mirror of
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
synced 2026-01-27 03:29:55 +00:00
Compare commits
243 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
8766965a30 | ||
|
|
34e68e1628 | ||
|
|
41d185b616 | ||
|
|
e0baa58ace | ||
|
|
c1ef12d887 | ||
|
|
4fc122de4b | ||
|
|
c341ccccb6 | ||
|
|
bda8701734 | ||
|
|
63fca457a7 | ||
|
|
38700d4743 | ||
|
|
bb492ba059 | ||
|
|
40ad070a02 | ||
|
|
209b1dd76b | ||
|
|
196fa19bfc | ||
|
|
6ffeeafc49 | ||
|
|
08b7c58ea7 | ||
|
|
6be91449f3 | ||
|
|
b515c15e01 | ||
|
|
827b99c961 | ||
|
|
49ec047af8 | ||
|
|
f94da07ed1 | ||
|
|
e2cfe7341b | ||
|
|
ce51ec52a2 | ||
|
|
f64d728ac6 | ||
|
|
1c6bba2a3d | ||
|
|
9a47c2ec2c | ||
|
|
fe32ad739d | ||
|
|
ade67e30a6 | ||
|
|
e9a21e7a55 | ||
|
|
3ef2a7d206 | ||
|
|
29b5bf0701 | ||
|
|
3eef536b64 | ||
|
|
0d24e697d2 | ||
|
|
a27633da55 | ||
|
|
4cd6174a22 | ||
|
|
9155e4d42c | ||
|
|
700642a400 | ||
|
|
1b592dbf56 | ||
|
|
d1eea880f3 | ||
|
|
119a3ad51f | ||
|
|
c820a22149 | ||
|
|
eb1e1820f9 | ||
|
|
ef59cff651 | ||
|
|
a454383c43 | ||
|
|
bec567fe26 | ||
|
|
d4041096c9 | ||
|
|
0903259ddf | ||
|
|
f3e64b1fa5 | ||
|
|
312cec5d71 | ||
|
|
b71e6339bd | ||
|
|
7ddbc3c0b2 | ||
|
|
4c2ef8f770 | ||
|
|
97c5e4f53c | ||
|
|
1d8d9f64b5 | ||
|
|
7437850600 | ||
|
|
829a4a7b89 | ||
|
|
22472ac8ad | ||
|
|
5f77fa26d3 | ||
|
|
f810b2dd8f | ||
|
|
08d3436f3b | ||
|
|
afa13306ef | ||
|
|
95200e82e1 | ||
|
|
a63ce64f4e | ||
|
|
a966be7546 | ||
|
|
d37e37acfa | ||
|
|
342fbc9041 | ||
|
|
d496569c9a | ||
|
|
7778142520 | ||
|
|
cde90c13c4 | ||
|
|
231b121fe0 | ||
|
|
c659ed2155 | ||
|
|
0a4c17cada | ||
|
|
6e65811d4a | ||
|
|
03673c060e | ||
|
|
1c11c4ad5a | ||
|
|
30c9593d3d | ||
|
|
f840586b6b | ||
|
|
886704e351 | ||
|
|
41626d22c3 | ||
|
|
57076060df | ||
|
|
5ef346cde3 | ||
|
|
edf76d9df2 | ||
|
|
837dc39811 | ||
|
|
f1870b7e87 | ||
|
|
20b6635a2a | ||
|
|
1fe8f26670 | ||
|
|
e82e958c3e | ||
|
|
2dd48eab79 | ||
|
|
4df90f5c95 | ||
|
|
a156214a48 | ||
|
|
15478e73b5 | ||
|
|
fcacf7dd66 | ||
|
|
82f819f336 | ||
|
|
effda54526 | ||
|
|
434301738a | ||
|
|
58804796f0 | ||
|
|
668ca800b8 | ||
|
|
a7233a594f | ||
|
|
4fba7baa69 | ||
|
|
5ebe22ddfc | ||
|
|
44c5450b28 | ||
|
|
5fd48f53de | ||
|
|
7128efc4f4 | ||
|
|
bd0ddfbb24 | ||
|
|
3108daf0e8 | ||
|
|
446ac14e7f | ||
|
|
363895494b | ||
|
|
04551a8132 | ||
|
|
ffc0e378d3 | ||
|
|
440f109f1f | ||
|
|
80fb247dbe | ||
|
|
b3e71e840d | ||
|
|
998514bebb | ||
|
|
d7e98200a8 | ||
|
|
ac790c8ede | ||
|
|
22365ec8d6 | ||
|
|
030a83aa4d | ||
|
|
460d32a4ed | ||
|
|
581bf1e6a4 | ||
|
|
74ea5493e5 | ||
|
|
94ec8884c3 | ||
|
|
6cf9acd6ab | ||
|
|
109a8a155e | ||
|
|
3caa1b51ed | ||
|
|
b44c36425a | ||
|
|
1e81403180 | ||
|
|
0f487a5c5c | ||
|
|
2baa12fea3 | ||
|
|
1a9157fe6e | ||
|
|
67eeb5fbf6 | ||
|
|
5911248ab9 | ||
|
|
1c693c0263 | ||
|
|
11ffed8afc | ||
|
|
cb54b66eda | ||
|
|
92a937ad01 | ||
|
|
ba9dce8d90 | ||
|
|
2622e1b596 | ||
|
|
b03b1a0211 | ||
|
|
3e33169a3a | ||
|
|
d8d991531a | ||
|
|
f626b9453d | ||
|
|
5067afeee9 | ||
|
|
018c6c8198 | ||
|
|
2846d79b7d | ||
|
|
783a847978 | ||
|
|
44effca702 | ||
|
|
475ef59197 | ||
|
|
3953260485 | ||
|
|
0a8e7d7d84 | ||
|
|
46d07d703a | ||
|
|
bd1dbe92c2 | ||
|
|
66fa745d6f | ||
|
|
37b5dca66e | ||
|
|
5db035cc3a | ||
|
|
90cf3147fd | ||
|
|
4d4f23e551 | ||
|
|
80b47c61bb | ||
|
|
57821aae6a | ||
|
|
e23bb6d4ea | ||
|
|
d4cca00575 | ||
|
|
86ea94a565 | ||
|
|
53f46c91a2 | ||
|
|
e5f93188c3 | ||
|
|
3e57842ac6 | ||
|
|
32c4589df3 | ||
|
|
5bbd97588c | ||
|
|
b2a663f7a7 | ||
|
|
6f93d19a2b | ||
|
|
79bab04fd2 | ||
|
|
5b69d1e622 | ||
|
|
651cf5fb46 | ||
|
|
5deb72cddf | ||
|
|
97ebe78205 | ||
|
|
b937e853c9 | ||
|
|
f63bbf947f | ||
|
|
16bc6d8868 | ||
|
|
ebe276ee44 | ||
|
|
995a5ecdba | ||
|
|
90d144a5f4 | ||
|
|
14a4440c33 | ||
|
|
cdf092f3ac | ||
|
|
e1598378dc | ||
|
|
599ad7f95f | ||
|
|
0b2bb138ee | ||
|
|
4a415f1a04 | ||
|
|
21de5fe003 | ||
|
|
a020df91b2 | ||
|
|
0260765b27 | ||
|
|
638c073f37 | ||
|
|
d11b53083b | ||
|
|
571072eea4 | ||
|
|
acfdbf1ed4 | ||
|
|
2e271aea5c | ||
|
|
b28497764f | ||
|
|
0d9d5f1e44 | ||
|
|
de3380818e | ||
|
|
acb85d7bb1 | ||
|
|
39ea33be9f | ||
|
|
1cac893e63 | ||
|
|
94823b871c | ||
|
|
599ff8a6f2 | ||
|
|
6893113e0b | ||
|
|
ed89d0e7e5 | ||
|
|
e47c14ab5e | ||
|
|
2ae512c8be | ||
|
|
4a427e309b | ||
|
|
510ee66b92 | ||
|
|
c41372143d | ||
|
|
f1d911834b | ||
|
|
40d9fc1079 | ||
|
|
88fa4398c8 | ||
|
|
3496fa58d9 | ||
|
|
737b697357 | ||
|
|
8523d7e9b5 | ||
|
|
77c0970500 | ||
|
|
707202ed71 | ||
|
|
922414b4ba | ||
|
|
7f18856321 | ||
|
|
cc1f35fc68 | ||
|
|
ae0f80ab0e | ||
|
|
8a436decf2 | ||
|
|
7357ccb347 | ||
|
|
d7075c5468 | ||
|
|
4923c8a177 | ||
|
|
9632909f72 | ||
|
|
7be3066d77 | ||
|
|
0c8ed0d265 | ||
|
|
5cbb9cefc2 | ||
|
|
a7468da59b | ||
|
|
f4218a71cd | ||
|
|
eb19cae176 | ||
|
|
7bfe4f3b54 | ||
|
|
9b66d42111 | ||
|
|
7a5a7f31cf | ||
|
|
76cd4bb6f1 | ||
|
|
21b050a355 | ||
|
|
1cb4fc8f25 | ||
|
|
2d7e6181f5 | ||
|
|
c6049fc2fa | ||
|
|
eff53d0ca7 | ||
|
|
a7da670e97 | ||
|
|
da65feea31 | ||
|
|
6997558714 |
1
.gitignore
vendored
1
.gitignore
vendored
@@ -1,2 +1,3 @@
|
||||
tags/temp/
|
||||
__pycache__/
|
||||
tags/tag_frequency.db
|
||||
|
||||
522
README.md
522
README.md
@@ -1,22 +1,70 @@
|
||||

|
||||
|
||||
# Booru tag autocompletion for A1111
|
||||
<div align="center">
|
||||
|
||||
[](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)
|
||||
# SD WebUI Tag Autocomplete
|
||||
## English • [简体中文](./README_ZH.md) • [日本語](./README_JA.md)
|
||||
|
||||
## [中文文档](./README_ZH.md)
|
||||
Booru style tag autocompletion for the AUTOMATIC1111 Stable Diffusion WebUI
|
||||
|
||||
This custom script serves as a drop-in extension for the popular [AUTOMATIC1111 web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) for Stable Diffusion.
|
||||
[![Github Release][release-shield]][release-url]
|
||||
[![stargazers][stargazers-shield]][stargazers-url]
|
||||
[![contributors][contributors-shield]][contributors-url]
|
||||
[![forks][forks-shield]][forks-url]
|
||||
[![issues][issues-shield]][issues-url]
|
||||
|
||||
[Changelog][release-url] •
|
||||
[Known Issues](#%EF%B8%8F-common-problems--known-issues) •
|
||||
[Report Bug][issues-url] •
|
||||
[Request Feature][issues-url]
|
||||
</div>
|
||||
<br/>
|
||||
|
||||
# 📄 Description
|
||||
|
||||
Tag Autocomplete is an extension for the popular [AUTOMATIC1111 web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) for Stable Diffusion.
|
||||
You can install it using the inbuilt available extensions list, clone the files manually as described [below](#-installation), or use a pre-packaged version from [Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases).
|
||||
|
||||
It displays autocompletion hints for recognized tags from "image booru" boards such as Danbooru, which are primarily used for browsing Anime-style illustrations.
|
||||
Since some Stable Diffusion models were trained using this information, for example [Waifu Diffusion](https://github.com/harubaru/waifu-diffusion), using exact tags in prompts can often improve composition and help to achieve a wanted look.
|
||||
Since most custom Stable Diffusion models were trained using this information or merged with ones that did, using exact tags in prompts can often improve composition and consistency, even if the model itself has a photorealistic style.
|
||||
|
||||
You can install it using the inbuilt available extensions list, clone the files manually as described [below](#installation), or use a pre-packaged version from [Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases).
|
||||
Disclaimer: The default tag lists contain NSFW terms, please use them responsibly.
|
||||
|
||||
## Common Problems & Known Issues:
|
||||
- Depending on your browser settings, sometimes an old version of the script can get cached. Try `CTRL+F5` to force-reload the site without cache if e.g. a new feature doesn't appear for you after an update.
|
||||
<br/>
|
||||
|
||||
## Screenshots & Demo videos
|
||||
# ✨ Features
|
||||
- 🚀 Instant completion hints while typing (under normal circumstances)
|
||||
- ⌨️ Keyboard navigation
|
||||
- 🌒 Dark & Light mode support
|
||||
- 🛠️ Many [settings](#%EF%B8%8F-settings) and customizability
|
||||
- 🌍 [Translation support](#translations) for tags, with optional live preview for the full prompt
|
||||
- **Note:** Translation files are provided by the community, see [here](#list-of-translations) for a list of translations I know of.
|
||||
|
||||
Tag autocomplete supports built-in completion for:
|
||||
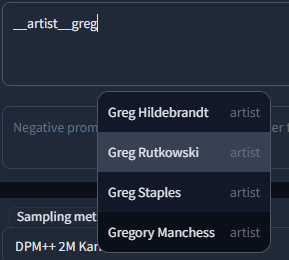
- 🏷️ **Danbooru & e621 tags** (Top 100k by post count, as of November 2022)
|
||||
- ✳️ [**Wildcards**](#wildcards)
|
||||
- ➕ [**Extra network**](#extra-networks-embeddings-hypernets-lora-) filenames, including
|
||||
- Textual Inversion embeddings [(jump to readme section)]
|
||||
- Hypernetworks
|
||||
- LoRA
|
||||
- LyCORIS / LoHA
|
||||
- 🪄 [**Chants**](#chants) (custom format for longer prompt presets)
|
||||
- 🏷️ "[**Extra file**](#extra-file)", one set of customizable extra tags
|
||||
|
||||
|
||||
Additionally, some support for other third party extensions exists:
|
||||
<details>
|
||||
<summary>Click to expand</summary>
|
||||
|
||||
- [Image Browser][image-browser-url] - Filename & EXIF keyword search
|
||||
- [Multidiffusion Upscaler][multidiffusion-url] - Regional Prompts
|
||||
- [Dataset Tag Editor][tag-editor-url] - Caption, Interrogate Result, Edit Tags & Edit Caption
|
||||
- [WD 1.4 Tagger][wd-tagger-url] - Additional & Excluded tags
|
||||
- [Umi AI][umi-url] - Completion for YAML wildcards
|
||||
</details>
|
||||
<br/>
|
||||
|
||||
# 🖼️ Screenshots & Demo videos
|
||||
<details>
|
||||
<summary>Click to expand</summary>
|
||||
Basic usage (with keyboard navigation):
|
||||
@@ -27,34 +75,42 @@ Wildcard script support:
|
||||
|
||||
https://user-images.githubusercontent.com/34448969/200128031-22dd7c33-71d1-464f-ae36-5f6c8fd49df0.mp4
|
||||
|
||||
Extra Network preview support:
|
||||
|
||||
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/assets/34448969/3c0cad84-fb5f-436d-b05a-28db35860d13
|
||||
|
||||
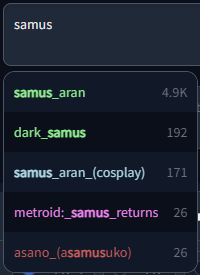
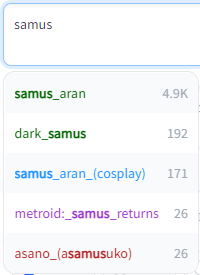
Dark and Light mode supported, including tag colors:
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
<br/>
|
||||
|
||||
## Installation
|
||||
### Using the built-in extension list
|
||||
1. Open the Extensions tab
|
||||
2. Open the Available sub-tab
|
||||
3. Click "Load from:"
|
||||
4. Find "Booru tag autocompletion" in the list
|
||||
# 📦 Installation
|
||||
## Using the built-in extension list
|
||||
1. Open the `Extensions` tab
|
||||
2. Open the `Available` sub-tab
|
||||
3. Click **Load from**
|
||||
4. Find **Booru tag autocompletion** in the list
|
||||
- The extension was one of the first available, so selecting "oldest first" will show it high up in the list.
|
||||
5. Click "Install" on the right side
|
||||
- Alternatively, use <kbd>CRTL</kbd> + <kbd>F</kbd> to search for the text on the page
|
||||
5. Click **Install** on the right side
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
|
||||
|
||||
### Manual clone
|
||||
## Manual clone
|
||||
```bash
|
||||
git clone "https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git" extensions/tag-autocomplete
|
||||
```
|
||||
(The second argument specifies the name of the folder, you can choose whatever you like).
|
||||
|
||||
## Additional completion support
|
||||
### Wildcards
|
||||
<br/>
|
||||
|
||||
# ❇️ Additional completion support
|
||||
## Wildcards
|
||||
Autocompletion also works with wildcard files used by https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards or other similar scripts/extensions.
|
||||
Completion is triggered by typing `__` (double underscore). It will first show a list of your wildcard files, and upon choosing one, the replacement options inside that file.
|
||||
This enables you to either insert categories to be replaced by the script, or directly choose one and use wildcards as a sort of categorized custom tag system.
|
||||
@@ -65,20 +121,64 @@ This enables you to either insert categories to be replaced by the script, or di
|
||||
|
||||
Wildcards are searched for in every extension folder, as well as the `scripts/wildcards` folder to support legacy versions. This means that you can combine wildcards from multiple extensions. Nested folders are also supported if you have grouped your wildcards in that way.
|
||||
|
||||
### Embeddings, Lora & Hypernets
|
||||
Completion for these three types is triggered by typing `<`. By default it will show all three mixed together, but further filtering can be done in the following way:
|
||||
## Extra networks (Embeddings, Hypernets, LoRA, ...)
|
||||
Completion for these types is triggered by typing `<`. By default it will show them all mixed together, but further filtering can be done in the following way:
|
||||
- `<e:` will only show embeddings
|
||||
- `<l:` or `<lora:` will only show Lora
|
||||
- `<l:` will only show LoRA and LyCORIS
|
||||
- Or `<lora:` and `<lyco:` respectively for the long form
|
||||
- `<h:` or `<hypernet:` will only show Hypernetworks
|
||||
|
||||
#### Embedding type filtering
|
||||
### Live previews
|
||||
Tag Autocomplete will now also show the preview images used for the cards in the Extra Networks menu in a small window next to the regular popup.
|
||||
This enables quick comparisons and additional info for unclear filenames without having to stop typing to look it up in the webui menu.
|
||||
It works for all supported extra network types that use preview images (Loras/Lycos, Embeddings & Hypernetworks). The preview window will stay hidden for normal tags or if no preview was found.
|
||||
|
||||

|
||||
|
||||
### Lora / Lyco trigger word completion
|
||||
This feature will try to add known trigger words on autocompleting a Lora/Lyco.
|
||||
|
||||
It primarily uses the list provided by the [model-keyword](https://github.com/mix1009/model-keyword/) extension, which thus needs to be installed to use this feature. The list is also regularly updated through it.
|
||||
However, once installed, you can deactivate it if you want, since tag autocomplete only needs the local keyword lists it ships with, not the extension itself.
|
||||
The used files are `lora-keyword.txt` and `lora-keyword-user.txt` in the model-keyword installation folder.
|
||||
If the main file isn't found, the feature will simply deactivate itself, everything else should work normally.
|
||||
|
||||
#### Note:
|
||||
As of [v1.5.0](https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/a3ddf464a2ed24c999f67ddfef7969f8291567be), the webui provides a native method to add activation keywords for Lora through the Extra networks config UI.
|
||||
These trigger words will always be preferred over the model-keyword ones and can be used without needing to install the model-keyword extension. This will however, obviously, be limited to those manually added keywords. For automatic discovery of keywords, you will still need the big list provided by model-keyword.
|
||||
|
||||
Custom trigger words can be added through two methods:
|
||||
1. Using the extra networks UI (recommended):
|
||||
- Only works with webui version v1.5.0 upwards, but much easier to use and works without the model-keyword extension
|
||||
- This method requires no manual refresh
|
||||
- <details>
|
||||
<summary>Image example</summary>
|
||||
|
||||

|
||||

|
||||
</details>
|
||||
2. Through the model-keyword UI:
|
||||
- One issue with this method is that it has no official support for the Lycoris extension and doesn't scan its folder for files, so to add them through the UI you will have to temporarily move them into the Lora model folder to be able to select them in model-keywords dropdown. Some are already included in the default list though, so trying it out first is advisable.
|
||||
- After having added your custom keywords, you will need to either restart the UI or use the "Refresh TAC temp files" setting button.
|
||||
- <details>
|
||||
<summary>Image example</summary>
|
||||
|
||||

|
||||
</details>
|
||||
|
||||
Sometimes the inserted keywords can be wrong due to a hash collision, however model-keyword and tag autocomplete take the name of the file into account too if the collision is known.
|
||||
|
||||
If it still inserts something wrong or you simply don't want the keywords added that time, you can undo / redo it directly after as often as you want, until you type something else
|
||||
(It uses the default undo/redo action of the browser, so <kbd>CTRL</kbd> + <kbd>Z</kbd>, context menu and mouse macros should all work).
|
||||
|
||||
### Embedding type filtering
|
||||
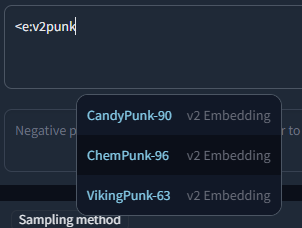
Embeddings trained for Stable Diffusion 1.x or 2.x models respectively are incompatible with the other type. To make it easier to find valid embeds, they are categorized by "v1 Embedding" and "v2 Embedding", including a slight color difference. You can also filter your search to include only v1 or v2 embeddings by typing `<v1/2` or `<e:v1/2` followed by the actual search term.
|
||||
|
||||
For example:
|
||||
|
||||
|
||||
|
||||
### Chants
|
||||
## Chants
|
||||
Chants are longer prompt presets. The name is inspired by some early prompt collections from Chinese users, which often were called along the lines of "Spellbook", "Codex", etc. The prompt snippets from such documents were fittingly called spells or chants for this reason.
|
||||
|
||||
Similar to embeddings and loras, this feature is triggered by typing the `<`, `<c:` or `<chant:` commands. For instance, when you enter `<c:HighQuality` in the prompt box and select it, the following prompt text will be inserted:
|
||||
@@ -88,6 +188,9 @@ Similar to embeddings and loras, this feature is triggered by typing the `<`, `<
|
||||
|
||||
|
||||
Chants can be added in JSON files following this format:
|
||||
<details>
|
||||
<summary>Chant format (click to expand)</summary>
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
@@ -110,6 +213,9 @@ Chants can be added in JSON files following this format:
|
||||
}
|
||||
]
|
||||
```
|
||||
</details>
|
||||
<br/>
|
||||
|
||||
The file can then be selected using the "Chant file" settings dropdown if it is located inside the extension's `tags` folder.
|
||||
|
||||
A chant object has four fields:
|
||||
@@ -118,7 +224,7 @@ A chant object has four fields:
|
||||
- `content` - The actual prompt content
|
||||
- `color` - Color, using the same category color system as normal tags
|
||||
|
||||
### Umi AI tags
|
||||
## Umi AI tags
|
||||
https://github.com/Klokinator/Umi-AI is a feature-rich wildcard extension similar to Unprompted or Dynamic Wildcards.
|
||||
In recent releases, it uses YAML-based wildcard tags to enable a complex chaining system,for example `<[preset][--female][sfw][species]>` will choose the preset category, exclude female related tags, further narrow it down with the following categories, and then choose one random fill-in matching all these criteria at runtime. Completion is triggered by `<[` and then each following new unclosed bracket, e.g. `<[xyz][`, until closed by `>`.
|
||||
|
||||
@@ -127,77 +233,290 @@ It also shows how many fill-in tags are available to choose from for that combo
|
||||
|
||||
Most of the credit goes to [@ctwrs](https://github.com/ctwrs) here, they contributed a lot as one of the Umi developers.
|
||||
|
||||
## Settings
|
||||
# 🛠️ Settings
|
||||
|
||||
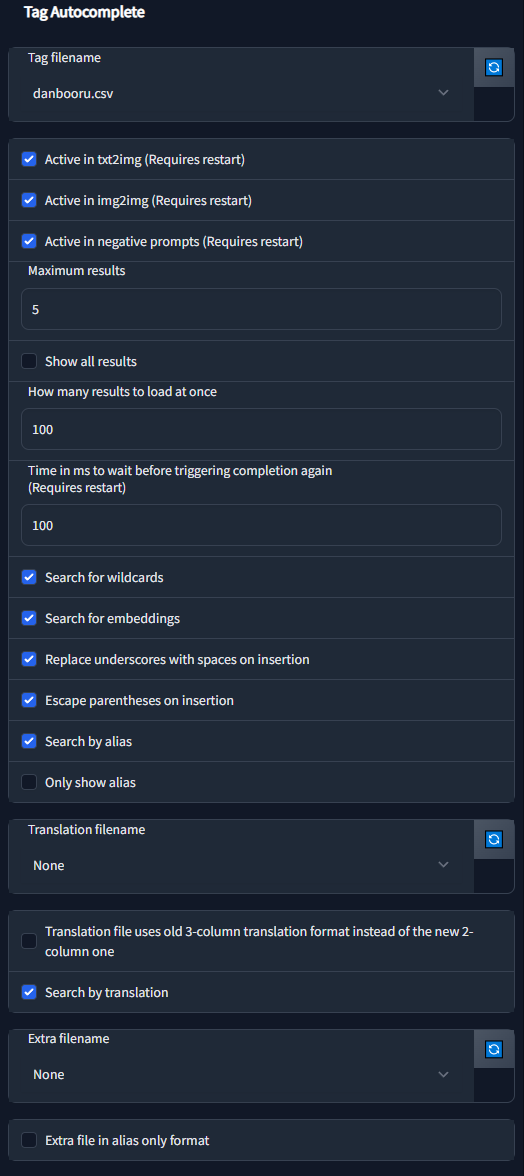
The extension has a large amount of configuration & customizability built in:
|
||||
The extension has a large amount of configuration & customizability built in. Most should be self-explanatory, but for a detailed description click on a section below.
|
||||
|
||||
|
||||
<!-- Filename -->
|
||||
<details>
|
||||
<summary>Tag filename</summary>
|
||||
|
||||
The main tag file the script uses. Included by default are `danbooru.csv` and `e621.csv`. While you can add custom tags here, the vast majority of models are not trained on anything other than these two (mostly danbooru), so it will not have much benefit.
|
||||
|
||||
You can also set it to `None` if you want to use other functionality of the extension (e.g. Wildcard or LoRA completion), but aren't interested in the normal tags.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Active In -->
|
||||
<details>
|
||||
<summary>"Active in" settings</summary>
|
||||
|
||||
Specifies where tag autocomplete should attach itself to and listen for changes.
|
||||
Negative prompts follow the settings for txt2img & img2img, so they will only be active if their "parent" is active.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Blacklist -->
|
||||
<details>
|
||||
<summary>Black / Whitelist</summary>
|
||||
|
||||
While the above options can turn off tag autocomplete globally, sometimes you might want to enable or disable it only for specific models. For example, if most of your models are Anime ones, you could add your photorealistic models, that weren't trained on booru tags and don't benefit from it, to the blacklist, which will automatically disable it after you switch to these models. You can use both the model name (including file extension) and their webui hashes (both short and long form).
|
||||
|
||||
`Blacklist` will exclude all specified models, while `Whitelist` will only activate it for these and stay off by default. One exception is an empty whitelist, which will be ignored (making it the same as an empty blacklist).
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Move Popup -->
|
||||
<details>
|
||||
<summary>Move completion popup with cursor</summary>
|
||||
|
||||
This option enables or disables the floating popup to follow the position of your cursor, like it would do in an IDE. The script tries to reserve enough room for the popup to prevent squishing on the right side, but that doesn't always work for longer tags. If disabled, the popup will stay on the left.
|
||||
|
||||

|
||||
|
||||

|
||||

|
||||
</details>
|
||||
<!-- Results Count -->
|
||||
<details>
|
||||
<summary>Result count</summary>
|
||||
|
||||
Settings for the amount of results to show at once.
|
||||
If `Show all results` is active, it will show a scrollable list instead of cutting it off after the number specified in `Maximum results`. For performance reasons, in that case not all are loaded at once, but instead in blocks. The block size is dictated by `How many results to load at once`. Once you reach the bottom, the next block will load (but that should rarely happen).
|
||||
|
||||
Notably, `Maximum results` will still have an influence if `Show all results` is used, since it dictates the height of the popup before scrolling begins.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Delay time -->
|
||||
<details>
|
||||
<summary>Completion delay</summary>
|
||||
|
||||
Depending on the configuration, real time tag completion can get computationally expensive.
|
||||
This option sets a "debounce" delay in milliseconds (1000ms = 1s), during which no second completion will get queried. This might especially be useful if you type very fast.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Search for -->
|
||||
<details>
|
||||
<summary>"Search for" settings</summary>
|
||||
|
||||
Pretty self explanatory, enables or disables certain completion types.
|
||||
|
||||
Umi AI wildcards are included in the normal wildcard option here, although they use a different format, since their usage intention is similar.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Wiki links -->
|
||||
<details>
|
||||
<summary>"?" Wiki links</summary>
|
||||
|
||||
If this option is turned on, it will show a `?` link next to the tag. Clicking this will try to open the wiki page for that tag on danbooru or e621, depending on which tag file you use.
|
||||
|
||||
> ⚠️ Warning:
|
||||
>
|
||||
> Danbooru and e621 are external sites and include a lot of NSFW content, which might show in the list of examples for a tag on its wiki page. Because of this, the option is disabled by default.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Wiki links -->
|
||||
<details>
|
||||
<summary>Extra network live previews</summary>
|
||||
|
||||
This option enables a small preview window alongside the normal completion popup that will show the card preview also usd in the extra networks tab for that file.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Insertion -->
|
||||
<details>
|
||||
<summary>Completion settings</summary>
|
||||
|
||||
These settings specify how the text will be inserted.
|
||||
|
||||
Booru sites mostly use underscores in tags instead of spaces, but during preprocessing most models replaced this back with spaces since the CLIP encoder used in Stable diffusion was trained on natural language. Thus, by default tag autocomplete will as well.
|
||||
|
||||
Parentheses are used as control characters in the webui to give more attention / weight to a specific part of the prompt, so tags including parentheses are escaped (`\( \)`) by default to not influence that.
|
||||
|
||||
Depending on the last setting, tag autocomplete will append a comma and space after inserting a tag, which may help for rapid completion of multiple tags in a row.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Lora keywords -->
|
||||
<details>
|
||||
<summary>Lora / Lyco trigger word insertion</summary>
|
||||
|
||||
See [the detailed readme section](#lora--lyco-trigger-word-completion) for more info.
|
||||
|
||||
Selects the mode to use for Lora / Lyco trigger word insertion.
|
||||
Needs the [model-keyword](https://github.com/mix1009/model-keyword/) extension to be installed, else it will do nothing.
|
||||
|
||||
- Never
|
||||
- Will not complete trigger words, even if the model-keyword extension is installed
|
||||
- Only user list
|
||||
- Will only load the custom keywords specified in the lora-keyword-user.txt file and ignore the default list
|
||||
- Always
|
||||
- Will load and use both lists
|
||||
|
||||
Switching from "Never" to what you had before or back will not require a restart, but changing between the full and user only list will.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Wildcard path mode -->
|
||||
<details>
|
||||
<summary>Wildcard path completion</summary>
|
||||
|
||||
Some collections of wildcards are organized in nested subfolders.
|
||||
They are listed with the full path to the file, like "hair/colors/light/..." or "clothing/male/casual/..." etc.
|
||||
|
||||
In these cases it is often hard to type the full path manually, but you still want to narrow the selection before further scrolling in the list.
|
||||
For this, a partial completion of the path can be triggered with <kbd>Tab</kbd> (or the custom hotkey for `ChooseSelectedOrFirst`) if the results to choose from are all paths.
|
||||
|
||||
This setting determines the mode it should use for completion:
|
||||
- To next folder level:
|
||||
- Completes until the next `/` in the path, preferring your selection as the way forward
|
||||
- If you want to directly choose an option, <kbd>Enter</kbd> / the `ChooseSelected` hotkey will skip it and fully complete.
|
||||
- To first difference:
|
||||
- Completes until the first difference in the results and waits for additional info
|
||||
- E.g. if you have "/sub/folder_a/..." and "/sub/folder_b/...", completing after typing "su" will insert everything up to "/sub/folder_" and stop there until you type a or b to clarify.
|
||||
- If you selected something with the arrow keys (regardless of pressing Enter or Tab), it will skip it and fully complete.
|
||||
- Always fully:
|
||||
- As the name suggests, disables the partial completion behavior and inserts the full path under all circumstances like with normal tags.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Alias -->
|
||||
<details>
|
||||
<summary>Alias settings</summary>
|
||||
|
||||
Tags often are referred to with multiple aliases. If `Search by alias` is turned on, those will be included in the search results, which might help if you are unsure of the correct tag. They will still get replaced by the actual tag they are linked to on insertion, since that is what the models were trained on.
|
||||
|
||||
`Only show alias` sets if you want to see only the alias or also the tag it maps to
|
||||
(shown as `<alias> ➝ <actual>`)
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Translations -->
|
||||
<details>
|
||||
<summary>Translation settings</summary>
|
||||
|
||||
Tag Autocomplete has support for tag translations specified in a separate file (`Translation filename`). You can search for tags using those translations, meaning that if you don't know the English tagword and have a translation file in your native language, you can use that instead.
|
||||
|
||||
It also has a legacy format option for some old files used in the community, as well as an experimental live translation preview for the whole prompt so you can easily find and edit tags afterwards.
|
||||
|
||||
For more details, see the [section on translations](#translations) below.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Extra file -->
|
||||
<details>
|
||||
<summary>Extra file settings</summary>
|
||||
|
||||
Specifies a set of extra tags that get appended either before or after the regular results, as specified here. Mostly useful for small custom tag sets such as the commonly used quality tags (masterpiece, best quality, etc.)
|
||||
|
||||
If you want completion for longer presets or even whole prompts, have a look at [Chants](#chants) instead.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Chants -->
|
||||
<details>
|
||||
<summary>Chant filename</summary>
|
||||
|
||||
Chants are longer presets or even whole prompts that can be selected & inserted at once, similar to the built in styles dropdown of the webui. They do offer some additional features though, and are faster to use.
|
||||
|
||||
For more info, see the section on [Chants](#chants) above.
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Hotkeys -->
|
||||
<details>
|
||||
<summary>Hotkeys</summary>
|
||||
|
||||
You can specify the hotkeys for most keyboard navigation features here.
|
||||
Should be one of the key names specified in https://www.w3.org/TR/uievents-key/#named-key-attribute-value.
|
||||
|
||||
Function explanation:
|
||||
- Move Up / Down: Select the next tag
|
||||
- Jump Up / Down: Move by five places at once
|
||||
- Jump to Start / End: Jump to the top or bottom of the list
|
||||
- ChooseSelected: Select the highlighted tag, or close popup if nothing was selected
|
||||
- ChooseSelectedOrFirst: Same as above, but default to the first result if nothing was selected
|
||||
- Close: Closes the popup
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Colors -->
|
||||
<details>
|
||||
<summary>Colors</summary>
|
||||
|
||||
Here, you can change the default colors used for different tag categories. They were chosen to be similar to the category colors of their source site.
|
||||
|
||||
The format is standard JSON
|
||||
- The object names correspond to the tag filename they should be used for.
|
||||
- The numbers are specifying the tag type, which is dependent on the tag source. For more info, see [CSV tag data](#csv-tag-data).
|
||||
- The first value in the square brackets is for dark, the second for light mode. HTML color names and hex codes should both work.
|
||||
|
||||
| Setting | Description |
|
||||
|---------|-------------|
|
||||
| tagFile | Specifies the tag file to use. You can provide a custom tag database of your liking, but since the script was developed with Danbooru tags in mind, it might not work properly with other configurations.|
|
||||
| activeIn | Allows to selectively (de)activate the script for txt2img, img2img, and the negative prompts for both. |
|
||||
| maxResults | How many results to show max. For the default tag set, the results are ordered by occurence count. For embeddings and wildcards it will show all results in a scrollable list. |
|
||||
| resultStepLength | Allows to load results in smaller batches of the specified size for better performance in long lists or if showAllResults is true. |
|
||||
| delayTime | Specifies how much to wait in milliseconds before triggering autocomplete. Helps prevent too frequent updates while typing. |
|
||||
| showAllResults | If true, will ignore maxResults and show all results in a scrollable list. **Warning:** can lag your browser for long lists. |
|
||||
| replaceUnderscores | If true, undescores are replaced with spaces on clicking a tag. Might work better for some models. |
|
||||
| escapeParentheses | If true, escapes tags containing () so they don't contribute to the web UI's prompt weighting functionality. |
|
||||
| appendComma | Specifies the starting value of the "Append commas" UI switch. If UI options are disabled, this will always be used. |
|
||||
| useWildcards | Used to toggle the wildcard completion functionality. |
|
||||
| useEmbeddings | Used to toggle the embedding completion functionality. |
|
||||
| alias | Options for aliases. More info in the section below. |
|
||||
| translation | Options for translations. More info in the section below. |
|
||||
| extras | Options for additional tag files / aliases / translations. More info below. |
|
||||
| chantFile | The file to use for chants (longer prompt presets / shortcuts). |
|
||||
| keymap | Customizable hotkeys. |
|
||||
| colors | Customizable tag colors. More info below. |
|
||||
### Colors
|
||||
Tag type colors can be specified by changing the JSON code in the tag autocomplete settings.
|
||||
The format is standard JSON, with the object names corresponding to the tag filenames (without the .csv) they should be used for.
|
||||
The first value in the square brackets is for dark, the second for light mode. Color names and hex codes should both work.
|
||||
```json
|
||||
{
|
||||
"danbooru": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["indianred", "firebrick"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["orange", "darkorange"]
|
||||
},
|
||||
"e621": {
|
||||
"-1": ["red", "maroon"],
|
||||
"0": ["lightblue", "dodgerblue"],
|
||||
"1": ["gold", "goldenrod"],
|
||||
"3": ["violet", "darkorchid"],
|
||||
"4": ["lightgreen", "darkgreen"],
|
||||
"5": ["tomato", "darksalmon"],
|
||||
"6": ["red", "maroon"],
|
||||
"7": ["whitesmoke", "black"],
|
||||
"8": ["seagreen", "darkseagreen"]
|
||||
}
|
||||
}
|
||||
```
|
||||
This can also be used to add new color sets for custom tag files.
|
||||
The numbers are specifying the tag type, which is dependent on the tag source. For an example, see [CSV tag data](#csv-tag-data).
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Temp files refresh -->
|
||||
<details>
|
||||
<summary>Refresh TAC temp files</summary>
|
||||
|
||||
### Aliases, Translations & Extra tags
|
||||
#### Aliases
|
||||
Like on Booru sites, tags can have one or multiple aliases which redirect to the actual value on completion. These will be searchable / shown according to the settings in `config.json`:
|
||||
- `searchByAlias` - Whether to also search for the alias or only the actual tag.
|
||||
- `onlyShowAlias` - Shows only the alias instead of `alias -> actual`. Only for displaying, the inserted text at the end is still the actual tag.
|
||||
This is a "fake" setting, meaning it doesn't actually configure anything. Rather, it is a small hack to abuse the refresh button developers can add to webui options. Clicking on the refresh button next to this setting will force tag autocomplete to recreate and reload some temporary internal files, which normally only happens on restarting the UI.
|
||||
|
||||
#### Translations
|
||||
Tag autocomplete depends on these files for various functionality, especially related to extra networks and wildcard completion. This setting can be used to rebuild the lists if you have, for example, added a few new LoRAs into the folder and don't want to restart the UI to get tag autocomplete to list them.
|
||||
|
||||
You can also add this to your quicksettings bar to have the refresh button available at all times.
|
||||
|
||||

|
||||
</details>
|
||||
<br/>
|
||||
|
||||
# Translations
|
||||
An additional file can be added in the translation section, which will be used to translate both tags and aliases and also enables searching by translation.
|
||||
This file needs to be a CSV in the format `<English tag/alias>,<Translation>`, but for backwards compatibility with older files that used a three column format, you can turn on `oldFormat` to use that instead.
|
||||
This file needs to be a CSV in the format `<English tag/alias>,<Translation>`. Some older files use a three column format, which requires a compatibility setting to be activated.
|
||||
You can find it under `Settings > Tag autocomplete > Translation filename > Translation file uses old 3-column translation format instead of the new 2-column one`.
|
||||
With it on, the second column will be unused and skipped during parsing.
|
||||
|
||||
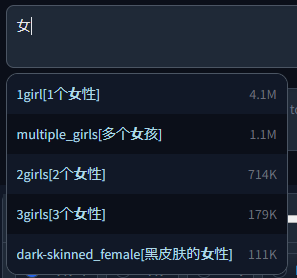
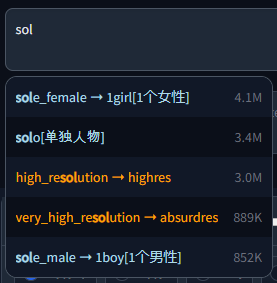
Example with chinese translation:
|
||||
Example with Chinese translation:
|
||||
|
||||
|
||||
|
||||
|
||||
#### Extra file
|
||||
## List of translations
|
||||
- [🇨🇳 Chinese tags](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/discussions/23) by @HalfMAI, using machine translation and manual correction for the most common tags (uses legacy format)
|
||||
- [🇨🇳 Chinese tags](https://github.com/sgmklp/tag-for-autocompletion-with-translation) by @sgmklp, smaller set of manual translations based on https://github.com/zcyzcy88/TagTable
|
||||
- [🇯🇵 Japanese tags](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/discussions/265) by @applemango, both machine and human translations available
|
||||
|
||||
> ### 🫵 I need your help!
|
||||
> Translations are a community effort. If you have translated a tag file or want to create one, please open a Pull Request or Issue so your link can be added here.
|
||||
> Please make sure the quality is alright though, machine translation gets a lot of stuff wrong even for the most common tags.
|
||||
|
||||
## Live preview
|
||||
> ⚠️ Warning:
|
||||
>
|
||||
> This feature is still experimental, you might encounter some bugs when using it.
|
||||
|
||||
This will show a live preview of all detected tags in the prompt, both correctly separated by commas as well as in a longer sentence. It can detect up to three-word pairs in natural sentences, preferring perfect multi-word matches over single tags.
|
||||
|
||||
Above the detected tags will be their translation from the translation file, so if you aren't sure what the English tag means, you can easily find it there even after they have been inserted into the prompt (instead of just in the popup during completion).
|
||||
|
||||
The option defaults to off, but you can activate it by choosing a translation file and checking "Show live tag translation below prompt".
|
||||
It will not affect the normal functionality if it is off.
|
||||
|
||||
Example with Chinese translation:
|
||||
|
||||

|
||||
|
||||
Clicking on a detected tag will also select it in the prompt for quick editing.
|
||||
|
||||

|
||||
|
||||
#### ⚠️ Known issues with live translation:
|
||||
The translation updates when the user types or pastes text, but not if the action happens programmatically (e.g. applying a style or loading from PNG Info / Image Browser). This can be worked around by typing something manually after the programmatic edit.
|
||||
|
||||
# Extra file
|
||||
An extra file can be used to add new / custom tags not included in the main set.
|
||||
The format is identical to the normal tag format shown in [CSV tag data](#csv-tag-data) below, with one exception:
|
||||
Since custom tags likely have no count, column three (or two if counting from zero) is instead used for the gray meta text displayed next to the tag.
|
||||
@@ -209,7 +528,7 @@ An example with the included (very basic) extra-quality-tags.csv file:
|
||||
|
||||
Whether the custom tags should be added before or after the normal tags can be chosen in the settings.
|
||||
|
||||
## CSV tag data
|
||||
# CSV tag data
|
||||
The script expects a CSV file with tags saved in the following way:
|
||||
```csv
|
||||
<name>,<type>,<postCount>,"<aliases>"
|
||||
@@ -248,3 +567,34 @@ or similarly for e621:
|
||||
|8 | Lore |
|
||||
|
||||
The tag type is used for coloring entries in the result list.
|
||||
|
||||
|
||||
## ⚠️ Common Problems & Known Issues:
|
||||
- Depending on your browser settings, sometimes an old version of the script can get cached. Try
|
||||
<kbd>CTRL</kbd> + <kbd>F5</kbd>
|
||||
to force-reload the site without cache if e.g. a new feature doesn't appear for you after an update.
|
||||
- If the prompt popup has broken styling for you or doesn't appear at all (like [this](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/assets/34448969/7bbfdd54-fc23-4bfc-85af-24704b139b3a)), make sure to update your **openpose-editor** extension if you have it installed. It is known to cause issues with other extensions in older versions.
|
||||
|
||||
|
||||
<!-- Variable declarations for shorter main text -->
|
||||
[release-shield]: https://img.shields.io/github/v/release/DominikDoom/a1111-sd-webui-tagcomplete?logo=github&style=
|
||||
[release-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases
|
||||
|
||||
[contributors-shield]: https://img.shields.io/github/contributors/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[contributors-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/graphs/contributors
|
||||
|
||||
[forks-shield]: https://img.shields.io/github/forks/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[forks-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/network/members
|
||||
|
||||
[stargazers-shield]: https://img.shields.io/github/stars/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[stargazers-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/stargazers
|
||||
|
||||
[issues-shield]: https://img.shields.io/github/issues/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[issues-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/issues/new/choose
|
||||
|
||||
<!-- Links for feature section -->
|
||||
[image-browser-url]: https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
|
||||
[multidiffusion-url]: https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
|
||||
[tag-editor-url]: https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
|
||||
[wd-tagger-url]: https://github.com/toriato/stable-diffusion-webui-wd14-tagger
|
||||
[umi-url]: https://github.com/Klokinator/Umi-AI
|
||||
|
||||
523
README_JA.md
Normal file
523
README_JA.md
Normal file
@@ -0,0 +1,523 @@
|
||||

|
||||
|
||||
<div align="center">
|
||||
|
||||
# SD WebUI Tag Autocomplete
|
||||
## [English Document](./README.md), [中文文档](./README_ZH.md), 日本語
|
||||
|
||||
Booruスタイルタグを自動補完するためのAUTOMATIC1111 Stable Diffusion WebUI用拡張機能
|
||||
|
||||
[![Github Release][release-shield]][release-url]
|
||||
[![stargazers][stargazers-shield]][stargazers-url]
|
||||
[![contributors][contributors-shield]][contributors-url]
|
||||
[![forks][forks-shield]][forks-url]
|
||||
[![issues][issues-shield]][issues-url]
|
||||
|
||||
[変更内容][release-url] •
|
||||
[確認されている問題](#%EF%B8%8F-よくある問題また現在確認されている問題) •
|
||||
[バグを報告する][issues-url] •
|
||||
[機能追加に関する要望][issues-url]
|
||||
</div>
|
||||
<br/>
|
||||
|
||||
# 📄 説明
|
||||
|
||||
Tag AutocompleteはStable Diffusion向けの人気のweb UIである、[AUTOMATIC1111 web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)の拡張機能として利用できます。
|
||||
|
||||
主にアニメ系イラストを閲覧するための掲示板「Danbooru」などで利用されているタグの自動補完ヒントを表示するための拡張機能となります。
|
||||
例えば[Waifu Diffusion](https://github.com/harubaru/waifu-diffusion)やNAIから派生した多くのモデルやマージなど、Stable Diffusionモデルの中にはこの情報を使って学習されたものもあるため、プロンプトに正確なタグを使用することで、多くのケースで構図を改善した思い通りの画像が生成できるようになります。
|
||||
|
||||
組み込みの利用可能な拡張機能リストを使ってインストールしたり、[下記](#-インストール)の説明に従って手動でファイルをcloneしたり、[Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)にあるパッケージ済みのバージョンを使うことができます。
|
||||
|
||||
<br/>
|
||||
|
||||
# ✨ Features
|
||||
- 🚀 タイピング中に補完のためのヒントを表示 (通常時)
|
||||
- ⌨️ キーボードナビゲーション
|
||||
- 🌒 ダーク&ライトモードのサポート
|
||||
- 🛠️ 多くの[設定](#%EF%B8%8F-設定)とカスタマイズ性を提供
|
||||
- 🌍 [翻訳サポート](#翻訳)タグ、オプションでプロンプトのライブ プレビュー付き
|
||||
- 私が知っている翻訳のリストは[こちら](#翻訳リスト)を参照してください。
|
||||
|
||||
タグの自動補完は組み込まれている補完内容をサポートしています:
|
||||
- 🏷️ **Danbooru & e621 tags** (投稿数上位100k、2022年11月現在)
|
||||
- ✳️ [**ワイルドカード**](#ワイルドカード)
|
||||
- ➕ [**Extra networks**](#extra-networks-embeddings-hypernets-lora-) filenames, including
|
||||
- Textual Inversion embeddings
|
||||
- Hypernetworks
|
||||
- LoRA
|
||||
- LyCORIS / LoHA
|
||||
- 🪄 [**Chants(詠唱)**](#chants詠唱) (長いプロンプトプリセット用のカスタムフォーマット)
|
||||
- 🏷️ "[**Extra file**](#extra-file)", カスタマイズ可能なextra tagsセット
|
||||
|
||||
|
||||
さらに、サードパーティの拡張機能にも対応しています:
|
||||
<details>
|
||||
<summary>クリックして開く</summary>
|
||||
|
||||
- [Image Browser][image-browser-url] - ファイル名とEXIFキーワードによる検索
|
||||
- [Multidiffusion Upscaler][multidiffusion-url] - 地域別のプロンプト
|
||||
- [Dataset Tag Editor][tag-editor-url] - キャプション, 結果の確認, タグの編集 & キャプションの編集
|
||||
- [WD 1.4 Tagger][wd-tagger-url] - 追加と除外タグ
|
||||
- [Umi AI][umi-url] - YAMLワイルドカードの補完
|
||||
</details>
|
||||
<br/>
|
||||
|
||||
## スクリーンショット & デモ動画
|
||||
<details>
|
||||
<summary>クリックすると開きます</summary>
|
||||
基本的な使い方 (キーボード操作を用いたもの):
|
||||
|
||||
https://user-images.githubusercontent.com/34448969/200128020-10d9a8b2-cea6-4e3f-bcd2-8c40c8c73233.mp4
|
||||
|
||||
ワイルドカードをサポート:
|
||||
|
||||
https://user-images.githubusercontent.com/34448969/200128031-22dd7c33-71d1-464f-ae36-5f6c8fd49df0.mp4
|
||||
|
||||
タグカラーを含むDarkモードとLightモードに対応:
|
||||
|
||||

|
||||

|
||||
</details>
|
||||
|
||||
# 📦 インストール
|
||||
## 内蔵されている拡張機能リストを用いた方法
|
||||
1. Extensions タブを開く
|
||||
2. Available タブを開く
|
||||
3. "Load from:" をクリック
|
||||
4. リストの中から "Booru tag autocompletion" を探す
|
||||
- この拡張機能は最初から利用可能だったものなので、 "oldest first" を選択すると、リストの上位に表示されます。
|
||||
5. 右側にある "Install" をクリック
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
|
||||
## 手動でcloneする方法
|
||||
```bash
|
||||
git clone "https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git" extensions/tag-autocomplete
|
||||
```
|
||||
(第2引数でフォルダ名を指定可能なので、好きな名前を指定しても良いでしょう)
|
||||
|
||||
# ❇️ 追加で有効化できる補完機能
|
||||
## ワイルドカード
|
||||
|
||||
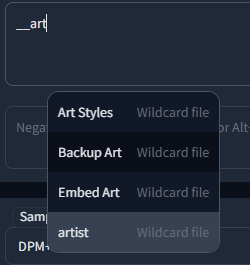
自動補完は、https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards 、または他の類似のスクリプト/拡張機能で使用されるワイルドカードファイルでも利用可能です。補完は `__` (ダブルアンダースコア) と入力することで開始されます。最初にワイルドカードファイルのリストが表示され、1つを選択すると、そのファイル内の置換オプションが表示されます。
|
||||
これにより、スクリプトによって置換されるカテゴリを挿入するか、または直接1つを選択して、ワイルドカードをカテゴリ化されたカスタムタグシステムのようなものとして使用することができます。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
ワイルドカードはすべての拡張機能フォルダと、古いバージョンをサポートするための `scripts/wildcards` フォルダで検索されます。これは複数の拡張機能からワイルドカードを組み合わせることができることを意味しています。ワイルドカードをグループ化した場合、ネストされたフォルダもサポートされます。
|
||||
|
||||
## Extra networks (Embeddings, Hypernets, LoRA, ...)
|
||||
これら3つのタイプの補完は、`<`と入力することで行われます。デフォルトでは3つとも混在して表示されますが、以下の方法でさらにフィルタリングを行うことができます:
|
||||
- `<e:` は、embeddingsのみを表示します。
|
||||
- `<l:` は、LoRAとLyCORISのみを表示します。
|
||||
- または `<lora:` と `<lyco:` で入力することも可能です
|
||||
- `<h:` 、または `<hypernet:` はHypernetworksのみを表示します
|
||||
|
||||
### Embedding type filtering
|
||||
Stable Diffusion 1.xまたは2.xモデル用にそれぞれトレーニングされたembeddingsは、他のタイプとの互換性がありません。有効なembeddingsを見つけやすくするため、若干の色の違いも含めて「v1 Embedding」と「v2 Embedding」で分類しています。また、`<v1/2`または`<e:v1/2`に続けて実際の検索のためのキーワードを入力すると、v1またはv2embeddingsのみを含むように検索を絞り込むことができます。
|
||||
|
||||
例:
|
||||
|
||||

|
||||
|
||||
## Chants(詠唱)
|
||||
Chants(詠唱)は、より長いプロンプトプリセットです。この名前は、中国のユーザーによる初期のプロンプト集からヒントを得たもので、しばしば「呪文書」(原文は「Spellbook」「Codex」)などと呼ばれていました。
|
||||
このような文書から得られるプロンプトのスニペットは、このような理由から呪文や詠唱と呼ばれるにふさわしいものでした。
|
||||
|
||||
EmbeddingsやLoraと同様に、この機能は `<`, `<c:`, `<chant:` コマンドを入力することで発動します。例えば、プロンプトボックスに `<c:HighQuality` と入力して選択すると、次のようなプロンプトテキストが挿入されます:
|
||||
|
||||
```
|
||||
(masterpiece, best quality, high quality, highres, ultra-detailed),
|
||||
```
|
||||
|
||||
Chants(詠唱)は、以下のフォーマットに従ってJSONファイルで追加することができます::
|
||||
|
||||
<details>
|
||||
<summary>Chant format (click to expand)</summary>
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"name": "Basic-NegativePrompt",
|
||||
"terms": "Negative,Low,Quality",
|
||||
"content": "(worst quality, low quality, normal quality)",
|
||||
"color": 3
|
||||
},
|
||||
{
|
||||
"name": "Basic-HighQuality",
|
||||
"terms": "Best,High,Quality",
|
||||
"content": "(masterpiece, best quality, high quality, highres, ultra-detailed)",
|
||||
"color": 1
|
||||
},
|
||||
{
|
||||
"name": "Basic-Start",
|
||||
"terms": "Basic, Start, Simple, Demo",
|
||||
"content": "(masterpiece, best quality, high quality, highres), 1girl, extremely beautiful detailed face, ...",
|
||||
"color": 5
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
</details>
|
||||
<br/>
|
||||
|
||||
このファイルが拡張機能の `tags` フォルダ内にある場合、settings内の"Chant file"ドロップダウンから選択することができます。
|
||||
|
||||
chantオブジェクトは4つのフィールドを持ちます:
|
||||
- `name` - 表示される名称
|
||||
- `terms` - 検索キーワード
|
||||
- `content` - 実際に挿入されるプロンプト
|
||||
- `color` - 表示される色。通常のタグと同じカテゴリーカラーシステムを使用しています。
|
||||
|
||||
## Umi AI tags
|
||||
https://github.com/Klokinator/Umi-AI は、Unprompted や Dynamic Wildcards に似た、機能豊富なワイルドカード拡張です。
|
||||
例えば `<[preset][--female][sfw][species]>` はプリセットカテゴリーを選び、女性関連のタグを除外し、さらに次のカテゴリーで絞り込み、実行時にこれらすべての条件に一致するランダムなフィルインを1つ選び出します。補完は `<[`] とそれに続く新しい開く括弧、例えば `<[xyz][`] で始まり、 `>` で閉じるまで続きます。
|
||||
|
||||
タグの自動補完は、これらのオプションをスマートに提案していきます。つまり、カテゴリータグの追加を続けても、その前に来たものと一致する結果だけが表示されるのです。
|
||||
また、タグの投稿数の代わりに、そのコンボから選択可能なフィルインタグの数を表示し、大規模になる初期内容に対して迅速な概要とフィルタリングを可能にします。
|
||||
|
||||
ほとんどの功績は[@ctwrs](https://github.com/ctwrs)によるものです。この方はUmiの開発者の一人として多くの貢献をしています。
|
||||
|
||||
# 🛠️ 設定
|
||||
|
||||
この拡張機能には多くの設定とカスタマイズ機能が組み込まれています。ほとんどのことははっきりしていますが、詳細な説明は以下のセクションをクリックしてください。
|
||||
|
||||
<!-- Filename -->
|
||||
<details>
|
||||
<summary>Tag filename</summary>
|
||||
|
||||
スクリプトが使用するメインのタグファイルとなります。デフォルトでは `danbooru.csv` と `e621.csv` が含まれており、ここにカスタムタグを追加することもできますが、大半のモデルはこの2つ以外(主にdanbooru)では学習していないため、あまり意味はありません。
|
||||
|
||||
拡張機能の他の機能(ワイルドカードやLoRA補完など)を使いたいが、通常のタグには興味がない場合は、`None`に設定することも可能です。
|
||||
|
||||

|
||||
</details>
|
||||
|
||||
<!-- Active In -->
|
||||
<details>
|
||||
<summary>"Active in" の設定</summary>
|
||||
|
||||
タグのオートコンプリートがどこにアタッチされ、変更を受け付けるかを指定します。
|
||||
ネガティブプロンプトはtxt2imgとimg2imgの設定に従うので、"親 "がアクティブな場合にのみアクティブとなります。
|
||||
|
||||

|
||||
</details>
|
||||
|
||||
<!-- Blacklist -->
|
||||
<details>
|
||||
<summary>Black / Whitelist</summary>
|
||||
|
||||
このオプションは、タグのオートコンプリートをグローバルにオフにすることができますが、特定のモデルに対してのみ有効または無効にしたい場合もあります。
|
||||
例えば、あなたのモデルのほとんどがアニメモデルである場合、boorタグでトレーニングされておらず、その恩恵を受けないフォトリアリスティックモデルをブラックリストに追加し、これらのモデルに切り替えた後に自動的に無効にすることができます。モデル名(拡張子を含む)とwebuiハッシュ(短い形式と長い形式の両方)の両方を使用できます。
|
||||
|
||||
`Blacklist`は指定したすべてのモデルを除外しますが、`Whitelist`はこれらのモデルに対してのみ有効で、デフォルトではオフのままです。例外として、空のホワイトリストは無視されます(空のブラックリストと同じです)。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Move Popup -->
|
||||
<details>
|
||||
<summary>カーソルで補完ポップアップを移動</summary>
|
||||
|
||||
このオプションは、IDEで行われるような、カーソルの位置に追従するフローティングポップアップを有効または無効にします。スクリプトはポップアップが右側でつぶれないように十分なスペースを確保しようとしますが、長いタグでは必ずしもうまくいきません。無効にした場合、ポップアップは左側に表示されます。
|
||||
|
||||

|
||||
|
||||

|
||||

|
||||
</details>
|
||||
<!-- Results Count -->
|
||||
<details>
|
||||
<summary>結果の数</summary>
|
||||
|
||||
一度に表示する結果の量を設定できます。
|
||||
`Show all results`が有効な場合、`Maximum results`で指定された数で切り捨てられるのではなく、スクロール可能なリストが表示されます。パフォーマンス上の理由から、この場合はすべてを一度に読み込むのではなく、ブロック単位で読み込みます。ブロックの大きさは`How many results to load at once`によって決まります。一番下に到達すると、次のブロックがロードされます(しかし、そんなことはめったには起こらないと思います)。
|
||||
|
||||
特筆すべきこととして、`Show all results` が使用される場合でも、`Maximum results` は影響を及ぼします。これは、スクロールが開始される前のポップアップの高さを制限するからです。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Delay time -->
|
||||
<details>
|
||||
<summary>補完の遅れについて</summary>
|
||||
|
||||
設定によっては、リアルタイムのタグ補完は計算量が多くなることがあります。
|
||||
このオプションは debounce による遅延をミリ秒単位で設定します(1000ミリ秒 = 1秒)。このオプションは、入力が非常に速い場合に特に有効です。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Search for -->
|
||||
<details>
|
||||
<summary>"Search for" に関する設定</summary>
|
||||
|
||||
特定の補完タイプを有効または無効にします。
|
||||
|
||||
Umi AIワイルドカードは、使用目的が似ているため、異なるフォーマットを使用しますが、ここでは通常のワイルドカードオプションに含まれます。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Wiki links -->
|
||||
<details>
|
||||
<summary>"?" Wiki links</summary>
|
||||
|
||||
このオプションがオンになっている場合、タグの横に `?` リンクが表示されます。これをクリックすると、danbooruまたはe621のそのタグのWikiページを開こうとします。
|
||||
|
||||
> ⚠️ 警告:
|
||||
>
|
||||
> Danbooruとe621は外部サイトであり、多くのNSFWコンテンツを含んでいます。このため、このオプションはデフォルトで無効になっています。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Insertion -->
|
||||
<details>
|
||||
<summary>補完設定</summary>
|
||||
|
||||
これらの設定で、テキストの挿入方法を指定できます。
|
||||
|
||||
Booruのサイトでは、タグにスペースの代わりにアンダースコアを使用することがほとんどですが、Stable diffusionで使用されているCLIPエンコーダーは自然言語でトレーニングされているため、前処理中にほとんどのモデルがこのアンダースコアをスペースに置き換えました。したがって、デフォルトではタグのオートコンプリートも同じようになります。
|
||||
|
||||
括弧は、プロンプトの特定の部分をより注目/重視するために、Webuiの制御文字として使用されるため、デフォルトでは括弧を含むタグはエスケープされます (`\( \)`) 。
|
||||
|
||||
最後の設定によりますが、タグのオートコンプリートはタグを挿入した後にカンマとスペースを追加します。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Wildcard path mode -->
|
||||
<details>
|
||||
<summary>ワイルドカードのパス補完</summary>
|
||||
|
||||
ワイルドカードのいくつかのコレクションは、ネストしたサブフォルダに整理されています。
|
||||
それらは、"hair/colors/light/... " や "clothing/male/casual/... " などのように、ファイルへのフルパスとともにリストアップされています。
|
||||
|
||||
このような場合、手動でフルパスを入力するのは難しいことが多いのですが、それでもリストをさらにスクロールする前に選択範囲を狭めたいものです。
|
||||
この場合、選択する結果がすべてのパスであれば、<kbd>Tab</kbd>(または`ChooseSelectedOrFirst`のカスタムホットキー)でパスの部分補完をトリガーすることが可能です。
|
||||
|
||||
この設定は、補完に使用するモードを決定します:
|
||||
- 次のフォルダレベルまで:
|
||||
- パス内の次の/まで補完し、選択したものを進む方向として優先します
|
||||
- オプションを直接選択したい場合は、<kbd>Enter</kbd> キーまたは `ChooseSelected` ホットキーを使用してスキップし、完全に補完します。
|
||||
- 最初の差分まで:
|
||||
- 結果内の最初の違いまで補完し、追加の情報を待ちます
|
||||
- 例:"/sub/folder_a/..." と "/sub/folder_b/..." がある場合、"su" と入力した後に補完すると、"/sub/folder_" まですべてを挿入し、a または b を入力して明確にするまでそこで停止します。
|
||||
- 矢印キーで何かを選択した場合(EnterキーやTabキーを押すかどうかに関係なく)、それをスキップして完全に補完します。
|
||||
- 常に全て:
|
||||
- 名前が示すように、部分的な補完動作を無効にし、通常のタグのようにすべての状況下で完全なパスを挿入します。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Alias -->
|
||||
<details>
|
||||
<summary>Alias 設定</summary>
|
||||
|
||||
タグはしばしば複数の別名(Alias)で参照されます。`Search by alias`がオンになっている場合、それらは検索結果に含まれ、正しいタグがわからない場合に役立ちます。この場合でも、挿入時にリンクされている実際のタグに置き換えられます。
|
||||
|
||||
`Only show alias` セットは、エイリアスのみを表示したい場合、またはそのエイリアスがマップするタグも表示したい場合に使用します。
|
||||
(`<alias> ➝ <actual>`として表示されます)
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Translations -->
|
||||
<details>
|
||||
<summary>翻訳設定</summary>
|
||||
|
||||
Tag Autocompleteは、別のファイル(`Translation filename`)で指定されたタグの翻訳をサポートしています。つまり、英語のタグ名が分からなくても、自身の言語の翻訳ファイルがあれば、それを代わりに使うことができます。
|
||||
|
||||
また、コミュニティで使用されている古いファイルのためのレガシーフォーマットオプションや、プロンプト全体のライブ翻訳プレビューなど実験的な機能もあります。
|
||||
|
||||
詳細については、以下の [翻訳に関するセクション](#翻訳) を参照してください。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Extra file -->
|
||||
<details>
|
||||
<summary>Extra ファイル設定</summary>
|
||||
|
||||
ここで指定したように、通常の結果の前後に追加される追加タグのセットを指定します。一般的に使用される品質タグ (`masterpiece, best quality,` など) のような小さなカスタムタグセットに便利です。
|
||||
|
||||
長いプリセットやプロンプト全体を補完したい場合は、代わりに [Chants(詠唱)](#chants詠唱) を参照してください。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Chants -->
|
||||
<details>
|
||||
<summary>Chant ファイル名</summary>
|
||||
|
||||
Chantとは、長いプリセット、あるいはプロンプト全体を一度に選択して挿入できるもので、Webuiに内蔵されているスタイルのドロップダウンに似ています。Chantにはいくつかの追加機能があり、より速く使用することができます。
|
||||
|
||||
詳しくは上記の[Chants(詠唱)](#chants詠唱)のセクションを参照してください。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Hotkeys -->
|
||||
<details>
|
||||
<summary>Hotkeys</summary>
|
||||
|
||||
ほとんどのキーボードナビゲーション機能のホットキーをここで指定できます。
|
||||
https://www.w3.org/TR/uievents-key/#named-key-attribute-value
|
||||
|
||||
機能の説明
|
||||
- Move Up / Down:次のタグを選択
|
||||
- Jump Up / Down:一度に5箇所移動する。
|
||||
- Jump to Start / End: リストの先頭または末尾にジャンプ
|
||||
- ChooseSelected ハイライトされたタグを選択するか、何も選択されていない場合はポップアップを閉じます。
|
||||
- ChooseSelectedOrFirst:上記と同じですが、何も選択されていない場合、デフォルトで最初の結果が選択されます。
|
||||
- Close ポップアップを閉じる
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Colors -->
|
||||
<details>
|
||||
<summary>Colors</summary>
|
||||
|
||||
ここでは、異なるタグカテゴリーに使用されるデフォルトの色を変更することができます。これらは、ソースサイトのカテゴリの色に似ているように選択されています。
|
||||
|
||||
フォーマットは標準的なJSON
|
||||
- オブジェクト名は、タグのファイル名に対応しています。
|
||||
- 数字はタグの種類を表し、タグのソースに依存します。詳細については、[CSV tag data](#csv-tag-data)を参照してください。
|
||||
- 角括弧内の最初の値はダークモード、2番目の値はライトモードです。HTMLの色名と16進数コードのどちらでも使えます。
|
||||
|
||||
これは、カスタムタグ・ファイルに新しいカラーセットを追加するためにも使用できます。
|
||||
|
||||

|
||||
</details>
|
||||
<!-- Temp files refresh -->
|
||||
<details>
|
||||
<summary>TACの一時作成ファイルのリフレッシュ</summary>
|
||||
|
||||
これは "フェイク"設定で、実際には何も設定しません。むしろ、開発者がwebuiのオプションに追加できる更新ボタンを悪用するための小さなハックです。この設定の隣にある更新ボタンをクリックすると、タグオートコンプリートにいくつかの一時的な内部ファイルを再作成・再読み込みさせます。
|
||||
|
||||
タグオートコンプリートは様々な機能、特に余分なネットワークとワイルドカード補完に関連するこれらのファイルに依存しています。この設定は、例えば新しいLoRAをいくつかフォルダに追加し、タグ・オートコンプリートにリストを表示させるためにUIを再起動したくない場合に、リストを再構築するために使用できます。
|
||||
|
||||
また、この設定をクイック設定バーに追加することで、いつでも更新ボタンを利用できるようになります。
|
||||
|
||||

|
||||
</details>
|
||||
<br/>
|
||||
|
||||
# 翻訳
|
||||
タグとエイリアスの両方を翻訳するために使用することができ、また翻訳による検索を可能にするための、追加のファイルを翻訳セクションに追加することができます。
|
||||
このファイルは、`<English tag/alias>,<Translation>`という形式のCSVである必要がありますが、3列のフォーマットを使用する古いファイルとの後方互換性のために、`oldFormat`をオンにすると、代わりに新しい2列の翻訳形式ではなく、古い3列の翻訳形式を使用するようになります。
|
||||
その場合、2番目のカラムは使用されず、パース時にスキップされます。
|
||||
|
||||
中国語の翻訳例:
|
||||
|
||||

|
||||

|
||||
|
||||
## 翻訳リスト
|
||||
- [🇨🇳 中国語訳](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/discussions/23) by @HalfMAI, 最も一般的なタグを機械翻訳と手作業で修正(レガシーフォーマットを使用)
|
||||
- [🇨🇳 中国語訳](https://github.com/sgmklp/tag-for-autocompletion-with-translation) by @sgmklp, [こちら](https://github.com/zcyzcy88/TagTable)をベースにして、より小さくした手動での翻訳セット。
|
||||
- [🇯🇵 日本語訳](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/discussions/265) by @applemango, 機械翻訳と人力翻訳の両方が利用可能。
|
||||
|
||||
> ### 🫵 あなたの助けが必要です!
|
||||
> 翻訳はコミュニティの努力により支えられています。もしあなたがタグファイルを翻訳したことがある場合、または作成したい場合は、あなたの成果をここに追加できるように、Pull RequestまたはIssueを開いてください。
|
||||
> 機械翻訳は、最も一般的なタグであっても、多くのことを間違えてしまいます。
|
||||
|
||||
## ライブ・プレビュー
|
||||
> ⚠️ 警告:
|
||||
>
|
||||
> この機能はまだ実験的なもので、使用中にバグに遭遇するかもしれません。
|
||||
|
||||
この機能はプロンプト内のすべての検出されたタグのライブプレビューを表示します。検出されたタグは、カンマで正しく区切られたものと長い文章の中にあるものの両方が表示されます。自然な文章では3単語まで検出することができ、1つのタグよりも複数単語の完全な一致を優先します。
|
||||
|
||||
検出されたタグの上には翻訳ファイルからの訳文が表示されるので、英語のタグの意味がよく分からない場合でも、プロンプトにタグが挿入された後でも(完了時のポップアップではなく)簡単に見つけることができます。
|
||||
|
||||
このオプションはデフォルトではオフになっていますが、翻訳ファイルを選択し、「Show live tag translation below prompt」をチェックすることで有効にすることができます。
|
||||
オフでも通常の機能には影響しません。
|
||||
|
||||
中国語翻訳時の例:
|
||||
|
||||

|
||||
|
||||
検出されたタグをクリックすると、そのタグがプロンプトで選択され、素早く編集できます。
|
||||
|
||||

|
||||
|
||||
#### ⚠️ ライブ翻訳に関する確認されている問題:
|
||||
ユーザーがテキストを入力または貼り付けると翻訳が更新されますが、プログラムによる操作(スタイルの適用やPNG Info / Image Browserからの読み込みなど)では更新されません。これは、プログラムによる編集の後に手動で何かを入力することで回避できます。
|
||||
|
||||
# Extra file
|
||||
エクストラファイルは、メインセットに含まれない新しいタグやカスタムタグを追加するために使用されます。
|
||||
[CSV tag data](#csv-tag-data)にある通常のタグのフォーマットと同じですが、ひとつだけ例外があります:
|
||||
カスタムタグにはカウントがないため、3列目(0から数える場合は2列目)はタグの横に表示される灰色のメタテキストに使用されます。
|
||||
空欄のままだと、「カスタムタグ」と表示されます。
|
||||
|
||||
これは同梱されるextra-quality-tags.csvファイルを使用した例で、非常に基本的な内容となります:
|
||||
|
||||
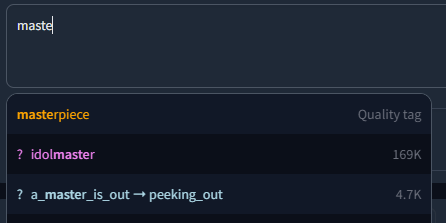
|
||||
|
||||
カスタムタグを通常のタグの前に追加するか、後に追加するかは、設定で選択することができます。
|
||||
|
||||
# CSV tag data
|
||||
このスクリプトは、以下の方法で保存されたタグ付きCSVファイルを想定しています:
|
||||
```csv
|
||||
<name>,<type>,<postCount>,"<aliases>"
|
||||
```
|
||||
Example:
|
||||
```csv
|
||||
1girl,0,4114588,"1girls,sole_female"
|
||||
solo,0,3426446,"female_solo,solo_female"
|
||||
highres,5,3008413,"high_res,high_resolution,hires"
|
||||
long_hair,0,2898315,longhair
|
||||
commentary_request,5,2610959,
|
||||
```
|
||||
注目すべきは、最初の行にカラム名を記載していないことと、count と aliases の両方が技術的にはオプションであることです、
|
||||
ただし、countは常にデフォルトデータに含まれています。複数のエイリアスは同様にカンマで区切る必要がありますが、CSVの解析に支障がないようにダブルクオーテーションで囲みます。
|
||||
|
||||
番号の付け方についてはDanbooruの[tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags)を参照してください:
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Meta |
|
||||
|
||||
また、e621についても同様です:
|
||||
| Value | Description |
|
||||
|-------|-------------|
|
||||
|-1 | Invalid |
|
||||
|0 | General |
|
||||
|1 | Artist |
|
||||
|3 | Copyright |
|
||||
|4 | Character |
|
||||
|5 | Species |
|
||||
|6 | Invalid |
|
||||
|7 | Meta |
|
||||
|8 | Lore |
|
||||
|
||||
タグの種類は、結果の一覧のエントリーの色付けに使用されます。
|
||||
|
||||
## ⚠️ よくある問題、また現在確認されている問題:
|
||||
- お使いのブラウザの設定によっては、古いバージョンのスクリプトがキャッシュされることがあります。例えば、アップデート後に新機能が表示されない場合は、キャッシュを使わずにサイトを強制的にリロードするために、
|
||||
<kbd>CTRL</kbd> + <kbd>F5</kbd>
|
||||
を試してください。
|
||||
- プロンプトのポップアップが壊れたスタイルで表示されるか、全く表示されない場合([このような場合](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/assets/34448969/7bbfdd54-fc23-4bfc-85af-24704b139b3a))、openpose-editor 拡張機能がインストールされている場合は更新してください。古いバージョンでは他の拡張機能との間で問題が生じることが知られています。
|
||||
|
||||
<!-- Variable declarations for shorter main text -->
|
||||
[release-shield]: https://img.shields.io/github/v/release/DominikDoom/a1111-sd-webui-tagcomplete?logo=github&style=
|
||||
[release-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases
|
||||
|
||||
[contributors-shield]: https://img.shields.io/github/contributors/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[contributors-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/graphs/contributors
|
||||
|
||||
[forks-shield]: https://img.shields.io/github/forks/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[forks-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/network/members
|
||||
|
||||
[stargazers-shield]: https://img.shields.io/github/stars/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[stargazers-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/stargazers
|
||||
|
||||
[issues-shield]: https://img.shields.io/github/issues/DominikDoom/a1111-sd-webui-tagcomplete
|
||||
[issues-url]: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/issues/new/choose
|
||||
|
||||
<!-- Links for feature section -->
|
||||
[image-browser-url]: https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
|
||||
[multidiffusion-url]: https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
|
||||
[tag-editor-url]: https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
|
||||
[wd-tagger-url]: https://github.com/toriato/stable-diffusion-webui-wd14-tagger
|
||||
[umi-url]: https://github.com/Klokinator/Umi-AI
|
||||
@@ -3,7 +3,7 @@
|
||||
# Booru tag autocompletion for A1111
|
||||
|
||||
[](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)
|
||||
## [English Document](./README.md)
|
||||
## [English Document](./README.md), [日本語ドキュメント](./README_JA.md)
|
||||
|
||||
## 功能概述
|
||||
|
||||
@@ -13,6 +13,12 @@
|
||||
你可以按照[以下方法](#installation)下载或拷贝文件,也可以使用[Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)中打包好的文件。
|
||||
|
||||
## 常见问题 & 已知缺陷:
|
||||
- 很多中国用户都报告过此扩展名和其他扩展名的 JavaScript 文件被阻止的问题。
|
||||
常见的罪魁祸首是 IDM / Internet Download Manager 浏览器插件,它似乎出于安全目的阻止了本地文件请求。
|
||||
如果您安装了 IDM,请确保在使用 webui 时禁用以下插件:
|
||||
|
||||

|
||||
|
||||
- 当`replaceUnderscores`选项开启时, 脚本只会替换Tag的一部分如果Tag包含多个单词,比如将`atago (azur lane)`修改`atago`为`taihou`并使用自动补全时.会得到 `taihou (azur lane), lane)`的结果, 因为脚本没有把后面的部分认为成同一个Tag。
|
||||
|
||||
## 演示与截图
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
// Core components
|
||||
var TAC_CFG = null;
|
||||
var tagBasePath = "";
|
||||
var modelKeywordPath = "";
|
||||
var tacSelfTrigger = false;
|
||||
|
||||
// Tag completion data loaded from files
|
||||
var allTags = [];
|
||||
@@ -10,11 +12,14 @@ var extras = [];
|
||||
var wildcardFiles = [];
|
||||
var wildcardExtFiles = [];
|
||||
var yamlWildcards = [];
|
||||
var umiWildcards = [];
|
||||
var embeddings = [];
|
||||
var hypernetworks = [];
|
||||
var loras = [];
|
||||
var lycos = [];
|
||||
var modelKeywordDict = new Map();
|
||||
var chants = [];
|
||||
var styleNames = [];
|
||||
|
||||
// Selected model info for black/whitelisting
|
||||
var currentModelHash = "";
|
||||
@@ -33,6 +38,13 @@ let hideBlocked = false;
|
||||
// Tag selection for keyboard navigation
|
||||
var selectedTag = null;
|
||||
var oldSelectedTag = null;
|
||||
var resultCountBeforeNormalTags = 0;
|
||||
|
||||
// Lora keyword undo/redo history
|
||||
var textBeforeKeywordInsertion = "";
|
||||
var textAfterKeywordInsertion = "";
|
||||
var lastEditWasKeywordInsertion = false;
|
||||
var keywordInsertionUndone = false;
|
||||
|
||||
// UMI
|
||||
var umiPreviousTags = [];
|
||||
|
||||
@@ -8,10 +8,12 @@ const ResultType = Object.freeze({
|
||||
"wildcardTag": 4,
|
||||
"wildcardFile": 5,
|
||||
"yamlWildcard": 6,
|
||||
"hypernetwork": 7,
|
||||
"lora": 8,
|
||||
"lyco": 9,
|
||||
"chant": 10
|
||||
"umiWildcard": 7,
|
||||
"hypernetwork": 8,
|
||||
"lora": 9,
|
||||
"lyco": 10,
|
||||
"chant": 11,
|
||||
"styleName": 12
|
||||
});
|
||||
|
||||
// Class to hold result data and annotations to make it clearer to use
|
||||
@@ -22,9 +24,12 @@ class AutocompleteResult {
|
||||
|
||||
// Additional info, only used in some cases
|
||||
category = null;
|
||||
count = null;
|
||||
count = Number.MAX_SAFE_INTEGER;
|
||||
usageBias = null;
|
||||
aliases = null;
|
||||
meta = null;
|
||||
hash = null;
|
||||
sortKey = null;
|
||||
|
||||
// Constructor
|
||||
constructor(text, type) {
|
||||
|
||||
@@ -8,7 +8,12 @@ const core = [
|
||||
"#txt2img_prompt > label > textarea",
|
||||
"#img2img_prompt > label > textarea",
|
||||
"#txt2img_neg_prompt > label > textarea",
|
||||
"#img2img_neg_prompt > label > textarea"
|
||||
"#img2img_neg_prompt > label > textarea",
|
||||
".prompt > label > textarea",
|
||||
"#txt2img_edit_style_prompt > label > textarea",
|
||||
"#txt2img_edit_style_neg_prompt > label > textarea",
|
||||
"#img2img_edit_style_prompt > label > textarea",
|
||||
"#img2img_edit_style_neg_prompt > label > textarea"
|
||||
];
|
||||
|
||||
// Third party text area selectors
|
||||
@@ -56,6 +61,38 @@ const thirdParty = {
|
||||
"[id^=MD-i2i][id$=prompt] textarea",
|
||||
"[id^=MD-i2i][id$=prompt] input[type='text']"
|
||||
]
|
||||
},
|
||||
"adetailer-t2i": {
|
||||
"base": "#txt2img_script_container",
|
||||
"hasIds": true,
|
||||
"onDemand": true,
|
||||
"selectors": [
|
||||
"[id^=script_txt2img_adetailer_ad_prompt] textarea",
|
||||
"[id^=script_txt2img_adetailer_ad_negative_prompt] textarea"
|
||||
]
|
||||
},
|
||||
"adetailer-i2i": {
|
||||
"base": "#img2img_script_container",
|
||||
"hasIds": true,
|
||||
"onDemand": true,
|
||||
"selectors": [
|
||||
"[id^=script_img2img_adetailer_ad_prompt] textarea",
|
||||
"[id^=script_img2img_adetailer_ad_negative_prompt] textarea"
|
||||
]
|
||||
},
|
||||
"deepdanbooru-object-recognition": {
|
||||
"base": "#tab_deepdanboru_object_recg_tab",
|
||||
"hasIds": false,
|
||||
"selectors": [
|
||||
"Found tags",
|
||||
]
|
||||
},
|
||||
"TIPO": {
|
||||
"base": "#tab_txt2img",
|
||||
"hasIds": false,
|
||||
"selectors": [
|
||||
"Tag Prompt"
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
@@ -89,7 +126,7 @@ function addOnDemandObservers(setupFunction) {
|
||||
|
||||
let base = gradioApp().querySelector(entry.base);
|
||||
if (!base) continue;
|
||||
|
||||
|
||||
let accordions = [...base?.querySelectorAll(".gradio-accordion")];
|
||||
if (!accordions) continue;
|
||||
|
||||
@@ -114,12 +151,12 @@ function addOnDemandObservers(setupFunction) {
|
||||
[...gradioApp().querySelectorAll(entry.selectors.join(", "))].forEach(x => setupFunction(x));
|
||||
} else { // Otherwise, we have to find the text areas by their adjacent labels
|
||||
let base = gradioApp().querySelector(entry.base);
|
||||
|
||||
|
||||
// Safety check
|
||||
if (!base) continue;
|
||||
|
||||
|
||||
let allTextAreas = [...base.querySelectorAll("textarea, input[type='text']")];
|
||||
|
||||
|
||||
// Filter the text areas where the adjacent label matches one of the selectors
|
||||
let matchingTextAreas = allTextAreas.filter(ta => [...ta.parentElement.childNodes].some(x => entry.selectors.includes(x.innerText)));
|
||||
matchingTextAreas.forEach(x => setupFunction(x));
|
||||
@@ -164,4 +201,4 @@ function getTextAreaIdentifier(textArea) {
|
||||
break;
|
||||
}
|
||||
return modifier;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,13 +1,14 @@
|
||||
// Utility functions for tag autocomplete
|
||||
|
||||
// Parse the CSV file into a 2D array. Doesn't use regex, so it is very lightweight.
|
||||
// We are ignoring newlines in quote fields since we expect one-line entries and parsing would break for unclosed quotes otherwise
|
||||
function parseCSV(str) {
|
||||
var arr = [];
|
||||
var quote = false; // 'true' means we're inside a quoted field
|
||||
const arr = [];
|
||||
let quote = false; // 'true' means we're inside a quoted field
|
||||
|
||||
// Iterate over each character, keep track of current row and column (of the returned array)
|
||||
for (var row = 0, col = 0, c = 0; c < str.length; c++) {
|
||||
var cc = str[c], nc = str[c + 1]; // Current character, next character
|
||||
for (let row = 0, col = 0, c = 0; c < str.length; c++) {
|
||||
let cc = str[c], nc = str[c+1]; // Current character, next character
|
||||
arr[row] = arr[row] || []; // Create a new row if necessary
|
||||
arr[row][col] = arr[row][col] || ''; // Create a new column (start with empty string) if necessary
|
||||
|
||||
@@ -22,14 +23,12 @@ function parseCSV(str) {
|
||||
// If it's a comma and we're not in a quoted field, move on to the next column
|
||||
if (cc == ',' && !quote) { ++col; continue; }
|
||||
|
||||
// If it's a newline (CRLF) and we're not in a quoted field, skip the next character
|
||||
// and move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\r' && nc == '\n' && !quote) { ++row; col = 0; ++c; continue; }
|
||||
// If it's a newline (CRLF), skip the next character and move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\r' && nc == '\n') { ++row; col = 0; ++c; quote = false; continue; }
|
||||
|
||||
// If it's a newline (LF or CR) and we're not in a quoted field,
|
||||
// move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\n' && !quote) { ++row; col = 0; continue; }
|
||||
if (cc == '\r' && !quote) { ++row; col = 0; continue; }
|
||||
// If it's a newline (LF or CR) move on to the next row and move to column 0 of that new row
|
||||
if (cc == '\n') { ++row; col = 0; quote = false; continue; }
|
||||
if (cc == '\r') { ++row; col = 0; quote = false; continue; }
|
||||
|
||||
// Otherwise, append the current character to the current column
|
||||
arr[row][col] += cc;
|
||||
@@ -41,7 +40,7 @@ function parseCSV(str) {
|
||||
async function readFile(filePath, json = false, cache = false) {
|
||||
if (!cache)
|
||||
filePath += `?${new Date().getTime()}`;
|
||||
|
||||
|
||||
let response = await fetch(`file=${filePath}`);
|
||||
|
||||
if (response.status != 200) {
|
||||
@@ -61,6 +60,92 @@ async function loadCSV(path) {
|
||||
return parseCSV(text);
|
||||
}
|
||||
|
||||
// Fetch API
|
||||
async function fetchTacAPI(url, json = true, cache = false) {
|
||||
if (!cache) {
|
||||
const appendChar = url.includes("?") ? "&" : "?";
|
||||
url += `${appendChar}${new Date().getTime()}`
|
||||
}
|
||||
|
||||
let response = await fetch(url);
|
||||
|
||||
if (response.status != 200) {
|
||||
console.error(`Error fetching API endpoint "${url}": ` + response.status, response.statusText);
|
||||
return null;
|
||||
}
|
||||
|
||||
if (json)
|
||||
return await response.json();
|
||||
else
|
||||
return await response.text();
|
||||
}
|
||||
|
||||
async function postTacAPI(url, body = null) {
|
||||
let response = await fetch(url, {
|
||||
method: "POST",
|
||||
headers: {'Content-Type': 'application/json'},
|
||||
body: body
|
||||
});
|
||||
|
||||
if (response.status != 200) {
|
||||
console.error(`Error posting to API endpoint "${url}": ` + response.status, response.statusText);
|
||||
return null;
|
||||
}
|
||||
|
||||
return await response.json();
|
||||
}
|
||||
|
||||
async function putTacAPI(url, body = null) {
|
||||
let response = await fetch(url, { method: "PUT", body: body });
|
||||
|
||||
if (response.status != 200) {
|
||||
console.error(`Error putting to API endpoint "${url}": ` + response.status, response.statusText);
|
||||
return null;
|
||||
}
|
||||
|
||||
return await response.json();
|
||||
}
|
||||
|
||||
// Extra network preview thumbnails
|
||||
async function getTacExtraNetworkPreviewURL(filename, type) {
|
||||
const previewJSON = await fetchTacAPI(`tacapi/v1/thumb-preview/${filename}?type=${type}`, true, true);
|
||||
if (previewJSON?.url) {
|
||||
const properURL = `sd_extra_networks/thumb?filename=${previewJSON.url}`;
|
||||
if ((await fetch(properURL)).status == 200) {
|
||||
return properURL;
|
||||
} else {
|
||||
// create blob url
|
||||
const blob = await (await fetch(`tacapi/v1/thumb-preview-blob/${filename}?type=${type}`)).blob();
|
||||
return URL.createObjectURL(blob);
|
||||
}
|
||||
} else {
|
||||
return null;
|
||||
}
|
||||
}
|
||||
|
||||
lastStyleRefresh = 0;
|
||||
// Refresh style file if needed
|
||||
async function refreshStyleNamesIfChanged() {
|
||||
// Only refresh once per second
|
||||
currentTimestamp = new Date().getTime();
|
||||
if (currentTimestamp - lastStyleRefresh < 1000) return;
|
||||
lastStyleRefresh = currentTimestamp;
|
||||
|
||||
const response = await fetch(`tacapi/v1/refresh-styles-if-changed?${new Date().getTime()}`)
|
||||
if (response.status === 304) {
|
||||
// Not modified
|
||||
} else if (response.status === 200) {
|
||||
// Reload
|
||||
QUEUE_FILE_LOAD.forEach(async fn => {
|
||||
if (fn.toString().includes("styleNames"))
|
||||
await fn.call(null, true);
|
||||
})
|
||||
} else {
|
||||
// Error
|
||||
console.error(`Error refreshing styles.txt: ` + response.status, response.statusText);
|
||||
}
|
||||
}
|
||||
|
||||
// Debounce function to prevent spamming the autocomplete function
|
||||
var dbTimeOut;
|
||||
const debounce = (func, wait = 300) => {
|
||||
@@ -89,6 +174,136 @@ function difference(a, b) {
|
||||
)].reduce((acc, [v, count]) => acc.concat(Array(Math.abs(count)).fill(v)), []);
|
||||
}
|
||||
|
||||
// Object flatten function adapted from https://stackoverflow.com/a/61602592
|
||||
// $roots keeps previous parent properties as they will be added as a prefix for each prop.
|
||||
// $sep is just a preference if you want to seperate nested paths other than dot.
|
||||
function flatten(obj, roots = [], sep = ".") {
|
||||
return Object.keys(obj).reduce(
|
||||
(memo, prop) =>
|
||||
Object.assign(
|
||||
// create a new object
|
||||
{},
|
||||
// include previously returned object
|
||||
memo,
|
||||
Object.prototype.toString.call(obj[prop]) === "[object Object]"
|
||||
? // keep working if value is an object
|
||||
flatten(obj[prop], roots.concat([prop]), sep)
|
||||
: // include current prop and value and prefix prop with the roots
|
||||
{ [roots.concat([prop]).join(sep)]: obj[prop] }
|
||||
),
|
||||
{}
|
||||
);
|
||||
}
|
||||
|
||||
// Calculate biased tag score based on post count and frequent usage
|
||||
function calculateUsageBias(result, count, uses) {
|
||||
// Check setting conditions
|
||||
if (uses < TAC_CFG.frequencyMinCount) {
|
||||
uses = 0;
|
||||
} else if (uses != 0) {
|
||||
result.usageBias = true;
|
||||
}
|
||||
|
||||
switch (TAC_CFG.frequencyFunction) {
|
||||
case "Logarithmic (weak)":
|
||||
return Math.log(1 + count) + Math.log(1 + uses);
|
||||
case "Logarithmic (strong)":
|
||||
return Math.log(1 + count) + 2 * Math.log(1 + uses);
|
||||
case "Usage first":
|
||||
return uses;
|
||||
default:
|
||||
return count;
|
||||
}
|
||||
}
|
||||
// Beautify return type for easier parsing
|
||||
function mapUseCountArray(useCounts, posAndNeg = false) {
|
||||
return useCounts.map(useCount => {
|
||||
if (posAndNeg) {
|
||||
return {
|
||||
"name": useCount[0],
|
||||
"type": useCount[1],
|
||||
"count": useCount[2],
|
||||
"negCount": useCount[3],
|
||||
"lastUseDate": useCount[4]
|
||||
}
|
||||
}
|
||||
return {
|
||||
"name": useCount[0],
|
||||
"type": useCount[1],
|
||||
"count": useCount[2],
|
||||
"lastUseDate": useCount[3]
|
||||
}
|
||||
});
|
||||
}
|
||||
// Call API endpoint to increase bias of tag in the database
|
||||
function increaseUseCount(tagName, type, negative = false) {
|
||||
postTacAPI(`tacapi/v1/increase-use-count?tagname=${tagName}&ttype=${type}&neg=${negative}`);
|
||||
}
|
||||
// Get use count of tag from the database
|
||||
async function getUseCount(tagName, type, negative = false) {
|
||||
const response = await fetchTacAPI(`tacapi/v1/get-use-count?tagname=${tagName}&ttype=${type}&neg=${negative}`, true, false);
|
||||
// Guard for no db
|
||||
if (response == null) return null;
|
||||
// Result
|
||||
return response["result"];
|
||||
}
|
||||
async function getUseCounts(tagNames, types, negative = false) {
|
||||
// While semantically weird, we have to use POST here for the body, as urls are limited in length
|
||||
const body = JSON.stringify({"tagNames": tagNames, "tagTypes": types, "neg": negative});
|
||||
const response = await postTacAPI(`tacapi/v1/get-use-count-list`, body)
|
||||
// Guard for no db
|
||||
if (response == null) return null;
|
||||
// Results
|
||||
return mapUseCountArray(response["result"]);
|
||||
}
|
||||
async function getAllUseCounts() {
|
||||
const response = await fetchTacAPI(`tacapi/v1/get-all-use-counts`);
|
||||
// Guard for no db
|
||||
if (response == null) return null;
|
||||
// Results
|
||||
return mapUseCountArray(response["result"], true);
|
||||
}
|
||||
async function resetUseCount(tagName, type, resetPosCount, resetNegCount) {
|
||||
await putTacAPI(`tacapi/v1/reset-use-count?tagname=${tagName}&ttype=${type}&pos=${resetPosCount}&neg=${resetNegCount}`);
|
||||
}
|
||||
|
||||
function createTagUsageTable(tagCounts) {
|
||||
// Create table
|
||||
let tagTable = document.createElement("table");
|
||||
tagTable.innerHTML =
|
||||
`<thead>
|
||||
<tr>
|
||||
<td>Name</td>
|
||||
<td>Type</td>
|
||||
<td>Count(+)</td>
|
||||
<td>Count(-)</td>
|
||||
<td>Last used</td>
|
||||
</tr>
|
||||
</thead>`;
|
||||
tagTable.id = "tac_tagUsageTable"
|
||||
|
||||
tagCounts.forEach(t => {
|
||||
let tr = document.createElement("tr");
|
||||
|
||||
// Fill values
|
||||
let values = [t.name, t.type-1, t.count, t.negCount, t.lastUseDate]
|
||||
values.forEach(v => {
|
||||
let td = document.createElement("td");
|
||||
td.innerText = v;
|
||||
tr.append(td);
|
||||
});
|
||||
// Add delete/reset button
|
||||
let delButton = document.createElement("button");
|
||||
delButton.innerText = "🗑️";
|
||||
delButton.title = "Reset count";
|
||||
tr.append(delButton);
|
||||
|
||||
tagTable.append(tr)
|
||||
});
|
||||
|
||||
return tagTable;
|
||||
}
|
||||
|
||||
// Sliding window function to get possible combination groups of an array
|
||||
function toNgrams(inputArray, size) {
|
||||
return Array.from(
|
||||
@@ -97,7 +312,11 @@ function toNgrams(inputArray, size) {
|
||||
);
|
||||
}
|
||||
|
||||
function escapeRegExp(string) {
|
||||
function escapeRegExp(string, wildcardMatching = false) {
|
||||
if (wildcardMatching) {
|
||||
// Escape all characters except asterisks and ?, which should be treated separately as placeholders.
|
||||
return string.replace(/[-[\]{}()+.,\\^$|#\s]/g, '\\$&').replace(/\*/g, '.*').replace(/\?/g, '.');
|
||||
}
|
||||
return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string
|
||||
}
|
||||
function escapeHTML(unsafeText) {
|
||||
@@ -141,6 +360,49 @@ function observeElement(element, property, callback, delay = 0) {
|
||||
}
|
||||
}
|
||||
|
||||
// Sort functions
|
||||
function getSortFunction() {
|
||||
let criterion = TAC_CFG.modelSortOrder || "Name";
|
||||
|
||||
const textSort = (a, b, reverse = false) => {
|
||||
// Assign keys so next sort is faster
|
||||
if (!a.sortKey) {
|
||||
a.sortKey = a.type === ResultType.chant
|
||||
? a.aliases
|
||||
: a.text;
|
||||
}
|
||||
if (!b.sortKey) {
|
||||
b.sortKey = b.type === ResultType.chant
|
||||
? b.aliases
|
||||
: b.text;
|
||||
}
|
||||
|
||||
return reverse ? b.sortKey.localeCompare(a.sortKey) : a.sortKey.localeCompare(b.sortKey);
|
||||
}
|
||||
const numericSort = (a, b, reverse = false) => {
|
||||
const noKey = reverse ? "-1" : Number.MAX_SAFE_INTEGER;
|
||||
let aParsed = parseFloat(a.sortKey || noKey);
|
||||
let bParsed = parseFloat(b.sortKey || noKey);
|
||||
|
||||
if (aParsed === bParsed) {
|
||||
return textSort(a, b, false);
|
||||
}
|
||||
|
||||
return reverse ? bParsed - aParsed : aParsed - bParsed;
|
||||
}
|
||||
|
||||
return (a, b) => {
|
||||
switch (criterion) {
|
||||
case "Date Modified (newest first)":
|
||||
return numericSort(a, b, true);
|
||||
case "Date Modified (oldest first)":
|
||||
return numericSort(a, b, false);
|
||||
default:
|
||||
return textSort(a, b);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Queue calling function to process global queues
|
||||
async function processQueue(queue, context, ...args) {
|
||||
for (let i = 0; i < queue.length; i++) {
|
||||
|
||||
@@ -7,7 +7,10 @@ class ChantParser extends BaseTagParser {
|
||||
let tempResults = [];
|
||||
if (tagword !== "<" && tagword !== "<c:") {
|
||||
let searchTerm = tagword.replace("<chant:", "").replace("<c:", "").replace("<", "");
|
||||
let filterCondition = x => x.terms.toLowerCase().includes(searchTerm) || x.name.toLowerCase().includes(searchTerm);
|
||||
let filterCondition = x => {
|
||||
let regex = new RegExp(escapeRegExp(searchTerm, true), 'i');
|
||||
return regex.test(x.terms.toLowerCase()) || regex.test(x.name.toLowerCase());
|
||||
};
|
||||
tempResults = chants.filter(x => filterCondition(x)); // Filter by tagword
|
||||
} else {
|
||||
tempResults = chants;
|
||||
@@ -41,7 +44,7 @@ async function load() {
|
||||
|
||||
function sanitize(tagType, text) {
|
||||
if (tagType === ResultType.chant) {
|
||||
return text.replace(/^.*?: /g, "");
|
||||
return text;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
@@ -51,4 +54,4 @@ PARSERS.push(new ChantParser(CHANT_TRIGGER));
|
||||
// Add our utility functions to their respective queues
|
||||
QUEUE_FILE_LOAD.push(load);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
QUEUE_AFTER_CONFIG_CHANGE.push(load);
|
||||
QUEUE_AFTER_CONFIG_CHANGE.push(load);
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
const EMB_REGEX = /<(?!l:|h:|c:)[^,> ]*>?/g;
|
||||
const EMB_TRIGGER = () => TAC_CFG.useEmbeddings && tagword.match(EMB_REGEX);
|
||||
const EMB_TRIGGER = () => TAC_CFG.useEmbeddings && (tagword.match(EMB_REGEX) || TAC_CFG.includeEmbeddingsInNormalResults);
|
||||
|
||||
class EmbeddingParser extends BaseTagParser {
|
||||
parse() {
|
||||
@@ -11,12 +11,18 @@ class EmbeddingParser extends BaseTagParser {
|
||||
if (searchTerm.startsWith("v1") || searchTerm.startsWith("v2")) {
|
||||
versionString = searchTerm.slice(0, 2);
|
||||
searchTerm = searchTerm.slice(2);
|
||||
} else if (searchTerm.startsWith("vxl")) {
|
||||
versionString = searchTerm.slice(0, 3);
|
||||
searchTerm = searchTerm.slice(3);
|
||||
}
|
||||
|
||||
let filterCondition = x => x[0].toLowerCase().includes(searchTerm) || x[0].toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
||||
let filterCondition = x => {
|
||||
let regex = new RegExp(escapeRegExp(searchTerm, true), 'i');
|
||||
return regex.test(x[0].toLowerCase()) || regex.test(x[0].toLowerCase().replaceAll(" ", "_"));
|
||||
};
|
||||
|
||||
if (versionString)
|
||||
tempResults = embeddings.filter(x => filterCondition(x) && x[1] && x[1] === versionString); // Filter by tagword
|
||||
tempResults = embeddings.filter(x => filterCondition(x) && x[2] && x[2].toLowerCase() === versionString.toLowerCase()); // Filter by tagword
|
||||
else
|
||||
tempResults = embeddings.filter(x => filterCondition(x)); // Filter by tagword
|
||||
} else {
|
||||
@@ -26,8 +32,13 @@ class EmbeddingParser extends BaseTagParser {
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
tempResults.forEach(t => {
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.embedding)
|
||||
result.meta = t[1] + " Embedding";
|
||||
let lastDot = t[0].lastIndexOf(".") > -1 ? t[0].lastIndexOf(".") : t[0].length;
|
||||
let lastSlash = t[0].lastIndexOf("/") > -1 ? t[0].lastIndexOf("/") : -1;
|
||||
let name = t[0].trim().substring(lastSlash + 1, lastDot);
|
||||
|
||||
let result = new AutocompleteResult(name, ResultType.embedding)
|
||||
result.sortKey = t[1];
|
||||
result.meta = t[2] + " Embedding";
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
@@ -38,9 +49,9 @@ class EmbeddingParser extends BaseTagParser {
|
||||
async function load() {
|
||||
if (embeddings.length === 0) {
|
||||
try {
|
||||
embeddings = (await readFile(`${tagBasePath}/temp/emb.txt`)).split("\n")
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => x.trim().split(",")); // Split into name, version type pairs
|
||||
embeddings = (await loadCSV(`${tagBasePath}/temp/emb.txt`))
|
||||
.filter(x => x[0]?.trim().length > 0) // Remove empty lines
|
||||
.map(x => [x[0].trim(), x[1], x[2]]); // Return name, sortKey, hash tuples
|
||||
} catch (e) {
|
||||
console.error("Error loading embeddings.txt: " + e);
|
||||
}
|
||||
@@ -49,7 +60,7 @@ async function load() {
|
||||
|
||||
function sanitize(tagType, text) {
|
||||
if (tagType === ResultType.embedding) {
|
||||
return text.replace(/^.*?: /g, "");
|
||||
return text;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
@@ -58,4 +69,4 @@ PARSERS.push(new EmbeddingParser(EMB_TRIGGER));
|
||||
|
||||
// Add our utility functions to their respective queues
|
||||
QUEUE_FILE_LOAD.push(load);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
|
||||
@@ -7,8 +7,11 @@ class HypernetParser extends BaseTagParser {
|
||||
let tempResults = [];
|
||||
if (tagword !== "<" && tagword !== "<h:" && tagword !== "<hypernet:") {
|
||||
let searchTerm = tagword.replace("<hypernet:", "").replace("<h:", "").replace("<", "");
|
||||
let filterCondition = x => x.toLowerCase().includes(searchTerm) || x.toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
||||
tempResults = hypernetworks.filter(x => filterCondition(x)); // Filter by tagword
|
||||
let filterCondition = x => {
|
||||
let regex = new RegExp(escapeRegExp(searchTerm, true), 'i');
|
||||
return regex.test(x.toLowerCase()) || regex.test(x.toLowerCase().replaceAll(" ", "_"));
|
||||
};
|
||||
tempResults = hypernetworks.filter(x => filterCondition(x[0])); // Filter by tagword
|
||||
} else {
|
||||
tempResults = hypernetworks;
|
||||
}
|
||||
@@ -16,8 +19,9 @@ class HypernetParser extends BaseTagParser {
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
tempResults.forEach(t => {
|
||||
let result = new AutocompleteResult(t.trim(), ResultType.hypernetwork)
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.hypernetwork)
|
||||
result.meta = "Hypernetwork";
|
||||
result.sortKey = t[1];
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
@@ -28,9 +32,9 @@ class HypernetParser extends BaseTagParser {
|
||||
async function load() {
|
||||
if (hypernetworks.length === 0) {
|
||||
try {
|
||||
hypernetworks = (await readFile(`${tagBasePath}/temp/hyp.txt`)).split("\n")
|
||||
.filter(x => x.trim().length > 0) //Remove empty lines
|
||||
.map(x => x.trim()); // Remove carriage returns and padding if it exists
|
||||
hypernetworks = (await loadCSV(`${tagBasePath}/temp/hyp.txt`))
|
||||
.filter(x => x[0]?.trim().length > 0) //Remove empty lines
|
||||
.map(x => [x[0]?.trim(), x[1]]); // Remove carriage returns and padding if it exists
|
||||
} catch (e) {
|
||||
console.error("Error loading hypernetworks.txt: " + e);
|
||||
}
|
||||
@@ -48,4 +52,4 @@ PARSERS.push(new HypernetParser(HYP_TRIGGER));
|
||||
|
||||
// Add our utility functions to their respective queues
|
||||
QUEUE_FILE_LOAD.push(load);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
|
||||
@@ -7,8 +7,11 @@ class LoraParser extends BaseTagParser {
|
||||
let tempResults = [];
|
||||
if (tagword !== "<" && tagword !== "<l:" && tagword !== "<lora:") {
|
||||
let searchTerm = tagword.replace("<lora:", "").replace("<l:", "").replace("<", "");
|
||||
let filterCondition = x => x.toLowerCase().includes(searchTerm) || x.toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
||||
tempResults = loras.filter(x => filterCondition(x)); // Filter by tagword
|
||||
let filterCondition = x => {
|
||||
let regex = new RegExp(escapeRegExp(searchTerm, true), 'i');
|
||||
return regex.test(x.toLowerCase()) || regex.test(x.toLowerCase().replaceAll(" ", "_"));
|
||||
};
|
||||
tempResults = loras.filter(x => filterCondition(x[0])); // Filter by tagword
|
||||
} else {
|
||||
tempResults = loras;
|
||||
}
|
||||
@@ -16,8 +19,15 @@ class LoraParser extends BaseTagParser {
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
tempResults.forEach(t => {
|
||||
let result = new AutocompleteResult(t.trim(), ResultType.lora)
|
||||
const text = t[0].trim();
|
||||
let lastDot = text.lastIndexOf(".") > -1 ? text.lastIndexOf(".") : text.length;
|
||||
let lastSlash = text.lastIndexOf("/") > -1 ? text.lastIndexOf("/") : -1;
|
||||
let name = text.substring(lastSlash + 1, lastDot);
|
||||
|
||||
let result = new AutocompleteResult(name, ResultType.lora)
|
||||
result.meta = "Lora";
|
||||
result.sortKey = t[1];
|
||||
result.hash = t[2];
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
@@ -28,18 +38,24 @@ class LoraParser extends BaseTagParser {
|
||||
async function load() {
|
||||
if (loras.length === 0) {
|
||||
try {
|
||||
loras = (await readFile(`${tagBasePath}/temp/lora.txt`)).split("\n")
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => x.trim()); // Remove carriage returns and padding if it exists
|
||||
loras = (await loadCSV(`${tagBasePath}/temp/lora.txt`))
|
||||
.filter(x => x[0]?.trim().length > 0) // Remove empty lines
|
||||
.map(x => [x[0]?.trim(), x[1], x[2]]); // Trim filenames and return the name, sortKey, hash pairs
|
||||
} catch (e) {
|
||||
console.error("Error loading lora.txt: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function sanitize(tagType, text) {
|
||||
async function sanitize(tagType, text) {
|
||||
if (tagType === ResultType.lora) {
|
||||
return `<lora:${text}:${TAC_CFG.extraNetworksDefaultMultiplier}>`;
|
||||
let multiplier = TAC_CFG.extraNetworksDefaultMultiplier;
|
||||
let info = await fetchTacAPI(`tacapi/v1/lora-info/${text}`)
|
||||
if (info && info["preferred weight"]) {
|
||||
multiplier = info["preferred weight"];
|
||||
}
|
||||
|
||||
return `<lora:${text}:${multiplier}>`;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
@@ -48,4 +64,4 @@ PARSERS.push(new LoraParser(LORA_TRIGGER));
|
||||
|
||||
// Add our utility functions to their respective queues
|
||||
QUEUE_FILE_LOAD.push(load);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
|
||||
@@ -5,10 +5,13 @@ class LycoParser extends BaseTagParser {
|
||||
parse() {
|
||||
// Show lyco
|
||||
let tempResults = [];
|
||||
if (tagword !== "<" && tagword !== "<l:" && tagword !== "<lyco:") {
|
||||
let searchTerm = tagword.replace("<lyco:", "").replace("<l:", "").replace("<", "");
|
||||
let filterCondition = x => x.toLowerCase().includes(searchTerm) || x.toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
||||
tempResults = lycos.filter(x => filterCondition(x)); // Filter by tagword
|
||||
if (tagword !== "<" && tagword !== "<l:" && tagword !== "<lyco:" && tagword !== "<lora:") {
|
||||
let searchTerm = tagword.replace("<lyco:", "").replace("<lora:", "").replace("<l:", "").replace("<", "");
|
||||
let filterCondition = x => {
|
||||
let regex = new RegExp(escapeRegExp(searchTerm, true), 'i');
|
||||
return regex.test(x.toLowerCase()) || regex.test(x.toLowerCase().replaceAll(" ", "_"));
|
||||
};
|
||||
tempResults = lycos.filter(x => filterCondition(x[0])); // Filter by tagword
|
||||
} else {
|
||||
tempResults = lycos;
|
||||
}
|
||||
@@ -16,8 +19,15 @@ class LycoParser extends BaseTagParser {
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
tempResults.forEach(t => {
|
||||
let result = new AutocompleteResult(t.trim(), ResultType.lyco)
|
||||
const text = t[0].trim();
|
||||
let lastDot = text.lastIndexOf(".") > -1 ? text.lastIndexOf(".") : text.length;
|
||||
let lastSlash = text.lastIndexOf("/") > -1 ? text.lastIndexOf("/") : -1;
|
||||
let name = text.substring(lastSlash + 1, lastDot);
|
||||
|
||||
let result = new AutocompleteResult(name, ResultType.lyco)
|
||||
result.meta = "Lyco";
|
||||
result.sortKey = t[1];
|
||||
result.hash = t[2];
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
@@ -28,18 +38,25 @@ class LycoParser extends BaseTagParser {
|
||||
async function load() {
|
||||
if (lycos.length === 0) {
|
||||
try {
|
||||
lycos = (await readFile(`${tagBasePath}/temp/lyco.txt`)).split("\n")
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => x.trim()); // Remove carriage returns and padding if it exists
|
||||
lycos = (await loadCSV(`${tagBasePath}/temp/lyco.txt`))
|
||||
.filter(x => x[0]?.trim().length > 0) // Remove empty lines
|
||||
.map(x => [x[0]?.trim(), x[1], x[2]]); // Trim filenames and return the name, sortKey, hash pairs
|
||||
} catch (e) {
|
||||
console.error("Error loading lyco.txt: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function sanitize(tagType, text) {
|
||||
async function sanitize(tagType, text) {
|
||||
if (tagType === ResultType.lyco) {
|
||||
return `<lyco:${text}:${TAC_CFG.extraNetworksDefaultMultiplier}>`;
|
||||
let multiplier = TAC_CFG.extraNetworksDefaultMultiplier;
|
||||
let info = await fetchTacAPI(`tacapi/v1/lyco-info/${text}`)
|
||||
if (info && info["preferred weight"]) {
|
||||
multiplier = info["preferred weight"];
|
||||
}
|
||||
|
||||
let prefix = TAC_CFG.useLoraPrefixForLycos ? "lora" : "lyco";
|
||||
return `<${prefix}:${text}:${multiplier}>`;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
@@ -48,4 +65,4 @@ PARSERS.push(new LycoParser(LYCO_TRIGGER));
|
||||
|
||||
// Add our utility functions to their respective queues
|
||||
QUEUE_FILE_LOAD.push(load);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
|
||||
42
javascript/ext_modelKeyword.js
Normal file
42
javascript/ext_modelKeyword.js
Normal file
@@ -0,0 +1,42 @@
|
||||
async function load() {
|
||||
let modelKeywordParts = (await readFile(`tmp/modelKeywordPath.txt`)).split(",")
|
||||
modelKeywordPath = modelKeywordParts[0];
|
||||
let customFileExists = modelKeywordParts[1] === "True";
|
||||
|
||||
if (modelKeywordPath.length > 0 && modelKeywordDict.size === 0) {
|
||||
try {
|
||||
let csv_lines = [];
|
||||
// Only add default keywords if wanted by the user
|
||||
if (TAC_CFG.modelKeywordCompletion !== "Only user list")
|
||||
csv_lines = (await loadCSV(`${modelKeywordPath}/lora-keyword.txt`));
|
||||
// Add custom user keywords if the file exists
|
||||
if (customFileExists)
|
||||
csv_lines = csv_lines.concat((await loadCSV(`${modelKeywordPath}/lora-keyword-user.txt`)));
|
||||
|
||||
if (csv_lines.length === 0) return;
|
||||
|
||||
csv_lines = csv_lines.filter(x => x[0].trim().length > 0 && x[0].trim()[0] !== "#") // Remove empty lines and comments
|
||||
|
||||
// Add to the dict
|
||||
csv_lines.forEach(parts => {
|
||||
const hash = parts[0];
|
||||
const keywords = parts[1]?.replaceAll("| ", ", ")?.replaceAll("|", ", ")?.trim();
|
||||
const lastSepIndex = parts[2]?.lastIndexOf("/") + 1 || parts[2]?.lastIndexOf("\\") + 1 || 0;
|
||||
const name = parts[2]?.substring(lastSepIndex).trim() || "none"
|
||||
|
||||
if (modelKeywordDict.has(hash) && name !== "none") {
|
||||
// Add a new name key if the hash already exists
|
||||
modelKeywordDict.get(hash).set(name, keywords);
|
||||
} else {
|
||||
// Create new hash entry
|
||||
let map = new Map().set(name, keywords);
|
||||
modelKeywordDict.set(hash, map);
|
||||
}
|
||||
});
|
||||
} catch (e) {
|
||||
console.error("Error loading model-keywords list: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
QUEUE_FILE_LOAD.push(load);
|
||||
70
javascript/ext_styles.js
Normal file
70
javascript/ext_styles.js
Normal file
@@ -0,0 +1,70 @@
|
||||
const STYLE_REGEX = /(\$(\d*)\(?)[^$|\[\],\s]*\)?/;
|
||||
const STYLE_TRIGGER = () => TAC_CFG.useStyleVars && tagword.match(STYLE_REGEX);
|
||||
|
||||
var lastStyleVarIndex = "";
|
||||
|
||||
class StyleParser extends BaseTagParser {
|
||||
async parse() {
|
||||
// Refresh if needed
|
||||
await refreshStyleNamesIfChanged();
|
||||
|
||||
// Show styles
|
||||
let tempResults = [];
|
||||
let matchGroups = tagword.match(STYLE_REGEX);
|
||||
|
||||
// Save index to insert again later or clear last one
|
||||
lastStyleVarIndex = matchGroups[2] ? matchGroups[2] : "";
|
||||
|
||||
if (tagword !== matchGroups[1]) {
|
||||
let searchTerm = tagword.replace(matchGroups[1], "");
|
||||
|
||||
let filterCondition = x => {
|
||||
let regex = new RegExp(escapeRegExp(searchTerm, true), 'i');
|
||||
return regex.test(x[0].toLowerCase()) || regex.test(x[0].toLowerCase().replaceAll(" ", "_"));
|
||||
};
|
||||
tempResults = styleNames.filter(x => filterCondition(x)); // Filter by tagword
|
||||
} else {
|
||||
tempResults = styleNames;
|
||||
}
|
||||
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
tempResults.forEach(t => {
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.styleName)
|
||||
result.meta = "Style";
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
return finalResults;
|
||||
}
|
||||
}
|
||||
|
||||
async function load(force = false) {
|
||||
if (styleNames.length === 0 || force) {
|
||||
try {
|
||||
styleNames = (await loadCSV(`${tagBasePath}/temp/styles.txt`))
|
||||
.filter(x => x[0]?.trim().length > 0) // Remove empty lines
|
||||
.filter(x => x[0] !== "None") // Remove "None" style
|
||||
.map(x => [x[0].trim()]); // Trim name
|
||||
} catch (e) {
|
||||
console.error("Error loading styles.txt: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function sanitize(tagType, text) {
|
||||
if (tagType === ResultType.styleName) {
|
||||
if (text.includes(" ")) {
|
||||
return `$${lastStyleVarIndex}(${text})`;
|
||||
} else {
|
||||
return`$${lastStyleVarIndex}${text}`
|
||||
}
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
PARSERS.push(new StyleParser(STYLE_TRIGGER));
|
||||
|
||||
// Add our utility functions to their respective queues
|
||||
QUEUE_FILE_LOAD.push(load);
|
||||
QUEUE_SANITIZE.push(sanitize);
|
||||
@@ -7,7 +7,7 @@ class UmiParser extends BaseTagParser {
|
||||
parse(textArea, prompt) {
|
||||
// We are in a UMI yaml tag definition, parse further
|
||||
let umiSubPrompts = [...prompt.matchAll(UMI_PROMPT_REGEX)];
|
||||
|
||||
|
||||
let umiTags = [];
|
||||
let umiTagsWithOperators = []
|
||||
|
||||
@@ -15,7 +15,7 @@ class UmiParser extends BaseTagParser {
|
||||
|
||||
umiSubPrompts.forEach(umiSubPrompt => {
|
||||
umiTags = umiTags.concat([...umiSubPrompt[0].matchAll(UMI_TAG_REGEX)].map(x => x[1].toLowerCase()));
|
||||
|
||||
|
||||
const start = umiSubPrompt.index;
|
||||
const end = umiSubPrompt.index + umiSubPrompt[0].length;
|
||||
if (textArea.selectionStart >= start && textArea.selectionStart <= end) {
|
||||
@@ -74,7 +74,7 @@ class UmiParser extends BaseTagParser {
|
||||
//console.log({ matches })
|
||||
|
||||
const filteredWildcards = (tagword) => {
|
||||
const wildcards = yamlWildcards.filter(x => {
|
||||
const wildcards = umiWildcards.filter(x => {
|
||||
let tags = x[1];
|
||||
const matchesNeg =
|
||||
matches.negative.length === 0
|
||||
@@ -113,7 +113,7 @@ class UmiParser extends BaseTagParser {
|
||||
|| !matches.all.includes(x[0])
|
||||
);
|
||||
}
|
||||
|
||||
|
||||
if (umiTags.length > 0) {
|
||||
// Get difference for subprompt
|
||||
let tagCountChange = umiTags.length - umiPreviousTags.length;
|
||||
@@ -129,7 +129,7 @@ class UmiParser extends BaseTagParser {
|
||||
return;
|
||||
}
|
||||
|
||||
let umiTagword = diff[0] || '';
|
||||
let umiTagword = tagCountChange < 0 ? '' : diff[0] || '';
|
||||
let tempResults = [];
|
||||
if (umiTagword && umiTagword.length > 0) {
|
||||
umiTagword = umiTagword.toLowerCase().replace(/[\n\r]/g, "");
|
||||
@@ -144,48 +144,53 @@ class UmiParser extends BaseTagParser {
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
tempResults.forEach(t => {
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.yamlWildcard)
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.umiWildcard)
|
||||
result.count = t[1];
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
finalResults = finalResults.sort((a, b) => b.count - a.count);
|
||||
return finalResults;
|
||||
} else if (showAll) {
|
||||
let filteredWildcardsSorted = filteredWildcards("");
|
||||
|
||||
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
filteredWildcardsSorted.forEach(t => {
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.yamlWildcard)
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.umiWildcard)
|
||||
result.count = t[1];
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
|
||||
originalTagword = tagword;
|
||||
tagword = "";
|
||||
|
||||
finalResults = finalResults.sort((a, b) => b.count - a.count);
|
||||
return finalResults;
|
||||
}
|
||||
} else {
|
||||
let filteredWildcardsSorted = filteredWildcards("");
|
||||
|
||||
|
||||
// Add final results
|
||||
let finalResults = [];
|
||||
filteredWildcardsSorted.forEach(t => {
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.yamlWildcard)
|
||||
let result = new AutocompleteResult(t[0].trim(), ResultType.umiWildcard)
|
||||
result.count = t[1];
|
||||
finalResults.push(result);
|
||||
});
|
||||
|
||||
originalTagword = tagword;
|
||||
tagword = "";
|
||||
|
||||
finalResults = finalResults.sort((a, b) => b.count - a.count);
|
||||
return finalResults;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function updateUmiTags( tagType, sanitizedText, newPrompt, textArea) {
|
||||
// If it was a yaml wildcard, also update the umiPreviousTags
|
||||
if (tagType === ResultType.yamlWildcard && originalTagword.length > 0) {
|
||||
function updateUmiTags(tagType, sanitizedText, newPrompt, textArea) {
|
||||
// If it was a umi wildcard, also update the umiPreviousTags
|
||||
if (tagType === ResultType.umiWildcard && originalTagword.length > 0) {
|
||||
let umiSubPrompts = [...newPrompt.matchAll(UMI_PROMPT_REGEX)];
|
||||
|
||||
let umiTags = [];
|
||||
@@ -203,11 +208,11 @@ function updateUmiTags( tagType, sanitizedText, newPrompt, textArea) {
|
||||
}
|
||||
|
||||
async function load() {
|
||||
if (yamlWildcards.length === 0) {
|
||||
if (umiWildcards.length === 0) {
|
||||
try {
|
||||
let yamlTags = (await readFile(`${tagBasePath}/temp/wcet.txt`)).split("\n");
|
||||
let umiTags = (await readFile(`${tagBasePath}/temp/umi_tags.txt`)).split("\n");
|
||||
// Split into tag, count pairs
|
||||
yamlWildcards = yamlTags.map(x => x
|
||||
umiWildcards = umiTags.map(x => x
|
||||
.trim()
|
||||
.split(","))
|
||||
.map(([i, ...rest]) => [
|
||||
@@ -218,14 +223,14 @@ async function load() {
|
||||
}, {}),
|
||||
]);
|
||||
} catch (e) {
|
||||
console.error("Error loading yaml wildcards: " + e);
|
||||
console.error("Error loading umi wildcards: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function sanitize(tagType, text) {
|
||||
// Replace underscores only if the yaml tag is not using them
|
||||
if (tagType === ResultType.yamlWildcard && !yamlWildcards.includes(text)) {
|
||||
// Replace underscores only if the umi tag is not using them
|
||||
if (tagType === ResultType.umiWildcard && !umiWildcards.includes(text)) {
|
||||
return text.replaceAll("_", " ");
|
||||
}
|
||||
return null;
|
||||
|
||||
@@ -1,24 +1,52 @@
|
||||
// Regex
|
||||
const WC_REGEX = /\b__([^,]+)__([^, ]*)\b/g;
|
||||
const WC_REGEX = new RegExp(/__([^,]+)__([^, ]*)/g);
|
||||
|
||||
// Trigger conditions
|
||||
const WC_TRIGGER = () => TAC_CFG.useWildcards && [...tagword.matchAll(WC_REGEX)].length > 0;
|
||||
const WC_FILE_TRIGGER = () => TAC_CFG.useWildcards && (tagword.startsWith("__") && !tagword.endsWith("__") || tagword === "__");
|
||||
const WC_TRIGGER = () => TAC_CFG.useWildcards && [...tagword.matchAll(new RegExp(WC_REGEX.source.replaceAll("__", escapeRegExp(TAC_CFG.wcWrap)), "g"))].length > 0;
|
||||
const WC_FILE_TRIGGER = () => TAC_CFG.useWildcards && (tagword.startsWith(TAC_CFG.wcWrap) && !tagword.endsWith(TAC_CFG.wcWrap) || tagword === TAC_CFG.wcWrap);
|
||||
|
||||
class WildcardParser extends BaseTagParser {
|
||||
async parse() {
|
||||
// Show wildcards from a file with that name
|
||||
let wcMatch = [...tagword.matchAll(WC_REGEX)]
|
||||
let wcMatch = [...tagword.matchAll(new RegExp(WC_REGEX.source.replaceAll("__", escapeRegExp(TAC_CFG.wcWrap)), "g"))];
|
||||
let wcFile = wcMatch[0][1];
|
||||
let wcWord = wcMatch[0][2];
|
||||
|
||||
// Look in normal wildcard files
|
||||
let wcFound = wildcardFiles.find(x => x[1].toLowerCase() === wcFile);
|
||||
let wcFound = wildcardFiles.filter(x => x[1].toLowerCase() === wcFile);
|
||||
if (wcFound.length === 0) wcFound = null;
|
||||
// Use found wildcard file or look in external wildcard files
|
||||
let wcPair = wcFound || wildcardExtFiles.find(x => x[1].toLowerCase() === wcFile);
|
||||
let wcPairs = wcFound || wildcardExtFiles.filter(x => x[1].toLowerCase() === wcFile);
|
||||
|
||||
let wildcards = (await readFile(`${wcPair[0]}/${wcPair[1]}.txt`)).split("\n")
|
||||
.filter(x => x.trim().length > 0 && !x.startsWith('#')); // Remove empty lines and comments
|
||||
if (!wcPairs) return [];
|
||||
|
||||
let wildcards = [];
|
||||
for (let i = 0; i < wcPairs.length; i++) {
|
||||
const basePath = wcPairs[i][0];
|
||||
const fileName = wcPairs[i][1];
|
||||
if (!basePath || !fileName) return;
|
||||
|
||||
// YAML wildcards are already loaded as json, so we can get the values directly.
|
||||
// basePath is the name of the file in this case, and fileName the key
|
||||
if (basePath.endsWith(".yaml")) {
|
||||
const getDescendantProp = (obj, desc) => {
|
||||
const arr = desc.split("/");
|
||||
while (arr.length) {
|
||||
obj = obj[arr.shift()];
|
||||
}
|
||||
return obj;
|
||||
}
|
||||
wildcards = wildcards.concat(getDescendantProp(yamlWildcards[basePath], fileName));
|
||||
} else {
|
||||
const fileContent = (await fetchTacAPI(`tacapi/v1/wildcard-contents?basepath=${basePath}&filename=${fileName}.txt`, false))
|
||||
.split("\n")
|
||||
.filter(x => x.trim().length > 0 && !x.startsWith('#')); // Remove empty lines and comments
|
||||
wildcards = wildcards.concat(fileContent);
|
||||
}
|
||||
}
|
||||
|
||||
if (TAC_CFG.sortWildcardResults)
|
||||
wildcards.sort((a, b) => a.localeCompare(b));
|
||||
|
||||
let finalResults = [];
|
||||
let tempResults = wildcards.filter(x => (wcWord !== null && wcWord.length > 0) ? x.toLowerCase().includes(wcWord) : x) // Filter by tagword
|
||||
@@ -36,21 +64,36 @@ class WildcardFileParser extends BaseTagParser {
|
||||
parse() {
|
||||
// Show available wildcard files
|
||||
let tempResults = [];
|
||||
if (tagword !== "__") {
|
||||
let lmb = (x) => x[1].toLowerCase().includes(tagword.replace("__", ""))
|
||||
if (tagword !== TAC_CFG.wcWrap) {
|
||||
let lmb = (x) => x[1].toLowerCase().includes(tagword.replace(TAC_CFG.wcWrap, ""))
|
||||
tempResults = wildcardFiles.filter(lmb).concat(wildcardExtFiles.filter(lmb)) // Filter by tagword
|
||||
} else {
|
||||
tempResults = wildcardFiles.concat(wildcardExtFiles);
|
||||
}
|
||||
|
||||
let finalResults = [];
|
||||
const alreadyAdded = new Map();
|
||||
// Get final results
|
||||
tempResults.forEach(wcFile => {
|
||||
let result = new AutocompleteResult(wcFile[1].trim(), ResultType.wildcardFile);
|
||||
result.meta = "Wildcard file";
|
||||
// Skip duplicate entries incase multiple files have the same name or yaml category
|
||||
if (alreadyAdded.has(wcFile[1])) return;
|
||||
|
||||
let result = null;
|
||||
if (wcFile[0].endsWith(".yaml")) {
|
||||
result = new AutocompleteResult(wcFile[1].trim(), ResultType.yamlWildcard);
|
||||
result.meta = "YAML wildcard collection";
|
||||
} else {
|
||||
result = new AutocompleteResult(wcFile[1].trim(), ResultType.wildcardFile);
|
||||
result.meta = "Wildcard file";
|
||||
result.sortKey = wcFile[2].trim();
|
||||
}
|
||||
|
||||
finalResults.push(result);
|
||||
alreadyAdded.set(wcFile[1], true);
|
||||
});
|
||||
|
||||
finalResults.sort(getSortFunction());
|
||||
|
||||
return finalResults;
|
||||
}
|
||||
}
|
||||
@@ -58,17 +101,19 @@ class WildcardFileParser extends BaseTagParser {
|
||||
async function load() {
|
||||
if (wildcardFiles.length === 0 && wildcardExtFiles.length === 0) {
|
||||
try {
|
||||
let wcFileArr = (await readFile(`${tagBasePath}/temp/wc.txt`)).split("\n");
|
||||
let wcBasePath = wcFileArr[0].trim(); // First line should be the base path
|
||||
wildcardFiles = wcFileArr.slice(1)
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => [wcBasePath, x.trim().replace(".txt", "")]); // Remove file extension & newlines
|
||||
let wcFileArr = await loadCSV(`${tagBasePath}/temp/wc.txt`);
|
||||
if (wcFileArr && wcFileArr.length > 0) {
|
||||
let wcBasePath = wcFileArr[0][0].trim(); // First line should be the base path
|
||||
wildcardFiles = wcFileArr.slice(1)
|
||||
.filter(x => x[0]?.trim().length > 0) //Remove empty lines
|
||||
.map(x => [wcBasePath, x[0]?.trim().replace(".txt", ""), x[1]]); // Remove file extension & newlines
|
||||
}
|
||||
|
||||
// To support multiple sources, we need to separate them using the provided "-----" strings
|
||||
let wcExtFileArr = (await readFile(`${tagBasePath}/temp/wce.txt`)).split("\n");
|
||||
let wcExtFileArr = await loadCSV(`${tagBasePath}/temp/wce.txt`);
|
||||
let splitIndices = [];
|
||||
for (let index = 0; index < wcExtFileArr.length; index++) {
|
||||
if (wcExtFileArr[index].trim() === "-----") {
|
||||
if (wcExtFileArr[index][0].trim() === "-----") {
|
||||
splitIndices.push(index);
|
||||
}
|
||||
}
|
||||
@@ -79,14 +124,25 @@ async function load() {
|
||||
let end = splitIndices[i];
|
||||
|
||||
let wcExtFile = wcExtFileArr.slice(start, end);
|
||||
let base = wcExtFile[0].trim() + "/";
|
||||
wcExtFile = wcExtFile.slice(1)
|
||||
.filter(x => x.trim().length > 0) // Remove empty lines
|
||||
.map(x => x.trim().replace(base, "").replace(".txt", "")); // Remove file extension & newlines;
|
||||
|
||||
wcExtFile = wcExtFile.map(x => [base, x]);
|
||||
wildcardExtFiles.push(...wcExtFile);
|
||||
if (wcExtFile && wcExtFile.length > 0) {
|
||||
let base = wcExtFile[0][0].trim() + "/";
|
||||
wcExtFile = wcExtFile.slice(1)
|
||||
.filter(x => x[0]?.trim().length > 0) //Remove empty lines
|
||||
.map(x => [base, x[0]?.trim().replace(base, "").replace(".txt", ""), x[1]]);
|
||||
wildcardExtFiles.push(...wcExtFile);
|
||||
}
|
||||
}
|
||||
|
||||
// Load the yaml wildcard json file and append it as a wildcard file, appending each key as a path component until we reach the end
|
||||
yamlWildcards = await readFile(`${tagBasePath}/temp/wc_yaml.json`, true);
|
||||
|
||||
// Append each key as a path component until we reach a leaf
|
||||
Object.keys(yamlWildcards).forEach(file => {
|
||||
const flattened = flatten(yamlWildcards[file], [], "/");
|
||||
Object.keys(flattened).forEach(key => {
|
||||
wildcardExtFiles.push([file, key]);
|
||||
});
|
||||
});
|
||||
} catch (e) {
|
||||
console.error("Error loading wildcards: " + e);
|
||||
}
|
||||
@@ -94,20 +150,19 @@ async function load() {
|
||||
}
|
||||
|
||||
function sanitize(tagType, text) {
|
||||
if (tagType === ResultType.wildcardFile) {
|
||||
return `__${text}__`;
|
||||
if (tagType === ResultType.wildcardFile || tagType === ResultType.yamlWildcard) {
|
||||
return `${TAC_CFG.wcWrap}${text}${TAC_CFG.wcWrap}`;
|
||||
} else if (tagType === ResultType.wildcardTag) {
|
||||
return text.replace(/^.*?: /g, "");
|
||||
return text;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
function keepOpenIfWildcard(tagType, sanitizedText, newPrompt, textArea) {
|
||||
// If it's a wildcard, we want to keep the results open so the user can select another wildcard
|
||||
if (tagType === ResultType.wildcardFile) {
|
||||
if (tagType === ResultType.wildcardFile || tagType === ResultType.yamlWildcard) {
|
||||
hideBlocked = true;
|
||||
autocomplete(textArea, newPrompt, sanitizedText);
|
||||
setTimeout(() => { hideBlocked = false; }, 100);
|
||||
setTimeout(() => { hideBlocked = false; }, 450);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
85
scripts/model_keyword_support.py
Normal file
85
scripts/model_keyword_support.py
Normal file
@@ -0,0 +1,85 @@
|
||||
# This file provides support for the model-keyword extension to add known lora keywords on completion
|
||||
|
||||
import csv
|
||||
import hashlib
|
||||
from pathlib import Path
|
||||
|
||||
from scripts.shared_paths import EXT_PATH, STATIC_TEMP_PATH, TEMP_PATH
|
||||
|
||||
# Set up our hash cache
|
||||
known_hashes_file = TEMP_PATH.joinpath("known_lora_hashes.txt")
|
||||
known_hashes_file.touch()
|
||||
file_needs_update = False
|
||||
|
||||
# Load the hashes from the file
|
||||
hash_dict = {}
|
||||
|
||||
|
||||
def load_hash_cache():
|
||||
if not known_hashes_file.exists():
|
||||
known_hashes_file.touch()
|
||||
with open(known_hashes_file, "r", encoding="utf-8") as file:
|
||||
reader = csv.reader(
|
||||
file.readlines(), delimiter=",", quotechar='"', skipinitialspace=True
|
||||
)
|
||||
for line in reader:
|
||||
name, hash, mtime = line
|
||||
hash_dict[name] = (hash, mtime)
|
||||
|
||||
|
||||
def update_hash_cache():
|
||||
global file_needs_update
|
||||
if file_needs_update:
|
||||
if not known_hashes_file.exists():
|
||||
known_hashes_file.touch()
|
||||
with open(known_hashes_file, "w", encoding="utf-8", newline='') as file:
|
||||
writer = csv.writer(file)
|
||||
for name, (hash, mtime) in hash_dict.items():
|
||||
writer.writerow([name, hash, mtime])
|
||||
|
||||
|
||||
# Copy of the fast inaccurate hash function from the extension
|
||||
# with some modifications to load from and write to the cache
|
||||
def get_lora_simple_hash(path):
|
||||
global file_needs_update
|
||||
mtime = str(Path(path).stat().st_mtime)
|
||||
filename = Path(path).name
|
||||
|
||||
if filename in hash_dict:
|
||||
(hash, old_mtime) = hash_dict[filename]
|
||||
if mtime == old_mtime:
|
||||
return hash
|
||||
try:
|
||||
with open(path, "rb") as file:
|
||||
m = hashlib.sha256()
|
||||
|
||||
file.seek(0x100000)
|
||||
m.update(file.read(0x10000))
|
||||
hash = m.hexdigest()[0:8]
|
||||
|
||||
hash_dict[filename] = (hash, mtime)
|
||||
file_needs_update = True
|
||||
|
||||
return hash
|
||||
except FileNotFoundError:
|
||||
return "NOFILE"
|
||||
|
||||
|
||||
# Find the path of the original model-keyword extension
|
||||
def write_model_keyword_path():
|
||||
# Ensure the file exists even if the extension is not installed
|
||||
mk_path = STATIC_TEMP_PATH.joinpath("modelKeywordPath.txt")
|
||||
mk_path.write_text("")
|
||||
|
||||
base_keywords = list(EXT_PATH.glob("*/lora-keyword.txt"))
|
||||
custom_keywords = list(EXT_PATH.glob("*/lora-keyword-user.txt"))
|
||||
custom_found = custom_keywords is not None and len(custom_keywords) > 0
|
||||
if base_keywords is not None and len(base_keywords) > 0:
|
||||
with open(mk_path, "w", encoding="utf-8") as f:
|
||||
f.write(f"{base_keywords[0].parent.as_posix()},{custom_found}")
|
||||
return True
|
||||
else:
|
||||
print(
|
||||
"Tag Autocomplete: Could not locate model-keyword extension, Lora trigger word completion will be limited to those added through the extra networks menu."
|
||||
)
|
||||
return False
|
||||
92
scripts/shared_paths.py
Normal file
92
scripts/shared_paths.py
Normal file
@@ -0,0 +1,92 @@
|
||||
from pathlib import Path
|
||||
|
||||
from modules import scripts, shared
|
||||
|
||||
try:
|
||||
from modules.paths import extensions_dir, script_path
|
||||
|
||||
# Webui root path
|
||||
FILE_DIR = Path(script_path).absolute()
|
||||
|
||||
# The extension base path
|
||||
EXT_PATH = Path(extensions_dir).absolute()
|
||||
except ImportError:
|
||||
# Webui root path
|
||||
FILE_DIR = Path().absolute()
|
||||
# The extension base path
|
||||
EXT_PATH = FILE_DIR.joinpath("extensions").absolute()
|
||||
|
||||
# Tags base path
|
||||
TAGS_PATH = Path(scripts.basedir()).joinpath("tags").absolute()
|
||||
|
||||
# The path to the folder containing the wildcards and embeddings
|
||||
try: # SD.Next
|
||||
WILDCARD_PATH = Path(shared.opts.wildcards_dir).absolute()
|
||||
except Exception: # A1111
|
||||
WILDCARD_PATH = FILE_DIR.joinpath("scripts/wildcards").absolute()
|
||||
EMB_PATH = Path(shared.cmd_opts.embeddings_dir).absolute()
|
||||
|
||||
# Forge Classic detection
|
||||
try:
|
||||
from modules_forge.forge_version import version as forge_version
|
||||
IS_FORGE_CLASSIC = forge_version == "classic"
|
||||
except ImportError:
|
||||
IS_FORGE_CLASSIC = False
|
||||
|
||||
# Forge Classic skips it
|
||||
if not IS_FORGE_CLASSIC:
|
||||
try:
|
||||
HYP_PATH = Path(shared.cmd_opts.hypernetwork_dir).absolute()
|
||||
except AttributeError:
|
||||
HYP_PATH = None
|
||||
else:
|
||||
HYP_PATH = None
|
||||
|
||||
try:
|
||||
LORA_PATH = Path(shared.cmd_opts.lora_dir).absolute()
|
||||
except AttributeError:
|
||||
LORA_PATH = None
|
||||
|
||||
try:
|
||||
try:
|
||||
LYCO_PATH = Path(shared.cmd_opts.lyco_dir_backcompat).absolute()
|
||||
except:
|
||||
LYCO_PATH = Path(shared.cmd_opts.lyco_dir).absolute() # attempt original non-backcompat path
|
||||
except AttributeError:
|
||||
LYCO_PATH = None
|
||||
|
||||
|
||||
def find_ext_wildcard_paths():
|
||||
"""Returns the path to the extension wildcards folder"""
|
||||
found = list(EXT_PATH.glob("*/wildcards/"))
|
||||
# Try to find the wildcard path from the shared opts
|
||||
try:
|
||||
from modules.shared import opts
|
||||
except ImportError: # likely not in an a1111 context
|
||||
opts = None
|
||||
|
||||
# Append custom wildcard paths
|
||||
custom_paths = [
|
||||
getattr(shared.cmd_opts, "wildcards_dir", None), # Cmd arg from the wildcard extension
|
||||
getattr(opts, "wildcard_dir", None), # Custom path from sd-dynamic-prompts
|
||||
]
|
||||
for path in [Path(p).absolute() for p in custom_paths if p is not None]:
|
||||
if path.exists():
|
||||
found.append(path)
|
||||
|
||||
return found
|
||||
|
||||
|
||||
# The path to the extension wildcards folder
|
||||
WILDCARD_EXT_PATHS = find_ext_wildcard_paths()
|
||||
|
||||
# The path to the temporary files
|
||||
# In the webui root, on windows it exists by default, on linux it doesn't
|
||||
STATIC_TEMP_PATH = FILE_DIR.joinpath("tmp").absolute()
|
||||
TEMP_PATH = TAGS_PATH.joinpath("temp").absolute() # Extension specific temp files
|
||||
|
||||
# Make sure these folders exist
|
||||
if not TEMP_PATH.exists():
|
||||
TEMP_PATH.mkdir()
|
||||
if not STATIC_TEMP_PATH.exists():
|
||||
STATIC_TEMP_PATH.mkdir()
|
||||
File diff suppressed because it is too large
Load Diff
190
scripts/tag_frequency_db.py
Normal file
190
scripts/tag_frequency_db.py
Normal file
@@ -0,0 +1,190 @@
|
||||
import sqlite3
|
||||
from contextlib import contextmanager
|
||||
|
||||
from scripts.shared_paths import TAGS_PATH
|
||||
|
||||
db_file = TAGS_PATH.joinpath("tag_frequency.db")
|
||||
timeout = 30
|
||||
db_ver = 1
|
||||
|
||||
|
||||
@contextmanager
|
||||
def transaction(db=db_file):
|
||||
"""Context manager for database transactions.
|
||||
Ensures that the connection is properly closed after the transaction.
|
||||
"""
|
||||
try:
|
||||
conn = sqlite3.connect(db, timeout=timeout)
|
||||
|
||||
conn.isolation_level = None
|
||||
cursor = conn.cursor()
|
||||
cursor.execute("BEGIN")
|
||||
yield cursor
|
||||
cursor.execute("COMMIT")
|
||||
except sqlite3.Error as e:
|
||||
print("Tag Autocomplete: Frequency database error:", e)
|
||||
finally:
|
||||
if conn:
|
||||
conn.close()
|
||||
|
||||
|
||||
class TagFrequencyDb:
|
||||
"""Class containing creation and interaction methods for the tag frequency database"""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.version = self.__check()
|
||||
|
||||
def __check(self):
|
||||
if not db_file.exists():
|
||||
print("Tag Autocomplete: Creating frequency database")
|
||||
with transaction() as cursor:
|
||||
self.__create_db(cursor)
|
||||
self.__update_db_data(cursor, "version", db_ver)
|
||||
print("Tag Autocomplete: Database successfully created")
|
||||
|
||||
return self.__get_version()
|
||||
|
||||
def __create_db(self, cursor: sqlite3.Cursor):
|
||||
cursor.execute(
|
||||
"""
|
||||
CREATE TABLE IF NOT EXISTS db_data (
|
||||
key TEXT PRIMARY KEY,
|
||||
value TEXT
|
||||
)
|
||||
"""
|
||||
)
|
||||
|
||||
cursor.execute(
|
||||
"""
|
||||
CREATE TABLE IF NOT EXISTS tag_frequency (
|
||||
name TEXT NOT NULL,
|
||||
type INT NOT NULL,
|
||||
count_pos INT,
|
||||
count_neg INT,
|
||||
last_used TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
||||
PRIMARY KEY (name, type)
|
||||
)
|
||||
"""
|
||||
)
|
||||
|
||||
def __update_db_data(self, cursor: sqlite3.Cursor, key, value):
|
||||
cursor.execute(
|
||||
"""
|
||||
INSERT OR REPLACE
|
||||
INTO db_data (key, value)
|
||||
VALUES (?, ?)
|
||||
""",
|
||||
(key, value),
|
||||
)
|
||||
|
||||
def __get_version(self):
|
||||
db_version = None
|
||||
with transaction() as cursor:
|
||||
cursor.execute(
|
||||
"""
|
||||
SELECT value
|
||||
FROM db_data
|
||||
WHERE key = 'version'
|
||||
"""
|
||||
)
|
||||
db_version = cursor.fetchone()
|
||||
|
||||
return db_version[0] if db_version else 0
|
||||
|
||||
def get_all_tags(self):
|
||||
with transaction() as cursor:
|
||||
cursor.execute(
|
||||
f"""
|
||||
SELECT name, type, count_pos, count_neg, last_used
|
||||
FROM tag_frequency
|
||||
WHERE count_pos > 0 OR count_neg > 0
|
||||
ORDER BY count_pos + count_neg DESC
|
||||
"""
|
||||
)
|
||||
tags = cursor.fetchall()
|
||||
|
||||
return tags
|
||||
|
||||
def get_tag_count(self, tag, ttype, negative=False):
|
||||
count_str = "count_neg" if negative else "count_pos"
|
||||
with transaction() as cursor:
|
||||
cursor.execute(
|
||||
f"""
|
||||
SELECT {count_str}, last_used
|
||||
FROM tag_frequency
|
||||
WHERE name = ? AND type = ?
|
||||
""",
|
||||
(tag, ttype),
|
||||
)
|
||||
tag_count = cursor.fetchone()
|
||||
|
||||
if tag_count:
|
||||
return tag_count[0], tag_count[1]
|
||||
else:
|
||||
return 0, None
|
||||
|
||||
def get_tag_counts(self, tags: list[str], ttypes: list[str], negative=False, date_limit=None):
|
||||
count_str = "count_neg" if negative else "count_pos"
|
||||
with transaction() as cursor:
|
||||
for tag, ttype in zip(tags, ttypes):
|
||||
if date_limit is not None:
|
||||
cursor.execute(
|
||||
f"""
|
||||
SELECT {count_str}, last_used
|
||||
FROM tag_frequency
|
||||
WHERE name = ? AND type = ?
|
||||
AND last_used > datetime('now', '-' || ? || ' days')
|
||||
""",
|
||||
(tag, ttype, date_limit),
|
||||
)
|
||||
else:
|
||||
cursor.execute(
|
||||
f"""
|
||||
SELECT {count_str}, last_used
|
||||
FROM tag_frequency
|
||||
WHERE name = ? AND type = ?
|
||||
""",
|
||||
(tag, ttype),
|
||||
)
|
||||
tag_count = cursor.fetchone()
|
||||
if tag_count:
|
||||
yield (tag, ttype, tag_count[0], tag_count[1])
|
||||
else:
|
||||
yield (tag, ttype, 0, None)
|
||||
|
||||
def increase_tag_count(self, tag, ttype, negative=False):
|
||||
pos_count = self.get_tag_count(tag, ttype, False)[0]
|
||||
neg_count = self.get_tag_count(tag, ttype, True)[0]
|
||||
|
||||
if negative:
|
||||
neg_count += 1
|
||||
else:
|
||||
pos_count += 1
|
||||
|
||||
with transaction() as cursor:
|
||||
cursor.execute(
|
||||
f"""
|
||||
INSERT OR REPLACE
|
||||
INTO tag_frequency (name, type, count_pos, count_neg)
|
||||
VALUES (?, ?, ?, ?)
|
||||
""",
|
||||
(tag, ttype, pos_count, neg_count),
|
||||
)
|
||||
|
||||
def reset_tag_count(self, tag, ttype, positive=True, negative=False):
|
||||
if positive and negative:
|
||||
set_str = "count_pos = 0, count_neg = 0"
|
||||
elif positive:
|
||||
set_str = "count_pos = 0"
|
||||
elif negative:
|
||||
set_str = "count_neg = 0"
|
||||
|
||||
with transaction() as cursor:
|
||||
cursor.execute(
|
||||
f"""
|
||||
UPDATE tag_frequency
|
||||
SET {set_str}
|
||||
WHERE name = ? AND type = ?
|
||||
""",
|
||||
(tag, ttype),
|
||||
)
|
||||
113301
tags/EnglishDictionary.csv
Normal file
113301
tags/EnglishDictionary.csv
Normal file
File diff suppressed because it is too large
Load Diff
238668
tags/danbooru.csv
238668
tags/danbooru.csv
File diff suppressed because it is too large
Load Diff
221787
tags/danbooru_e621_merged.csv
Normal file
221787
tags/danbooru_e621_merged.csv
Normal file
File diff suppressed because one or more lines are too long
@@ -28,5 +28,17 @@
|
||||
"terms": "Water, Magic, Fancy",
|
||||
"content": "(extremely detailed CG unity 8k wallpaper), (masterpiece), (best quality), (ultra-detailed), (best illustration),(best shadow), (an extremely delicate and beautiful), classic, dynamic angle, floating, fine detail, Depth of field, classic, (painting), (sketch), (bloom), (shine), glinting stars,\n\na girl, solo, bare shoulders, flat chest, diamond and glaring eyes, beautiful detailed cold face, very long blue and sliver hair, floating black feathers, wavy hair, extremely delicate and beautiful girls, beautiful detailed eyes, glowing eyes,\n\nriver, (forest),palace, (fairyland,feather,flowers, nature),(sunlight),Hazy fog, mist",
|
||||
"color": 5
|
||||
},
|
||||
{
|
||||
"name": "Pony-Positive",
|
||||
"terms": "Pony,Score,Positive,Quality",
|
||||
"content": "score_9, score_8_up, score_7_up, score_6_up, source_anime, source_furry, source_pony, source_cartoon",
|
||||
"color": 1
|
||||
},
|
||||
{
|
||||
"name": "Pony-Negative",
|
||||
"terms": "Pony,Score,Negative,Quality",
|
||||
"content": "score_1, score_2, score_3, score_4, score_5, source_anime, source_furry, source_pony, source_cartoon",
|
||||
"color": 3
|
||||
}
|
||||
]
|
||||
110665
tags/derpibooru.csv
Normal file
110665
tags/derpibooru.csv
Normal file
File diff suppressed because it is too large
Load Diff
200358
tags/e621.csv
200358
tags/e621.csv
File diff suppressed because one or more lines are too long
22419
tags/e621_sfw.csv
Normal file
22419
tags/e621_sfw.csv
Normal file
File diff suppressed because one or more lines are too long
160178
tags/noob_characters-chants.json
Normal file
160178
tags/noob_characters-chants.json
Normal file
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user