagBasePath}/${c.translation.translationFile}?${new Date().getTime()}`);
|
||||
tArray.forEach(t => {
|
||||
if (c.translation.oldFormat)
|
||||
translations.set(t[0], t[2]);
|
||||
else
|
||||
translations.set(t[0], t[1]);
|
||||
});
|
||||
} catch (e) {
|
||||
console.error("Error loading translations file: " + e);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
async function syncOptions() {
|
||||
let newCFG = {
|
||||
// Main tag file
|
||||
tagFile: opts["tac_tagFile"],
|
||||
// Active in settings
|
||||
activeIn: {
|
||||
global: opts["tac_active"],
|
||||
txt2img: opts["tac_activeIn.txt2img"],
|
||||
img2img: opts["tac_activeIn.img2img"],
|
||||
negativePrompts: opts["tac_activeIn.negativePrompts"],
|
||||
thirdParty: opts["tac_activeIn.thirdParty"]
|
||||
},
|
||||
// Results related settings
|
||||
maxResults: opts["tac_maxResults"],
|
||||
showAllResults: opts["tac_showAllResults"],
|
||||
resultStepLength: opts["tac_resultStepLength"],
|
||||
delayTime: opts["tac_delayTime"],
|
||||
useWildcards: opts["tac_useWildcards"],
|
||||
useEmbeddings: opts["tac_useEmbeddings"],
|
||||
// Insertion related settings
|
||||
replaceUnderscores: opts["tac_replaceUnderscores"],
|
||||
escapeParentheses: opts["tac_escapeParentheses"],
|
||||
appendComma: opts["tac_appendComma"],
|
||||
// Alias settings
|
||||
alias: {
|
||||
searchByAlias: opts["tac_alias.searchByAlias"],
|
||||
onlyShowAlias: opts["tac_alias.onlyShowAlias"]
|
||||
},
|
||||
// Translation settings
|
||||
translation: {
|
||||
translationFile: opts["tac_translation.translationFile"],
|
||||
oldFormat: opts["tac_translation.oldFormat"],
|
||||
searchByTranslation: opts["tac_translation.searchByTranslation"],
|
||||
},
|
||||
// Extra file settings
|
||||
extra: {
|
||||
extraFile: opts["tac_extra.extraFile"],
|
||||
onlyAliasExtraFile: opts["tac_extra.onlyAliasExtraFile"]
|
||||
}
|
||||
}
|
||||
|
||||
if (CFG && CFG.colors) {
|
||||
newCFG["colors"] = CFG.colors;
|
||||
}
|
||||
if (newCFG.alias.onlyShowAlias) {
|
||||
newCFG.alias.searchByAlias = true; // if only show translation, enable search by translation is necessary
|
||||
}
|
||||
|
||||
// Reload tags if the tag file changed
|
||||
if (!CFG || newCFG.tagFile !== CFG.tagFile || newCFG.extra.extraFile !== CFG.extra.extraFile) {
|
||||
allTags = [];
|
||||
await loadTags(newCFG);
|
||||
}
|
||||
// Reload translations if the translation file changed
|
||||
if (!CFG || newCFG.translation.translationFile !== CFG.translation.translationFile) {
|
||||
translations.clear();
|
||||
await loadTranslations(newCFG);
|
||||
}
|
||||
|
||||
// Update CSS if maxResults changed
|
||||
if (CFG && newCFG.maxResults !== CFG.maxResults) {
|
||||
gradioApp().querySelectorAll(".autocompleteResults").forEach(r => {
|
||||
r.style.maxHeight = `${newCFG.maxResults * 50}px`;
|
||||
});
|
||||
}
|
||||
|
||||
// Apply changes
|
||||
CFG = newCFG;
|
||||
}
|
||||
|
||||
// Debounce function to prevent spamming the autocomplete function
|
||||
var dbTimeOut;
|
||||
const debounce = (func, wait = 300) => {
|
||||
return function (...args) {
|
||||
if (dbTimeOut) {
|
||||
clearTimeout(dbTimeOut);
|
||||
}
|
||||
|
||||
dbTimeOut = setTimeout(() => {
|
||||
func.apply(this, args);
|
||||
}, wait);
|
||||
}
|
||||
}
|
||||
|
||||
// Difference function to fix duplicates not being seen as changes in normal filter
|
||||
function difference(a, b) {
|
||||
if (a.length == 0) {
|
||||
return b;
|
||||
}
|
||||
if (b.length == 0) {
|
||||
return a;
|
||||
}
|
||||
|
||||
return [...b.reduce((acc, v) => acc.set(v, (acc.get(v) || 0) - 1),
|
||||
a.reduce((acc, v) => acc.set(v, (acc.get(v) || 0) + 1), new Map())
|
||||
)].reduce((acc, [v, count]) => acc.concat(Array(Math.abs(count)).fill(v)), []);
|
||||
}
|
||||
|
||||
// Create the result list div and necessary styling
|
||||
function createResultsDiv(textArea) {
|
||||
let resultsDiv = document.createElement("div");
|
||||
let resultsList = document.createElement('ul');
|
||||
|
||||
let textAreaId = getTextAreaIdentifier(textArea);
|
||||
let typeClass = textAreaId.replaceAll(".", " ");
|
||||
|
||||
resultsDiv.style.maxHeight = `${CFG.maxResults * 50}px`;
|
||||
resultsDiv.setAttribute('class', `autocompleteResults ${typeClass}`);
|
||||
resultsList.setAttribute('class', 'autocompleteResultsList');
|
||||
resultsDiv.appendChild(resultsList);
|
||||
|
||||
return resultsDiv;
|
||||
}
|
||||
|
||||
// The selected tag index. Needs to be up here so hide can access it.
|
||||
var selectedTag = null;
|
||||
var previousTags = [];
|
||||
|
||||
// Show or hide the results div
|
||||
function isVisible(textArea) {
|
||||
let textAreaId = getTextAreaIdentifier(textArea);
|
||||
let resultsDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
||||
return resultsDiv.style.display === "block";
|
||||
}
|
||||
function showResults(textArea) {
|
||||
let textAreaId = getTextAreaIdentifier(textArea);
|
||||
let resultsDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
||||
resultsDiv.style.display = "block";
|
||||
}
|
||||
function hideResults(textArea) {
|
||||
let textAreaId = getTextAreaIdentifier(textArea);
|
||||
let resultsDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
||||
resultsDiv.style.display = "none";
|
||||
selectedTag = null;
|
||||
}
|
||||
|
||||
function escapeRegExp(string) {
|
||||
return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string
|
||||
}
|
||||
function escapeHTML(unsafeText) {
|
||||
let div = document.createElement('div');
|
||||
div.textContent = unsafeText;
|
||||
return div.innerHTML;
|
||||
}
|
||||
|
||||
const WEIGHT_REGEX = /[([]([^,()[\]:| ]+)(?::(?:\d+(?:\.\d+)?|\.\d+))?[)\]]/g;
|
||||
const TAG_REGEX = /([^\s,|]+)/g
|
||||
let hideBlocked = false;
|
||||
|
||||
// On click, insert the tag into the prompt textbox with respect to the cursor position
|
||||
function insertTextAtCursor(textArea, result, tagword) {
|
||||
let text = result[0];
|
||||
let tagType = result[1];
|
||||
|
||||
let cursorPos = textArea.selectionStart;
|
||||
var sanitizedText = text
|
||||
|
||||
// Replace differently depending on if it's a tag or wildcard
|
||||
if (tagType === "wildcardFile") {
|
||||
sanitizedText = "__" + text.replace("Wildcards: ", "") + "__";
|
||||
} else if (tagType === "wildcardTag") {
|
||||
sanitizedText = text.replace(/^.*?: /g, "");
|
||||
} else if (tagType === "embedding") {
|
||||
sanitizedText = `<${text.replace(/^.*?: /g, "")}>`;
|
||||
} else {
|
||||
sanitizedText = CFG.replaceUnderscores ? text.replaceAll("_", " ") : text;
|
||||
}
|
||||
|
||||
if (CFG.escapeParentheses) {
|
||||
sanitizedText = sanitizedText
|
||||
.replaceAll("(", "\\(")
|
||||
.replaceAll(")", "\\)")
|
||||
.replaceAll("[", "\\[")
|
||||
.replaceAll("]", "\\]");
|
||||
}
|
||||
|
||||
var prompt = textArea.value;
|
||||
|
||||
// Edit prompt text
|
||||
let editStart = Math.max(cursorPos - tagword.length, 0);
|
||||
let editEnd = Math.min(cursorPos + tagword.length, prompt.length);
|
||||
let surrounding = prompt.substring(editStart, editEnd);
|
||||
let match = surrounding.match(new RegExp(escapeRegExp(`${tagword}`), "i"));
|
||||
let afterInsertCursorPos = editStart + match.index + sanitizedText.length;
|
||||
|
||||
var optionalComma = "";
|
||||
if (CFG.appendComma && tagType !== "wildcardFile") {
|
||||
optionalComma = surrounding.match(new RegExp(`${escapeRegExp(tagword)}[,:]`, "i")) !== null ? "" : ", ";
|
||||
}
|
||||
|
||||
// Replace partial tag word with new text, add comma if needed
|
||||
let insert = surrounding.replace(match, sanitizedText + optionalComma);
|
||||
|
||||
// Add back start
|
||||
var newPrompt = prompt.substring(0, editStart) + insert + prompt.substring(editEnd);
|
||||
textArea.value = newPrompt;
|
||||
textArea.selectionStart = afterInsertCursorPos + optionalComma.length;
|
||||
textArea.selectionEnd = textArea.selectionStart
|
||||
|
||||
// Since we've modified a Gradio Textbox component manually, we need to simulate an `input` DOM event to ensure its
|
||||
// internal Svelte data binding remains in sync.
|
||||
textArea.dispatchEvent(new Event("input", { bubbles: true }));
|
||||
|
||||
// Update previous tags with the edited prompt to prevent re-searching the same term
|
||||
let weightedTags = [...newPrompt.matchAll(WEIGHT_REGEX)]
|
||||
.map(match => match[1]);
|
||||
let tags = newPrompt.match(TAG_REGEX)
|
||||
if (weightedTags !== null) {
|
||||
tags = tags.filter(tag => !weightedTags.some(weighted => tag.includes(weighted)))
|
||||
.concat(weightedTags);
|
||||
}
|
||||
previousTags = tags;
|
||||
|
||||
// Hide results after inserting
|
||||
if (tagType === "wildcardFile") {
|
||||
// If it's a wildcard, we want to keep the results open so the user can select another wildcard
|
||||
hideBlocked = true;
|
||||
autocomplete(textArea, prompt, sanitizedText);
|
||||
setTimeout(() => { hideBlocked = false; }, 100);
|
||||
} else {
|
||||
hideResults(textArea);
|
||||
}
|
||||
}
|
||||
|
||||
function addResultsToList(textArea, results, tagword, resetList) {
|
||||
let textAreaId = getTextAreaIdentifier(textArea);
|
||||
let resultDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
||||
let resultsList = resultDiv.querySelector('ul');
|
||||
|
||||
// Reset list, selection and scrollTop since the list changed
|
||||
if (resetList) {
|
||||
resultsList.innerHTML = "";
|
||||
selectedTag = null;
|
||||
resultDiv.scrollTop = 0;
|
||||
resultCount = 0;
|
||||
}
|
||||
|
||||
// Find right colors from config
|
||||
let tagFileName = CFG.tagFile.split(".")[0];
|
||||
let tagColors = CFG.colors;
|
||||
let mode = gradioApp().querySelector('.dark') ? 0 : 1;
|
||||
let nextLength = Math.min(results.length, resultCount + CFG.resultStepLength);
|
||||
|
||||
for (let i = resultCount; i < nextLength; i++) {
|
||||
let result = results[i];
|
||||
let li = document.createElement("li");
|
||||
|
||||
let flexDiv = document.createElement("div");
|
||||
flexDiv.classList.add("resultsFlexContainer");
|
||||
li.appendChild(flexDiv);
|
||||
|
||||
let itemText = document.createElement("div");
|
||||
itemText.classList.add("acListItem");
|
||||
flexDiv.appendChild(itemText);
|
||||
|
||||
let displayText = "";
|
||||
// If the tag matches the tagword, we don't need to display the alias
|
||||
if (result[3] && !result[0].includes(tagword)) { // Alias
|
||||
let splitAliases = result[3].split(",");
|
||||
let bestAlias = splitAliases.find(a => a.toLowerCase().includes(tagword));
|
||||
|
||||
// search in translations if no alias matches
|
||||
if (!bestAlias) {
|
||||
let tagOrAlias = pair => pair[0] === result[0] || result[3].split(",").includes(pair[0]);
|
||||
var tArray = [...translations];
|
||||
if (tArray) {
|
||||
var translationKey = [...translations].find(pair => tagOrAlias(pair) && pair[1].includes(tagword));
|
||||
if (translationKey)
|
||||
bestAlias = translationKey[0];
|
||||
}
|
||||
}
|
||||
|
||||
displayText = escapeHTML(bestAlias);
|
||||
|
||||
// Append translation for alias if it exists and is not what the user typed
|
||||
if (translations.has(bestAlias) && translations.get(bestAlias) !== bestAlias && bestAlias !== result[0])
|
||||
displayText += `[${translations.get(bestAlias)}]`;
|
||||
|
||||
if (!CFG.alias.onlyShowAlias && result[0] !== bestAlias)
|
||||
displayText += " ➝ " + result[0];
|
||||
} else { // No alias
|
||||
displayText = escapeHTML(result[0]);
|
||||
}
|
||||
|
||||
// Append translation for result if it exists
|
||||
if (translations.has(result[0]))
|
||||
displayText += `[${translations.get(result[0])}]`;
|
||||
|
||||
// Print search term bolded in result
|
||||
itemText.innerHTML = displayText.replace(tagword, `<b>${tagword}</b>`);
|
||||
|
||||
// Add post count & color if it's a tag
|
||||
// Wildcards & Embeds have no tag type
|
||||
if (!result[1].startsWith("wildcard") && result[1] !== "embedding") {
|
||||
// Set the color of the tag
|
||||
let tagType = result[1];
|
||||
let colorGroup = tagColors[tagFileName];
|
||||
// Default to danbooru scheme if no matching one is found
|
||||
if (!colorGroup)
|
||||
colorGroup = tagColors["danbooru"];
|
||||
|
||||
// Set tag type to invalid if not found
|
||||
if (!colorGroup[tagType])
|
||||
tagType = "-1";
|
||||
|
||||
itemText.style = `color: ${colorGroup[tagType][mode]};`;
|
||||
|
||||
// Post count
|
||||
if (result[2] && !isNaN(result[2])) {
|
||||
let postCount = result[2];
|
||||
let formatter;
|
||||
|
||||
// Danbooru formats numbers with a padded fraction for 1M or 1k, but not for 10/100k
|
||||
if (postCount >= 1000000 || (postCount >= 1000 && postCount < 10000))
|
||||
formatter = Intl.NumberFormat("en", { notation: "compact", minimumFractionDigits: 1, maximumFractionDigits: 1 });
|
||||
else
|
||||
formatter = Intl.NumberFormat("en", {notation: "compact"});
|
||||
|
||||
let formattedCount = formatter.format(postCount);
|
||||
|
||||
let countDiv = document.createElement("div");
|
||||
countDiv.textContent = formattedCount;
|
||||
countDiv.classList.add("acPostCount");
|
||||
flexDiv.appendChild(countDiv);
|
||||
}
|
||||
}
|
||||
|
||||
// Add listener
|
||||
li.addEventListener("click", function () { insertTextAtCursor(textArea, result, tagword); });
|
||||
// Add element to list
|
||||
resultsList.appendChild(li);
|
||||
}
|
||||
resultCount = nextLength;
|
||||
}
|
||||
|
||||
function updateSelectionStyle(textArea, newIndex, oldIndex) {
|
||||
let textAreaId = getTextAreaIdentifier(textArea);
|
||||
let resultDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
||||
let resultsList = resultDiv.querySelector('ul');
|
||||
let items = resultsList.getElementsByTagName('li');
|
||||
|
||||
if (oldIndex != null) {
|
||||
items[oldIndex].classList.remove('selected');
|
||||
}
|
||||
|
||||
// make it safer
|
||||
if (newIndex !== null) {
|
||||
items[newIndex].classList.add('selected');
|
||||
}
|
||||
|
||||
// Set scrolltop to selected item if we are showing more than max results
|
||||
if (items.length > CFG.maxResults) {
|
||||
let selected = items[newIndex];
|
||||
resultDiv.scrollTop = selected.offsetTop - resultDiv.offsetTop;
|
||||
}
|
||||
}
|
||||
|
||||
var wildcardFiles = [];
|
||||
var wildcardExtFiles = [];
|
||||
var embeddings = [];
|
||||
var results = [];
|
||||
var tagword = "";
|
||||
var resultCount = 0;
|
||||
async function autocomplete(textArea, prompt, fixedTag = null) {
|
||||
// Return if the function is deactivated in the UI
|
||||
if (!CFG.activeIn.global) return;
|
||||
|
||||
// Guard for empty prompt
|
||||
if (prompt.length === 0) {
|
||||
hideResults(textArea);
|
||||
return;
|
||||
}
|
||||
|
||||
if (fixedTag === null) {
|
||||
// Match tags with RegEx to get the last edited one
|
||||
// We also match for the weighting format (e.g. "tag:1.0") here, and combine the two to get the full tag word set
|
||||
let weightedTags = [...prompt.matchAll(WEIGHT_REGEX)]
|
||||
.map(match => match[1]);
|
||||
let tags = prompt.match(TAG_REGEX)
|
||||
if (weightedTags !== null) {
|
||||
tags = tags.filter(tag => !weightedTags.some(weighted => tag.includes(weighted)))
|
||||
.concat(weightedTags);
|
||||
}
|
||||
|
||||
let tagCountChange = tags.length - previousTags.length;
|
||||
let diff = difference(tags, previousTags);
|
||||
previousTags = tags;
|
||||
|
||||
// Guard for no difference / only whitespace remaining / last edited tag was fully removed
|
||||
if (diff === null || diff.length === 0 || (diff.length === 1 && tagCountChange < 0)) {
|
||||
if (!hideBlocked) hideResults(textArea);
|
||||
return;
|
||||
}
|
||||
|
||||
tagword = diff[0]
|
||||
|
||||
// Guard for empty tagword
|
||||
if (tagword === null || tagword.length === 0) {
|
||||
hideResults(textArea);
|
||||
return;
|
||||
}
|
||||
} else {
|
||||
tagword = fixedTag;
|
||||
}
|
||||
|
||||
tagword = tagword.toLowerCase().replace(/[\n\r]/g, "");
|
||||
|
||||
if (CFG.useWildcards && [...tagword.matchAll(/\b__([^, ]+)__([^, ]*)\b/g)].length > 0) {
|
||||
// Show wildcards from a file with that name
|
||||
wcMatch = [...tagword.matchAll(/\b__([^, ]+)__([^, ]*)\b/g)]
|
||||
let wcFile = wcMatch[0][1];
|
||||
let wcWord = wcMatch[0][2];
|
||||
|
||||
var wcPair;
|
||||
|
||||
// Look in normal wildcard files
|
||||
if (wcFound = wildcardFiles.find(x => x[1].toLowerCase() === wcFile))
|
||||
wcPair = wcFound;
|
||||
else // Look in extensions wildcard files
|
||||
wcPair = wildcardExtFiles.find(x => x[1].toLowerCase() === wcFile);
|
||||
|
||||
let wildcards = (await readFile(`${wcPair[0]}/${wcPair[1]}.txt?${new Date().getTime()}`)).split("\n")
|
||||
.filter(x => x.trim().length > 0 && !x.startsWith('#')); // Remove empty lines and comments
|
||||
|
||||
results = wildcards.filter(x => (wcWord !== null && wcWord.length > 0) ? x.toLowerCase().includes(wcWord) : x) // Filter by tagword
|
||||
.map(x => [wcFile + ": " + x.trim(), "wildcardTag"]); // Mark as wildcard
|
||||
} else if (CFG.useWildcards && (tagword.startsWith("__") && !tagword.endsWith("__") || tagword === "__")) {
|
||||
// Show available wildcard files
|
||||
let tempResults = [];
|
||||
if (tagword !== "__") {
|
||||
let lmb = (x) => x[1].toLowerCase().includes(tagword.replace("__", ""))
|
||||
tempResults = wildcardFiles.filter(lmb).concat(wildcardExtFiles.filter(lmb)) // Filter by tagword
|
||||
} else {
|
||||
tempResults = wildcardFiles.concat(wildcardExtFiles);
|
||||
}
|
||||
results = tempResults.map(x => ["Wildcards: " + x[1].trim(), "wildcardFile"]); // Mark as wildcard
|
||||
} else if (CFG.useEmbeddings && tagword.match(/<[^,> ]*>?/g)) {
|
||||
// Show embeddings
|
||||
let tempResults = [];
|
||||
if (tagword !== "<") {
|
||||
tempResults = embeddings.filter(x => x.toLowerCase().includes(tagword.replace("<", ""))) // Filter by tagword
|
||||
} else {
|
||||
tempResults = embeddings;
|
||||
}
|
||||
// Since some tags are kaomoji, we have to still get the normal results first.
|
||||
// Create escaped search regex with support for * as a start placeholder
|
||||
let searchRegex;
|
||||
if (tagword.startsWith("*")) {
|
||||
tagword = tagword.slice(1);
|
||||
searchRegex = new RegExp(`${escapeRegExp(tagword)}`, 'i');
|
||||
} else {
|
||||
searchRegex = new RegExp(`(^|[^a-zA-Z])${escapeRegExp(tagword)}`, 'i');
|
||||
}
|
||||
genericResults = allTags.filter(x => x[0].toLowerCase().search(searchRegex) > -1).slice(0, CFG.maxResults);
|
||||
results = genericResults.concat(tempResults.map(x => ["Embeddings: " + x.trim(), "embedding"])); // Mark as embedding
|
||||
} else {
|
||||
// Create escaped search regex with support for * as a start placeholder
|
||||
let searchRegex;
|
||||
if (tagword.startsWith("*")) {
|
||||
tagword = tagword.slice(1);
|
||||
searchRegex = new RegExp(`${escapeRegExp(tagword)}`, 'i');
|
||||
} else {
|
||||
searchRegex = new RegExp(`(^|[^a-zA-Z])${escapeRegExp(tagword)}`, 'i');
|
||||
}
|
||||
// If onlyShowAlias is enabled, we don't need to include normal results
|
||||
if (CFG.alias.onlyShowAlias) {
|
||||
results = allTags.filter(x => x[3] && x[3].toLowerCase().search(searchRegex) >- 1);
|
||||
} else {
|
||||
// Else both normal tags and aliases/translations are included depending on the config
|
||||
let baseFilter = (x) => x[0].toLowerCase().search(searchRegex) >- 1;
|
||||
let aliasFilter = (x) => x[3] && x[3].toLowerCase().search(searchRegex) >- 1;
|
||||
let translationFilter = (x) => (translations.has(x[0]) && translations.get(x[0]).toLowerCase().search(searchRegex) >- 1)
|
||||
|| x[3] && x[3].split(",").some(y => translations.has(y) && translations.get(y).toLowerCase().search(searchRegex) >- 1);
|
||||
|
||||
let fil;
|
||||
if (CFG.alias.searchByAlias && CFG.translation.searchByTranslation)
|
||||
fil = (x) => baseFilter(x) || aliasFilter(x) || translationFilter(x);
|
||||
else if (CFG.alias.searchByAlias && !CFG.translation.searchByTranslation)
|
||||
fil = (x) => baseFilter(x) || aliasFilter(x);
|
||||
else if (CFG.translation.searchByTranslation && !CFG.alias.searchByAlias)
|
||||
fil = (x) => baseFilter(x) || translationFilter(x);
|
||||
else
|
||||
fil = (x) => baseFilter(x);
|
||||
|
||||
results = allTags.filter(fil);
|
||||
}
|
||||
// Slice if the user has set a max result count
|
||||
if (!CFG.showAllResults) {
|
||||
results = results.slice(0, CFG.maxResults);
|
||||
}
|
||||
}
|
||||
|
||||
// Guard for empty results
|
||||
if (!results.length) {
|
||||
hideResults(textArea);
|
||||
return;
|
||||
}
|
||||
|
||||
showResults(textArea);
|
||||
addResultsToList(textArea, results, tagword, true);
|
||||
}
|
||||
|
||||
var oldSelectedTag = null;
|
||||
function navigateInList(textArea, event) {
|
||||
// Return if the function is deactivated in the UI
|
||||
if (!CFG.activeIn.global) return;
|
||||
|
||||
validKeys = ["ArrowUp", "ArrowDown", "PageUp", "PageDown", "Home", "End", "Enter", "Tab", "Escape"];
|
||||
|
||||
if (!validKeys.includes(event.key)) return;
|
||||
if (!isVisible(textArea)) return
|
||||
// Return if ctrl key is pressed to not interfere with weight editing shortcut
|
||||
if (event.ctrlKey || event.altKey) return;
|
||||
|
||||
oldSelectedTag = selectedTag;
|
||||
|
||||
switch (event.key) {
|
||||
case "ArrowUp":
|
||||
if (selectedTag === null) {
|
||||
selectedTag = resultCount - 1;
|
||||
} else {
|
||||
selectedTag = (selectedTag - 1 + resultCount) % resultCount;
|
||||
}
|
||||
break;
|
||||
case "ArrowDown":
|
||||
if (selectedTag === null) {
|
||||
selectedTag = 0;
|
||||
} else {
|
||||
selectedTag = (selectedTag + 1) % resultCount;
|
||||
}
|
||||
break;
|
||||
case "PageUp":
|
||||
if (selectedTag === null || selectedTag === 0) {
|
||||
selectedTag = resultCount - 1;
|
||||
} else {
|
||||
selectedTag = (Math.max(selectedTag - 5, 0) + resultCount) % resultCount;
|
||||
}
|
||||
break;
|
||||
case "PageDown":
|
||||
if (selectedTag === null || selectedTag === resultCount - 1) {
|
||||
selectedTag = 0;
|
||||
} else {
|
||||
selectedTag = Math.min(selectedTag + 5, resultCount - 1) % resultCount;
|
||||
}
|
||||
break;
|
||||
case "Home":
|
||||
selectedTag = 0;
|
||||
break;
|
||||
case "End":
|
||||
selectedTag = resultCount - 1;
|
||||
break;
|
||||
case "ArrowLeft":
|
||||
selectedTag = 0;
|
||||
break;
|
||||
case "ArrowRight":
|
||||
selectedTag = resultCount - 1;
|
||||
break;
|
||||
case "Enter":
|
||||
if (selectedTag !== null) {
|
||||
insertTextAtCursor(textArea, results[selectedTag], tagword);
|
||||
}
|
||||
break;
|
||||
case "Tab":
|
||||
if (selectedTag === null) {
|
||||
selectedTag = 0;
|
||||
}
|
||||
insertTextAtCursor(textArea, results[selectedTag], tagword);
|
||||
break;
|
||||
case "Escape":
|
||||
hideResults(textArea);
|
||||
break;
|
||||
}
|
||||
if (selectedTag === resultCount - 1
|
||||
&& (event.key === "ArrowUp" || event.key === "ArrowDown" || event.key === "ArrowLeft" || event.key === "ArrowRight")) {
|
||||
addResultsToList(textArea, results, tagword, false);
|
||||
}
|
||||
// Update highlighting
|
||||
if (selectedTag !== null)
|
||||
updateSelectionStyle(textArea, selectedTag, oldSelectedTag);
|
||||
|
||||
// Prevent default behavior
|
||||
event.preventDefault();
|
||||
event.stopPropagation();
|
||||
}
|
||||
|
||||
// One-time setup, triggered from onUiUpdate
|
||||
async function setup() {
|
||||
// Load colors
|
||||
CFG["colors"] = (await readFile(`${tagBasePath}/colors.json?${new Date().getTime()}`, true));
|
||||
|
||||
// Load wildcards
|
||||
if (wildcardFiles.length === 0) {
|
||||
try {
|
||||
let wcFileArr = (await readFile(`${tagBasePath}/temp/wc.txt?${new Date().getTime()}`)).split("\n");
|
||||
let wcBasePath = wcFileArr[0].trim(); // First line should be the base path
|
||||
wildcardFiles = wcFileArr.slice(1)
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => [wcBasePath, x.trim().replace(".txt", "")]); // Remove file extension & newlines
|
||||
|
||||
// To support multiple sources, we need to separate them using the provided "-----" strings
|
||||
let wcExtFileArr = (await readFile(`${tagBasePath}/temp/wce.txt?${new Date().getTime()}`)).split("\n");
|
||||
let splitIndices = [];
|
||||
for (let index = 0; index < wcExtFileArr.length; index++) {
|
||||
if (wcExtFileArr[index].trim() === "-----") {
|
||||
splitIndices.push(index);
|
||||
}
|
||||
}
|
||||
// For each group, add them to the wildcardFiles array with the base path as the first element
|
||||
for (let i = 0; i < splitIndices.length; i++) {
|
||||
let start = splitIndices[i - 1] || 0;
|
||||
if (i > 0) start++; // Skip the "-----" line
|
||||
let end = splitIndices[i];
|
||||
|
||||
let wcExtFile = wcExtFileArr.slice(start, end);
|
||||
let base = wcExtFile[0].trim() + "/";
|
||||
wcExtFile = wcExtFile.slice(1)
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => x.trim().replace(base, "").replace(".txt", "")); // Remove file extension & newlines;
|
||||
|
||||
wcExtFile = wcExtFile.map(x => [base, x]);
|
||||
wildcardExtFiles.push(...wcExtFile);
|
||||
}
|
||||
} catch (e) {
|
||||
console.error("Error loading wildcards: " + e);
|
||||
}
|
||||
}
|
||||
// Load embeddings
|
||||
if (embeddings.length === 0) {
|
||||
try {
|
||||
embeddings = (await readFile(`${tagBasePath}/temp/emb.txt?${new Date().getTime()}`)).split("\n")
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => x.replace(".bin", "").replace(".pt", "").replace(".png", "")); // Remove file extensions
|
||||
} catch (e) {
|
||||
console.error("Error loading embeddings.txt: " + e);
|
||||
}
|
||||
}
|
||||
|
||||
// Find all textareas
|
||||
let textAreas = getTextAreas();
|
||||
|
||||
// Add event listener to apply settings button so we can mirror the changes to our internal config
|
||||
let applySettingsButton = gradioApp().querySelector("#tab_settings > div > .gr-button-primary");
|
||||
applySettingsButton.addEventListener("click", () => {
|
||||
// Wait 500ms to make sure the settings have been applied to the webui opts object
|
||||
setTimeout(async () => {
|
||||
await syncOptions();
|
||||
}, 500);
|
||||
});
|
||||
// Add change listener to our quicksettings to change our internal config without the apply button for them
|
||||
let quicksettings = gradioApp().querySelector('#quicksettings');
|
||||
let commonQueryPart = "[id^=setting_tac] > label >";
|
||||
quicksettings.querySelectorAll(`${commonQueryPart} input, ${commonQueryPart} textarea, ${commonQueryPart} select`).forEach(e => {
|
||||
e.addEventListener("change", () => {
|
||||
setTimeout(async () => {
|
||||
await syncOptions();
|
||||
}, 500);
|
||||
});
|
||||
});
|
||||
|
||||
// Not found, we're on a page without prompt textareas
|
||||
if (textAreas.every(v => v === null || v === undefined)) return;
|
||||
// Already added or unnecessary to add
|
||||
if (gradioApp().querySelector('.autocompleteResults.p')) {
|
||||
if (gradioApp().querySelector('.autocompleteResults.n') || !CFG.activeIn.negativePrompts) {
|
||||
return;
|
||||
}
|
||||
} else if (!CFG.activeIn.txt2img && !CFG.activeIn.img2img) {
|
||||
return;
|
||||
}
|
||||
|
||||
textAreas.forEach(area => {
|
||||
// Return if autocomplete is disabled for the current area type in config
|
||||
let textAreaId = getTextAreaIdentifier(area);
|
||||
if ((!CFG.activeIn.img2img && textAreaId.includes("img2img"))
|
||||
|| (!CFG.activeIn.txt2img && textAreaId.includes("txt2img"))
|
||||
|| (!CFG.activeIn.negativePrompts && textAreaId.includes("n"))
|
||||
|| (!CFG.activeIn.thirdParty && textAreaId.includes("thirdParty"))) {
|
||||
return;
|
||||
}
|
||||
|
||||
// Only add listeners once
|
||||
if (!area.classList.contains('autocomplete')) {
|
||||
// Add our new element
|
||||
var resultsDiv = createResultsDiv(area);
|
||||
area.parentNode.insertBefore(resultsDiv, area.nextSibling);
|
||||
// Hide by default so it doesn't show up on page load
|
||||
hideResults(area);
|
||||
|
||||
// Add autocomplete event listener
|
||||
area.addEventListener('input', debounce(() => autocomplete(area, area.value), CFG.delayTime));
|
||||
// Add focusout event listener
|
||||
area.addEventListener('focusout', debounce(() => hideResults(area), 400));
|
||||
// Add up and down arrow event listener
|
||||
area.addEventListener('keydown', (e) => navigateInList(area, e));
|
||||
// CompositionEnd fires after the user has finished IME composing
|
||||
// We need to block hide here to prevent the enter key from insta-closing the results
|
||||
area.addEventListener('compositionend', () => {
|
||||
hideBlocked = true;
|
||||
setTimeout(() => { hideBlocked = false; }, 100);
|
||||
});
|
||||
|
||||
// Add class so we know we've already added the listeners
|
||||
area.classList.add('autocomplete');
|
||||
}
|
||||
});
|
||||
|
||||
// Add style to dom
|
||||
let acStyle = document.createElement('style');
|
||||
//let css = gradioApp().querySelector('.dark') ? autocompleteCSS_dark : autocompleteCSS_light;
|
||||
let mode = gradioApp().querySelector('.dark') ? 0 : 1;
|
||||
// Check if we are on webkit
|
||||
let browser = navigator.userAgent.toLowerCase().indexOf('firefox') > -1 ? "firefox" : "other";
|
||||
|
||||
let css = autocompleteCSS;
|
||||
// Replace vars with actual values (can't use actual css vars because of the way we inject the css)
|
||||
Object.keys(styleColors).forEach((key) => {
|
||||
css = css.replace(`var(${key})`, styleColors[key][mode]);
|
||||
})
|
||||
Object.keys(browserVars).forEach((key) => {
|
||||
css = css.replace(`var(${key})`, browserVars[key][browser]);
|
||||
})
|
||||
|
||||
if (acStyle.styleSheet) {
|
||||
acStyle.styleSheet.cssText = css;
|
||||
} else {
|
||||
acStyle.appendChild(document.createTextNode(css));
|
||||
}
|
||||
gradioApp().appendChild(acStyle);
|
||||
}
|
||||
|
||||
onUiUpdate(async () => {
|
||||
if (Object.keys(opts).length === 0) return;
|
||||
if (CFG) return;
|
||||
|
||||
// Get our tag base path from the temp file
|
||||
tagBasePath = await readFile(`tmp/tagAutocompletePath.txt?${new Date().getTime()}`);
|
||||
// Load config from webui opts
|
||||
await syncOptions();
|
||||
// Rest of setup
|
||||
setup();
|
||||
});
|
||||
153
scripts/tag_autocomplete_helper.py
Normal file
153
scripts/tag_autocomplete_helper.py
Normal file
@@ -0,0 +1,153 @@
|
||||
# This helper script scans folders for wildcards and embeddings and writes them
|
||||
# to a temporary file to expose it to the javascript side
|
||||
|
||||
import gradio as gr
|
||||
from pathlib import Path
|
||||
from modules import scripts, script_callbacks, shared
|
||||
|
||||
# Webui root path
|
||||
FILE_DIR = Path().absolute()
|
||||
|
||||
# The extension base path
|
||||
EXT_PATH = FILE_DIR.joinpath('extensions')
|
||||
|
||||
# Tags base path
|
||||
TAGS_PATH = Path(scripts.basedir()).joinpath('tags')
|
||||
|
||||
# The path to the folder containing the wildcards and embeddings
|
||||
WILDCARD_PATH = FILE_DIR.joinpath('scripts/wildcards')
|
||||
EMB_PATH = Path(shared.cmd_opts.embeddings_dir)
|
||||
|
||||
|
||||
def find_ext_wildcard_paths():
|
||||
"""Returns the path to the extension wildcards folder"""
|
||||
found = list(EXT_PATH.glob('*/wildcards/'))
|
||||
return found
|
||||
|
||||
|
||||
# The path to the extension wildcards folder
|
||||
WILDCARD_EXT_PATHS = find_ext_wildcard_paths()
|
||||
|
||||
# The path to the temporary files
|
||||
STATIC_TEMP_PATH = FILE_DIR.joinpath('tmp') # In the webui root, on windows it exists by default, on linux it doesn't
|
||||
TEMP_PATH = TAGS_PATH.joinpath('temp') # Extension specific temp files
|
||||
|
||||
|
||||
def get_wildcards():
|
||||
"""Returns a list of all wildcards. Works on nested folders."""
|
||||
wildcard_files = list(WILDCARD_PATH.rglob("*.txt"))
|
||||
resolved = [w.relative_to(WILDCARD_PATH).as_posix(
|
||||
) for w in wildcard_files if w.name != "put wildcards here.txt"]
|
||||
return resolved
|
||||
|
||||
|
||||
def get_ext_wildcards():
|
||||
"""Returns a list of all extension wildcards. Works on nested folders."""
|
||||
wildcard_files = []
|
||||
|
||||
for path in WILDCARD_EXT_PATHS:
|
||||
wildcard_files.append(path.relative_to(FILE_DIR).as_posix())
|
||||
wildcard_files.extend(p.relative_to(path).as_posix() for p in path.rglob("*.txt") if p.name != "put wildcards here.txt")
|
||||
wildcard_files.append("-----")
|
||||
|
||||
return wildcard_files
|
||||
|
||||
|
||||
def get_embeddings():
|
||||
"""Returns a list of all embeddings"""
|
||||
return [str(e.relative_to(EMB_PATH)) for e in EMB_PATH.glob("**/*") if e.suffix in {".bin", ".pt", ".png"}]
|
||||
|
||||
|
||||
def write_tag_base_path():
|
||||
"""Writes the tag base path to a fixed location temporary file"""
|
||||
with open(STATIC_TEMP_PATH.joinpath('tagAutocompletePath.txt'), 'w', encoding="utf-8") as f:
|
||||
f.write(TAGS_PATH.relative_to(FILE_DIR).as_posix())
|
||||
|
||||
|
||||
def write_to_temp_file(name, data):
|
||||
"""Writes the given data to a temporary file"""
|
||||
with open(TEMP_PATH.joinpath(name), 'w', encoding="utf-8") as f:
|
||||
f.write(('\n'.join(data)))
|
||||
|
||||
|
||||
csv_files = []
|
||||
csv_files_withnone = []
|
||||
def update_tag_files():
|
||||
"""Returns a list of all potential tag files"""
|
||||
global csv_files, csv_files_withnone
|
||||
files = [str(t.relative_to(TAGS_PATH)) for t in TAGS_PATH.glob("*.csv")]
|
||||
csv_files = files
|
||||
csv_files_withnone = ["None"] + files
|
||||
|
||||
|
||||
|
||||
# Write the tag base path to a fixed location temporary file
|
||||
# to enable the javascript side to find our files regardless of extension folder name
|
||||
if not STATIC_TEMP_PATH.exists():
|
||||
STATIC_TEMP_PATH.mkdir(exist_ok=True)
|
||||
|
||||
write_tag_base_path()
|
||||
update_tag_files()
|
||||
|
||||
# Check if the temp path exists and create it if not
|
||||
if not TEMP_PATH.exists():
|
||||
TEMP_PATH.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# Set up files to ensure the script doesn't fail to load them
|
||||
# even if no wildcards or embeddings are found
|
||||
write_to_temp_file('wc.txt', [])
|
||||
write_to_temp_file('wce.txt', [])
|
||||
write_to_temp_file('emb.txt', [])
|
||||
|
||||
# Write wildcards to wc.txt if found
|
||||
if WILDCARD_PATH.exists():
|
||||
wildcards = [WILDCARD_PATH.relative_to(FILE_DIR).as_posix()] + get_wildcards()
|
||||
if wildcards:
|
||||
write_to_temp_file('wc.txt', wildcards)
|
||||
|
||||
# Write extension wildcards to wce.txt if found
|
||||
if WILDCARD_EXT_PATHS is not None:
|
||||
wildcards_ext = get_ext_wildcards()
|
||||
if wildcards_ext:
|
||||
write_to_temp_file('wce.txt', wildcards_ext)
|
||||
|
||||
# Write embeddings to emb.txt if found
|
||||
if EMB_PATH.exists():
|
||||
embeddings = get_embeddings()
|
||||
if embeddings:
|
||||
write_to_temp_file('emb.txt', embeddings)
|
||||
|
||||
# Register autocomplete options
|
||||
def on_ui_settings():
|
||||
TAC_SECTION = ("tac", "Tag Autocomplete")
|
||||
# Main tag file
|
||||
shared.opts.add_option("tac_tagFile", shared.OptionInfo("danbooru.csv", "Tag filename", gr.Dropdown, lambda: {"choices": csv_files}, refresh=update_tag_files, section=TAC_SECTION))
|
||||
# Active in settings
|
||||
shared.opts.add_option("tac_active", shared.OptionInfo(True, "Enable Tag Autocompletion", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_activeIn.txt2img", shared.OptionInfo(True, "Active in txt2img (Requires restart)", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_activeIn.img2img", shared.OptionInfo(True, "Active in img2img (Requires restart)", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_activeIn.negativePrompts", shared.OptionInfo(True, "Active in negative prompts (Requires restart)", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_activeIn.thirdParty", shared.OptionInfo(True, "Active in third party textboxes [Dataset Tag Editor] (Requires restart)", section=TAC_SECTION))
|
||||
# Results related settings
|
||||
shared.opts.add_option("tac_maxResults", shared.OptionInfo(5, "Maximum results", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_showAllResults", shared.OptionInfo(False, "Show all results", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_resultStepLength", shared.OptionInfo(100, "How many results to load at once", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_delayTime", shared.OptionInfo(100, "Time in ms to wait before triggering completion again (Requires restart)", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_useWildcards", shared.OptionInfo(True, "Search for wildcards", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_useEmbeddings", shared.OptionInfo(True, "Search for embeddings", section=TAC_SECTION))
|
||||
# Insertion related settings
|
||||
shared.opts.add_option("tac_replaceUnderscores", shared.OptionInfo(True, "Replace underscores with spaces on insertion", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_escapeParentheses", shared.OptionInfo(True, "Escape parentheses on insertion", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_appendComma", shared.OptionInfo(True, "Append comma on tag autocompletion", section=TAC_SECTION))
|
||||
# Alias settings
|
||||
shared.opts.add_option("tac_alias.searchByAlias", shared.OptionInfo(True, "Search by alias", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_alias.onlyShowAlias", shared.OptionInfo(False, "Only show alias", section=TAC_SECTION))
|
||||
# Translation settings
|
||||
shared.opts.add_option("tac_translation.translationFile", shared.OptionInfo("None", "Translation filename", gr.Dropdown, lambda: {"choices": csv_files_withnone}, refresh=update_tag_files, section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_translation.oldFormat", shared.OptionInfo(False, "Translation file uses old 3-column translation format instead of the new 2-column one", section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_translation.searchByTranslation", shared.OptionInfo(True, "Search by translation", section=TAC_SECTION))
|
||||
# Extra file settings
|
||||
shared.opts.add_option("tac_extra.extraFile", shared.OptionInfo("None", "Extra filename", gr.Dropdown, lambda: {"choices": csv_files_withnone}, refresh=update_tag_files, section=TAC_SECTION))
|
||||
shared.opts.add_option("tac_extra.onlyAliasExtraFile", shared.OptionInfo(False, "Extra file in alias only format", section=TAC_SECTION))
|
||||
|
||||
script_callbacks.on_ui_settings(on_ui_settings)
|
||||
@@ -1,363 +0,0 @@
|
||||
// Style for new elements. Gets appended to the Gradio root.
|
||||
const autocompleteCSS_dark = `
|
||||
#autocompleteResults {
|
||||
position: absolute;
|
||||
z-index: 999;
|
||||
margin: 5px 0 0 0;
|
||||
background-color: #0b0f19 !important;
|
||||
border: 1px solid #4b5563 !important;
|
||||
border-radius: 12px !important;
|
||||
overflow: hidden;
|
||||
}
|
||||
#autocompleteResultsList > li:nth-child(odd) {
|
||||
background-color: #111827;
|
||||
}
|
||||
#autocompleteResultsList > li {
|
||||
list-style-type: none;
|
||||
padding: 10px;
|
||||
cursor: pointer;
|
||||
}
|
||||
#autocompleteResultsList > li:hover {
|
||||
background-color: #1f2937;
|
||||
}
|
||||
#autocompleteResultsList > li.selected {
|
||||
background-color: #374151;
|
||||
}
|
||||
`;
|
||||
const autocompleteCSS_light = `
|
||||
#autocompleteResults {
|
||||
position: absolute;
|
||||
z-index: 999;
|
||||
margin: 5px 0 0 0;
|
||||
background-color: #ffffff !important;
|
||||
border: 1.5px solid #e5e7eb !important;
|
||||
border-radius: 12px !important;
|
||||
overflow: hidden;
|
||||
}
|
||||
#autocompleteResultsList > li:nth-child(odd) {
|
||||
background-color: #f9fafb;
|
||||
}
|
||||
#autocompleteResultsList > li {
|
||||
list-style-type: none;
|
||||
padding: 10px;
|
||||
cursor: pointer;
|
||||
}
|
||||
#autocompleteResultsList > li:hover {
|
||||
background-color: #f5f6f8;
|
||||
}
|
||||
#autocompleteResultsList > li.selected {
|
||||
background-color: #e5e7eb;
|
||||
}
|
||||
`;
|
||||
|
||||
var acConfig = null;
|
||||
|
||||
// Parse the CSV file into a 2D array. Doesn't use regex, so it is very lightweight.
|
||||
function parseCSV(str) {
|
||||
var arr = [];
|
||||
var quote = false; // 'true' means we're inside a quoted field
|
||||
|
||||
// Iterate over each character, keep track of current row and column (of the returned array)
|
||||
for (var row = 0, col = 0, c = 0; c < str.length; c++) {
|
||||
var cc = str[c], nc = str[c+1]; // Current character, next character
|
||||
arr[row] = arr[row] || []; // Create a new row if necessary
|
||||
arr[row][col] = arr[row][col] || ''; // Create a new column (start with empty string) if necessary
|
||||
|
||||
// If the current character is a quotation mark, and we're inside a
|
||||
// quoted field, and the next character is also a quotation mark,
|
||||
// add a quotation mark to the current column and skip the next character
|
||||
if (cc == '"' && quote && nc == '"') { arr[row][col] += cc; ++c; continue; }
|
||||
|
||||
// If it's just one quotation mark, begin/end quoted field
|
||||
if (cc == '"') { quote = !quote; continue; }
|
||||
|
||||
// If it's a comma and we're not in a quoted field, move on to the next column
|
||||
if (cc == ',' && !quote) { ++col; continue; }
|
||||
|
||||
// If it's a newline (CRLF) and we're not in a quoted field, skip the next character
|
||||
// and move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\r' && nc == '\n' && !quote) { ++row; col = 0; ++c; continue; }
|
||||
|
||||
// If it's a newline (LF or CR) and we're not in a quoted field,
|
||||
// move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\n' && !quote) { ++row; col = 0; continue; }
|
||||
if (cc == '\r' && !quote) { ++row; col = 0; continue; }
|
||||
|
||||
// Otherwise, append the current character to the current column
|
||||
arr[row][col] += cc;
|
||||
}
|
||||
return arr;
|
||||
}
|
||||
|
||||
// Load file
|
||||
function readFile(filePath) {
|
||||
let request = new XMLHttpRequest();
|
||||
request.open("GET", filePath, false);
|
||||
request.send(null);
|
||||
return request.responseText;
|
||||
}
|
||||
|
||||
function loadCSV() {
|
||||
let text = readFile(`file/tags/${acConfig.tagFile}`);
|
||||
return parseCSV(text);
|
||||
}
|
||||
|
||||
// Debounce function to prevent spamming the autocomplete function
|
||||
var dbTimeOut;
|
||||
const debounce = (func, wait = 300) => {
|
||||
return function(...args) {
|
||||
if (dbTimeOut) {
|
||||
clearTimeout(dbTimeOut);
|
||||
}
|
||||
|
||||
dbTimeOut = setTimeout(() => {
|
||||
func.apply(this, args);
|
||||
}, wait);
|
||||
}
|
||||
}
|
||||
|
||||
// Difference function to fix duplicates not being seen as changes in normal filter
|
||||
function difference(a, b) {
|
||||
if (a.length == 0) {
|
||||
return b;
|
||||
}
|
||||
if (b.length == 0) {
|
||||
return a;
|
||||
}
|
||||
|
||||
return [...b.reduce( (acc, v) => acc.set(v, (acc.get(v) || 0) - 1),
|
||||
a.reduce( (acc, v) => acc.set(v, (acc.get(v) || 0) + 1), new Map() )
|
||||
)].reduce( (acc, [v, count]) => acc.concat(Array(Math.abs(count)).fill(v)), [] );
|
||||
}
|
||||
|
||||
// Create the result list div and necessary styling
|
||||
function createResultsDiv() {
|
||||
let resultsDiv = document.createElement("div");
|
||||
let resultsList = document.createElement('ul');
|
||||
|
||||
resultsDiv.setAttribute('id', 'autocompleteResults');
|
||||
resultsList.setAttribute('id', 'autocompleteResultsList');
|
||||
resultsDiv.appendChild(resultsList);
|
||||
|
||||
return resultsDiv;
|
||||
}
|
||||
|
||||
// The selected tag index. Needs to be up here so hide can access it.
|
||||
var selectedTag = null;
|
||||
|
||||
// Show or hide the results div
|
||||
var isVisible = false;
|
||||
function showResults() {
|
||||
let resultsDiv = gradioApp().querySelector('#autocompleteResults');
|
||||
resultsDiv.style.display = "block";
|
||||
isVisible = true;
|
||||
}
|
||||
function hideResults() {
|
||||
let resultsDiv = gradioApp().querySelector('#autocompleteResults');
|
||||
resultsDiv.style.display = "none";
|
||||
isVisible = false;
|
||||
selectedTag = null;
|
||||
}
|
||||
|
||||
// On click, insert the tag into the prompt textbox with respect to the cursor position
|
||||
function insertTextAtCursor(text, tagword) {
|
||||
let promptTextbox = gradioApp().querySelector('#txt2img_prompt > label > textarea');
|
||||
let cursorPos = promptTextbox.selectionStart;
|
||||
let sanitizedText = acConfig.replaceUnderscores ? text.replaceAll("_", " ") : text;
|
||||
sanitizedText = acConfig.escapeParentheses ? sanitizedText.replaceAll("(", "\\(").replaceAll(")", "\\)") : sanitizedText;
|
||||
|
||||
var prompt = promptTextbox.value;
|
||||
let optionalComma = (prompt[cursorPos] === "," || prompt[cursorPos + tagword.length] === ",") ? "" : ", ";
|
||||
|
||||
// Edit prompt text
|
||||
let direction = prompt.substring(cursorPos, cursorPos + tagword.length) === tagword ? 1 : -1;
|
||||
if (direction === 1) {
|
||||
promptTextbox.value = prompt.substring(0, cursorPos) + sanitizedText + optionalComma + prompt.substring(cursorPos + tagword.length)
|
||||
// Update cursor position to after the inserted text
|
||||
promptTextbox.selectionStart = cursorPos + sanitizedText.length + optionalComma.length;
|
||||
} else {
|
||||
promptTextbox.value = prompt.substring(0, cursorPos - tagword.length) + sanitizedText + optionalComma + prompt.substring(cursorPos)
|
||||
promptTextbox.selectionStart = cursorPos - tagword.length + sanitizedText.length + optionalComma.length;
|
||||
}
|
||||
prompt = promptTextbox.value;
|
||||
promptTextbox.selectionEnd = promptTextbox.selectionStart;
|
||||
|
||||
// Since we've modified a Gradio Textbox component manually, we need to simulate an `input` DOM event to ensure its
|
||||
// internal Svelte data binding remains in sync.
|
||||
promptTextbox.dispatchEvent(new Event("input", { bubbles: true }));
|
||||
|
||||
// Hide results after inserting
|
||||
hideResults();
|
||||
|
||||
// Update previous tags with the edited prompt to prevent re-searching the same term
|
||||
let tags = prompt.match(/[^, ]+/g);
|
||||
previousTags = tags;
|
||||
}
|
||||
|
||||
function addResultsToList(results, tagword) {
|
||||
let resultsList = gradioApp().querySelector('#autocompleteResultsList');
|
||||
resultsList.innerHTML = "";
|
||||
|
||||
// Find right colors from config
|
||||
let tagFileName = acConfig.tagFile.split(".")[0];
|
||||
let tagColors = acConfig.colors;
|
||||
//let colorIndex = Object.keys(tagColors).findIndex(key => key === tagFileName);
|
||||
//let colorValues = Object.values(tagColors)[colorIndex];
|
||||
|
||||
let mode = gradioApp().querySelector('.dark') ? 0 : 1;
|
||||
|
||||
for (let i = 0; i < results.length; i++) {
|
||||
let result = results[i];
|
||||
let li = document.createElement("li");
|
||||
li.innerHTML = result[0];
|
||||
|
||||
// Set the color of the tag
|
||||
let tagType = result[1];
|
||||
li.style = `color: ${tagColors[tagFileName][tagType][mode]};`;
|
||||
// Add listener
|
||||
li.addEventListener("click", function() { insertTextAtCursor(result[0], tagword); });
|
||||
// Add element to list
|
||||
resultsList.appendChild(li);
|
||||
}
|
||||
}
|
||||
|
||||
function updateSelectionStyle(num) {
|
||||
let resultsList = gradioApp().querySelector('#autocompleteResultsList');
|
||||
let items = resultsList.getElementsByTagName('li');
|
||||
|
||||
for (let i = 0; i < items.length; i++) {
|
||||
items[i].classList.remove('selected');
|
||||
}
|
||||
|
||||
items[num].classList.add('selected');
|
||||
}
|
||||
|
||||
allTags = [];
|
||||
previousTags = [];
|
||||
results = [];
|
||||
tagword = "";
|
||||
resultCount = 0;
|
||||
function autocomplete(prompt) {
|
||||
// Guard for empty prompt
|
||||
if (prompt.length === 0) {
|
||||
hideResults();
|
||||
return;
|
||||
}
|
||||
|
||||
// Match tags with RegEx to get the last edited one
|
||||
let tags = prompt.match(/[^, ]+/g);
|
||||
let diff = difference(tags, previousTags)
|
||||
previousTags = tags;
|
||||
|
||||
// Guard for no difference / only whitespace remaining
|
||||
if (diff === undefined || diff.length === 0) {
|
||||
hideResults();
|
||||
return;
|
||||
}
|
||||
|
||||
tagword = diff[0]
|
||||
|
||||
// Guard for empty tagword
|
||||
if (tagword === undefined || tagword.length === 0) {
|
||||
hideResults();
|
||||
return;
|
||||
}
|
||||
|
||||
results = allTags.filter(x => x[0].includes(tagword)).slice(0, acConfig.maxResults);
|
||||
resultCount = results.length;
|
||||
|
||||
// Guard for empty results
|
||||
if (resultCount === 0) {
|
||||
hideResults();
|
||||
return;
|
||||
}
|
||||
|
||||
showResults();
|
||||
addResultsToList(results, tagword);
|
||||
}
|
||||
|
||||
function navigateInList(event) {
|
||||
validKeys = ["ArrowUp", "ArrowDown", "ArrowLeft", "ArrowRight", "Enter", "Escape"];
|
||||
|
||||
if (!validKeys.includes(event.key)) return;
|
||||
if (!isVisible) return
|
||||
|
||||
switch (event.key) {
|
||||
case "ArrowUp":
|
||||
if (selectedTag === null) {
|
||||
selectedTag = resultCount - 1;
|
||||
} else {
|
||||
selectedTag = (selectedTag - 1 + resultCount) % resultCount;
|
||||
}
|
||||
break;
|
||||
case "ArrowDown":
|
||||
if (selectedTag === null) {
|
||||
selectedTag = 0;
|
||||
} else {
|
||||
selectedTag = (selectedTag + 1) % resultCount;
|
||||
}
|
||||
break;
|
||||
case "ArrowLeft":
|
||||
selectedTag = 0;
|
||||
break;
|
||||
case "ArrowRight":
|
||||
selectedTag = resultCount - 1;
|
||||
break;
|
||||
case "Enter":
|
||||
if (selectedTag !== null) {
|
||||
insertTextAtCursor(results[selectedTag][0], tagword);
|
||||
}
|
||||
break;
|
||||
case "Escape":
|
||||
hideResults();
|
||||
break;
|
||||
}
|
||||
// Update highlighting
|
||||
if (selectedTag !== null)
|
||||
updateSelectionStyle(selectedTag);
|
||||
|
||||
// Prevent default behavior
|
||||
event.preventDefault();
|
||||
event.stopPropagation();
|
||||
}
|
||||
|
||||
onUiUpdate(function(){
|
||||
// One-time CSV setup
|
||||
if (acConfig === null) acConfig = JSON.parse(readFile("file/tags/config.json"));
|
||||
if (allTags.length === 0) allTags = loadCSV();
|
||||
|
||||
let promptTextbox = gradioApp().querySelector('#txt2img_prompt > label > textarea');
|
||||
|
||||
if (promptTextbox === null) return;
|
||||
if (gradioApp().querySelector('#autocompleteResults') != null) return;
|
||||
|
||||
// Only add listeners once
|
||||
if (!promptTextbox.classList.contains('autocomplete')) {
|
||||
// Add our new element
|
||||
var resultsDiv = gradioApp().querySelector('#autocompleteResults') ?? createResultsDiv();
|
||||
promptTextbox.parentNode.insertBefore(resultsDiv, promptTextbox.nextSibling);
|
||||
// Hide by default so it doesn't show up on page load
|
||||
hideResults();
|
||||
|
||||
// Add autocomplete event listener
|
||||
promptTextbox.addEventListener('input', debounce(() => autocomplete(promptTextbox.value), 100));
|
||||
// Add focusout event listener
|
||||
promptTextbox.addEventListener('focusout', debounce(() => hideResults(), 400));
|
||||
// Add up and down arrow event listener
|
||||
promptTextbox.addEventListener('keydown', (e) => navigateInList(e));
|
||||
|
||||
// Add class so we know we've already added the listeners
|
||||
promptTextbox.classList.add('autocomplete');
|
||||
|
||||
// Add style to dom
|
||||
let acStyle = document.createElement('style');
|
||||
|
||||
let css = gradioApp().querySelector('.dark') ? autocompleteCSS_dark : autocompleteCSS_light;
|
||||
if (acStyle.styleSheet) {
|
||||
acStyle.styleSheet.cssText = css;
|
||||
} else {
|
||||
acStyle.appendChild(document.createTextNode(css));
|
||||
}
|
||||
gradioApp().appendChild(acStyle);
|
||||
}
|
||||
});
|
||||
21
tags/colors.json
Normal file
21
tags/colors.json
Normal file
@@ -0,0 +1,21 @@
|
||||
{
|
||||
"danbooru": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["orange", "darkorange"]
|
||||
},
|
||||
"e621": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["gold", "goldenrod"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["tomato", "darksalmon"],
|
||||
"6": ["red", "maroon"],
|
||||
"7": ["whitesmoke", "black"],
|
||||
"8": ["seagreen", "darkseagreen"]
|
||||
}
|
||||
}
|
||||
@@ -1,26 +0,0 @@
|
||||
{
|
||||
"tagFile": "danbooru.csv",
|
||||
"maxResults": 5,
|
||||
"replaceUnderscores": true,
|
||||
"escapeParentheses": true,
|
||||
"colors": {
|
||||
"danbooru": {
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["orange", "darkorange"]
|
||||
},
|
||||
"e621": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["gold", "goldenrod"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["tomato", "darksalmon"],
|
||||
"6": ["red", "maroon"],
|
||||
"7": ["whitesmoke", "black"],
|
||||
"8": ["seagreen", "darkseagreen"]
|
||||
}
|
||||
}
|
||||
}
|
||||
209721
tags/danbooru.csv
209721
tags/danbooru.csv
File diff suppressed because it is too large
Load Diff
166094
tags/e621.csv
166094
tags/e621.csv
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user